
十五. 迭代器与闭包
1. 闭包:能够捕获环境的匿名函数
Rust 中的闭包是一种匿名函数,它可以被存入变量或作为参数传递给其他函数。你可以在一个地方创建闭包,然后在不同的上下文中调用它来执行运算。与普通函数不同,闭包的关键特性在于它能够从其被定义的作用域中捕获并使用外部环境的值。后续将展示如何利用这些特性来实现代码复用和行为自定义。
①使用闭包捕获环境
// 示例 13-1: T恤公司的赠送方案
// 1. 定义颜色枚举 ShirtColor
#[derive(Debug, PartialEq, Copy, Clone)]
enum ShirtColor {
Red,
Blue,
// 为简单起见,只使用两种颜色
}
// 2. 定义库存结构体 Inventory
struct Inventory {
shirts: Vec<ShirtColor>, // 库存T恤颜色列表
}
impl Inventory {
// giveaway 方法: 根据用户偏好返回T恤颜色
// 参数 user_preference: 用户颜色偏好,有值则送对应颜色,无值则送库存最多的颜色
fn giveaway(
&self,
user_preference: Option<ShirtColor>,
) -> ShirtColor {
// 使用闭包: 当user_preference为None时,调用self.most_stocked()获取库存最多的颜色
// 闭包 || self.most_stocked() 捕获当前Inventory实例的引用
user_preference.unwrap_or_else(|| self.most_stocked())
}
// most_stocked 方法: 统计并返回库存最多的颜色
fn most_stocked(&self) -> ShirtColor {
let mut num_red = 0;
let mut num_blue = 0;
// 遍历库存,统计红蓝T恤数量
for color in &self.shirts {
match color {
ShirtColor::Red => num_red += 1,
ShirtColor::Blue => num_blue += 1,
}
}
// 返回数量较多的颜色
if num_red > num_blue {
ShirtColor::Red
} else {
ShirtColor::Blue
}
}
}
// 3. 主函数演示
fn main() {
// 创建库存实例,包含2件蓝色和1件红色T恤
let store = Inventory {
shirts: vec![
ShirtColor::Blue,
ShirtColor::Red,
ShirtColor::Blue,
],
};
// 用户1: 有颜色偏好(红色)
let user_pref1 = Some(ShirtColor::Red);
let giveaway1 = store.giveaway(user_pref1);
println!(
"用户偏好 {:?} 获得 {:?}",
user_pref1, giveaway1
);
// 输出: 用户偏好 Some(Red) 获得 Red
// 用户2: 无颜色偏好
let user_pref2 = None;
let giveaway2 = store.giveaway(user_pref2);
println!(
"用户偏好 {:?} 获得 {:?}",
user_pref2, giveaway2
);
// 输出: 用户偏好 None 获得 Blue
}
// 核心要点:
// 1. 闭包 || self.most_stocked() 捕获了当前 Inventory 实例的不可变引用
// 2. unwrap_or_else 方法在需要时才执行闭包,实现惰性求值
// 3. 闭包可以捕获其定义环境中的值,这是普通函数无法做到的
// 4. 此设计将业务逻辑(如何选择颜色)与标准库方法解耦,提高代码复用性②闭包的类型推断和标注
// 函数与闭包在类型标注上的主要差异:
// 1. 函数必须标注参数和返回值类型,因为它们是公开接口的一部分,需要明确约定。
// 2. 闭包通常存储在变量中,不用于公开接口,且通常很短小,编译器可推断其类型,因此通常无需标注。
// 但在需要明确性或特殊场景下,仍可为闭包手动添加类型标注。
// 示例 13-2: 展示为闭包添加可选类型标注的四种等效写法
// 以下四个闭包都实现为参数加1并返回的功能,展示了从完全标注到完全推断的渐进变化
let add_one_v1 = |x: u32| -> u32 { x + 1 }; // 完整标注类型
let add_one_v2 = |x| { x + 1 }; // 省略类型标注
let add_one_v3 = |x| x + 1; // 省略花括号(单个表达式)
let add_one_v4 = |x| x + 1; // 同v3,强调类型需在调用时推导
// 类比:闭包的类型推导类似于 `let v = Vec::new()`,
// 需要在调用时通过使用上下文来推断具体类型。
// 示例 13-3: 演示闭包类型推导的具体性
// 闭包定义中的每个参数和返回值都会被推导为具体的、单一的类型
let example_closure = |x| x; // 未标注类型,可接受任意类型调用
// 第一次用 String 调用,编译器将 x 的参数和返回类型都推导为 String
let s = example_closure(String::from("hello"));
// 第二次尝试用整数调用,会导致编译错误
// 错误信息:期望 String 类型,实际找到整数
// 因为闭包 example_closure 的类型已固定为接收并返回 String
let n = example_closure(5); // 编译错误:类型不匹配
// 核心总结:
// 1. 闭包类型标注可选,编译器通常可推断。
// 2. 但每个闭包实例的参数和返回值类型是具体且唯一的,一旦通过使用推导出类型,就无法再改变。
// 3. 这与函数的严格类型标注形成对比,体现了闭包作为"匿名函数"的灵活性与限制。③捕获引用或所有权
// src/main.rs
// 示例 13-4: 定义并调用一个捕获不可变引用的闭包
// 闭包捕获环境的三种方式:不可变借用、可变借用、获取所有权
// 本示例闭包通过不可变借用捕获 list,因为只需打印而不修改
fn main() {
let list = vec![1, 2, 3];
println!("Before defining closure: {:?}", list);
// ① 闭包定义:捕获 list 的不可变引用用于打印
let only_borrows = || println!("From closure: {:?}", list);
println!("Before calling closure: {:?}", list);
// ② 调用闭包
only_borrows();
println!("After calling closure: {:?}", list);
}// src/main.rs
// 示例 13-5: 定义并调用一个捕获可变引用的闭包
// 本例修改闭包体,向 list 添加元素,因此闭包捕获可变引用
fn main() {
let mut list = vec![1, 2, 3];
println!("Before defining closure: {:?}", list);
// 定义捕获可变引用的闭包
let mut borrows_mutably = || list.push(7);
// 注意:不可在闭包定义与调用间添加 println! 访问 list
// 因为可变借用存在时,不允许其他借用(包括不可变借用)
// 尝试在此处添加 println!("{:?}", list) 会导致编译错误
borrows_mutably();
// 可变借用结束,可安全访问 list
println!("After calling closure: {:?}", list);
}
// 运行输出:
// Before defining closure: [1, 2, 3]
// After calling closure: [1, 2, 3, 7]// src/main.rs
// 示例 13-6: 使用 move 关键字强制闭包为线程取得 list 的所有权
// 背景:创建新线程时,需确保闭包内捕获数据的有效性
// move 强制闭包获取捕获值的所有权,避免主线程提前结束导致悬垂引用
use std::thread;
fn main() {
let list = vec![1, 2, 3];
println!("Before defining closure: {:?}", list);
// ① 使用 move 关键字强制闭包获取 list 的所有权
// 即使闭包体仅需不可变引用(② 处),也必须 move
// 原因:新线程执行时机不确定,需保证 list 在闭包内有效
thread::spawn(move || {
// ② 闭包体只需不可变引用,但必须拥有所有权
println!("From thread: {:?}", list)
}).join().unwrap();
// 注意:定义闭包后,主线程无法再使用 list,因其所有权已转移
// 尝试移除 move 或在此处使用 list 将导致编译错误
}④将捕获的值移出闭包及Fn系列trait
闭包会从外部环境捕获变量,其具体的捕获方式(是获取所有权、可变借用还是不可变借用)由闭包体的代码行为自动决定。这种行为决定了闭包会自动实现哪些
Fn系列的 trait。Rust 为闭包定义了三种 trait:
FnOnce:所有闭包都至少实现此 trait,表示闭包可以被调用一次。如果一个闭包会将其捕获的某个值的所有权移出自身(即消费掉这个值),那么它只实现 FnOnce,因为该操作只能安全地执行一次。
FnMut:适用于那些需要修改捕获的值,但不会将值的所有权移出闭包的闭包。此类闭包可以被多次调用。
Fn:适用于那些仅需要不可变地访问捕获的值,或者根本不捕获任何外部值的闭包。它们可以被多次调用,甚至安全地用于并发场景,因为调用不会改变环境状态。
// src/main.rs
// 示例 13-1: Option<T> 的 unwrap_or_else 方法定义
// 此方法接收一个闭包作为参数,当 Option 为 None 时调用该闭包生成默认值
// 闭包必须实现 FnOnce() -> T trait,表示可被调用一次,无参数,返回 T 类型
impl<T> Option<T> {
fn unwrap_or_else<F>(self, f: F) -> T
where
F: FnOnce() -> T, // 闭包必须实现 FnOnce trait
{
match self {
Some(x) => x, // Some 时直接返回值
None => f(), // None 时调用闭包生成默认值
}
}
}
// 示例 13-7: 使用 sort_by_key 对矩形按宽度排序
// sort_by_key 方法接收一个闭包,该闭包会被多次调用,因此需要 FnMut trait
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
// 闭包 |r| r.width 无捕获、修改或移出环境的值,实现 FnMut
list.sort_by_key(|r| r.width);
println!("{:#?}", list);
// 输出: 按宽度 3, 7, 10 排序的矩形列表
}
// 示例 13-8: 错误的尝试 - 闭包将 value 移出环境,只实现 FnOnce
// 此代码无法通过编译,因为 sort_by_key 需要 FnMut
fn invalid_closure_usage() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
let mut sort_operations = vec![];
let value = String::from("by key called");
// 错误: 闭包将 value 的所有权移入 sort_operations
// 这会导致闭包只能被调用一次,只实现 FnOnce
// 但 sort_by_key 需要 FnMut,因此编译错误
/*
list.sort_by_key(|r| {
sort_operations.push(value); // 错误: 移动了 value
r.width
});
*/
}
// 示例 13-9: 正确的计数器实现,闭包仅捕获可变引用,实现 FnMut
fn valid_counter_usage() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
let mut num_sort_operations = 0;
// 闭包捕获 num_sort_operations 的可变引用
// 每次调用递增计数器,不将值移出环境
// 因此实现 FnMut,可被多次调用
list.sort_by_key(|r| {
num_sort_operations += 1;
r.width
});
println!("{:#?}, sorted in {num_sort_operations} operations", list);
}
// 核心要点总结:
// 1. unwrap_or_else 使用 FnOnce trait,因为闭包最多被调用一次
// 2. sort_by_key 使用 FnMut trait,因为闭包会被多次调用
// 3. 闭包的 trait 实现由其捕获环境的方式决定:
// - 不捕获任何值: 可实现 Fn、FnMut、FnOnce
// - 捕获不可变引用: 可实现 Fn、FnOnce
// - 捕获可变引用: 可实现 FnMut、FnOnce
// - 捕获所有权(移动值): 只实现 FnOnce
// 4. 函数也可以实现 Fn 系列 trait,当不需要捕获环境值时可用函数替代闭包2. 使用迭代器处理元素序列
①介绍
// src/main.rs
// 迭代器模式允许你依次为序列中的每个元素执行某些任务。迭代器会在这个过程中负责遍历每个元素并决定序列何时结束。
// 只要使用了迭代器,我们就可以避免手动实现这些逻辑。
// 在 Rust 中,迭代器是惰性的(lazy)。这就意味着在创建迭代器后,除非你主动调用方法来消耗并使用迭代器,否则它们不会产生任何实际效果。
// 示例 13-10:创建一个迭代器
// 通过调用 Vec<T> 的 iter 方法创建了一个用于遍历动态数组 v1 的迭代器。
// 这段代码本身并不会产生任何影响,因为迭代器尚未被使用。
fn main() {
// 创建一个包含整数 1、2、3 的动态数组
let v1 = vec![1, 2, 3];
// 调用 iter 方法创建迭代器,存储在 v1_iter 变量中
// 此时迭代器尚未被消耗,没有任何实际效果
let v1_iter = v1.iter();
// 迭代器被存储在 v1_iter 变量中。一旦创建了迭代器,我们就可以通过多种方式来使用它。
// 在第3章的示例3-5中,我们曾经使用 for 循环来依次遍历数组的每个元素并执行相关的代码。
// 我们当时一笔带过了它的工作原理,但这段代码实际上隐式地创建并使用了一个迭代器。
// 示例 13-11:在 for 循环中使用迭代器
// 将迭代器的创建和它在 for 循环中的使用分离开来。
// 当 for 循环开始使用 v1_iter 中的迭代器时,迭代器中的每个元素都会被用于循环中的一次迭代,并打印出每个值。
for val in v1_iter {
println!("Got: {val}");
}
// 对于那些没有在标准库中提供迭代器的语言而言,为了实现类似的功能,你通常需要定义一个从0开始的变量作为索引
// 来获得动态数组中的值,并在循环中逐次递增这个变量的值,直到它达到动态数组的总长度为止。
// 迭代器会为我们处理所有上述逻辑,这减少了重复代码并消除了潜在的混乱。
// 另外,迭代器还可以用统一的逻辑来灵活处理各种不同种类的序列,而不仅仅是像动态数组一样可以进行索引的数据结构。
// 让我们来看一看迭代器是如何做到这一点的。
}②Iterator trait和next方法
// src/lib.rs
// 核心概念:迭代器模式允许依次处理序列中的每个元素,而无需手动管理索引和边界。
// Rust 的迭代器是惰性的,除非主动消耗,否则不会产生效果。
// 1. Iterator trait 定义(标准库中,此处为注释说明)
// 所有迭代器都实现标准库中的 Iterator trait。其核心是 next 方法,
// 每次调用返回 Some(Item),迭代结束时返回 None。
// 定义中使用的 type Item 和 Self::Item 是关联类型,指定了迭代器返回元素的类型。
// trait Iterator {
// type Item;
// fn next(&mut self) -> Option<Self::Item>;
// // 其他方法有默认实现,已省略
// }
#[cfg(test)]
mod tests {
#[test]
fn iterator_demonstration() {
let v1 = vec![1, 2, 3];
// 创建迭代器:iter 方法返回不可变引用的迭代器
// 必须声明为 mut,因为调用 next 会改变迭代器内部状态(消耗迭代器)
let mut v1_iter = v1.iter();
// 手动调用 next 方法遍历元素
assert_eq!(v1_iter.next(), Some(&1)); // 返回元素的不可变引用
assert_eq!(v1_iter.next(), Some(&2));
assert_eq!(v1_iter.next(), Some(&3));
assert_eq!(v1_iter.next(), None); // 迭代结束
// 注意:在 for 循环中使用迭代器时,循环会取得所有权并在内部使其可变,
// 因此无需手动声明 mut。
// 其他迭代器创建方法:
// - into_iter: 获取所有权并返回元素本身的迭代器
// - iter_mut: 返回可变引用的迭代器
}
}②消耗迭代器的方法
// src/lib.rs
// 示例 13-13: 调用 sum 方法计算迭代器中所有元素的总和
// 核心概念:sum 是 Iterator trait 的一个消耗适配器,它会获取迭代器的所有权,并反复调用 next 方法遍历元素,最终返回所有元素的总和。
// 测试函数,验证 sum 方法的行为
#[test]
fn iterator_sum() {
// 1. 创建待处理的数据:一个包含 1, 2, 3 的动态数组
let v1 = vec![1, 2, 3];
// 2. 通过 iter 方法获取 v1 的不可变引用迭代器
let v1_iter = v1.iter();
// 3. 调用 sum 方法,对迭代器中的所有元素求和
// 注意:sum 会获取迭代器的所有权,因此调用后 v1_iter 不能再被使用
let total: i32 = v1_iter.sum();
// 4. 断言求和结果正确
assert_eq!(total, 6);
}
/*
* 核心要点(基于两张图片内容):
* 1. Iterator trait 提供了许多带有默认实现的方法,可在标准库 API 文档中查阅。
* 2. 其中部分方法(如 sum)会调用 next 方法,因此实现 Iterator trait 时必须手动定义 next 方法。
* 3. 调用 next 的方法被称为消耗适配器,因为它们会消耗(获取所有权)迭代器本身。
* 4. 在调用 sum 方法后,迭代器 v1_iter 的所有权被获取,无法再被后续代码使用。
* 5. 迭代器是惰性的,但消耗适配器会主动遍历并消耗迭代器,产生最终结果。
*/③生成迭代器的其他方法
// src/main.rs
// 示例 13-14: 调用 map 方法创建新的迭代器
// 核心概念:迭代器适配器(如 map)不立即执行,而是返回一个新的迭代器
// 注意:此代码会因迭代器未被消耗而触发编译警告
// 定义 Vec<i32> 类型的 v1
let v1: Vec<i32> = vec![1, 2, 3];
// 调用 map 方法创建新迭代器,为每个元素加1
// 由于迭代器是惰性的,此操作不会立即执行
v1.iter().map(|x| x + 1);
// 编译警告:
// warning: unused `Map` that must be used
// note: iterators are lazy and do nothing unless consumed
// 含义:迭代器是惰性的,除非被消耗,否则不执行任何操作
// 修复:需调用消耗适配器(如 collect)来触发计算// src/main.rs
// 示例 13-15: 调用 map 方法创建新迭代器,再调用 collect 方法将其转换为动态数组
// 核心概念:通过消耗适配器(如 collect)实际执行迭代操作
// 定义 Vec<i32> 类型的 v1
let v1: Vec<i32> = vec![1, 2, 3];
// 链式调用:iter() 创建迭代器 -> map() 转换元素 -> collect() 收集为动态数组
// collect 会消耗迭代器,执行所有计算,并将结果收集到指定集合类型
let v2: Vec<_> = v1.iter().map(|x| x + 1).collect();
// 断言验证:v2 应包含 v1 中每个元素加1后的值
assert_eq!(v2, vec![2, 3, 4]);
// 设计优势:
// 1. map 接收闭包参数,可对每个元素执行任意操作
// 2. 可链式调用多个迭代器适配器,构建复杂的数据处理管道
// 3. 复用 Iterator trait 的通用迭代功能,通过闭包自定义具体行为
// 4. 由于迭代器是惰性的,此设计支持灵活、高效的数据处理// 核心原则总结(基于图片4):
// 所有迭代器都是惰性的,必须调用某个消耗适配器的方法(如 collect、sum、fold),才能从迭代器适配器中获取最终结果。④使用闭包捕获环境
// src/lib.rs
// 示例 13-16: 通过传入捕获了 shoe_size 变量的闭包来使用 filter 方法
// 核心概念:迭代器适配器 filter 接收一个闭包参数,该闭包返回布尔值决定元素是否被包含在结果中
// 定义 Shoe 结构体,表示鞋子的属性
#[derive(PartialEq, Debug)] // 派生 PartialEq 和 Debug trait 以便于比较和调试
struct Shoe {
size: u32, // 鞋码尺寸
style: String, // 鞋子款式
}
// shoes_in_size 函数:从鞋子动态数组中过滤出指定尺寸的鞋子
// 参数 shoes: 包含 Shoe 结构体的动态数组
// 参数 shoe_size: 目标鞋码尺寸
// 返回值: 包含满足尺寸条件的鞋子动态数组
fn shoes_in_size(shoes: Vec<Shoe>, shoe_size: u32) -> Vec<Shoe> {
// 1. 调用 into_iter 获取动态数组所有权的迭代器
// 2. 调用 filter 适配器,传入闭包捕获外部变量 shoe_size
// 3. 闭包比较每只鞋的尺寸与目标尺寸,返回布尔值
// 4. 调用 collect 收集过滤结果到动态数组
shoes.into_iter().filter(|s| s.size == shoe_size).collect()
}
// 测试模块
#[cfg(test)]
mod tests {
use super::*; // 导入父模块中的所有项
#[test]
fn filters_by_size() {
// 创建测试数据:包含三双不同尺寸的鞋子
let shoes = vec![
Shoe {
size: 10,
style: String::from("sneaker"), // 运动鞋,尺寸 10
},
Shoe {
size: 13,
style: String::from("sandal"), // 凉鞋,尺寸 13
},
Shoe {
size: 10,
style: String::from("boot"), // 靴子,尺寸 10
},
];
// 调用 shoes_in_size 函数,过滤出尺寸为 10 的鞋子
let in_my_size = shoes_in_size(shoes, 10);
// 断言:期望返回的向量包含两双尺寸为 10 的鞋子
assert_eq!(
in_my_size,
vec![
Shoe {
size: 10,
style: String::from("sneaker")
},
Shoe {
size: 10,
style: String::from("boot")
},
]
);
}
}3. 比较循环和迭代器的性能
为了客观比较使用
for循环与迭代器实现search函数的性能,我们以《福尔摩斯探案集》全文作为数据,搜索包含单词“the”的文本行。基准测试结果显示,迭代器版本(bench_search_iter,约 19.2 毫秒/迭代)实际上比for循环版本(bench_search_iter,约 19.6 毫秒/迭代)稍快。这初步证明了迭代器的效率。这种高性能的根源在于,Rust 的迭代器是一种零开销抽象。这意味着,使用迭代器和闭包这样的高级抽象,在编译后生成的底层机器代码,与手动编写的底层代码(如
for循环)几乎一样高效,不会引入额外的运行时开销。这遵循了与 C++ 相同的“零开销”原则:你无需为未使用的功能付费,也无法为已使用的功能手写出更好的代码。一个来自真实音频解码器的案例(使用线性预测算法)清晰地展示了这一点。该代码通过链式调用迭代器适配器(如
zip、map、sum和位操作)对数组和切片进行复杂的数学计算。Rust 编译器能够对此进行深度优化:它知道循环将迭代 12 次,因此会自动执行“循环展开”,消除循环控制的开销;它还能将系数全部存入寄存器以实现快速访问,并省略运行时的数组边界检查。最终,这段高级、抽象的迭代器代码被编译成了与手写汇编相媲美的高效机器码。因此,你可以完全放心地在 Rust 中使用迭代器和闭包。它们既能让你写出表达力强、高层次抽象的代码,又不会牺牲任何运行时性能。
十六. 智能指针
指针是包含内存地址的变量,Rust 中最常见的是引用(
&),它仅借用数据。智能指针(如String和Vec<T>)则是拥有所指向数据的数据结构,并提供额外元数据与功能(如String确保 UTF-8 有效性)。智能指针通常通过实现Deref和Droptrait 来获得与引用一致的行为及自定义清理逻辑。
1. 使用Box<T>在堆上分配数据
装箱(
Box<T>)是 Rust 中最基础的智能指针,其核心功能是在堆上分配数据,栈上仅保存一个指向该堆数据的指针。除了这项内存布局开销外,它几乎没有其他性能损耗。它主要适用于三种场景:
处理编译时大小未知的类型:当你有一个类型在编译时无法确定其大小(例如递归类型),但需要在要求固定尺寸的上下文中使用它时。
高效转移大量数据的所有权:转移包含大量数据的变量的所有权时,为了避免在栈上进行耗时的逐字节复制,可以将其存储在堆上。这样,转移所有权时只需复制轻量的指针本身,效率更高。
实现 trait 对象:当你希望拥有一个实现了特定 trait 的值,但并不关心其具体类型时(称为 trait 对象,后续章节会深入探讨)。
①使用Box<T>在堆上存储数据
// src/main.rs
// 在讨论 `Box<T>` 的堆存储用例前,我们先了解其语法及交互方式。
// 示例 15-1:使用装箱在堆上存储一个 i32 值。
fn main() {
// 创建一个 `Box<i32>` 实例,在堆上分配一个 i32 类型的值 5,变量 b 持有该 Box
let b = Box::new(5);
// 访问装箱数据的语法与访问栈数据的语法相同,打印输出 b = 5
println!("b = {b}");
// 装箱会在离开作用域时(即 b 到达 main 函数结尾)被释放,同时释放栈上的指针和堆上的数据
// 将单个值存放在堆上通常没有太大用处,所以不常用,但本示例用于展示语法
// 后续将展示必须使用装箱来定义所需类型的场景
}②使用装箱定义递归类型
Rust 要求在编译时知晓所有类型的具体大小,但递归类型(一种允许在自身内部嵌套同类型值的特殊类型)因其理论上可无限嵌套,其大小无法在编译时确定。解决此问题的关键在于:装箱(Box)具有固定大小。通过将递归类型内部指向自身的成员包装在
Box<T>中,即可实现递归类型的定义。一种典型的递归类型是链表(cons list)。理解其定义方式,同样适用于设计其他更为复杂的递归数据结构。
链表
// src/main.rs
// 本文件演示如何使用 `Box<T>` 定义递归的链表数据结构,以解决编译时类型大小未知的问题。
// 示例 15-2(修正前):尝试使用枚举定义递归链表,但因递归导致大小无限,无法编译
// 核心问题:枚举的 Cons 变体直接包含另一个 List,形成无限递归,编译器无法计算其大小
/*
enum List { // 错误:递归类型 `List` 具有无限大小
Cons(i32, List), // 递归,不通过间接引用
Nil,
}
*/
// 示例 15-4:使用 `Box<T>` 修正递归链表定义
// 解决方案:将 Cons 变体中的第二个元素类型改为 `Box<List>`,即指向堆上 List 的智能指针
// 由于 `Box<T>` 具有固定大小(一个指针),编译器可确定枚举大小
// 注意:这里使用了泛型,但为简化,先定义 i32 专用链表
enum List {
Cons(i32, Box<List>), // 通过 Box 实现间接引用,避免无限递归
Nil, // 递归终止标记
}
// 示例 15-3:使用修正后的 List 枚举创建链表
// 注意:需先导入枚举变体
use crate::List::{Cons, Nil};
fn main() {
// 创建链表 1 -> 2 -> 3 -> Nil
// 每个 Cons 变体分配在堆上,通过 Box 持有
let list = Cons(1, Box::new(Cons(2, Box::new(Cons(3, Box::new(Nil))))));
// 链表结构在堆上的布局:
// 栈上变量 list -> 堆上 Cons(1) -> 堆上 Cons(2) -> 堆上 Cons(3) -> 堆上 Nil
// 每个 Box 包含一个指向下一节点的指针,因此 List 枚举的大小是固定的
}
// 核心设计原理说明(基于6张图片内容):
// 1. 链接列表是函数式编程中的常见数据结构,由嵌套二元组构成,最后一个元素是 Nil
// 2. Rust 中递归类型(如 List)不能直接包含自身,否则会导致类型大小无限
// 3. 编译错误提示:递归类型具有无限大小,建议通过 Box、Rc 或引用引入间接引用
// 4. Box<T> 是智能指针,在堆上分配数据,其自身(指针)大小固定,可解决递归类型大小问题
// 5. 虽然链接列表在 Rust 中不常用(Vec<T> 更高效),但此例展示了 Box 在定义递归类型时的关键作用计算一个非递归类型的大小
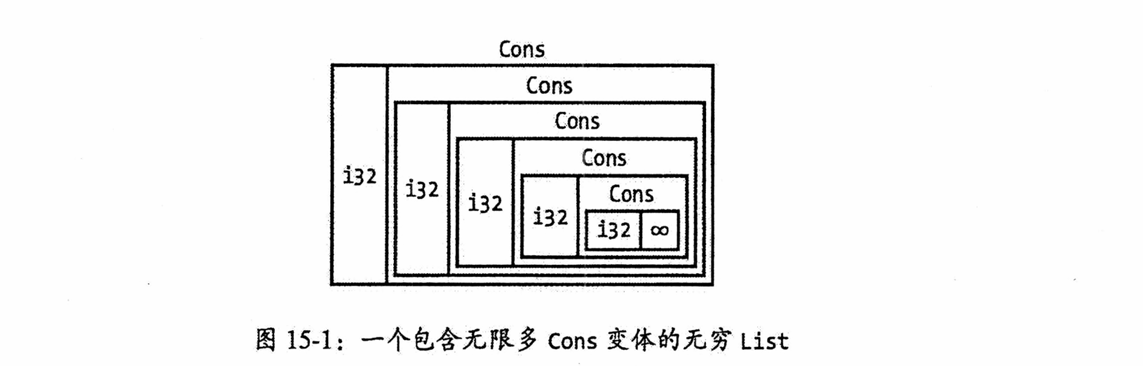
// 回顾第6章中定义的 Message 枚举
enum Message {
Quit, // 无关联数据
Move { x: i32, y: i32 }, // 关联包含两个 i32 字段的匿名结构体
Write(String), // 关联一个 String
ChangeColor(i32, i32, i32), // 关联三个 i32
}
// Rust 计算枚举存储空间的规则:
// 1. 枚举实例的大小由能容纳其最大变体的空间决定。
// 2. 因为每次只有一个变体存在,所以只需为最大变体分配空间。
// 3. 对于 Message 枚举,Rust 遍历所有变体,发现 Move 变体(包含两个 i32)所需空间最大。
// 模拟 Rust 确定递归类型(如示例 15-2 的 List)大小时的问题:
// 编译器检查 Cons 变体,发现它包含一个 i32 和另一个 List 值。
// 为了计算 List 的大小,编译器需要递归地计算 Cons 的大小,这会导致无限循环。
// 此过程示意图可参考图 15-1,展示了这种无限递归的计算过程。
// 核心要点:
// 1. 非递归枚举(如 Message)的大小可在编译时确定。
// 2. 递归类型(如包含自身的 List)的大小在编译时无法直接计算,会导致无限递归。
// 3. 解决递归类型大小问题的常用方法是使用间接引用(如 Box<T>),将递归部分分配到堆上。使用Box<T>将递归类型固定下来
新的 Cons 变体需要存储一个 i32 和一个装箱指针,而 Nil 变体不存储任何值。通过使用装箱,List 值的大小被固定为一个 i32 加上一个指针的大小,从而打破了无限递归,使编译器能够计算出其确切存储空间。
除了提供间接访问和堆分配外,装箱没有其他特殊功能或额外性能开销,因此非常适用于只需间接访问的场景,如链接列表。
Box<T>作为智能指针,其核心在于实现了Dereftrait(允许其被当作引用使用)和Droptrait(离开作用域时自动清理堆数据),这两个 trait 也是理解其他智能指针的关键。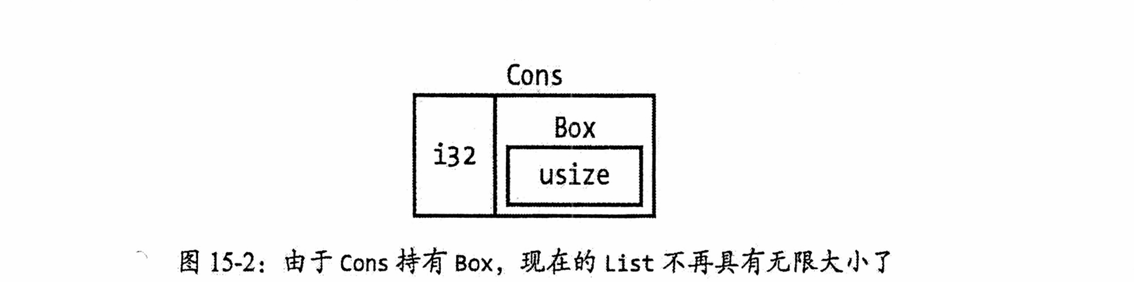
// src/main.rs
// Rust 编译器无法推断递归类型所需的空间大小,因此会报错。
// 错误信息中包含一条有用的建议:插入一些间接(如 `Box`、`Rc` 或 `&`)来使类型可表示。
// 这里的“间接”意味着改变数据结构,使其存储指向值的指针,而不是直接存储值本身。
// 示例 15-5:为了拥有固定大小而使用 `Box<T>` 的 `List` 定义
// 修改说明:因为 `Box<T>` 是一个指针,所以 Rust 总是可以确定其具体大小。指针的大小总是恒定的,不会因为它指向的数据的大小而发生变化。
// 这意味着可以在 `Cons` 变体中存放一个 `Box<T>`,而不是直接存放另一个 `List` 值。`Box<T>` 会指向下一个 `List` 值并将其存放在堆上,而不是直接存放在 `Cons` 变体中。
// 从理论上讲,我们仍然拥有一个“持有”其他列表的列表,但现在的实现更像是一项挨着一项,而不是一项包含另一项。
// 修改后的 `List` 枚举定义:
enum List {
// 通过 `Box<T>` 实现间接引用,避免递归导致大小无限
Cons(i32, Box<List>), // ①
Nil, // ②
}
// 导入 `List` 枚举的变体,以便在 `main` 函数中使用
use crate::List::{Cons, Nil};
fn main() {
// 创建链表 1 -> 2 -> 3 -> Nil
// 每个 `Cons` 变体分配在堆上,通过 `Box` 持有
let list = Cons(
1, // ③
Box::new(Cons(
2, // ④
Box::new(Cons(
3, // ⑤
Box::new(Nil) // ⑥
))
))
);
// 代码现在可以通过编译
}2. 通过Deref Trait将智能指针视作常规引用
实现
Dereftrait 允许我们自定义解引用运算符*的行为,从而将智能指针当作常规引用来处理。这意味着,原本为引用编写的代码无需修改即可直接应用于智能指针。我们可以通过实现
Dereftrait 来为自定义类型(例如一个模拟Box<T>的MyBox<T>)赋予类似引用的解引用能力。Rust 还提供了解引用转换特性,它能自动将实现了Deref的类型的引用转换为目标类型的引用,从而在函数传参等场景中进一步简化代码。本节构建的MyBox<T>仅为演示,不会在堆上分配数据,重点在于理解Deref的机制。
①跳转到指针指向的值
// src/main.rs
// 常规引用是一种指针,可形象理解为指向存储于别处值的箭头。
// 在示例15-6中,创建i32值的引用,并通过解引用运算符访问其指向的值。
fn main() {
let x = 5; // 变量x存储i32值5
let y = &x; // 变量y存储x的引用,即指向x的指针
assert_eq!(5, x); // 直接断言x与5相等,可行
// 对y进行解引用(*y)以跟踪引用,获取其指向的实际整数值5
// 解引用后,编译器可比较实际值
assert_eq!(5, *y);
// 注意:若改为assert_eq!(5, y); 会触发编译错误:
// error[E0277]: can't compare `{integer}` with `&{integer}`
// 因为数值和引用是不同类型,不能直接比较。
// 必须使用解引用运算符跳转到引用指向的值。
}②把Box<T>当成引用来操作
// src/main.rs
// 示例 15-7: 对 Box<T> 进行解引用操作
// 本示例演示如何使用 Box<T> 在堆上分配数据,并通过解引用运算符访问其内部值,与对引用的解引用操作类似。
fn main() {
let x = 5; // 变量 x 存储 i32 值 5
// ① 使用 Box::new 在堆上分配一个整数 x 的拷贝,并将指针赋给 y
let y = Box::new(x);
// 断言栈上的 x 等于 5
assert_eq!(5, x);
// ② 对堆上的值进行解引用,并断言其等于 5
// 与示例 15-6 中对引用的解引用操作类似,这里对装箱指针进行解引用
assert_eq!(5, *y);
// ②(接图片2说明)我们依然可以使用解引用运算符来跟踪装箱指针,正如跟踪引用一样。
// 接下来,我们会实现一个自定义的装箱类型,并借此来研究为什么对 Box<T> 能够进行解引用操作。
}③定义自己的智能指针
// src/main.rs
// 示例 15-8: 定义一个 MyBox<T> 类型
// 目标:构建一个类似于 Box<T> 的智能指针,理解其与常规引用的差异,并支持解引用运算符。
// 注意:MyBox<T> 被定义为单元素元组结构体,类似于 Box<T> 的定义方式。
// ① 定义泛型结构体 MyBox<T>,它是包含一个类型为 T 的元素的元组结构体
struct MyBox<T>(T);
// 为 MyBox<T> 实现关联函数
impl<T> MyBox<T> {
// ② 定义 new 函数,类似于 Box<T>::new,接收一个 T 类型的值
fn new(x: T) -> MyBox<T> {
// ③ 返回用传入值构造的 MyBox 实例
MyBox(x)
}
}
// 示例 15-9: 以类似于使用引用和 Box<T> 的方式来使用 MyBox<T>
// 尝试将 main 函数中的 Box<T> 替换为 MyBox<T>,但此代码无法通过编译
// 因为 Rust 还不知道应该如何解引用 MyBox,必须为 MyBox<T> 实现 Deref trait
fn main() {
