
参考书籍:《Rust权威指南》第2版 Steve Klabnik Carol Nichols 著 毛靖凯 译
一. Cargo
1. 基础命令
cargo new 项目名称
cargo build 编译
cargo run 运行
cargo check检查代码是否能运行。
2. 使用发布配置定制构建
Cargo 有两套常用编译配置:
dev(开发)和release(发布),彼此独立,可分别定制。opt-level控制代码优化强度(0~3):值越高,优化越强、编译越慢、运行越快。可通过
[profile.*]覆盖默认配置,例如修改dev的优化级别。
# Cargo.toml
# 开发配置(默认 cargo build 使用):以编译速度优先,方便调试
[profile.dev]
opt-level = 0 # 0级优化,编译快,保留调试信息
# 发布配置(cargo build --release 使用):以运行性能优先
[profile.release]
opt-level = 3 # 3级优化,编译慢,生成的二进制性能更高
# 自定义示例:修改开发配置的优化级别,折中编译速度和运行性能
[profile.dev]
opt-level = 13. 将包发布在crates.io平台
4. Cargo工作空间
随着项目规模扩大,单个库包可能变得臃肿,需要拆分为多个关联的库包。Cargo 的 工作空间(workspace) 功能,可用于管理多个需要协同开发的关联包。
①创建工作空间
# 1. 创建工作空间根目录并进入
mkdir add
cd add
# 2. 在根目录下创建工作空间配置文件 Cargo.toml
# 这是一个虚拟清单(virtual manifest),不包含 [package] 区域
# 通过 [workspace.members] 指定工作空间的成员包路径
cat > Cargo.toml <<EOF
[workspace]
members = [
"adder",
]
EOF
# 3. 使用 cargo new 创建二进制单元包(adde)
# 该命令会在 add 目录下生成一个名为 adder 的子目录
cargo new adder
# 4. 查看当前目录结构
# 预期结构:
# add/
# ├── Cargo.lock # 工作空间共享的依赖锁定文件
# ├── Cargo.toml # 工作空间配置文件
# ├── adder/ # 二进制包目录
# │ ├── Cargo.toml # 包的配置文件
# │ └── src
# │ └── main.rs # 二进制入口文件
# └── target/ # 工作空间共享的输出目录(编译产物存放于此)
# 5. 构建整个工作空间
# 注意:即使进入 adder 目录执行构建,产物依然会输出到根目录的 target 文件夹中
cargo build
# 补充说明:共享 target 目录的好处
# 工作空间中的包通常是相互依赖的。如果各自拥有独立的 target 目录,
# 在构建过程中就需要反复编译工作空间中的其余包。共享一个 target 目录
# 可以有效避免这些不必要的重复编译过程,提升构建效率。②在工作空间中创建第二个包
介绍
# 1. 更新工作空间成员配置
# 在根目录的 Cargo.toml 文件中添加 "add_one" 路径
cat > Cargo.toml <<EOF
[workspace]
members = [
"adder",
"add_one",
]
EOF
# 2. 生成新的库单元包 add_one
# 使用 --lib 标志创建一个库而不是二进制文件
cargo new add_one --lib
# 3. 在 add_one/src/lib.rs 中添加 add_one 函数
cat > add_one/src/lib.rs <<EOF
pub fn add_one(x: i32) -> i32 {
x + 1
}
EOF
# 4. 让二进制包 adder 依赖 add_one
# 在 adder/Cargo.toml 中添加路径依赖
cat > adder/Cargo.toml <<EOF
[package]
name = "adder"
version = "0.1.0"
edition = "2021"
[dependencies]
add_one = { path = "../add_one" }
EOF
# 5. 在 adder/src/main.rs 中使用 add_one 包
cat > adder/src/main.rs <<EOF
use add_one;
fn main() {
let num = 10;
println!(
"Hello, world! {num} plus one is {}!",
add_one::add_one(num)
);
}
EOF
# 6. 构建整个工作空间
# 在 add 根目录下运行
cargo build
# 7. 运行二进制单元包 adder
# 使用 -p 参数指定要运行的包
cargo run -p adder在工作空间中依赖外部包
# 1. 在 add_one 包中添加 rand 依赖
# 编辑 add_one/Cargo.toml,在 [dependencies] 区域加入 rand 包
cat > add_one/Cargo.toml <<EOF
[dependencies]
rand = "0.8.5"
EOF
# 2. 在 add_one 源码中使用 rand (仅为演示,实际未调用)
# 编辑 add_one/src/lib.rs
cat > add_one/src/lib.rs <<EOF
use rand;
pub fn add_one(x: i32) -> i32 {
x + 1
}
EOF
# 3. 构建整个工作空间
# 此时 Cargo 会下载并编译 rand,且 rand 会被记录到根目录的 Cargo.lock 中
cargo build
# 4. 演示错误:直接在 adder 中使用 rand 会导致编译失败
# 编辑 adder/src/main.rs,尝试引入 rand
cat > adder/src/main.rs <<EOF
use add_one;
use rand; // 试图使用工作空间中的 rand
fn main() {
let num = 10;
println!(
"Hello, world! {num} plus one is {}!",
add_one::add_one(num)
);
}
EOF
# 运行构建,会产生 unresolved import 错误
cargo build
# 5. 解决错误:显式在 adder 中添加 rand 依赖
# 编辑 adder/Cargo.toml,添加 rand 依赖
cat > adder/Cargo.toml <<EOF
[package]
name = "adder"
version = "0.1.0"
edition = "2021"
[dependencies]
add_one = { path = "../add_one" }
rand = "0.8.5" # 显式声明依赖
EOF
# 6. 再次构建
# 这次构建会成功,Cargo 不会重复下载 rand,而是复用工作空间中已有的版本
cargo build为工作空间添加测试
# 接上一节,为 add_one 包添加单元测试
# 1. 编辑 add_one/src/lib.rs,在原有函数下方添加测试模块
cat >> add_one/src/lib.rs <<EOF
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
assert_eq!(3, add_one(2));
}
}
EOF
# 2. 在 add 根目录下运行 cargo test
# 在工作空间根目录下运行此命令,会一次性构建并运行所有成员包(add_one 和 adder)的测试
cargo test
# 3. 仅运行特定包的测试
# 如果只想运行 add_one 包的测试,可以使用 -p 参数指定包名
cargo test -p add_one
# 【上下文说明】
# 上一轮对话中已经完成了以下操作:
# 1. 在 add_one/Cargo.toml 中添加了 rand = "0.8.5" 依赖
# 2. 在 adder/Cargo.toml 中也添加了 rand = "0.8.5" 依赖以解决编译报错
# 当前步骤是在此基础上,为库包 add_one 编写并运行单元测试。5. 使用cargo install安装二进制文件
6. 使用自定义命令扩展
二. 变量、常量和隐藏
1. 变量
Rust 中的变量(
let x = 2)默认是不可变的,这是其安全设计的重要部分。要声明一个可变变量,需在声明时加上mut关键字,例如let mut x = 5;。这使得变量x的值在后续可以被修改。不可变是默认行为:这能防止值被意外更改导致的 Bug,尤其在并发场景下,并能使代码逻辑更清晰。
显式可变性:通过
mut关键字显式声明可变性,是一种“深思熟虑的可变性”,在提供灵活性的同时,维持了代码的安全性与清晰意图。
2. 常量
声明与不可变性:常量必须用
const关键字声明,且必须显式标注类型。它不仅在默认状态下不可变,而且是永远不可变的,因此不允许使用mut关键字。作用域:常量可以被声明在包括全局作用域在内的任何作用域,这便于程序的不同部分共享数据。
值的约束:常量只能绑定到一个在编译时就能确定的常量表达式,不能绑定函数返回值或其他需要在运行时计算的值。
命名约定:Rust 的命名约定是使用全大写字母,并用下划线分隔单词来命名常量。
例如,
const THREE_HOURS_IN_SECONDS: u32 = 60 * 60 * 3;就是一个常量声明。编译器会在编译时计算出表达式60 * 60 * 3的结果。将程序中的硬编码值定义为常量,能提高代码的可读性与可维护性,便于后续的理解和统一修改。
3. 隐藏
变量遮蔽是 Rust 中的一项特性,它允许你通过再次使用
let关键字来重新声明一个已有的同名变量,从而创建全新的变量实例。这个新变量会“遮蔽”前一个,后续对变量名的引用都将指向最新的声明。变量遮蔽与将变量声明为
mut有本质区别。变量遮蔽能让你在保持原变量不可变性的同时,在后续重新绑定一个完全不同类型的新值。例如,你可以先用变量名spaces存储一个字符串,之后在另一行用同名spaces存储这个字符串的长度(一个数值)。而如果声明为可变变量(
mut),虽然其值可变,但类型一旦确定就无法更改。尝试为可变变量赋一个不同类型的值(例如,从字符串改为整数)会导致编译错误,因为 Rust 是静态类型语言。
4. 注释
Rust 使用双斜杠
//来编写注释,编译器会忽略这些内容。注释的主要作用是向阅读代码的人提供解释和说明。注释通常有两种放置方式:一是放在代码行的末尾,对同一行代码进行说明;更常见的格式是在需要说明的代码块上方单独放置一行或多行注释。当注释需要跨越多行时,必须在每一行的开头都加上
//。Rust 还有一种功能更强大的文档注释,专门用于生成项目文档,这将在后续章节中详细介绍。
三. 数据类型
Rust 是静态类型语言,这意味着它在编译时需要知道所有变量的具体类型。编译器在多数情况下能根据绑定和使用方式自动推导类型,但在特定场景下则必须显式标注类型。
例如,当使用
parse()方法将String类型(如"42")转换为数值类型时,编译器无法自动推断目标数值类型(如i32或u32),必须像let guess: u32 = ...一样给出明确标注。如果省略标注,编译时将提示“type annotations needed”错误,并建议为变量指定一个类型。后续我们将介绍不同数据类型的标注方式。本章的数据类型都是固定大小,存储在栈上,离开作用域弹出栈空间。在新作用域需要使用这些值,则复制一个新的去使用。
1. 标量类型
Rust 中的标量类型是代表单个值的类型统称。其内置了四种基础标量类型:整数、浮点数、布尔值和字符。
①整数

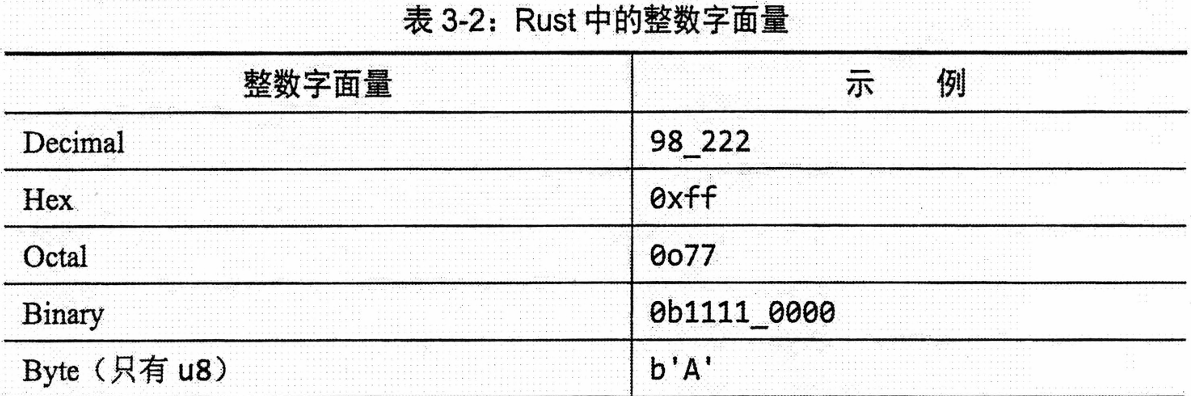
Rust 的整数类型分为有符号(以
i开头,如i8、i32)和无符号(以u开头,如u8、u32)两大类。有符号整数可表示负数,无符号整数则只能表示非负数。每种类型都有明确的位长度(如8、16、32、64、128位),以及两种平台相关类型:isize和usize,其长度(32位或64位)由程序运行的计算机架构决定。一个n位的有符号整数(如i8)可表示的范围是从 -(2ⁿ⁻¹) 到 2ⁿ⁻¹ - 1,而无符号整数(如u8)的表示范围则是从 0 到 2ⁿ - 1。在代码中书写整数字面量时,可以添加类型后缀(如
57u8)并使用下划线_作为分隔符以提高可读性(如1_000)。如果无法确定使用哪种类型,i32通常是良好的默认选择,因为它在多数情况下运算速度最快。isize和usize则主要用于集合的索引。当尝试为整数变量赋予一个超出其类型表示范围的值时,就会发生整数溢出。Rust 对此的处理方式取决于编译模式:在调试(debug)模式下,溢出会触发程序 panic(即因错误而终止);在发布(release)模式下,则会执行二进制补码环绕,即超出最大值的数值会“环绕”到该类型的最小值重新开始(例如,对于
u8类型,256 会变为 0)。如果需要显式处理溢出,标准库为数值类型提供了多种方法:
wrapping_*系列方法会执行环绕操作;checked_*方法在溢出时返回None;overflowing_*方法会返回结果和一个指示是否溢出的布尔值;saturating_*方法则会将结果限制在该类型可表示的最小值或最大值。
②浮点数
Rust 提供了两种浮点数(即带小数的数字)类型:f32(单精度,占 32 位)和 f64(双精度,占 64 位)。在现代 CPU 上,两者的运算效率相近,但由于
f64拥有更高的精度,Rust 默认会将浮点数字面量(如2.0)的类型推导为f64。这两种类型均遵循 IEEE-754 标准。
③数值运算
Rust 支持所有数值类型进行加、减、乘、除和取余这五种基本数学运算。整数除法有一个重要特性:它会向零截断,即直接舍弃小数部分。例如,
-5 / 3的结果是-1,而不是向下取整的-2。在代码中,每个使用运算符的表达式都会计算出结果,然后被绑定到赋值语句(
let)左侧的变量上。Rust 所支持的所有运算符可在附录 B 中查阅。
④布尔类型
Rust 的布尔类型(
bool)只有两个值:true和false,占用 1 个字节内存。在声明变量时,可使用bool关键字进行显式类型标注。它最主要的用途是作为if表达式中的条件判断依据。
⑤字符类型
Rust 的
char类型用于表示单个字符,占 4 个字节,是一个 Unicode 标量值。它可以表示字母(如'z')、数字、象形文字(如中文),甚至表情符号(如'😻')。在代码中,char字面量使用单引号定义,这与使用双引号的字符串字面量不同。需要特别注意的是,由于 Unicode 中并没有明确的“字符”概念,一个我们直觉上的“字形”(例如一个带重音符号的字母)在 Rust 中可能由多个
char值组合表示。这个主题将在后续关于字符串的章节中详细讨论。
2. 复合类型
复合类型能将多个不同类型的值组合成一个类型。Rust 内置了两种基础的复合类型:元组 (tuple) 和数组 (array)。
①元组
Rust 中的元组是一种固定长度的复合类型,可用于组合多个不同类型的值。
// src/main.rs
// 元组是一种复合类型,可组合不同类型的值,长度固定。
// 示例1:创建元组,并可选择性地添加类型标注
fn main() {
// 创建元组,包含i32、f64、u8三种类型的值
let tup: (i32, f64, u8) = (500, 6.4, 1);
// 示例2:通过模式匹配(解构)获取元组中的单个值
let (x, y, z) = tup; // 将tup解构为x、y、z三个变量
println!("The value of y is: {y}"); // 输出y的值:6.4
// 示例3:通过索引(点号.)访问元组元素,索引从0开始
let five_hundred = tup.0; // 访问第一个元素
let six_point_four = tup.1; // 访问第二个元素
let one = tup.2; // 访问第三个元素
println!("Access by index: {}, {}, {}", five_hundred, six_point_four, one);
// 示例4:单元元组,表示为(),用于空值或空的返回类型
let unit: () = (); // 显式声明单元元组
println!("Unit tuple: {:?}", unit); // 输出: ()
// 表达式无返回值时隐式返回单元元组
let implicit_unit = {
let _ = 5; // 无返回值的表达式
};
println!("Implicit unit: {:?}", implicit_unit); // 输出: ()
}②数组
// src/main.rs
// Rust数组是一种存储在栈上、长度固定、元素类型相同的集合。
fn main() {
// 基本数组声明
let a = [1, 2, 3, 4, 5]; // 类型推导为[i32; 5],包含5个i32类型元素
// 数组类型标注格式:[元素类型; 元素数量]
let b: [i32; 5] = [1, 2, 3, 4, 5]; // 显式指定类型
// 简化初始化:创建所有元素值相同的数组
let c = [3; 5]; // 等价于[3, 3, 3, 3, 3],类型为[i32; 5]
// 示例:存储一年12个月份名称
let months = ["January", "February", "March", "April", "May", "June",
"July", "August", "September", "October", "November", "December"];
// 访问数组元素:通过索引(从0开始)
let first = months[0]; // "January"
let second = months[1]; // "February"
println!("First month: {}", first);
println!("Array a: {:?}", a);
println!("Array c: {:?}", c);
}// src/main.rs
// 演示尝试通过用户输入索引访问数组元素,并说明Rust对越界访问的运行时检查与安全处理。
use std::io; // 引入标准输入/输出库
fn main() {
// 定义一个包含5个元素的数组
let a = [1, 2, 3, 4, 5];
println!("Please enter an array index.");
// 创建一个可变String来存储用户输入
let mut index = String::new();
// 从标准输入读取一行
io::stdin()
.read_line(&mut index)
.expect("Failed to read line");
// 将输入字符串转换为 usize 类型(用于数组索引)
let index: usize = index
.trim() // 去除首尾空白字符
.parse() // 解析为数值
.expect("Index entered was not a number"); // 若非数字则报错
// 【核心】尝试用用户输入的索引访问数组元素
// 如果输入的索引在数组边界内(0到4),则能安全获取到该元素。
// 如果索引 >= 数组长度(本例为5),程序会在**运行时** panic,
// 并给出明确错误信息:"index out of bounds: the len is 5 but the index is ..."
// 这体现了Rust的安全原则:立即中断程序,防止非法内存访问。
let element = a[index];
// 只有索引合法时,才会执行到这一行并打印结果
println!("The value of the element at index {index} is: {element}");
}
// === 运行结果说明(对应图片内容) ===
// 1. 输入合法索引(0-4):程序正常输出对应元素值。
// 2. 输入越界索引(如10):程序 panic,输出错误信息并终止,最后的 println! 不会被执行。
//
// 错误示例:
// thread 'main' panicked at 'index out of bounds: the len is 5 but the index is 10', src/main.rs:19:19
//
// 这与其他一些底层语言(如C/C++)形成对比,后者在越界访问时往往会导致未定义行为。
// Rust 通过在运行时检查数组边界,确保了内存安全,即使这会以程序 panic 为代价。
// 第9章将讨论如何通过更灵活的错误处理来避免 panic,并编写更健壮的代码。四. 函数
1. 函数定义
Rust 中函数通过
fn关键字定义,其基本结构为函数名、圆括号和标识函数体的花括号。通过函数名加圆括号即可调用函数。Rust 的官方编码规范采用蛇形命名法,即函数与变量名应全部使用小写字母,并用下划线分隔单词。
Rust 不关心函数在代码中的定义先后顺序,只要其定义在使用它的作用域内是可见的即可。
在Rust中,函数的参数是函数签名的一部分,属于特殊的变量。调用函数时必须为这些参数提供具体的值。通常我们无需严格区分参数变量(parameter)和传入的具体值(argument),可统一称作“参数”。
Rust 的一个重要设计是:在函数签名中必须为每个参数显式声明类型。这是经过深思熟虑的决定,它使编译器无需依赖其他代码就能明确知道你的意图,并能在类型已知的前提下提供更精准、有用的错误提示信息。函数可以通过逗号分隔来定义多个参数。
// src/main.rs
// main函数:程序入口点
fn main() {
// 调用print_labeled_measurement函数,传入整数值5和字符'h'
print_labeled_measurement(5, 'h');
}
// print_labeled_measurement函数:打印带标签的测量值
// 参数:value - 32位整数类型的测量值
// unit_label - 字符类型的单位标签
fn print_labeled_measurement(value: i32, unit_label: char) {
// 使用println!宏按照指定格式输出测量信息
println!("The measurement is: {value}{unit_label}");
}2. 语句和表达式
Rust 的函数体由一系列语句构成,并可选择以一个表达式结束。作为一门“基于表达式的语言”,Rust 将语句与表达式视为两个根本不同的概念,这是其重要的语言特性。
语句 执行某些操作但不返回值。
表达式 在执行后会产生一个结果值。大多数 Rust 代码都是由表达式组成的。
// src/main.rs
// 演示 Rust 中语句与表达式的核心区别
fn main() {
// ====================
// 1. 语句不返回值
// ====================
// `let y = 6;` 是一条语句,它执行绑定操作,但不返回任何值。
// 因此,你不能将一条 `let` 语句赋值给另一个变量。
// 下面这行代码会引发编译错误(对应图1、图2的错误信息):
// let x = (let y = 6);
// 编译器会提示:expected expression, found statement (`let`)
println!("语句不返回值,因此无法用于赋值。");
// ====================
// 2. 表达式会计算出一个值
// ====================
// 花括号 `{}` 可以创建一个代码块,它本身也是一个表达式。
// 整个代码块的值,等于其内部**最后一个表达式**的计算结果。
let y = {
// 这是一个语句,无返回值
let x = 3;
// 这是一个表达式,计算结果为 `x + 1` 即 4
// 【关键点】此处末尾**没有**分号,因此整个代码块的值是 4
x + 1 // <- 无分号,是表达式
};
// 变量 y 被绑定为代码块表达式的结果,即 4
println!("表达式代码块的结果 y = {}", y); // 输出: y = 4
// ====================
// 3. 错误示例:在表达式后添加分号
// ====================
// 如果在表达式末尾添加分号,它会转变为语句,不再返回值。
// 下面的代码块将不返回任何有效值,因此不能用于初始化变量。
// let z = {
// let x = 3;
// x + 1; // <- 有分号,是语句,不返回值
// };
// 尝试编译上述代码会得到类型不匹配的错误。
println!("表达式末尾加分号会使其变成语句,从而不返回值。");
// ====================
// 4. 函数返回值
// ====================
// 在 Rust 中,函数的返回值等同于函数体中最后一个表达式的值。
// 可以使用 `return` 关键字提前返回,但通常隐式返回更常见。
let result = five();
println!("函数 five() 的返回值是: {}", result); // 输出: 5
let plus_one_result = plus_one(5);
println!("plus_one(5) 的结果是: {}", plus_one_result); // 输出: 6
}
// 这是一个返回 i32 类型的函数
// 函数体由单个表达式 `5` 构成,因此该函数的返回值是 5
fn five() -> i32 {
5 // 无分号,是表达式,作为函数返回值
}
// 接收一个参数,并将其加 1 后返回
fn plus_one(x: i32) -> i32 {
x + 1 // 无分号,是表达式,作为函数返回值
// 如果写成 `x + 1;`,将导致编译错误,因为这是一个语句,不符合函数声明的返回类型 `-> i32`。
}3. 函数的返回值
// src/main.rs
// 函数可以向调用代码返回值,其类型在箭头(->)后声明。
// 返回值等于函数体最后一个表达式的值,也可用 return 提前返回,但通常隐式返回更常见。
// 示例1:five 函数,无参数,返回 i32 类型的 5
fn five() -> i32 {
5 // 函数体仅为一个表达式 5,它被隐式返回
}
// 示例2:plus_one 函数,接收一个 i32 参数,返回该参数加 1 的结果
fn plus_one(x: i32) -> i32 {
x + 1 // 表达式 x + 1 的结果被隐式返回
// 重要:此处绝不能加分号,否则将变为语句,不再返回值,导致类型不匹配错误。
}
// 错误示例:在表达式后误加分号
// fn plus_one(x: i32) -> i32 {
// x + 1; // 错误:加上分号使表达式变为语句,函数默认返回单元类型 `()`,与声明的 `i32` 冲突
// }
fn main() {
// 使用 five() 的返回值初始化变量 x
let x = five();
println!("The value of x is: {x}"); // 输出: The value of x is: 5
// 使用 plus_one(5) 的返回值初始化变量 y
let y = plus_one(5);
println!("The value of y is: {y}"); // 输出: The value of y is: 6
}五. 控制流
1. if表达式
①基本形式
// src/main.rs
// 1. if表达式的基本结构
// if表达式允许根据条件执行不同的代码分支,条件必须是bool类型。
// 语法结构:`if 条件 { ... } else { ... }`
fn main() {
// 示例1:基本if-else
let number = 3;
if number < 5 { // 条件必须是bool值
println!("condition was true");
} else {
println!("condition was false");
}
// 2. 条件必须为bool类型
// 以下代码会编译错误,因为Rust不会自动将整数转换为布尔值
// let number = 3;
// if number { // 错误:expected `bool`, found integer
// println!("number was three");
// }
// 正确的做法是显式比较
let number = 3;
if number != 0 { // 正确:显式比较产生bool值
println!("number was something other than zero");
}
// 3. 多重条件判断:使用else if
// Rust会依次检查条件,执行第一个为真的分支
let number = 6;
if number % 4 == 0 {
println!("number is divisible by 4");
} else if number % 3 == 0 {
println!("number is divisible by 3"); // 执行此分支
} else if number % 2 == 0 {
println!("number is divisible by 2"); // 不会执行,因为前面已匹配
} else {
println!("number is not divisible by 4, 3, or 2");
}
// 注意:Rust只会执行第一个条件为真的分支,找到后不再检查其他条件
}
// 补充说明:
// 1. 条件表达式必须产生bool值,这是Rust与Ruby/JavaScript等语言的重要区别
// 2. 过多的else if会使代码混乱,第6章将介绍更强大的match表达式来处理多重分支
// 3. if表达式可以返回值,但每个分支必须返回相同类型②let if
// src/main.rs
// 在 let 语句中使用 if
// 因为 if 是一个表达式,所以可以在 let 语句的右侧用它来生成一个值。
// 示例 1: 正确用法 - 所有分支返回相同类型
fn main() {
// 1. 基本 if-else
let condition = true;
let number = if condition { 5 } else { 6 }; // if 表达式的值被绑定到 number
println!("The value of number is: {}", number); // 输出: 5
// 2. 代码块的值是其最后一个表达式的值
let x = {
let y = 10;
y + 1 // 无分号,这是一个表达式,其值就是代码块的值
};
println!("The value of x is: {}", x); // 输出: 11
// 3. 条件必须为 bool 类型
let check = true;
if check { // 正确:条件为 bool 值
println!("Condition is true.");
}
// 示例 2: 错误用法 - 分支类型不一致(此段代码会导致编译错误)
// 如果取消注释,编译时会提示错误: "if and else have incompatible types"
// let another_condition = true;
// let number2 = if another_condition {
// 5 // i32 类型
// } else {
// "six" // &str 类型 (字符串切片)
// // 错误:if 与 else 分支返回了不同的类型
// };
// println!("The value of number2 is: {}", number2);
}
// 核心要点(基于图片内容):
// 1. if 是表达式,其值等于最终执行的那个代码块的值。
// 2. 在 let 语句中使用 if 时,整个 if 表达式的值会被绑定到变量。
// 3. if 和 else 分支的返回值必须是**相同的类型**。这是 Rust 编译器在编译时进行类型检查所必需的。
// 4. 要求类型一致是为了保证在编译时就能确定变量的确切类型,从而实现内存安全和高性能。
// 5. 如果允许分支类型不同,变量的类型将只能在运行时确定,这会使得编译器实现复杂化,并可能牺牲 Rust 提供的安全保障。2. 循环
①loop
// src/main.rs
// 演示Rust中loop循环及其相关特性,包括break、continue、从循环中返回值以及嵌套循环与循环标签。
fn main() {
// 1. 基本loop循环:无限循环,可使用Ctrl+C终止
// loop {
// println!("again!"); // 会不断打印"again!"
