
六. Lambda表达式和流
1. 与匿名类相比,优先选择Lambda表达式
函数类型:将只有一个抽象方法的接口(极少数情况下是抽象类)用作函数类型。它们的实例被称为函数对象。JDK1.1以来,创建函数对象的主要方式是使用匿名类。
函数式接口:在Java8中,java正式形成了这样的概念:只有一个抽象方法的接口非常特殊,值得特殊对待。这样的接口被称为函数式接口。Java支持使用Lambda表达式来创建这些接口的实例,其功能与匿名类相似,但更简洁。
除非参数类型的存在能让程序更清晰,否则应该省略Lambda表达式中所有参数的类型信息:编译器会使用一个类型推导的过程,根据上下文推断出这些类型。建议不要使用原始类型、建议优先使用泛型类型、建议优先使用泛型方法,这些建议对于类型推导很重要,因为大部分信息都是由泛型推导而来的。
(五1)中的Operation是带有特定于常量的类主体(重写部分)和数据(symbol)的枚举类型,与特定于常量的类主体相比,应该首选枚举实例字段。
看基于Lambda的Operation枚举,可能会认为特定于常量的类主体已经失去了作用。但并非如此,与方法和类不同,Lambda表达式没有名字,也缺乏文档;若计算不是不言而明的,或者超过几行代码,就不要将其放在Lambda中,一行代码是理想的,三行是合理的最大值。若一个Lambda表达式很长或难以理,要么想办法简化,要么重构程序去掉它。此外传递给枚举构造器的参数是在静态上下文进行求值的,因此,枚举构造器重的Lambda表达式不能访问枚举的实例成员(枚举构造器是静态的,并且在
Lambda表达式中使用的代码通常会在类加载时进行编译,因此这些表达式和实例成员之间的关系可能会引起冲突。枚举的实例成员是在每个枚举实例创建时才存在,而Lambda表达式在编译时可能无法访问这些实例)。上述限制导致特定于常量的类主体仍有用。匿名内部类能做到,Lambda表达式做不到的场景:Lambda仅限于函数式接口,若想创建抽象类的实例,可以用匿名类来完成,不能用Lambda。类似的,对于存在多个抽象方法的接口,也可以用匿名类来创建实例,但不能用Lambda。最后,Lambda无法获得对自身的引用,在Lambda中,this关键字指向的是包围这个表达式的实例;在匿名类中,this关键字指向的是这个匿名类的实例。若需要在函数对象的方法体内访问这个对象,必须使用匿名类。
Lambda表达式和匿名类共同点:无法可靠的跨不同的Java实现对其进行序列化和反序列化。若有一个函数对象,想令其可以序列化,可以使用私有的静态嵌套类。

//带有函数对象字段和特定于常量的行为的枚举
enum Operation
{
PLUS("+", (x, y) -> x + y),
MINUS("-", (x, y) -> x - y),
MULTIPLY("*", (x, y) -> x * y),
DIVIDE("/", (x, y) -> x / y);
//与特定常量的数据结合使用
private final String symbol;
private final DoubleBinaryOperator op;
Operation(String symbol, DoubleBinaryOperator op)
{
this.symbol = symbol;
this.op = op;
}
@Override
public String toString()
{
return symbol;
}
public double apply(double x, double y)
{
return op.applyAsDouble(x, y);
}
}2. 与Lambda表达式相比,优先选择方法引用
大多数情况下方法引用比Lambda更加简洁,Lambda比方法引用可读性和可维护性更好。

3. 首选标准的函数式接口
①使用标准的函数式接口
java.util.function包提供了大量标准的函数式接口。若存在标准的函数式接口可以满足需求,就应该优先使用这个接口,而不是专门编写一个。
java.util.function中有43个接口,但只要记住6个基本接口,必要时可推导出其余接口。这些基本接口都应用于对象引用类型。Operator接口表示结果和参数类型相同的函数。Predicate接口表示接受一个参数并返回一个boolean值的函数。Function接口表示参数和返回类型不同的函数。Supplier接口表示没有参数但会返回一个值的函数。Consumer接口表示接受一个参数但没返回值的函数。

6个基本接口中的每一个都有3个变体,分别用于处理基本类型int、long、double。他们的名称是在基本接口的名称前面加上基本类型作为前缀衍生出来的。IntPredicate。
Function接口还有另外9个变体,用于结果类型是基本类型值的情况。源类型和结果类型总是不同的,因为若相同应为Operator。若源类型和结果类型都是基本类型,则在Function之前加上SrcToResult作为前缀,LongToIntFunction(6个变体)。若源类型是基本类型且结果类型是对象引用,则在Function前加上SrcToObj,DoubleToObjFunction(3个变体)。