let x = 5;
// 使用 MyBox::new 创建实例,类似于 Box::new
let y = MyBox::new(x);
assert_eq!(5, x);
// 尝试对 MyBox<T> 实例进行解引用操作,但会编译失败
// 错误信息:type `MyBox<{integer}>` cannot be dereferenced
// 原因:没有为 MyBox<T> 类型实现 Deref trait
assert_eq!(5, *y);
}④实现Deref trait
// src/main.rs
// 示例 15-10: 为 `MyBox<T>` 实现 `Deref` trait
// 目标:使自定义智能指针 `MyBox<T>` 支持解引用运算符 `*`
// 导入 `Deref` trait,它定义在 `std::ops` 模块中
use std::ops::Deref;
// 为泛型结构体 `MyBox<T>` 实现 `Deref` trait
impl<T> Deref for MyBox<T> {
// 定义关联类型 `Target` 为 `T`,指定解引用操作的目标类型
type Target = T; // ①
// 实现 `deref` 方法,返回对内部数据的引用
// 方法接收 `&self`,返回 `&Self::Target`(即 `&T`)
fn deref(&self) -> &Self::Target {
// ② 通过 `&self.0` 返回对元组结构体中第一个元素的引用
// 这使得调用者可以通过 `*` 运算符访问内部值
&self.0
}
}
// 示例 15-9 的 main 函数(修正后)
// 为 `MyBox<T>` 实现 `Deref` 后,此代码可正常编译运行
fn main() {
let x = 5;
let y = MyBox::new(x);
assert_eq!(5, x);
// ③ Rust 隐式地将 `*y` 展开为 `*(y.deref())`
// 首先调用 `deref` 方法获取引用,然后对结果进行普通解引用
assert_eq!(5, *y);
}
// 核心机制说明(整合自图片2、3):
// 1. 没有 `Deref` trait 时,编译器只能对 `&` 形式的常规引用进行解引用操作。
// 2. `deref` 方法使编译器可以从任何实现了 `Deref` 的类型中获取值,并调用 `deref` 来获得可解引用的引用。
// 3. Rust 将 `*y` 隐式展开为 `*(y.deref())`,从而免去手动调用 `deref` 的步骤。
// 4. 所有权系统要求 `deref` 返回引用(而非值),以避免意外转移所有权。
// 5. 此替换过程是单次的,不会无限递归,因此最终能得到 `i32` 类型的值。⑤函数和方法的隐式解引用转换
解引用转换是Rust提供的一项便捷特性,它允许编译器自动将实现了
Dereftrait 的类型的引用,转换为另一种目标类型的引用。例如,它可以将&String自动转换为&str,因为String类型实现了返回&str的Dereftrait。其工作原理是:当你将一个类型的引用作为参数传递给函数或方法,而该类型与参数声明的类型不匹配时,编译器会自动插入一系列
deref()方法调用,直到类型匹配为止。这个过程完全在编译时完成。这项特性带来的核心好处是:它让程序员在调用函数时,无需再手动多次使用
&和*运算符进行显式的引用与解引用操作。更重要的是,它使得我们能够编写出更加通用、灵活的代码,这些代码可以同时无缝地处理常规引用和各种智能指针。
// src/main.rs
// 本文件演示 Rust 的解引用转换特性,展示其如何自动将实现了 `Deref` trait 的类型的引用转换为目标类型的引用。
// 示例 15-11: 定义接收字符串切片参数的 `hello` 函数
fn hello(name: &str) {
println!("Hello, {name}!");
}
// 示例 15-12: 解引用转换使我们可以将 `MyBox<String>` 的引用传入 `hello` 函数
// 说明:Rust 通过调用 `deref` 将 `&MyBox<String>` 转换为 `&String`,再转换为 `&str`,最终匹配函数签名
fn main() {
let m = MyBox::new(String::from("Rust"));
hello(&m);
// 等效于:hello(&(*m)[..]);
// 自动转换过程:&m -> 调用 `deref` 得到 &String -> 调用 `deref` 得到 &str
}
// 示例 15-13: 若无解引用转换,需手动多次解引用,代码复杂
fn main_without_coercion() {
let m = MyBox::new(String::from("Rust"));
hello(&(*m)[..]);
// 手动步骤:1. 解引用 `*m` 得到 `String`
// 2. 通过 `[..]` 获取整个 `String` 的切片
// 3. 取引用 `&` 得到 `&str`
// 自动转换使代码更清晰、易读写。
}
// 核心总结(整合自三张图片):
// 1. 解引用转换是 Rust 在编译时自动执行的,对实现了 `Deref` trait 的类型,会自动插入 `deref` 调用直到类型匹配。
// 2. 此特性允许在调用函数时,传递不同类型的引用(如 `&MyBox<String>`),编译器会自动转换为目标类型(如 `&str`)。
// 3. 转换过程是零开销的,编译时完成,无运行时性能损耗。
// 4. 这大大简化了代码,避免了手动多次解引用和取切片的繁琐操作。⑥解引用转换与可变性
Rust 通过
Dereftrait 允许自定义不可变引用(&T)的*解引用行为,而DerefMuttrait 则用于重载可变引用(&mut T)的*运算符。当类型满足以下三种情况时,Rust 编译器会自动执行解引用转换,以简化代码:
&T转 &U:当类型 T实现了 Deref<Target=U>时,允许将 &T转换为 &U。
&mut T转 &mut U:当类型 T实现了 DerefMut<Target=U>时,允许将 &mut T转换为 &mut U。
&mut T转 &U:当类型 T实现了 Deref<Target=U>时,允许将 &mut T转换为 &U,但这个过程是不可逆的。
转换规则的核心在于 Rust 严格的借用规则。规则3之所以成立,是因为将一个可变引用(要求唯一性)降级为不可变引用总是安全的。但反之,从不可变引用(允许多个)升级为可变引用则无法保证其唯一性,因此编译器绝不允许将
&U转换为&mut T。
3. 使用Drop Trait在清理时允许代码
Droptrait 允许为类型定义其值在离开作用域时(被销毁前)需要执行的自定义代码,这通常是释放文件、网络连接或内存等资源的关键机制。在智能指针模式中,Drop几乎是不可或缺的,例如 Box<T>就依靠它来自动释放所指向的堆内存。
通过实现
Droptrait 并提供一个接收&mut self参数的drop函数,即可指定清理逻辑。Rust 编译器会自动在合适的地方插入对drop的调用,这从根本上避免了手动管理资源可能导致的泄漏或遗忘,也无需在代码中多处编写重复的清理语句。
// src/main.rs
// 示例 15-14: 定义 CustomSmartPointer 结构体,并实现 Drop trait
// 核心功能:在实例离开作用域时打印清理信息,演示 Rust 如何自动管理资源
struct CustomSmartPointer {
data: String, // 结构体包含一个 String 类型的数据字段
}
// 为 CustomSmartPointer 实现 Drop trait
// Drop trait 已在预导入模块中,无需显式引入
impl Drop for CustomSmartPointer {
// 实现 drop 方法,指定实例离开作用域时需要执行的清理逻辑
fn drop(&mut self) {
// 在清理时打印包含实例数据的提示信息
println!("Dropping CustomSmartPointer with data `{}`!", self.data);
}
}
fn main() {
// 示例 15-14 续: 创建两个 CustomSmartPointer 实例
// ① 创建实例 c
let c = CustomSmartPointer {
data: String::from("my stuff"),
};
// ② 创建实例 d
let d = CustomSmartPointer {
data: String::from("other stuff"),
};
println!("CustomSmartPointers created.");
// ③ 函数结尾,实例 c 和 d 将离开作用域
// Rust 会自动调用 drop 方法,且按创建顺序的逆序(d 先,c 后)清理
} // ④ 作用域结束,自动调用 drop 清理
// 示例 15-15: 尝试手动调用 Drop trait 的 drop 方法(此代码无法通过编译)
// 错误原因:Rust 禁止显式调用 drop 方法,以防止重复释放
/*
fn main() {
let c = CustomSmartPointer {
data: String::from("some data"),
};
println!("CustomSmartPointer created.");
c.drop(); // 错误:不允许显式调用 drop
println!("CustomSmartPointer dropped before the end of main.");
}
*/
// 编译错误信息: explicit use of destructor method
// 析构函数(destructor)是清理实例的函数,对应构造函数(constructor)
// 示例 15-16: 使用 std::mem::drop 函数提前清理值
// 这是正确的提前清理方式,该函数在预导入模块中
fn main_early_drop() {
let c = CustomSmartPointer {
data: String::from("some data"),
};
println!("CustomSmartPointer created.");
drop(c); // 调用 std::mem::drop 函数,提前清理 c
println!("CustomSmartPointer dropped before the end of main.");
// 输出顺序:
// CustomSmartPointer created.
// Dropping CustomSmartPointer with data `some data`!
// CustomSmartPointer dropped before the end of main.
}4. 基于引用计数的智能指针Rc<T>
Rust 中的所有权规则通常是清晰且明确的,一个值只有一个所有者。但在某些特定场景下,例如图数据结构中,一个节点可能被多条边所共享,从概念上说该节点同时属于所有指向它的边。这意味着它需要多重所有权:只要还有边指向它,这个节点就不应被清理。
为了支持这种模式,Rust 提供了
Rc<T>类型(引用计数)。你可以将它想象成客厅里的电视:当第一个人打开电视后,其他人都可以观看;电视会一直保持开启,直到最后一个人离开房间才关闭。Rc<T>在内部维护一个引用计数器,用于跟踪有多少个部分正在共享这份数据。当计数降为零时,说明数据不再被任何地方使用,此时会被自动安全地清理。因此,当你需要在程序的多个部分之间共享堆上的数据,并且无法在编译时确定哪一部分会最后结束时,就应使用
Rc<T>。需要注意的是,Rc<T>仅适用于单线程场景。
①使用Rc<T>共享数据
我们将通过一个例子来演示如何创建多个共享部分数据所有权的列表。目标是:创建两个独立的列表(b 和 c),它们都共享并连接到同一个基础列表(a)的尾部。
具体步骤是:首先,创建一个包含元素 5 和 10 的列表 a。接着,创建列表 b,它在开头添加元素 3,然后链接到整个列表 a 之后。同样,创建列表 c,它在开头添加元素 4,也链接到列表 a 之后。这样,列表 b 和 c 就共同享有了包含 5 和 10 的尾部数据。
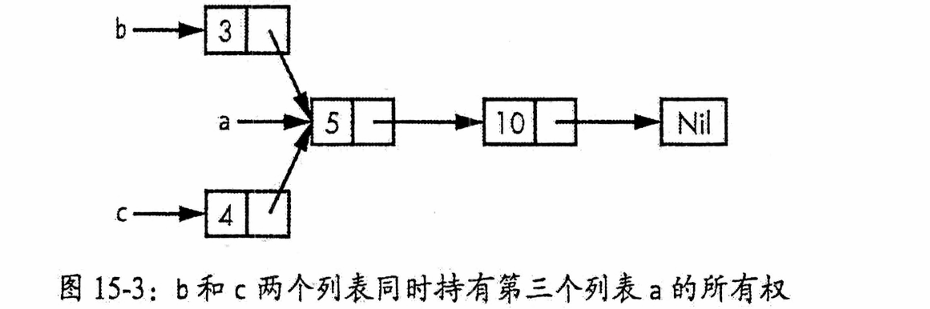
// 示例 15-17: 尝试使用 Box<T> 定义共享所有权的链表(此代码无法通过编译)
// 目标:创建两个链表 b 和 c,它们共享并连接到同一个基础链表 a 的尾部。
// 问题:Box<T> 具有独占所有权,当 a 被移动到 b 中后,无法再用于创建 c。
enum List {
Cons(i32, Box<List>), // 每个 Cons 变体持有值和一个指向下一节点的 Box
Nil, // 链表结束标记
}
use crate::List::{Cons, Nil};
fn main() {
// 创建基础链表 a: 5 -> 10 -> Nil
let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
// 尝试创建链表 b: 3 -> a
let b = Cons(3, Box::new(a)); // 此时 a 的所有权被移动到 b 中
// 尝试再次使用 a 创建链表 c: 4 -> a
let c = Cons(4, Box::new(a)); // 编译错误:a 已被移动,无法再次使用
}// 示例 15-18: 使用 Rc<T> 实现共享所有权的链表
// 解决方案:将 Box<T> 替换为 Rc<T>,允许多个 Cons 变体共享同一份数据的所有权。
// 引入 Rc<T> 类型,用于引用计数智能指针
use std::rc::Rc;
// 定义 List 枚举,其 Cons 变体使用 Rc<List> 来允许共享所有权
enum List {
Cons(i32, Rc<List>), // 通过 Rc 实现共享,允许多个 Cons 指向同一数据
Nil,
}
// 导入 List 的变体
use crate::List::{Cons, Nil};
fn main() {
// 创建基础链表 a: 5 -> 10 -> Nil,并用 Rc 包装,使其可被多个所有者共享
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
// 创建链表 b: 3 -> a
// 通过 Rc::clone 增加 a 的引用计数,a 和 b 共享同一份数据
let b = Cons(3, Rc::clone(&a));
// 创建链表 c: 4 -> a
// 再次克隆 a 的 Rc,引用计数继续增加,a、b、c 共享数据
let c = Cons(4, Rc::clone(&a));
// 注意:Rc::clone 仅增加引用计数,不复制数据,因此效率高。a.clone会深度拷贝
// 当 a、b、c 离开作用域,引用计数降为 0 时,数据被自动清理
}②克隆Rc<T>会增加引用计数
// src/main.rs
// 示例 15-19: 通过打印引用计数,观察 Rc<T> 在创建和丢弃引用时的变化
// 目标:验证 Rc<T> 的引用计数机制,即通过克隆增加计数,离开作用域时自动减少
// 引入 Rc 和相关枚举
use std::rc::Rc;
use crate::List::{Cons, Nil};
// 定义 List 枚举,使用 Rc 实现共享所有权
enum List {
Cons(i32, Rc<List>),
Nil,
}
fn main() {
// 创建列表 a: 5 -> 10 -> Nil,并用 Rc 包装,初始引用计数为 1
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
// 打印创建 a 后的引用计数
println!("创建 a 后的引用计数 = {}", Rc::strong_count(&a));
// 创建列表 b: 3 -> a,通过 Rc::clone 增加 a 的引用计数
let b = Cons(3, Rc::clone(&a));
println!("创建 b 后的引用计数 = {}", Rc::strong_count(&a));
{
// 创建列表 c: 4 -> a,同样通过 Rc::clone 增加引用计数
let c = Cons(4, Rc::clone(&a));
println!("创建 c 后的引用计数 = {}", Rc::strong_count(&a));
// 内部作用域结束,c 离开作用域,引用计数自动减 1
} // 这里 c 被丢弃,引用计数减少
// 打印 c 离开作用域后的引用计数
println!("c 离开作用域后的引用计数 = {}", Rc::strong_count(&a));
// 注意:b 和 a 将在 main 函数结束时离开作用域,引用计数归零,Rc<List> 被清理
}
/*
* 运行此程序将输出(对应图片3):
* 创建 a 后的引用计数 = 1
* 创建 b 后的引用计数 = 2
* 创建 c 后的引用计数 = 3
* c 离开作用域后的引用计数 = 2
*
* 机制说明:
* 1. Rc::new 创建 a 时,引用计数初始为 1。
* 2. 每次调用 Rc::clone(&a),引用计数加 1,但不复制底层数据。
* 3. 当每个 Rc<List> 离开作用域时,其 Drop trait 实现会自动将引用计数减 1。
* 4. 引用计数降为 0 时,底层数据被自动清理。
*
* 设计价值(对应图片4):
* 1. Rc<T> 通过不可变引用,允许多个部分共享只读数据,无需编译时确定唯一所有者。
* 2. 它遵循 Rust 的借用规则:多个不可变借用是安全的,但不可同时存在可变借用。
* 3. 若需可变性,可结合内部可变性模式(如 RefCell<T>),这将在后续章节讨论。
*/5. RefCell<T>和内部可变性模式
内部可变性是 Rust 的一种设计模式,它允许你在仅持有数据的不可变引用时,也能修改其内部数据。这通常违反 Rust 的借用规则,但该模式通过在其数据结构中使用
unsafe代码来绕过编译器的常规检查,并将这些规则的手动维护责任交给开发者。此模式适用于开发者能确保不违反借用规则,而编译器无法静态推断出此安全性的场景。相关的
unsafe代码被封装在安全的 API 之内,因此从外部看,该类型的行为仍然是不可变的。RefCell<T>类型就是应用这一模式的典型例子。
①使用RefCell<T>在运行时检查借用规则
RefCell<T>与 Box<T>都代表单一所有权,但核心区别在于借用规则的检查时机。Rust 的借用规则(任一时刻只能有一个可变引用或多个不可变引用,且引用必须有效)对于普通引用和 Box<T>是在编译时强制检查的,违反规则会导致编译错误;而 RefCell<T>将这部分检查移至运行时,违反规则会触发 panic。
Rust 默认采用编译时检查,这能在开发早期暴露问题且无运行时开销,是最佳选择。然而,编译器的静态分析本质上是保守的——它有时会拒绝一些实际上安全的代码,以确保绝对安全。当你能在逻辑上保证代码遵守借用规则,但编译器无法静态确认时,
RefCell<T>便有了用武之地。它允许你在运行时检查借用规则,从而实现了内部可变性模式:即使RefCell<T>本身是不可变的,你也能修改其内部存储的值。选择智能指针的依据如下:
所有权:
Rc<T>允许多个所有者;Box<T>和RefCell<T>仅允许一个所有者。借用检查:
Box<T>在编译时检查可变/不可变借用;Rc<T>在编译时仅检查不可变借用;RefCell<T>在运行时检查可变/不可变借用。RefCell<T>和 Rc<T>一样,仅用于单线程场景。内部可变性模式为某些需要灵活可变性的特定场景提供了安全且可控的解决方案。
②内部可变性:可变的借用一个不可变值
介绍
需要一个值在对外保持不可变性的同时,能够在其方法内部修改自身,除了这个值本身的方法,其余代码仍不能修改这个值。
// src/main.rs
// 本文件演示 Rust 中借用规则的推论以及 `RefCell<T>` 的内部可变性。
// 核心要点:
// 1. 借用规则的一个推论是:不能可变地借用一个不可变的值。
// 2. `RefCell<T>` 提供了内部可变性,将借用检查从编译时推迟到运行时,违反规则会触发 panic。
// ====================
// 第一部分:错误示例 - 尝试可变借用不可变的值
// ====================
// 根据第一张图片内容,以下代码尝试创建不可变变量 `x` 的可变引用 `y`,违反了借用规则,无法通过编译。
/*
fn main() {
let x = 5; // 不可变变量 x
let y = &mut x; // 错误:尝试创建 x 的可变引用
}
*/
// 编译错误信息(精简自图片1):
// error[E0596]: cannot borrow `x` as mutable, as it is not declared as mutable
// 错误解释:`x` 未被声明为可变,因此不能对其进行可变借用。
// ====================
// 第二部分:使用 `RefCell<T>` 实现内部可变性
// ====================
// 根据第二张图片内容,`RefCell<T>` 允许在不可变的外部接口下修改内部值,但借用规则检查被推迟到运行时。
// 核心总结:
// 1. 借用规则禁止对不可变值进行可变借用,这是 Rust 内存安全的基础。
// 2. `RefCell<T>` 通过运行时检查借用规则,实现了内部可变性,允许在不可变外部接口下修改内部数据。
// 3. 使用 `RefCell<T>` 时,必须确保在运行时遵守借用规则,否则会触发 panic。
// 4. 内部可变性适用于需要灵活可变性,但编译器无法在编译时确定安全性的场景。内部可变性的场景:模拟对象
测试替身是在测试中替代真实类型的占位类型,用于观察特定行为并验证实现是否正确,类似于影视制作中的替身演员。其中,模拟对象是一种特殊的测试替身,负责记录测试过程以便后续断言。
Rust 的标准库没有直接提供模拟对象功能,但开发者可以自行定义结构体来实现。例如,可以设计一个用于记录当前值与最大值(如API调用次数与限额)并比较其接近程度的库。该库仅负责数值比较与触发逻辑,而实际的信息发送功能(如打印、发送邮件或短信)则通过一个名为
Messenger的 trait 交由外部应用程序代码来实现,从而将核心逻辑与具体通信细节解耦。
// src/lib.rs
// 本文件实现了一个用于跟踪数值接近上限并发送警告的库,并演示了如何使用 RefCell<T> 实现内部可变性以进行测试。
// 1. 定义 Messenger trait,用于发送消息
pub trait Messenger {
// send 方法接收 self 的不可变引用和消息字符串切片
// 实现此 trait 的类型需提供具体的消息发送逻辑
fn send(&self, msg: &str);
}
// 2. 定义 LimitTracker 结构体,用于跟踪当前值相对于最大值的接近程度
// 结构体使用生命周期参数 'a 和泛型参数 T,T 必须实现 Messenger trait
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T, // 消息发送器,不可变引用
value: usize, // 当前值
max: usize, // 最大值
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger, // 约束 T 必须实现 Messenger trait
{
// 关联函数 new,创建 LimitTracker 实例
// 参数 messenger 是实现了 Messenger trait 的类型的引用
// 参数 max 是允许的最大值
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0, // 初始化当前值为 0
max,
}
}
// 设置当前值,并根据与最大值的比例触发相应的警告消息
// 方法接收可变引用 self,以便更新 value
pub fn set_value(&mut self, value: usize) {
self.value = value; // 更新当前值
// 计算当前值占最大值的百分比
let percentage_of_max = self.value as f64 / self.max as f64;
// 根据百分比发送不同的警告消息
if percentage_of_max >= 1.0 {
// 超过 100% 时发送错误信息
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
// 达到 90% 时发送紧急信息
self.messenger.send("Urgent: You're at 90% of your quota!");
} else if percentage_of_max >= 0.75 {
// 达到 75% 时发送警告信息
self.messenger.send("Warning: You're at 75% of your quota!");
}
}
}
// 3. 测试模块
// 使用 RefCell<T> 实现内部可变性,允许在不可变引用下修改内部数据
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell; // 引入 RefCell 用于内部可变性
// 定义 MockMessenger 结构体,用于测试
// 包含一个 RefCell<Vec<String>> 字段,用于记录发送的消息
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
// 构造函数,初始化 sent_messages 为空向量
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]), // 使用 RefCell 包装空向量
}
}
}
// 为 MockMessenger 实现 Messenger trait
impl Messenger for MockMessenger {
// send 方法接收不可变引用 self,但通过 RefCell 可以修改内部向量
fn send(&self, message: &str) {
// 通过 borrow_mut 获取可变引用,将消息添加到向量中
// 这利用了 RefCell 的内部可变性,允许在不可变引用下修改数据
self.sent_messages.borrow_mut().push(String::from(message));
}
}
// 测试函数:验证当当前值超过最大值的 75% 时,是否发送了警告消息
#[test]
fn it_sends_an_over_75_percent_warning_message() {
// 创建 MockMessenger 实例
let mock_messenger = MockMessenger::new();
// 使用 MockMessenger 的引用和最大值 100 创建 LimitTracker
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
// 设置当前值为 80(超过最大值的 75%)
limit_tracker.set_value(80);
// 断言:MockMessenger 的记录中应有一条消息
// 通过 borrow 获取不可变引用,检查向量长度
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}③使用RefCell<T>在运行时记录借用信息
// 文件: src/lib.rs
// 示例: RefCell<T> 的正确使用与错误使用示例
// 本示例演示了如何使用 RefCell<T> 实现内部可变性,以及违反借用规则时在运行时触发 panic 的情况。
// 引入 RefCell 以在不可变环境中实现内部可变性
use std::cell::RefCell;
// 1. Messenger trait 定义
// 定义一个消息发送器 trait,用于发送消息
pub trait Messenger {
// send 方法接收一个不可变的 self 引用和一个消息字符串切片
// 使用 &self 而非 &mut self 是为了允许不可变上下文调用
fn send(&self, msg: &str);
}
// 2. MockMessenger 结构体定义
// 用于测试的模拟消息发送器,记录发送的消息
pub struct MockMessenger {
// 使用 RefCell 包装 Vec<String>,以便在不可变引用下修改内部数据
// RefCell 允许我们在运行时检查借用规则
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
// 构造函数,创建一个新的 MockMessenger 实例
pub fn new() -> MockMessenger {
MockMessenger {
// 初始化一个空的字符串向量,用 RefCell 包装
sent_messages: RefCell::new(vec![]),
}
}
}
// 3. 为 MockMessenger 实现 Messenger trait
impl Messenger for MockMessenger {
// 正确的实现:每次调用 send 时,将消息添加到 sent_messages
fn send(&self, message: &str) {
// 通过 borrow_mut 获取可变借用,然后向向量中添加消息
// 这利用了 RefCell 的内部可变性,允许在不可变引用下修改数据
self.sent_messages.borrow_mut().push(String::from(message));
}
}
// 4. 示例 15-23: 错误的实现,在同一个作用域中创建两个可变引用
// 这段代码会在运行时触发 panic,因为违反了 Rust 的借用规则
pub struct MockMessengerError {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessengerError {
pub fn new() -> MockMessengerError {
MockMessengerError {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessengerError {
fn send(&self, message: &str) {
// 错误:在同一个作用域中创建两个可变引用
// 第一次调用 borrow_mut 创建了一个 RefMut<T> 智能指针
let mut one_borrow = self.sent_messages.borrow_mut();
// 错误:第二次调用 borrow_mut 试图创建另一个可变引用
// 此时 one_borrow 仍处于作用域中,违反了"同一时间只能有一个可变借用"的规则
let mut two_borrow = self.sent_messages.borrow_mut();
// 尝试向两个借用中添加相同的消息
one_borrow.push(String::from(message));
two_borrow.push(String::from(message));
// 当这段代码运行时,RefCell<T> 会在第二次调用 borrow_mut 时触发 panic
// 错误信息: "already borrowed: BorrowMutError"
}
}
// 5. 测试模块
// 测试正确的使用和错误使用(预期 panic)
#[cfg(test)]
mod tests {
use super::*;
// 测试正确的实现
#[test]
fn it_sends_a_message() {
let mock_messenger = MockMessenger::new();
mock_messenger.send("Hello, world!");
// 检查消息是否被正确记录
// 通过 borrow 获取不可变引用,检查向量内容
let messages = mock_messenger.sent_messages.borrow();
assert_eq!(messages.len(), 1);
assert_eq!(messages[0], "Hello, world!");
}
// 测试错误的实现,预期会触发 panic
#[test]
#[should_panic(expected = "already borrowed: BorrowMutError")]
fn it_panics_when_creating_two_mutable_references() {
let mock_messenger = MockMessengerError::new();
mock_messenger.send("This will panic");
// 预期在调用 send 时触发 panic,因为内部创建了两个可变引用
}
}
/*
* 核心总结:
* 1. 我们创建不可变引用和可变引用时分别使用 & 与 &mut 语法。
* 2. 对于 RefCell<T> 而言,我们需要使用 borrow 和 borrow_mut 方法来实现类似的功能。
* 3. borrow 返回 Ref<T> 智能指针,borrow_mut 返回 RefMut<T> 智能指针,它们都实现了 Deref,可当作常规引用使用。
* 4. RefCell<T> 会记录当前活跃的 Ref<T> 和 RefMut<T> 数量,以此维护借用规则(一个不可变或多个可变借用)。
* 5. 当违反借用规则(如同一个作用域创建两个可变引用)时,RefCell<T> 会在运行时触发 panic,而非编译时报错。
* 6. 选择运行时检查可能使问题在开发后期才暴露,且有轻微性能开销,但 RefCell<T> 允许在不可变环境中修改数据,实现常规引用无法完成的功能。
*/④结合使用Rc<T>和RefCell<T>来实现有多重所有权的可变数据
// src/main.rs
// 示例 15-24: 结合使用 Rc<T> 和 RefCell<T> 创建可变的共享列表
// 核心:Rc<T> 允许多个所有者共享数据,但默认不可变;通过内部包裹 RefCell<T>,可实现共享且可修改的数据。
// 导入所需的库
use std::cell::RefCell;
use std::rc::Rc;
// 从当前 crate 导入 List 枚举及其变体
use crate::List::{Cons, Nil};
// 定义 List 枚举,表示一个链接列表
// Cons 变体包含一个 Rc<RefCell<i32>> 类型的数据(可共享且可变的整数)和下一个节点的 Rc<List>
#[derive(Debug)]
enum List {
Cons(Rc<RefCell<i32>>, Rc<List>), // ①
Nil,
}
fn main() {
// 1. 创建 Rc<RefCell<i32>> 实例,内部包裹整数值 5
// 此 value 可被多个所有者共享,且其内部值可修改
let value = Rc::new(RefCell::new(5)); // ①
// 2. 创建列表 a,包含 value 和一个 Nil 尾节点
// 通过 Rc::clone 共享 value 的所有权,而非转移所有权
let a = Rc::new(Cons(Rc::clone(&value), Rc::new(Nil))); // ②
// 3. 创建列表 b,包含新节点 3 并共享列表 a
let b = Cons(Rc::new(RefCell::new(3)), Rc::clone(&a)); // ②
// 4. 创建列表 c,包含新节点 4 并共享列表 a
let c = Cons(Rc::new(RefCell::new(4)), Rc::clone(&a)); // ②
// 5. 修改 value 指向的值,增加 10
// 通过自动解引用将 Rc<RefCell<i32>> 解引用为 RefCell<i32>,然后调用 borrow_mut 获取可变引用
// borrow_mut 返回 RefMut<i32> 智能指针,可通过解引用运算符修改内部值
*value.borrow_mut() += 10; // ③
// 6. 打印修改后的列表 a、b、c
// 由于 a 是 Rc<List>,需要使用 * 解引用获取 List 以进行调试打印
println!("a after = {:?}", *a); // ③
println!("b after = {:?}", b); // ③
println!("c after = {:?}", c); // ③
// 输出示例:
// a after = Cons(RefCell { value: 15 }, Nil)
// b after = Cons(RefCell { value: 3 }, Cons(RefCell { value: 15 }, Nil))
// c after = Cons(RefCell { value: 4 }, Cons(RefCell { value: 15 }, Nil))
// 所有共享 value 的列表节点中的值都已从 5 变为 15
}
/*
* 核心总结(基于四张图片内容):
*
* 1. 设计模式:
* - Rc<T> 允许多个所有者共享数据,但默认只提供不可变访问。
* - RefCell<T> 提供内部可变性,允许在不可变引用下修改内部数据。
* - 结合 Rc<RefCell<T>>,可实现多所有者共享且可修改的数据。
*
* 2. 示例说明:
* - 本示例创建了三个列表 a、b、c,其中 b 和 c 共享列表 a。
* - 通过修改共享的 value(Rc<RefCell<i32>>),所有相关列表节点中的值都同步更新。
* - 列表表面不可变,但通过 RefCell<T> 的方法在必要时修改内部值。
*
* 3. 运行时检查:
* - RefCell<T> 在运行时检查借用规则,违反规则(如同时创建两个可变引用)会触发 panic。
* - 这种检查避免了数据竞争,但牺牲了少量运行时性能,换取了灵活性。
*
* 4. 线程安全:
* - RefCell<T> 不能用于多线程代码,因为其运行时检查非线程安全。
* - 多线程环境下应使用 Mutex<T>(互斥锁),这是线程安全版本的内部可变性容器。
* - Mutex<T> 将在第 16 章讨论。
*
* 5. 使用场景:
* - 当需要多个部分共享并可能修改同一数据,且编译时无法确定唯一所有者时,此模式非常有用。
* - 例如,图形结构、观察者模式等需要多重所有权和内部可变性的场景。
*/6. 循环引用会造成内存泄露