// }
// 2. 使用break退出循环
let mut count = 0;
loop {
count += 1;
if count > 5 {
break; // 当count>5时退出循环
}
println!("Count: {}", count);
}
// 3. 从loop循环中返回值
// 在break表达式后跟要返回的值,该值会被赋予接收循环结果的变量
let mut counter = 0;
let result = loop {
counter += 1;
if counter == 10 {
break counter * 2; // 当counter等于10时,返回counter*2的值
}
};
println!("The result is {}", result); // 输出: 20
// 4. 嵌套循环与循环标签
// 循环标签以单引号开头,用于在嵌套循环中指定break/continue的作用目标
let mut count = 0;
'counting_up: loop { // 外层循环标签'counting_up
println!("count = {}", count);
let mut remaining = 10;
loop { // 内层循环
println!("remaining = {}", remaining);
if remaining == 9 {
break; // 无标签的break只退出内层循环
}
if count == 2 {
break 'counting_up; // 带标签的break退出外层循环
}
remaining -= 1;
}
count += 1;
}
println!("End count = {}", count); // 当count=2时退出外层循环,输出End count = 2
}②while
// src/main.rs
// 演示Rust中while条件循环的使用
fn main() {
// 定义并初始化一个可变变量number,赋值为3
let mut number = 3;
// while条件循环:在每次执行循环体之前都判断条件
// 当条件为真(number不等于0)时,执行循环体内的代码
// 当条件为假时,退出循环
while number != 0 {
// 打印当前number的值
println!("{number}!");
// 将number减1
number = number - 1;
}
// 循环结束后打印特定的消息
println!("LIFTOFF!!!");
}
// 核心要点(基于图片内容):
// 1. while循环是一种常见的循环模式,它在每次执行循环体之前都判断一次条件
// 2. 如果条件为真,则执行循环体中的代码
// 3. 如果条件为假,就退出当前循环
// 4. 相比使用loop、if、else和break来模拟条件循环,while结构更简洁清晰③for
// src/main.rs
// 示例3-4:使用 while 结构遍历数组
// 这种方式需要手动管理索引,容易因索引错误或条件更新不及时导致程序 panic
fn main() {
// 定义数组
let a = [10, 20, 30, 40, 50];
// 初始化索引变量
let mut index = 0;
// while 循环遍历数组
while index < 5 { // 注意:此处条件为硬编码,若数组长度改变,此条件也需要相应更新
println!("the value is: {}", a[index]);
index = index + 1; // 手动递增索引
}
}
// 示例3-5:使用 for 循环遍历集合
// 这种方式更安全、简洁,无需手动管理索引,避免越界访问
fn main() {
let a = [10, 20, 30, 40, 50];
// for 循环自动遍历数组每个元素
for element in a { // 无需索引,直接获取元素
println!("the value is: {element}");
}
// 示例3-3 重构:使用 for 循环配合 Range
// Range 生成数字序列,rev() 方法反转序列实现倒数
for number in (1..4).rev() { // (1..4) 生成 1,2,3,rev() 反转后为 3,2,1
println!("{number}!");
}
println!("LIFTOFF!!!");
}
// 核心要点:
// 1. while 循环遍历数组需手动管理索引,易出错,效率较低
// 2. for 循环遍历集合更安全、简洁,是 Rust 中最常用的循环结构
// 3. 配合 Range 类型,for 循环可轻松实现各种数字序列的遍历
// 4. 使用 rev() 方法可反转 Range 序列,方便实现倒序遍历3. match
①介绍
Rust 的控制流结构
match极其强大,它允许你将一个值与一系列模式进行比较,并基于匹配到的模式执行相应的代码。其强大之处不仅在于模式的丰富表现力(可包含字面量、变量、通配符等),更在于编译器会强制检查所有可能的情况都必须得到处理,从而保证了代码的完备性与安全。可以将
match表达式的工作机制想象为一台硬币分类机:硬币会沿着设有不同大小孔洞的轨道滑动,并掉入第一个与之大小匹配的孔中。类似地,值会依次通过match中的各个模式,当遇到第一个“匹配”的模式时,其关联的代码块便会被执行,该值也可在此代码块中被使用。
// src/main.rs
// 示例 6-3: 枚举与 `match` 表达式
// 定义一个表示美国硬币的枚举
enum Coin {
Penny,
Nickel,
Dime,
Quarter,
}
// 函数 `value_in_cents`:根据硬币类型返回对应分值(美分)
fn value_in_cents(coin: Coin) -> u8 {
// `match` 表达式:将 `coin` 的值与一系列模式进行比较
// 关键机制:1. 可匹配任何类型(不限于布尔值,区别于`if`)
// 2. 按分支顺序逐一尝试匹配
// 3. 执行第一个匹配成功的分支代码
match coin {
// 分支语法:`模式 => 关联的代码`
// 分支代码是一个表达式,其计算结果将作为整个 `match` 的结果返回
Coin::Penny => 1, // 匹配 `Coin::Penny`,返回 1
Coin::Nickel => 5, // 匹配 `Coin::Nickel`,返回 5
Coin::Dime => 10, // 匹配 `Coin::Dime`,返回 10
Coin::Quarter => 25,// 匹配 `Coin::Quarter`,返回 25
}
// 编译器强制要求:`match` 必须覆盖枚举的所有可能变体(穷尽性检查)
}
// 扩展示例:在匹配分支中执行多行代码
// 当分支代码超过一行时,需使用花括号 `{}` 包裹,此时可省略分支后的逗号
fn value_in_cents_with_log(coin: Coin) -> u8 {
match coin {
Coin::Penny => {
// 多行代码块
println!("Lucky penny!");
1 // 代码块的最后一个表达式作为返回值
}
// 其他单行分支保持简洁写法
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter => 25,
}
}②绑定值的模式
// 示例 6-4: 定义 Coin 和 UsState 枚举
// 背景:1999-2008年间,美国25美分硬币(Quarter)有各州设计,故在Quarter变体中存储州信息。
// 定义 UsState 枚举,列举美国各州(此处简化,只展示部分)
#[derive(Debug)] // 派生Debug trait,使枚举可打印
enum UsState {
Alabama,
Alaska,
// 其他州省略...
}
// 定义 Coin 枚举,表示美国硬币类型
enum Coin {
Penny, // 1分硬币
Nickel, // 5分硬币
Dime, // 10分硬币
Quarter(UsState), // 25分硬币,额外存储对应的州信息
}
// 示例 6-5: 通过匹配分支提取枚举变体中的值
// 功能:根据硬币类型返回对应分值(美分),对Quarter变体额外打印州名
fn value_in_cents(coin: Coin) -> u8 {
match coin {
// 基本变体直接返回对应分值
Coin::Penny => 1,
Coin::Nickel => 5,
Coin::Dime => 10,
// 匹配到Quarter变体时,用变量`state`绑定其内部UsState值
// 然后可在分支代码中使用该绑定,例如打印州名
Coin::Quarter(state) => {
println!("这是一枚来自{:?}州的25美分硬币!", state);
25
}
}
}
fn main() {
// 创建一枚阿拉斯加州设计的25美分硬币
let alaska_quarter = Coin::Quarter(UsState::Alaska);
// 调用函数,将匹配到Quarter分支,state绑定为UsState::Alaska
// 输出:这是一枚来自Alaska州的25美分硬币!
// 函数返回:25
let value = value_in_cents(alaska_quarter);
println!("这枚硬币的面值是{}美分。", value);
}③匹配Option<T>
// src/main.rs
// 示例 6-5: 使用 `match` 表达式处理 `Option<i32>`
// 功能:接收一个 `Option<i32>` 值,有值则加1,无值则返回 `None`
fn plus_one(x: Option<i32>) -> Option<i32> {
// 使用 `match` 表达式匹配 `Option<T>` 的两种变体
match x {
// 匹配 `None` 模式,表示无值,直接返回 `None`
None => None, // ①
// 匹配 `Some(i)` 模式,`i` 绑定 `Some` 内部的值,返回 `Some(i + 1)`
Some(i) => Some(i + 1), // ②
}
}
fn main() {
// 创建一个 `Some(5)` 的 `Option<i32>` 值
let five = Some(5);
// 调用 `plus_one` 函数,传入 `Some(5)`,预期得到 `Some(6)`
let six = plus_one(five); // ③
// 调用 `plus_one` 函数,传入 `None`,预期得到 `None`
let none = plus_one(None); // ④
}
/*
* 核心执行过程分析(对应图片内容):
* 1. 当调用 `plus_one(five)` 时,参数 `x` 被绑定为 `Some(5)`。
* 2. 进入 `match` 表达式,依次尝试匹配分支:
* - 尝试匹配 `None` 分支,`Some(5)` 无法匹配,继续下一个分支。 // 对应图片分析1
* - 匹配 `Some(i)` 分支成功,`i` 绑定为 `5`,执行 `Some(i + 1)` 返回 `Some(6)`。 // 对应图片分析2
* 3. 当调用 `plus_one(None)` 时,参数 `x` 为 `None`,进入 `match` 表达式:
* - 匹配 `None` 分支成功,直接返回 `None`,其他分支跳过。 // 对应图片分析3
*
* 设计思想总结:
* 1. `match` 表达式与枚举结合,是 Rust 中常见的模式匹配套路。
* 2. 匹配枚举变体,可将其内部值绑定到变量,并基于此执行相应代码。
* 3. 此模式能安全、清晰地处理所有可能情况,深受社区喜爱。 // 对应图片总结4
*/④匹配必须穷举所有可能性
// src/main.rs
// 核心概念:Rust 的 `match` 表达式必须是**穷尽**的,即分支必须覆盖所有可能值。
// 编译器会在编译时强制检查,如果存在未覆盖的情形,将报错并指出具体缺失的模式。
// ====================
// 错误示例:未覆盖 `None` 的 `plus_one` 函数
// ====================
// 此函数意图对 `Option<i32>` 进行加1操作,但只处理了 `Some` 变体,遗漏了 `None`。
// 尝试编译以下代码将导致错误。
/*
fn plus_one(x: Option<i32>) -> Option<i32> {
match x { // 开始匹配 x
Some(i) => Some(i + 1), // 只处理了 Some(i) 的情况
// 错误:缺少处理 `None` 的分支
} // match 结束
}
*/
// 编译错误信息(精简自图片1):
// error[E0004]: non-exhaustive patterns: `None` not covered
// --> src/main.rs:3:15
// |
// 3 | match x {
// | ^ pattern `None` not covered
// |
// note: `Option<i32>` defined here
// help: 确保通过添加通配符分支或显式模式来处理所有情形,例如:
// |
// 4 | Some(i) => Some(i + 1),
// 5 | None => todo!(), // 或 panic!("处理None") 等
// |
// ====================
// 正确示例:处理了所有情形的 `plus_one` 函数
// ====================
// 必须为 `Option<T>` 的两个变体(`Some(T)` 和 `None`)都提供处理分支。
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
Some(i) => Some(i + 1), // 有值则加1
None => None, // 无值则返回 None
}
}
fn main() {
let five = Some(5);
let six = plus_one(five); // 得到 Some(6)
let none = plus_one(None); // 得到 None
}
// ====================
// 核心总结(基于图片2内容)
// ====================
// 1. 穷尽性:Rust 的匹配是穷尽的,必须列出所有可能性以保证代码有效。
// 2. 编译器辅助:Rust 能确切指出哪些模式被遗漏,帮助开发者完善逻辑。
// 3. 安全价值:对于 `Option<T>`,强制处理 `None` 避免了“价值数十亿美金的空值错误”,
// 无需在运行时怀疑值是否存在,从类型系统层面保证了安全。⑤通配符及_占位符
// src/main.rs
// 核心概念:在 `match` 表达式中,可以使用通配模式来处理剩余所有值
// 通常用于为特定值定制行为,并为其余值提供默认行为
// 注意:通配分支必须放在最后,否则会阻止后续分支执行
// 示例1:使用名为 `other` 的通配变量,捕获剩余值并传入函数
// 此模式满足 match 的穷尽性要求
fn example_with_other() {
let dice_roll = 9;
match dice_roll {
3 => add_fancy_hat(), // 特定值 3
7 => remove_fancy_hat(), // 特定值 7
other => move_player(other), // 通配模式,绑定剩余值到变量 other
}
fn add_fancy_hat() {}
fn remove_fancy_hat() {}
fn move_player(num_spaces: u8) {}
}
// 示例2:使用下划线 `_` 通配模式,忽略剩余值且不绑定变量
// 适用于不需要使用匹配值的情况
fn example_with_underscore_reroll() {
let dice_roll = 9;
match dice_roll {
3 => add_fancy_hat(), // 特定值 3
7 => remove_fancy_hat(), // 特定值 7
_ => reroll(), // 通配模式 `_`,匹配任意值但不绑定
}
fn add_fancy_hat() {}
fn remove_fancy_hat() {}
fn reroll() {}
}
// 示例3:使用下划线 `_` 和单元值 `()` 表示忽略剩余值且不执行任何操作
// 单元值 `()` 表示空操作
fn example_with_underscore_ignore() {
let dice_roll = 9;
match dice_roll {
3 => add_fancy_hat(), // 特定值 3
7 => remove_fancy_hat(), // 特定值 7
_ => (), // 通配模式 `_` 搭配单元值,忽略剩余值且不运行代码
}
fn add_fancy_hat() {}
fn remove_fancy_hat() {}
}
/*
* 核心总结(基于四张图片内容):
* 1. 通配模式有两种:变量(如 `other`)可绑定值,下划线(`_`)忽略值不绑定
* 2. 通配分支必须置于最后,否则后续分支无法运行
* 3. 使用 `_` 时,Rust 不会因未使用变量而发出警告
* 4. 可以使用单元值 `()` 表示不执行任何操作
* 5. 这些模式都满足了 match 表达式必须穷尽所有可能性的要求
* 6. 下划线 `_` 是一种特殊模式,它匹配任意值但不绑定,告知编译器我们不使用该值
* 7. 后续第 18 章将介绍更多关于模式与匹配的知识
*/4. 简单控制流if let
// src/main.rs
// 示例 6-6: 使用 match 表达式处理 Option<u8> 值
// 功能:当值为 Some 变体时,打印其内部值;值为 None 时忽略
// 缺点:必须添加通配分支 `_ => ()` 来满足穷尽性,代码略显冗余
let config_max = Some(3u8);
match config_max {
Some(max) => println!("The maximum is configured to be {}", max),
_ => (), // 为满足穷尽性而添加,但在此场景下显得多余
}
// 使用 if let 语法实现相同功能,更加简洁
// 功能:仅当匹配到 Some 模式时执行代码,忽略 None
// 语法:`if let 模式 = 表达式 { ... }`
// 优点:代码更简短,减少缩进和模板代码
// 缺点:放弃了 match 的穷尽性检查
let config_max = Some(3u8);
if let Some(max) = config_max { // 模式 Some(max) 匹配 config_max
println!("The maximum is configured to be {}", max);
}
// 示例 6-7: 在 if let 中搭配使用 else
// 场景:处理 Coin 枚举,对特定变体执行操作,其余情况计数
// 背景:Coin 枚举的 Quarter 变体包含一个 UsState 值
#[derive(Debug)]
enum UsState {
Alabama,
// 其他州省略...
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
// 使用 match 表达式处理 Coin
// 功能:匹配 Quarter 时打印州信息,其他情况计数
let mut count = 0;
match coin {
Coin::Quarter(state) => println!("State quarter from {:?}!", state),
_ => count += 1,
}
// 使用 if let 与 else 实现相同逻辑
// 功能:当匹配到 Quarter 时打印州信息,否则计数
// 优点:代码结构更清晰,避免了通配分支
let mut count = 0;
if let Coin::Quarter(state) = coin {
println!("State quarter from {:?}!", state);
} else {
count += 1;
}
// 核心总结:
// 1. if let 是 match 的语法糖,用于处理只关心一种匹配而忽略其他情况
// 2. 语法格式:`if let 模式 = 表达式 { ... }`
// 3. 可搭配 else 处理不匹配的情况
// 4. 在简洁性与穷尽性检查之间权衡,选择适合的语法
// 5. 当 match 显得冗长时,考虑使用 if let六. 所有权
1. 什么是所有权
所有权是 Rust 的一套核心规则系统,用于管理程序运行时使用的内存。与其他语言在运行时通过垃圾回收或手动管理内存的方式不同,Rust 通过在编译时检查所有权规则来确保内存安全,且不产生任何运行时开销。
所有权概念对许多程序员而言是新颖的,但理解并掌握它是编写出安全高效 Rust 代码的关键,也是理解 Rust 其他独特特性的基础。本章将通过“字符串”这一常用数据类型的示例,来具体学习所有权的相关规则。
①堆和栈
在 Rust 这类系统级编程语言中,理解值的存储位置(栈或堆)至关重要,这直接影响语言行为和编程方式。
栈遵循“后进先出”原则,数据大小必须固定且已知,其存入(入栈)和移除(出栈)操作非常高效,因为位置总在栈顶。
堆的管理更松散,可动态申请任意大小的空间,操作系统返回一个指向该空间的指针。这个过程称为“堆分配”。
指针(大小固定)本身可存储在栈上,访问堆上数据需要通过指针“跳转”。
访问栈上紧密排列的数据比访问堆上稀疏的数据快得多,处理器缓存能更高效地工作,且堆分配操作本身也消耗资源。
许多系统编程语言需要开发者手动跟踪堆内存的分配、避免冗余并及时清理。Rust 的所有权系统在编译时自动管理这些复杂任务,将开发者从频繁思考栈和堆的负担中解放出来。然而,理解底层内存管理的工作原理,对于深入掌握所有权系统的意义及其设计精髓仍然非常重要。
②所有权规则
所有权是Rust管理内存的核心规则系统。它的核心规则有三条:
Rust中的每一个值都有一个对应的所有者。
在同一时间内,该值有且仅有一个所有者。
当所有者离开其作用域时,它持有的值就会被自动丢弃。
这套在编译时强制检查的规则,使得Rust能够在无需垃圾回收或手动内存管理的情况下,保证内存安全且不产生运行时开销。掌握所有权是理解Rust独特编程方式的关键。
③变量作用域
// src/main.rs
// 示例 4-1: Rust 中变量的作用域示例
// 作用域是程序中一个项(如变量)有效的范围。
fn main() {
// 变量 `s` 在此处尚未声明,不可用
{ // 新的作用域开始
let s = "hello"; // 变量 `s` 在此声明,它是一个字符串字面量
// 变量 `s` 从此刻起变得有效
println!("{}", s); // 在此作用域内可以对 `s` 进行相关操作
} // 当前作用域结束
// 变量 `s` 在此处已离开其作用域,不再可用
// 核心规则总结:
// 1. 变量在进入其作用域后变得有效。
// 2. 变量会保持有效性,直至离开其作用域。
// 此规则与其他编程语言中的作用域概念基本一致。
}
// 后续将基于作用域的概念,继续学习更复杂的 String 类型。④String字符串
// src/main.rs
// 示例1:通过 String 类型演示所有权规则
// 选择 String 类型是因为它存储在堆上,便于观察内存管理机制
fn main() {
// 1. 字符串字面量(不可变,编译时已知,存储在栈上)
let literal = "hello"; // 固定大小,不可变
// 2. String 类型(可动态增长,存储在堆上)
// 使用 String::from 从字面量创建 String 实例
// 双冒号 :: 是命名空间操作符,用于调用特定类型下的函数
let s = String::from("hello"); // 此时 s 是 String 类型,数据存储在堆上
// 3. String 类型的可变性
let mut mutable_s = String::from("hello"); // 添加 mut 关键字使其可变
mutable_s.push_str(", world!"); // push_str() 方法可向尾部追加内容
println!("{}", mutable_s); // 输出: hello, world!
}
// 示例2:比较 String 与字符串字面量的内存处理方式
fn main() {
// 字符串字面量
// 内存处理:硬编码到程序二进制文件中,编译时确定,不可变
// 适用场景:文本值在编译时已知,且不需要修改
let literal = "immutable literal";
// String 类型
// 内存处理:运行时在堆上动态分配内存,大小可变
// 适用场景:需要修改或运行时才确定的字符串
let mut s = String::from("initial");
s.push_str(" and modified");
println!("{}", s); // 输出: initial and modified
/* 核心区别总结:
1. 字符串字面量:
- 编译时确定,硬编码到可执行文件
- 不可变,固定大小
- 存储在栈上(或程序的只读数据段)
2. String 类型:
- 运行时在堆上动态分配内存
- 可变,可动态增长/缩小
- 需要手动/自动管理内存(Rust 通过所有权系统自动管理)
这种内存处理方式的差异决定了它们的不同特性与适用场景。
*/
}⑤内存与分配
字符串字面量由于其内容在编译时已知,会被直接嵌入到最终的可执行文件中,因此访问效率很高,但这也决定了其不可变的特性。对于那些需要在运行时处理、大小可变或未知的文本,我们则需使用
String类型,它需要在堆上进行动态内存分配。在内存管理上,不同语言采取了不同策略。一些语言通过垃圾回收(GC)机制自动追踪和清理不再使用的内存。而对于没有GC的语言(如C、C++),程序员则必须自己负责显式地分配和释放内存,这极易出错,可能导致内存泄漏、非法访问或重复释放等问题。
Rust 提供了一个独特而安全的解决方案:所有权系统。当一个变量(如
String类型)离开其作用域时,Rust 会自动调用drop函数来释放其占用的堆内存,这类似于 C++ 中的 RAII 模式。此机制在简单场景下清晰易用,但其真正的威力在于它通过一套编译时检查的所有权规则,系统性地解决了多个变量引用同一块堆内存时的复杂问题,从而在无需垃圾回收的情况下保证了内存安全。
// src/main.rs
fn main() {
{ // 进入一个新的作用域
let s = String::from("hello"); // 变量 `s` 开始生效,其生命周期从此处开始
// 在此作用域内,可以对变量 `s` 执行相关操作
} // 当前作用域到此结束,变量 `s` 在此失效,其占用的内存将被自动释放
}变量和数据的交互方式:移动
在 Rust 中,当处理像整数这样固定大小、简单的数据类型时,其赋值行为是直接的“拷贝”。如代码
let x = 5;和let y = x;所示,将x赋值给y时,整数5本身的值被复制了一份。其结果是,两个独立的数值
5被分别推入栈中,变量x和y各自拥有一个完全相同的、彼此独立的副本。这是因为此类简单类型的复制成本极低,且行为明确。-
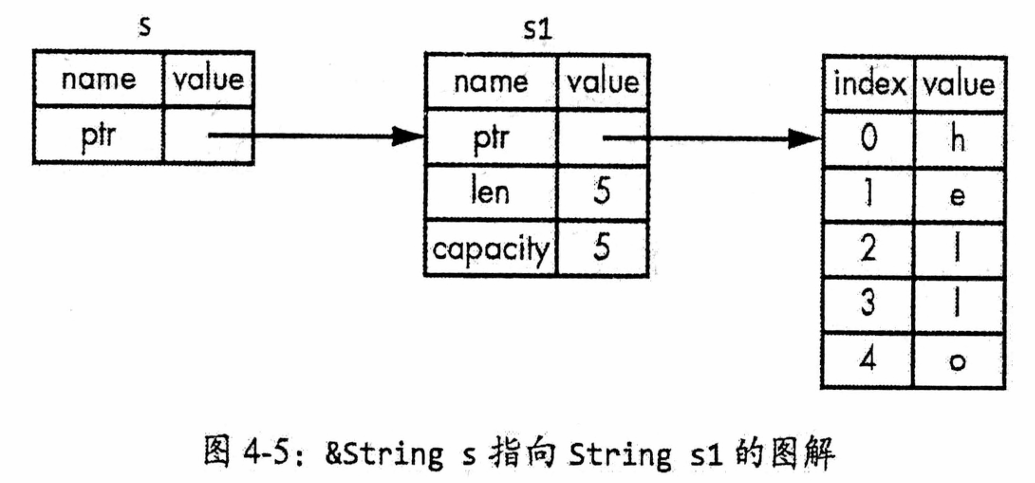
现在,我们来看
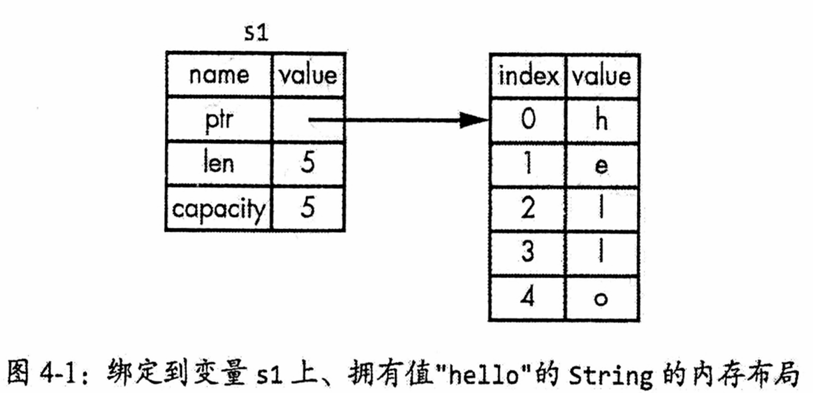
let s1 = String::from("hello"); let s2 = s1;这段代码的具体行为。String在内存中分为两部分:栈上存储的元数据(指向堆内存的指针 ptr、当前长度 len和总容量 capacity)以及堆上存储的实际字符内容,其结构如图4-1所示。当你执行 let s2 = s1时,Rust 只会复制栈上的元数据(指针、长度、容量),而不会复制堆上的字符数据。因此,赋值后 s1和 s2的指针将指向同一块堆内存,如图4-2所示。
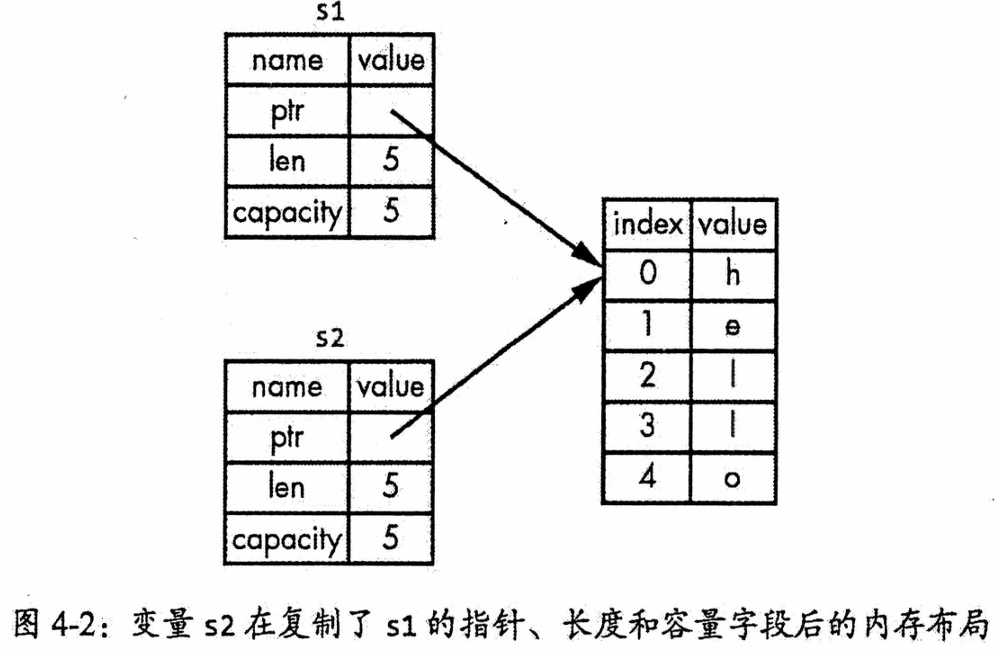
Rust 为了避免
s1和s2离开作用域时重复释放同一块内存,会立即使s1失效。这个过程称为移动,即所有权从s1转移给了s2。这种设计是出于性能考虑。如果 Rust 在每次赋值时都默认对堆数据进行深度拷贝(如图4-3所示),当数据量很大时,会造成显著的运行时性能开销。因此,Rust 通过移动语义,在保证安全的同时,也确保了高效。
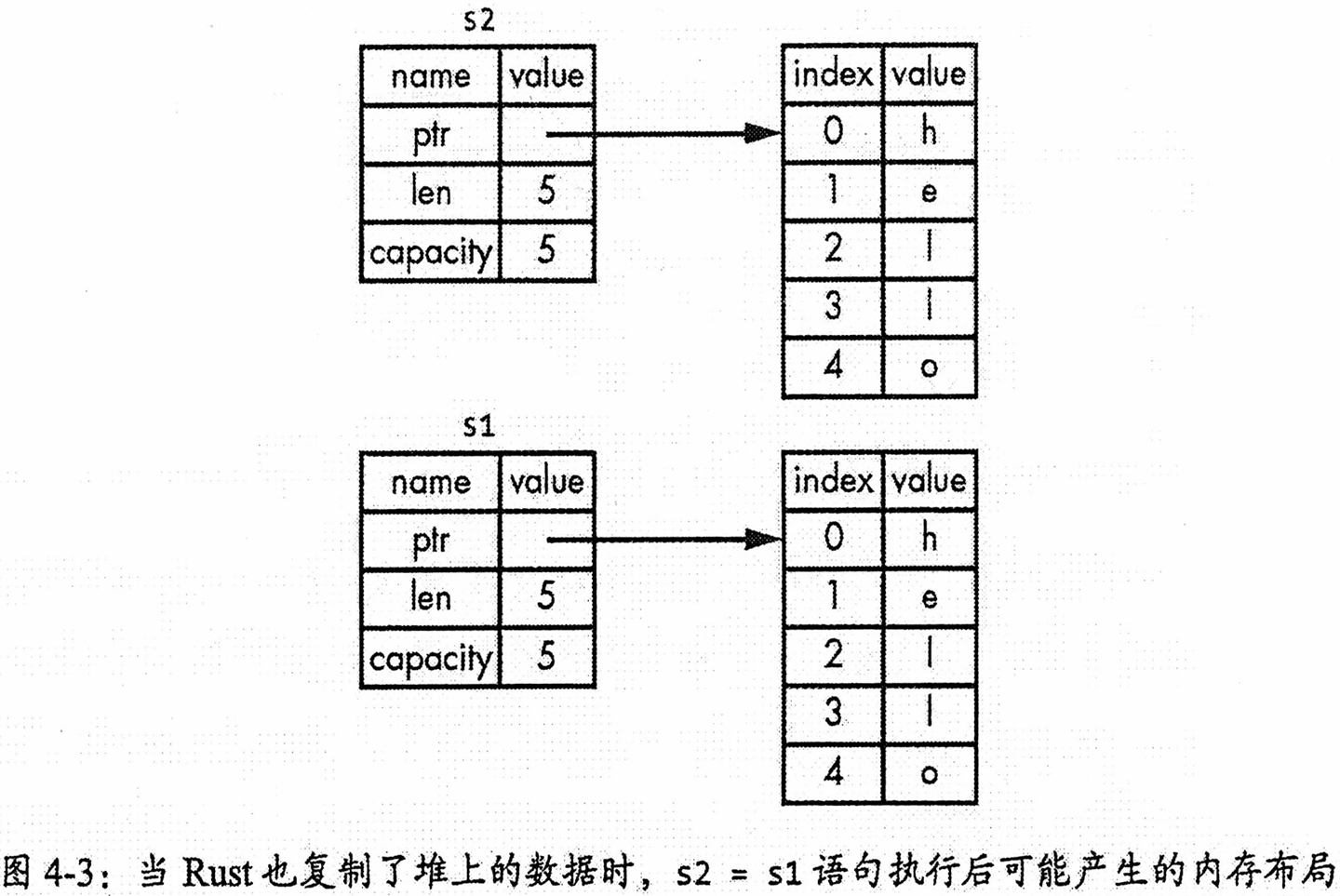
Rust 通过独特的所有权转移机制解决了一个关键的内存安全问题:二次释放。如图4-2所示,当执行
let s2 = s1;后,s1和s2指向同一块堆内存,如果两者都有效,离开作用域时会尝试重复释放该内存。为了防止这种情况,Rust 会立即使s1失效,从而确保了只有s2在离开作用域时释放内存。这种行为与“浅拷贝”有本质区别,因此 Rust 使用“移动”这一术语来描述,如图4-4所示。可以说
s1的所有权被移动到了s2中。这背后体现了 Rust 的一项核心设计原则:永远不会自动创建数据的深度拷贝。这种“移动”语义保证了所有的自动赋值操作在默认情况下都是高效的,无需担心性能损耗。
变量和数据的交互方式:克隆
// 当需要深度拷贝(deep copy)String 在堆上的数据,而不仅仅是复制栈上的指针、长度、容量等元数据时,
// 可以使用 `clone` 方法。这显式地复制了完整的堆数据,如示意图 4-3 所示。
// 示例:使用 clone 方法进行深度拷贝
let s1 = String::from("hello");
// 调用 clone 方法,完整复制 s1 的堆数据和栈上元数据
let s2 = s1.clone();
// 此时 s1 和 s2 是两个完全独立、拥有各自数据的 String 实例
println!("s1 = {s1}, s2 = {s2}"); // 输出: s1 = hello, s2 = hello
// 核心注意:
// 调用 `clone` 可能是一个消耗大量资源的操作,因为它需要分配新的堆内存并进行数据拷贝。
// 在代码中看到 `clone` 的调用,就意味着你正在执行一项明确的、可能开销较大的复制操作。栈上的数据复制
之前的讨论留下了一个知识点:在示例4-2中,整型代码
let x = 5; let y = x;看似与移动语义矛盾,因为x在赋值后依然有效。这是因为整型等类型完全存储在栈上,复制其值的操作非常快速且成本固定,因此无需移动,复制后新旧变量均可独立使用。对于这类类型,深度拷贝与浅度拷贝没有区别。Rust 提供了
Copy这个特殊的 trait 来标注这类完全存储在栈上的数据类型。实现了Copy的类型在变量赋值时会通过复制创建新实例,而不会发生所有权移动。需要注意的是,如果一个类型或其任意成员实现了Droptrait(需要在离开作用域时执行特殊清理),Rust 就不允许它再实现Copy。那么,哪些类型实现了
Copy呢? 一般来说,任何简单的标量组合类型都可以实现,而需要分配内存或资源的类型则不能。具体包括:所有的整数类型(如u32)、布尔类型(bool、所有的浮点类型(如f64)、字符类型(char)、元组,但前提是其包含的所有字段类型都必须实现了Copy(例如,(i32, i32)实现了,而(i32, String)没有)。
⑥所有权与函数
// src/main.rs
// 示例 4-3: 函数中变量所有权和作用域的变化过程
// 核心概念:将变量传递给函数,在所有权语义上等同于赋值,会触发移动(对于未实现Copy的类型)或复制(对于实现了Copy的类型)。
fn main() {
// 变量 s (String类型) 进入作用域。String 类型数据存储在堆上,其赋值行为是“移动”。
let s = String::from("hello");
// 调用 takes_ownership 函数,将 s 的所有权移入函数。
// 此后,s 在 main 函数中失效,不可再使用。
takes_ownership(s);
// 尝试在此处使用变量 s 将导致编译时错误,因为其所有权已被移走。
// println!("{}", s); // 取消注释此行将触发编译错误
// 变量 x (i32类型) 进入作用域。i32 是实现了 Copy trait 的标量类型,其赋值行为是“复制”。
let x = 5;
// 调用 makes_copy 函数。x 的值被复制一份传入函数,因此 x 在调用后依然有效。
makes_copy(x);
println!("在 main 中,x 仍然可用: {x}"); // 输出: 5
} // 作用域结束。x 离开作用域。s 早已离开其值的“所有权”作用域,此处无特别操作。
// takes_ownership 函数:接收一个 String 参数,并取得其所有权。
fn takes_ownership(some_string: String) { // some_string 进入本函数作用域
println!("takes_ownership 收到: {some_string}");
} // 此处 some_string 离开作用域,其 `drop` 函数被自动调用,堆内存被释放。
// makes_copy 函数:接收一个实现了 Copy trait 的 i32 参数。
fn makes_copy(some_integer: i32) { // some_integer 进入本函数作用域
println!("makes_copy 收到: {some_integer}");
} // 此处 some_integer 离开作用域。由于是栈上数据,无特殊清理操作。
// === 代码执行结果与说明 ===
// 1. 成功运行输出:
// takes_ownership 收到: hello
// makes_copy 收到: 5
// 在 main 中,x 仍然可用: 5
// 2. 若取消第 12 行的注释,尝试在移动后使用 s,编译器将报错:
// error[E0382]: borrow of moved value: `s`
// 这体现了 Rust 所有权系统的静态检查能力,从根本上防止了“悬垂指针”等内存错误。⑦返回值与作用域
// src/main.rs
// 示例 4-4:函数返回值时所有权的转移过程
// 所有权转移不仅发生在赋值和传参时,也发生在函数返回值时。
fn main() {
// gives_ownership 将其返回值的所有权移动给 s1
let s1 = gives_ownership();
let s2 = String::from("hello"); // s2 进入作用域
// takes_and_gives_back 函数取得 s2 的所有权,并将其返回值(所有权)移动给 s3
// 从此,s2 在 main 作用域内失效
let s3 = takes_and_gives_back(s2);
} // s3 和 s1 离开作用域,其值被丢弃。s2 的所有权已移动,无事发生。
// gives_ownership 函数:将其创建的 String 的所有权移动给调用者
fn gives_ownership() -> String {
let some_string = String::from("yours"); // some_string 进入作用域