3个基本函数接口都有双参数版本:BiPreDicate<T, U>、BiFunction<T, U, R>、BiConsumer<T, U>。也有分别返回3个基本类型值的BiFunction变体:ToIntBiFunction<T, U>、ToLongBiFunction、ToDoubleBiFunction。还有Consumer双参数变体,他们接受一个对象引用和一个基本类型:ObjDoubleConsumer<T>、ObjIntConsumer<T>、ObjLongConsumer<T>。一共9个双参数版本的基本接口。
最后是BooleanSupplier接口,他是Supplier接口的一个变体,返回boolean值。
很多标注函数式接口之所以存在,只是为了提供对基本类型的支持。不要将基本类型的函数式接口替换为对应封装类的基本函数式接口。大批量操作中使用基本类型的封装类型对性能影响严重。
②编写自己的函数式接口
若没有一个标准接口能满足要求,就自己编写函数式接口。
有些时候,哪怕存在标准接口,仍需表写自己的函数式按接口:它将被频繁使用,一个描述性的名字能带来好处;它有严格的通用约定;自定义的默认方法能带来好处。
应该始终在我们编写的函数式接口上使用@FunctionalInterface注解:它告诉这个类以及文档读者,该接口被设计用于支持Lambda;它让接口中只有一个抽象方法,否则无法通过编译;可以防止维护者在接口不断演变时不小心加入新的抽象方法。
注意:不要提供这样的重载方法--在同一个参数位置上接受不同的函数式接口,有可能在客户端造成歧义。例如:ExecutorService的submit方法既可以接受Callable<T>,也可以接受Runnable,所以存在这样的可能,在编写客户程序时需要使用强制类型转换来选择正确的重载版本。

ExecutorService executor = Executors.newFixedThreadPool(2);
Runnable task = new Runnable() {
@Override
public void run() {
System.out.println("Task executed");
}
};
// 假设你本来想提交一个Callable,但是不小心传入了Runnable类型任务,编译时可能需要强制转换
Future<Integer> result = (Future<Integer>) executor.submit(task); // 强制类型转换会引发ClassCastException4. 谨慎使用流
①使用流注意事项
流:表示有限或无限的数据元素序列。流中的元素可以来自任何地方。流中的数据元素可以是对象引用或基本类型值。流支持三种基本类型:int、long和double。
流管道:表示在这些元素上进行的多阶段计算。
一个流由一个源流、0个或多个中间操作和一个终结操作组成。中键操作都会将一个流转换成另外一个流。终结操作对最后一个中间操作产生的流执行最终的计算。
流管道是延迟求值的:求值直到终结操作被调用时才会开始,并且永远不会计算对于完成终结操作而言并不需要的数据元素。延迟求值使得处理无限流成为可能。没有终结操作的流管道会进入静默的误操作状态。
流API是流式的:它被设计为允许将组成管道的所有调用链接成单条表达式。
默认情况,流管道会顺序运行,若想其并行执行,只需在管道中的任何一个流上调用parallel方法,但很多时候这样处理并不合适。
过度使用流会使程序难以阅读和维护。
在没有显式的类型信息的情况下,仔细命名Lambda的参数对流管道的可读性至关重要。
就可读性而言,在流管道中使用辅助方法(外部的类的静态或实例方法,辅助方法中可以处理char值)比在迭代代码中使用更为重要,因为管道缺乏显式的类型信息和具名的临时变量。
Java不支持基本类型的char流:char流返回的最终值是int流,虽然可以强制类型转换,但通常应该避免使用流处理char值(缺乏原生
char流支持;字符编码是字符处理中一个很复杂的问题。不同的编码方案(如 UTF - 8、UTF - 16 等)会对字符的存储和处理产生影响。在使用流处理字符时,很容易因为编码问题导致数据处理错误;
将
char转换为int以使用现有的流 API 会带来额外的性能开销。每一个char转换为int都需要进行一次类型转换操作,当处理大量字符时,这些额外的操作会累积起来,影响程序的性能;使用流处理
char值时,代码的语义可能不够明确。流 API 主要设计用于处理集合和数组中的元素,而char本身是单个字符,将其放入流的上下文中处理,可能会让其他开发者难以理解代码的意图;对于字符处理,传统的循环和方法已经足够强大和直观。例如,使用
for循环遍历字符串中的每个字符,代码简洁明了,易于维护。)。通常,即使是非常复杂的任务,也最好使用流和迭代的某种组合来完成,以便代码的可读性和可维护性。