Rust 的内存安全保障使其难以意外制造内存泄漏,但这并非完全不可能。与数据竞争不同,Rust 并不保证在编译时彻底防止内存泄漏,因此内存泄漏在 Rust 中被视为一种内存安全行为。
具体而言,通过组合使用
Rc<T>(引用计数智能指针)和RefCell<T>(提供内部可变性),可以创建出相互引用、形成环状结构的实例。由于环中每个指针的引用计数都无法减少到 0,它们所指向的值将永远不会被释放,从而导致内存泄漏。
①创建循环引用
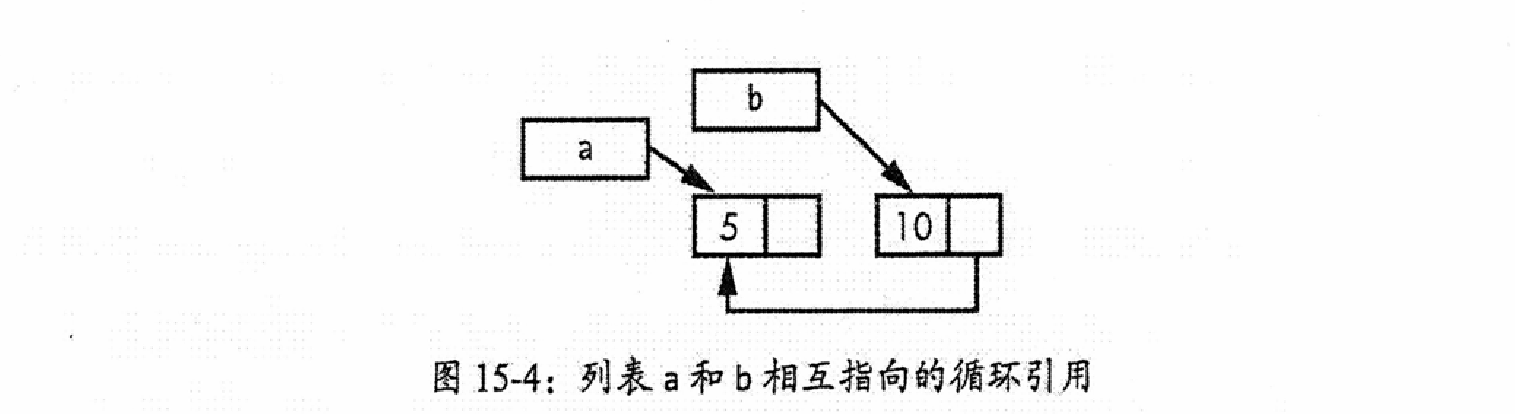
// src/main.rs
// 示例 15-25: 使用 `RefCell<Rc<List>>` 定义 List 枚举,使其允许修改 Cons 变体指向的下一个值
// 核心:定义枚举 List,其中 Cons 变体的第二个元素为 `RefCell<Rc<List>>`,
// 这使得我们可以修改 Cons 变体指向的下一个 List 值,而不仅仅是修改 i32 值。
// 导入必要的模块
use std::cell::RefCell;
use std::rc::Rc;
// 从当前 crate 导入 List 枚举的变体
use crate::List::{Cons, Nil};
// 定义 List 枚举,派生 Debug trait 以便打印
#[derive(Debug)]
enum List {
// Cons 变体:包含一个 i32 值和一个 RefCell<Rc<List>>,后者允许修改指向的下一个 List
Cons(i32, RefCell<Rc<List>>), // ①
// Nil 变体:表示列表结束
Nil,
}
// 为 List 实现方法
impl List {
// tail 方法:返回 Cons 变体中第二个元素的引用(Option<&RefCell<Rc<List>>>)
// 如果是 Cons 变体,返回其第二个元素的引用;如果是 Nil,返回 None
fn tail(&self) -> Option<&RefCell<Rc<List>>> { // ②
match self {
// 匹配 Cons 变体,返回其第二个元素的引用
Cons(_, item) => Some(item),
// 匹配 Nil 变体,返回 None
Nil => None,
}
}
}
// 示例 15-26: 构造一个循环引用,由两个相互指向对方的 List 组成
fn main() {
// 1. 创建列表 a,初始值为 5,下一个元素为 Nil
// 使用 Rc 包装,以便后续共享所有权
let a = Rc::new(Cons(5, RefCell::new(Rc::new(Nil)))); // ①
// 打印 a 的初始引用计数
println!("a initial rc count = {}", Rc::strong_count(&a));
// 打印 a 的下一个元素
println!("a next item = {:?}", a.tail());
// 2. 创建列表 b,值为 10,下一个元素指向 a
let b = Rc::new(Cons(10, RefCell::new(Rc::clone(&a)))); // ②
// 创建 b 后,a 的引用计数变为 2(a 本身和 b 中的引用)
println!("a rc count after b creation = {}", Rc::strong_count(&a));
// 打印 b 的初始引用计数
println!("b initial rc count = {}", Rc::strong_count(&b));
// 打印 b 的下一个元素
println!("b next item = {:?}", b.tail());
// 3. 修改 a 的下一个元素为 b,从而创建循环引用
// 通过 tail 方法获取 a 的第二个元素的引用(RefCell<Rc<List>>)
if let Some(link) = a.tail() { // ③
// 通过 borrow_mut 获取可变引用,并将 Rc<List> 中存储的值由 Nil 修改为 b
*link.borrow_mut() = Rc::clone(&b);
}
// 修改 a 后,b 的引用计数变为 2(b 本身和 a 中的引用)
println!("b rc count after changing a = {}", Rc::strong_count(&b));
// 修改 a 后,a 的引用计数变为 2(a 本身和 b 中的引用,注意 b 也指向 a)
println!("a rc count after changing a = {}", Rc::strong_count(&a));
// 取消下面的注释行可以观察循环引用,但会导致栈溢出,因为打印会无限递归
// println!("a next item = {:?}", a.tail());
}
// 运行结果(对应图片5):
// a initial rc count = 1
// a next item = Some(RefCell { value: Nil })
// a rc count after b creation = 2
// b initial rc count = 1
// b next item = Some(RefCell { value: Cons(5, RefCell { value: Nil }) })
// b rc count after changing a = 2
// a rc count after changing a = 2
// 结果分析:
// 1. 在完成 a 指向 b 的操作后,两个 Rc<List> 实例的引用计数都变成了 2。
// 2. 在 main 函数结尾,Rust 会先丢弃 b,使其引用计数从 2 减至 1(因为 a 仍引用 b)。
// 3. 接着丢弃 a,使其引用计数从 2 减至 1(因为 b 仍引用 a)。
// 4. 由于引用计数不为 0,两个 Rc<List> 实例的堆内存都不会被释放,造成内存泄漏。
// 注意事项(对应图片6):
// 1. 如果取消最后一行 println! 的注释,Rust 会在尝试打印循环引用时反复跳转,导致栈溢出。
// 2. 在生产环境中,循环引用可能导致内存逐渐耗尽,最终拖垮系统。
// 3. 在 Rust 中创建循环引用并不容易,但使用包含 RefCell<T> 的 Rc<T> 或其他内部可变性与引用计数指针的组合时,需要自行确保不会创建循环引用。
// 4. 避免循环引用的方法包括重新组织数据结构,将引用拆分为持有所有权和不持有所有权两种情形,或者使用弱引用(Weak<T>)等。
// 核心总结:
// 1. 本示例展示了如何通过 Rc<T> 和 RefCell<T> 创建循环引用,导致内存泄漏。
// 2. Rust 的内存安全保证并不包括防止内存泄漏,因此需要开发者注意此类问题。
// 3. 在复杂程序中,应通过代码审查、测试等手段来避免循环引用。②使用Weak<T>代替Rc<T>来避免循环引用
介绍
Rc<T>通过强引用计数 (strong_count) 管理所有权,仅当该计数归零时实例才会被清理。调用 Rc::downgrade可创建弱引用 (Weak<T>),它会增加弱引用计数 (weak_count) 但不增加强引用计数,因此不拥有所有权,也不会影响实例的清理时机。
弱引用的核心价值在于避免循环引用导致的内存泄漏。由于弱引用不构成所有权关系,即使形成引用环,当强引用计数为零时,环会被打破,相关内存仍可被安全回收。
为了安全地使用弱引用,必须通过
upgrade方法将其升级为Option<Rc<T>>。此方法在值仍存在时返回Some,在值已被清理时返回None,由 Rust 的类型系统保证访问安全。这种机制使得构建类似树状结构(子节点拥有父节点的弱引用)等复杂数据关系成为可能,而无内存泄漏之忧。
创建树状数据结构体:带有子节点的Node
// src/main.rs
// 目标:创建一个树形结构,其中每个节点(Node)可以拥有多个子节点,并且子节点可以被多个父节点共享。
// 为了实现这一目标,我们使用以下Rust特性:
// 1. Rc<T> 允许数据有多个所有者(引用计数),用于共享子节点。
// 2. RefCell<T> 提供内部可变性,允许在不可变引用下修改子节点列表。
// 导入必要的模块
use std::cell::RefCell;
use std::rc::Rc;
// 定义 Node 结构体
#[derive(Debug)]
struct Node {
value: i32, // 节点存储的整数值
// 子节点列表:通过 RefCell 包装 Vec<Rc<Node>> 实现内部可变性,
// 使得即使 Node 实例不可变,也能修改其子节点。
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
// 示例 15-27: 创建叶节点(无子节点)和分支节点(以叶节点为子节点)
// 创建叶节点 leaf,值为 3,子节点列表为空
let leaf = Rc::new(Node {
value: 3,
children: RefCell::new(vec![]),
});
// 创建分支节点 branch,值为 5,并将 leaf 作为其子节点
let branch = Rc::new(Node {
value: 5,
// 通过 Rc::clone 增加 leaf 的引用计数,使 branch 共享 leaf 的所有权
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
// 此时,leaf 有两个所有者:变量 leaf 本身和 branch 的子节点列表。
// 可以通过 branch.children 从 branch 访问 leaf,但 leaf 不知道它是 branch 的子节点。
// 后续将修改代码,使 leaf 能够指向其父节点(使用弱引用 Weak<T> 避免循环引用)。
}增加子节点向父节点的引用
// src/main.rs
// 示例 15-28: 创建树形结构,其中子节点通过 `Weak<T>` 弱引用感知父节点,避免循环引用
// 核心目标:定义树节点结构,子节点可访问父节点,但父节点不因子节点引用而泄漏内存。
// 导入必要的模块
use std::cell::RefCell;
use std::rc::{Rc, Weak};
// 定义 Node 结构体
#[derive(Debug)]
struct Node {
value: i32, // 节点存储的整数值
parent: RefCell<Weak<Node>>, // 父节点引用,使用 Weak<T> 避免循环引用
children: RefCell<Vec<Rc<Node>>>, // 子节点列表,通过 Rc 共享,RefCell 提供内部可变性
}
fn main() {
// 1. 创建叶节点 leaf,值为 3,初始时无父节点,子节点列表为空
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()), // 初始化为空 Weak 引用
children: RefCell::new(vec![]), // 无子节点
});
// 2. 打印 leaf 的父节点信息,此时应为 None
println!("leaf 创建后,其父节点 = {:?}", leaf.parent.borrow().upgrade());
// 输出: leaf 创建后,其父节点 = None
// 3. 创建分支节点 branch,值为 5,初始时无父节点,并将 leaf 作为其子节点
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()), // 分支节点自身也无父节点
children: RefCell::new(vec![Rc::clone(&leaf)]), // 将 leaf 添加为子节点
});
// 4. 修改 leaf 的父节点指向 branch,通过 Weak 引用避免循环引用
// 获取 leaf.parent 的可变借用,将其设置为指向 branch 的弱引用
*leaf.parent.borrow_mut() = Rc::downgrade(&branch);
// 5. 再次打印 leaf 的父节点,现在应为 Some(branch)
println!("设置后,leaf 的父节点 = {:?}", leaf.parent.borrow().upgrade());
// 输出: leaf 的父节点 = Some(Node { ... })
// 通过 Weak 引用,leaf 可以安全地访问父节点,且不会导致循环引用和栈溢出
// 打印时,Weak 引用会显示为 (Weak),不会递归打印整个树
// 6. 验证引用计数,确认无内存泄漏
println!("branch 的强引用计数 = {}", Rc::strong_count(&branch)); // 应为 2 (branch 和 leaf.children 中的引用)
println!("leaf 的强引用计数 = {}", Rc::strong_count(&leaf)); // 应为 2 (leaf 和 branch.children 中的引用)
// 当 main 函数结束时,branch 和 leaf 的强引用计数会降为 0,内存被正确释放
}显示strong_count和weak_count的变化
// src/main.rs
// 本示例通过创建一个树形结构,展示 Rc<T> 和 Weak<T> 引用计数的变化,
// 证明通过使用弱引用(Weak)可以有效避免循环引用和内存泄漏。
use std::cell::RefCell;
use std::rc::{Rc, Weak};
// 定义树节点结构,包含值、父节点(弱引用)和子节点(Rc列表)
#[derive(Debug)]
struct Node {
value: i32,
parent: RefCell<Weak<Node>>, // 父节点使用弱引用,避免循环引用
children: RefCell<Vec<Rc<Node>>>, // 子节点列表,通过Rc共享所有权
}
fn main() {
// 创建叶节点 leaf,初始父节点为 Weak::new(),子节点为空
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()), // ① leaf 的 Rc<Node> 创建后,强引用计数为1,弱引用计数为0
children: RefCell::new(vec![]),
});
// 打印 leaf 创建后的引用计数
println!("leaf 创建后 - 强引用: {}, 弱引用: {}",
Rc::strong_count(&leaf), Rc::weak_count(&leaf));
{
// 内部作用域开始
// 创建分支节点 branch,其子节点包含 leaf
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![Rc::clone(&leaf)]), // branch 克隆 leaf 的 Rc,leaf 强引用计数变为2
});
// 将 leaf 的父节点设置为 branch 的弱引用
*leaf.parent.borrow_mut() = Rc::downgrade(&branch); // ③ branch 的弱引用计数变为1
// 打印 branch 的引用计数
println!("内部作用域内 - branch 强引用: {}, 弱引用: {}",
Rc::strong_count(&branch), Rc::weak_count(&branch));
// 打印 leaf 的引用计数
println!("内部作用域内 - leaf 强引用: {}, 弱引用: {}",
Rc::strong_count(&leaf), Rc::weak_count(&leaf));
// ⑤ 内部作用域结束,branch 离开作用域,其 Rc<Node> 的强引用计数减为0,Node 被丢弃
} // 虽然此时 branch 的弱引用计数(leaf.parent 指向)仍为1,但这不会阻止 Node 被丢弃
// 尝试在作用域结束后访问 leaf 的父节点,会得到 None
println!("内部作用域结束后 - leaf 的父节点: {:?}",
leaf.parent.borrow().upgrade()); // 输出 None
// 打印 leaf 的引用计数,此时只有 leaf 变量持有 Rc<Node> 的强引用,计数为1
println!("内部作用域结束后 - leaf 强引用: {}, 弱引用: {}",
Rc::strong_count(&leaf), Rc::weak_count(&leaf));
// 程序结束时,leaf 离开作用域,强引用计数降为0,节点被清理,无内存泄漏
}十七. 无畏并发
安全且高效地处理并发编程是 Rust 的核心目标之一,它区分了“并发”(独立运行)与“并行”(同时运行)。Rust 将内存安全与并发挑战统一交由所有权和类型系统管理,能在编译期而非运行时捕获错误,这种特性被称为“无畏并发”。
为实现这一目标,Rust 并未局限于单一教条,而是提供了多种建模工具以应对不同场景。本章将探讨如何创建线程、使用通道进行消息传递、允许多线程共享状态的并发模式,以及如何通过
Sync和Sendtrait 将并发保证扩展至自定义类型。
1. 使用线程同时运行代码
现代操作系统通过进程和线程来管理程序的并发执行,其中线程是程序内部独立运行的部分,允许将计算操作拆分以提高性能,但这也引入了因执行顺序不确定而导致的竞争、死锁及难以复现的 Bug 等复杂性。
①使用spawn创建新线程
// src/main.rs
// 使用 thread::spawn 创建新线程,验证主线程与新线程的交替执行及输出顺序的不确定性。
// 注意:主线程结束后,新线程会被强制终止,无论其任务是否完成。
use std::thread;
use std::time::Duration;
fn main() {
// 启动一个新线程
thread::spawn(|| {
for i in 1..10 { // 新线程循环打印
println!("hi number {i} from the spawned thread!");
thread::sleep(Duration::from_millis(1)); // 暂停1毫秒,让出CPU
}
});
// 主线程循环打印
for i in 1..5 {
println!("hi number {i} from the main thread!");
thread::sleep(Duration::from_millis(1));
}
// 现象:
// 1. 每次运行输出顺序可能不同,因为线程调度由操作系统决定。
// 2. 主线程结束后,新线程的循环可能提前中断(如示例中只输出了5次就停止了),
// 因为操作系统会回收主线程及相关资源,导致新线程被销毁。
}②使用join句柄等待所有线程结束
// src/main.rs
// 示例 16-1:演示多线程交替执行,但主线程结束后子线程可能被强制终止
use std::thread;
use std::time::Duration;
fn main() {
// 创建新线程
thread::spawn(|| {
// 子线程循环打印
for i in 1..10 {
println!("hi number {i} from the spawned thread!");
thread::sleep(Duration::from_millis(1));
}
});
// 主线程循环打印
for i in 1..5 {
println!("hi number {i} from the main thread!");
thread::sleep(Duration::from_millis(1));
}
// 注意:主线程结束后,子线程可能还没执行完就被销毁了
// 每次运行输出顺序可能不同,因为线程调度由操作系统决定
}
// 示例 16-2:使用 JoinHandle 等待子线程结束
/*
use std::thread;
use std::time::Duration;
fn main() {
// 保存 spawn 返回的句柄
let handle = thread::spawn(|| {
for i in 1..10 {
println!("hi number {i} from the spawned thread!");
thread::sleep(Duration::from_millis(1));
}
});
// 主线程循环打印
for i in 1..5 {
println!("hi number {i} from the main thread!");
thread::sleep(Duration::from_millis(1));
}
// 阻塞主线程,等待子线程执行完毕
handle.join().unwrap();
}
*/
// 示例:将 join 放在主线程循环之前
/*
use std::thread;
use std::time::Duration;
fn main() {
let handle = thread::spawn(|| {
for i in 1..10 {
println!("hi number {i} from the spawned thread!");
thread::sleep(Duration::from_millis(1));
}
});
// 先等待子线程结束,再执行主线程循环
handle.join().unwrap();
for i in 1..5 {
println!("hi number {i} from the main thread!");
thread::sleep(Duration::from_millis(1));
}
}
*/③在线程中使用move闭包
use std::thread;
fn main() {
// 主线程创建一个动态数组
let v = vec![1, 2, 3];
// --- 示例 16-3:尝试在子线程中使用主线程的数据 ---
// 错误分析:
// 1. 闭包内部只是读取 v,因此 Rust 默认推导出闭包是“借用”了 v。
// 2. thread::spawn 要求闭包的参数生命周期必须是 'static(即闭包不能依赖主线程中可能提前销毁的局部变量)。
// 3. 如果允许编译,子线程可能在主线程结束后才运行,此时主线程的 v 已被销毁,子线程持有的引用将变成悬垂指针(Dangling Pointer)。
// 编译器报错:closure may outlive the current function, but it borrows `v`
// let handle = thread::spawn(|| {
// println!("Here's a vector: {:?}", v);
// });
// --- 示例 16-4:主线程提前销毁数据 ---
// 错误分析:
// 即使没有编译器的 'static 限制,如果主线程在子线程执行完毕前主动销毁了数据,也会导致子线程访问非法内存。
// let handle = thread::spawn(|| {
// println!("Here's a vector: {:?}", v);
// });
// drop(v); // 主线程在这里丢弃了 v
// handle.join().unwrap();
// --- 示例 16-5:使用 move 关键字转移所有权 ---
// 解决方案:
// 在主线程中调用 thread::spawn 时,在闭包前加上 move 关键字。
// 这会强制闭包获取它所需数据的所有权(Ownership),而不是仅仅借用。
let handle = thread::spawn(move || {
println!("Here's a vector: {:?}", v);
});
// 等待子线程执行完毕
handle.join().unwrap();
}2. 使用消息在线程间转移数据
①介绍
在现代并发编程中,消息传递(Message Passing)机制正被广泛用于保障并发安全。其核心思想是:线程或 Actor 之间通过互相发送包含数据的消息来进行通信,而非直接操作共享内存。这一理念源自 Go 语言的经典口号:“不要通过共享内存来通信,而是通过通信来共享内存”。
你可以将通道想象成有活水流动的溪流或河流,数据就像放入其中的橡皮鸭或小船,顺流而下抵达终点。在编程中,通道由位于上游的发送者和位于下游的接收者两部分组成。代码可以通过调用发送者的方法来传送数据,而另一处代码则可以通过检查接收者来获取数据。如果发送者或接收者中的任何一端被丢弃,相应的通道就会被关闭。
use std::sync::mpsc;
use std::thread;
fn main() {
// 创建一个通道,mpsc 表示“多生产者,单消费者”(Multiple Producer, Single Consumer)
// mpsc::channel() 返回一个包含两个端点的元组:发送端 (tx) 和接收端 (rx)
let (tx, rx) = mpsc::channel();
// 生成一个新线程,模拟“上游”的生产者
thread::spawn(move || {
// 在新线程中创建数据
let val = String::from("hi");
// 使用发送端 tx 将数据发送到通道中
// send 方法会获取数据的所有权并将其移入通道
// unwrap() 用于在发送失败时(如接收端已被销毁)触发 panic
tx.send(val).unwrap();
});
// 在主线程中,通过接收端 rx 从通道中获取数据
// recv 方法会阻塞当前线程,直到有数据到达通道
// 一旦接收到数据,recv 会将其包裹在 Result 中返回
let received = rx.recv().unwrap();
// 打印接收到的值
println!("Got: {}", received);
}②通道和所有权转移
use std::sync::mpsc;
use std::thread;
fn main() {
// 创建一个通道,mpsc 代表“多生产者,单消费者”(Multiple Producer, Single Consumer)
// 该函数返回一个元组,包含发送端 (tx) 和接收端 (rx)
let (tx, rx) = mpsc::channel();
// 生成一个新线程,模拟数据的“生产者”
thread::spawn(move || {
// 在新线程中创建一个字符串变量
let val = String::from("hi");
// 使用发送端 tx 将 val 发送到通道
// send 方法会获取数据的所有权并将其移入通道
tx.send(val).unwrap();
// 【核心逻辑演示】
// 如果我们尝试在这里再次使用 val,Rust 会阻止我们
// 因为 send 已经将 val 的所有权转移给了接收端
// println!("val is {}", val); // 这行代码会导致编译错误
});
// 在主线程中,通过接收端 rx 从通道中获取数据
// recv 方法会阻塞当前线程,直到有数据到达
// 一旦接收到数据,它会将其包裹在 Result 中返回
let received = rx.recv().unwrap();
// 打印接收到的值
println!("Got: {}", received);
}③发送多个值并观察接受者的等待过程
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
// 创建一个通道,mpsc 代表“多生产者,单消费者”(Multiple Producer, Single Consumer)
// 该函数返回一个元组,包含发送端 (tx) 和接收端 (rx)
let (tx, rx) = mpsc::channel();
// 生成一个新线程,模拟数据的“生产者”
thread::spawn(move || {
// 在新线程中创建一个包含多个字符串的动态数组
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
// 遍历数组,逐个发送字符串
for val in vals {
tx.send(val).unwrap();
// 每次发送后暂停 1 秒,模拟耗时操作
thread::sleep(Duration::from_secs(1));
}
// 当循环结束后,发送端 tx 会被销毁,通道随之关闭
});
// 在主线程中,将 rx 视作迭代器来处理
// 这种方式会不断接收消息,直到通道关闭(即发送端被销毁)
for received in rx {
// 打印接收到的值
println!("Got: {}", received);
}
// 【核心逻辑说明】
// 注意主线程的 for 循环中没有执行任何暂停或延迟指令。
// 这表明主线程正在阻塞等待接收新线程传递过来的值。
// 输出的时间间隔(1s)完全是由新线程中的 sleep 控制的。
}④通过克隆发送者创建多个生产者
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
// 创建一个通道,mpsc 代表“多生产者,单消费者”(Multiple Producer, Single Consumer)
// 该函数返回一个元组,包含发送端 (tx) 和接收端 (rx)
let (tx, rx) = mpsc::channel();
// 【核心步骤】克隆发送端
// 为了创建第二个生产者,我们需要克隆原始的发送端 tx。
// 这会生成一个具有相同功能的新发送端句柄 (tx1),以便传递给第一个新线程。
let tx1 = tx.clone();
// 生成第一个新线程,并传入克隆后的发送端 tx1
thread::spawn(move || {
// 准备要发送的数据集合
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
// 遍历并发送数据,每次发送后暂停 1 秒
for val in vals {
tx1.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
// 生成第二个新线程,并传入原始发送端 tx
thread::spawn(move || {
// 准备另一组要发送的数据集合
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
// 遍历并发送数据,每次发送后暂停 1 秒
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
// 在主线程中,将 rx 视作迭代器来处理
// 这种方式会不断接收消息,直到所有发送端都被销毁、通道关闭
for received in rx {
// 打印接收到的值
println!("Got: {}", received);
}
// 【运行说明】
// 由于两个子线程都在向同一个接收端发送数据,
// 程序运行时会交替打印出两组不同的消息。
// 注意:具体的输出顺序可能因操作系统的线程调度而异,这体现了并发编程的不确定性。
}3. 共享状态的并发
消息传递虽然是一种优秀的并发通信机制,但并非唯一选择。另一种常见的方法是让多个线程直接访问相同的共享数据,这与Go语言中“不要通过共享内存来通信”的理念形成了对照。
这两种机制在所有权概念上有着本质的区别。通道(Channel)的行为更接近于单一所有权,即数据一旦被发送到通道,发送方就不能再使用它。相反,共享内存并发则更类似于多重所有权,允许多个线程同时访问同一块内存地址。虽然智能指针可以实现多重所有权,但这无疑增加了系统管理的复杂性。幸运的是,Rust的类型系统和所有权规则能够有效地帮助我们正确管理这些所有权。
为了具体说明共享内存领域的并发处理,我们可以引入互斥体(Mutex)。作为一种常见的并发原语,互斥体的核心特性是任意时刻只允许一个线程访问它所保护的数据。线程在访问数据前必须先获取锁,使用完毕后必须释放锁,这种机制确保了共享数据在并发环境下的安全访问。
①互斥体一次只允许一个线程访问数据
介绍
互斥体(mutex)的核心在于实现“互斥”,即在任意时刻只允许一个线程访问其守护的数据。为了获得访问权,线程必须先发出信号来获取锁。这种锁机制确保了只有持有锁的线程才能操作数据,从而守护了共享资源的安全。
管理互斥体需要严格遵守两条铁律:首先,必须在使用数据前尝试获取锁;其次,必须在操作完成后及时释放锁,以便其他线程能够继续获取。
正因为手动管理这些步骤极易出错,开发者通常更倾向于使用通道等机制。不过在 Rust 中,得益于类型系统和所有权规则的强力约束,编译器能够在加锁和解锁的过程中提供安全保障,有效避免了因疏忽而导致的并发错误。
Mutex<T>接口
use std::sync::Mutex;
fn main() {
// 创建一个新的互斥体,内部初始值为 5
let m = Mutex::new(5);
// 使用作用域块限制锁的生命周期
{
// 获取互斥体的锁。lock() 调用会阻塞当前线程直到获取锁成功
// 返回的 MutexGuard 是一个智能指针,实现了 Deref 和 Drop 特性
let mut num = m.lock().unwrap();
// 通过解引用智能指针来修改内部数据
*num = 6;
// 当 num 离开作用域时,Drop 特性会自动释放锁,无需手动解锁
}
// 锁释放后,打印整个互斥体,可以看到内部值已被成功修改
println!("m = {:?}", m);
}在多个线程间共享Mutex<T>
use std::sync::Mutex;
use std::thread;
fn main() {
// 创建一个 Mutex<T>,内部初始值为 0。此时还未发生所有权转移。
let counter = Mutex::new(0);
// 用于存储后续生成的线程句柄
let mut handles = vec![];
// 循环 10 次,依次启动 10 个线程
for _ in 0..10 {
// 【错误点演示】
// 这里尝试将 counter 移动进闭包会导致编译失败。
// 因为 Mutex<i32> 没有实现 Copy trait,在第一次循环后所有权就被移走了。
let handle = thread::spawn(move || {
// 尝试获取互斥体的锁。lock() 会阻塞当前线程直到获取锁成功。
// 返回的 MutexGuard 是一个智能指针,通过 Deref 指向内部数据,并通过 Drop 实现自动解锁。
let mut num = counter.lock().unwrap();
// 对受保护的内部数据进行加 1 操作
*num += 1;
});
handles.push(handle);
}
// 等待所有子线程运行完毕
for handle in handles {
handle.join().unwrap();
}
// 所有线程结束后,主线程再次获取锁并打印最终结果
println!("Result: {}", *counter.lock().unwrap());
}多线程与多重所有权
// 在第 15 章中,我们借助智能指针 Rc<T> 提供的引用计数为单个值赋予了多个所有者。
// 接下来,我们会尝试使用相同的方法来解决当前的问题。
// 在示例 16-14 中,我们使用 Rc<T> 来包裹 Mutex<T>,并在每次需要将所有权移动至线程中时都克隆 Rc<T>。
use std::rc::Rc;
use std::sync::Mutex;
use std::thread;
fn main() {
let counter = Rc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let counter = Rc::clone(&counter);
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}
/*
再次编译代码,居然出现了另一个错误!编译器可真能教会我们不少东西:
error[E0277]: `Rc<Mutex<i32>>` cannot be sent between threads safely
--> src/main.rs:11:22
|
11 | let handle = thread::spawn(move || {
| ----------------------------- ^
| |
| `Rc<Mutex<i32>>` cannot be sent between threads safely
12 | let mut num = counter.lock().unwrap();
13 |
14 | *num += 1;
15 | });
| - within this `[closure@src/main.rs:11:36: 15:10]`
|
= help: within `[closure@src/main.rs:11:36: 15:10]`, the trait `Send` is not implemented for `Rc<Mutex<i32>>`
= note: required because it appears within the type `[closure@src/main.rs:11:36: 15:10]`
note: required by a bound in `spawn`
这段错误提示信息的内容非常丰富!其中的重点部分就是`Rc<Mutex<i32>>` cannot be sent between threads safely(它告诉我们 Rc<Mutex<i32>> 不能在线程间安全地传递)。
编译器随后给出了具体的原因:the trait `Send` is not implemented for `Rc<Mutex<i32>>`(Rc<Mutex<i32>> 没有实现 Send trait)。
我们会在下一节中再来讨论 Send,它确保了我们在线程中使用的类型能够在并发环境中正常工作。
遗憾的是,Rc<T> 在跨线程使用时并不安全。当 Rc<T> 管理引用计数时,它会在每次调用 clone 的过程中都增加引用计数,并在每次克隆出的实例被丢弃时都减少引用计数,但它并没有使用任何并发原语来保证修改计数的过程不会被另一个线程所打断。
这极有可能导致计数错误并产生诡异的 bug,比如内存泄漏或值在使用时被莫名其妙地提前释放。
我们需要的是一个行为与 Rc<T> 一致,且能够保证线程安全的引用计数类型。
*/原子引用计数Arc<T>
// 幸运的是,有一种被称为 Arc<T> 的类型,它既拥有类似于 Rc<T> 的行为,
// 又保证了自己可以被安全地用于并发环境中。其名称中的 A 代表着原子(atomic),
// 表明自己是一个原子引用计数(atomically reference-counted)类型。
// 原子是一种新的并发原语,我们可以参考标准库文档中的 std::sync::atomic 部分
// 来获得更多相关信息。原子和原生类型用法相似,并且可以安全地在多个线程间共享。
// 为什么不默认使用 Arc<T>?