some_string // some_string 作为返回值,其所有权被移动到调用函数
}
// takes_and_gives_back 函数:取得一个 String 的所有权,并将其返回
fn takes_and_gives_back(a_string: String) -> String { // a_string 进入作用域
a_string // a_string 作为返回值,其所有权被移动到调用函数
}// src/main.rs
// 示例 4-5:通过元组返回多个值,以将参数所有权交还给调用者
// 这种方法允许函数使用一个值而不永久地取得其所有权,但依然显得繁琐。
fn main() {
let s1 = String::from("hello");
// calculate_length 取得 s1 的所有权,但通过元组将其与长度一起返回
// 通过解构,s2 重新获得了字符串的所有权
let (s2, len) = calculate_length(s1);
println!("The length of '{}' is {}.", s2, len);
}
fn calculate_length(s: String) -> (String, usize) {
let length = s.len(); // len() 返回字符串的字节长度
(s, length) // 以元组形式返回原字符串和其长度,将所有权交还
}2. 引用与借用
①什么是引用和借用
// src/main.rs
// 示例:通过引用(&)传递参数,避免函数调用导致 String 所有权转移。
// 引用(reference)是一个指向值的地址,允许访问该值但不获得其所有权,保证了内存安全。
// main函数
fn main() {
let s1 = String::from("hello"); // 拥有字符串 "hello" 的变量 s1
// 将 s1 的引用(&s1)传递给函数,s1 的所有权不发生转移
let len = calculate_length(&s1);
// 函数调用后,s1 依然有效
println!("The length of '{s1}' is {len}.");
}
// calculate_length 函数:接收一个 String 的引用(&String)并返回其长度
// 参数 s 是一个引用,不持有 String 的所有权,因此不会在离开作用域时 drop 原数据
fn calculate_length(s: &String) -> usize { // s 是 String 的引用
s.len() // 返回字符串的字节长度
} // 此处 s 离开作用域,但因它是引用,不持有所有权,其指向的字符串不会被释放
/*
* 核心概念说明:
* 1. 引用(&):类似于指针,指向某个值的地址。允许访问该值,但不拥有所有权。
* 2. 借用:通过引用传递参数给函数被称为“借用”。如同借东西,用完后无须“归还”所有权,因为从未拥有。
* 3. 作用域行为:引用变量离开其作用域时,不会销毁它所指向的数据,因为它不拥有该数据。
*/
// 示例4-6:尝试修改一个不可变引用指向的值(此代码无法通过编译)
// 说明:与变量类似,引用默认是不可变的,Rust 不允许修改不可变引用指向的值。
fn main() {
let s = String::from("hello");
change(&s); // 尝试传入不可变引用并进行修改
}
fn change(some_string: &String) { // 参数为不可变引用
some_string.push_str(", world"); // 错误!不能通过不可变引用来修改其指向的值。
}
// 编译错误信息:
// error[E0596]: cannot borrow `*some_string` as mutable, as it is behind a `&` reference
// 帮助:考虑将此处的引用改为可变引用:`&mut String`
/*
* 总结:
* 1. 使用引用(&T)可以“借用”值而不获取所有权,使原始变量在函数调用后依然可用。
* 2. 与使用 & 进行引用相反的操作是解引用(dereferencing),使用 * 运算符(后续章节详述)。
* 3. 引用默认是不可变的,要修改借用的值,必须使用可变引用(&mut T)。
*/②可变引用
// src/main.rs
// 示例:通过可变引用修改借用的值
// 核心概念:要修改借用的值,必须满足两个条件:
// 1. 变量本身必须声明为可变的 (`mut`)
// 2. 必须传递可变引用 (`&mut`) 给函数
fn main() {
// 1. 将变量 s 声明为可变的 (`mut`)
let mut s = String::from("hello");
// 2. 通过传递可变引用 (&mut s) 来调用函数
change(&mut s);
println!("修改后的 s: {}", s); // 输出: hello, world
}
// 3. 函数参数必须接收可变引用 (`&mut String`)
fn change(some_string: &mut String) {
some_string.push_str(", world");
}
/*
* 可变引用的核心限制与数据竞争预防
* 限制1: 不能同时持有多个可变引用
*/
fn main() {
let mut s = String::from("hello");
// 错误示例:同时创建两个可变引用 (编译失败)
// let r1 = &mut s;
// let r2 = &mut s; // 错误[E0499]: 不能在同一时间多次可变借用 `s`
// println!("{}, {}", r1, r2);
// 错误信息解释:
// 当第一个可变借用 r1 仍在作用域内(后续的 `println!` 还要使用它)时,
// 创建第二个可变借用 r2 违反了 Rust 的借用规则。
}
/*
* 此限制的设计目的:在编译时避免数据竞争 (Data Race)。
* 数据竞争发生的三个条件:
* 1. 两个或以上指针同时访问同一数据
* 2. 至少有一个指针用于写入
* 3. 没有同步访问的机制
* Rust 通过这条编译时规则,从根本上杜绝了数据竞争的可能性。
*/
/*
* 限制2: 不能在持有不可变引用的同时创建可变引用
*/
fn main() {
let mut s = String::from("hello");
let r1 = &s; // 不可变引用,没问题
let r2 = &s; // 另一个不可变引用,没问题
// 错误示例:在存在不可变引用时尝试创建可变引用
// let r3 = &mut s; // 错误[E0502]: 不能将 `s` 作为可变借用,因为它也作为不可变借用
// println!("{}, {}, and {}", r1, r2, r3);
// 原因:不可变引用的用户不希望其值在背后被改变。
// 允许多个不可变引用同时存在,是因为它们不会修改数据,是安全的。
}
/*
* 引用作用域的关键规则:
* 一个引用的作用域从它被创建开始,持续到它最后一次被使用为止。
* 编译器能够自动推导出引用作用域的结束位置。
*/
fn main() {
let mut s = String::from("hello");
let r1 = &s; // 不可变引用 r1
let r2 = &s; // 不可变引用 r2
// r1 和 r2 的最后一次使用在这里
println!("{} and {}", r1, r2);
// 编译器可以推导出:r1 和 r2 的作用域在此结束
// 因此,在此之后创建可变引用是合法的
let r3 = &mut s; // 没问题
println!("{}", r3);
}
/*
* 通过作用域管理多个可变引用
* 可以利用花括号 `{}` 创建一个显式的作用域,让前一个引用提前离开作用域,
* 从而合法地创建新的可变引用。
*/
fn main() {
let mut s = String::from("hello");
{
let r1 = &mut s; // 第一个可变引用
// 使用 r1 ...
} // r1 在此离开作用域,被释放
let r2 = &mut s; // 可以创建第二个可变引用
println!("{}", r2);
}
/*
* 总结与价值
* Rust 的借用规则(一个数据的可变引用具有排他性)虽然可能让初学者感到约束,
* 但它使得编译器能够在编译时而非运行时,就发现潜在的数据竞争错误。
* 这消除了追踪运行时数据意外变化的调试负担,是 Rust 内存安全和并发安全的重要基石。
*/fn main() {
let mut s = String::from("hello");
// 情况1:创建可变引用后,原始变量暂时"冻结"
let r = &mut s; // 从这里开始,s 暂时不能直接使用
r.push_str(", world");
// s.push_str("!"); // ❌ 错误:不能通过 s 修改,因为 r 仍在使用中
println!("r = {}", r);
// 情况2:可变引用离开作用域后,原始变量恢复使用
// 假设 r 在 println! 后不再使用,编译器可推断其作用域结束
s.push_str("!"); // ✅ 正确:此时 r 已不再被使用
println!("s = {}", s);
}fn main() {
let mut x = 5;
// 阶段1:可变借用
let y = &mut x;
*y += 1; // 只能通过 y 修改
// 阶段2:不可变借用(必须在 y 的作用域结束后)
let z1 = &x;
let z2 = &x;
println!("z1={}, z2={}", z1, z2); // 只能通过 z1, z2 读取
// 阶段3:重新获得完整所有权
x = 10; // 在 z1, z2 的作用域结束后才能修改
}③悬垂引用
// src/main.rs
// 本文件演示 Rust 如何防止悬垂引用(dangling references)
// 1. 悬垂指针问题背景
// 在拥有指针概念的语言中,容易错误地创建悬垂指针。悬垂指针指向的内存
// 可能已被释放或重新分配,导致未定义行为和安全漏洞。
// Rust 编译器确保引用永远不会成为悬垂引用:如果持有某个数据的引用,
// 编译器保证这个数据不会在引用被销毁前离开自己的作用域。
// 2. 尝试创建悬垂引用的错误示例
// 此代码无法通过编译,展示了 Rust 如何在编译时发现此错误
/*
// 错误的函数定义:尝试返回一个局部变量的引用
fn dangle() -> &String { // 错误:缺少生命周期说明符
let s = String::from("hello"); // s 是函数内的局部变量
&s // 尝试返回指向 s 的引用
} // 这里,s 离开作用域并被释放,导致返回的引用成为悬垂引用
*/
// 编译错误信息(对应图片):
// error[E0106]: missing lifetime specifier
// --> src/main.rs:5:13
// |
// 5 | fn dangle() -> &String {
// | ^ expected named lifetime parameter
// |
// = help: this function's return type contains a borrowed value,
// but there is no value for it to be borrowed from
// = help: consider using the 'static lifetime
// 错误信息指出:函数返回类型包含借用的值,但不存在可供借用的值。
// 3. 生命周期概念提示
// 错误信息中提到的"生命周期"是新概念,将在第10章详细讨论。
// 但即使不了解生命周期,错误信息也准确地指出了问题核心:
// 函数返回一个借用的值,却没有一个可供借用的值存在。
// 4. 分析 dangle 函数的问题
// 在 dangle 函数中:
// 1. 创建局部变量 s(String 类型)
// 2. 尝试返回指向 s 的引用
// 3. 函数结束时,s 离开作用域并被释放
// 4. 返回的引用指向已释放的内存,成为悬垂引用
// Rust 成功在编译时拦截了这种危险代码。
// 5. 正确的解决方案:直接返回值本身
// 解决此问题的方法很简单:直接返回 String 值本身,而不是引用。
// 这样所有权会从函数内部转移到调用者,避免了悬垂引用问题。
fn no_dangle() -> String {
let s = String::from("hello");
s // 直接返回 String 本身,所有权被转移
}
// 这种写法没有任何问题,所有权被转移出函数,不会涉及释放后再访问的问题。
// 6. 主函数演示正确用法
fn main() {
// 调用 no_dangle 函数获取 String
let valid_string = no_dangle();
println!("有效的字符串: {}", valid_string);
// 尝试调用错误的 dangle 函数(注释掉,因为无法编译)
// let dangling = dangle(); // 编译错误
// println!("悬垂引用: {}", dangling);
}
// 总结:
// 1. Rust 编译器在编译时防止悬垂引用的创建
// 2. 返回局部变量的引用会导致编译错误
// 3. 解决方案是直接返回值本身,转移所有权
// 4. 这是 Rust 内存安全保证的重要组成部分④引用的规则
在任何给定时刻,对于同一数据,你只能拥有一个可变引用,或者可以同时拥有任意数量的不可变引用,二者不可兼得。
其次,引用必须始终是有效的,Rust 确保了这一点。
3. 切片类型
①什么是切片
// src/main.rs
// 示例4-7:first_word函数,返回String参数中首个单词结尾处的索引
// 函数签名:接收一个字符串的不可变引用,返回一个表示索引的usize值
fn first_word(s: &String) -> usize {
// 1. 将String转换为字节数组,以便逐字节检查
let bytes = s.as_bytes();
// 2. 遍历字节数组,使用enumerate获取索引和元素的元组
for (i, &item) in bytes.iter().enumerate() {
// 3. 检查当前字节是否为空格(使用字节字面量语法b' ')
if item == b' ' {
// 4. 找到空格,返回当前位置索引
return i;
}
}
// 5. 未找到空格,返回整个字符串的长度
s.len()
}
// src/main.rs
// 示例4-8:展示返回的索引在字符串被修改后失效的问题
fn main() {
// 1. 创建一个可变的String变量
let mut s = String::from("hello world");
// 2. 调用first_word获取第一个单词的结尾索引(应为5)
let word = first_word(&s); // 索引5被绑定到word变量
// 3. 清空字符串,使其变为空字符串""
s.clear();
// 【核心问题说明】
// 此时,虽然word变量的值仍然是5,但由于原字符串s已被清空,
// 这个索引值失去了实际意义,成为无效状态。
// 这种情况可能导致后续使用此索引访问字符串时发生错误。
// 4. 问题分析
// 索引值word独立于原字符串s,当s被修改后,word无法自动更新,
// 导致两者状态不同步。这种设计迫使开发者必须持续跟踪索引的有效性,
// 增加了维护负担和出错风险。
// 5. 扩展到更复杂的场景
// 对于需要返回多个索引的函数(如返回第二个单词的起始和结束索引),
// 问题更加严重:需要同步维护多个独立的索引变量。
// fn second_word(s: &String) -> (usize, usize) { ... }
// 这种API设计使代码更易出错,且难以维护。
}②字符串切片
什么是字符串切片
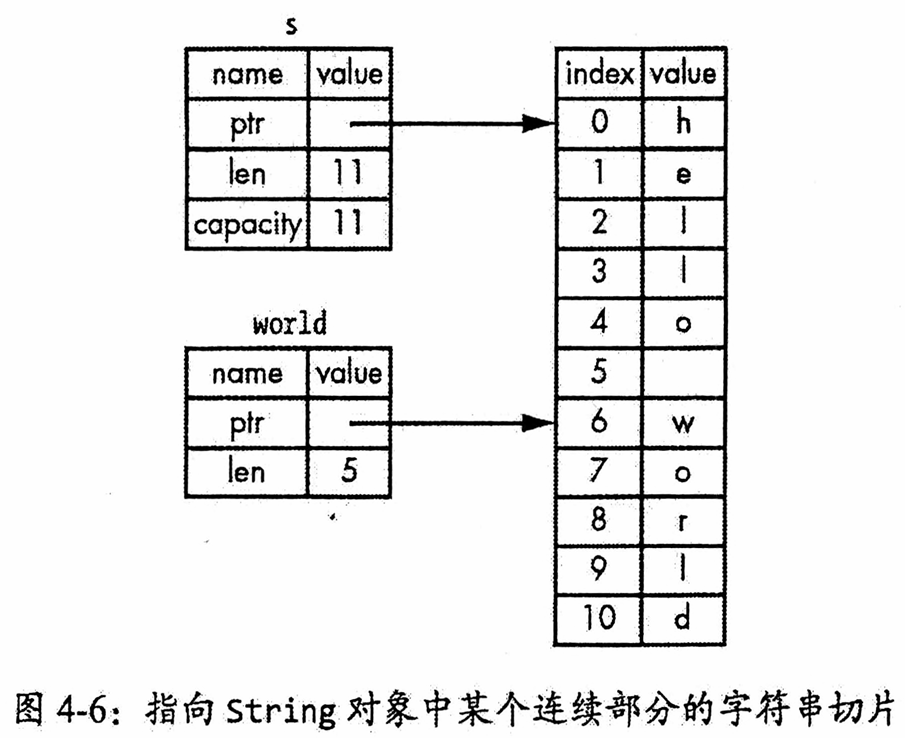
// src/main.rs
// 示例4-9: 字符串切片
// 字符串切片是指向String对象中某个连续部分的引用,其类型为&str。
fn main() {
// 1. 基本切片语法
// 语法:[starting_index..ending_index]
// starting_index: 起始字节位置
// ending_index: 结束位置的下一个索引
let s = String::from("hello world");
// 创建两个切片
let hello = &s[0..5]; // 指向"hello"
let world = &s[6..11]; // 指向"world"
// 2. 范围语法糖
// 当范围从第一个元素(索引0)开始时,可省略起始值
let slice1 = &s[0..2];
let slice2 = &s[..2]; // 与slice1等价
// 当范围包含到最后一个字节时,可省略结束值
let len = s.len();
let slice3 = &s[3..len];
let slice4 = &s[3..]; // 与slice3等价
// 同时省略首尾值,创建整个字符串的切片
let slice5 = &s[0..len];
let slice6 = &s[..]; // 与slice5等价
// 3. 重要注意事项
// 字符串切片边界必须位于有效的UTF-8字符边界内
// 尝试从多字节字符中间创建切片会导致运行时错误
// 本节为简化问题,仅使用ASCII字符集
// 4. 重构first_word函数,返回切片而非索引
let word = first_word(&s);
println!("第一个单词: {}", word);
// 5. 编译时错误示例
// 以下代码会导致编译错误,因为同时存在不可变引用和可变引用
// let mut s2 = String::from("hello world");
// let word2 = first_word(&s2);
// s2.clear(); // 错误:尝试获取可变引用,clear会截断字符串,所以这里传的是可变引用。
// println!("第一个单词: {}", word2); // word2的不可变引用在此处仍在使用
}
// 重构后的first_word函数
// 返回类型为&str,即字符串切片
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i]; // 找到空格,返回从开头到空格的切片
}
}
&s[..] // 未找到空格,返回整个字符串的切片
}
// 同理可重构second_word函数
// fn second_word(s: &String) -> &str { ... }
/*
* 编译时安全性分析:
* 1. 切片与原始数据关联,编译器确保引用有效
* 2. 当存在切片引用时,阻止对原始数据的可变修改
* 3. 避免示例4-8中的索引失效问题
* 4. Rust借用规则在编译时防止数据竞争和悬垂引用
*
* 错误示例分析(对应图片7-8):
* 当存在不可变切片引用时,尝试调用clear()获取可变引用会导致编译错误:
* error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
*
* 这体现了Rust的内存安全保证:要么多个不可变引用,要么一个可变引用,但不能同时存在。
*/字符串字面量就是切片
字符串字面量(如
"Hello, world!")是直接存储在最终编译出的二进制程序中的。学习了切片后,可以更准确地理解其本质:当我们写下let s = "Hello, world!";时,变量s的类型是&str。它是一个指向该二进制程序中特定位置的字符串切片。正因为&str是一个不可变的引用,所以字符串字面量天生就是不可变的。
将字符串切片作为参数
// src/main.rs
// 示例4-9:改进后的first_word函数,使用字符串切片作为参数类型
// 优化动机:既然可以分别创建字符串字面量和String的切片,那么我们可以优化函数接口
// 改进后的签名:使用&str代替&String,使函数能同时处理String和&str两种类型
// 这种写法更通用,且不会损失任何功能,是经验丰富的Rust开发者常用的方式
// 定义改进后的first_word函数,参数为字符串切片&str,返回&str
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
// main函数展示改进后的first_word如何被调用
fn main() {
// 1. 使用String对象调用
let my_string = String::from("hello world");
// 接收String的部分切片
let word1 = first_word(&my_string[0..6]);
println!("word1: {}", word1);
// 接收String的整体切片
let word2 = first_word(&my_string[..]);
println!("word2: {}", word2);
// 接收String的引用(等价于整体切片)
let word3 = first_word(&my_string);
println!("word3: {}", word3);
// 2. 使用字符串字面量调用
let my_string_literal = "hello world";
// 接收字符串字面量的部分切片
let word4 = first_word(&my_string_literal[0..6]);
println!("word4: {}", word4);
// 接收字符串字面量的整体切片
let word5 = first_word(&my_string_literal[..]);
println!("word5: {}", word5);
// 字符串字面量本身就是切片,可以直接传递
let word6 = first_word(my_string_literal);
println!("word6: {}", word6);
}
/*
* 核心优化点总结:
* 1. 参数类型从&String改为&str,提高API的通用性
* 2. 函数现在可以同时处理String和字符串字面量
* 3. 调用时更加灵活,可以传递切片的不同部分
* 4. 这种灵活性来自Deref强制转换(将在第15章详细介绍)
* 5. 改进后的API不会损失任何功能,但使用范围更广
*/③其他类型的切片
// src/main.rs
// 从名字上就可以看出来,字符串切片是专门用于字符串的。实际上,Rust还有其他更加通用的切片类型,以下面的数组为例:
// 创建一个整数数组
let a = [1, 2, 3, 4, 5];
// 就像我们想要引用字符串的某个部分一样,你也可能希望引用数组的某个部分。这时,你可以这样做:
// 创建一个数组切片,引用数组a中索引1到3(不包含3)的元素
let slice = &a[1..3];
// 断言切片的内容与预期一致
assert_eq!(slice, &[2, 3]);
/*
* 核心说明:
* 1. 切片类型是&[i32],它在内部存储了一个指向起始元素的引用和一个长度。
* 2. 这与字符串切片的工作机制完全一样。
* 3. 你将在各种各样的集合中接触到此类切片。
* 4. 我们会在第8章中讨论动态数组时再来介绍那些常用的集合。
*/七. 结构体
1. 定义和实例化结构体
结构体与元组类似,都能持有多个不同类型相关的值。两者的核心区别在于,结构体需要为其中的每个数据字段明确命名,这使其含义更清晰。正是由于拥有命名字段,结构体的使用比元组更灵活:访问数据时无需依赖顺序索引,可直接通过字段名进行。
定义结构体需使用
struct关键字,其名称应能体现数据的组合意义。在随后的花括号中,需声明所有字段的名字及其类型。
// src/main.rs
// 示例 5-1: 定义一个名为 `User` 的结构体
// 结构体(struct)是一种自定义数据类型,允许你命名并将多个相关的值组合在一起
// 这里的 `User` 结构体用于存储一个账户的信息
struct User {
active: bool, // 用户是否处于活跃状态
username: String, // 用户名
email: String, // 电子邮件地址
sign_in_count: u64, // 登录次数
}
// 示例 5-2: 创建 `User` 结构体的一个实例
// 为 `User` 结构体的每个字段赋予具体的值来创建一个实例
// 字段赋值的顺序不需要与结构体定义中的顺序一致
fn main() {
let user1 = User {
active: true,
username: String::from("someusername123"),
email: String::from("someone@example.com"),
sign_in_count: 1,
};
// 现在可以使用 user1
}
// 示例 5-3: 修改一个可变 `User` 实例中的字段值
// 如果实例被声明为可变 (`mut`),则可以通过点号修改其字段
// 注意:整个实例的可变性是统一的,不能单独指定某个字段为可变
fn main() {
let mut user1 = User {
active: true,
username: String::from("someusername123"),
email: String::from("someone@example.com"),
sign_in_count: 1,
};
user1.email = String::from("anotheremail@example.com"); // 修改 email 字段
}
// 示例 5-4: 一个返回 `User` 实例的函数
// 可以在函数的最后一个表达式中构造结构体实例,并将其隐式返回
// 此函数接收 email 和 username 参数,并用它们以及固定值构造 User
fn build_user(email: String, username: String) -> User {
User {
active: true, // 直接赋予值 true
username: username, // 使用参数 `username` 初始化同名字段
email: email, // 使用参数 `email` 初始化同名字段
sign_in_count: 1, // 直接赋予值 1
}
}①简化版的字段初始化方法
// 当函数参数名与结构体字段名完全一致时,可使用字段初始化简写语法。
// 此语法不会改变程序行为,但能避免重复书写相同的名称,使代码更简洁。
// 示例 5-5:使用字段初始化简写语法的 build_user 函数
// 由于参数名 `username` 和 `email` 与结构体字段名完全相同,
// 因此可省略为 `username,` 和 `email,`,而不需写成 `username: username,`。
fn build_user(email: String, username: String) -> User {
User {
active: true,
username, // 字段初始化简写:等价于 `username: username,`
email, // 字段初始化简写:等价于 `email: email,`
sign_in_count: 1,
}
}③使用结构体更新语法,基于其他实例创建新实例
// src/main.rs
// 在许多创建新实例的场景中,除了需要修改的一小部分字段,其余字段的值与旧实例中的完全相同。
// 我们可以使用结构体更新语法来快速实现新实例的创建。
// 示例5-6:不使用结构体更新语法的写法
// 创建新的User实例user2,除email和username外,其余字段的值都与user1实例中的值相同
fn main() {
// 假设已有user1实例
let user1 = User {
active: true,
username: String::from("user1"),
email: String::from("user1@example.com"),
sign_in_count: 1,
};
// 不使用结构体更新语法
let user2 = User {
active: user1.active, // 复制user1的active字段
username: user1.username, // 移动user1的username字段
email: String::from("another@example.com"), // 设置新email
sign_in_count: user1.sign_in_count, // 复制user1的sign_in_count字段
};
// 注意:由于username字段中的String值从user1移动到了user2,创建完user2后,user1的username字段失效
}
// 示例5-7:使用结构体更新语法的写法
// 通过结构体更新语法,我们可以使用更少的代码来实现完全相同的效果
fn main() {
// 假设已有user1实例
let user1 = User {
active: true,
username: String::from("user1"),
email: String::from("user1@example.com"),
sign_in_count: 1,
};
// 使用结构体更新语法
let user2 = User {
email: String::from("another@example.com"), // 设置新email
..user1 // 双点号..表明剩余未被显式赋值的字段都与user1实例中的字段相同
};
// 代码中的..user1必须放置在结构体初始化代码的最后
// 它可以指定剩余未指定的字段都从user1相应的字段中获取值
// 使用结构体更新语法时,可以任意顺序为字段赋值,无需考虑字段在结构体中的定义顺序
}
// 结构体更新语法的数据移动规则:
// 1. 结构体更新语法与赋值语法类似,都使用了=,这是因为它会移动数据
// 2. 如果user1中的字段(如String类型的username)被移动到了user2,则user1在创建完user2后不再可用
// 3. 如果只使用了user1中实现了Copy trait的字段(如active和sign_in_count),而其他字段(如email和username)被赋予了新值,
// 那么user1在创建user2之后依旧可用③使用不需要对字段命名的元组结构体来创建不同的类型
// src/main.rs
// 元组结构体:通过 `struct` 关键字定义,拥有结构体名称,但字段本身无名,仅有类型。
// 适用场景:为元组赋予有意义的类型名,使其区别于其他结构相同但语义不同的元组。
// 定义时,在结构体名称后的括号内声明字段类型,例如:
struct Color(i32, i32, i32);
struct Point(i32, i32, i32);
fn main() {
// 创建元组结构体实例
let black = Color(0, 0, 0);
let origin = Point(0, 0, 0);
// 关键特性1:类型独立性
// 即使 Color 和 Point 均由三个 i32 组成,它们是不同的类型。
// 例如,接收 Color 类型参数的函数无法接受 Point 参数。
// 关键特性2:实例行为类似元组
// 1. 可通过模式匹配解构
let Color(r, g, b) = black;
println!("Color: R:{}, G:{}, B:{}", r, g, b);
// 2. 可通过点号 `.` 加索引访问字段
let x = origin.0;
let y = origin.1;
let z = origin.2;
println!("Point: ({}, {}, {})", x, y, z);
}④没有任何字段的单元结构体
// src/main.rs
// 单元结构体:没有任何字段的结构体,与单元元组 `()` 类似。
// 定义语法:使用 `struct` 关键字、结构体名称和分号,无需花括号或圆括号。
// 定义一个名为 AlwaysEqual 的单元结构体
struct AlwaysEqual;
fn main() {
// 实例化单元结构体:直接使用结构体名,无需附带花括号或圆括号
let subject = AlwaysEqual;
// 单元结构体的主要用途:
// 当需要为某个类型实现 trait,但该类型不需要存储任何数据时,单元结构体非常有用。
// 例如,可以为 AlwaysEqual 实现一个特殊的 trait,让它的实例等于任何其他类型的实例。
// 关于 trait 的定义和实现,将在第10章详细讨论。
}⑤结构体数据所有权
// src/main.rs
// 示例 5-1: 定义 User 结构体,其字段使用持有自身所有权的 String 类型
// 核心说明:选择 String 而非 &str 引用,是为了让结构体实例拥有其数据的完整所有权。
// 这意味着只要结构体实例有效,其内部的字符串数据就必定有效,无需依赖外部数据的生命周期。
struct User {
active: bool,
username: String, // 使用 String 类型,持有所有权
email: String, // 使用 String 类型,持有所有权
sign_in_count: u64,
}
// 注意:若尝试在结构体中直接存储引用(例如 &str),将导致编译错误。
// 错误的定义示例:
// struct UserWithRef {
// active: bool,
// username: &str, // 错误:缺少生命周期说明符
// email: &str, // 错误:缺少生命周期说明符
// sign_in_count: u64,
// }
//
// 编译器错误提示:
// error[E0106]: missing lifetime specifier
// help: consider introducing a named lifetime parameter
// 建议写法示例:struct UserWithRef<'a> { username: &'a str, ... }
//
// 这是因为结构体本身不拥有该引用的数据,Rust 需要通过生命周期(lifetime)注解
// 来保证引用数据的存活时间不短于结构体实例本身。生命周期将在第 10 章详细讨论。
// 当前,为简化问题,我们使用持有所有权的 String 类型。
fn main() {
// 创建一个 User 实例,其数据完全由实例自身拥有
let user1 = User {
active: true,
username: String::from("someusername123"),
email: String::from("someone@example.com"),
sign_in_count: 1,
};
// 实例 user1 离开作用域时,其内部的 String 数据将被自动释放,内存管理是安全的。
}2. 方法语法
方法与函数十分相似:它们都使用
fn关键字声明,都可以拥有参数和返回值,都包含了一段可执行的代码。其核心区别在于,方法总是被定义在某个结构体(或枚举类型、trait对象,将在第6章和第17章介绍)的上下文中,并且其第一个参数永远是self,用于指代调用该方法的结构体实例。
①定义方法
// src/main.rs
// 示例 5-13: 在 Rectangle 结构体中定义 area 方法
// 核心:将之前接收 Rectangle 实例为参数的 area 函数,改写为 Rectangle 结构体的方法
#[derive(Debug)]
struct Rectangle {
width: u32, // 宽度
height: u32, // 高度
}
// 使用 impl 关键字为 Rectangle 结构体实现功能
// impl 块内的所有内容都与 Rectangle 类型相关联
impl Rectangle {
// 1. 定义 area 方法
// 方法签名使用 &self 替代 rectangle: &Rectangle
// &self 是 self: &Self 的简写,Self 是 impl 目标类型(此处为 Rectangle)的别名
// 第一个参数必须是 self,Rust 允许使用简写形式
fn area(&self) -> u32 {
// 通过点号访问结构体字段
self.width * self.height
}
// 2. 定义 width 方法(演示方法与字段可同名)
// 此方法与 width 字段同名,但返回 bool 类型
// 在 main 中,rect1.width() 表示调用此方法,rect1.width 表示访问字段
fn width(&self) -> bool {
self.width > 0
}
}
// 3. 主函数演示方法调用
// 方法调用语法:在实例后加点和括号
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
// 调用 area 方法
println!(
"The area of the rectangle is {} square pixels.",
rect1.area()
);
// 调用 width 方法
if rect1.width() {
println!("The rectangle has a nonzero width; it is {}", rect1.width);
}
}
// 核心概念说明:
// 1. 方法定义在 impl 块中,与结构体关联
// 2. 方法签名第一个参数必须是 self,可选择不可变借用(&self)、可变借用(&mut self)或所有权(self)
// 3. 使用 &self 是因为只需读取数据,无需修改或获取所有权
// 4. 方法调用语法:instance.method(),比独立函数调用更清晰
// 5. 方法名可与字段名相同,通过有无括号区分
// 6. 访问器(getter)是常见的同名方法,用于返回字段值
// 7. Rust 不自动生成访问器,需手动实现(第7章介绍公有/私有控制)②运算符->去哪了
在 C 和 C++ 中,调用方法需要区分
.和->运算符,后者用于对指针解引用。Rust 没有->运算符,它通过自动引用和解引用功能简化了操作:当你调用object.something()时,编译器会自动添加&、&mut或*来匹配方法的self参数类型。这使得p1.distance(&p2)与(&p1).distance(&p2)完全等价。由于每个方法都有明确的
self类型(&self、&mut self或self),Rust 能够根据方法名自动推断出正确的调用方式。这种隐式借用机制极大地提升了体验,让严格的所有权系统在实际编码中变得更加直观和易于使用。
③带有更多参数的方法
// src/main.rs
// 本文件演示如何为 Rectangle 结构体定义 can_hold 方法,
// 并展示其使用场景(对应图片1中的示例5-14和图片2中的实现说明)。
// 1. 定义 Rectangle 结构体
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
// 2. 为 Rectangle 实现方法
impl Rectangle {
// 计算矩形面积的方法
fn area(&self) -> u32 {
self.width * self.height
}
// 定义 can_hold 方法
// 功能:判断当前矩形(self)是否能完全容纳另一个矩形(other)
// 参数:&self 为当前矩形的不可变借用,other 为另一个矩形的不可变借用
// 返回:布尔值,若当前矩形的宽和高均大于另一个矩形,则返回 true
// 设计:通过不可变借用读取 other 的数据,不影响原实例的所有权
// 逻辑:依次比较宽度和高度,两者均大于时返回 true
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
// 3. 主函数:创建矩形实例并测试 can_hold 方法
fn main() {
// 创建三个矩形实例
let rect1 = Rectangle { width: 30, height: 50 };
let rect2 = Rectangle { width: 10, height: 40 };
let rect3 = Rectangle { width: 60, height: 45 };
// 调用 can_hold 方法,检查 rect1 是否能容纳 rect2 和 rect3
// 预期输出:rect1 能容纳 rect2(因为 rect2 的宽和高都小于 rect1),返回 true
// rect1 不能容纳 rect3(因为 rect3 的宽度大于 rect1),返回 false
println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2));
println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3));
}④关联函数
// src/main.rs
// 1. 关联函数(Associated Functions)定义
// 所有定义在 `impl` 块中的函数都称为关联函数,因为它们与 `impl` 的目标类型相关联。
// 关联函数可以没有 `self` 参数,因此不是方法(method),不作用于具体实例。
// 2. 关联函数的常见用途:构造器
// 关联函数常被用作构造器,返回结构体的新实例。虽然通常命名为 `new`,
// 但 `new` 并非内置关键字,可自定义名称。例如,为 `Rectangle` 定义 `square` 关联函数,
// 用于创建一个正方形(宽高相等)的矩形实例。
// 定义 Rectangle 结构体
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
// 为 Rectangle 实现关联函数
impl Rectangle {
// square 关联函数:接收一个尺寸参数,返回宽高相等的正方形 Rectangle
// 参数 size: u32 - 正方形的边长
// 返回类型 Self - 是 impl 后面类型的别名,此处即 Rectangle
fn square(size: u32) -> Self {
Self {
width: size,
height: size,
}
}
// 另一个关联函数示例:传统构造器 new
// 这只是一个命名约定,Rust 本身没有特殊对待 `new`
fn new(width: u32, height: u32) -> Self {
Self { width, height }
}
}
// 3. 关联函数的调用
// 通过结构体名称和 `::` 语法调用关联函数
// `::` 语法也用于模块创建的命名空间(模块概念在第7章讨论)
fn main() {
// 调用 square 关联函数创建正方形矩形
let sq = Rectangle::square(3);
println!("正方形矩形: {:?}", sq);
// 调用 new 关联函数创建一般矩形
let rect = Rectangle::new(30, 50);
println!("一般矩形: {:?}", rect);
}
// 核心总结:
// 1. 关联函数定义在 impl 块中,与类型关联
// 2. 没有 self 参数的关联函数不是方法,常用作构造器
// 3. 通过 Type::function_name() 调用关联函数
// 4. Self 是 impl 目标类型的别名⑤多个impl块
// src/main.rs
// 核心概念:结构体可以拥有多个 `impl` 块。本代码对应示例5-16,
// 将方法分散到不同的 `impl` 块中,虽然在此场景下并非必要,但语法合法。
// 多个 `impl` 块的实际应用(如为泛型或trait提供不同实现)将在第10章讨论。
// 定义 Rectangle 结构体
struct Rectangle {
width: u32,
height: u32,
}
// 第一个 impl 块:实现 area 方法
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
}
// 第二个 impl 块:实现 can_hold 方法
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}八. 枚举
枚举(通常简称为enum)是一种允许通过列举所有可能的变体来定义类型的语言构造。它能够将数据与每个变体直接关联,从而高效地编码信息。
本章将首先通过定义和使用枚举的示例,展示其如何将数据与变体结合。接着,会重点讨论一个极为实用的
Option枚举,它专门用于表示值“存在”或“不存在”的场景,是处理空值的核心工具。
1. 定义枚举
// src/main.rs
// 示例6-1: 枚举与IP地址处理
// 核心概念:枚举允许定义一组可能的值,每个值称为一个变体(variant)。
// 本例通过IP地址类型展示枚举的用法。
// 定义 IpAddrKind 枚举,表示IP地址的两种标准:IPv4 和 IPv6
// 枚举名是自定义数据类型,变体 V4 和 V6 是该类型的可能值
enum IpAddrKind {
V4, // IPv4 变体
V6, // IPv6 变体
}
// 主函数演示枚举使用
fn main() {
// 创建枚举实例
let four = IpAddrKind::V4; // 通过 :: 语法访问枚举变体
let six = IpAddrKind::V6;
// 可以像普通数据类型一样使用
route(four);
route(six);
}
// 接收 IpAddrKind 类型参数的函数
// 可以处理任意 IP 地址版本
fn route(ip_kind: IpAddrKind) {
match ip_kind {
IpAddrKind::V4 => println!("处理 IPv4 地址"),
IpAddrKind::V6 => println!("处理 IPv6 地址"),
}
}
/*
* 枚举的优势(对比结构体):
* 1. IP地址只能是 IPv4 或 IPv6 中的一种,枚举变体互斥
* 2. 枚举可以更精确地表达"多选一"的语义约束
* 3. 枚举变体可以携带额外数据(后续示例展示)
* 4. 编译器可确保对所有可能变体进行穷尽处理
*
* 核心思想:
* 枚举将值限定在预定义的可能值集合中,确保类型安全,
* 避免无效状态,是Rust表达概念分类的强大工具。
*/2. 枚举值
// src/main.rs
// 示例6-1: 使用结构体存储IP地址的数据和类型
// 核心概念:定义枚举表示IP地址种类,结构体组合枚举和地址数据
// 但此方法存在冗余,后续将展示如何用枚举直接内嵌数据来简化
// 1. 定义枚举 IpAddrKind,表示IP地址类型
enum IpAddrKind {
V4, // IPv4
V6, // IPv6
}
// 2. 定义结构体 IpAddr,包含类型和地址数据
struct IpAddr {
kind: IpAddrKind, // 地址类型
address: String, // 地址数据
}
// 3. 创建实例
fn main() {
// 创建IPv4实例
let home = IpAddr {
kind: IpAddrKind::V4,
address: String::from("127.0.0.1"),
};
// 创建IPv6实例
let loopback = IpAddr {
kind: IpAddrKind::V6,
address: String::from("::1"),
};
}
// 示例6-1改进:枚举直接内嵌数据
// 核心优化:枚举变体可直接关联数据,无需额外结构体
enum IpAddr {
V4(String), // IPv4变体直接关联String
V6(String), // IPv6变体直接关联String
}
fn main() {
// 创建实例:更简洁,直接通过枚举构造函数
let home = IpAddr::V4(String::from("127.0.0.1"));
let loopback = IpAddr::V6(String::from("::1"));
// 枚举变体自动成为构造函数,如IpAddr::V4()是接收String返回IpAddr的函数
}
// 示例6-1进一步改进:枚举变体可关联不同类型和数量的数据
// 核心优势:每个变体可拥有不同的数据类型和结构
enum IpAddr {
V4(u8, u8, u8, u8), // IPv4用4个u8值表示
V6(String), // IPv6用String表示
}
fn main() {
// IPv4实例:用4个u8值
let home = IpAddr::V4(127, 0, 0, 1);
// IPv6实例:用String
let loopback = IpAddr::V6(String::from("::1"));
}
// 标准库中的IpAddr定义(简化示意)
// 实际标准库将地址数据封装到独立结构体中
struct Ipv4Addr {
// 省略具体实现
}
struct Ipv6Addr {
// 省略具体实现
}
enum IpAddr {
V4(Ipv4Addr), // 变体关联结构体
V6(Ipv6Addr),
}
// 示例6-2: Message枚举展示变体可内嵌多种数据类型
enum Message {
Quit, // 无关联数据
Move { x: i32, y: i32 }, // 匿名结构体
Write(String), // 单个String
ChangeColor(i32, i32, i32), // 三个i32的元组
}
// 对比:用多个结构体实现相同功能(但无法统一处理)
struct QuitMessage; // 单元结构体
struct MoveMessage { x: i32, y: i32 }
struct WriteMessage(String);
struct ChangeColorMessage(i32, i32, i32);
// 枚举的优势:单一类型,可统一处理
// 枚举与结构体相似之处:均可通过impl定义方法
impl Message {
fn call(&self) {
// 方法体
}
}
fn main() {
// 创建Message实例并调用方法
let m = Message::Write(String::from("hello"));
m.call(); // 调用call方法,self指向m
}
// 后续将介绍标准库中的Option枚举,用于处理值存在或不存在的场景3. Option枚举以及在空值处理方面的优势
Option是 Rust 标准库中定义的一个枚举,专门用于编码“一个值可能存在,也可能不存在”的常见场景。例如,从一个列表中获取首个元素时,有元素的列表能返回一个值,而空列表则无法返回任何值。通过使用 Option类型,编译器可以在编译时强制检查是否妥善处理了所有情况,从而避免其他语言中因遗漏处理而导致的常见错误。
Rust 在设计上有意避免了“空值”这一存在于许多其他语言中的功能。空值本身是一个值,却表示“没有值”,这导致变量会处于“空值”和“非空值”两种状态。空值的发明者 Tony Hoare 后来称其为一个“价值数十亿美金的错误”,因为它虽然易于实现,却在实际使用中导致了无数的错误、漏洞和系统崩溃——当程序像使用非空值那样使用空值时,就会触发错误。
尽管“空值”本身问题很多,但它试图表达的“值因某种原因无效或缺失”的概念确实是有意义的。Rust 通过
Option枚举以一种更安全的方式来表达这一概念,它在类型系统的层面上帮助开发者规避了空值带来的风险。Option<T>是 Rust 用于安全处理“可能有值,可能为空”这一场景的核心枚举。它的设计哲学是:任何可能为空的值,都必须被显式地包装在 Option<T>类型中。当你使用这个值时,编译器会强制你必须编写代码来显式处理 Some(T)(有值)和 None(空值)两种情况。
这种设计带来了巨大的安全性收益:只要一个值的类型不是
Option<T>,你就可以确信它绝对不是空值,从而无需进行空值检查。这从根本上杜绝了空指针异常这类常见错误。为了从
Option<T>的Some变体中取出内部的值并使用它,你需要使用像match这样的控制流结构。match表达式允许你根据枚举的具体变体(Some或None)来执行不同的代码分支,并能在匹配到Some(T)时安全地获取其中包裹的数据。Option<T>本身也提供了大量实用的辅助方法,具体可在官方文档中查阅,熟练掌握它们能极大提升编码效率。
// src/main.rs
// 核心概念:Rust 没有空值,但通过 Option<T> 枚举表达值可能无效或缺失的场景
// Option<T> 定义在标准库中,已包含在预导入模块,可直接使用 Some 和 None
// <T> 是泛型参数,表示 Some 变体可以包含任意类型的数据
// 标准库中的 Option<T> 定义(示意):
// enum Option<T> {
// None, // 表示无值
// Some(T), // 表示有值,并持有类型为 T 的数据
// }
fn main() {
// 示例1:创建包含不同类型数据的 Some 变体
let some_number: Option<i32> = Some(5); // Some 包含 i32
let some_char: Option<char> = Some('e'); // Some 包含 char
// 编译器可根据 Some 中的值自动推导出 Option<T> 的具体类型
// 示例2:创建 None 变体必须显式标注类型
let absent_number: Option<i32> = None; // 必须标注为 Option<i32>
// 因为 None 不包含数据,编译器无法推导具体类型
// 核心安全特性:Option<T> 和 T 是不同的类型,不能直接混用
let x: i8 = 5;
let y: Option<i8> = Some(5);
// 以下代码会导致编译错误:
// let sum = x + y; // 错误:无法将 i8 与 Option<i8> 相加
// 错误信息:no implementation for `i8 + Option<i8>`
// 安全优势:
// 1. 当持有类型 T 时,编译器确保值有效,无需空值检查
// 2. 当持有 Option<T> 时,必须处理值不存在的可能性
// 3. 必须先将 Option<T> 转换为 T 才能使用,避免空值假设错误
// 使用 Option<T> 前必须转换:
match y {
Some(value) => println!("值为: {}", value + x), // 有值时使用
None => println!("无值"), // 无值时处理
}
}
/*
* 设计优势总结:
* 1. 通过类型系统区分"有值"和"无值"状态
* 2. 编译时强制处理所有可能情况
* 3. 避免空指针解引用等运行时错误
* 4. 明确表达意图,提高代码可读性
*/九. 包、单元包(Crate)和模块
随着程序复杂度增加,合理组织代码、对功能进行分组和分离变得至关重要。Rust 提供了以包、单元包、模块和路径为核心的模块系统来帮助管理代码。
包 是 Cargo 提供的构建、测试和分享代码的功能单元。一个包可包含多个二进制单元包和一个可选的库单元包。
单元包 是生成库或可执行文件的树状模块结构,是编译器处理的基本单元。
模块 与
use关键字 共同用于控制代码的文件组织、作用域和条目的私有性。路径 则是一种命名结构体、函数、模块等条目的方法。
封装是实现细节隐藏,允许通过公共接口复用代码,这减轻了开发者的心智负担。与此紧密相关的概念是作用域,它定义了特定区域内名称(如变量、函数)的有效范围及其具体含义。你可以创建作用域并控制名称是否在其中,但不能在同一作用域内让一个名称指向两个不同条目。
对于大型项目,可以将代码拆分到独立的单元包中作为外部依赖引用。Cargo 还提供了工作空间功能,用于管理多个相互关联的包。
1. 包与单元包
单元包是 Rust 编译器可处理的最小代码单元,可分为可执行、含有
main函数的二进制单元包,以及被共享、不含main的库单元包。一个包由一个或多个提供相关功能的单元包组成,并通过Cargo.toml文件描述其构建信息。一个包可包含多个二进制单元包,但最多只能有一个库单元包。一个包至少包含一个单元包。当你使用
cargo new创建新包时,默认会生成一个二进制单元包,其入口是src/main.rs文件。如果包中同时存在src/main.rs和src/lib.rs,则会分别创建一个同名的二进制单元包和库单元包(默认路径)。此外,你还可以在src/bin/目录下添加更多源文件,每个文件都会被视作独立的二进制单元包。Cargo会在构建库和二进制程序时,将这些单元包的根节点文件作为参数传递给rustc。




2. 定义模块控制作用域和私有性
本节将讨论模块系统中的核心概念,包括路径(用于命名条目)、
use关键字(用于将路径引入作用域)和pub关键字(用于将条目标记为公共)。此外,也会涉及as关键字、外部包和通配符的使用。模块是代码组织的核心单元,它允许你将单元包内的代码按逻辑进行分组,从而提升可读性和易用性。同时,模块也控制着条目的访问权限(私有性):模块内的代码默认是私有的,这封装了内部实现细节;而通过
pub将模块或条目标记为公共后,外部代码就可以使用并依赖它们。
// src/lib.rs
// 示例7-1:模拟餐厅的模块化代码组织
// 本库单元包模拟餐厅的前厅与后厨分工结构,展示了如何使用模块来组织代码。
// 定义前厅模块,对应餐厅的前厅区域,负责接待和服务客户。
mod front_of_house {
// 定义接待子模块,处理客户排队和安排座位。
mod hosting {
// 将客户添加到等待列表中。
fn add_to_waitlist() {}
// 为客户安排座位。
fn seat_at_table() {}
}
// 定义服务子模块,处理点餐、上菜和结账。
mod serving {
// 接收客户订单。
fn take_order() {}
// 上菜。
fn serve_order() {}
// 结账。
fn take_payment() {}
}
}
/*
* 模块树结构(对应示例7-2的树状图):
* crate (隐式根模块)
* ├── front_of_house
* │ ├── hosting
* │ │ ├── add_to_waitlist
* │ │ └── seat_at_table
* │ └── serving
* │ ├── take_order
* │ ├── serve_order
* │ └── take_payment
*
* 模块关系说明(对应图片3和4):
* 1. 模块可以嵌套定义,如hosting和serving是front_of_house的子模块。
* 2. 同级模块(sibling)定义在同一父模块内,如hosting和serving。
* 3. 整个模块树以隐式根模块crate为根,类似于文件系统的根目录。
* 4. 模块用于组织代码,便于导航和维护,类似于目录组织文件。
*/3. 在模块树中指明条目路径
①介绍
在 Rust 的模块系统中,路径用于定位模块树中的具体条目,如函数或结构体,类似于文件系统的导航方式。
路径主要分为两种形式:绝对路径从单元包的根节点(
crate)开始,相对路径则从当前模块出发,可使用self或super等标识符来表示向上或同级的相对位置。无论是绝对还是相对路径,均由一系列以双冒号(
::)分隔的标识符组成。私有性规则:
默认私有,子模块可以使用祖先模块的条目,但父模块不能使用子模块的私有条目。
同一父模块下的子模块互相可见对方的模块声明。
在 crate 根定义的模块(即直接在
lib.rs或main.rs中定义的模块),其声明默认对整个 crate 可见。
// src/lib.rs
// 示例 7-3:尝试调用私有函数导致编译错误
// 此示例展示了如何通过绝对路径和相对路径调用函数,但由于模块私有性,无法通过编译。
// 定义 front_of_house 模块,包含私有子模块 hosting
mod front_of_house {
mod hosting { // 私有模块,无法从外部访问
fn add_to_waitlist() {} // 私有函数
}
}
// 公共函数,作为库的公共 API
pub fn eat_at_restaurant() {
// 尝试通过绝对路径调用私有函数
crate::front_of_house::hosting::add_to_waitlist();
// 错误:模块 `hosting` 是私有的
// 尝试通过相对路径调用私有函数
front_of_house::hosting::add_to_waitlist();
// 错误:模块 `hosting` 是私有的
}
// 编译错误信息(示例 7-4):
// error[E0603]: module `hosting` is private
// --> src/lib.rs:9:28
// 9 | crate::front_of_house::hosting::add_to_waitlist();
// | ^^^^^^^ private module
// 注意:模块 `hosting` 定义在 src/lib.rs:2:5
// 错误原因:Rust 默认所有条目(模块、函数等)都是私有的,无法从外部访问。
// 核心总结:
// 1. 绝对路径:从单元包根(crate)开始,适用于定义和调用代码分离的场景。
// 2. 相对路径:从当前模块开始,适用于定义和调用代码一起移动的场景。
// 3. 私有性规则:默认私有,子模块可以使用祖先模块的条目,但父模块不能使用子模块的私有条目。
// 4. 使用 `pub` 关键字暴露路径,使子模块中的条目在祖先模块中可见。②使用pub关键字暴露路径
// src/lib.rs
// 示例 7-5 至 7-7: 演示 Rust 模块可见性规则
// 本文件展示如何通过 `pub` 关键字逐步公开模块和函数,使外部代码可以访问
// 背景:餐厅模块结构,front_of_house 包含 hosting 子模块,hosting 包含 add_to_waitlist 函数
// 定义 front_of_house 模块
// 注意:在 crate 根定义的模块,其声明对整个 crate 可见(相当于 pub(crate))
// 同级模块(如 eat_at_restaurant)可以访问 front_of_house 模块本身
mod front_of_house {
// 将 hosting 子模块标记为 pub,使其对祖先模块(front_of_house)的调用者可见
// 仅公开模块本身,其内部内容默认仍私有
pub mod hosting {
// 将函数标记为 pub,使其对外部调用者可见
// 这是必要的,因为模块公开不自动公开其内容
pub fn add_to_waitlist() {}
}
}
// 公共函数,作为库的公共 API 一部分
pub fn eat_at_restaurant() {
// 绝对路径:从 crate 根开始
// 1. crate::front_of_house ✅ 可见(同级模块)
// 2. crate::front_of_house::hosting ✅ 可见(hosting 被标记为 pub)
// 3. crate::front_of_house::hosting::add_to_waitlist() ✅ 可见(函数被标记为 pub)
crate::front_of_house::hosting::add_to_waitlist();
// 相对路径:从当前模块开始
// 1. front_of_house ✅ 可见(同级模块)
// 2. front_of_house::hosting ✅ 可见(hosting 被标记为 pub)
// 3. front_of_house::hosting::add_to_waitlist() ✅ 可见(函数被标记为 pub)
front_of_house::hosting::add_to_waitlist();
}
/*
* 关键点总结(基于6张图片内容):
*
* 1. 模块声明可见性(图片1、5):
* - 在 crate 根定义的模块(如 front_of_house)对整个 crate 可见
*
* 2. 内容可见性(图片2、3、4):
* - 模块内的函数、结构体等默认私有
* - 即使模块被标记为 pub,其内部内容仍私有,需单独用 `pub` 公开
*
* 3. 路径解析(图片5):
* - 绝对路径: crate::front_of_house::hosting::add_to_waitlist()
* - front_of_house 与 eat_at_restaurant 同级,可直接访问
* - hosting 和 add_to_waitlist 需显式标记为 pub
* - 相对路径: front_of_house::hosting::add_to_waitlist()
* - 从当前模块开始,其余逻辑同绝对路径
*
* 4. 公共API契约(图片6):
* - 公开的模块和函数构成库的公共API
* - 更改公共API需谨慎,因为它建立了与用户的契约
* - 更多细节参考《Rust API 编写指南》
*
* 编译通过条件:
* 1. hosting 模块标记为 pub
* 2. add_to_waitlist 函数标记为 pub
* 3. 路径中的所有中间模块都可见
*/③二进制和库包
当一个Rust包同时包含二进制单元包(
src/main.rs)和库单元包(src/lib.rs)时,其根节点名称默认与包名相同。在这种架构下,二进制单元包通常仅包含调用库单元包并启动程序的简单代码,而核心功能则全部实现在库单元包中,以便于其他项目共享和复用。由于模块树定义在
src/lib.rs中,二进制单元包可通过包名访问库单元包的公共条目。这意味着二进制单元包在调用库代码时,与外部用户遵循相同的规则:它只能使用库单元包的公共API。这种“自己调用自己”的模式,迫使开发者同时从作者和用户的双重角度审视代码,有助于设计出更清晰、更易用的API。
④从super关键字开始构建相对路径
// src/lib.rs
// 示例 7-8: 使用 super 关键字构造指向父模块的相对路径
// 功能:在子模块中通过 super 调用父模块中的函数
// 优势:便于模块树重构,移动模块时无需更新相对路径
// 1. 在根模块中定义 deliver_order 函数
// 此函数模拟将订单送给客户
fn deliver_order() {
// 实现送餐逻辑
}
// 2. 定义 back_of_house 模块,表示餐厅后厨
mod back_of_house {
// 3. 在 back_of_house 模块中定义 fix_incorrect_order 函数
// 功能:修正错误订单,并亲自送给客户
fn fix_incorrect_order() {
// 调用同一模块内的 cook_order 函数
cook_order();
// 使用 super 关键字构造指向父模块的相对路径
// 调用父模块(根模块)中的 deliver_order 函数
// 优势:当 back_of_house 模块移动时,此相对路径无需更新
super::deliver_order();
}
// 4. 定义 cook_order 函数,模拟烹饪订单
fn cook_order() {
// 实现烹饪逻辑
}
}
// 模块关系说明:
// - deliver_order 位于根模块
// - back_of_house 是根模块的子模块
// - fix_incorrect_order 和 cook_order 是 back_of_house 的子模块
//
// 核心设计思想:
// 1. 使用 super 关键字从子模块访问父模块的条目
// 2. 类似文件系统的 .. 语法,允许向上导航模块树
// 3. 当子模块与父模块功能紧密相关时,使用 super 便于未来重构
// 4. 避免硬编码路径,提高代码的可维护性⑤将结构体或枚举声明为公共的
// src/lib.rs
// 示例7-9和7-10:展示结构体与枚举在可见性规则上的差异
// 核心概念:
// 1. 结构体声明为公共时,其字段默认仍私有,需显式标记pub
// 2. 枚举声明为公共时,其所有变体自动变为公共
// 定义后厨模块
mod back_of_house {
// 1. Breakfast结构体 - 演示部分字段公开
// 结构体本身公共,但字段默认私有,需显式标记pub
pub struct Breakfast {
pub toast: String, // 公共字段:顾客可选择的面包类型
seasonal_fruit: String, // 私有字段:厨师决定的时令水果
}
impl Breakfast {
// 必须提供公共关联函数来创建实例,因为存在私有字段
pub fn summer(toast: &str) -> Breakfast {
Breakfast {
toast: String::from(toast),
seasonal_fruit: String::from("peaches"), // 内部设置时令水果
}
}
}
// 2. Appetizer枚举 - 演示枚举变体的可见性
// 枚举声明为公共时,其所有变体自动变为公共
pub enum Appetizer {
Soup, // 变体自动公共
Salad, // 变体自动公共
}
}
// 公共函数,演示结构体和枚举的使用
pub fn eat_at_restaurant() {
// 1. 使用结构体Breakfast
// 创建Breakfast实例,必须通过公共关联函数
let mut meal = back_of_house::Breakfast::summer("Rye");
// 可以读写公共字段toast
meal.toast = String::from("Wheat");
println!("我想要{}面包", meal.toast);
// 以下代码无法编译,因为seasonal_fruit是私有字段
// meal.seasonal_fruit = String::from("blueberries");
// 错误:field `seasonal_fruit` of struct `Breakfast` is private
// 2. 使用枚举Appetizer
// 可以直接使用枚举的变体,因为枚举公共时变体自动公共
let order1 = back_of_house::Appetizer::Soup;
let order2 = back_of_house::Appetizer::Salad;
}
/*
* 设计差异说明(基于图片4、5内容):
*
* 结构体字段默认私有原因:
* 1. 结构体字段可独立存在,部分私有不影响整体使用