// 因为线程安全需要性能开销,只有必要时才应该使用 Arc<T>;单线程场景下 Rc<T> 更快。
// 由于 Arc<T> 与 Rc<T> 接口完全一致,只需修改 use、new、clone 三处即可
use std::sync::{Arc, Mutex};
use std::thread;
fn main() {
let counter = Arc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let counter = Arc::clone(&counter);
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}
/*
示例 16-15:使用 Arc<T> 包裹 Mutex<T> 实现多线程共享所有权
运行结果:
Result: 10
终于成功了!计数器的值从 0 变成了 10。
这个例子展示了 Mutex<T> 与线程安全的核心用法:
1. 用 Arc<T> 实现多线程间共享所有权
2. 用 Mutex<T> 保证同一时间只有一个线程修改共享数据
小提示:
如果只是简单的数值操作,标准库的 std::sync::atomic 模块提供了比 Mutex<T> 更高效的原子类型,
本例使用 Mutex<T> 只是为了专注展示它的工作方式。
*/②RefCell<T>/Rc<T>和Mutex<T>/Arc<T>的相似性
虽然
counter本身不可变,但我们依然能获取其内部值的可变引用。这说明Mutex<T>与Cell系列类型功能相似,都提供内部可变性 —— 就像第 15 章用RefCell<T>修改Rc<T>的内容,这里我们用Mutex<T>修改Arc<T>中的数据。Rust 无法帮你完全规避所有逻辑错误:和
Rc<T>存在循环引用导致内存泄漏的风险类似,Mutex<T>也可能引发死锁 —— 当两个线程各持有一个锁,又同时请求对方的锁时,会陷入永久等待。你可以尝试编写死锁程序,并借鉴其他语言的互斥体死锁规避策略,Rust 标准库的Mutex<T>和MutexGuard文档也提供了相关参考信息。接下来我们会讨论
Send与Sync这两个 trait,并演示如何在自定义类型中使用它们
4. 使用Send trait和Sync trait对并发进行扩展
Rust 语言本身内置的并发特性极少,本章讨论的并发特性大多来自标准库。并发解决方案不局限于语言或标准库,用户可自定义并发功能,也可使用第三方并发框架。
仅有两个并发概念被嵌入 Rust 语言中:
std::marker模块的Sendtrait 与Synctrait。
①允许线程间转移所有权的Send trait
只有实现
Sendtrait 的类型,才能安全在线程间转移所有权。除Rc<T>等极少数类型外,几乎所有 Rust 类型都实现了Send。Rc<T>仅设计用于单线程环境,无需为线程安全付出额外性能开销;若跨线程使用,可能导致引用计数错误。Rust 的类型系统与 trait 约束会阻止意外跨线程传递
Rc<T>。例如示例 16-14 中,使用Rc<T>会触发 “Send未实现” 的编译错误,换成实现了Send的Arc<T>即可通过编译。完全由
Send类型组成的复合类型会被自动标记为Send。除第 19 章讨论的裸指针外,几乎所有原生类型都满足Send约束。
②允许多个线程同时访问的Sync trait
只有实现
Synctrait 的类型,才能被多个线程安全引用。等价条件是:若类型T的引用&T满足Send约束,则T满足Sync约束,即T的引用可安全跨线程传递。与Send类似,所有原生类型都满足Sync,由Sync类型组成的复合类型也会自动被识别为满足Sync。Rc<T>、RefCell<T>及Cell<T>系列不满足Sync约束:Rc<T>因单线程引用计数机制无法保证线程安全;RefCell<T>的运行时借用检查不提供线程安全保障。而Mutex<T>满足Sync,可被多线程共享访问。
③手动实现Send和Sync是不安全的
由
Send和Sync类型组成的复合类型,会自动实现这两个 trait,无需手动实现。Send与Sync是标签 trait,没有实现方法,仅用于标记并发安全属性。手动实现这两个 trait 需要使用不安全 Rust 代码。自定义并发类型若包含未实现
Send/Sync的类型,需谨慎确保线程安全。相关安全保证与实现细节可参考 Rust 官方的 The Rustonomicon 文档,第 19 章会进一步讨论。
十八. Async、Await、Future与Stream
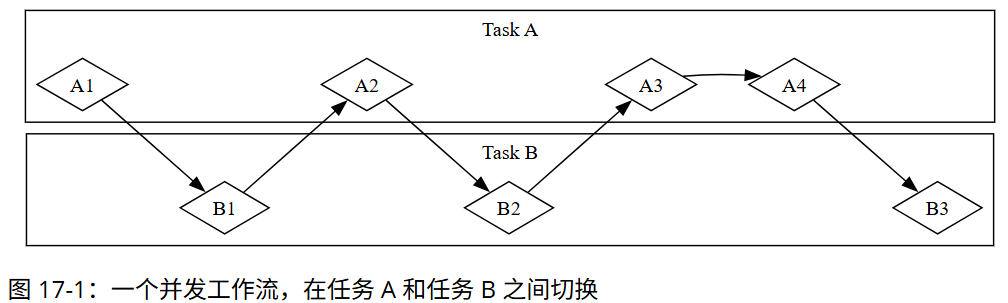
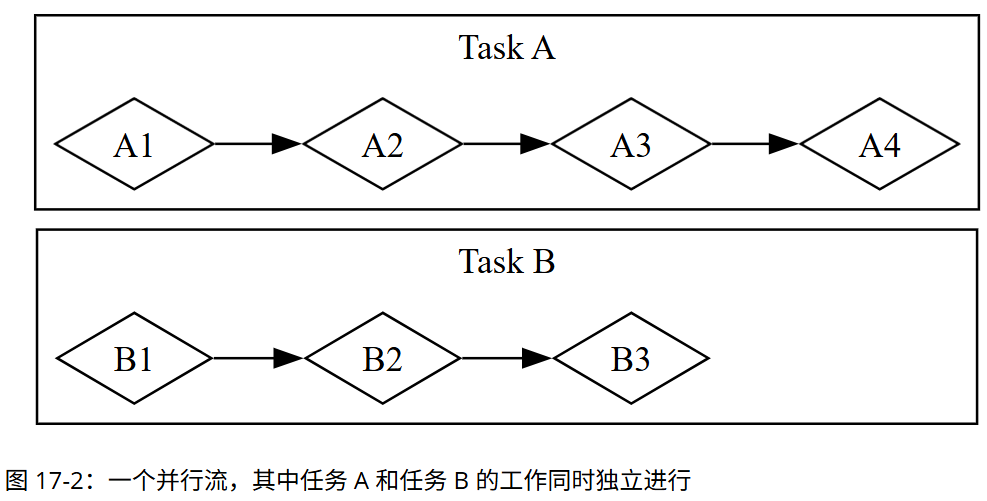
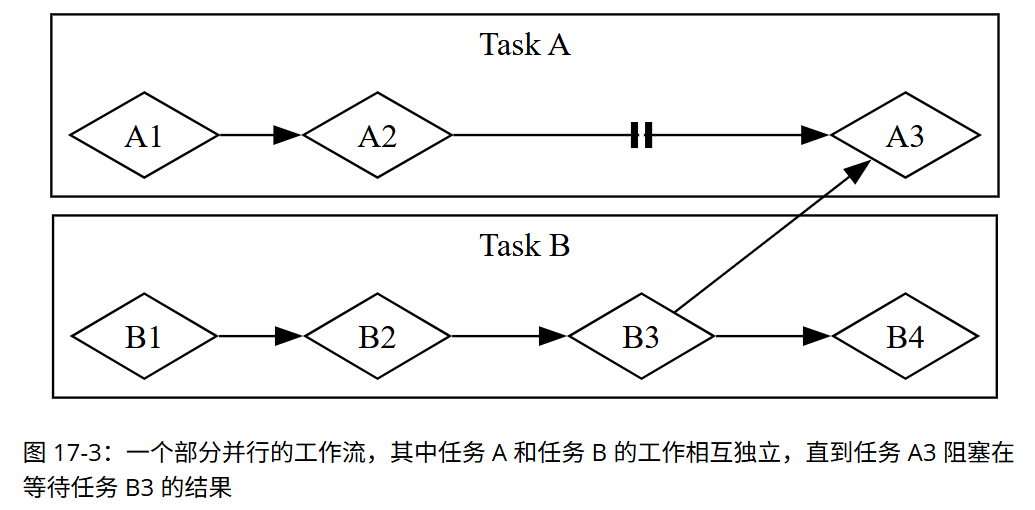
很多计算机操作耗时,等待过程中可通过并发、并行处理其他任务。程序逻辑多为近线性,而异步编程是一种抽象,它用 “可暂停点” 和 “最终结果” 表达代码,由运行时处理协调细节。本章基于并发模型,介绍 Rust 的
futures、streams、async/await语法,以及第三方提供的异步运行时。以视频导出(CPU 密集型,受限于处理器算力)和视频下载(I/O 密集型,受限于网络速度)为例,操作系统提供了程序级并发,但更细粒度的并发机会(如文件下载工具不阻塞 UI)需要自行处理,而多数网络、文件相关 API 是阻塞的。
blocking术语通常用于文件、网络等资源交互函数,这类场景下非阻塞操作更具优势。虽然可通过创建线程避免阻塞主线程,但线程资源开销较大;更理想的方式是定义任务,让运行时自动选择最佳执行顺序 —— 这正是 Rust 的async抽象提供的能力。本章将介绍:async/await语法,以及如何借助运行时执行异步函数用异步模型解决并发相关挑战
多线程与异步的互补方案及组合使用方式
-
并发:单个执行单元(如单人、单核 CPU)在多个任务间切换推进,同一时刻只处理一个任务,无同时进展。
并行:多个执行单元(如团队成员、多核 CPU)同时推进多个任务,同一时刻均可取得进展。
任务间的依赖关系会让原本的并发或并行转为串行;并行与并发也会交叉影响,如解除阻塞的任务会导致其他任务无法并行 / 并发推进。
软件与硬件层面逻辑一致:单核 CPU 可通过线程、进程、异步实现并发;多核 CPU 可同时执行任务实现并行。Rust 的
async代码通常以并发方式执行,底层是否利用并行,取决于硬件、操作系统和所使用的异步运行时。
1. Future与async语法
①介绍
Rust 异步编程的核心元素是
futures与async/await关键字。Future:代表 “未来才会就绪的值”,在其他语言中也被称为
task或promise。Rust 通过Futuretrait 为异步操作提供统一接口,所有实现该 trait 的类型都是 future,它们会保存自身进度信息及 “就绪” 的具体含义。async/await:
async用于标记可中断、可恢复的代码块或函数;在async代码中,可用await等待一个 future 就绪,每个await位置都是潜在的暂停 / 恢复点。检查 future 是否就绪的过程称为polling(轮询)。与 C#、JavaScript 等语言的
async/await相比,Rust 在语法处理上存在差异,这是设计使然。编写异步 Rust 时,大多直接使用async/await,编译器会将其编译为基于Futuretrait 的代码(类似for循环编译为基于Iteratortrait 的代码);用户也可为自定义类型实现Futuretrait,后续会深入讲解其原理。
②异步程序
介绍
为专注学习异步编程,这里使用
trplcrate(“The Rust Programming Language” 缩写),它重导出了本章所需的类型、Trait 和函数,底层基于futures和tokiocrate:futures是 Rust 异步代码的官方实验库,FutureTrait 最初在此设计;tokio是目前最广泛使用的异步运行时,常见于 Web 应用,因测试充分、生态成熟被选用;trpl会对部分 API 重命名 / 包装,简化使用,源码可查看重导出来源与注释说明。接下来将编写第一个异步程序:构建命令行工具,并发抓取两个网页、提取
<title>元素,输出最先完成流程的页面标题。
定义 page_title 函数
// 引入 trpl crate 提供的 HTML 解析功能
use trpl::Html;
/// 异步函数:获取指定 URL 网页的标题文本
async fn page_title(url: &str) -> Option<String> {
// 发送 GET 请求,await 等待响应(Rust 的 await 是后缀关键字,跟在表达式后)
let response = trpl::get(url).await;
// 获取响应文本,同样需要 await,因为 text() 也是异步操作
let response_text = response.text().await;
// 解析 HTML,用 CSS 选择器提取第一个 <title> 元素
Html::parse(&response_text)
.select_first("title")
// 如果找到 title 元素,提取其内部文本
.map(|title| title.inner_html())
}
// 示例17-2:await 的链式调用写法,等价于上面的两步 await
// let response_text = trpl::get(url).await.text().await;
/*
--- 关键概念说明 ---
1. async 函数编译规则:
- Rust 会将 async 函数编译为返回 `impl Future<Output = T>` 的非异步函数
- 编译器会为 async 代码块生成一个实现了 Future trait 的匿名类型
*/
use std::future::Future;
use trpl::Html;
// page_title 函数的等价非异步写法
fn page_title_equivalent(url: &str) -> impl Future<Output = Option<String>> {
// async move 块捕获 url 参数,生成 Future
async move {
let text = trpl::get(url).await.text().await;
Html::parse(&text)
.select_first("title")
.map(|title| title.inner_html())
}
}
/*
2. Future 的惰性:
- Rust 的 Future 是惰性的,只有调用 await 时才会执行(类似迭代器的 next)
- 不使用 await 的 Future 不会运行,编译器会给出警告
- 与 thread::spawn 不同,async 代码不会立即执行,只有 await 才触发
3. await 关键字:
- Rust 中 await 是后缀关键字,放在表达式后面,便于链式调用
- 与其他语言(如 C#/JS)的前缀 await 不同,这种设计让链式调用更易读
4. HTML 解析与 Option 处理:
- Html::parse 将响应文本解析为 HTML 结构
- select_first("title") 返回 Option<ElementRef>(可能不存在该元素)
- Option::map 处理 Some/None 情况,存在则提取 inner_html,否则返回 None
*/
// 后续可在异步 main 中调用该函数(需异步运行时支持,如 tokio)
// #[tokio::main]
// async fn main() {
// let url = "https://example.com";
// let title = page_title(url).await;
// println!("Page title: {:?}", title);
// }使用运行时执行异步函数
// 引入所需依赖
use trpl::Html;
/// 异步函数:获取指定 URL 网页的标题文本
async fn page_title(url: &str) -> Option<String> {
let response = trpl::get(url).await;
let response_text = response.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}
/*
示例17-3:错误写法,async fn main 无法编译
错误原因:Rust 不允许将特殊的 main 函数标记为 async
错误信息:`main` function is not allowed to be `async`
*/
// async fn main() {
// let args: Vec<String> = std::env::args().collect();
// let url = &args[1];
// match page_title(url).await {
// Some(title) => println!("The title for {url} was {title}"),
// None => println!("{url} had no title"),
// }
// }
/*
--- 关键说明:为什么 main 不能直接是 async ---
异步代码需要运行时(executor)管理执行细节,main 作为程序入口,本身不是运行时
Rust 不自带全局运行时,需要手动选择并初始化(如 tokio、async-std 等)
因此,不能直接在 main 中使用 await,必须借助运行时提供的阻塞函数(如 trpl::block_on)
*/
/// 示例17-4:正确写法,使用 trpl::block_on 运行异步代码块
fn main() {
// 获取命令行参数(沿用第12章模式)
let args: Vec<String> = std::env::args().collect();
// trpl::block_on 接受一个 future,阻塞当前线程直到其完成
// 内部会借助 tokio 设置运行时,执行传入的 async 块
trpl::block_on(async {
let url = &args[1];
match page_title(url).await {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
});
}
/*
运行结果示例:
$ cargo run -- https://www.rust-lang.org
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.05s
Running `target/debug/async_await 'https://www.rust-lang.org'`
The title for https://www.rust-lang.org was Rust Programming Language
*/
/*
--- Future 的工作原理 ---
每个 await 点都是控制权交还给运行时的位置,Rust 会记录当前状态(类似状态机)
编译器会自动为 async 代码生成状态机数据结构,管理不同 await 点的状态
例如 page_title 函数的状态机伪代码:
enum PageTitleFuture<'a> {
Initial { url: &'a str },
GetAwaitPoint { url: &'a str },
TextAwaitPoint { response: trpl::Response },
}
运行时(executor)负责驱动这个状态机,推进 future 执行
补充:部分运行时提供 #[async_main] 宏,本质也是自动包装 block_on 逻辑
*/让两个 URL 并发竞争
// 引入 trpl 提供的 Either 枚举与 HTML 解析功能
use trpl::{Either, Html};
fn main() {
// 获取命令行传入的两个 URL 参数
let args: Vec<String> = std::env::args().collect();
// 使用 trpl::block_on 运行异步代码块,阻塞线程直到所有异步操作完成
trpl::block_on(async {
// 创建两个 future(此时 future 是惰性的,尚未执行)
let title_fut_1 = page_title(&args[1]);
let title_fut_2 = page_title(&args[2]);
// trpl::select 并发执行两个 future,返回最先完成的结果
// 返回值是 trpl::Either:Left 表示第一个 future 先完成,Right 表示第二个先完成
let (url, maybe_title) = match trpl::select(title_fut_1, title_fut_2).await {
Either::Left(left) => left,
Either::Right(right) => right,
};
// 打印最先完成的 URL,以及对应的标题(或无标题提示)
println!("{url} returned first");
match maybe_title {
Some(title) => println!("Its page title was: '{title}'"),
None => println!("It had no title."),
}
})
}
/// 异步函数:获取 URL 对应页面的标题,同时返回 URL 本身(用于判断哪个先完成)
/// 返回值:(URL 字符串, 页面标题 Option)
async fn page_title(url: &str) -> (&str, Option<String>) {
// 发送 GET 请求并等待响应,再等待响应文本解析完成
let response_text = trpl::get(url).await.text().await;
// 解析 HTML 并提取 <title> 元素文本
let title = Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html());
// 同时返回 URL 和标题,方便后续判断哪个请求先完成
(url, title)
}
/*
--- 关键说明 ---
1. trpl::select:并发执行多个 future,返回最先完成的结果,常用于“竞态”场景
2. trpl::Either:类似 Result,但无“成功/失败”语义,仅表示“两个 future 中哪一个先完成”
enum Either<A, B> { Left(A), Right(B) }
3. future 的惰性:page_title 创建的 future 只有被 await(或被 select 驱动)时才会执行
4. page_title 新增 URL 返回值:即使页面无标题,也能明确知道哪个 URL 先完成
*/2. 并发与async
①使用 spawn_task 创建新任务
use std::time::Duration;
use trpl; // 引入 trpl crate,提供异步工具函数
fn main() {
// 示例 17-6:创建新异步任务(主任务结束后,新任务会被关闭,无法执行到结束)
trpl::block_on(async {
// 生成一个新的异步任务,类似 `thread::spawn`
trpl::spawn_task(async {
for i in 1..10 {
println!("hi number {i} from the first task!");
// 异步 sleep,必须 await,让出控制权给运行时
trpl::sleep(Duration::from_millis(500)).await;
}
});
// 主任务的循环(主任务结束时,spawn 的任务也会被关闭)
for i in 1..5 {
println!("hi number {i} from the second task!");
trpl::sleep(Duration::from_millis(500)).await;
}
});
println!("\n--- Example 17-7 (with join handle) ---\n");
// 示例 17-7:用 join 句柄 await,让任务执行到完成
trpl::block_on(async {
// 生成任务并获取句柄(句柄本身是 future,类似线程的 JoinHandle)
let handle = trpl::spawn_task(async {
for i in 1..10 {
println!("hi number {i} from the first task!");
trpl::sleep(Duration::from_millis(500)).await;
}
});
// 主任务循环
for i in 1..5 {
println!("hi number {i} from the second task!");
trpl::sleep(Duration::from_millis(500)).await;
}
// 等待任务完成,unwrap 处理可能的错误
handle.await.unwrap();
});
println!("\n--- Example 17-8 (with trpl::join) ---\n");
// 示例 17-8:用 trpl::join 等待两个匿名 future
trpl::block_on(async {
// 定义两个异步 future(此时是惰性的,未执行)
let fut1 = async {
for i in 1..10 {
println!("hi number {i} from the first task!");
trpl::sleep(Duration::from_millis(500)).await;
}
};
let fut2 = async {
for i in 1..5 {
println!("hi number {i} from the second task!");
trpl::sleep(Duration::from_millis(500)).await;
}
};
// trpl::join 会公平地交替检查两个 future,等待两者都完成
trpl::join(fut1, fut2).await;
});
}
/*
--- 关键概念说明 ---
1. trpl::spawn_task:
类似 thread::spawn,创建异步任务并返回 JoinHandle(future),可通过 await 等待任务完成。
2. trpl::sleep:
thread::sleep 的异步版本,必须 await,让出控制权给运行时,让其他任务有机会执行。
3. trpl::join:
并发等待多个 future,会公平交替检查每个 future,避免单个 future 一直领先;
线程由操作系统调度,而 async 运行时(如 trpl 底层的 tokio)控制任务调度。
4. 公平性:
trpl::join 会以相同频率检查每个 future,因此每次运行输出顺序一致;
线程调度由操作系统决定,顺序可能随机。
5. 惰性 future:
async 代码块生成的 future 只有被 await/join/select 驱动时才会执行,不驱动则不会运行。
*/②通过消息传递在两个任务之间发送数据
介绍
use std::time::Duration;
use trpl; // 引入 trpl crate,提供异步信道等工具
fn main() {
// 示例 17-9:创建异步信道并发送/接收单个消息(顺序执行,无并发)
trpl::block_on(async {
// 创建异步多生产者单消费者信道,返回发送端 tx 和接收端 rx(rx 需可变)
let (tx, mut rx) = trpl::channel();
let val = String::from("hi");
// 发送消息:异步信道的 send 不会阻塞,无需 await(发送端无数量限制)
tx.send(val).unwrap();
// 接收消息:recv 返回 Future,需 await,不会阻塞线程,而是交还控制权给运行时
let received = rx.recv().await.unwrap();
println!("received '{received}'");
/* 关键说明:
- 同步信道的 Receiver::recv 会阻塞线程,而异步 trpl::Receiver::recv 不会阻塞
- 这里所有操作是顺序执行的,没有并发,消息会立刻到达
*/
});
println!("\n--- Example 17-10 (multiple messages with async channel) ---\n");
// 示例 17-10:通过异步信道发送多个消息并接收(存在问题:消息批量到达、程序不退出)
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
// 准备要发送的消息列表
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
// 发送消息,每次发送后异步 sleep 500ms(让出控制权)
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
/* 接收消息:使用 while let 循环处理异步流
- Rust 目前无法直接用 for 循环处理异步产生的条目,因此用 while let + recv().await
- 每次 await rx.recv() 会交还控制权给运行时,直到消息到达或信道关闭
- 信道关闭时,rx.recv().await 会返回 None,循环终止;否则返回 Some(message)
*/
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
/* 此示例存在的问题:
1. 消息不是按 500ms 间隔到达,而是在发送全部消息后批量到达
2. 程序不会退出:因为发送端 tx 未被丢弃,信道不会关闭,rx.recv() 会一直等待新消息
*/
});
}
/*
--- 异步信道 vs 同步信道 关键区别 ---
1. 接收端 rx:异步版本中 rx 是可变的,同步版本中 rx 不可变
2. recv 方法:异步 recv 返回 Future,需 await;同步 recv 直接阻塞线程
3. send 方法:异步 send 不阻塞,无需 await;同步 send 可能因信道满而阻塞
4. 并发模型:异步信道的发送/接收不会阻塞线程,控制权会交还运行时,让其他任务执行
*/一个async代码块中的代码会线性执行
use std::time::Duration;
use trpl;
fn main() {
trpl::block_on(async {
// 创建异步信道,得到发送端 tx 和接收端 rx
let (tx, mut rx) = trpl::channel();
/* 问题说明(对应示例17-10的问题):
* 同一个 async 块内的代码,会按 `await` 出现的顺序线性执行,没有并发
* 之前的示例中,所有 `tx.send` 和 `sleep` 会先依次执行完毕,之后才会执行接收循环
* 因此消息会在发送延迟全部结束后批量到达,无法实现间隔输出
*/
// 定义发送端 future:封装发送逻辑,包含异步 sleep 延迟
let tx_fut = async move {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx.send(val).unwrap();
// 每次发送后异步 sleep 500ms,让出控制权给运行时
trpl::sleep(Duration::from_millis(500)).await;
}
};
// 定义接收端 future:封装接收逻辑,用 while let 处理异步消息流
let rx_fut = async move {
// 当信道未关闭时,rx.recv().await 返回 Some(value);信道关闭后返回 None,循环终止
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
/* 关键:用 trpl::join 并发执行两个 future
* join 会公平地交替调度发送和接收任务,让两者并发运行
* 发送端每次 sleep 让出控制权后,接收端就能及时收到已发送的消息
* 最终实现“每 500ms 收到一条消息”的预期效果
*/
trpl::join(tx_fut, rx_fut).await;
/* 补充说明:
* 发送端 future 执行完毕后,tx 会被自动丢弃,信道随之关闭
* 接收端的 while let 循环会因 rx.recv().await 返回 None 而正常终止,程序可以退出
*/
});
}将所有权移入 async 代码块
use std::time::Duration;
use trpl;
fn main() {
trpl::block_on(async {
// 创建异步信道,得到发送端 tx 和接收端 rx
let (tx, mut rx) = trpl::channel();
/* 问题根源(原示例17-11的死锁循环):
* 1. trpl::join 需同时等待 tx_fut 和 rx_fut 完成
* 2. tx_fut 发送完消息后结束,但 tx 仅被借用,未被 drop,信道未关闭
* 3. rx_fut 的 while let 循环会一直等待,直到 rx.recv() 返回 None(信道关闭)
* 4. 外层 async 块需等待 join 完成才会结束,tx 才会被 drop
* 形成循环依赖,导致程序永远不退出
*/
// 关键修改:使用 `async move` 将 tx 的所有权移入发送端 future
// 发送端 future 结束后,tx 会被自动 drop,信道随之关闭
let tx_fut = async move {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
// 发送端 future 结束,tx 被 drop,信道发送端关闭
};
// 接收端 future:while let 循环处理消息流,信道关闭后自动终止
let rx_fut = async move {
// 信道未关闭时,rx.recv().await 返回 Some(value);信道关闭后返回 None,循环终止
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
// trpl::join 并发执行两个 future:
// - tx_fut 结束后 tx 被 drop,信道关闭
// - rx_fut 收到 None 后循环结束
// 两个 future 都完成后,join 返回,外层 async 块结束,程序正常退出
trpl::join(tx_fut, rx_fut).await;
});
}
/* 核心知识点:
1. async move:将变量所有权移入 async 代码块,与闭包的 move 关键字用法一致
2. 信道关闭机制:当所有发送端 tx 被 drop 后,信道会自动关闭,接收端 rx.recv() 会返回 None
3. 死锁循环:原示例中因 tx 未被及时 drop,导致 rx_fut 无法结束,形成循环依赖
4. 异步流处理:while let 循环是处理异步消息流的常用方式,会持续 await rx.recv() 直到信道关闭
*/使用 join! 宏合并多个 future
use std::time::Duration;
use trpl;
fn main() {
trpl::block_on(async {
// 创建异步多生产者单消费者信道,得到发送端 tx 和接收端 rx
let (tx, mut rx) = trpl::channel();
// 克隆发送端 tx,创建第一个生产者 tx1(异步信道支持多生产者)
let tx1 = tx.clone();
// 第一个发送 future:async move 将 tx1 所有权移入,发送结束后 tx1 会被自动 drop
let tx1_fut = async move {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx1.send(val).unwrap();
// 每次发送后异步 sleep 500ms,让出控制权给运行时
trpl::sleep(Duration::from_millis(500)).await;
}
};
// 接收端 future:while let 循环持续接收消息,直到信道关闭
let rx_fut = async move {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
// 信道关闭后 rx.recv().await 返回 None,循环自动终止
};
// 第二个发送 future:async move 将原始 tx 所有权移入,发送结束后 tx 会被自动 drop
let tx_fut = async move {
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
// 每次发送后异步 sleep 1500ms,让出控制权给运行时
trpl::sleep(Duration::from_millis(1500)).await;
}
};
/* 关键:使用 trpl::join! 宏等待多个 future 完成
* - 支持任意数量的 future(编译期已知数量),比 trpl::join 更灵活
* - 两个发送 future 结束后,tx 和 tx1 都被 drop,信道发送端全部关闭
* - 接收端 rx_fut 会因信道关闭收到 None,循环终止
* - 所有 future 完成后,join! 返回,外层 async 块结束,程序正常退出
*/
trpl::join!(tx1_fut, tx_fut, rx_fut);
});
}
/*
--- 核心知识点 ---
1. 多生产者异步信道:通过 clone tx 创建多个发送端,异步信道天然支持多生产者单消费者模型
2. async move 的必要性:将发送端所有权移入 async 块,确保发送结束后 tx 被 drop,信道关闭,避免死循环
3. trpl::join! 宏:用于等待多个编译期数量已知的 future,会并发调度所有传入的任务
4. 调度与延迟:两个发送 future 使用不同 sleep 延迟,接收消息的时间间隔也会随之变化,顺序由运行时调度决定
5. 信道关闭逻辑:当所有发送端被 drop 后,接收端 rx.recv().await 会返回 None,接收循环自动终止
*/3. 使用任意数量的futures
①将控制权交还给运行时
use std::thread;
use std::time::Duration;
use trpl;
/// 示例17-14:用 `thread::sleep` 模拟阻塞操作(会阻塞当前线程,导致其他 future 饥饿)
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{}' ran for {}ms", name, ms);
}
fn main() {
trpl::block_on(async {
// ------------------------------
// 示例17-15:无中间 await,future 饥饿问题
// ------------------------------
println!("=== Example 17-15: Starvation Problem ===");
let a = async {
println!("'a' started.");
slow("a", 30);
slow("a", 10);
slow("a", 20);
// 仅在最后一次 await 时才让出控制权,中间 slow 会持续阻塞线程
trpl::sleep(Duration::from_millis(50)).await;
println!("'a' finished.");
};
let b = async {
println!("'b' started.");
slow("b", 75);
slow("b", 10);
slow("b", 15);
slow("b", 350);
trpl::sleep(Duration::from_millis(50)).await;
println!("'b' finished.");
};
// select 会在第一个 future 完成时结束,此处 a 会先执行完所有 slow 才到 await,b 会被“饿死”
trpl::select(a, b).await;
println!();
// ------------------------------
// 示例17-16:用 `trpl::sleep(1ms).await` 插入 await 点,让出控制权
// ------------------------------
println!("=== Example 17-16: Using trpl::sleep to Yield ===");
let one_ms = Duration::from_millis(1);
let a = async {
println!("'a' started.");
slow("a", 30);
trpl::sleep(one_ms).await; // 每次 slow 后让出控制权,让其他任务获得执行机会
slow("a", 10);
trpl::sleep(one_ms).await;
slow("a", 20);
trpl::sleep(one_ms).await;
println!("'a' finished.");
};
let b = async {
println!("'b' started.");
slow("b", 75);
trpl::sleep(one_ms).await;
slow("b", 10);
trpl::sleep(one_ms).await;
slow("b", 15);
trpl::sleep(one_ms).await;
slow("b", 350);
trpl::sleep(one_ms).await;
println!("'b' finished.");
};
trpl::join!(a, b).await;
println!();
// ------------------------------
// 示例17-17:用 `trpl::yield_now().await` 直接让出控制权(更高效)
// ------------------------------
println!("=== Example 17-17: Using yield_now to Yield ===");
let a = async {
println!("'a' started.");
slow("a", 30);
trpl::yield_now().await; // 仅交还控制权给运行时,不实际休眠,比 sleep 更高效
slow("a", 10);
trpl::yield_now().await;
slow("a", 20);
trpl::yield_now().await;
println!("'a' finished.");
};
let b = async {
println!("'b' started.");
slow("b", 75);
trpl::yield_now().await;
slow("b", 10);
trpl::yield_now().await;
slow("b", 15);
trpl::yield_now().await;
slow("b", 350);
trpl::yield_now().await;
println!("'b' finished.");
};
trpl::join!(a, b).await;
});
}
/*
--- 核心知识点 ---
1. async 代码块执行规则:
- 只有 `await` 点会让出控制权给运行时,让其他任务执行
- `await` 之间的代码是同步执行的,不会自动切换任务
2. 饥饿(Starvation)问题:
- 若一个 future 长时间阻塞(如使用 `thread::sleep`)且无中间 `await` 点,其他 future 会一直得不到执行机会
3. 让出控制权的两种方式:
- `trpl::sleep(Duration::from_millis(1)).await`:短暂休眠后让出控制权,适合简单场景
- `trpl::yield_now().await`:仅交还控制权,不实际休眠,更高效,适合计算密集型任务
4. 协作式多任务:
- async Rust 是协作式多任务,每个 future 需主动通过 `await` 点让出控制权,避免长时间阻塞
- 过度拆分任务(如每一行都插入 `await`)会增加状态机开销,需平衡性能与并发性
*/②构建我们自己的异步抽象
use std::future::Future;
use std::time::Duration;
use trpl::Either;
/// 为任意 future 添加超时控制的异步函数
///
/// # 参数
/// - `future_to_try`: 需要执行的异步操作(泛型,支持任意 Future)
/// - `max_time`: 最大等待时长
///
/// # 返回值
/// - `Ok(F::Output)`: future 在超时前成功完成,返回其输出
/// - `Err(Duration)`: 超时发生,返回设置的最大等待时长
async fn timeout<F: Future>(
future_to_try: F,
max_time: Duration,
) -> Result<F::Output, Duration> {
// 使用 trpl::select 让业务 future 和超时计时器竞争
// select 会按参数顺序轮询,先完成的 future 会被返回
match trpl::select(future_to_try, trpl::sleep(max_time)).await {
// 第一个参数(业务 future)先完成,返回其输出,包装为 Ok
Either::Left(output) => Ok(output),
// 第二个参数(sleep 计时器)先完成,发生超时,返回 Err(max_time)
Either::Right(_) => Err(max_time),
}
}
fn main() {
trpl::block_on(async {
// 示例 17-18:测试超时场景 - 模拟耗时 5 秒的操作,设置 2 秒超时
let slow = async {
trpl::sleep(Duration::from_secs(5)).await;
"Finally finished"
};
match timeout(slow, Duration::from_secs(2)).await {
Ok(message) => println!("Succeeded with '{}'", message),
Err(duration) => {
println!("Failed after {} seconds", duration.as_secs());
}
}
// 补充:测试成功场景 - 1 秒完成的操作,设置 3 秒超时
let fast = async {
trpl::sleep(Duration::from_secs(1)).await;
"Completed quickly"
};
match timeout(fast, Duration::from_secs(3)).await {
Ok(message) => println!("Succeeded with '{}'", message),
Err(duration) => {
println!("Failed after {} seconds", duration.as_secs());
}
}
});
}
/*
--- 核心知识点 ---
1. timeout 函数设计:
- 泛型 `F: Future` 支持任意异步操作,可复用在网络请求、文件IO等场景
- 返回 `Result<F::Output, Duration>`,明确区分“成功完成”和“超时失败”状态
2. trpl::select 的使用:
- `select(future1, future2)` 并发执行两个 future,返回先完成的那个
- 这里用它让业务 future 和 `trpl::sleep` 计时器竞争,实现超时控制
- select 按参数顺序轮询,因此将业务 future 放在第一个参数,避免不公平轮询导致误超时
3. Either 枚举:
- `trpl::Either::Left` 对应第一个参数的结果(业务 future 成功)
- `trpl::Either::Right` 对应第二个参数的结果(计时器先完成,超时)
4. 异步组合:
- 通过 `select` 和 `sleep` 两个基础构件,构建出强大的超时工具
- 可与 `retry` 逻辑组合,实现“带超时的重试请求”等复杂异步模式
*/4. Stream:按顺序出现的 Future
// 引入 `StreamExt` trait,提供 stream 的 `next` 方法(修复编译错误的关键)
use trpl::StreamExt;
fn main() {
trpl::block_on(async {
// ------------------------------
// 示例17-21:从迭代器创建 stream(原始代码,编译报错)
// ------------------------------
// 错误原因:`StreamExt` trait 未被引入,`next` 方法不可见
/*
let values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
let iter = values.iter().map(|n| n * 2);
let mut stream = trpl::stream_from_iter(iter);
// 编译报错:no method named `next` found for struct `tokio_stream::iter::Iter`
while let Some(value) = stream.next().await {
println!("The value was: {value}");
}
*/
// ------------------------------
// 示例17-22:修复后的代码,成功使用迭代器创建 stream
// ------------------------------
let values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
// 1. 创建迭代器,将每个元素翻倍(和同步迭代器用法一致)
let iter = values.iter().map(|n| n * 2);
// 2. 使用 `trpl::stream_from_iter` 将同步迭代器转换为异步 stream
let mut stream = trpl::stream_from_iter(iter);
// 3. 用 `while let` 循环处理 stream 中的元素,和同步迭代器类似,但需要 `await`
// `StreamExt` trait 提供的 `next` 方法返回 Future,需 await;流结束时返回 `None`
while let Some(value) = stream.next().await {
println!("The value was: {value}");
}
/*
--- 核心知识点 ---
1. Stream 概念:
- 迭代器的异步版本,处理随时间推移产生的一系列值(如异步信道消息、网络数据、文件分块)
- 和 Future 密切相关,可与其他 Future 组合(如限流、超时)
2. 迭代器 vs Stream:
| 特性 | 迭代器(Iterator) | Stream |
|------------|--------------------|--------|
| 执行方式 | 同步 | 异步(需 await) |
| 获取下一个 | `next() -> Option<T>` | `next().await -> Option<T>`(需 StreamExt) |
3. 编译错误原因:
- `next` 方法由 `StreamExt` trait 提供,必须引入作用域才能使用
- 其他 trait 如 `futures_util::stream::StreamExt` 也提供类似方法,trpl 封装了简化版本
4. trpl::stream_from_iter:
- 将同步迭代器转换为 Stream,让同步序列能以异步方式处理
- 后续可使用 StreamExt 的其他工具方法(如 filter、map、fold 等,和迭代器类似)
*/
});
}5. 深入理解 async 相关的 trait
①Future trait
use std::pin::Pin;
use std::task::{Context, Poll, RawWaker, RawWakerVTable, Waker};
/// ------------------------------
/// Rust Future Trait 核心定义(异步编程基础)
/// ------------------------------
pub trait Future {
/// 关联类型:Future 最终完成时的输出类型,类似 Iterator 的 Item
type Output;
/// 轮询 Future 状态,由异步运行时调用
///
/// # 参数说明
/// - `self: Pin<&mut Self>`: 固定住的 self 引用,保证 Future 在内存中的位置不变,支持跨 await 点的状态保存
/// - `cx: &mut Context<'_>`: 上下文,包含 Waker,Future 就绪时通过它通知运行时
///
/// # 返回值
/// - `Poll::Ready(Output)`: Future 已完成,返回结果值
/// - `Poll::Pending`: Future 未完成,运行时需稍后再次轮询
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}
/// ------------------------------
/// Poll 枚举:Future 轮询结果的状态
/// ------------------------------
pub enum Poll<T> {
/// Future 已完成,包含输出值
Ready(T),
/// Future 未完成,运行时需稍后重试
Pending,
}
/// ------------------------------
/// 辅助:创建空 Waker(简化示例,实际由运行时提供)
/// ------------------------------
fn noop_waker() -> Waker {
const VTABLE: RawWakerVTable = RawWakerVTable::new(
|_| RawWaker::new(std::ptr::null(), &VTABLE),
|_| {},
|_| {},
|_| {},
);
unsafe { Waker::from_raw(RawWaker::new(std::ptr::null(), &VTABLE)) }
}
fn main() {
// ------------------------------
// 示例:await 的底层编译伪代码(简化版)
// ------------------------------
// 模拟异步函数:获取网页标题(返回 Future<Output = Option<String>>)
async fn page_title(_url: &str) -> Option<String> {
None
}
let url = "https://example.com";
let mut page_title_fut = page_title(url);
// 单次轮询的简化逻辑(实际由编译器/运行时处理)
match unsafe { Pin::new_unchecked(&mut page_title_fut) }
.poll(&mut Context::from_waker(&noop_waker()))
{
Poll::Ready(title) => match title {
Some(t) => println!("The title for {url} was {t}"),
None => println!("{url} had no title"),
},
Poll::Pending => println!("Future pending, need to reschedule"),
}
// 轮询循环伪代码(实际由运行时实现,避免阻塞)
/*
loop {
match unsafe { Pin::new_unchecked(&mut page_title_fut) }
.poll(&mut Context::from_waker(&noop_waker()))
{
Poll::Ready(value) => {
match value {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
break;
}
Poll::Pending => {
// 控制权交还运行时,调度其他任务,稍后重试
}
}
}
*/
// ------------------------------
// 示例:异步信道 recv 的轮询过程
// ------------------------------
// 模拟异步信道接收端(实现 Future trait)
struct Receiver;
impl Future for Receiver {
type Output = Option<String>;
fn poll(self: Pin<&mut Self>, _cx: &mut Context<'_>) -> Poll<Self::Output> {
// 伪实现:信道关闭返回 Ready(None),收到消息返回 Ready(Some(msg)),否则 Pending
Poll::Pending
}
}
let mut rx = Receiver;
match unsafe { Pin::new_unchecked(&mut rx) }
.poll(&mut Context::from_waker(&noop_waker()))
{
Poll::Ready(Some(msg)) => println!("Received message: {msg}"),
Poll::Ready(None) => println!("Channel closed"),
Poll::Pending => println!("Waiting for message..."),
}
}
/*
--- 核心知识点注释 ---
1. Future Trait:
- 异步编程的核心,所有异步操作都实现此 trait
- `poll` 方法由运行时调用,不会阻塞线程,仅检查状态
- `Pin` 保证 Future 内存位置不变,支持跨 await 点的状态保存
- `Context` 携带 Waker,用于 Future 就绪时唤醒运行时
2. Poll 枚举:
- `Poll::Ready(T)`:Future 已完成,返回结果;此时不应再次调用 poll(可能 panic)
- `Poll::Pending`:Future 未完成,运行时需稍后重试,控制权会交还运行时
3. await 底层逻辑:
- 编译器将 `await future` 编译为轮询循环,直到 poll 返回 Ready
- 当 poll 返回 Pending 时,运行时会调度其他任务,避免阻塞
- 运行时负责管理所有 Future 的轮询与调度,实现并发
4. 异步信道 recv:
- `rx.recv()` 返回 Future,本质是轮询其状态
- 消息到达/信道关闭时 poll 返回 Ready,否则返回 Pending,运行时暂停任务等待唤醒
5. 注意事项:
- 大多数 Future 在返回 Ready 后,再次调用 poll 会 panic(除非文档说明支持重复轮询)
- 直接调用 poll 的场景极少,用户通常只需使用 async/await
*/②Pin 类型与 Unpin trait
use std::future::Future;
use std::pin::Pin;
use std::task::{Context, Poll};
use trpl;
// ------------------------------
// 示例17-23:错误代码 - 尝试用 join_all 处理动态集合的 Future
// ------------------------------
fn main() {
trpl::block_on(async {
// 模拟示例17-13中的多生产者信道任务
let (tx, mut rx) = trpl::channel();
let tx1 = tx.clone();
// 发送端Future 1(async move生成的匿名Future,类型唯一)
let tx1_fut = async move {
let vals = vec!["hi", "from", "the", "future"];
for val in vals {
tx1.send(val).unwrap();
trpl::sleep(std::time::Duration::from_millis(500)).await;
}
};
// 接收端Future(async move生成的匿名Future,类型唯一)
let rx_fut = async move {
while let Some(_value) = rx.recv().await {
// 处理消息
}
};
// 发送端Future 2(async move生成的匿名Future,类型唯一)
let tx_fut = async move {
let vals = vec!["more", "messages", "for", "you"];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(std::time::Duration::from_millis(1500)).await;
}
};
// ------------------------------
// 错误写法:用 Box<dyn Future> 存储不同类型的Future,尝试传给 join_all
// ------------------------------
// 编译报错:`dyn Future<Output = ()>` cannot be unpinned
// 原因:async代码块生成的匿名Future默认是!Unpin,而join_all要求元素实现Unpin
/*
let futures: Vec<Box<dyn Future<Output = ()>>> = vec![
Box::new(tx1_fut),
Box::new(rx_fut),
Box::new(tx_fut),
];
trpl::join_all(futures).await;
*/
/*
--- 错误原因解析 ---
1. 不同async代码块生成的Future是不同的匿名enum类型,即使Output相同也不能直接放入Vec
2. 用Box<dyn Future>包装后,类型统一,但dyn Future<Output = ()>未实现Unpin trait
3. join_all要求元素类型必须实现Future + Unpin,因为它会移动这些元素
4. Box<T>只有在T实现Unpin时,才会自动实现Future trait,因此这里Box<dyn Future>不满足约束
*/
});
}
// ------------------------------
// Future Trait 核心定义(异步编程基础)
// ------------------------------
pub trait Future {
/// Future最终完成时的输出类型(类似Iterator的Item)
type Output;
/// 轮询Future状态,由异步运行时调用
///
/// # 参数说明
/// - `self: Pin<&mut Self>`: 固定住的self引用,保证Future在内存中的位置不变
/// (async代码块生成的Future可能包含跨await点的自引用,移动会导致未定义行为)
/// - `cx: &mut Context<'_>`: 上下文,包含Waker,Future就绪时通过它通知运行时
///
/// # 返回值
/// - `Poll::Ready(Output)`: Future已完成,返回结果
/// - `Poll::Pending`: Future未完成,运行时需稍后再次轮询
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}
/*
--- 关键知识点:Pin与Unpin ---
1. Pin的作用:
- 用于包装指针类型(如&mut、Box),限制被指向值的移动
- 解决async Future中自引用的安全问题:自引用结构移动后,内部引用会失效
- Pin本身不是指针,只是给编译器施加约束的工具
2. Unpin trait:
- 标记trait,类型实现Unpin表示可以安全移动
- 编译器会自动为大多数无自引用的类型(如String、Vec、基本类型)实现Unpin
- async代码块生成的Future默认是!Unpin,因为它们可能包含跨await点的自引用
3. 为什么await不需要显式Pin:
- 直接await future时,Rust编译器会自动将其Pin住,无需手动处理
- 但将Future放入集合(如Vec)传给join_all时,需要显式Pin以满足trait约束
4. 修复示例17-23的思路:
- 使用Box::pin或pin!宏将Future固定到堆上,得到Pin<Box<dyn Future<Output = ()>>>
- Pin<Box<dyn Future>>既满足Future trait,又满足Unpin约束(Box是可移动的,Pin只固定内部值)
- 这样就能将不同类型的Future存入Vec并传给join_all
*/
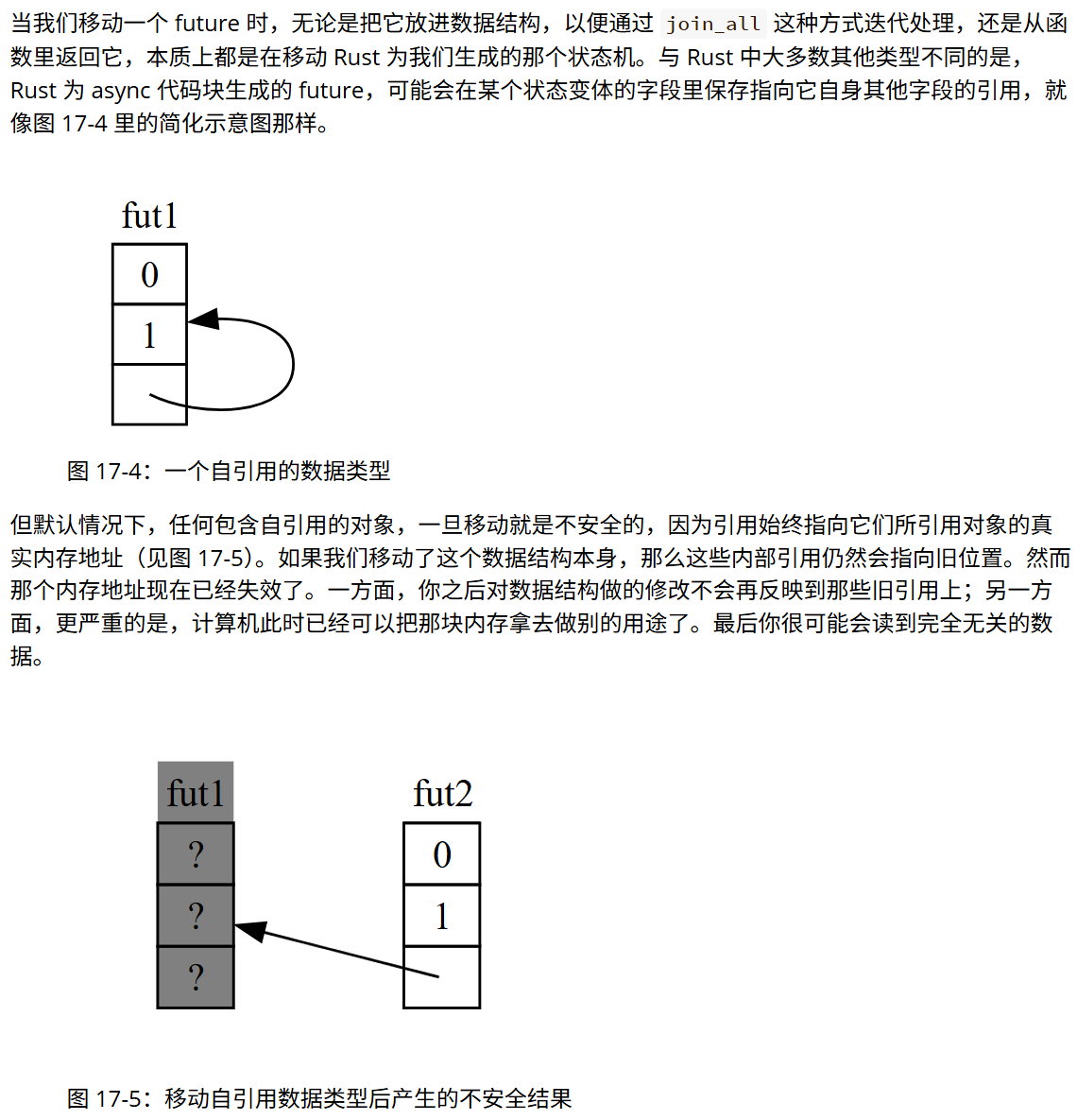
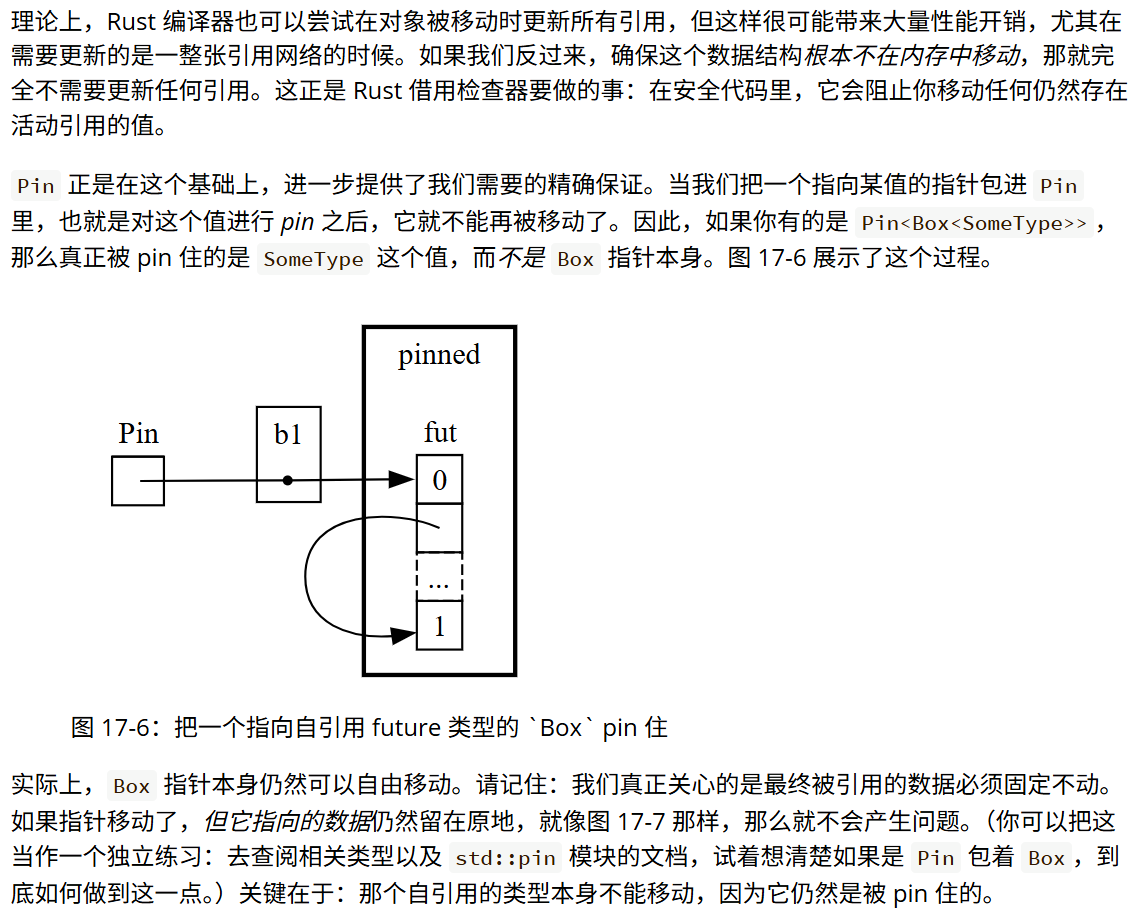
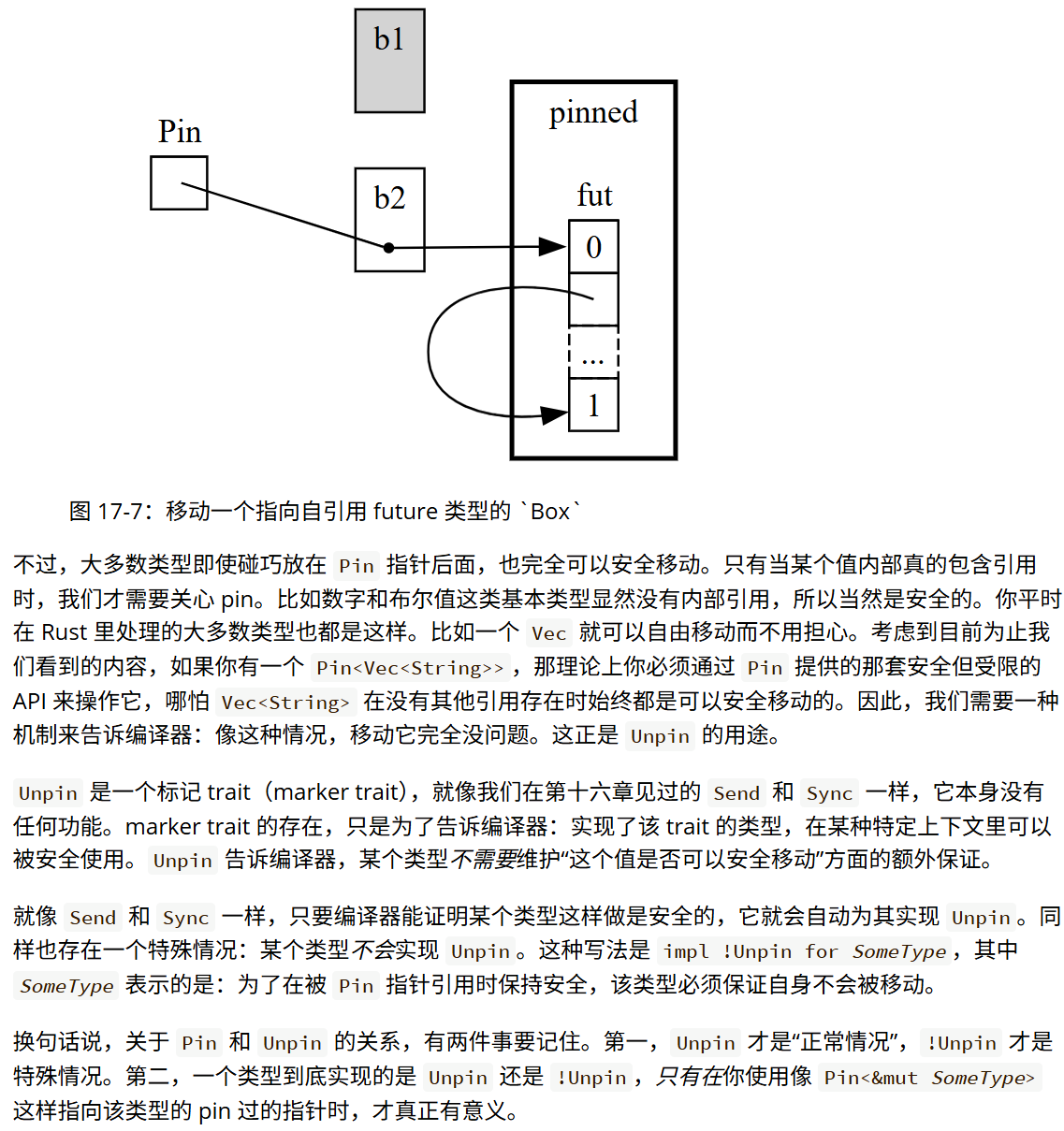
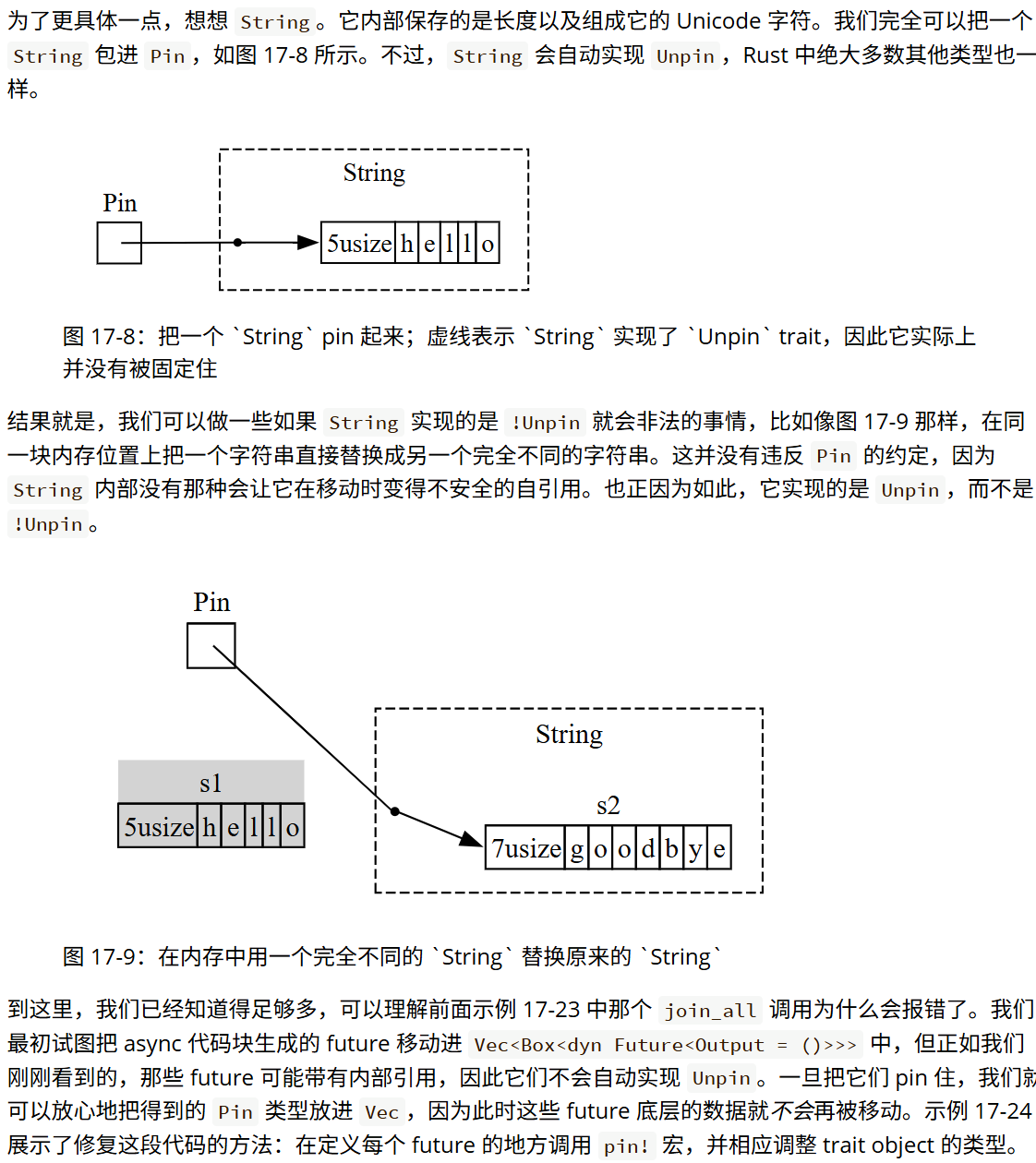

③Stream trait
use std::pin::Pin;
use std::task::{Context, Poll};
// ------------------------------
// Stream Trait:结合Iterator与Future特征的异步迭代器
// ------------------------------
/// 异步迭代器的核心Trait,用于表示“随时间逐渐就绪的一系列元素”
/// 结合了Iterator的“序列”概念和Future的“值就绪”特性
trait Stream {
/// Stream产生的元素类型(类似Iterator::Item)
type Item;
/// 轮询Stream,获取下一个元素
///
/// # 返回值说明
/// - `Poll::Ready(Some(item))`: 下一个元素已就绪,返回该元素
/// - `Poll::Ready(None)`: Stream已结束,没有更多元素
/// - `Poll::Pending`: 元素尚未就绪,运行时稍后会再次轮询
///
/// 类似`Future::poll`的轮询方式,同时结合了`Iterator::next`的序列生成逻辑
fn poll_next(
self: Pin<&mut Self>,
cx: &mut Context<'_>,
) -> Poll<Option<Self::Item>>;
}
// ------------------------------
// StreamExt Trait:Stream的扩展API,提供更便捷的高层方法
// ------------------------------
/// 为Stream提供高层异步API,如`next`方法,让用户无需直接调用`poll_next`
/// 所有实现了Stream的类型,都会自动获得StreamExt的实现
trait StreamExt: Stream {
/// 异步获取Stream的下一个元素(类似Iterator::next的异步版本)
///
/// # 返回值
/// - `Some(Self::Item)`: 下一个元素就绪
/// - `None`: Stream已结束
///
/// # 约束说明
/// `Self: Unpin`:简化实现,大多数无自引用的Stream都满足此约束
async fn next(&mut self) -> Option<Self::Item>
where
Self: Unpin;
// 其他扩展方法(如map、filter、fold等,与Iterator类似)
// ...