* 2. 支持信息隐藏,控制对内部状态的访问
* 3. 需要显式公开字段,避免无意中暴露实现细节
*
* 枚举变体自动公共原因:
* 1. 枚举的变体是其类型的完整集合,必须全部可用
* 2. 如果某些变体不可用,模式匹配会不完整
* 3. 为所有变体手动添加pub繁琐且不必要
* 4. 枚举通常用于表示一组固定的选项,全部公开更合理
*/4. 使用use将路径导入作用域
①介绍
// src/lib.rs
// 示例 7-11: 使用 `use` 关键字简化模块路径调用
// 核心概念:`use` 为模块路径创建缩写,减少重复编写冗长路径
// 背景:在 Rust 中,按完整路径调用函数(如 `crate::front_of_house::hosting::add_to_waitlist()`)会显得重复和冗长
// 1. 定义模块结构
mod front_of_house { // 定义外层模块 front_of_house
pub mod hosting { // 在 front_of_house 内定义 pub 子模块 hosting
pub fn add_to_waitlist() {} // 在 hosting 内定义一个 pub 函数 add_to_waitlist
}
}
// 2. 使用 `use` 导入路径
// 将 `crate::front_of_house::hosting` 模块路径导入当前作用域
// 类比:类似于文件系统中创建符号链接,`hosting` 成为当前作用域的有效名称
// 注意:使用 `use` 引入路径同样遵守私有性规则
use crate::front_of_house::hosting;
// 3. 利用缩写调用函数
pub fn eat_at_restaurant() { // 定义一个 pub 函数 eat_at_restaurant
hosting::add_to_waitlist(); // 使用导入的缩写 hosting 来调用 add_to_waitlist
}
// 示例 7-12: 演示 `use` 语句的作用域限制
// 核心概念:`use` 只在它出现的特定作用域内创建缩写
// 问题:将 `eat_at_restaurant` 函数移到新子模块 `customer` 中,与 `use` 语句作用域不同
mod customer { // 新子模块,与 `use` 语句处于不同作用域
// 尝试调用 `hosting::add_to_waitlist()` 会导致编译错误
// 因为 `use crate::front_of_house::hosting;` 在父作用域,在此子模块中无效
pub fn eat_at_restaurant() {
// ❌ 错误:缩写无法在 customer 模块中继续生效
hosting::add_to_waitlist(); // 编译错误:use of undeclared crate or module `hosting`
}
}
// 4. 编译错误与解决方案
// 编译错误信息(对应图片4):
// error[E0433]: failed to resolve: use of undeclared crate or module `hosting`
// warning: unused import: `crate::front_of_house::hosting`
// 解决方案:
// 方案1:将 `use` 语句移至 `customer` 模块中
// 方案2:在子模块中使用 `super::hosting` 引用父模块中的缩写
// 方案1:移动 use 语句
mod customer1 {
use crate::front_of_house::hosting; // 在子模块内导入
pub fn eat_at_restaurant() {
hosting::add_to_waitlist(); // ✅ 现在可以编译
}
}
// 方案2:使用 super 引用父模块
mod customer2 {
// 不在此处使用 use,而是通过 super 引用父作用域
pub fn eat_at_restaurant() {
super::hosting::add_to_waitlist(); // ✅ 通过 super 访问父模块的 hosting
}
}②创建use路径时的惯用方式
// src/lib.rs
// 本文件演示 Rust 中 `use` 关键字的三种使用场景:
// 1. 示例 7-13: 非惯用方式 - 直接导入函数(不推荐)
// 2. 示例 7-14: 惯用方式 - 导入模块(推荐)和导入结构体
// 3. 示例 7-15: 处理同名类型 - 通过父模块区分
// ====================
// 1. 示例 7-13: 非惯用的导入方式
// ====================
// 直接导入 `add_to_waitlist` 函数,导致调用时无法清晰看出函数定义位置
// 这种方式虽然可行,但不推荐,因为它破坏了代码的可读性
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
// 非惯用:直接导入函数
use crate::front_of_house::hosting::add_to_waitlist;
pub fn eat_at_restaurant() {
add_to_waitlist(); // 调用函数,但无法看出函数来自哪个模块
}
// ====================
// 2. 示例 7-14: 惯用的导入方式
// ====================
// 惯用方式1: 导入模块,调用时指定模块名
// 优势:清晰表明函数来源,避免完整路径重复
mod front_of_house2 {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
// 惯用:导入模块,而非直接导入函数
use crate::front_of_house2::hosting;
pub fn eat_at_restaurant2() {
hosting::add_to_waitlist(); // 清晰表明函数来自 hosting 模块
}
// 惯用方式2: 导入结构体、枚举等类型时,通常使用完整路径
// 从标准库导入 HashMap
use std::collections::HashMap;
pub fn create_map() {
let mut map = HashMap::new();
map.insert(1, 2);
}
// ====================
// 3. 示例 7-15: 处理同名类型
// ====================
// 当需要导入两个同名类型时,应导入其父模块,通过模块名区分
// 错误做法:直接导入两个 Result 类型会导致冲突
// use std::fmt::Result;
// use std::io::Result; // 错误:重复的 Result 定义
// 正确做法:导入父模块,通过模块前缀区分
use std::fmt;
use std::io;
pub fn function1() -> fmt::Result {
// 使用 fmt::Result
Ok(())
}
pub fn function2() -> io::Result<()> {
// 使用 io::Result
Ok(())
}
// 核心总结:
// 1. 函数通常导入其父模块,通过模块名调用,提高可读性
// 2. 结构体、枚举等类型通常直接导入,但需避免同名冲突
// 3. 同名类型应通过父模块区分,这是 Rust 社区的约定俗成③使用as关键字提供新的名称
// src/lib.rs
// 示例 7-16: 使用 `as` 关键字对引入作用域的类型进行重命名
// 当通过 `use` 语句引入同名类型时,可以使用 `as` 关键字为其中一个创建别名,避免冲突。
// 引入 std::fmt 模块中的 Result 类型
use std::fmt::Result;
// 引入 std::io 模块中的 Result 类型,并将其重命名为 IoResult
// 通过重命名,避免了与上面的 Result 类型发生命名冲突
use std::io::Result as IoResult;
// 函数 function1 返回 fmt::Result 类型
// 由于已通过 use 引入,可直接使用 Result
fn function1() -> Result {
// 函数体省略
Ok(())
}
// 函数 function2 返回 io::Result 类型
// 通过别名 IoResult 来引用 io::Result
fn function2() -> IoResult<()> {
// 函数体省略
Ok(())
}
/*
* 核心总结(基于两张图片内容):
* 1. 解决同名类型冲突的两种方法:
* - 示例 7-15: 引入父模块,通过模块前缀区分,如 `fmt::Result` 和 `io::Result`
* - 示例 7-16: 通过 `as` 关键字为其中一个类型创建别名
* 2. 两种方法都符合 Rust 编码惯例,可根据个人喜好和具体场景选择
* 3. 使用 `as` 重命名时,新名称(别名)仅在当前作用域有效
*/④使用pub use重导出名称
// src/lib.rs
// 示例 7-17: 通过 `pub use` 重导出,使 `hosting` 模块成为公共 API 的一部分
// 核心概念:`pub use` 不仅将条目引入当前作用域,还使其对外部代码可见,称为"重导出"
// 作用:允许代码的内部组织结构与对外公开的 API 结构分离,满足不同使用者的视角
// 1. 内部模块结构:员工视角的"前厅"和"后厨"划分
mod front_of_house { // 内部模块,表示餐厅的前厅区域
pub mod hosting { // 内部子模块,表示接待服务
pub fn add_to_waitlist() {} // 内部函数,添加客户到等待列表
}
}
// 2. 重导出:将 `hosting` 模块从根模块重导出
// 语法:`pub use crate::front_of_house::hosting;`
// 效果:外部代码可直接通过 `restaurant::hosting::add_to_waitlist()` 调用
// 对比:未重导出的路径为 `restaurant::front_of_house::hosting::add_to_waitlist()`
pub use crate::front_of_house::hosting;
// 3. 内部使用:餐厅内部代码仍可使用简化路径
pub fn eat_at_restaurant() {
hosting::add_to_waitlist(); // 内部代码通过重导出的名称访问
}
/*
* 设计价值总结(基于两张图片内容):
*
* 1. 分离关注点(图片2):
* - 内部结构:员工按"前厅/后厨"组织代码,符合业务逻辑
* - 外部接口:客户按"餐厅/服务"使用 API,符合使用习惯
* - 通过 `pub use` 桥接两者,无需修改内部实现
*
* 2. API 设计优化(图片1、2):
* - 未重导出:外部调用路径冗长,暴露内部细节
* `restaurant::front_of_house::hosting::add_to_waitlist()`
* - 重导出后:外部调用路径简洁,隐藏内部结构
* `restaurant::hosting::add_to_waitlist()`
*
* 3. 维护性优势:
* - 可调整内部模块结构而不影响外部 API
* - 外部代码依赖稳定的重导出接口
* - 内部重构时,只需更新 `pub use` 语句
*
* 4. 文档影响:
* - 重导出的条目会出现在单元包文档中
* - 第14章将详细介绍如何使用 `pub use` 优化公共 API
*
* 技术对比:
* - 普通 `use`: 仅当前作用域可见,私有导入
* - `pub use`: 公开重导出,成为公共 API 的一部分
*/⑤使用外部包
// src/main.rs
// 本文件演示如何在 Rust 项目中引入并使用外部包(以 rand 为例)和标准库条目(以 HashMap 为例)。
// 第一部分:引入和使用外部包 `rand`
// 核心步骤:
// 1. 在 Cargo.toml 中添加依赖:`rand = "0.8.5"`
// 2. 在代码中使用 `use` 将所需定义引入作用域
// 3. 调用包提供的函数
// 示例1:生成1到100的随机数
// 将 `rand` 包中的 `Rng` trait 引入作用域,以便使用随机数生成器的方法
use rand::Rng;
fn main() {
// 调用 `rand::thread_rng()` 获取随机数生成器,然后调用 `gen_range` 生成指定范围内的随机数
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("生成的随机数是: {}", secret_number);
}
// 第二部分:引入和使用标准库
// 标准库(std)是内置的外部包,无需修改 Cargo.toml 文件
// 但同样需要使用 `use` 将特定条目引入作用域
// 示例2:使用标准库中的 HashMap
// 绝对路径以 `std` 开头,这是标准库单元包的名称
use std::collections::HashMap;
fn use_hashmap() {
// 创建一个 HashMap 实例
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
println!("Scores: {:?}", scores);
}⑥使用嵌套路径清理众多use语句
// src/main.rs
// 示例 7-18: 使用嵌套路径合并导入相同前缀的多个条目
// 核心:当需要从同一包/模块导入多个条目时,可用花括号 {} 列出差异部分,合并为一行
// 原始方式(两行):
// use std::cmp::Ordering;
// use std::io;
// 优化方式(一行,嵌套路径):
use std::{cmp::Ordering, io};
// 等价于同时导入了 std::cmp::Ordering 和 std::io
// 示例 7-19 和 7-20: 在嵌套路径中使用 self 关键字
// 当两条导入路径有共同前缀,且其中一条是另一条本身时,可用 self 进行合并
// 原始方式(两行):
// use std::io;
// use std::io::Write;
// 优化方式(一行,使用 self):
use std::io::{self, Write};
// 等价于同时导入了 std::io 和 std::io::Write
// 注意:self 代表 std::io 模块本身,Write 是 std::io 中的子项⑦通配符
在 Rust 中,可以使用
use语句配合*通配符,将一个路径下定义的所有公共条目一次性导入当前作用域,例如use std::collections::*;。但请谨慎使用此特性,因为它会使代码难以追踪:你很难快速判断作用域中存在哪些名称,以及某个名称具体定义在何处。
通配符导入常用于两个特定场景:一是在测试代码中,为了方便会将待测模块的所有内容引入
tests模块;二是用于构建“预导入模块”,为标准库或框架中的常用条目提供全局可用的快捷方式。
5. 将模块拆分为不同文件
①介绍
// src/lib.rs
// 示例 7-21: 当模块规模增大时,可将模块定义移至新文件以优化代码组织。
// 本文件中,仅保留对 `front_of_house` 模块的声明,其具体定义将移至单独文件。
// 注意:在创建对应的 `src/front_of_house.rs` 文件前,此代码无法通过编译。
mod front_of_house; // 声明 `front_of_house` 模块,其内容在外部文件中定义
pub use crate::front_of_house::hosting; // 重导出子模块,使其成为公共 API 的一部分
pub fn eat_at_restaurant() {
hosting::add_to_waitlist(); // 通过重导出的路径调用函数
}// src/front_of_house.rs
// 示例 7-22: `front_of_house` 模块的具体定义从 `src/lib.rs` 移动至此文件。
// 文件命名与模块声明(`mod front_of_house;`)的名称相同,编译器可自动查找。
pub mod hosting { // 在模块内定义一个子模块
pub fn add_to_waitlist() {} // 子模块中的公共函数
}// src/front_of_house.rs (修改后)
// 步骤1: 当需要进一步分离子模块时,修改父模块文件,仅声明子模块。
// 此处将 `hosting` 模块的定义移出,因此改为声明 `pub mod hosting;`。
pub mod hosting; // 声明 `hosting` 子模块,其内容将在单独文件中定义// 文件系统操作说明
// 步骤2: 为子模块创建对应的目录和文件。
// 由于 `hosting` 是 `front_of_house` 的子模块,其文件应放在以父模块命名的目录下。
// 创建目录: `src/front_of_house/`
// 创建文件: `src/front_of_house/hosting.rs`
// src/front_of_house/hosting.rs
// 步骤3: 在新建的文件中定义子模块的具体内容。
pub fn add_to_waitlist() {} // 将原 `hosting` 模块中的函数定义移至此文件// 核心规则总结
// 1. 模块声明 (`mod module_name;`) 用于从外部文件加载模块定义。
// 2. 编译器通过模块树和文件路径的对应关系查找代码:
// - 根模块声明的模块 (`mod front_of_house;`),默认在 `src/front_of_house.rs` 中查找。
// - 子模块 (`pub mod hosting;`) 需放在以父模块命名的目录下 (`src/front_of_house/hosting.rs`)。
// 3. 目录和文件的布局必须与模块树的层级结构匹配,编译器据此确定模块归属。
// 4. 只需在模块树中使用一次 `mod` 声明来加载文件,这不同于其他语言的 `include` 操作。②另一种文件路径
Rust 支持两种模块文件路径风格。对于在根节点声明的
front_of_house模块,编译器会搜索src/front_of_house.rs(常见风格)或较老的src/front_of_house/mod.rs。对于其子模块hosting,对应的路径则为src/front_of_house/hosting.rs或src/front_of_house/hosting/mod.rs。注意,不能对同一模块混用两种风格,否则会引发编译错误。虽然项目内不同模块可采用不同风格,但这可能造成混淆。此外,使用
mod.rs风格会产生多个同名文件,在编辑器中同时打开时不易区分。将模块代码拆分至独立文件,不会改变模块树的结构,模块间的函数调用依然有效。
mod关键字用于声明模块,并指示 Rust 在对应路径的文件中查找其代码;而pub use等语句则不受文件拆分的影响。这种机制使得在模块规模增长时,能轻松将其移至新文件,保持代码组织清晰。
十. 通用集合类型
1. 使用动态数组存储多个值
Vec<T> 是 Rust 标准库提供的一种动态数组集合类型。其核心功能是在单个数据结构中存储多个相同类型的值,并且这些值在内存中是彼此相邻、连续排布的。这种特性使得它非常适用于需要管理一系列同类数据的场景,例如存储一段文本中的字符序列,或是记录购物车里所有商品的价格列表。
①创建动态数组
在 Rust 中,创建动态数组(
Vec<T>)主要有两种方式:使用
Vec::new函数创建空数组:由于初始数组为空,编译器无法推断元素类型,因此通常需要显式指定类型标记,例如let v: Vec<i32> = Vec::new();。使用
vec!宏简化创建:该宏会根据提供的初始值自动创建并填充数组,并且编译器能够推断出元素的类型,例如let v = vec![1, 2, 3];会创建一个Vec<i32>。这种方式更为简洁和常用。
②更新动态数组
// src/main.rs
// 示例 8-3: 使用 push 方法向动态数组(Vec)添加元素
fn main() {
// 创建一个空的动态数组 v。必须声明为 mut 才可修改。
let mut v = Vec::new();
// 使用 push 方法依次向数组末尾添加元素
v.push(5);
v.push(6);
v.push(7);
v.push(8);
// 此时 v 的内容为 [5, 6, 7, 8]
// 注意:Rust 能根据添加的整数值自动推断出 v 的类型为 Vec<i32>,
// 因此无需显式标注类型(如 Vec<i32>)。
}③读取动态数组中的元素
// 动态数组(Vec<T>)提供了两种访问元素的方法:通过索引和使用 get 方法。
// 示例 8-4: 通过索引和 get 方法访问数组元素
// 为了清晰展示,我们在示例中标注了函数返回值的类型
fn main() {
// 创建包含5个元素的动态数组
let v = vec![1, 2, 3, 4, 5];
// 1. 通过索引访问第三个元素
// 注意:索引从0开始,所以索引2对应第三个元素
// 这种方式返回元素的直接引用,如果索引越界会导致panic
let third: &i32 = &v[2]; // 获取第三个元素的引用
println!("The third element is {third}");
// 2. 通过get方法访问第三个元素
// get方法返回Option<&T>,需要匹配处理Some和None两种情况
// 这种方式在索引越界时不会panic,而是返回None
let third: Option<&i32> = v.get(2);
match third {
Some(third) => println!("The third element is {third}"),
None => println!("There is no third element."),
}
}
// 示例 8-5: 尝试访问不存在的元素
// Rust提供了两种引用方式,让开发者可以选择程序的响应方式
// 这个示例尝试访问只有5个元素的数组的第100个元素
fn access_out_of_bounds() {
let v = vec![1, 2, 3, 4, 5];
// 1. 使用索引方式 - 会导致panic
// 当索引越界时,[]方法会触发panic,适合希望程序直接崩溃的场景
// let does_not_exist = &v[100]; // 取消注释会导致panic
// 2. 使用get方法 - 返回None
// get方法检测到索引越界时返回None,不会使程序崩溃
// 适合偶尔越界访问是正常行为的场景
let does_not_exist = v.get(100);
match does_not_exist {
Some(value) => println!("Found: {value}"),
None => println!("No element at index 100"),
}
// 例如,索引来自用户输入时,应该处理None情况并向用户提供反馈
}
// 示例 8-6: 在持有引用时尝试修改数组
// 这个示例违反了Rust的借用规则:不能同时拥有可变引用和不可变引用
fn invalid_reference_usage() {
let mut v = vec![1, 2, 3, 4, 5];
// 获取第一个元素的不可变引用
let first = &v[0]; // 不可变借用发生在这里
// 尝试向数组添加元素 - 这需要可变借用
// v.push(6); // 错误:不能对v进行可变借用,因为它已经被不可变借用
// 在不可变引用first的后面使用了它
println!("The first element is: {first}");
// 错误信息:cannot borrow `v` as mutable because it is also borrowed as immutable
}
// 借用检查器解释:
// 动态数组中的元素是连续存储的。当向数组末尾添加新元素时,如果当前空间不足,
// 可能需要重新分配内存并将所有元素移动到新的位置。这会导致原有的引用指向被释放的内存。
// 借用规则(不能同时拥有可变和不可变引用)帮助我们避免这类悬垂引用问题。④遍历动态数组中的值
// src/main.rs
// 示例 8-7: 使用 for 循环遍历并打印动态数组中的所有元素
// 核心:通过 for 循环获取数组中每个元素的不可变引用,无需手动管理索引
fn main() {
let v = vec![100, 32, 57];
for i in &v { // 遍历数组 v 的不可变引用
println!("{}", i); // 打印每个元素
}
}
// 示例 8-8: 遍历动态数组,获取所有元素的可变引用并修改其值
// 核心:通过 for 循环获取数组中每个元素的可变引用,并修改其指向的值
fn main() {
let mut v = vec![100, 32, 57]; // 数组必须声明为 mut
for i in &mut v { // 遍历数组 v 的可变引用
*i += 50; // 通过解引用运算符 * 获取 i 存储的值,并加 50
}
// 注意:修改后 v 变为 [150, 82, 107]
}
/*
* 补充说明(基于图片2):
* 1. 解引用运算符 (*) 用于获取可变引用指向的底层值,以便进行修改。第 15 章将深入讨论。
* 2. 借用检查规则保证了遍历的安全性。无论是在 for 循环中持有不可变引用(如示例8-7)还是可变引用(如示例8-8),都会阻止在遍历期间修改整个数组的结构(如插入或删除元素)。尝试在 for 循环体内修改数组结构会导致编译时错误,这类似于示例8-6中的错误,避免了潜在的并发数据访问问题。
*/⑤使用枚举存储多个类型的值
// src/main.rs
// 示例 8-9: 在动态数组中存储不同类型的值
// 动态数组(Vec<T>)通常只能存储相同类型的元素,但通过定义枚举类型,可以将不同类型的值统一封装在枚举的不同变体中。
// 因为所有枚举变体都属于同一个枚举类型,所以可以将枚举存入动态数组,从而间接实现存储多种类型。
// 本示例模拟表格单元值,可以是整数、浮点数或字符串。
// 定义 SpreadsheetCell 枚举,包含三种变体,分别存储不同类型的数据
// 每个变体相当于一种类型的数据容器
enum SpreadsheetCell {
Int(i32), // 存储整数
Float(f64), // 存储浮点数
Text(String), // 存储字符串
}
fn main() {
// 创建动态数组 row,包含不同类型的 SpreadsheetCell 枚举变体
// 通过 vec! 宏初始化数组,编译器可推断出 Vec<SpreadsheetCell> 类型
let row = vec![
SpreadsheetCell::Int(3), // 整数值 3
SpreadsheetCell::Text(String::from("blue")), // 字符串值 "blue"
SpreadsheetCell::Float(10.12), // 浮点数值 10.12
];
// 现在 row 中存储了三种不同类型的值,但统一为 SpreadsheetCell 枚举类型
// 可通过模式匹配(match)处理每个元素,编译器确保所有变体都得到处理
}
/*
* 设计原理与注意事项(对应第2张图):
* 1. 编译时类型确定:Rust 需要在编译时确定动态数组的类型,以计算堆上所需存储空间。
* 2. 枚举的优势:枚举明确列出所有可能的变体类型,结合 `match` 表达式可在编译时保证所有情况都得到妥善处理,避免运行时类型错误。
* 3. 适用场景:当所有可能出现在动态数组中的类型可以在编写代码时穷尽,枚举是理想选择。
* 4. 扩展性:如果无法在编译时穷尽所有类型,可考虑使用第 17 章将介绍的 trait 对象。
* 5. 其他方法:标准库为 `Vec<T>` 提供了丰富的方法,如 `push` 添加元素,`pop` 移除并返回最后一个元素等。请查阅 API 文档获取完整信息。
*/⑥在销毁动态数组时也销毁其中的元素
// src/main.rs
// 示例 8-10: 展示动态数组及其元素在离开作用域时被自动销毁的位置
// 核心机制:动态数组在离开其作用域时,会自动释放其分配的内存,其持有的所有元素也会被清理。
fn main() {
// 创建动态数组 v,包含三个整数元素
let v = vec![1, 2, 3];
// 在此处可以使用 v 及其引用
// ...
} // 作用域在此结束,动态数组 v 离开作用域,其内存被自动释放,所有元素(整数1、2、3)也被销毁。
// 重要安全保证:
// Rust 的借用检查器确保,任何指向动态数组内部数据的引用,都只能在动态数组本身有效期间(即其作用域内)被使用。
// 这从根本上防止了悬垂引用(dangling references)等内存安全问题。2. 使用字符串存储UTF-8编码的文本
Rust 字符串对于新手来说容易出错,主要有三方面原因:一是 Rust 的设计倾向于在编译时暴露潜在的错误;二是字符串本身的数据结构比许多开发者想象的更为复杂;三是 Rust 字符串采用 UTF-8 编码。
之所以在集合章节讨论字符串,是因为其本质就是字节的集合,并通过一系列方法将这些字节解析为文本。字符串的操作(如创建、更新和访问)与其他集合类型有相似之处,但也有其特殊性和复杂性。例如,直接通过索引访问字符串中的字符通常很困难,这源于人和计算机对同一段字符串数据的解释方式存在差异。
①字符串是什么
Rust 的字符串涉及两种主要类型。在语言核心层面是字符串切片(
str),它通常以引用的形式(&str)出现,是一个指向存储在别处的 UTF-8 编码字符串数据的不可变视图,例如程序中的字符串字面量就属于此类。另一种是定义在标准库中的
String 类型。它是可增长、可变的,并且自身拥有其字符串数据,同样基于 UTF-8 编码。在 Rust 的语境中,当开发者提及“字符串”时,通常泛指String和字符串切片&str这两种密切相关且广泛使用的类型。
②创建一个新的字符串
// src/main.rs
// 示例 8-11 至 8-14: Rust 中 String 的创建与 UTF-8 编码特性
// 核心1: String 的实现基于一个字节向量 (Vec<u8>),因此许多 Vec<T> 的操作也适用于 String。
// 核心2: 字符串是 UTF-8 编码的,可存储任何合法的 Unicode 文本数据。
fn main() {
// 示例 8-11: 使用 new 关联函数创建一个新的空 String
let mut s = String::new(); // 创建后可填入数据
// 示例 8-12: 对实现了 Display trait 的类型调用 to_string 方法
// 可以从字符串字面量或其他类型(如数字)创建 String
let data = "initial contents";
let s1 = data.to_string(); // 从 &str 创建
let s2 = "initial contents".to_string(); // 直接对字面量调用
// 示例 8-13: 使用 String::from 函数基于字面量创建 String
// 功能上与 to_string 等效,是另一种风格的选择
let s3 = String::from("initial contents");
// 示例 8-14: 演示 String 可存储多种 UTF-8 编码的语言文本
// 以下是存储在字符串中的不同语言的问候语,均为合法的 String 值
let hello_arabic = String::from("السلام عليكم");
let hello_czech = String::from("Dobrý den");
let hello_english = String::from("Hello");
let hello_hindi = String::from("नमस्ते");
let hello_japanese = String::from("こんにちは");
let hello_korean = String::from("안녕하세요");
let hello_chinese = String::from("你好");
let hello_portuguese = String::from("Olá");
let hello_russian = String::from("Добрый день");
let hello_spanish = String::from("Hola");
}③更新字符串
使用push_str或push向字符串中添加内容
// src/main.rs
// 示例 8-15: 使用 `push_str` 方法向 `String` 尾部追加字符串切片
// 注意:`push_str` 接收一个字符串切片参数,不获取其所有权,因此后续仍可使用被追加的字符串
fn main() {
// 1. 创建一个可变的 String
let mut s1 = String::from("foo");
// 2. 创建一个字符串切片
let s2 = "bar";
// 3. 向 s1 尾部追加 s2
s1.push_str(s2);
// 4. 打印 s2,证明其所有权未被获取,仍可用
println!("s2 is {s2}");
// 5. 此时 s1 的内容为 "foobar"
println!("s1 is {s1}");
}
// 示例 8-16: 通过拼接后打印 s2 证明 `push_str` 不获取所有权
// 如果 `push_str` 取得 s2 的所有权,将无法在后续打印
// 代码同上,但注释更强调所有权行为
// 示例 8-17: 使用 `push` 方法向 `String` 尾部追加单个字符
// `push` 方法接收一个字符参数,并将其添加到字符串末尾
fn push_example() {
let mut s = String::from("lo");
s.push('l'); // 向字符串 "lo" 追加字符 'l'
// 执行后,s 的内容变为 "lol"
println!("After push: s is {s}"); // 输出: lol
}使用+运算符将两个String合并到一个新的String中
// src/main.rs
// 示例 8-18: 使用 `+` 运算符合并两个已存在的字符串
// 核心:`+` 运算符调用 `add` 方法,会获取第一个操作数(`s1`)的所有权,并接受第二个操作数(`s2`)的引用
fn main() {
let s1 = String::from("Hello, ");
let s2 = String::from("world!");
// 注意:`s1` 在加法操作后被移动,无法再使用
// 这是因为 `+` 运算符调用的 `add` 方法签名类似:fn add(self, s: &str) -> String
// 其中 `self` 会获取第一个操作数的所有权
let s3 = s1 + &s2; // 等价于 s1.add(&s2)
// 执行后,s3 的内容为 "Hello, world!"