}
/*
--- 兼容旧版Rust的StreamExt定义说明 ---
早期不支持“在trait中使用async函数”的Rust版本中,next方法会这样定义:
fn next(&mut self) -> Next<'_, Self>
where
Self: Unpin;
其中`Next<'_, Self>`是一个实现了Future的结构体,显式携带对self的引用生命周期,
确保await时引用有效,其内部逻辑与async fn next完全等价。
*/
/*
--- 核心知识点对比 ---
| 特性/方法 | Iterator | Future | Stream |
|-----------------|-------------------|---------------------|-------------------------|
| 核心关联类型 | Item | Output | Item |
| 获取元素方法 | next() -> Option<Item> | poll() -> Poll<Output> | poll_next() -> Poll<Option<Item>> |
| 执行方式 | 同步(立即返回) | 异步(需await) | 异步(需await,通过poll_next轮询) |
| 元素数量 | 0到多个 | 始终1个Output | 0到多个,随时间逐渐就绪 |
--- Stream与StreamExt的设计逻辑 ---
1. 底层Stream trait:仅定义poll_next方法,保证基础轮询逻辑,兼容不同实现
2. 高层StreamExt trait:提供async next等便捷方法,用户无需手动处理Poll状态
3. 分离设计的好处:社区可在不修改底层Stream trait的情况下,迭代扩展高层API
4. 实际使用中,我们通常直接使用StreamExt的next方法,而非手动调用poll_next
*/6. 结合起来看:Future、任务与线程
Rust 中线程与异步(async)并非二选一,而是常结合使用。
线程是操作系统提供的并发模型,适合 CPU 密集型任务,如大规模并行数据处理;但线程内存开销大,且嵌入式系统可能不支持。
异步模型以任务为单位,由运行时管理,无需每个并发操作独占线程,适合 I/O 密集型任务,如同时处理多来源消息。任务可在线程间迁移,多数多线程运行时采用 “工作窃取” 调度提升性能。
经验法则:CPU 密集型任务优先用线程,I/O 密集型任务优先用异步;实际开发中可结合两者,让各部分发挥所长。
use std::{thread, time::Duration};
fn main() {
// 创建异步信道,获取发送端`tx`和接收端`rx`
// 用于在线程和异步代码块之间传递消息
let (tx, mut rx) = trpl::channel();
// 启动新线程,通过`move`将发送端`tx`的所有权移入线程
// 线程中执行阻塞/CPU密集型任务(如视频编码、批量数据处理)
thread::spawn(move || {
// 循环发送1~10的数字消息
for i in 1..11 {
tx.send(i).unwrap(); // 向信道发送消息
// 线程阻塞1秒,模拟耗时的同步操作(如CPU密集计算)
thread::sleep(Duration::from_secs(1));
}
});
// 用`trpl::block_on`运行异步代码块,处理消息接收
// 异步代码块负责非阻塞的消息监听,适合I/O/UI响应场景
trpl::block_on(async {
// 异步循环接收信道消息:`rx.recv().await`会等待下一条消息就绪
// 当信道关闭(发送端被drop)时,循环终止
while let Some(message) = rx.recv().await {
println!("{message}");
}
});
}
/*
--- 代码场景说明 ---
这是线程与async结合的典型示例:
1. 线程负责执行阻塞/CPU密集型工作(如视频编码、批量计算),避免阻塞异步运行时
2. 异步信道作为桥梁,线程完成任务后通过它通知异步代码(如更新UI、处理结果)
3. 异步代码块通过`await`非阻塞地等待消息,保持事件循环的响应性
现实中这类场景很常见:比如后台线程处理视频编码,完成后通过异步信道通知UI更新进度。
*/十九. 面向对象特性
1. 面向对象语言特性
关于 “一门语言需要哪些特性才算面向对象编程语言”,编程社区始终没有共识。Rust 受多种编程范式影响,其中也包括面向对象编程。
通常认为,面向对象编程语言的核心特性包括:命名对象、封装和继承。下面将逐一分析这些特性的含义,以及 Rust 对它们的支持情况。
①对象包含数据和行为
《设计模式:可复用面向对象软件的基础》(由 “设计模式四人帮” Erich Gamma、Richard Helm、Ralph Johnson 和 John Vlissides 所著)中,对面向对象编程给出了如下定义:面向对象的程序由对象组成,对象包装了数据和操作这些数据的流程(即方法或操作)。
基于这一定义,Rust 是支持面向对象编程的:结构体和枚举可以包含数据,而
impl块为它们提供了对应的方法。尽管 Rust 中没有直接称为 “对象” 的语法,但带方法的结构体 / 枚举完全满足四人帮定义中对象的功能要求。
②封装实现细节
// 示例17-1:维护整数列表及平均值的结构体
// 通过封装实现数据隐藏与内部状态同步
pub struct AveragedCollection {
// 私有字段:存储整数列表,外部无法直接访问
list: Vec<i32>,
// 私有字段:缓存列表的平均值,外部无法直接访问
average: f64,
}
// 示例17-2:为结构体实现公共接口,控制数据访问与修改
impl AveragedCollection {
/// 向集合中添加元素,自动更新平均值缓存
pub fn add(&mut self, value: i32) {
self.list.push(value);
self.update_average(); // 调用私有方法同步更新平均值
}
/// 从集合中移除最后一个元素,自动更新平均值缓存
pub fn remove(&mut self) -> Option<i32> {
let result = self.list.pop();
match result {
Some(value) => {
self.update_average(); // 调用私有方法同步更新平均值
Some(value)
}
None => None,
}
}
/// 获取当前集合的平均值(只读接口)
pub fn average(&self) -> f64 {
self.average // 直接返回缓存值,无需重复计算
}
/// 私有方法:重新计算并更新平均值缓存
/// 仅内部方法可调用,外部无法访问
fn update_average(&mut self) {
let total: i32 = self.list.iter().sum();
self.average = total as f64 / self.list.len() as f64;
}
}
/*
--- 封装的核心作用 ---
1. 数据隐藏:list和average字段为私有,外部无法直接修改,避免数据不一致
2. 状态同步:所有修改操作(add/remove)都会自动调用update_average,保证平均值始终正确
3. 接口稳定:即使内部实现(如list改用HashSet),只要公共方法签名不变,外部代码无需修改
4. 读写分离:average仅通过average()方法只读,外部无法直接修改,保证数据一致性
--- Rust中封装的实现方式 ---
- 默认所有成员私有,通过pub关键字标记公开接口
- 私有字段+公共方法的组合,完全符合面向对象中封装的定义
- 内部实现细节对外部透明,修改内部逻辑不影响调用方代码
*/③作为类系统和代码共享机制的继承
继承机制允许一个对象复用另一个对象的数据与行为,避免重复定义代码。Rust 没有传统面向对象语言中的继承语法,但提供了替代方案:
代码复用:通过 trait 的默认方法实现代码共享。任何实现该 trait 的类型都可自动获得默认方法,也可按需重写,类似子类对父类方法的继承与覆盖。
多态支持:Rust 用 trait 对象实现多态,而非继承。trait 对象允许不同类型在运行时相互替换,满足 “同一接口,不同实现” 的多态需求。
传统继承存在过度共享代码、限制灵活性的问题,Rust 选择用 trait 与 trait 对象替代继承,兼顾了代码复用与多态能力,同时避免了继承的弊端。
2. 使用trait对象存储不同类型的值
动态数组只能存储同一类型元素,可通过枚举(如
SpreadsheetCell)在编译期固定类型,实现多类型存储。但当需要支持用户扩展类型时,该方案不再适用。以 GUI 库为例,它需要存储不同类型的组件(如
Button、TextField、用户自定义的Image、SelectBox等),并对所有组件调用draw方法,无需关心具体实现细节。在支持继承的语言中,可定义
Component基类并实现draw方法,其他组件继承自该类,框架以Component实例的方式统一处理。Rust 没有继承,因此需要通过其他方式实现该功能,以支持用户扩展自定义类型。
①为共有行为定义一个trait
// src/lib.rs
// 定义Draw trait,包含所有GUI组件都需实现的draw方法
pub trait Draw {
fn draw(&self);
}
// Screen结构体,持有一个动态数组,存储实现了Draw trait的trait对象
pub struct Screen {
// 使用Box<dyn Draw>作为元素类型,允许存储不同类型的组件
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
// run方法:遍历components,调用每个组件的draw方法
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
/*
// 使用泛型参数与trait约束定义的Screen结构体(与trait对象方案对比)
// 该方案仅支持存储单一类型的组件(同质集合),而trait对象方案支持混合类型
pub struct Screen<T: Draw> {
pub components: Vec<T>,
}
impl<T> Screen<T>
where
T: Draw,
{
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
*/
/*
--- 核心知识点 ---
1. trait对象(dyn Draw):
- 通过`Box<dyn Draw>`创建,指向实现了Draw trait的类型实例
- 支持在Vec中存储不同类型的组件(如Button、TextField、用户自定义组件)
- 运行时动态分发draw方法,无需在编译时知晓所有具体类型
2. 泛型与trait约束:
- 编译时单态化,生成对应具体类型的代码,性能开销低
- 但Vec<T>只能存储同一类型的组件,无法实现混合类型集合
3. trait对象的优势:
- 支持用户扩展自定义组件,只要实现Draw trait即可加入Screen
- 单个Screen实例可同时持有多种不同类型的GUI组件,满足GUI场景需求
*/②实现trait
// src/lib.rs - GUI库定义
pub trait Draw {
/// 绘制组件的方法,所有GUI组件都需实现
fn draw(&self);
}
pub struct Screen {
// 存储实现了Draw trait的组件(trait对象)
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
/// 遍历所有组件并调用其draw方法
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
/// 按钮组件:实现Draw trait
pub struct Button {
pub width: u32,
pub height: u32,
pub label: String,
}
impl Draw for Button {
fn draw(&self) {
// 实际绘制按钮的代码(此处省略实现细节)
}
}
// src/main.rs - 用户使用GUI库的代码
use gui::{Draw, Button, Screen};
/// 用户自定义的下拉选择框组件
struct SelectBox {
width: u32,
height: u32,
options: Vec<String>,
}
impl Draw for SelectBox {
fn draw(&self) {
// 实际绘制选择框的代码(此处省略实现细节)
}
}
fn main() {
// 创建Screen实例,添加不同类型的组件
let screen = Screen {
components: vec![
// 添加用户自定义的SelectBox组件
Box::new(SelectBox {
width: 75,
height: 10,
options: vec![
String::from("Yes"),
String::from("Maybe"),
String::from("No"),
],
}),
// 添加库中定义的Button组件
Box::new(Button {
width: 50,
height: 10,
label: String::from("OK"),
}),
],
};
// 运行Screen,依次调用所有组件的draw方法
screen.run();
/*
// 错误示例:String未实现Draw trait,无法加入Screen
// 编译时会报错:`String: Draw` is not satisfied
let invalid_screen = Screen {
components: vec![Box::new(String::from("Hi"))],
};
invalid_screen.run();
*/
}
/*
--- 核心知识点 ---
1. trait对象实现多态:
- 通过`Box<dyn Draw>`存储不同类型的组件,只要它们实现了Draw trait
- Screen无需关心组件的具体类型,只需调用draw方法,类似"鸭子类型"
2. 编译期安全检查:
- Rust会在编译时验证组件是否实现了Draw trait,避免运行时错误
- 尝试添加未实现Draw的类型(如String)会直接编译失败
3. 库的扩展性:
- 用户可以自定义新组件(如SelectBox),只要实现Draw trait就能被Screen接收
- 库代码无需修改即可支持用户扩展的组件,实现了开闭原则
*/③trait对象会执行动态派发
泛型 trait 约束通过单态化生成具体类型的代码,采用静态派发,编译器在编译期即可确定调用的方法,性能开销低。
Trait 对象采用动态派发:编译器无法在编译期确定所有可能的具体类型,因此需要在运行时通过 trait 对象内部的指针定位方法调用,会产生额外的运行时开销,且可能阻止编译器内联优化。
动态派发的优势是灵活性高,支持混合存储不同类型的组件,实现类似示例中的 GUI 场景;静态派发性能更优,但仅支持单一类型集合。实际开发中可根据项目对性能与灵活性的需求进行选择。
二十. 模式与匹配
模式是 Rust 中用于匹配类型结构的特殊语法,可与
match表达式等工具配合控制程序流程。模式通常由字面量、解构的数组 / 枚举 / 结构体 / 元组、变量、通配符、占位符等组成,示例包括x、(a, 3)、Some(Color::Red)等。模式描述了数据的形状,通过与值对比匹配,成功时可在后续代码中使用模式命名的标识符,失败时则跳过对应代码。
本章将讨论模式的使用场景、可失败与不可失败模式的区别,以及各类模式语法,帮助你通过模式匹配更清晰地表达程序逻辑。
1. 使用模式的场合
①match分支
fn main() {
// match表达式基础语法
/*
match 待匹配的值 {
模式1 => 匹配成功时执行的表达式,
模式2 => 匹配成功时执行的表达式,
模式3 => 匹配成功时执行的表达式,
}
*/
// 示例:匹配Option<i32>类型的值x
let x: Option<i32> = Some(5);
// match表达式必须穷尽所有可能性,模式None和Some(i)覆盖了Option的所有情况
let result = match x {
// 模式1:匹配None变体
None => None,
// 模式2:匹配Some变体,并解构其中的值i
Some(i) => Some(i + 1),
};
// 匹配结果:Some(6)
println!("{:?}", result);
/*
核心知识点:
1. match分支的模式:箭头左侧的None和Some(i)就是模式,分别匹配Option的不同变体
2. 穷尽性要求:match必须覆盖值的所有可能情况,否则会编译报错
3. 全匹配模式:
- 变量名模式(如last):匹配所有剩余值,并绑定到变量上,永远不会失败
- _模式:匹配所有值,但不绑定到变量,常用于忽略未处理的情况
*/
// 使用_模式的match示例:只处理特定值,忽略其他所有情况
let num = 7;
match num {
1 => println!("匹配到1"),
5 => println!("匹配到5"),
_ => println!("匹配到其他值"), // 覆盖所有未指定的情况,满足穷尽性要求
}
}②if let条件表达式
fn main() {
// 示例:混合使用 if let、else if、else if let 和 else
let favorite_color: Option<&str> = None;
let is_tuesday = false;
let age: Result<u8, _> = "34".parse();
// 逻辑:按优先级判断背景色
// 1. 优先使用用户指定的颜色
if let Some(color) = favorite_color {
println!("Using your favorite, {color}, as the background");
}
// 2. 周二固定使用绿色
else if is_tuesday {
println!("Tuesday is green day!");
}
// 3. 根据解析出的年龄判断颜色(Ok分支)
else if let Ok(age) = age {
// 注意:age变量会覆盖外部同名变量,作用域仅限当前分支内
if age > 30 {
println!("Using purple as the background color");
} else {
println!("Using orange as the background color");
}
}
// 4. 所有条件不满足时的默认分支
else {
println!("Using blue as the background color");
}
/*
核心知识点:
1. if let 语法:
- 本质是只匹配单个分支的match表达式,支持else/else if分支
- 适合处理Option/Result类型的单个匹配场景,语法比match更简洁
2. 变量覆盖:
- if let Ok(age) = age 会在分支内创建新的age变量,覆盖外部同名变量
- 被覆盖的变量仅在当前分支的作用域内有效,因此无法将 age > 30 合并到 if let 条件中
3. 与match的区别:
- if let 不强制穷尽所有可能性,编译器不会警告遗漏分支
- match 强制穷尽所有情况,能避免逻辑缺陷,但语法灵活性不如if let混合分支
*/
}③while let循环
fn main() {
// 创建一个动态数组作为栈
let mut stack = Vec::new();
// 入栈:依次压入1、2、3
stack.push(1);
stack.push(2);
stack.push(3);
// while let循环:只要stack.pop()返回Some变体,就执行循环体
// pop()会取出栈顶元素并包装在Some中,栈为空时返回None,循环结束
while let Some(top) = stack.pop() {
// 打印弹出的元素,顺序与入栈相反:3、2、1
println!("{}", top);
}
/*
核心知识点:
1. while let语法:
- 与if let类似,反复进行模式匹配,直到匹配失败
- 常用于遍历Option/Result类型的序列,或处理栈、队列等数据结构
2. 栈的处理逻辑:
- stack.pop()每次返回Some(value)时,循环体被执行,打印并消费栈顶元素
- 栈为空时pop()返回None,匹配失败,循环终止
*/
}④for 循环
fn main() {
// 创建一个字符类型的动态数组
let v = vec!['a', 'b', 'c'];
// 使用 enumerate() 生成包含索引和值的元组
// 模式 (index, value) 会解构每次迭代的元组,分别赋值给 index 和 value
for (index, value) in v.iter().enumerate() {
// 打印每个元素及其索引
println!("{value} is at index {index}");
}
/*
输出结果:
a is at index 0
b is at index 1
c is at index 2
核心知识点:
1. for循环中的模式:for关键字后的值(如`(index, value)`)是一个模式,用于匹配迭代器的元素
2. enumerate()适配器:会为迭代器的每个元素生成一个元组,格式为`(索引, 元素值)`
3. 解构赋值:模式`(index, value)`会将元组的索引和元素值分别绑定到index和value变量上,无需手动处理索引
*/
}⑤let语句
fn main() {
// 1. 最朴素的let模式:单个变量名模式,匹配任何值并绑定到变量x
let x = 5;
println!("x = {}", x);
// 2. 使用模式解构元组:一次性创建多个变量
let (x, y, z) = (1, 2, 3);
println!("x = {}, y = {}, z = {}", x, y, z);
// 3. 错误示例:模式中元素数量与元组不匹配,编译报错
// let (x, y) = (1, 2, 3);
// 错误提示:expected a tuple with 3 elements, found one with 2 elements
// 4. 修正方式:使用_忽略不需要的元素,保持数量匹配
let (a, _, b) = (10, 20, 30);
println!("a = {}, b = {}", a, b);
/*
核心知识点:
1. let语句本质:let 模式 = 表达式; 变量名本身就是一种模式
2. 元组解构:模式(x, y, z)会匹配元组(1,2,3),并将元素分别绑定到变量
3. 模式匹配规则:模式元素数量必须与表达式的结构完全匹配,否则编译报错
4. 忽略模式:使用_可以忽略元组中不需要的元素,避免因数量不匹配导致的错误
*/
}⑥函数参数
// 示例18-6:函数参数中的模式(最朴素的变量名模式)
fn foo(x: i32) {
// 函数体:参数x本身就是一个模式,会匹配传入的任何i32值
println!("Received x: {}", x);
}
// 示例18-7:在函数参数中使用模式解构元组
fn print_coordinates(&(x, y): &(i32, i32)) {
// 模式&(x, y)会匹配传入的元组引用,解构出x和y的值
println!("Current location: ({}, {})", x, y);
}
fn main() {
// 调用foo函数,传入i32值,参数x模式匹配成功
foo(42);
// 创建元组并传递给print_coordinates函数
let point = (3, 5);
print_coordinates(&point);
// 闭包参数中的模式示例(与函数类似)
let closure = |&(a, b): &(i32, i32)| {
println!("Closure received: ({}, {})", a, b);
};
closure(&point);
}
/*
核心知识点:
1. 函数参数本质是模式:
- 像 `fn foo(x: i32)` 中的 `x` 就是一个模式,会匹配任何i32值
- 与let语句类似,模式会将匹配到的值绑定到变量上
2. 元组解构模式:
- `print_coordinates(&(x, y): &(i32, i32))` 中的 `&(x, y)` 是模式
- 它会匹配元组引用,解构出x和y的值,无需在函数内手动解引用
3. 闭包参数中的模式:
- 闭包参数列表同样支持模式,与函数参数模式用法一致
- 例如 `|&(a, b): &(i32, i32)|` 同样能解构元组引用
4. 模式的可失败性:
- 函数/闭包参数中的模式是**不可失败**的,必须能匹配所有传入的值
- 例如 `&(x, y)` 模式必须匹配所有&(i32, i32)类型的值,否则编译报错
*/2. 可失败性:模式是否会匹配失败
模式分为 不可失败(irrefutable)和可失败(refutable) 两种:
不可失败模式:能匹配任何传入的值,例如
let x = 5;中的x,它可以匹配表达式右侧所有可能的返回值。可失败模式:可能因特定值匹配失败,例如
if let Some(x) = a_value中的Some(x),若a_value为None,则模式匹配失败。函数参数、
let语句、for循环:只接收不可失败模式,因为程序无法在值不匹配时执行有意义的操作。if let和while let:可接收可失败或不可失败模式,但使用不可失败模式时编译器会警告,因为这类语句本应处理可能失败的场景。
fn main() {
// 示例1:在let中使用可失败模式(编译错误)
// let Some(x) = some_option_value;
// 错误原因:let语句只接收不可失败模式,Some(x)无法匹配None值
// 修正方案:使用if let处理可失败模式
let some_option_value: Option<i32> = Some(42);
if let Some(x) = some_option_value {
println!("{}", x);
}
// 示例2:在if let中使用不可失败模式(编译警告)
// if let x = 5 {
// println!("{}", x);
// }
// 警告原因:模式x总是匹配,if let失去意义,应直接用let
// match分支的模式要求:
// 1. 除最后分支外,其他分支必须使用可失败模式
// 2. 最后分支使用不可失败模式(覆盖剩余所有情况)
let value: Option<i32> = Some(10);
match value {
Some(0) => println!("Zero"),
Some(x) if x > 0 => println!("Positive: {}", x),
None => println!("None"), // 最后分支:不可失败模式,匹配所有剩余情况
}
}3. 模式语法
①匹配字面量
fn main() {
let x = 1;
// 使用字面量模式匹配
match x {
1 => println!("one"), // 匹配值为1的情况
2 => println!("two"), // 匹配值为2的情况
3 => println!("three"), // 匹配值为3的情况
_ => println!("anything"), // 匹配其他所有值
}
}②匹配命名变量
fn main() {
// 外部作用域的变量
let x = Some(5);
let y = 10;
match x {
// 分支1:匹配 Some(50),当前x是Some(5),不匹配
Some(50) => println!("Got 50"),
// 分支2:匹配 Some(y),这里的y是**新变量**,会覆盖外部的同名变量
// 新的y绑定到x中Some的值(即5),覆盖外部的y=10
Some(y) => println!("Matched, y = {y}"),
// 分支3:匹配所有其他情况,不引入新变量,使用外部作用域的x
_ => println!("Default case, x = {:?}", x),
}
// match结束,内部作用域的y被销毁,外部的y=10恢复
println!("at the end: x = {:?}, y = {y}", x);
}
/*
输出结果:
Matched, y = 5
at the end: x = Some(5), y = 10
核心知识点:
1. match中的变量覆盖:match分支的模式会创建新的作用域,内部变量会覆盖外部同名变量
2. 变量作用域:match结束后,内部变量失效,外部变量恢复
3. 匹配守卫:若要在match中比较外部变量的值,需要使用匹配守卫(后续章节会介绍)
*/③多重模式
fn main() {
let x = 1;
// 使用 | 表示“或”模式,匹配多个值中的任意一个
match x {
// 匹配1或2,只要x的值是其中之一,就执行分支代码
1 | 2 => println!("one or two"),
3 => println!("three"),
// 匹配所有其他值
_ => println!("anything"),
}
}④使用“..=”匹配区间值
fn main() {
仅允许以下两种定义区间,rust可以在编译时确保区间非空
// 示例1:使用..=匹配数值闭区间
let x = 5;
match x {
// 匹配1到5(含两端)的所有值,比用|运算符更简洁
1..=5 => println!("one through five"),
_ => println!("something else"),
}
// 示例2:使用..=匹配字符闭区间
let c = 'c';
match c {
// 匹配'a'到'j'(含两端)的所有ASCII字符
'a'..='j' => println!("early ASCII letter"),
// 匹配'k'到'z'(含两端)的所有ASCII字符
'k'..='z' => println!("late ASCII letter"),
_ => println!("something else"),
}
}⑤通过解构分解值
结构结构体
// 定义Point结构体,包含x和y字段
struct Point {
x: i32,
y: i32,
}
fn main() {
// 示例1:使用结构体模式解构字段(自定义变量名)
let p = Point { x: 0, y: 7 };
let Point { x: a, y: b } = p;
assert_eq!(0, a);
assert_eq!(7, b);
// 示例2:使用字段简写解构结构体(变量名与字段名相同)
let Point { x, y } = p;
assert_eq!(0, x);
assert_eq!(7, y);
// 示例3:在match中使用结构体模式匹配,结合字面量和变量
let p = Point { x: 0, y: 7 };
match p {
// 匹配y=0的点(x轴上的点),创建变量x
Point { x, y: 0 } => println!("On the x axis at {x}"),
// 匹配x=0的点(y轴上的点),创建变量y
Point { x: 0, y } => println!("On the y axis at {y}"),
// 匹配其他所有点,同时创建变量x和y
Point { x, y } => println!("On neither axis: ({x}, {y})"),
}
}解构枚举
// 定义包含不同类型数据的枚举
enum Message {
Quit, // 无数据的变体
Move { x: i32, y: i32 }, // 结构体形式的变体
Write(String), // 元组形式(单元素)的变体
ChangeColor(i32, i32, i32),// 元组形式(多元素)的变体
}
fn main() {
// 创建枚举实例
let msg = Message::ChangeColor(0, 160, 255);
// 使用match解构不同类型的枚举变体
match msg {
// 匹配无数据的变体,模式仅需变体名
Message::Quit => {
println!("The Quit variant has no data to destructure.");
}
// 匹配结构体形式的变体,使用与结构体解构相同的语法
Message::Move { x, y } => {
println!("Move in the x dir {x}, in the y dir {y}");
}
// 匹配单元素元组形式的变体,模式需包含变量接收数据
Message::Write(text) => {
println!("Text message: {text}");
}
// 匹配多元素元组形式的变体,模式变量数量需与元素数量一致
Message::ChangeColor(r, g, b) => {
println!("Change color to red {r}, green {g}, and blue {b}");
}
}
}解构嵌套的结构体和枚举
// 定义颜色空间枚举:支持RGB和HSV两种表示方式
enum Color {
Rgb(i32, i32, i32),
Hsv(i32, i32, i32),
}
// 定义消息枚举,其中ChangeColor变体包含嵌套的Color枚举
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(Color), // 嵌套的枚举类型
}
fn main() {
// 创建嵌套枚举实例:Message::ChangeColor包含Color::Hsv变体
let msg = Message::ChangeColor(Color::Hsv(0, 160, 255));
// 使用match表达式匹配嵌套枚举,同时解构外层和内层枚举
match msg {
// 匹配外层Message::ChangeColor,且内层为Color::Rgb的情况
Message::ChangeColor(Color::Rgb(r, g, b)) => {
println!("Change color to red {r}, green {g}, and blue {b}");
}
// 匹配外层Message::ChangeColor,且内层为Color::Hsv的情况
Message::ChangeColor(Color::Hsv(h, s, v)) => {
println!("Change color to hue {h}, saturation {s}, value {v}");
}
// 匹配其他所有情况(Quit、Move、Write变体)
_ => (),
}
}结构结构体和元组
// 定义结构体Point,包含x和y字段
#[derive(Debug)]
struct Point {
x: i32,
y: i32,
}
fn main() {
// 复杂嵌套解构示例:元组中嵌套元组和结构体
let ((feet, inches), Point { x, y }) = ((3, 10), Point { x: 3, y: -10 });
// 解构后变量的值:
println!("feet: {}", feet); // 3
println!("inches: {}", inches); // 10
println!("x: {}", x); // 3
println!("y: {}", y); // -10
/*
核心知识点:
1. 模式可以嵌套使用,支持同时解构元组、结构体等复杂组合类型
2. 嵌套解构的模式需要与值的结构完全匹配,才能正确分解所有元素
3. 解构后可以直接使用分解出的变量,无需额外访问原始值的字段或元素
*/
}4. 忽略模式中的值
①使用"_"忽略整个值
// 使用下划线 _ 忽略不需要的函数参数
fn foo(_: i32, y: i32) {
// 第一个参数被下划线模式忽略,不绑定变量,也不会产生“未使用变量”警告
println!("This code only uses the y parameter: {}", y);
}
fn main() {
// 调用函数时,第一个参数的值 3 会被模式忽略
foo(3, 4);
}②使用嵌套的"_"忽略值的某些部分
fn main() {
// ------------------- 示例1:匹配 Option 并忽略 Some 内部值 -------------------
let mut setting_value = Some(5);
let new_setting_value = Some(10);
match (setting_value, new_setting_value) {
// 两个值都是 Some,但不关心内部具体数值,只匹配 Some 变体本身
(Some(_), Some(_)) => {
println!("Can't overwrite an existing customized value");
}
// 匹配所有其他情况(任意一个是 None 或其他变体)
_ => {
setting_value = new_setting_value;
}
}
println!("setting is {:?}", setting_value);
// ------------------- 示例2:匹配元组并忽略部分元素 -------------------
let numbers = (2, 4, 8, 16, 32);
match numbers {
// 解构元组,用 _ 忽略不需要的第2个和第4个元素
(first, _, third, _, fifth) => {
println!("Some numbers: {}, {}, {}", first, third, fifth);
}
}
}③通过以“_”开头的名称来忽略未使用的变量
fn main() {
// 示例1:用下划线开头的变量避免未使用警告
let _x = 5; // 变量名以下划线开头,不触发“未使用变量”警告
let y = 10; // 普通变量名,未使用会触发警告
// 示例2:下划线开头的变量会绑定值,转移所有权(会报错)
let s = Some(String::from("Hello!"));
// if let Some(_s) = s { // _s会绑定s的值,String所有权被转移
// println!("found a string");
// }
// println!("{:?}", s); // 错误:s的所有权已被转移,无法再使用
// 示例3:单独使用下划线不绑定值,不转移所有权(可正常运行)
let s = Some(String::from("Hello!"));
if let Some(_) = s { // _ 不会绑定s的值,String所有权不会被转移
println!("found a string");
}
println!("{:?}", s); // 可以正常使用s,所有权未被转移
}④使用“..”忽略值的剩余部分
// 定义三维坐标结构体
struct Point {
x: i32,
y: i32,
z: i32,
}
fn main() {
// ------------------- 示例1:结构体中使用..忽略多个字段 -------------------
let origin = Point { x: 0, y: 0, z: 0 };
match origin {
// 只匹配x字段,使用..忽略y和z字段
Point { x, .. } => println!("x is {}", x),
}
// ------------------- 示例2:元组中使用..忽略中间值 -------------------
let numbers = (2, 4, 8, 16, 32);
match numbers {
// 匹配第一个和最后一个值,用..忽略中间所有值
(first, .., last) => {
println!("Some numbers: {}, {}", first, last);
}
}
// ------------------- 示例3:元组中错误使用..(编译失败) -------------------