println!("{}", s3);
// 尝试使用 s1 会导致编译错误
// println!("{}", s1); // 取消注释将导致编译错误
}
// 示例 8-19: 通过拼接多个字符串展示 `+` 运算符的局限性
// 当需要拼接多个字符串时,使用 `+` 运算符会使代码难以阅读和分析
fn concatenate_with_plus() {
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
// 拼接字符串 "tic-tac-toe",但代码可读性差
let s = s1 + "-" + &s2 + "-" + &s3;
// 此时 s 的内容为 "tic-tac-toe"
// 注意:s1 的所有权在第一次加法时被移动,后续不能再使用
println!("{}", s);
}
// 示例 8-20: 使用 `format!` 宏拼接多个字符串
// 对于复杂的字符串合并,`format!` 宏是更可读、更安全的选择
// 它不会获取任何参数的所有权,而是生成一个新的字符串
fn concatenate_with_format() {
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
// 使用 `format!` 宏,与 `println!` 类似,但返回一个字符串
let s = format!("{}-{}-{}", s1, s2, s3);
// 此时 s 的内容同样为 "tic-tac-toe"
// 但 s1、s2、s3 的所有权均未被移动,仍可继续使用
println!("s1: {}, s2: {}, s3: {}", s1, s2, s3);
println!("s: {}", s);
}
/*
* 核心机制解释(基于第2、3张图片):
*
* 1. `+` 运算符与 `add` 方法:
* - `+` 运算符调用 `add(self, s: &str) -> String` 方法
* - `self` 会获取第一个操作数的所有权,所以 `s1` 在操作后失效
* - 第二个参数为 `&str` 类型,但可以传递 `&String`,因为 Rust 会自动进行解引用转换
* - 解引用转换(deref coercion)将 `&String` 转换为 `&str`(即 `&s2[..]`)
*
* 2. 效率说明:
* - `add` 方法不会复制整个字符串,而是将第二个字符串的内容追加(复制)到第一个字符串中
* - 这避免了不必要的复制,是高效的实现
*
* 3. 设计建议:
* - 对于简单的两个字符串合并,`+` 运算符是合适的
* - 对于复杂的多字符串拼接,推荐使用 `format!` 宏
* - `format!` 宏生成可读性更高的代码,且不会获取参数的所有权
*/④索引字符串
内部布局
// src/main.rs
// 示例 8-19(对应图片1、2): 尝试对 String 使用索引语法访问字符
// 核心:Rust 的 String 类型不支持通过整数索引直接访问其内部的字符。
// 这与许多其他语言(如 Python、Java)不同,是 Rust 的安全设计之一。
// 下面的代码无法通过编译,因为 String 类型没有实现 Index<{integer}> trait
fn main() {
let s1 = String::from("hello");
// 尝试通过索引 0 获取第一个字符
// 错误:类型 `String` 不能被整数索引
// 编译错误信息:error[E0277]: the type `String` cannot be indexed by `{integer}`
let h = s1[0];
}
// 核心原因说明(对应图片2):
// 1. Rust 字符串在内存中以 UTF-8 编码存储,每个字符的字节长度可能不同(1-4字节)。
// 2. 通过整数索引无法保证在常数时间内获取到字符,因为需要从头遍历计算字节位置。
// 3. 索引操作通常期望是 O(1) 时间复杂度,但 UTF-8 字符串无法满足。
// 4. 为了避免误解和运行时错误,Rust 选择在编译时禁止此操作。
// 后续将详细讨论 Rust 在内存中存储字符串的方式,以及如何正确访问字符串中的字符。// src/main.rs
// 示例说明 Rust 字符串的内部表示和索引访问限制
// 核心要点:Rust 的 `String` 是 `Vec<u8>` 的封装,以 UTF-8 格式编码字符,不同字符占用的字节数可变。
// 示例 1: 测量字符串长度(字节数),说明 UTF-8 编码特性
fn measure_string_length() {
// 1. 拉丁字母示例
// 字符串 "Hola" 使用 UTF-8 编码,每个字符占 1 字节,总长度为 4
let hello_len = String::from("Hola").len(); // 返回 4
println!("'Hola' 的长度(字节数): {}", hello_len);
// 2. 西里尔字母示例
// 字符串 "Здравствуйте" 包含 12 个字符,但每个字符占 2 字节,总长度为 24
let hello_len_cyrillic = String::from("Здравствуйте").len(); // 返回 24
println!("'Здравствуйте' 的长度(字节数): {}", hello_len_cyrillic);
}
// 示例 2: 解释为何 Rust 不允许通过整数索引直接访问字符串中的字符
fn explain_index_restriction() {
// 1. 非法代码示例
// 以下代码无法通过编译,Rust 禁止通过索引直接访问字符串中的字节/字符
// let hello = "Здравствуйте";
// let answer = &hello[0]; // 错误:尝试访问第一个字节
/*
* 编译错误原因(基于两张图片内容):
* 1. 编码复杂性:
* - 字符 "З" 在 UTF-8 编码中由字节 208 和 151 表示
* - 索引 0 返回字节 208,但它不是一个完整的字符,无实际意义
* 2. 语义混淆:
* - 即使对于单字节字符(如拉丁字母 "h"),&"hello"[0] 会返回字节值 104
* - 用户通常期望获取字符 "h",而不是数字 104
* 3. 安全设计:
* - Rust 在编译时拒绝此类代码,避免运行时错误和语义误解
* - 这符合 Rust 的内存安全和类型安全哲学
*/
}
// 正确做法提示:
// 要遍历字符串的字符,可使用 `.chars()` 方法
// 要遍历字符串的字节,可使用 `.bytes()` 方法
fn proper_string_iteration() {
let s = "Здравствуйте";
// 按字符迭代
for c in s.chars() {
println!("字符: {}", c);
}
// 按字节迭代
for b in s.bytes() {
println!("字节: {}", b);
}
}
fn main() {
measure_string_length();
explain_index_restriction();
proper_string_iteration();
}字节、标量和字形簇
// src/main.rs
// 示例:展示 Rust 中字符串数据的三种查看方式
// 核心概念:Rust 的字符串使用 UTF-8 编码,可以按字节、Unicode 标量值(char)和字形簇三种不同方式解析
// 注意:字形簇的处理需要引入第三方库 `unicode-segmentation`
// 在 Cargo.toml 中添加:unicode-segmentation = "1.10.0"
// 引入第三方库以处理字形簇
use unicode_segmentation::UnicodeSegmentation;
fn main() {
// 示例字符串:梵文书写的印度语单词 "नमसे"
let word = "नमसे";
// 1. 查看字节表示(u8 值)
// UTF-8 编码中,每个字符可能占用1到4个字节
// 此单词在内存中存储为18个字节
let bytes = word.as_bytes();
println!("字节表示 ({} 字节): {:?}", bytes.len(), bytes);
// 输出: [224, 164, 168, 224, 164, 174, 224, 164, 184, 224, 165, 141, 224, 164, 164, 224, 165, 135]
// 2. 查看 Unicode 标量值(Rust 中的 char 类型)
// 每个 char 对应一个 Unicode 标量值,但注意:某些 char 单独无意义(如音标)
let chars: Vec<char> = word.chars().collect();
println!("Unicode 标量值 ({} 个 char): {:?}", chars.len(), chars);
// 输出: ['न', 'म', 'स', 'े', 'त', 'े']
// 注意:第四个和第六个是音标,不独立成字母
// 3. 查看字形簇(最接近人类理解的“字母”)
// 字形簇是用户感知的基本单位,由多个 Unicode 标量值组合而成
// 需要 `unicode-segmentation` 库支持
let graphemes: Vec<&str> = word.graphemes(true).collect();
println!("字形簇 ({} 个): {:?}", graphemes.len(), graphemes);
// 输出: ["न", "म", "स", "ते"]
// 解释:为什么 Rust 不允许通过整数索引直接访问字符串中的字符?
// 1. 性能预期:索引操作通常期望是常数时间 O(1),但 UTF-8 字符串无法保证。
// 2. 编码变长:UTF-8 字符占用字节数不同,必须从头遍历才能确定第 n 个字符的位置。
// 3. 语义模糊:索引是应该返回字节、char 还是字形簇?Rust 避免歧义,要求显式选择处理方式。
// 4. 安全设计:防止返回无效的字符片段(如孤立的 UTF-8 字节),避免运行时错误。
// 正确做法:根据需求选择遍历方式
println!("\n按字节遍历:");
for (i, &byte) in word.as_bytes().iter().enumerate() {
println!(" 字节索引 {}: {}", i, byte);
}
println!("\n按 char 遍历:");
for (i, c) in word.chars().enumerate() {
println!(" char 索引 {}: {}", i, c);
}
println!("\n按字形簇遍历:");
for (i, g) in word.graphemes(true).enumerate() {
println!(" 字形簇索引 {}: {}", i, g);
}
}
/*
* 总结:
* 1. Rust 字符串是 UTF-8 编码的字节序列,提供三种视角:字节、Unicode 标量值(char)、字形簇。
* 2. 禁止直接索引是因为 UTF-8 的变长编码特性,无法保证常数时间访问,且语义不明确。
* 3. 程序员应显式选择所需的解析方式,通过相应方法(bytes()、chars()、graphemes())进行遍历。
* 4. 这种设计虽然在开始时可能带来不便,但避免了其他语言中常见的字符串处理错误,并支持国际化。
*/ ⑤字符串切片
// 注意:在Rust中,通过索引直接访问字符串通常是不明确的,因为返回值类型可以是字节、字符、字形簇或字符串切片。
// 如果需要创建字符串切片,必须通过索引范围明确指定字节范围。
fn main() {
// 定义字符串"Здравствуйте",其中每个字符占2字节
let hello = "Здравствуйте";
// 通过范围[0..4]创建字符串切片,包含前4个字节(即前2个字符)
// 此范围必须对应有效的UTF-8字符边界,否则会触发panic
let s = &hello[0..4]; // 正确:包含字符"Зд"(每个字符2字节)
println!("切片内容: {}", s); // 输出: "Зд"
// 注意:尝试创建跨越字符边界的切片会导致panic
// 例如,&hello[0..1] 会触发panic,因为索引1不是有效的字符边界
// 编译可通过,但运行时会产生类似以下错误信息:
// thread 'main' panicked at 'byte index 1 is not a char boundary; it is inside 'З' (bytes 0..2) of `Здравствуйте`', src/main.rs:4:14
// 因此,应谨慎使用范围语法创建字符串切片,确保范围对应有效的字符边界
}⑥遍历字符串
// src/main.rs
// 为了更好地处理字符串中的各个部分,你需要明确指定是处理字符(Unicode 标量值)还是字节。
// 对于单个 Unicode 标量值,可以使用 `chars` 方法。
// 例如,对字符串 "Зд" 调用 `chars` 会返回两个 `char` 类型的值,之后可遍历每个元素:
let s = "Зд";
// 通过 chars 方法遍历每个 Unicode 标量值(字符)
for c in s.chars() {
println!("{}", c);
}
// 输出:
// З
// д
// 或者,可以使用 `bytes` 方法来依次返回每个原始字节,在某些场景下可能有用:
// 通过 bytes 方法遍历每个原始字节
for b in s.bytes() {
println!("{}", b);
}
// 这段代码会打印出组成这个字符串的 4 个字节值:
// 208
// 151
// 208
// 180
// 注意:合法的 Unicode 标量值可能会占用 1 个字节以上的空间。
// 从字符串中获取字形簇(grapheme cluster)相对复杂,标准库没有提供此功能。
// 如果有这方面的需求,可以在 crates.io 上获取相关的开源库(例如 `unicode-segmentation`)。⑦处理字符串的复杂性
总而言之,字符串的处理确实复杂,而不同的编程语言对此有不同的设计考量。Rust 明确选择将正确处理 UTF-8 数据作为所有程序的默认行为。这意味着开发者需要提前理解并处理与 UTF-8 编码相关的细节。虽然相较于某些语言,这确实在前期暴露了更多的复杂性,但它有效地避免了在开发后期,尤其是涉及非 ASCII 字符(如各种语言文字、表情符号)时可能出现的棘手错误。
所幸的是,Rust 标准库为
String和&str类型提供了大量实用的功能(例如用于搜索的contains方法和用于替换的replace方法),以帮助开发者稳健地处理这些复杂情况。
3. 在哈希映射中存储键值对
哈希映射(
HashMap<K, V>)用于存储从键(类型K)到值(类型V)的映射关系。其内部通过一个哈希函数来决定如何存储这些键值对。该数据结构在不同编程语言中名称各异,如哈希、映射、对象、哈希表、字典或关联数组,但其核心功能是相似的。当你需要根据特定键(而不仅仅是数字索引)来高效地查找、插入或更新数据时,哈希映射尤其有用。例如,在一个游戏中,你可以将团队名称作为键,团队得分作为值存入哈希映射,从而能通过团队名快速查询其当前分数。
①创建一个新的哈希映射
// 引入标准库中的哈希映射类型
use std::collections::HashMap;
fn main() {
// 创建一个新的、可变的空哈希映射
let mut scores = HashMap::new();
// 向哈希映射中插入键值对:键为队伍名称(String),值为分数(i32)
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
// 示例说明:
// 1. 哈希映射的使用频率低于动态数组和字符串,因此需手动引入,不在预导入模块中。
// 2. 哈希映射将数据存储在堆上。
// 3. 哈希映射是同质的:所有键必须为同一类型(此处为String),所有值也必须为同一类型(此处为i32)。
// 4. 标准库未提供用于构建哈希映射的内置宏,需逐个插入键值对。
}②访问哈希映射中的值
// 导入标准库中的哈希映射类型
use std::collections::HashMap;
fn main() {
// 1. 创建哈希映射并插入键值对
// 创建可变的哈希映射scores,存储String到i32的映射
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
// 2. 通过键获取对应的值
// 定义要查询的键
let team_name = String::from("Blue");
// 通过get方法获取Option<&i32>,再通过copied转为Option<i32>,最后通过unwrap_or处理未找到的情况
let score = scores.get(&team_name).copied().unwrap_or(0);
println!("Blue队的分数是: {}", score);
// 3. 遍历哈希映射中的所有键值对
// 通过for循环遍历哈希映射的引用,每次迭代返回一个键值对的引用
// 注意:遍历的顺序是不确定的,可能与插入顺序不同
println!("\n遍历所有队伍分数:");
for (key, value) in &scores {
println!("{key}: {value}");
}
}③哈希映射与所有权
// src/main.rs
// 示例 8-22: 演示向 HashMap 插入数据时,所有权规则如何作用
// 1. 对于实现 Copy trait 的类型(如 i32),其值被复制到哈希映射中,原变量仍可用。
// 2. 对于拥有所有权的类型(如 String),其值在插入时发生移动,所有权转移给哈希映射,原变量失效。
// 3. 若插入的是引用,则不会转移所有权,但需保证引用的有效性与哈希映射相同。
use std::collections::HashMap;
fn main() {
// 情况1: 插入拥有所有权的 String 类型
let field_name = String::from("Favorite color");
let field_value = String::from("Blue");
let mut map = HashMap::new();
map.insert(field_name, field_value); // 此时 field_name 和 field_value 的所有权被移动
// 尝试在此处使用 field_name 或 field_value 将导致编译错误
// println!("{}", field_name); // 错误:value borrowed here after move
// println!("{}", field_value); // 错误:value borrowed here after move
// 情况2: 插入实现 Copy trait 的 i32 类型
let num_key = 1;
let num_val = 100;
map.insert(num_key.to_string(), num_val); // num_val 被复制,原变量仍可用
println!("num_val 仍可用: {}", num_val); // 正确
// 情况3: 插入引用(需注意生命周期)
let my_key = "my_key";
let my_val = 42;
map.insert(my_key.to_string(), &my_val); // 插入 my_val 的引用
// 此时 my_key 和 my_val 必须比 map 存活更久,否则会导致悬垂引用
// 关于生命周期的详细讨论见第10章
}④更新哈希映射
覆盖旧值
// src/main.rs
// 示例 8-23: 在哈希映射中,使用相同键插入新值会覆盖旧值
// 核心:对同一键调用 insert 会替换原值,最终只保留最后一次插入的值。
use std::collections::HashMap;
fn main() {
let mut scores = HashMap::new();
// 第一次插入,键"Blue"对应值10
scores.insert(String::from("Blue"), 10);
// 第二次使用相同键"Blue"插入,值25会覆盖原来的10
scores.insert(String::from("Blue"), 25);
// 打印哈希映射,将只包含{"Blue": 25}
// 注意:实际编译时,HashMap未实现Display,需用Debug打印({:?}),此处按原图保留
println!("{}", scores);
}只在健没有对应值时添加新值
// 引入标准库中的哈希映射
use std::collections::HashMap;
fn main() {
// 创建一个可变的哈希映射,用于存储队伍名称(String)到分数(i32)的映射
let mut scores = HashMap::new();
// 预先为蓝队插入一个分数值 10
scores.insert(String::from("Blue"), 10);
// 使用 entry API 处理键 "Yellow" 和 "Blue"
// 1. 检查键 "Yellow" 是否存在,不存在则插入 50
scores.entry(String::from("Yellow")).or_insert(50);
// 2. 检查键 "Blue" 是否存在,存在则保留原值 10
scores.entry(String::from("Blue")).or_insert(50);
// 打印哈希映射的内容
println!("{:?}", scores);
// 运行结果:{"Yellow": 50, "Blue": 10}
// 说明:黄队原本不存在,所以插入了 50;蓝队已存在值为 10,所以保持不变
}基于旧值来更新值
// src/main.rs
// 示例 8-25: 使用哈希映射统计文本中每个单词的出现次数
// 核心思路:遍历文本中的每个单词,在哈希映射中记录其出现次数。
// 如果单词是首次出现,则插入初始值0,然后对其计数值加1。
// 引入标准库中的 HashMap
use std::collections::HashMap;
fn main() {
// 定义要统计的文本
let text = "hello world wonderful world";
// 创建一个可变的哈希映射,键为单词(&str),值为出现次数(i32)
let mut map = HashMap::new();
// 遍历文本中的每个单词(以空白符分隔)
for word in text.split_whitespace() {
// 使用 entry API 检查当前单词是否已存在于映射中
// or_insert(0) 会:
// - 如果单词存在,返回其对应值的可变引用
// - 如果不存在,先插入值0,再返回这个新值的可变引用
let count = map.entry(word).or_insert(0);
// 对返回的可变引用进行解引用,然后将计数值加1
*count += 1;
}
// 打印统计结果
// 注意:哈希映射的遍历顺序是不确定的,因此每次输出的键值对顺序可能不同
// 可能的输出:{"world": 2, "hello": 1, "wonderful": 1}
println!("{:?}", map);
}4. 哈希函数
Rust 的
HashMap<K, V>默认使用名为 SipHash 的哈希函数。这个选择主要基于安全考量,旨在有效抵御一种特定的拒绝服务攻击。虽然 SipHash 并非最快的哈希算法,但其提供的安全性通常值得付出少许性能代价。如果性能分析表明默认的哈希函数成为瓶颈,你可以更换为其他哈希算法。这通过指定一个实现了
BuildHashertrait 的哈希计算器(hasher)类型来实现。Rust 社区在 crates.io 上提供了大量基于不同哈希算法的开源实现,可供选择。
十一. 错误处理
Rust 将错误明确分为可恢复与不可恢复两类,并为其提供了截然不同的处理机制。对于文件未找到这类可恢复的错误,Rust 通过
Result<T, E>枚举来报告错误,允许开发者选择重试或向用户反馈。而对于数组越界等表明存在程序逻辑漏洞的不可恢复错误(即Bug),Rust 则会通过panic!宏直接终止程序,防止错误状态扩散。这种设计与大多数依赖异常机制的语言有根本区别。Rust 不提供异常,而是通过类型系统(
Result<T, E>)和专门的宏(panic!)来结构化地处理不同性质的错误,从而强制开发者在编译时就明确对错误的处理意图。
1. 不可恢复错误与panic!
[package]
name = "panic_demo"
version = "0.1.0"
edition = "2021"
# 配置 panic 行为:默认“展开”(unwind) 或 “中止”(abort)
# “展开”会遍历调用栈并清理数据,二进制文件较大。
# “中止”直接结束,不清理,二进制文件更小。内存由OS回收。
# 在 [profile.release] 下设置 panic = 'abort' 可缩小生产环境的二进制体积。
# 例如:
# [profile.release]
# panic = 'abort'//! 本文件演示 Rust 中 `panic!` 的触发、行为与调试。
//!
//! `panic!` 用于处理不可恢复的错误,发生时程序默认会:
//! 1. 打印错误信息。
//! 2. 展开调用栈并清理数据。
//! 3. 退出程序。
/// 示例 1: 显式调用 `panic!` 宏
/// 这是最直接的触发方式,用于处理程序无法继续执行的严重错误。
fn explicit_panic() {
panic!("crash and burn"); // 触发 panic,程序将在此终止
}
/// 示例 2: 因 Bug 隐式触发 panic (数组越界访问)
/// 当执行非法操作(如访问无效索引)时,Rust 标准库会调用 `panic!`。
/// 这可以防止 C 语言中常见的“缓冲区溢出”等安全问题。
fn implicit_panic_from_bug() {
let v = vec![1, 2, 3];
// 尝试访问第 100 个元素(索引 99),但数组长度仅为 3。
// 这将导致 Rust 运行时 panic,防止访问非法内存。
v[99]; // 此行触发 panic: index out of bounds
}
fn main() {
println!("=== 演示 1: 显式调用 panic! ===");
// 取消下一行注释以运行示例1
// explicit_panic();
println!("\n=== 演示 2: 数组越界触发 panic! ===");
// 取消下一行注释以运行示例2
// implicit_panic_from_bug();
println!("\n提示:要查看详细的调用栈回溯信息,请设置环境变量 RUST_BACKTRACE=1");
println!("例如在终端执行:RUST_BACKTRACE=1 cargo run");
// 回溯信息能列出从起点到错误点的所有函数调用,帮助你定位问题根源。
// 注意:回溯信息可能很长,关键是从底部找到你编写的代码文件(如 src/main.rs)。
}
// 当程序 panic 且设置了 RUST_BACKTRACE=1 时,会输出如下的回溯信息:
// thread 'main' panicked at 'index out of bounds: the len is 3 but the index is 99', src/main.rs:4:5
// stack backtrace:
// 0: rust_begin_unwind
// ...
// 6: panic_demo::implicit_panic_from_bug
// at src/main.rs:16:5 // <-- 这一行指向你代码中触发 panic 的位置
// 7: panic_demo::main
// at src/main.rs:27:5
//
// 解读与使用方法:
// 1. 第一行指明了 panic 的原因和发生位置(文件:行:列)。
// 2. 回溯列表(backtrace)展示了函数调用链。
// 3. 从列表的**底部**(本例为第7行)往上看,找到属于你项目的模块(如 `panic_demo::`)。
// 4. 该行指向的代码位置(`src/main.rs:27:5`)就是你需要调查和修复的起点。
//
// 注意:
// * 回溯信息的具体内容因操作系统、Rust 版本而异。
// * 必须在调试模式(默认的 `cargo run` 或 `cargo build`)下才能获得详细的回溯信息。
// * 使用 `RUST_BACKTRACE=full` 可获取更详尽的信息。2. 可恢复错误与Result
①介绍
// 1. 大部分错误其实没有严重到需要整个程序停止运行的程度。函数常常会由于一些可以简单解释并做出响应的原因而运行失败。
// 例如,尝试打开文件的操作会因为文件不存在而失败。在这种情形下,你可能会考虑创建该文件而不是中止进程。
// 2. 第2章介绍了Result类型,它被定义为两个变体:Ok和Err
// Result<T, E> 是一个枚举,T 代表成功时返回的值类型,E 代表错误时返回的错误类型
// 由于泛型参数,Result可以用于多种需要返回不同成功值和错误值的场景
// 示例9-3: 调用可能失败的函数,它会返回Result值
use std::fs::File;
fn main() {
// 尝试打开名为"hello.txt"的文件
// File::open返回Result<T, E>类型,T是std::fs::File(文件句柄),E是std::io::Error
let greeting_file_result = File::open("hello.txt");
// 成功时返回包含文件句柄的Ok实例,失败时返回包含错误信息的Err实例
}
// 示例9-4: 使用match表达式处理所有可能的Result变体
fn main_with_match() {
use std::fs::File;
let greeting_file_result = File::open("hello.txt");
// 使用match表达式处理Result
let greeting_file = match greeting_file_result {
Ok(file) => file, // 成功时返回文件句柄
Err(error) => {
// 失败时调用panic!宏终止程序
panic!("Problem opening the file: {:?}", error);
}
};
// 成功后可以使用greeting_file进行读写操作
}
// 注意:Result枚举及其变体已通过预导入模块自动引入作用域,无需显式指明Result::
// 当结果是Ok时,代码会将Ok变体内部的file值移出,绑定到greeting_file变量
// 当结果是Err时,通过panic!宏处理错误
// 运行代码时,如果当前目录中不存在hello.txt文件,panic!宏会输出类似以下信息:
// thread 'main' panicked at 'Problem opening the file: Os { code: 2, kind: NotFound, message: "No such file or directory" }', src/main.rs:10:13
// 这明确指出了错误的原因②匹配不同的错误
使用match处理错误
// src/main.rs
// 示例 9-5: 以不同的方式处理不同的错误类型
// 目标:根据 File::open 失败的具体原因采取不同的处理策略
// 1. 如果是因为文件不存在,则创建该文件。
// 2. 如果是其他错误(如权限不足),则直接触发 panic!。
// 引入标准库中的文件操作模块和错误类型枚举
use std::fs::File;
use std::io::ErrorKind;
fn main() {
// 尝试打开名为 "hello.txt" 的文件,返回 Result<T, E> 类型
let greeting_file_result = File::open("hello.txt");
// 使用 match 表达式处理 greeting_file_result
let greeting_file = match greeting_file_result {
// 成功打开文件,返回文件句柄
Ok(file) => file,
// 打开文件失败,根据错误类型进行不同处理
Err(error) => match error.kind() {
// 如果错误是因为文件不存在
ErrorKind::NotFound => {
// 尝试创建文件
match File::create("hello.txt") {
// 创建成功,返回新文件的句柄
Ok(fc) => fc,
// 创建文件失败,触发 panic! 并显示错误信息
Err(e) => panic!(
"Problem creating the file: {:?}",
e
),
}
}
// 如果是其他类型的错误(如权限不足),则直接触发 panic!
other_error => {
panic!(
"Problem opening the file: {:?}",
other_error
);
}
},
};
// 成功获取文件句柄后,后续可以进行文件操作
}使用非match处理错误
// src/main.rs
// 本示例演示如何使用闭包和 `unwrap_or_else` 方法处理文件打开操作,替代嵌套的 `match` 表达式。
// 这种方式比示例9-5的代码更清晰、简洁,是处理 Result<T, E> 的常用模式。
// 引入标准库中的文件操作模块和错误类型枚举
use std::fs::File;
use std::io::ErrorKind;
fn main() {
// 使用 `unwrap_or_else` 方法处理 File::open 返回的 Result<T, E>
// 核心逻辑:
// 1. 尝试打开名为 "hello.txt" 的文件
// 2. 成功则返回文件句柄
// 3. 失败则执行传入的闭包进行错误处理
let greeting_file = File::open("hello.txt").unwrap_or_else(|error| {
// 闭包接收错误值 `error` 作为参数
// 判断错误类型是否为 NotFound(文件不存在)
if error.kind() == ErrorKind::NotFound {
// 尝试创建文件
File::create("hello.txt").unwrap_or_else(|error| {
// 创建文件失败,触发 panic!
panic!("Problem creating the file: {:?}", error);
})
} else {
// 其他错误类型(如权限不足),触发 panic!
panic!("Problem opening the file: {:?}", error);
}
});
// 此时 greeting_file 是已成功打开或创建的文件句柄
}
// 注释说明(基于两张图片内容):
// 1. 本代码行为与示例9-5完全一致,但避免了嵌套的 match 表达式
// 2. 使用了闭包(匿名函数)和 `unwrap_or_else` 方法
// 3. 第13章将深入讲解闭包,届时可回顾此示例
// 4. 处理错误时,`Result<T, E>` 提供了许多类似方法(如 `unwrap_or_else`),可简化嵌套的 match失败时触发panic的快捷方式:unwrap和expect
// src/main.rs
// 1. 通过 `unwrap` 实现示例 9-4 中 `match` 表达式的等效功能
// 行为:成功时返回 `Ok` 内部的值,失败时调用 `panic!`
use std::fs::File;
fn main() {
// 如果文件打开成功,`greeting_file` 将被赋值为文件句柄。
// 如果失败(例如文件不存在),程序将 panic 并输出类似如下默认信息:
// thread 'main' panicked at 'called `Result::unwrap()` on an Err value: Os { code: 2, kind: NotFound, ... }', src/main.rs:4:49
let greeting_file = File::open("hello.txt").unwrap();
}
// 2. 使用 `expect` 方法自定义 panic 错误信息
// 功能与 `unwrap` 一致,但允许在失败时提供更具说明性的错误提示,便于追踪错误来源。
fn main_with_expect() {
use std::fs::File;
// 如果 `hello.txt` 不存在,将触发 panic 并打印自定义消息,后跟系统错误详情:
// thread 'main' panicked at 'hello.txt should be included in this project: Os { code: 2, ... }', src/main.rs:8:49
// 自定义消息清晰地说明了操作失败的原因,有助于调试。
let greeting_file = File::open("hello.txt")
.expect("hello.txt should be included in this project");
// 在生产环境中,经验丰富的 Rust 开发者更倾向于使用 `expect` 而非 `unwrap`,
// 因为它能为“操作本应成功”的假设提供更丰富的上下文信息,便于定位问题。
}3. 传播错误
①介绍
// src/main.rs
// 示例9-6:一个从文件中读取用户名的函数。当文件不存在或无法读取时,将错误传播(返回)给调用者处理。
// 这种模式给予调用者更多控制权,由其根据上下文决定如何处理错误(如重试、使用默认值或报告给用户)。
use std::fs::File;
use std::io::{self, Read};
// ① 函数返回 Result<String, io::Error>。成功时返回包含用户名的 Ok(String),失败时返回包含错误的 Err(io::Error)。
fn read_username_from_file() -> Result<String, io::Error> {
// ② 尝试打开文件 "hello.txt",可能成功返回文件句柄,也可能失败返回错误。
let username_file_result = File::open("hello.txt");
// ③ 使用 match 表达式处理 File::open 的 Result。
let mut username_file = match username_file_result {
// ④ 成功:将文件句柄赋值给变量 username_file,继续执行。
Ok(file) => file,
// ⑤ 失败:提前返回错误。`return` 将错误值 e 包装在 Err 中返回给调用者。
Err(e) => return Err(e),
};
// ⑥ 创建一个新的空 String,用于存储从文件中读取的用户名。
let mut username = String::new();
// ⑦ 尝试从文件句柄中读取所有内容到字符串 username。该方法也可能失败。
// ⑧ 成功:返回包含用户名的 Ok(username)。
// ⑨ 失败:返回包含错误的 Err(e)。作为函数的最后一个表达式,无需显式写 `return`。
match username_file.read_to_string(&mut username) {
Ok(_) => Ok(username),
Err(e) => Err(e),
}
}
// 注:在 Rust 中,传播错误是常见模式,因此专门提供了 `?` 运算符来简化此语法,后续会介绍。②传播错误快捷方式:?运算符
// src/main.rs
// 示例 9-7: 使用 `?` 运算符简化错误传播
// 功能:与示例 9-6 相同,但通过 `?` 运算符自动处理 `Result` 值的成功/失败情况。
// 核心:`?` 是 Rust 提供的语法糖,用于在函数返回 `Result` 时简化错误传播。
use std::fs::File;
use std::io::{self, Read};
fn read_username_from_file() -> Result<String, io::Error> {
// 尝试打开文件,若成功则将文件句柄赋值给 username_file,若失败则自动返回错误。
let mut username_file = File::open("hello.txt")?;
let mut username = String::new();
// 尝试读取文件内容到字符串,若成功则继续,若失败则自动返回错误。
username_file.read_to_string(&mut username)?;
// 如果所有操作都成功,返回包含用户名的 `Ok` 值。
Ok(username)
}// src/main.rs
// 示例 9-8: 通过链式方法调用进一步简化代码
// 功能:在示例 9-7 的基础上,将 `read_to_string` 直接链接到 `File::open` 的结果上调用。
// 注意:依然保留了 `?` 运算符,确保任一环节出错都能自动传播错误。
use std::fs::File;
use std::io::{self, Read};
fn read_username_from_file() -> Result<String, io::Error> {
let mut username = String::new();
// 链式调用:打开文件并直接读取内容到字符串,任何一步出错都会自动返回错误。
File::open("hello.txt")?.read_to_string(&mut username)?;
// 成功时返回包含用户名的 `Ok` 值。
Ok(username)
}// src/main.rs
// 示例 9-9: 使用 `fs::read_to_string` 进一步简化文件读取操作
// 功能:直接调用标准库提供的便捷函数,打开文件、创建 `String` 并读取内容,然后返回。
// 注意:此方法最简洁,但之前示例展示了逐步的错误处理机制。
use std::fs;
use std::io;
fn read_username_from_file() -> Result<String, io::Error> {
// 一行代码完成打开文件、读取内容并返回字符串。若出错,错误会自动传播。
fs::read_to_string("hello.txt")
}// 关于 `?` 运算符的补充说明(基于图片 2 和 3 的文本内容):
// 1. `?` 运算符与 `match` 表达式的核心区别在于,`?` 会自动调用 `from` 函数进行错误类型转换。
// 2. `from` 函数定义在 `std::convert::From` trait 中,用于在不同错误类型间转换。
// 3. 当函数返回统一的错误类型,但内部操作可能产生多种错误时,此机制非常有用。
// 4. 例如,若自定义错误类型 `OurError` 实现了 `From<io::Error>`,则 `?` 可自动将 `io::Error` 转换为 `OurError`。
// 5. 在示例 9-7 和 9-8 中,`?` 在 `File::open` 和 `read_to_string` 后使用,成功时提取值,失败时提前返回错误。
// 6. 通过链式调用(示例 9-8)和 `fs::read_to_string`(示例 9-9),代码可进一步简化,更符合人体工程学。
// 7. 但为了充分展示错误处理机制,之前的示例采用了逐步处理的方式。
// 使用 `?` 运算符的注意事项总结:
// 1. `?` 只能用于返回 `Result`、`Option` 或实现了 `std::ops::Try` 的类型(如 `std::task::Poll`)的函数。
// 2. 在 `main` 函数中,如果希望使用 `?`,需要将返回类型改为 `Result`,或者通过其他方式(如 `match`)处理错误。
// 3. 错误传播是 Rust 中常见的错误处理模式,`?` 运算符使其变得简洁而安全。③?运算符可以被用于哪些情形
// src/main.rs
// 示例 9-10: 尝试在返回 `()` 类型的 `main` 函数中使用 `?` 将无法通过编译
// 核心规则: 只有当函数的返回类型与 `?` 运算符作用的值相兼容时,才可以使用 `?` 运算符。
// 这是因为 `?` 用于从函数中提前返回值,其功能类似于示例 9-6 中的 `match` 表达式。
// 该 `match` 表达式处理 `Result` 值,并在提前返回分支中返回 `Err(e)`。为了与此兼容,函数的返回类型必须是 `Result`。
// 下面的代码会引发编译错误,因为 `main` 函数的返回类型是 `()`,与 `File::open` 返回的 `Result` 不兼容。
use std::fs::File;
fn main() { // 返回类型为 `()`
let greeting_file = File::open("hello.txt")?; // 错误:无法在返回 `()` 的函数中使用 `?`
}
// 编译错误信息(精简自第2张图):
// error[E0277]: the `?` operator can only be used in a function that returns `Result` or `Option`
// 帮助信息: 此函数应返回 `Result` 或 `Option` 以接受 `?`
// 为了修正错误,有两种选择:
// 1. 如果函数签名无其他限制,更改其返回类型,使其与 `?` 作用的值相兼容。
// 2. 使用 `match` 或 `Result<T, E>` 的方法手动处理错误。
// 示例 9-11: 在 `Option<T>` 值后使用 `?` 运算符
// 与在 `Result<T, E>` 上使用 `?` 类似,你只能在一个返回 `Option` 的函数中对 `Option` 值使用 `?`。
// 当值是 `None` 时,`None` 会被作为函数的结果提前返回;当值是 `Some` 时,`Some` 中持有的值则会被用作当前表达式的结果,并继续执行后续代码。
// 此函数查找给定文本中第一行的最后一个字符。由于给定的文本中可能含有,也可能不含有对应的字符,所以返回 `Option<char>`。
fn last_char_of_first_line(text: &str) -> Option<char> {
// 获取字符串行的迭代器,取第一行。若文本为空,`next` 返回 `None`,`?` 使函数返回 `None`。
// 否则,`next` 返回一个包含第一行字符串切片的 `Some` 值,`?` 提取出这个切片。
// 接着获取该行字符的迭代器,并取最后一个字符。`last` 也返回 `Option`。
// 如果第一行存在最后一个字符,它将以 `Some` 变体的形式返回。
// `?` 运算符简化了在一行内表达整个逻辑的方式。
text.lines().next()?.chars().last()
}
// 核心补充(基于第5张图):
// 1. 你可以在一个返回 `Result` 的函数中为 `Result` 值使用 `?`,也可以在一个返回 `Option` 的函数中为 `Option` 值使用 `?`,但不能混合使用。
// 2. `?` 不会自动在 `Result` 和 `Option` 之间转换。可以使用 `Result::ok` 或 `Option::ok_or` 等方法显式转换。
// 示例 9-12: 将 `main` 函数的返回类型修改为 `Result<(), Box<dyn Error>>`,使 `?` 运算符可以被用在 `Result` 值上
// `main` 函数可以返回一个 `Result<T, E>`。这里将返回类型修改为 `Result<(), Box<dyn Error>>`,并在结尾返回 `Ok(())`。
// `Box<dyn Error>` 是一个 trait 对象,可理解为“任何可能的错误类型”。
// 它允许任意的 `Err` 值提前返回,因此可以在 `Result` 值后使用 `?`。
// 尽管此 `main` 函数只会返回 `std::io::Error` 这一种错误,但通过 `Box<dyn Error>`,可以合法地在 `main` 中返回其他错误类型。
use std::error::Error;
fn main() -> Result<(), Box<dyn Error>> {
let greeting_file = File::open("hello.txt")?; // 现在可以使用 `?`,因为 `main` 返回 `Result`
Ok(()) // 返回 `Ok(())` 表示成功执行
}
// 关于 `main` 函数返回 `Result` 的补充说明(基于第7张图):
// 1. 当 `main` 函数返回类型是 `Result<(), E>` 时,可执行文件在 `main` 返回 `Ok(())` 时以 0 值退出,在返回 `Err` 值时以非 0 值退出。
// 2. 这与 C 语言可执行文件的退出惯例(成功返回 0,错误返回非 0 整数)兼容。
// 3. `main` 函数可以返回任何实现了 `std::process::Termination` trait 的类型,该 trait 包含一个指定退出码的 `report` 函数。4. 要不要使用panic!
在 Rust 中,
panic!与返回Result的选择取决于错误的性质。panic!会导致程序不可恢复地终止,适用于开发者确信错误无法恢复、程序不应继续运行的场景,此时由你代替调用者做出“不可恢复”的决定。而返回Result枚举则将错误处理的主动权交给调用者,使其能够根据实际情况决定是尝试恢复,还是将其视为不可恢复的错误(例如,调用者可以选择通过unwrap或expect触发panic!)。因此,在定义可能失败的功能时,通常优先推荐返回Result,这提供了最大的灵活性。不过,在某些特定场景下,直接触发
panic是更合适的选择。例如,在编写示例代码、原型代码或测试时,使用panic!通常比处理Result更加简便。此外,还存在一些开发者能确信操作不会失败,但编译器无法静态推断的情形。最后,在编写库代码时,也应遵循一些通用的指导原则来决定是否使用panic!。
①示例、原型代码和测试
在编写示例代码时,为追求简洁和可读性,可使用
unwrap或expect等方法作为错误处理的占位符,读者可理解此处需根据实际上下文进行完善。在快速构建原型时,使用这些方法同样方便,它们能作为明确的记号,便于后续增强程序健壮性时进行有针对性的错误处理。
在测试代码中,若任何方法调用失败(即使非被测功能本身),也意味着测试未通过。由于测试通过
panic来标记失败,因此在此场景下调用unwrap或expect是恰当的做法。
②当你比编译器有更多信息时
在某些情况下,尽管
parse这类方法总会返回Result类型,但开发者基于具体逻辑(例如处理一个已知有效的硬编码字符串)能够确保结果一定是Ok值。此时,使用unwrap或通过expect提供解释是合理的做法,这相当于向编译器表明错误在此场景下不可能发生。以解析硬编码 IP 地址
"127.0.0.1"为例,虽然可以确定它是合法的,但方法签名并未改变。通过expect添加的说明性文本,在代码未来演进(如改为处理用户输入)时,能有效地提示此处需要增强错误处理。
③错误处理指导原则
在 Rust 中,选择使用
panic!还是返回Result取决于错误的性质:使用
panic!的情形:当代码处于“损坏状态”时,即程序运行的基本假设、保证或约定被打破,例如:传入非法、矛盾或不存在的值,且该状态不可预期、不可编码到类型系统中,后续代码的运行依赖于此状态不会发生。
继续运行可能导致不安全、有害的后果(如安全漏洞),例如访问越界内存。
函数或代码块的约定被违反,这通常意味着调用方存在 bug,且调用方难以进行合理的恢复。
-
返回
Result的情形:当失败是可预期和可恢复的业务逻辑一部分时,应返回Result枚举,将错误处理的选择权交给调用者。例如解析格式错误的数据、处理HTTP请求的限流状态等。-
利用类型系统预防错误:通过使用合适的类型(如用特定类型而非
Option确保值非空,用u32确保值非负),可以在编译期由编译器强制执行约束,从而避免许多运行时的错误检查,使代码更简洁、安全。在任何情况下,函数若可能触发panic,都应在 API 文档中明确约定。
④创建自定义类型验证有效性
// src/main.rs
// 本示例展示如何通过定义自定义类型 `Guess` 来封装值验证逻辑,确保其值始终在有效范围内(1-100)。
// 核心思想:利用 Rust 的类型系统,在创建实例时强制执行有效性检查,从而避免后续重复验证。
/// 表示一个在 1 到 100 之间的猜测值。
/// 该结构体封装了验证逻辑,确保其内部值始终有效。
/// 字段 `value` 是私有的,外部代码必须通过提供的公共 API 创建和访问实例。
pub struct Guess {
value: i32, // 私有字段,存储实际的猜测值
}
impl Guess {
/// 创建一个新的 `Guess` 实例。
/// 参数 `value`:一个 i32 类型的整数。
/// 返回值:如果 `value` 在 1 到 100 之间(包含),返回包含该值的 `Guess` 实例。
/// 如果值不在有效范围内,此函数会触发 panic,表示调用者传入了一个无效的值(即程序存在 bug)。
/// 注意:在公共 API 文档中应明确说明触发 panic 的条件。
///
/// 示例:
/// ```
/// let guess = Guess::new(50); // 成功创建
/// ```
pub fn new(value: i32) -> Guess {
// 验证输入值是否在有效范围内
if value < 1 || value > 100 {
panic!(
"猜测值必须在 1 到 100 之间,传入的值为 {}。",
value
);
}
// 验证通过,创建并返回 Guess 实例
Guess { value }
}
/// 获取猜测值的只读引用(getter 方法)。
/// 由于 `value` 字段是私有的,外部代码需要通过此公共方法来访问内部值。
/// 这确保了外部代码无法直接修改 `value`,从而维持了该类型的不变性保证。
/// 返回值:内部存储的猜测值(i32)。
pub fn value(&self) -> i32 {
self.value
}
}
// 示例用法:在需要 1-100 之间整数的函数签名中,可直接使用 `Guess` 类型,无需额外验证。
// 这提高了代码的清晰度和安全性,因为类型系统保证了值的有效性。十二. 泛型
在 Rust 中,泛型允许在定义函数、结构体、枚举和方法时使用抽象的类型占位符,从而创建可灵活搭配不同具体类型使用的代码。本节将首先介绍如何在这些元素中应用泛型,随后讨论其对代码运行性能的影响。
1. 在函数定义中
// src/main.rs
// 示例 10-4: 定义两个仅在名称和签名类型上有所区别的函数
// 1. largest_i32 函数:从 i32 切片中找出最大值
fn largest_i32(list: &[i32]) -> &i32 {
let mut largest = &list[0]; // 假设第一个元素为当前最大值
for item in list { // 遍历切片中的每个元素
if item > largest { // 比较当前元素与当前最大值
largest = item; // 若当前元素更大,则更新最大值
}
}
largest // 返回最大值的引用
}
// 2. largest_char 函数:从 char 切片中找出最大值
// 与 largest_i32 函数逻辑完全相同,仅类型从 i32 变为 char
fn largest_char(list: &[char]) -> &char {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
// 测试 largest_i32 函数
let number_list = vec![34, 50, 25, 100, 65];
let result = largest_i32(&number_list);
println!("The largest number is {}", result);
// 测试 largest_char 函数
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest_char(&char_list);
println!("The largest char is {}", result);
}// src/main.rs
// 示例 10-5: 使用泛型参数将两个 largest 函数合并为一个
// 1. 定义泛型函数 largest<T>,用于从切片中找出最大值
// 注意:此版本目前无法通过编译,因为比较操作 `>` 要求类型 T 实现 `std::cmp::PartialOrd` trait
fn largest<T>(list: &[T]) -> &T { // 声明泛型参数 T,用于函数的参数类型和返回值类型
let mut largest = &list[0]; // 假设第一个元素为当前最大值
for item in list { // 遍历切片中的每个元素
if item > largest { // 错误:比较操作 `>` 不能应用于 `&T` 类型
largest = item; // 尝试更新最大值
}
}
largest // 返回最大值的引用
}
// 2. 主函数,测试泛型函数 largest
fn main() {
// 使用 i32 切片调用 largest
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list);
println!("The largest number is {}", result);
// 使用 char 切片调用 largest
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest(&char_list);
println!("The largest char is {}", result);
}// src/main.rs
// 修正后的示例 10-5: 为泛型参数 T 添加 trait bound 以支持比较操作
// 1. 通过为泛型参数 T 添加 `std::cmp::PartialOrd` trait bound,确保类型 T 支持比较操作
// 这允许函数在 T 的所有可比较类型上工作,包括 i32 和 char
fn largest<T: std::cmp::PartialOrd>(list: &[T]) -> &T { // 使用 `T: std::cmp::PartialOrd` 限制 T 为可比较类型
let mut largest = &list[0];
for item in list {
if item > largest { // 现在可以安全地使用 `>` 运算符,因为 T 实现了 `PartialOrd`
largest = item;
}
}
largest
}
// 2. 主函数保持不变,但代码现在可以成功编译
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list);
println!("The largest number is {}", result);
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest(&char_list);
println!("The largest char is {}", result);
}2. 在结构体定义中
// src/main.rs
// 示例 10-6: 定义一个使用单个泛型参数的结构体 `Point<T>`
// 此结构体可以存储任意类型的 x 和 y 坐标值,但要求 x 和 y 必须是相同类型
struct Point<T> { // ① 在结构体名称后声明泛型参数 T
x: T, // ② 字段 x 为 T 类型
y: T, // ③ 字段 y 也为 T 类型
}
// 示例 10-7: 尝试创建 x 和 y 类型不同的 Point 实例(此代码无法通过编译)
// 由于 x 和 y 都使用相同的泛型参数 T,它们必须是相同类型
// 以下代码会被编译器拒绝,因为整数 5 和浮点数 4.0 类型不匹配
// let wont_work = Point { x: 5, y: 4.0 };
// 编译错误:expected integer, found floating-point number
// 示例 10-8: 定义使用两个泛型参数的结构体 `Point<T, U>`
// 此版本允许 x 和 y 为不同类型,分别用泛型参数 T 和 U 表示
struct Point<T, U> { // 使用两个泛型参数
x: T, // x 字段为 T 类型
y: U, // y 字段为 U 类型
}
fn main() {
// 使用示例 10-6 的定义创建两个 Point 实例
let integer_point = Point { x: 5, y: 10 }; // Point<i32>
let float_point = Point { x: 1.0, y: 4.0 }; // Point<f64>
// 使用示例 10-8 的定义创建三个合法的 Point 实例
let both_integer = Point { x: 5, y: 10 }; // Point<i32, i32>
let both_float = Point { x: 1.0, y: 4.0 }; // Point<f64, f64>
let integer_and_float = Point { x: 5, y: 4.0 }; // Point<i32, f64>,这是合法的
// 注意:过多的泛型参数会使代码难以阅读
// 当需要在代码中使用很多泛型时,应考虑将代码重构为更小的片段
}3. 在枚举定义中
// 类似于结构体,枚举定义也可以在它们的变体中存放泛型数据。
// 标准库中的 `Option<T>` 枚举,用于表示一个值可能存在的抽象概念。
// 它是一个拥有一个泛型参数 `T` 的枚举,包含两个变体:
// 1. `Some(T)`:持有一个 `T` 类型的值,表示值存在。
// 2. `None`:不持有任何值,表示值不存在。
// 由于使用了泛型,无论这个可能存在的值是什么类型,都可以用 `Option<T>` 来表达这种抽象。
enum Option<T> {
Some(T), // 值存在
None, // 值不存在
}
// 枚举同样可以使用多个泛型参数。
// 标准库中的 `Result<T, E>` 枚举,用于表示操作可能成功或失败的场景。
// 它有两个泛型参数:`T` 和 `E`,以及两个变体:
// 1. `Ok(T)`:持有一个 `T` 类型的值,表示操作成功。
// 2. `Err(E)`:持有一个 `E` 类型的值,表示操作失败(包含错误信息)。
// 这使得 `Result<T, E>` 可以很方便地用于可能成功(返回某个 `T` 类型的值),也可能失败(返回某个 `E` 类型的错误)的场景。
// 例如,打开文件时,`T` 被替换为 `std::fs::File` 类型(文件句柄),`E` 被替换为 `std::io::Error` 类型(错误信息)。
enum Result<T, E> {
Ok(T), // 操作成功,返回 T 类型的值
Err(E), // 操作失败,返回 E 类型的错误
}4. 在方法定义中
// 定义泛型结构体 `Point<T>`,包含两个相同类型的字段 x 和 y。
struct Point<T> {
x: T,
y: T,
}
// 示例 10-9:为泛型结构体 `Point<T>` 实现方法 `x`,返回字段 x 的引用。
// 注意:`impl<T>` 声明泛型参数 `T`,表明此实现块适用于所有具体的 `T` 类型。
impl<T> Point<T> {
fn x(&self) -> &T {
&self.x
}
}
// 示例 10-10:仅为具体类型 `Point<f32>` 实现方法 `distance_from_origin`。
// 此实现块不声明泛型参数,因为它只针对 `f32` 类型。
impl Point<f32> {
fn distance_from_origin(&self) -> f32 {
(self.x.powi(2) + self.y.powi(2)).sqrt()
}
}
// 定义另一个泛型结构体 `Point<X1, Y1>`,允许 x 和 y 字段为不同类型。
struct Point2<X1, Y1> {
x: X1,
y: Y1,
}
// 示例 10-11:为 `Point2<X1, Y1>` 实现方法 `mixup`,该方法使用额外的泛型参数 `X2, Y2`。
// 结构体的泛型参数 `X1, Y1` 在 `impl` 后声明,因为它们属于结构体定义的一部分。
// 方法的泛型参数 `X2, Y2` 在方法签名中声明,因为它们仅与此方法相关。
impl<X1, Y1> Point2<X1, Y1> {
fn mixup<X2, Y2>(self, other: Point2<X2, Y2>) -> Point2<X1, Y2> {
Point2 {
x: self.x, // 新实例的 x 来自调用者自身(类型为 X1)
y: other.y, // 新实例的 y 来自传入的另一个 Point2(类型为 Y2)
}
}
}
fn main() {
// 示例 10-9 的演示
let p = Point { x: 5, y: 10 };
println!("p.x = {}", p.x());
// 示例 10-10 的演示
let p_float = Point { x: 3.0, y: 4.0 };
println!("Distance from origin: {}", p_float.distance_from_origin());
// 示例 10-11 的演示
let p1 = Point2 { x: 5, y: 10.4 }; // Point2<i32, f64>
let p2 = Point2 { x: "Hello", y: 'c' }; // Point2<&str, char>
let p3 = p1.mixup(p2); // 返回 Point2<i32, char>
println!("p3.x = {}, p3.y = {}", p3.x, p3.y);
}5. 泛型代码的性能问题
// 1. 泛型的运行时效率
// Rust 的泛型机制不会引入运行时开销。编译器会在编译时执行“单态化”,
// 将泛型代码转换为针对具体类型的特定代码,从而避免运行时的额外开销。
// 2. 单态化过程说明
// 当编译使用泛型的代码时,编译器会查找所有泛型代码被调用的地方,
// 并基于实际使用的具体类型生成对应的非泛型代码。
// 这个过程与示例 10-5 中创建泛型函数的步骤相反。
// 3. Option<T> 的单态化示例
// 以下代码展示了编译器如何将泛型 Option<T> 转换为具体类型:
// 编译器生成的具体类型定义(针对 i32)
enum Option_i32 {
Some(i32),
None,
}
// 编译器生成的具体类型定义(针对 f64)
enum Option_f64 {
Some(f64),
None,
}
fn main() {
// 使用具体类型 Option_i32
let integer = Option_i32::Some(5);
// 使用具体类型 Option_f64
let float = Option_f64::Some(5.0);
// 编译后,原始的泛型 Option<T> 被替换为上述具体类型定义。
// 因此,使用泛型的代码在运行时与手动为每种类型编写特定代码的效率完全相同。
// 单态化使得 Rust 的泛型在运行时极其高效。
}十三. trait
Trait 是 Rust 中用于定义类型可共享行为的抽象。它允许你以抽象方式描述一组功能,并能通过 Trait 约束 来要求泛型参数必须实现某些特定行为,从而编写出灵活的泛型代码。
需要注意的是,Trait 在概念上与其他编程语言中的“接口”(interface)类似,但两者并不完全等同。
1. 定义trait
Trait 定义了一个类型的行为,具体表现为其可供调用的方法集合。当不同类型能够调用相同的方法时,意味着它们共享了相同的行为。Trait 的作用正是将这些共享的方法签名组合起来,形成一个为实现特定目标所必需的行为规范。
// src/lib.rs
// 示例 10-12: 定义一个表示摘要行为的公共 trait
// 本 trait 用于为不同类型(如 NewsArticle 或 Tweet)提供统一的摘要生成接口。
/// Summary trait 定义了生成摘要所需的方法。
/// 任何实现了此 trait 的类型都必须提供 `summarize` 方法的具体实现。
pub trait Summary {
/// 生成并返回该实例的摘要字符串。
/// 这是一个 trait 方法签名,具体实现由实现它的类型提供。
fn summarize(&self) -> String;
}
/// 新闻文章结构体,用于存储某地的新闻故事。
/// 包含标题、地点、作者和内容等文本字段。
struct NewsArticle {
title: String, // 新闻标题
location: String, // 新闻发生地点
author: String, // 新闻作者
content: String, // 新闻正文内容
}
/// 为 NewsArticle 实现 Summary trait,使其能够生成新闻摘要。
impl Summary for NewsArticle {
/// 生成新闻文章的摘要,格式为:`{标题},由{作者}发布于{地点}`
fn summarize(&self) -> String {
format!("{},由{}发布于{}", self.title, self.author, self.location)
}
}
/// 推文结构体,用于存储 Twitter 风格的短消息。
/// 包含内容和元数据(推文类型)。
struct Tweet {
content: String, // 推文内容,最多280个字符
tweet_type: TweetType, // 推文类型:新推文、转发或回复
}
/// 推文类型枚举,描述推文的分类。
enum TweetType {
New, // 新推文
Retweet, // 转发
Reply, // 回复
}
/// 为 Tweet 实现 Summary trait,使其能够生成推文摘要。
impl Summary for Tweet {
/// 生成推文的摘要,根据推文类型添加相应前缀。
fn summarize(&self) -> String {
let prefix = match self.tweet_type {
TweetType::New => "新推文",
TweetType::Retweet => "转发",
TweetType::Reply => "回复",
};
format!("{}: {}", prefix, self.content)
}
}
/*
* 使用示例(在 main 函数中):
*
* let article = NewsArticle {
* title: String::from("重大新闻"),
* location: String::from("北京"),
* author: String::from("记者张三"),
* content: String::from("新闻内容..."),
* };
* println!("{}", article.summarize()); // 输出: 重大新闻,由记者张三发布于北京
*
* let tweet = Tweet {
* content: String::from("今天天气真好!"),
* tweet_type: TweetType::New,
* };
* println!("{}", tweet.summarize()); // 输出: 新推文: 今天天气真好!