// let numbers = (2, 4, 8, 16, 32);
// match numbers {
// // 错误:..在元组中使用超过一次,产生歧义
// (.., second, ..) => {
// println!("Some numbers: {}", second);
// }
// }
}5. 使用匹配守卫添加额外条件
fn main() {
// ------------------- 示例1:匹配守卫(match guard)使用场景1:过滤偶数 -------------------
let num = Some(4);
match num {
// 匹配 Some(x) 且 x 是偶数(匹配守卫 if x % 2 == 0)
Some(x) if x % 2 == 0 => println!("The number {} is even", x),
// 匹配 Some(x) 且 x 是奇数(无额外守卫)
Some(x) => println!("The number {} is odd", x),
// 匹配 None
None => (),
}
// ------------------- 示例2:匹配守卫解决变量覆盖问题 -------------------
let x = Some(5);
let y = 10;
match x {
// 匹配 Some(50),直接字面量匹配
Some(50) => println!("Got 50"),
// 匹配 Some(n),同时使用匹配守卫比较 n 和外部变量 y
Some(n) if n == y => println!("Matched, n = {}", n),
// 匹配其他情况
_ => println!("Default case, x = {:?}", x),
}
println!("at the end: x = {:?}, y = {}", x, y);
// ------------------- 示例3:匹配守卫与多重模式(|)组合 -------------------
let x = 4;
let y = false;
match x {
// 匹配 4、5、6 且 y 为 true(匹配守卫作用于所有模式)
4 | 5 | 6 if y => println!("yes"),
// 匹配其他情况
_ => println!("no"),
}
}6. @绑定
// 定义包含id字段的枚举
enum Message {
Hello { id: i32 },
}
fn main() {
// 创建枚举实例
let msg = Message::Hello { id: 5 };
match msg {
// 使用@运算符:匹配id在3..=7区间,并将值绑定到id_variable变量
Message::Hello {
id: id_variable @ 3..=7,
} => println!("Found an id in range: {}", id_variable),
// 匹配id在10..=12区间,但不绑定值到变量(后续无法使用)
Message::Hello { id: 10..=12 } => {
println!("Found an id in another range")
}
// 匹配其他所有id值,使用结构体字段简写语法绑定id到变量
Message::Hello { id } => println!("Some other id: {}", id),
}
}二十一. 高级特性
1. 不安全rust
到目前为止,我们讨论的代码都有编译期强制的内存安全保障。但 Rust 内部存在不安全 Rust(Unsafe Rust),它和常规 Rust 语法相同,但提供了额外的 “超能力”,不强制实施内存安全规则。
不安全 Rust 的存在原因:
静态分析的保守性:编译器为了避免接受非法代码,会拒绝部分合法但无法被验证安全的程序。此时可以用不安全代码告知编译器 “这段代码由我自行保证安全”,但开发者需要为使用不当(如空指针解引用)导致的内存问题负责。
底层硬件与系统编程需求:底层计算机硬件本身存在不安全特性,若 Rust 完全禁止不安全操作,部分底层任务(如直接与操作系统交互、编写操作系统)将无法完成。作为系统语言,Rust 需要支持这类场景。
①不安全超能力
在 Rust 中,使用
unsafe关键字可以标记代码块,进入不安全模式,执行安全 Rust 不允许的 5 种 “不安全超能力” 操作:解引用裸指针
调用不安全的函数或方法
访问或修改可变静态变量
实现不安全 trait
访问联合体中的字段
-
unsafe不会关闭 Rust 的常规安全检查(如借用检查器依然有效),它仅允许访问上述 5 种特性,编译器不再为这些操作提供内存安全保障。unsafe本身不代表代码一定危险,只是将内存安全的责任转移给了程序员,需要手动确保代码合法访问内存。所有不安全操作被约束在
unsafe块中,便于内存错误的定位。应尽量避免直接使用unsafe,推荐将其封装在安全的 API 抽象中,防止不安全代码泄漏。
②解引用裸指针
在 Rust 中,裸指针(raw pointer)是类似引用的指针类型,分为不可变裸指针
*const T和可变裸指针*mut T,其中星号是类型的一部分,而非解引用运算符。裸指针与引用、智能指针的区别:
可忽略借用规则,允许同一地址同时存在可变和不可变指针,或多个可变指针
不保证指向有效内存地址
允许为空
无自动清理机制
使用裸指针的目的:通过放弃部分安全保障,换取更高性能,或实现与其他语言、硬件的交互(这些场景中 Rust 的安全保障本身不适用)。
fn main() {
// ------------------- 示例1:从引用创建裸指针(无需unsafe) -------------------
let mut num = 5;
// 不可变裸指针:从不可变引用转换
let r1 = &num as *const i32;
// 可变裸指针:从可变引用转换
let r2 = &mut num as *mut i32;
// ------------------- 示例2:创建指向任意地址的裸指针(不安全) -------------------
// 直接从内存地址创建裸指针,无法保证有效性,仅为演示
let address = 0x012345usize;
let r = address as *const i32;
// ------------------- 示例3:在unsafe块中解引用裸指针 -------------------
unsafe {
// 解引用裸指针必须在unsafe块中进行
println!("r1 is: {}", *r1);
println!("r2 is: {}", *r2);
}
/*
关键说明:
1. 创建裸指针无需unsafe,但解引用必须在unsafe块中,因为无法保证内存安全
2. 裸指针可同时存在指向同一地址的可变和不可变指针,会绕过Rust借用规则,存在数据竞争风险
3. 裸指针的主要用途:与C语言交互、构建借用检查器无法理解的安全抽象
*/
}③调用不安全的函数或方法
介绍
// 定义不安全函数,需用 unsafe 标记
unsafe fn dangerous() {
// 函数体内本身就是 unsafe 上下文,可直接执行其他不安全操作
println!("这是一个不安全函数");
}
fn main() {
// 必须在 unsafe 代码块中调用不安全函数
unsafe {
dangerous();
}
// 错误示例:在 unsafe 代码块外调用不安全函数,编译会报错
// dangerous(); // 错误: call to unsafe function is unsafe and requires unsafe function or block
}创建不安全代码的安全抽象
use std::slice;
// 示例 1:标准库 split_at_mut 的用法
fn use_std_split_at_mut() {
let mut v = vec![1, 2, 3, 4, 5, 6];
let r = &mut v[..];
let (a, b) = r.split_at_mut(3);
assert_eq!(a, &mut [1, 2, 3]);
assert_eq!(b, &mut [4, 5, 6]);
}
// 示例 2:仅用安全 Rust 尝试实现 split_at_mut(会编译失败)
// fn bad_split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
// let len = values.len();
// assert!(mid <= len);
// // 编译错误:cannot borrow `*values` as mutable more than once at a time
// (&mut values[..mid], &mut values[mid..])
// }
// 示例 3:使用 unsafe 正确实现 split_at_mut
fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = values.len();
let ptr = values.as_mut_ptr(); // 获取切片裸指针
assert!(mid <= len); // 确保 mid 索引合法
// 所有 unsafe 操作必须包裹在 unsafe 块中
unsafe {
(
// 从 ptr 处创建长度为 mid 的切片
slice::from_raw_parts_mut(ptr, mid),
// ptr.add(mid) 计算偏移后的指针,创建剩余长度的切片
slice::from_raw_parts_mut(ptr.add(mid), len - mid),
)
}
}
// 示例 4:错误用法:基于任意内存地址创建切片(会导致未定义行为)
fn unsafe_slice_undefined_behavior() {
let address = 0x01234usize;
let r = address as *mut i32;
let _values: &[i32] = unsafe {
// 用任意地址创建切片,无法保证有效性,仅作演示
slice::from_raw_parts_mut(r, 10000)
};
// 注意:使用 _values 会导致崩溃,此处不执行任何操作
}
fn main() {
use_std_split_at_mut();
// 使用我们自己实现的 split_at_mut
let mut data = vec![10, 20, 30, 40, 50];
let (left, right) = split_at_mut(&mut data, 2);
println!("left: {:?}", left); // [10, 20]
println!("right: {:?}", right); // [30, 40, 50]
unsafe_slice_undefined_behavior();
}
//安全封装的关键:split_at_mut 是一个安全函数,虽然内部使用了 unsafe,但通过断言和裸指针操作,确保了返回的两个切片不会重叠,从而避免了数据竞争。
//slice::from_raw_parts_mut 与 ptr.add 是不安全的,必须在 unsafe 块中调用,且调用者需要手动保证指针和偏移的有效性。
//任意地址创建切片是危险的,会导致未定义行为,因此 unsafe 必须配合严格的安全检查(如 assert!)才能安全使用。使用extern函数调用外部代码
// 使用 extern "C" 声明 C 标准库函数
extern "C" {
// 声明 C 标准库中的 abs 函数(求整数绝对值)
// 外部函数默认是 unsafe,Rust 无法验证其安全性
fn abs(input: i32) -> i32;
}
fn main() {
// 调用外部 C 函数必须包裹在 unsafe 块中
unsafe {
println!(
"Absolute value of -3 according to C: {}",
abs(-3) // 调用 C 标准库的 abs 函数
);
}
}从其他语言调用rust函数
// 导出一个可被 C 语言调用的 Rust 函数
#[no_mangle] // 禁止 Rust 编译器修改函数名,保证外部语言能正确识别
pub extern "C" fn call_from_c() {
// 函数实现
println!("Just called a Rust function from C!");
}
fn main() {
// 这个函数会被编译为 C 兼容的符号,可被其他语言调用
// 此类导出函数本身不需要 unsafe 标记
}④访问或修改可变静态变量
Rust 支持全局变量,这类变量也被称为静态变量。由于所有权机制,使用可变全局变量可能引发问题,例如多线程同时访问时会导致数据竞争。
// ------------------- 示例1:定义和使用不可变静态变量 -------------------
// 静态变量只能存储具有'static生命周期的引用,编译器自动处理生命周期
static HELLO_WORLD: &str = "Hello, world!";
// ------------------- 示例2:定义和使用可变静态变量 -------------------
// 使用 mut 标记可变静态变量,读写操作必须在 unsafe 块中
static mut COUNTER: u32 = 0;
fn add_to_count(inc: u32) {
// 修改可变静态变量必须在 unsafe 块中
unsafe {
COUNTER += inc;
}
}
fn main() {
// 访问不可变静态变量是安全的
println!("value is: {}", HELLO_WORLD);
// 调用修改可变静态变量的函数
add_to_count(3);
// 读取可变静态变量也必须在 unsafe 块中
unsafe {
println!("COUNTER: {}", COUNTER);
}
}⑤实现不安全的trait
// 定义一个不安全 trait:用 unsafe 标记
unsafe trait Foo {
// 某些方法(编译器无法验证其安全性)
}
// 为 i32 实现不安全 trait,必须用 unsafe impl
unsafe impl Foo for i32 {
// 对应的方法实现
}
// 示例:手动为包含裸指针的类型实现 Send/Sync(需要 unsafe)
use std::marker::{Send, Sync};
// 自定义一个包含裸指针的类型
struct MyType {
ptr: *mut i32, // 裸指针默认不实现 Send/Sync
}
// 手动实现 Send,承诺该类型可以安全跨线程传递
unsafe impl Send for MyType {}
// 手动实现 Sync,承诺该类型可以安全从多个线程访问
unsafe impl Sync for MyType {}
fn main() {
// 使用示例
let _x: i32 = 42;
let _my_type = MyType { ptr: std::ptr::null_mut() };
}⑥访问联合体中的字段
Rust 中,联合体(union)类似结构体,但任意时刻只有一个字段处于使用状态,主要用于与 C 语言代码交互。访问联合体字段属于不安全操作,因为 Rust 无法保证联合体实例中数据的具体类型,需通过
unsafe完成。
⑦使用不安全代码的时机
使用
unsafe执行那 5 种 “超能力” 本身是合法的,但由于缺少编译器的强制内存安全保障,保持这类代码的正确性并不简单。建议仅在有充足理由时使用
unsafe,其显式标记也便于后续定位内存问题。
2. 高级trait
①关联类型
关联类型是 trait 中的类型占位符,可用于 trait 方法签名。trait 的实现者需根据场景为关联类型指定具体类型,从而在定义 trait 时无需提前确定其中涉及的具体类型。
关联类型比本章其他高级特性更常用,但又比基础特性用得少,处于中间状态。
// 标准库 Iterator trait 的定义:带有关联类型 Item
pub trait Iterator {
// 关联类型:Item,迭代器产生的元素类型占位符
type Item;
// next 方法返回 Option<Self::Item>,表示迭代器的下一个元素
fn next(&mut self) -> Option<Self::Item>;
}
// 假设的泛型版本 Iterator trait:用泛型参数 T 代替关联类型
// 与关联类型不同,这种设计允许为 同一类型 多次 实现 Iterator<T>
pub trait IteratorGeneric<T> {
fn next(&mut self) -> Option<T>;
}
// 示例结构体 Counter,用于实现 Iterator trait
struct Counter {
count: u32,
}
// 为 Counter 实现带有关联类型的 Iterator trait
impl Iterator for Counter {
// 指定关联类型 Item 为 u32(迭代产生的元素类型)
type Item = u32;
fn next(&mut self) -> Option<Self::Item> {
// 这里省略具体实现,仅演示语法
if self.count < 10 {
self.count += 1;
Some(self.count)
} else {
None
}
}
}
fn main() {
let mut counter = Counter { count: 0 };
// 使用 Iterator trait,无需显式标注 Item 类型(已在实现中指定为 u32),使用泛型,因为可以有多个next,需要指定类型
assert_eq!(counter.next(), Some(1));
assert_eq!(counter.next(), Some(2));
}②默认泛型参数和运算符重载
泛型参数可以指定默认类型,语法为
<PlaceholderType=ConcreteType>。当默认类型满足使用需求时,实现者无需额外指定类型,这一技术常用于运算符重载。默认类型参数主要有两种应用场景:
扩展类型功能而不破坏现有代码,通过为 trait 新增带默认值的类型参数,实现向后兼容。
支持特定场景下的自定义行为,同时为大多数用户提供便捷的默认使用方式。标准库的
Addtrait 是典型例子,默认实现同类型加法,也支持自定义行为。
use std::ops::Add;
// 示例1:定义 Point 结构体,重载 + 运算符(默认 Rhs=Self)
#[derive(Debug, Copy, Clone, PartialEq)]
struct Point {
x: i32,
y: i32,
}
// 实现 Add trait,使用默认 Rhs=Self(即 Point 类型)
impl Add for Point {
// 关联类型 Output:指定 add 方法的返回类型
type Output = Point;
fn add(self, other: Point) -> Point {
Point {
x: self.x + other.x,
y: self.y + other.y,
}
}
}
// 示例2:定义 Millimeters 和 Meters 结构体,实现跨单位加法
struct Millimeters(u32);
struct Meters(u32);
// 为 Millimeters 实现 Add trait,指定 Rhs=Meters(而非默认的 Self)
impl Add<Meters> for Millimeters {
// 关联类型 Output:指定返回类型为 Millimeters
type Output = Millimeters;
fn add(self, other: Meters) -> Millimeters {
// 将米转换为毫米后相加
Millimeters(self.0 + (other.0 * 1000))
}
}
fn main() {
// 测试 Point 的加法
let p1 = Point { x: 1, y: 0 };
let p2 = Point { x: 2, y: 3 };
let p3 = p1 + p2;
assert_eq!(p3, Point { x: 3, y: 3 });
println!("Point addition successful: {:?}", p3);
// 测试 Millimeters 和 Meters 的加法
let mm = Millimeters(500);
let m = Meters(2);
let total_mm = mm + m;
// 2米 = 2000毫米,500 + 2000 = 2500毫米
assert_eq!(total_mm.0, 2500);
println!("Cross-unit addition successful: {} mm", total_mm.0);
}③消除同名方法在调用时的歧义
同名方法调用优先级:当一个类型和多个 trait 都有同名方法时,调用
instance.method()会优先选择直接在类型上实现的方法。调用 trait 方法的语法:使用
Trait::method(&instance)可以显式指定调用哪个 trait 的实现。无
self的关联函数歧义:对于没有self参数的函数,Rust 无法通过调用者推断类型,必须使用完全限定语法<Type as Trait>::function()来明确指定类型和 trait。
// ------------------------------
// 场景1:多个 trait 存在同名方法,且类型自身也有同名方法
// ------------------------------
// 定义两个 trait,它们都包含一个名为 `fly` 的方法
trait Pilot {
fn fly(&self);
}
trait Wizard {
fn fly(&self);
}
// 定义一个结构体 `Human`,它将实现上面两个 trait,并且自身也实现了 `fly` 方法
struct Human;
impl Pilot for Human {
fn fly(&self) {
println!("This is your captain speaking.");
}
}
impl Wizard for Human {
fn fly(&self) {
println!("Up!");
}
}
impl Human {
// 结构体自身的 `fly` 方法
fn fly(&self) {
println!("*waving arms furiously*");
}
}
// ------------------------------
// 场景2:无 self 的关联函数同名问题,需要完全限定语法
// ------------------------------
trait Animal {
// 定义一个无 `self` 参数的关联函数
fn baby_name() -> String;
}
struct Dog;
impl Dog {
// 结构体自身的关联函数 `baby_name`
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
// 为 `Dog` 实现 `Animal` trait 中的 `baby_name`
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
// ------------------------------
// 场景1:调用 `Human` 的 `fly` 方法
// ------------------------------
let person = Human;
// 1. 默认调用:直接调用结构体自身实现的方法
println!("默认调用 Human::fly():");
person.fly();
// 输出: *waving arms furiously*
// 2. 显式调用 trait 中的方法:使用 `Trait::method(&instance)` 语法
println!("\n显式调用 Pilot::fly(&person):");
Pilot::fly(&person);
// 输出: This is your captain speaking.
println!("\n显式调用 Wizard::fly(&person):");
Wizard::fly(&person);
// 输出: Up!
// ------------------------------
// 场景2:调用 `Dog` 的 `baby_name` 关联函数
// ------------------------------
println!("\n------------------------------");
// 1. 默认调用:直接调用结构体自身的关联函数
println!("调用 Dog::baby_name():");
println!("A baby dog is called a {}", Dog::baby_name());
// 输出: A baby dog is called a Spot
// 2. 尝试直接调用 trait 关联函数(会报错,因为 Rust 无法推断具体类型)
// println!("调用 Animal::baby_name():");
// println!("A baby dog is called a {}", Animal::baby_name());
// 编译错误: cannot infer type for `_`
// 3. 使用完全限定语法 `<Type as Trait>::function()` 解决歧义
println!("\n使用完全限定语法 <Dog as Animal>::baby_name():");
println!("A baby dog is called a {}", <Dog as Animal>::baby_name());
// 输出: A baby dog is called a puppy
}④使用超trait
use std::fmt;
// 定义 OutlinePrint trait,依赖 Display trait(超trait)
trait OutlinePrint: fmt::Display {
// 默认实现:打印带星号边框的 self 字符串
fn outline_print(&self) {
// 调用 Display 的 to_string 方法(因 OutlinePrint 继承了 Display)
let output = self.to_string();
let len = output.len();
// 打印顶边框
println!("{}", "*".repeat(len + 4));
// 打印空白行
println!("*{}*", " ".repeat(len + 2));
// 打印带 self 内容的行
println!("* {} *", output);
// 打印空白行
println!("*{}*", " ".repeat(len + 2));
// 打印底边框
println!("{}", "*".repeat(len + 4));
}
}
// 定义 Point 结构体,初始未实现 Display
struct Point {
x: i32,
y: i32,
}
// 为 Point 实现 Display trait(满足 OutlinePrint 的超trait约束)
impl fmt::Display for Point {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
write!(f, "({}, {})", self.x, self.y)
}
}
// 为 Point 实现 OutlinePrint trait(无需重写方法,直接使用默认实现)
impl OutlinePrint for Point {}
fn main() {
let p = Point { x: 1, y: 3 };
// 调用 outline_print 方法,打印带星号边框的 Point 字符串
p.outline_print();
}⑤使用newtype模式在外部类型上实现外部trait
Rust 的孤儿规则规定,只有当类型或 trait 中任意一个定义在本地包内时,才能为该类型实现这个 trait。
newtype模式可绕过此限制:通过定义一个包含目标类型的单字段元组结构体(瘦封装),由于新类型位于本地包内,可为其实现任何 trait。该模式不会产生额外运行时开销,封装类型会在编译期被优化掉。
use std::fmt;
// 定义一个 newtype:Wrapper,它是对 Vec<String> 的瘦封装
// 这是一个本地类型,因此我们可以为它实现任何 trait
struct Wrapper(Vec<String>);
// 为 Wrapper 实现 Display trait
// 因为 Wrapper 是本地类型,这绕过了孤儿规则(无法直接为外部 Vec<T> 实现 Display)
impl fmt::Display for Wrapper {
fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result {
// 使用 self.0 访问内部的 Vec<String>
// 将 Vec 中的字符串用逗号连接,并用 [] 包裹
write!(f, "[{}]", self.0.join(", "))
}
}
fn main() {
// 创建一个 Wrapper 实例,包裹一个 Vec<String>
let w = Wrapper(vec![
String::from("hello"),
String::from("world"),
]);
// 由于我们实现了 Display,现在可以使用 println!("{}", w) 来打印它
println!("w = {}", w);
// 输出: w = [hello, world]
// --- newtype 的优缺点说明 ---
// 优点:
// 1. 零成本抽象:Wrapper 在编译时会被优化掉,没有运行时开销。
// 2. 绕过孤儿规则:可以为任何外部类型实现 trait。
// 缺点:
// 1. 默认无法访问内部类型的方法:Wrapper 本身不实现 Vec 的任何方法,
// 比如 w.push("new") 会报错,因为 push 是 Vec 的方法,不是 Wrapper 的。
// 2. 为了解决方法访问问题,可以为 Wrapper 实现 Deref trait(见下方),
// 或者手动实现所需方法。
// 如果我们希望 Wrapper 拥有 Vec 的所有方法,可以这样实现 Deref:
// use std::ops::Deref;
// impl Deref for Wrapper {
// type Target = Vec<String>;
// fn deref(&self) -> &Self::Target {
// &self.0
// }
// }
// 实现 Deref 后,w.push("new") 就可以工作了。
}3. 高级类型
①使用newtype模式实现类型安全与抽象
newtype模式有多种用途:静态区分值的含义与单位,防止类型混淆,例如
Millimeters和Meters封装u32,可避免单位误用。为类型细节提供抽象能力,通过新类型暴露与内部私有类型不同的公共 API,限制用户访问权限。
隐藏内部实现,例如用
People封装HashMap<i32, String>,用户仅能通过指定 API 操作,无需了解内部的 ID 映射逻辑。
②使用类型别名创建同义类型
类型别名:只是现有类型的同义词,不会创建新类型,核心用途是简化代码、减少重复。
与
newtype的对比:类型别名:不提供类型安全,无法防止单位混淆。
newtype:是独立类型,能实现类型安全,但会增加少量代码。-
简化长类型,如
Box<dyn Fn() + Send + 'static>。为通用类型提供固定参数,如
std::io::Result<T>。
use std::fmt;
use std::io::Error;
use std::result::Result;
// ---------------
// 类型别名:基础用法
// ---------------
// 1. 简单别名:为 i32 创建别名 Kilometers
type Kilometers = i32;
fn main() {
let x: i32 = 5;
let y: Kilometers = 5;
// 因为 Kilometers 是 i32 的别名,它们是同一种类型,可以直接相加
println!("x + y = {}", x + y);
// ---------------
// 2. 为复杂类型创建别名:简化重复的长类型
// ---------------
// 原始长类型:Box<dyn Fn() + Send + 'static>
let long_type: Box<dyn Fn() + Send + 'static> = Box::new(|| println!("hi"));
fn takes_long_type(_f: Box<dyn Fn() + Send + 'static>) {}
fn returns_long_type() -> Box<dyn Fn() + Send + 'static> {
Box::new(|| {})
}
// 使用类型别名简化:Thunk
type Thunk = Box<dyn Fn() + Send + 'static>;
let short_type: Thunk = Box::new(|| println!("hello"));
fn takes_thunk(_f: Thunk) {}
fn returns_thunk() -> Thunk {
Box::new(|| {})
}
// ---------------
// 3. 标准库中的典型用法:std::io::Result<T>
// ---------------
// 简化定义:为 Result<T, std::io::Error> 创建别名
type IoResult<T> = Result<T, Error>;
// 简化前:完整写法
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize, Error>;
fn flush(&mut self) -> Result<(), Error>;
}
// 简化后:使用别名
pub trait SimpleWrite {
fn write(&mut self, buf: &[u8]) -> IoResult<usize>;
fn flush(&mut self) -> IoResult<()>;
}
// ---------------
// 与 newtype 的关键区别
// ---------------
// 类型别名:只是同义词,无类型安全检查
let km: Kilometers = 10;
let meters: i32 = 10;
// 编译器不会报错,因为 Kilometers 和 i32 是同一类型
let sum = km + meters;
println!("sum: {}", sum);
// newtype:是独立类型,提供类型安全
struct Millimeters(u32);
struct Meters(u32);
let mm = Millimeters(1000);
let m = Meters(1);
// 编译错误:类型不匹配
// let total = mm + m;
}③永不返回的never类型
use std::io;
// ------------------------------
// 1. 发散函数:以 ! 作为返回类型
// ------------------------------
fn bar() -> ! {
// 这是一个发散函数,永远不会返回
panic!("This function never returns!");
}
// ------------------------------
// 2. match 表达式中使用 continue:continue 的返回类型是 !
// ------------------------------
fn guess_game_example() {
let mut guess = String::new();
io::stdin().read_line(&mut guess).unwrap();
// 解析输入为 u32,错误时使用 continue
let _guess_num: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue, // continue 的返回类型是 !,可以和 u32 兼容
};
println!("Your guess is valid: {}", _guess_num);
}
// ------------------------------
// 3. Option::unwrap 中 panic! 的使用
// ------------------------------
fn unwrap_example() {
let some_val: Option<i32> = Some(42);
let _val = some_val.unwrap(); // 正常分支返回 i32
// None 分支会 panic!,panic! 的返回类型是 !,因此 match 整体返回 i32
let none_val: Option<i32> = None;
// let _none_val = none_val.unwrap(); // 运行时 panic,返回类型为 !
}
// ------------------------------
// 4. loop 表达式:无 break 的 loop 返回 !
// ------------------------------
fn forever_loop() {
print!("forever ");
// 无 break 的 loop 永远不会结束,返回类型为 !
loop {
print!("and ever ");
}
}
fn main() {
// 示例1:发散函数(调用会 panic,因此注释)
// bar();
// 示例2:match 中使用 continue(正常运行)
// guess_game_example();
// 示例3:Option::unwrap
unwrap_example();
// 示例4:永远循环(调用会无限执行,因此注释)
// forever_loop();
}④动态大小类型和Sized trait
fn main() {
// ------------------------------
// 动态大小类型(DST)示例:str
// ------------------------------
// 错误:str 是动态大小类型,无法直接创建变量,rust要求同一类型必须具有相同大小
// let s1: str = "Hello there!";
// let s2: str = "How's it going?";
// 正确:使用 &str(字符串切片),它是带长度信息的指针
let s1: &str = "Hello there!";
let s2: &str = "How's it going?";
println!("s1: {}, length: {}", s1, s1.len());
println!("s2: {}, length: {}", s2, s2.len());
// 其他 DST 指针用法:Box<str>
let boxed_str: Box<str> = Box::from("boxed string");
println!("boxed_str: {}", boxed_str);
// ------------------------------
// 泛型函数与 Sized 约束
// ------------------------------
// 默认泛型函数:隐式添加 Sized 约束,仅接受编译期可知大小的类型
fn generic<T: Sized>(_t: T) {
// ...
}
// 解除 Sized 限制:使用 ?Sized 约束,同时参数改为引用
fn generic_dst<T: ?Sized>(_t: &T) {
// ...
}
// 调用示例:Sized 类型(如 i32)和 DST(如 str)都可以传入
let num = 42;
generic(num);
generic_dst(&num);
let s = "hello";
// generic(s); // 错误:str 无 Sized 约束,无法传入默认泛型函数
generic_dst(s); // 正确:&str 满足 ?Sized 约束
}4. 高级函数与闭包
①函数指针
函数指针
fn类型:与闭包不同,
fn是一个具体类型(不是 trait),可以直接作为参数类型声明。普通函数会自动转换为对应的
fn类型,无需额外语法。函数指针实现了所有闭包 trait(
Fn/FnMut/FnOnce),因此可以传入接收闭包的函数(如Iterator::map)。
-
函数指针 vs 闭包:
闭包更灵活,可以捕获环境变量;函数指针只能传递纯函数。
函数指针适合传递已定义好的函数,无需额外定义闭包,代码更简洁。
-
枚举构造器的特殊用法:
枚举变体的构造器(如
Status::Value)本质上是函数指针,可以直接用于需要函数的场景(如map)。这种写法和闭包效果完全相同,编译后生成的代码也一致。
use std::fmt::Display;
fn main() {
// ------------------------------
// 1. 函数指针(fn 类型)基础用法
// ------------------------------
// 定义一个普通函数
fn add_one(x: i32) -> i32 {
x + 1
}
// 定义一个接收函数指针作为参数的函数
// 参数 f 的类型是 fn(i32) -> i32,即“接收 i32、返回 i32 的函数指针”
fn do_twice(f: fn(i32) -> i32, arg: i32) -> i32 {
f(arg) + f(arg)
}
// 调用 do_twice,直接传入普通函数 add_one
// add_one 会被自动转换为函数指针类型 fn(i32) -> i32
let answer = do_twice(add_one, 5);
println!("The answer is: {}", answer); // 输出: 12
// ------------------------------
// 2. 在 Iterator::map 中使用函数指针替代闭包
// ------------------------------
let list_of_numbers = vec![1, 2, 3];
// 方式1:使用闭包
let list_of_strings_closure: Vec<String> = list_of_numbers
.iter()
.map(|i| i.to_string())
.collect();
println!("Using closure: {:?}", list_of_strings_closure);
// 方式2:使用函数指针(ToString::to_string)
// 注意:使用完全限定语法消除歧义
let list_of_strings_fn: Vec<String> = list_of_numbers
.iter()
.map(ToString::to_string)
.collect();
println!("Using function pointer: {:?}", list_of_strings_fn);
// ------------------------------
// 3. 枚举构造器作为函数指针
// ------------------------------
#[derive(Debug)]
enum Status {
Value(u32),
Stop,
}
// 枚举变体的构造器可以被当作函数指针使用
// Status::Value 本质上是一个 fn(u32) -> Status 类型的函数指针
let list_of_statuses: Vec<Status> = (0u32..20).map(Status::Value).collect();
println!("Using enum constructor as function pointer: {:?}", list_of_statuses);
}②返回闭包
fn main() {
// ------------------------------
// 错误示例:直接返回 dyn Fn,无法编译
// 原因:dyn Fn 是 trait 对象,属于动态大小类型(DST),Rust 无法在编译期确定其大小,因此不能直接作为返回值
// ------------------------------
// fn returns_closure() -> dyn Fn(i32) -> i32 {
// |x| x + 1
// }
// ------------------------------
// 方案一:使用 impl Trait 返回闭包(推荐,无运行时开销)
// ------------------------------
// impl Trait 会让编译器推断出闭包的具体类型,同时满足返回 trait 的需求
fn returns_closure_impl() -> impl Fn(i32) -> i32 {
|x| x + 1
}
let closure_impl = returns_closure_impl();
println!("使用 impl Trait 调用结果:{}", closure_impl(5)); // 输出:6
// ------------------------------
// 方案二:使用 Box<dyn Trait> 包装闭包(trait 对象)
// ------------------------------
// 用 Box 把闭包装箱成 trait 对象,通过指针访问,解决动态大小问题
fn returns_closure_box() -> Box<dyn Fn(i32) -> i32> {
Box::new(|x| x + 1)
}
let closure_box = returns_closure_box();
println!("使用 Box<dyn Trait> 调用结果:{}", closure_box(5)); // 输出:6
}5. 宏
Rust 的 “宏” 是一组相关功能的统称,包含使用
macro_rules!构造的声明宏,以及三类过程宏:自定义
#[derive]宏:为结构体或枚举指定随derive属性自动添加的代码。属性宏:为任意条目添加自定义属性。
函数宏:形式类似函数,可接收并处理标记序列。
宏与函数的核心区别是:宏在编译期展开,可处理语法层面的重复代码与元编程场景,弥补函数在这些场景的不足。
①宏与函数的区别
宏是元编程范式,本质是 “编写生成代码的代码”,能自动生成 trait 实现,
println!、vec!等均为宏。宏的核心优势:
支持可变参数,无需在定义时固定参数数量与类型。
编译期展开,可完成函数无法实现的任务,如自动为类型实现 trait。
宏的缺点:
定义复杂,需编写生成 Rust 代码的 Rust 代码,可读性、维护性较差。
调用前必须提前定义或引入,而函数无此限制。
②用于通用元编程的macro_rules!宏
// ------------------------------
// 声明宏(macro_rules!)示例:简化版 vec! 宏
// ------------------------------
// #[macro_export]:标记宏为可导出,引入包后即可使用
#[macro_export]
macro_rules! vec {
// 模式匹配分支:匹配任意数量、逗号分隔的表达式
// 语法解析:
// $($x:expr),* 表示:
// $():捕获重复模式
// $x:expr:捕获任意 Rust 表达式,命名为 $x
// ,:匹配表达式后的逗号分隔符
// *:允许模式重复 0 次或多次
( $( $x:expr ),* ) => {
{
let mut temp_vec = Vec::new();
// $()*:对捕获的每个表达式重复执行内部代码
$(
temp_vec.push($x);
)*
temp_vec
}
};
}
fn main() {
// 使用自定义 vec! 宏创建动态数组
let v1: Vec<u32> = vec![1, 2, 3];
println!("v1: {:?}", v1);
// 宏支持任意数量的参数
let v2: Vec<&str> = vec!["hello", "world"];
println!("v2: {:?}", v2);
let v3: Vec<i32> = vec![];
println!("v3: {:?}", v3);
}
/*
编译时,vec![1, 2, 3] 会被展开为:
{
let mut temp_vec = Vec::new();
temp_vec.push(1);
temp_vec.push(2);
temp_vec.push(3);
temp_vec
}
*/③基于属性创建代码的过程宏
// 过程宏定义示例
// 注意:过程宏必须放在单独的 proc-macro 类型包中,此处为简化示例
use proc_macro::TokenStream;
/// 这是一个占位的过程宏示例
/// - 过程宏接收输入的 TokenStream(标记序列)
/// - 处理后生成并返回新的 TokenStream
/// - 具体宏类型(派生/属性/函数宏)由函数上的属性决定
#[proc_macro_derive(SomeAttribute)] // 实际使用时替换为对应属性,如 #[proc_macro] / #[proc_macro_attribute]
pub fn some_name(input: TokenStream) -> TokenStream {
// input: 传入宏的源代码标记序列
// 此处可编写逻辑处理 input 并生成新代码
// 示例中直接返回原输入(无实际处理)
input
}
/*
过程宏核心说明:
1. 定义形式:函数接收并返回 proc_macro::TokenStream,通过函数上的属性区分宏类型
- #[proc_macro_derive]:自定义派生宏,为结构体/枚举自动实现 trait
- #[proc_macro_attribute]:属性宏,为条目添加自定义属性
- #[proc_macro]:函数宏,形式类似函数,处理标记序列
2. 工作机制:接收输入代码的标记流,处理后生成新代码,与声明宏的模式匹配替换不同
3. 限制:过程宏必须放在单独的 proc-macro 包中,当前 Rust 限制
*/④自定义派生宏
项目结构:
hello_macro:定义 trait,用户依赖此包即可使用 trait。hello_macro_derive:单独的 proc-macro 包,实现派生宏,自动为类型生成 trait 实现。pancakes:示例项目,通过#[derive(HelloMacro)]自动实现 trait。-
关键工具:
syn:解析 Rust 代码,将 TokenStream 转换为可操作的语法树。quote:将语法树转换回 Rust 代码,支持模板替换(如#name)。proc-macro:Rust 内置库,提供过程宏接口。
-
运行流程:
用户在类型上标注
#[derive(HelloMacro)]。编译器调用
hello_macro_derive过程宏。宏解析类型名称,生成
impl HelloMacro代码。编译期自动注入生成的代码,用户无需手动实现。
// ==============================================
// 项目结构说明:
// hello_macro/
// ├── src/lib.rs # 定义 HelloMacro trait
// ├── hello_macro_derive/
// │ ├── Cargo.toml # 过程宏包配置
// │ └── src/lib.rs # 派生宏实现
// └── Cargo.toml
//
// pancakes/
// ├── Cargo.toml # 依赖配置
// └── src/main.rs # 使用示例
// ==============================================
// ------------------------------
// 1. hello_macro/src/lib.rs:定义 trait
// ------------------------------
pub trait HelloMacro {
fn hello_macro();
}
// ------------------------------
// 2. hello_macro/hello_macro_derive/Cargo.toml
// ------------------------------
/*
[package]
name = "hello_macro_derive"
version = "0.1.0"
edition = "2021"
[lib]
proc-macro = true
[dependencies]
syn = "1.0"
quote = "1.0"
proc-macro2 = "1.0"
*/
// ------------------------------
// 3. hello_macro/hello_macro_derive/src/lib.rs:派生宏实现
// ------------------------------
use proc_macro::TokenStream;
use quote::quote;
use syn;
/// 自定义派生宏,为类型自动实现 HelloMacro trait
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// 将输入 TokenStream 解析为语法树
let ast = syn::parse(input).unwrap();
// 生成 trait 实现代码
impl_hello_macro(&ast)
}
/// 根据解析后的语法树,生成 HelloMacro 的实现
fn impl_hello_macro(ast: &syn::DeriveInput) -> TokenStream {
// 获取被派生的类型名称
let name = &ast.ident;
// 使用 quote! 生成实现代码
let gen = quote! {
impl HelloMacro for #name {
fn hello_macro() {
println!(
"Hello, Macro! My name is {}!",
stringify!(#name)
);
}
}
};
// 将生成的代码转换为 TokenStream
gen.into()
}
// ------------------------------
// 4. pancakes/src/main.rs:使用示例
// ------------------------------
use hello_macro::HelloMacro;
use hello_macro_derive::HelloMacro;
// 通过 derive 自动实现 HelloMacro
#[derive(HelloMacro)]
struct Pancakes;
fn main() {
// 调用自动生成的方法
Pancakes::hello_macro();
// 输出:Hello, Macro! My name is Pancakes!
}
/*
pancakes/Cargo.toml 依赖配置:
[dependencies]
hello_macro = { path = "../hello_macro" }
hello_macro_derive = { path = "../hello_macro/hello_macro_derive" }
*/⑤属性宏
// ------------------------------
// 属性宏示例:Web 路由标记宏
// ------------------------------
// 属性宏需要放在单独的 proc-macro 包中
use proc_macro::TokenStream;
use quote::quote;
use syn;
/// 自定义属性宏 `#[route(...)]`,用于标记 Web 路由函数
/// 参数:
/// - attr: 属性本身的内容(如 `GET, "/"`)
/// - item: 被标记的条目(如 `fn index() { ... }`)
#[proc_macro_attribute]
pub fn route(attr: TokenStream, item: TokenStream) -> TokenStream {
// 解析属性内容和被标记的条目
let _attr_tokens = attr; // 可解析路由方法、路径等信息
let func = syn::parse_macro_input!(item as syn::ItemFn);
// 获取函数名称和签名
let func_name = &func.sig.ident;
let func_body = &func.block;
// 示例:生成一个包装函数,注册路由(实际框架中会更复杂)
let gen = quote! {
pub fn #func_name() {
println!("Handling route defined by #[route] attribute");
#func_body
}
};
gen.into()
}
/*
用户端使用示例:
#[route(GET, "/")]
fn index() {
println!("Hello from the index route!");
}
编译后会生成类似如下代码:
pub fn index() {
println!("Handling route defined by #[route] attribute");
println!("Hello from the index route!");
}
*/
/*
属性宏与派生宏的核心区别:
1. 用途更灵活:派生宏仅用于结构体/枚举,属性宏可用于函数、模块等任意条目
2. 参数更丰富:属性宏可接收自定义参数(如路由方法、路径),而派生宏的参数固定为 trait 名称
3. 接口不同:属性宏的函数接收两个 TokenStream(属性内容 + 被标记条目),派生宏仅接收被派生的条目
*/⑥函数宏
// ------------------------------
// 函数宏(过程宏的一种)示例:模拟 sql! 宏
// ------------------------------
// 函数宏需要放在单独的 proc-macro 包中
use proc_macro::TokenStream;
use quote::quote;
/// 模拟 sql! 函数宏,接收 SQL 语句标记流并生成代码
/// 实际场景中可解析 SQL 语法、验证正确性并生成类型安全的执行代码
#[proc_macro]
pub fn sql(input: TokenStream) -> TokenStream {
// input 为圆括号内的标记序列,如 "SELECT * FROM posts WHERE id=1"
// 此处仅作示例,实际可使用 syn/自定义解析器处理 SQL 语法
let sql_str = input.to_string();
// 生成简单代码:返回 SQL 字符串(实际可生成更复杂的执行逻辑)
let gen = quote! {
{
// 编译期可添加 SQL 语法校验逻辑
const SQL: &str = #sql_str;
SQL
}
};
gen.into()
}
/*
用户端使用示例:
let sql = sql!(SELECT * FROM posts WHERE id=1);
println!("Generated SQL: {}", sql);
编译后会生成类似如下代码:
let sql = {
const SQL: &str = "SELECT * FROM posts WHERE id=1";
SQL
};
*/
/*
函数宏核心说明:
1. 定义方式:使用 #[proc_macro] 属性标记,函数接收并返回 TokenStream
2. 与 macro_rules! 的区别:
- 函数宏可使用完整 Rust 代码处理 TokenStream,逻辑更灵活(如 SQL 语法校验)
- macro_rules! 仅能通过模式匹配替换,无法执行复杂逻辑
3. 适用场景:需要对输入进行复杂解析、校验或生成代码的场景(如 SQL、正则表达式、DSL 等)
*/二十二. 编写自动化测试
Edsger W. Dijkstra 指出:测试可以高效暴露 bug,但无法证明 bug 不存在。尽管如此,开发者仍应尽力测试。
程序的正确性是代码实际行为与设计目标的一致程度。Rust 从设计之初就重视程序正确性,类型系统提供了大量安全保障,但仍无法防止所有错误,因此 Rust 在语言层面内置了编写和执行自动化测试的功能。
以
add_two函数为例,Rust 会通过类型检查和借用检查避免传入错误类型,但无法保证其逻辑是否符合预期,比如是否真的将输入值加 2,而非其他值。此时需要通过测试用例断言其行为,例如传入 3 时返回 5,确保修改代码时原有正确行为不受影响。本章将介绍 Rust 测试工具的运行机制,包括测试常用的标注和宏、测试运行的默认行为与选项参数,以及单元测试和集成测试的组织方式。
1. 如何编写测试
Rust 中的测试是一类特殊函数,用于验证非测试代码是否按预期运行。测试函数通常包含三部分:
准备测试所需的数据或状态。
调用待测试的代码。
通过断言验证运行结果是否与预期一致。
编写测试代码的核心功能包括:
test属性、测试宏(如assert!、assert_eq!、assert_ne!),以及should_panic属性。
①测试函数的构成
// 运行 `cargo new adder --lib` 会自动生成如下文件结构:
// adder/
// ├── Cargo.toml
// └── src/
// └── lib.rs
// ------------------------------
// src/lib.rs:测试模块与示例函数
// ------------------------------
/// 测试模块,仅在运行 `cargo test` 时编译
#[cfg(test)]
mod tests {
// 导入外部代码(如果有实际函数)
// use super::*;
/// 基础测试函数,`#[test]` 属性标记为测试用例
#[test]
fn it_works() {
// 1. 准备数据/状态
let result = 2 + 2;
// 2. 调用待测试代码
// 3. 断言结果与预期一致
assert_eq!(result, 4);
}
/// 测试函数可自定义命名,名称会在测试结果中显示
#[test]
fn exploration() {
assert_eq!(2 + 2, 4);
}
/// 失败测试示例:调用 `panic!` 会导致测试失败
#[test]
fn another() {
panic!("Make this test fail");
}
}
/*
核心概念说明:
1. `#[cfg(test)]`:标记模块为测试专用,仅在测试模式下编译
2. `#[test]`:标记函数为测试用例,`cargo test` 会自动执行所有带此属性的函数
3. `assert_eq!`:断言宏,用于验证两个值是否相等,不相等则测试失败
4. 测试失败机制:测试函数触发 `panic!` 时,测试会被标记为失败,`cargo test` 会输出详细错误信息
运行 `cargo test` 时,输出会包含:
- 每个测试用例的运行结果(ok/FAILED)
- 测试摘要:通过/失败/忽略/过滤的用例数量
- 文档测试(Doc-tests)结果(当前示例无文档测试,因此显示 `running 0 tests`)
*/
/*
扩展说明:
- 可通过 `cargo test 测试函数名` 单独运行特定测试用例
- 可通过 `#[should_panic]` 属性标记预期会 panic 的测试
- 可通过 `#[ignore]` 属性标记测试为忽略,不默认运行
*/②使用assert!宏检查结果
/// 定义矩形结构体,派生 Debug 便于调试
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
/// 判断当前矩形是否能容纳另一个矩形
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
/// 测试模块,仅在运行 `cargo test` 时编译
#[cfg(test)]
mod tests {
// 导入外部模块的所有内容
use super::*;
/// 测试:大矩形能容纳小矩形
#[test]
fn larger_can_hold_smaller() {
// 准备数据:创建两个矩形实例
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
// 断言 `larger.can_hold(&smaller)` 为 true,否则测试失败
assert!(larger.can_hold(&smaller));
}
/// 测试:小矩形不能容纳大矩形
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
// 断言 `smaller.can_hold(&larger)` 为 false,因此取反后断言为 true
assert!(!smaller.can_hold(&larger));
}
}
/*
核心说明:
1. `assert!` 宏:接收布尔表达式,为 true 时测试通过,为 false 时调用 panic! 导致测试失败。
2. `use super::*`:将外部模块的所有内容导入测试模块,便于直接使用 `Rectangle`。
3. 当 `can_hold` 方法实现错误(如 `self.width < other.width`)时,测试会失败,`cargo test` 会输出 `assertion failed` 错误信息,帮助定位问题。
*/③使用assert_eq!和assert_ne!宏判断相等性
/// 示例函数:将输入值加2
pub fn add_two(a: i32) -> i32 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
/// 测试 add_two 函数:输入2,预期输出4
#[test]
fn it_adds_two() {
// assert_eq! 断言两个值相等,失败时会打印左右值
assert_eq!(4, add_two(2));
}
/// 测试 add_two 函数:输入任意值,预期输出不等于输入值
#[test]
fn it_changes_input() {
// assert_ne! 断言两个值不相等,失败时会打印左右值
let input = 5;
assert_ne!(input, add_two(input));
}
}
/*
核心说明:
1. `assert_eq!` 和 `assert_ne!`:
- 分别用于断言两个值**相等**和**不相等**,失败时会自动打印左右值,便于调试。
- 参数必须同时实现 `PartialEq`(用于相等判断)和 `Debug`(用于打印) trait。
- 基本类型和大多数标准库类型默认实现了这两个 trait,自定义类型可通过 `#[derive(PartialEq, Debug)]` 派生。
2. 测试失败场景:
- 若 `add_two` 实现错误(如 `a + 3`),调用 `assert_eq!(4, add_two(2))` 会失败,输出:
`assertion failed: (left == right) left: `4`, right: `5``,清晰显示预期值和实际值。
3. `assert_ne!` 适用场景:
- 无法确定具体输出值,但可确定输出值与输入值不相等(如带随机、日期依赖的函数)。
*/④添加自定义的错误提示信息
/// 生成问候语的函数
pub fn greeting(name: &str) -> String {
format!("Hello {name}!")
}
#[cfg(test)]
mod tests {
use super::*;
/// 测试问候语中是否包含传入的姓名
#[test]
fn greeting_contains_name() {
let name = "Carol";
let result = greeting(name);
// 断言问候语中包含姓名,并添加自定义错误提示
assert!(
result.contains(name),
// 自定义错误提示:使用格式化字符串,会在断言失败时打印
"Greeting did not contain name, value was `{}`",
result
);
}
}
/*
核心说明:
1. 自定义错误提示:
- `assert!`、`assert_eq!`、`assert_ne!` 宏支持在必要参数后传入自定义错误信息,这些参数会传递给 `format!` 宏。
- 可以使用 `{}` 占位符格式化输出变量,帮助调试时快速了解失败场景。
2. 测试失败场景:
- 若 `greeting` 函数实现错误(如返回固定字符串 `"Hello!"`),断言失败时会输出:
`Greeting did not contain name, value was `Hello!``,清晰显示实际返回值,便于定位问题。
3. 适用场景:
- 当断言失败时,默认提示信息不够直观,添加自定义提示可以快速定位问题原因,例如打印关键变量的值。
*/④使用should_panic!检查panic
/// 表示 1~100 之间的猜测值
pub struct Guess {
value: i32,
}
impl Guess {
/// 创建 Guess 实例,仅允许值在 1~100 之间,否则 panic
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be greater than or equal to 1, got {}.",
value
);
} else if value > 100 {
panic!(
"Guess value must be less than or equal to 100, got {}.",
value
);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
/// 测试:传入大于 100 的值,预期会 panic
#[test]
#[should_panic(expected = "less than or equal to 100")]
fn greater_than_100() {
Guess::new(200);
}
/// 测试:传入小于 1 的值,预期会 panic
#[test]
#[should_panic(expected = "greater than or equal to 1")]
fn less_than_1() {
Guess::new(-1);
}
}
/*
核心说明:
1. `#[should_panic]` 属性:
- 标记测试函数预期会 panic,若函数正常执行不 panic,则测试失败。
- `expected` 参数可指定 panic 消息中应包含的子串,使测试更精确。
2. 测试失败场景:
- 若 `Guess::new` 实现错误(如将 `value > 100` 的 panic 消息写为 `greater than or equal to 1`),`greater_than_100` 测试会失败,输出:
`panic did not contain expected string`,并显示实际 panic 消息和预期子串,便于定位问题。
3. 适用场景:
- 验证代码在错误输入下的 panic 行为,确保错误处理逻辑符合预期。
*/⑤使用Result<T, E>编写测试
#[cfg(test)]
mod tests {
// 用 Result<T, E> 作为返回类型,而非 panic
#[test]
fn it_works() -> Result<(), String> {
if 2 + 2 == 4 {
Ok(()) // 测试通过时返回 Ok(())
} else {
Err(String::from("two plus two does not equal four")) // 测试失败时返回 Err
}
}
// 示例:在测试中使用 ? 运算符简化错误处理
#[test]
fn with_question_mark() -> Result<(), String> {
let value = 4;
if value != 4 {
return Err(String::from("value is not 4"));
}
Ok(())
}
// 注意:不能对返回 Result 的测试使用 #[should_panic]
// 若要断言操作会失败,应使用 assert!(value.is_err())
#[test]
fn assert_error_case() {
let result: Result<(), &str> = Err("test error");
assert!(result.is_err());
}
}
/*
核心说明:
1. 测试函数返回 Result<T, E>:
- 测试通过时返回 Ok(()),失败时返回 Err,不会触发 panic。
- 这种方式允许在测试中使用 ? 运算符,简化错误处理逻辑。
2. 与 #[should_panic] 的互斥:
- 不能对返回 Result 的测试使用 #[should_panic] 属性。
- 若需断言操作会失败,直接使用 assert!(value.is_err()) 即可。
*/2. 控制测试的运行方式
这段文字主要介绍了
cargo test命令的工作方式和参数用法:它会在测试模式下编译代码,并运行生成的测试二进制文件。
默认行为:并行运行所有测试,并截获测试输出,只打印最终结果,让输出更整洁。
参数传递规则:
cargo test [cargo 参数] -- [测试二进制参数]
例如
cargo test --help查看cargo test本身的选项,cargo test -- --help查看传递给测试二进制文件的选项。
①并行或串行的运行测试
Rust 默认以多线程并行运行测试,以提高执行效率。这种方式要求测试之间无依赖,且不共享状态或环境(如文件、环境变量),否则可能因相互干扰导致断言失败。
若需避免并行干扰,可通过
--test-threads参数控制线程数:单线程运行:
cargo test -- --test-threads=1,测试会顺序执行,解决共享状态冲突,但耗时更长。
②显示函数输出
/// 示例函数:打印输入值并返回固定值 10
fn prints_and_returns_10(a: i32) -> i32 {
println!("I got the value {}", a);
10
}
#[cfg(test)]
mod tests {
use super::*;
/// 测试通过:断言返回值为 10
#[test]
fn this_test_will_pass() {
let value = prints_and_returns_10(4);
assert_eq!(10, value);
}
/// 测试失败:断言返回值为 5(实际为 10)
#[test]
fn this_test_will_fail() {
let value = prints_and_returns_10(8);
assert_eq!(5, value);
}
}
/*
核心说明:
1. 默认输出行为:
- `cargo test` 默认捕获并丢弃测试通过时的标准输出(如 `println!`),仅显示测试结果。
- 测试失败时,会同时显示错误信息和被捕获的标准输出,便于调试。
2. 查看通过测试的输出:
- 使用 `cargo test -- --show-output` 命令,可强制显示所有测试(包括通过的)的标准输出。
- 此时通过的测试会打印 `I got the value 4`,失败的测试会打印 `I got the value 8` 和断言错误信息。
*/③运行部分特定名称的测试
介绍
/// 示例函数:将输入值加 2
pub fn add_two(a: i32) -> i32 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn add_two_and_two() {
assert_eq!(4, add_two(2));
}
#[test]
fn add_three_and_two() {
assert_eq!(5, add_two(3));
}
#[test]
fn one_hundred() {
assert_eq!(102, add_two(100));
}
}
/*
核心说明:
1. 默认行为:`cargo test` 会并行运行所有标记 `#[test]` 的函数。
2. 运行单个测试:
- 命令格式:`cargo test 测试函数名`,例如 `cargo test add_two_and_two`,只会运行指定名称的测试。
3. 运行多个匹配的测试:
- 可以传入部分名称进行过滤,例如 `cargo test add` 会运行所有名称包含 `add` 的测试(`add_two_and_two` 和 `add_three_and_two`)。
*/运行单个测试
# 1. 运行单个测试函数
cargo test one_hundred
# 输出中会看到:
# running 1 test
# test tests::one_hundred ... ok
# 2 filtered out(另外两个测试被过滤掉)
# 2. 按名称过滤,运行多个匹配的测试
# 运行所有名称包含 `add` 的测试
cargo test add
# 3. 说明:
# - `cargo test` 只接收**一个**过滤参数(第一个),不能直接用多个参数分别指定多个函数。
# - 想同时运行多个测试,只能通过**部分名称匹配**(如上面的 `add`)来批量选择。通过过滤名称来运行多个测试
# 运行所有名称中包含 "add" 的测试
cargo test add
# 运行 tests 模块下的所有测试
cargo test tests::④通过显示指定来忽略某些测试
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = 2 + 2;
assert_eq!(result, 4);
}
/// 标记为 `#[ignore]` 的测试,默认会被跳过
#[test]
#[ignore]
fn expensive_test() {
// 耗时较长的测试逻辑,比如复杂计算、IO 操作等
}
}# 默认运行:仅执行未被 ignore 的测试
cargo test
# 单独运行被 ignore 的测试
cargo test -- --ignored
# 运行所有测试,包括被 ignore 的
cargo test -- --include-ignored3. 测试的组织结构
Rust 社区主要将测试分为两类:
单元测试:聚焦单个模块,可测试私有接口,小而专注。
集成测试:位于库外部,仅通过公共接口使用代码,可联用多个模块,模拟外部使用场景。
编写单元测试和集成测试,可确保代码库无论是独立模块还是整体都能按预期运行。
①单元测试
介绍
单元测试用于隔离小段代码,快速验证其功能是否符合预期。
惯例是将单元测试与被测代码放在同一文件中,并使用
#[cfg(test)]标注的tests模块存放测试函数。
测试模块和
#[cfg(test)]#[cfg(test)]的作用它是一个条件编译属性,标记模块仅在测试模式下(运行
cargo test时)被编译和运行。可以节省正常编译(
cargo build)的时间和空间,避免测试代码被打包到发布版本中。该属性作用于整个模块,不仅包括
#[test]函数,也包括模块内的其他辅助函数。-
单元测试与集成测试的区别
单元测试:与业务代码在同一文件中,必须使用
#[cfg(test)]标记。集成测试:存放在项目根目录下的
tests/目录中,默认就会被视为测试代码,无需额外标记。
// src/lib.rs
// 单元测试模块:仅在 `cargo test` 时编译
#[cfg(test)]
mod tests {
use super::*;
/// 示例测试函数
#[test]
fn it_works() {
let result = 2 + 2;
assert_eq!(result, 4);
}
/// 模块内的辅助函数,同样受 `#[cfg(test)]` 控制
fn test_helper() -> i32 {
10
}
}测试私有函数
// src/lib.rs
/// 对外暴露的加法函数,调用内部私有实现
pub fn add_two(a: i32) -> i32 {
internal_adder(a, 2)
}
/// 私有加法函数:未加 pub 修饰,仅在当前模块可见
fn internal_adder(a: i32, b: i32) -> i32 {
a + b
}
// 测试模块:仅在 cargo test 时编译
#[cfg(test)]
mod tests {
// 引入父模块所有内容,包括私有函数
use super::*;
/// 直接测试私有函数 internal_adder
#[test]
fn internal() {
assert_eq!(4, internal_adder(2, 2));
}
}②集成测试
在 Rust 中,集成测试位于库外部,只能调用对外公开的接口,目的是验证库的各部分能否协同工作。单元测试通过的代码,在集成运行时也可能出现问题,因此集成测试覆盖率同样重要。创建集成测试需先建立
tests目录。
tests目录
tests/目录下的文件无需#[cfg(test)]标记,Cargo 仅在cargo test时编译它们。集成测试文件需要显式
use adder;引入库,只能调用公开接口。运行方式:
cargo test:同时运行单元测试、集成测试和文档测试。只有单元测试成功了后面的才会运行。cargo test --test integration_test:只运行tests/integration_test.rs中的所有测试。
adder/
├── Cargo.toml
├── src/
│ └── lib.rs # 业务代码与单元测试
└── tests/
└── integration_test.rs # 集成测试文件// src/lib.rs
pub fn add_two(a: i32) -> i32 {
a + 2
}
fn internal_adder(a: i32, b: i32) -> i32 {
a + b
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn internal() {
assert_eq!(4, internal_adder(2, 2));
}
}// tests/integration_test.rs
use adder; // 引入库
#[test]
fn it_adds_two() {
assert_eq!(4, adder::add_two(2));
}在集成测试中使用子模块
在 Rust 中,
tests目录下的每个文件都会被编译成独立的单元包,方便按功能分组管理集成测试,同时隔离作用域、贴近用户使用场景。但src目录的模块规则(如mod.rs自动加载)不适用于tests目录。
// 目录结构
// adder/
// ├── src/lib.rs
// └── tests/
// ├── common/
// │ └── mod.rs // 共享辅助函数
// └── integration_test.rs
// tests/common/mod.rs
/// 可在多个集成测试中复用的初始化辅助函数
/// 若直接写common.rs会在测试信息中显示辅助函数,这不是想看到的
pub fn setup() {
// 初始化代码
}
// tests/integration_test.rs
use adder;
// 引入共享模块
mod common;
#[test]
fn it_adds_two() {
// 调用共享的辅助函数
common::setup();
assert_eq!(4, adder::add_two(2));
}二进制单元包的集成测试
二进制单元包(仅含
src/main.rs)无法在tests目录中创建集成测试,也无法被其他包通过use引入。库单元包(src/lib.rs)才能对外暴露函数供外部调用。因此,Rust 二进制项目通常将核心逻辑放在
src/lib.rs中,src/main.rs仅做简单调用。这样,集成测试就能把项目当作库包,通过use访问核心功能,保证逻辑正确后,main.rs的胶水代码自然可以正常工作。