*
* 设计优势:
* 1. 通过 Summary trait 为不同类型提供了统一的行为接口。
* 2. 不同类型的 summarize 实现可以不同,但调用方式一致。
* 3. 便于后续扩展,可以轻松为其他类型实现 Summary trait。
*/2. 为类型实现trait
// src/lib.rs
// 示例 10-12: 定义一个公共的 Summary trait,用于抽象“生成摘要”这一行为。
// trait 定义了一组方法签名,实现了该 trait 的类型必须提供这些方法的具体实现。
pub trait Summary {
fn summarize(&self) -> String; // 核心方法,用于生成摘要字符串
}
// 定义 NewsArticle 结构体
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
// 示例 10-13: 为 NewsArticle 类型实现 Summary trait
// 在 `impl` 块中,指定 trait 名 (`Summary`) 和为之实现的类型 (`for NewsArticle`)。
// 然后在块内提供 trait 中声明的所有方法的具体实现。
impl Summary for NewsArticle {
// 为 NewsArticle 提供 summarize 方法的具体实现,生成包含标题、作者、地点的摘要。
fn summarize(&self) -> String {
format!("{},由{}发布于{}", self.headline, self.author, self.location)
}
}
// 定义 Tweet 结构体
pub struct Tweet {
pub username: String,
pub content: String,
pub reply: bool,
pub retweet: bool,
}
// 示例 10-13 (续): 为 Tweet 类型实现 Summary trait
// 不同类-型可以实现同一 trait 的不同行为。Tweet 的摘要包含用户名和内容。
impl Summary for Tweet {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
// 使用说明:
// 1. 为类型实现 trait 的语法:`impl Trait名 for 类型名 { ... }`。
// 2. 库的用户需将 trait 引入作用域(`use aggregator::Summary;`),才能在其实例上调用 trait 方法。
// 3. 示例调用代码 (通常位于 main.rs 或另一个二进制单元包中):
// use aggregator::{Summary, Tweet};
// let tweet = Tweet { ... };
// println!("1 new tweet: {}", tweet.summarize());
// 重要规则(孤儿规则):
// 只有当 trait 或目标类型**至少有一个**定义在当前单元包中时,才能为该类型实现此 trait。
// 例如:
// - 可以在本库 (aggregator) 中为外部的 `Vec<T>` 实现本地的 `Summary` trait (trait 本地)。
// - 可以在本库中为本地类型 `Tweet` 实现外部的 `Display` trait (类型本地)。
// - 但不能为外部的 `Vec<T>` 实现外部的 `Display` trait (两者都外部)。
// 此规则保证了代码的一致性,防止两个库为同一类型实现同一 trait 时发生冲突。3. 默认实现
// src/lib.rs
// 示例 10-14: 为 Summary trait 中的 summarize 方法提供一个默认实现
// 默认实现可避免为每个实现类型都提供相同的行为,但允许类型在需要时重载。
pub trait Summary {
fn summarize(&self) -> String {
String::from("(Read more...)") // 默认返回固定的字符串
}
}
// 示例 10-13 续: 为 NewsArticle 实现 Summary trait,但使用默认的 summarize 方法
// 通过指定空的 impl 块,表示不重写 summarize 方法,而使用 trait 中定义的默认实现。
impl Summary for NewsArticle {} // 空的 impl 块,自动继承默认的 summarize 方法
// 示例 10-13 续: 为 Tweet 实现 Summary trait,自定义 summarize 方法
// 此处的实现会重载默认的 summarize 方法,使用自定义的逻辑生成摘要。
impl Summary for Tweet {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
// 示例: 在默认实现中调用 trait 内的其他方法
// 在 trait 内部,可以在默认实现的方法中调用另一个没有默认实现的方法。
pub trait Summary {
fn summarize_author(&self) -> String; // 无默认实现,必须由实现类型提供
fn summarize(&self) -> String { // 默认实现
format!("(Read more from {}...)", self.summarize_author())
}
}
// 为 Tweet 实现这个版本的 Summary trait
// 只需实现 summarize_author 方法,即可获得默认的 summarize 行为。
impl Summary for Tweet {
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}
// 示例: 在 NewsArticle 的实例上调用 summarize 方法
// 由于使用默认实现,将输出 "(Read more...)"。
let article = NewsArticle {
headline: String::from("Penguins win the Stanley Cup Championship!"),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best hockey team in the NHL.",
),
};
println!("New article available! {}", article.summarize());
// 示例: 在 Tweet 的实例上调用 summarize 方法
// 由于重载了 summarize 方法,将输出自定义的摘要。
let tweet = Tweet {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
retweet: false,
};
println!("1 new tweet: {}", tweet.summarize());
// 重要说明: 在重载方法实现的过程中,无法调用该方法的默认实现。
// 即,如果为某个类型重写了 summarize 方法,则不能在其内部调用 trait 中定义的默认 summarize 实现。4. 使用trait作为参数
①介绍
// src/lib.rs
// 示例 10-15: 使用 impl Trait 语法定义函数参数,以接收任何实现了指定 trait 的类型
// 核心:impl Trait 语法用于定义接收实现了特定 trait 的任意类型的函数参数
// 注意:这是 trait bound 的语法糖,适用于简单场景
// 定义 Summary trait
pub trait Summary {
fn summarize(&self) -> String;
}
// 定义 NewsArticle 结构体
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
// 为 NewsArticle 实现 Summary trait
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{},由{}发布于{}", self.headline, self.author, self.location)
}
}
// 定义 Tweet 结构体
pub struct Tweet {
pub username: String,
pub content: String,
pub reply: bool,
pub retweet: bool,
}
// 为 Tweet 实现 Summary trait
impl Summary for Tweet {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
// 1. 定义 notify 函数,使用 impl Trait 语法指定 item 参数类型
// 参数 item 可以是任何实现了 Summary trait 的类型
// 在函数体内,可以调用来自 Summary trait 的任何方法
pub fn notify(item: &impl Summary) {
// 调用 item 的 summarize 方法
println!("Breaking news! {}", item.summarize());
}
// 2. 函数调用说明
// 可以在调用 notify 时传入任意实现了 Summary 的实例(如 NewsArticle 或 Tweet)
// 尝试使用其他未实现 Summary 的类型(如 String 或 i32)将导致编译错误
// 因为这些类型没有实现 Summary trait
// 示例:在 main 函数中调用 notify
fn main() {
// 创建 NewsArticle 实例
let article = NewsArticle {
headline: String::from("重大新闻"),
location: String::from("北京"),
author: String::from("记者张三"),
content: String::from("新闻内容..."),
};
// 创建 Tweet 实例
let tweet = Tweet {
username: String::from("user123"),
content: String::from("今天天气真好!"),
reply: false,
retweet: false,
};
// 成功调用,因为 NewsArticle 和 Tweet 都实现了 Summary
notify(&article);
notify(&tweet);
// 以下代码将无法编译,因为 String 没有实现 Summary
// let s = String::from("hello");
// notify(&s); // 编译错误:`String` 没有实现 `Summary`
}②trait约束
// src/lib.rs
// 本文件演示 `impl Trait` 语法与完整 trait 约束语法的对比,以及如何控制函数参数的类型一致性。
// 定义 Summary trait
pub trait Summary {
fn summarize(&self) -> String;
}
// 示例 1: 单参数函数的两种等价写法
// 1.1 使用 `impl Trait` 语法(简洁形式)
// 参数 `item` 可以是任何实现了 `Summary` trait 的类型
pub fn notify_impl(item: &impl Summary) {
println!("Breaking news! {}", item.summarize());
}
// 1.2 使用完整的 trait 约束语法(泛型形式)
// 泛型参数 `T` 被约束为实现 `Summary` trait 的类型
pub fn notify_generic<T: Summary>(item: &T) {
println!("Breaking news! {}", item.summarize());
}
// 两种写法完全等价,`impl Trait` 是 trait 约束的语法糖,在简单场景中更简洁。
// 示例 2: 两个参数函数的不同类型要求
// 2.1 允许两个参数为不同类型(但都必须实现 `Summary`)
// 使用 `impl Trait` 语法,`item1` 和 `item2` 可以是不同的具体类型
pub fn notify_different_types(item1: &impl Summary, item2: &impl Summary) {
println!("Item 1: {}, Item 2: {}", item1.summarize(), item2.summarize());
}
// 2.2 强制两个参数为相同类型(且必须实现 `Summary`)
// 使用 trait 约束,泛型 `T` 同时用于 `item1` 和 `item2`,确保它们类型相同
pub fn notify_same_type<T: Summary>(item1: &T, item2: &T) {
println!("Item 1: {}, Item 2: {}", item1.summarize(), item2.summarize());
}
// 核心区别:`notify_different_types` 允许两个参数分别是不同的实现了 `Summary` 的类型,
// 而 `notify_same_type` 要求两个参数必须是完全相同的类型。
// 使用场景总结:
// 1. 当参数类型灵活性更重要时,使用 `impl Trait` 语法。
// 2. 当需要强制多个参数类型一致时,必须使用完整的 trait 约束语法。③通过+语法来指定多个trait约束
// src/lib.rs
// 本示例演示如何在 Rust 中同时指定多个 trait 约束。
// 核心:使用 `+` 语法,要求类型同时实现多个 trait。
// 引入标准库中的 Display trait,用于格式化输出
use std::fmt::Display;
// 1. 非泛型函数的写法:使用 `impl Trait` 语法,配合 `+` 指定多个 trait
// 参数 `item` 必须同时实现 `Summary` 和 `Display` 两个 trait
pub fn notify_impl_trait(item: &(impl Summary + Display)) {
// 由于实现了 Display,可以使用 `{}` 格式化输出
println!("Item: {}", item);
// 同时可以调用 Summary 的方法
println!("Summary: {}", item.summarize());
}
// 2. 泛型函数的写法:在泛型参数上使用 `+` 指定多个 trait
// 泛型 `T` 必须同时满足 `Summary` 和 `Display` 约束
pub fn notify_generic<T: Summary + Display>(item: &T) {
// 函数体与非泛型版本相同
println!("Item: {}", item);
println!("Summary: {}", item.summarize());
}
// 3. 说明:
// 两种写法功能完全等价,选择取决于具体场景和代码风格。
// 当 trait 约束较多时,使用 where 从句可以提高可读性(后续章节介绍)。④使用where从句简化trait约束
// src/lib.rs
// 本文件演示如何使用 `where` 子句来优化包含多个复杂 trait 约束的泛型函数签名,以提升代码可读性。
// 示例:一个泛型函数,其签名因 trait 约束直接内嵌而显得拥挤、难以阅读。
// 函数 `some_function` 接受两个泛型参数 `T` 和 `U`,它们各自有复杂的 trait 约束。
// 这种写法的问题在于,大量的约束信息夹杂在函数名与参数列表之间,掩盖了函数的核心结构。
fn some_function<T: std::fmt::Display + Clone, U: std::fmt::Debug + Clone>(t: &T, u: &U) -> i32 {
// 函数实现...
0
}
// 使用 `where` 子句重写上述函数,将 trait 约束移到函数签名之后。
// 这种写法使得函数名、参数列表和返回类型的核心结构清晰可见,可读性更强。
fn some_function_cleaned<T, U>(t: &T, u: &U) -> i32
where
T: std::fmt::Display + Clone, // where 子句列出对泛型参数 T 的约束
U: std::fmt::Debug + Clone, // where 子句列出对泛型参数 U 的约束
{
// 函数实现...
0
}
// 核心总结:
// 1. 当泛型函数拥有多个参数且 trait 约束复杂时,直接在尖括号 <> 内声明会降低可读性。
// 2. `where` 子句允许将这些约束后置,使函数签名的主体部分(名称、参数、返回类型)保持紧凑、清晰。
// 3. 使用 `where` 子句是 Rust 社区的常见风格,尤其在约束较多时,它能显著改善代码结构。5. 返回实现trait的类型
// src/lib.rs
// 示例 10-13(修改版):展示在函数返回值中使用 `impl Trait` 语法的功能与限制
// 核心概念:`impl Trait` 可用于函数返回位置,表示返回某个实现了指定 trait 的类型,无需显式写出具体类型。
// 但此语法要求函数在所有执行路径上返回完全相同的具体类型(单一类型)。
// 定义 Summary trait
pub trait Summary {
fn summarize(&self) -> String;
}
// 定义 NewsArticle 结构体
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
// 为 NewsArticle 实现 Summary trait
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{},由{}发布于{}", self.headline, self.author, self.location)
}
}
// 定义 Tweet 结构体
pub struct Tweet {
pub username: String,
pub content: String,
pub reply: bool,
pub retweet: bool,
}
// 为 Tweet 实现 Summary trait
impl Summary for Tweet {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
// 示例 1: 正确用法 - 函数返回单一具体类型(Tweet)
// 该函数返回一个实现了 Summary trait 的类型(此处为 Tweet)。
// 调用者只知道返回类型实现了 Summary,但不知道具体是 Tweet。
pub fn returns_summarizable() -> impl Summary {
// 创建并返回一个 Tweet 实例
Tweet {
username: String::from("horse_ebooks"),
content: String::from("of course, as you probably already know, people"),
reply: false,
retweet: false,
}
}
// 示例 2: 错误用法 - 尝试根据条件返回不同类型(NewsArticle 或 Tweet)
// 此代码无法通过编译,因为 `impl Trait` 要求函数在所有执行路径上返回相同的具体类型。
// 虽然 NewsArticle 和 Tweet 都实现了 Summary,但 Rust 编译器无法确定返回的具体类型是哪一个。
// 要支持这种场景,需使用 trait 对象(将在第 17 章介绍)。
pub fn returns_summarizable_conditional(switch: bool) -> impl Summary {
if switch {
// 尝试返回 NewsArticle
NewsArticle {
headline: String::from("Penguins win the Stanley Cup Championship!"),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best hockey team in the NHL.",
),
}
} else {
// 尝试返回 Tweet
Tweet {
username: String::from("horse_ebooks"),
content: String::from("of course, as you probably already know, people"),
reply: false,
retweet: false,
}
}
}
// 设计意图与价值:
// 1. 隐藏具体类型:调用者只需知道返回类型实现了特定 trait(如 Summary),无需关心具体类型。
// 2. 简化签名:特别适用于闭包和迭代器等返回复杂或匿名类型的场景,避免冗长的类型签名。
// 3. 单一类型约束:当前 `impl Trait` 在返回位置要求所有执行路径返回同一具体类型,这是编译时的保证。6. 使用trait约束有条件的实现方法
// 示例 10-15: 在带有泛型参数的 impl 块中使用 trait 约束,有条件地实现方法
// 核心:通过为满足特定 trait 约束的泛型类型实现方法,实现代码的精准控制。
// 引入 Display trait 用于格式化输出
use std::fmt::Display;
// 定义泛型结构体 Pair<T>,包含两个相同类型的字段
struct Pair<T> {
x: T,
y: T,
}
// 为所有类型 T 实现 Pair<T> 的 new 关联函数
// 此方法无条件提供,用于创建 Pair<T> 实例
impl<T> Pair<T> {
fn new(x: T, y: T) -> Self {
Self { x, y }
}
}
// 仅为同时实现了 Display 和 PartialOrd trait 的类型 T 实现 cmp_display 方法
// Display 用于打印,PartialOrd 用于比较
impl<T: Display + PartialOrd> Pair<T> {
fn cmp_display(&self) {
if self.x >= self.y {
println!("The largest member is x = {}", self.x);
} else {
println!("The largest member is y = {}", self.y);
}
}
}
// 覆盖实现(blanket implementation)(是一种为满足特定 trait 边界(trait bounds)
的所有类型自动实现某个 trait 的机制。它通过泛型实现一次,就能让许多类型获得该 trait 的实现。)示例:
// 标准库对所有满足 Display trait 约束的类型实现了 ToString trait
// 因此,任何实现了 Display 的类型都可以调用 to_string 方法
// 例如,整数 3 实现了 Display,所以可以调用 3.to_string() 得到 String 类型的 "3"
// 代码示例(模拟标准库中的实现):
// impl<T: Display> ToString for T {
// // 实现细节省略
// fn to_string(&self) -> String {
// // 将 self 格式化为字符串
// }
// }
// 设计价值总结:
// 1. 条件性实现:通过 trait 约束,在编译时精确控制方法的实现范围,避免为不合适的类型提供不相关的方法。
// 2. 编译时安全:编译器确保只有满足约束的类型才能调用相应方法,将潜在错误从运行时转移到编译时。
// 3. 性能优势:无需运行时检查,编译时已确定方法的存在性,同时保持了泛型的灵活性。
// 4. 代码重用:通过覆盖实现,可以基于一个 trait 为满足条件的众多类型统一提供功能,减少重复代码。十四. 生命周期
生命周期是 Rust 中一种用于确保引用在使用时始终有效的泛型。每一个引用都有其对应的生命周期,用于描述其保持有效的代码作用域。在大多数简单情况下,生命周期会由编译器自动推断,无需手动标注。然而,当多个引用的生命周期关系较为复杂时,必须通过标注来明确它们之间的关系,以便编译器在编译时就能保证程序运行时不会出现悬垂引用等内存安全问题。尽管生命周期概念在其他编程语言中并不常见,但它是编写安全、高效 Rust 代码的核心知识之一。
1. 使用声明周期避免悬垂引用
①介绍
// src/main.rs
// 示例 10-16: 尝试在值离开作用域时使用指向它的引用
// 生命周期最主要的目标是避免悬垂引用,防止程序引用到非预期数据。
fn main() {
let r; // ① 在外部作用域声明一个未初始化的变量 r
{ // 开始一个新的内部作用域
let x = 5; // ② 在内部作用域中声明并初始化变量 x
r = &x; // ③ 尝试将 r 设置为指向 x 的引用
} // ④ 内部作用域结束,变量 x 在此处离开作用域,其占用的内存被释放
println!("r: {}", r); // ⑤ 尝试打印 r 所指向的值
// 此时 r 指向已被释放的内存,导致悬垂引用
// 这段代码无法通过编译,因为在使用 r 时,它所引用的值 x 已经离开了作用域
}
/*
* 核心分析:
* 1. 变量 x 的生命周期限于内部作用域,在离开作用域时被销毁
* 2. 变量 r 的生命周期覆盖了整个外部作用域
* 3. 当内部作用域结束时,r 仍然试图引用已销毁的 x,导致悬垂引用
*
* 借用检查器(borrow checker)工作原理:
* 1. Rust 编译器会检查所有引用的有效性
* 2. 当发现 r 引用的 x 的生命周期短于 r 本身时,编译器会拒绝编译
* 3. 错误信息示例: error[E0597]: `x` does not live long enough
* 4. 这是因为 r 借用(borrow)了 x,但 x 在 r 结束借用前就被丢弃了
*
* Rust 的设计哲学:
* 1. 通过编译时检查避免运行时悬垂引用错误
* 2. 确保内存安全,防止访问已释放的内存
* 3. 强制开发者在代码编写阶段处理生命周期问题
*/②借用检查器
// src/main.rs
// 示例 10-16 和 10-17: 演示借用检查器如何比较生命周期以检测悬垂引用
// 核心:Rust 的借用检查器会验证引用的生命周期是否短于或等于被引用值的生命周期
// 错误示例:`x` 的生命周期 `'b` 短于引用 `r` 的生命周期 `'a`,导致悬垂引用
fn main() {
{
let r; // 引用 r 的生命周期 'a 从此处开始
{ // 内部代码块开始
let x = 5; // 值 x 的生命周期 'b 从此处开始
r = &x; // 尝试将 r 指向 x,但编译器会拒绝,因为 'b 短于 'a
} // 内部代码块结束,x 的生命周期 'b 到此结束,x 被释放
println!("r: {}", r); // 错误:尝试使用指向已释放内存的引用 r
} // 外部代码块结束,r 的生命周期 'a 到此结束
}
// 示例 10-18: 修正后的代码,确保数据的生命周期长于引用的生命周期
// 核心:被引用的值 x 的生命周期 'b 必须长于引用 r 的生命周期 'a
// 这样,只要引用 r 在使用,x 就始终有效
fn valid_reference() {
let x = 5; // 值 x 的生命周期 'b 开始
let r = &x; // 引用 r 的生命周期 'a 开始,且 'a 是 'b 的子集
println!("r: {}", r); // 正确:此时 x 和 r 都有效
} // 生命周期结束:首先 r 的 'a 结束,然后 x 的 'b 结束
/*
* 生命周期比较总结:
* 1. 借用检查器在编译时比较生命周期,确保引用不会比其引用的值存在更久
* 2. 在示例 10-16 中,'b 短于 'a,r 指向已被释放的内存,编译失败
* 3. 在示例 10-18 中,'b 长于 'a,x 的生命周期覆盖了 r 的生命周期,编译通过
* 4. 接下来,将探讨如何在函数中使用泛型生命周期标注参数和返回值
*/2. 函数中的泛型生命周期
// src/main.rs
// 示例 10-20: 定义 longest 函数,意图返回两个字符串切片中较长的那个
// 但此版本无法通过编译,因为返回值引用缺少生命周期标注,编译器无法确定其有效性
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() {
x
} else {
y
}
}
// src/main.rs (修正后)
// 为 longest 函数添加泛型生命周期参数 'a
// 标注说明:参数 x 和 y 都必须具有至少与 'a 一样长的生命周期,
// 并且返回值也具有同样的生命周期 'a
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}
// 主函数:演示 longest 函数的使用
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}"); // 输出: The longest string is abcd
}3. 生命周期标注语法
// src/main.rs
// 生命周期标注并不改变引用的实际存活时间,而是用于向 Rust 编译器描述多个引用生命周期之间的关系。
// 生命周期参数的命名以撇号(')开头,通常为简短的小写字母(如 'a)。
// 标注置于引用运算符 & 之后,用空格与引用类型分隔。
// 示例:不同类型的引用
&i32; // 普通引用
&'a i32; // 拥有显式生命周期 'a 的引用
&'a mut i32; // 拥有显式生命周期 'a 的可变引用
// 单个生命周期标注本身意义有限,其主要用途是标注多个泛型生命周期参数间的关系。
// 示例 10-20: longest 函数,返回两个字符串切片中较长者
// 通过生命周期标注 'a,指定参数 x 和 y 必须拥有相同的生命周期 'a,
// 且返回值也拥有同样的生命周期 'a,从而确保返回值引用有效
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}
// 主函数:演示 longest 函数的调用
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}4. 函数签名中的生命周期标注
// src/main.rs
// 以下代码示例演示了 Rust 中生命周期标注的用法,特别是如何通过标注多个引用的生命周期来避免悬垂引用。
// 示例 10-21: longest 函数的定义,指定了签名中所有的引用都必须拥有相同的生命周期 'a
// 函数签名向 Rust 表明,函数所获取的两个字符串切片参数的存活时间,必须不短于给定的生命周期 'a
// 这个函数签名同时意味着,从这个函数返回的字符串切片也可以获得不短于 'a 的生命周期
// 在实践中,这意味着 longest 函数返回的引用的生命周期与函数参数引用的值的生命周期中较短的那个相同
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}
// 示例 10-22: 使用具有不同生命周期的 String 来调用 longest 函数
// 当我们将具体的引用传入 longest 时,被用于替代 'a 的具体生命周期就是 x 作用域与 y 作用域重叠的那一部分
// 换句话说,泛型生命周期 'a 会被具体化为 x 与 y 两者中生命周期较短的那一个
// 因为我们将返回的引用也标注为生命周期参数 'a,所以返回的引用在具体化后的生命周期范围内都是有效的
fn main() {
let string1 = String::from("long string is long");
{
let string2 = String::from("xyz");
let result = longest(string1.as_str(), string2.as_str());
println!("The longest string is {result}");
}
}
// 示例 10-23: 尝试在 string2 离开作用域后使用 result
// 这段代码无法通过编译,因为 result 的引用生命周期必须短于两个参数的生命周期
// 错误信息:error[E0597]: `string2` does not live long enough
// 为了使 println! 语句中的 result 是有效的,string2 需要一直保持有效,直到外部作用域结束
// 因为我们在函数参数与返回值中使用了同样的生命周期参数 'a,所以 Rust 才会指出这些问题
fn main_fail() {
let string1 = String::from("long string is long");
let result;
{
let string2 = String::from("xyz");
result = longest(string1.as_str(), string2.as_str());
} // string2 离开作用域
println!("The longest string is {result}"); // 错误:尝试在 string2 离开作用域后使用 result
}
// 核心概念总结:
// 1. 生命周期标注并不改变引用的实际存活时间,而是用于向 Rust 编译器描述多个引用生命周期之间的关系
// 2. 在函数签名中指定生命周期参数,并没有改变任何传入或返回的值的生命周期,只是向借用检查器指出了一些可以用于检查非法调用的约束
// 3. 当我们在函数中标注生命周期时,这些标注会出现在函数签名中,而不是函数体中,这些生命周期标注会成为函数约定的一部分
// 4. 函数签名中包含生命周期约定可以简化 Rust 编译器所需要执行的分析,使得编译器错误可以更精确地指向出现问题的代码
// 5. 即使从逻辑上我们可以确定某个引用是有效的(例如 result 指向 string1),但编译器根据生命周期标注的规则(返回引用的生命周期与传入引用中较短者相同)可能会拒绝编译
// 6. 建议尝试将不同的值、具有不同生命周期的引用传入 longest 函数,并改变返回引用的使用方式,提前对代码能否通过借用检查器的编译做出判断,然后借助编译来验证5. 深入理解生命周期
// src/main.rs
// 1. 示例一:返回第一个参数,无需为第二个参数指定生命周期
// 指定生命周期的方式往往取决于函数的具体功能。
// 如果 longest 函数改为返回第一个字符串切片参数,则无需为参数 y 指定生命周期。
// 此时,参数 y 的生命周期与返回值无关,代码能通过编译。
// 注释:为参数 x 与返回类型指定相同的生命周期参数 'a,
// 但忽略参数 y,因为 y 的生命周期与 x 和返回值的生命周期没有任何关系。
fn longest<'a>(x: &'a str, y: &str) -> &'a str {
x // 返回第一个参数 x
}
// 2. 示例二:尝试返回内部临时值的引用,无法通过编译
// 当函数返回一个引用时,返回类型的生命周期参数必须与至少一个参数的生命周期参数相匹配。
// 如果返回的引用没有指向任何参数,它必然指向一个在函数内部创建的值,
// 而该值在函数结束时离开作用域,导致返回的引用成为悬垂引用。
// 下面的代码无法通过编译,即使为返回类型指定了生命周期参数 'a:
// error[E0515]: cannot return reference to local variable `result`
// 错误原因:返回了对当前函数所拥有的数据的引用,这是不允许的。
fn longest_bad<'a>(x: &str, y: &str) -> &'a str {
let result = String::from("really long string"); // 内部创建的 String
result.as_str() // 错误:尝试返回对局部变量 result 的引用
}
// 3. 根本问题与解决方案
// 这里的问题在于,result 在 longest 函数结束时离开作用域并被清理,
// 但我们依然尝试返回一个指向它的引用,这会产生悬垂引用。
// 无论怎么改变生命周期参数,都无法阻止悬垂引用的产生,Rust 不允许创建悬垂引用。
// 最佳解决办法是返回一个持有自身所有权的数据类型(如 String),而不是引用,
// 这样就将清理值的责任转移给了函数调用者。
// 从根本上说,生命周期语法用于关联函数中不同参数及返回值的生命周期。
// 一旦它们形成关联,Rust 就获得了足够的信息来保障内存安全,
// 阻止可能导致创建悬垂指针或其他违反内存安全的行为。6. 结构体定义中的生命周期标注
// src/main.rs
// 结构体通常持有自有类型,但也可以存储引用,此时必须为结构体定义中的每个引用添加生命周期标注。
// 示例 10-24: 定义 ImportantExcerpt 结构体,存储一个字符串切片引用
// ① 在结构体名称后的尖括号内声明泛型生命周期参数 'a
struct ImportantExcerpt<'a> {//实例存活时间不超过part的存活
// ② 为 part 字段添加生命周期标注,指明其引用数据的生命周期
part: &'a str,
}
fn main() {
// ③ 创建一个 String 实例 novel
let novel = String::from(
"Call me Ishmael. Some years ago..."
);
// ④ 获取 novel 中第一个句子的引用
let first_sentence = novel
.split('.')
.next()
.expect("Could not find a '.'");
// ⑤ 创建 ImportantExcerpt 实例,其 part 字段存储对 novel 中数据的引用
let i = ImportantExcerpt {
part: first_sentence,
};
// 由于 novel 的生命周期长于 ImportantExcerpt 实例 i,
// 且 i 的 part 字段被标注为 'a,与 novel 中数据的生命周期匹配,
// 因此编译器可以确保 i 中的引用始终有效,不会发生悬垂引用。
}7. 生命周期省略
// src/lib.rs
// 本文件演示 Rust 的生命周期省略规则,并展示两个示例函数:first_word 和 longest。
// 通过这两个函数,说明在哪些情况下可以省略生命周期标注,哪些情况必须显式标注。
// 示例 10-25: first_word 函数,用于返回字符串中第一个单词的切片
// 这个函数在没有显式生命周期标注的情况下可以正常编译,因为它符合 Rust 的生命周期省略规则
fn first_word(s: &str) -> &str {
// 将字符串转换为字节序列,以便逐字节检查
let bytes = s.as_bytes();
// 遍历字节序列,同时获取索引和字节值
for (i, &item) in bytes.iter().enumerate() {
// 如果遇到空格字节,返回从开头到当前索引的子切片
if item == b' ' {
return &s[0..i];
}
}
// 如果没有找到空格,返回整个字符串
&s[..]
}
// 示例 10-20: longest 函数,尝试返回两个字符串切片中较长的一个
// 这个函数在初始版本(无生命周期标注)中无法通过编译
// 因为编译器无法推断返回引用的生命周期
fn longest(x: &str, y: &str) -> &str { // 编译错误:缺少生命周期标注
if x.len() > y.len() {
x
} else {
y
}
}
// 修正版本:为 longest 函数添加显式生命周期标注
// 通过生命周期标注 'a,明确参数和返回值的生命周期关系
fn longest_correct<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}
// 生命周期省略规则解释:
// 1. 第一条规则:每个引用参数都有自己的生命周期参数
// 例如:fn foo<'a>(x: &'a i32) 和 fn foo<'a, 'b>(x: &'a i32, y: &'b i32)
// 2. 第二条规则:如果只有一个输入生命周期参数,它会被赋给所有输出生命周期参数
// 例如:fn foo<'a>(x: &'a i32) -> &'a i32
// 3. 第三条规则:如果方法有多个输入生命周期参数,但其中一个是&self或&mut self,
// 那么self的生命周期会被赋给所有输出生命周期参数
// 对 first_word 函数应用生命周期省略规则:
// 1. 应用第一条规则:为参数 s 指定生命周期 'a → fn first_word<'a>(s: &'a str) -> &str
// 2. 应用第二条规则:输入生命周期 'a 被赋给输出生命周期 → fn first_word<'a>(s: &'a str) -> &'a str
// 此时所有引用都有生命周期,编译通过。
// 对 longest 函数应用生命周期省略规则:
// 1. 应用第一条规则:为每个参数指定生命周期 → fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str
// 2. 由于有两个输入生命周期,第二条规则不适用
// 3. 由于不是方法,第三条规则不适用
// 编译器无法确定返回值的生命周期,因此需要显式标注。
// 总结:
// 1. 生命周期省略规则是编译器内部的模式,用于在某些常见场景中自动推断生命周期
// 2. 当规则无法推断时,必须显式标注生命周期
// 3. 随着 Rust 的发展,可能会有更多模式被加入编译器,减少手动标注的需求8. 方法定义中的生命周期标注
// 为拥有生命周期的结构体 `ImportantExcerpt` 实现方法
// 声明生命周期参数 `'a` 的位置在 `impl` 关键字之后,并用于结构体名称之后
// 因为此生命周期是结构体类型的一部分
impl<'a> ImportantExcerpt<'a> {
// 方法 `level`:仅接收一个指向 `self` 的参数,返回 i32 类型
// 返回值不引用任何数据,因此与生命周期无关
// 根据第一条生命周期省略规则,可省略方法中 `self` 引用的生命周期标注
fn level(&self) -> i32 {
3
}
}
impl<'a> ImportantExcerpt<'a> {
// 方法 `announce_and_return_part`:接收 `&self` 和一个字符串切片引用 `announcement`,返回字符串切片
// 应用生命周期省略规则:
// 1. 第一条规则:为 `&self` 和 `announcement` 分别赋予各自的生命周期
// 2. 第三条规则:由于其中一个参数是 `&self`,返回类型被赋予 `&self` 的生命周期
// 因此,编译器可自动计算出所有生命周期,无需手动标注
fn announce_and_return_part(&self, announcement: &str) -> &str {
println!("Attention please: {}", announcement);
self.part//返回的是self所以可以省略
}
}9. 静态生命周期
'static是 Rust 中的一个特殊生命周期,表示被其标记的引用在整个程序的执行期间都有效。所有字符串字面量都隐式地拥有 'static生命周期,因为它们的文本被直接存储在程序的二进制文件中,始终可用。虽然编译器有时会建议使用
'static生命周期来修复错误,但在采纳前必须审慎考虑。你首先需要确认这个引用是否真的需要与程序同寿;更重要的是,大多数此类错误的根源是试图创建悬垂引用或发生了生命周期不匹配。正确的做法是修复这些潜在问题,而不应简单地求助于'static标记。
10. 同时使用泛型参数、trait约束与生命周期
// 导入标准库中的 Display trait,用于格式化输出
use std::fmt::Display;
// 定义函数 `longest_with_an_announcement`,它同时使用生命周期参数、泛型参数和 trait 约束
// 函数签名说明:
// 1. 生命周期参数 'a 和泛型参数 T 都声明在函数名后的尖括号中
// 2. 两个字符串切片参数 x 和 y 共享相同的生命周期 'a
// 3. 泛型参数 ann 的类型 T 必须实现 Display trait,以便用 {} 进行格式化输出
// 4. 返回具有生命周期 'a 的字符串切片,确保返回的引用有效
fn longest_with_an_announcement<'a, T>(
x: &'a str, // 第一个字符串切片,生命周期为 'a
y: &'a str, // 第二个字符串切片,同样具有生命周期 'a
ann: T, // 泛型参数 ann,类型为 T,需实现 Display trait
) -> &'a str // 返回具有相同生命周期 'a 的字符串切片
where
T: Display, // 通过 where 从句约束 T 必须实现 Display trait
{
// 打印传入的 ann 参数,这里利用了 Display trait 的格式化功能
println!("Announcement! {ann}");
// 比较两个字符串的长度,返回较长的那个
if x.len() > y.len() {
x
} else {
y
}
}
// 核心要点(基于两张图片内容):
// 1. 生命周期参数(如 'a)和泛型参数(如 T)都放置在函数名后的尖括号列表中。
// 2. 生命周期标注确保引用在使用期间有效,避免悬垂引用。
// 3. trait 约束(如 T: Display)通过 where 从句指定,确保泛型类型具有所需的行为。
// 4. 此函数是对示例 10-21 中 longest 函数的扩展,增加了泛型参数和 trait 约束。
// 5. 通过组合使用生命周期、泛型和 trait 约束,Rust 能在编译时保证安全性和灵活性。