只有在使用流确实有意义的情况下,才应该重构现有代码以使用流,以及在新代码中使用流。
②迭代优点
流管道使用函数对象(通常为Lambda或方法引用)来表达重复的计算,而迭代代码使用代码块表达重复计算。通过代码块可以做到一些通过函数对象无法做到的事情(若某项计算最好使用这些方法完成,就不适合使用流):
从代码块中,可以读取或修改作用域内的任何局部变量;而从Lambda中,只能读取final或effectively final的变量,并且不能修改任何局部变量。
从代码块中,可以使用return,实现从包围的方法中返回,也可以在包围的循环执行continue或break,或抛出包围的方法声明会抛出的任何检查型异常;而Lambda中这些都不能做。
③流的优点
若某项计算最好使用下面完成,就使用流:
对元素序列进行统一的转换。
对元素序列进行过滤。
使用单个操作将多个元素序列合并起来(例如将他们相加、连接、计算最小值)。
将元素序列累加到一个集合中,也许是根据某个共同属性来分组。
在一个元素序列中查找满足某个条件的元素。
④反转映射
使用流很难做到同时从管道的多个阶段访问相应的元素:一旦把一个值映射到其他的值,原来的值就消失了。一个方案是,将每个值映射到一个包含原值和新值的值对对象,但会导致代码混乱冗长。一个更好的方案是在需要访问的早期阶段的值时反转映射。
//映射到值对对象
class Pair<T, U> {
private final T first;
private final U second;
public Pair(T first, U second) {
this.first = first;
this.second = second;
}
public T getFirst() {
return first;
}
public U getSecond() {
return second;
}
}
public class StreamPairExample {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
List<Pair<Integer, Integer>> pairs = numbers.stream()
.map(n -> new Pair<>(n, n * 2))
.collect(Collectors.toList());
// 可以访问原始值和新值
pairs.forEach(pair -> System.out.println("Original: " + pair.getFirst() + ", New: " + pair.getSecond()));
}
}//反转映射
//在这个例子中,映射操作是将每个数乘以 2,反转映射就是将新值除以 2。
//通过这种方式,我们可以在后续阶段恢复原始值,而不需要引入额外的值对对象,使代码更加简洁。
public class ReverseMapExample {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> squaredNumbers = numbers.stream()
.map(n -> n * 2)
.collect(Collectors.toList());
// 反转映射,从新值恢复到原始值
List<Integer> originalNumbers = squaredNumbers.stream()
.map(n -> n / 2)
.collect(Collectors.toList());
System.out.println("Original: " + numbers);
System.out.println("New: " + squaredNumbers);
System.out.println("Recovered original: " + originalNumbers);
}
}5. 在流中首选没有副作用的函数
①流范型
流范型最重要在于将计算组织为一个结构化的转换序列,其中每个阶段的结果都尽可能接近上一个节点的结果的纯函数。纯函数就是,结果仅取决于其输入的函数,它不依赖于任何可变状态,也不会更新任何状态,为了实现这一点,传递大流操作(包括中间和终结操作)中的任何函数对象都应该没有副作用。
/**
* 使用了流API,但没有使用函数式编程范型--不要这么做
*
* 下面使用了流、Lambda和方法引用,并得到了正确的代码。
* 但它根本不是流代码,而是伪装成流代码的迭代式代码。它没有
* 得到流API的任何好处,而且他比相应的迭代式代码更长、更难阅读
* 和维护。
*
* 问题在于这段代码在一个终结操作forEach中完成了所有的工作,使用了一个
* 会修改外部状态(freq)的Lambda。
* forEach操作应该做的是展示流的计算结果,除此之外任何动作都是“代码中的
* 坏味道”好事,就像会修改状态的Lambda一样。
* forEach操作应该仅用于报告流计算结果,而不是执行计算
*/
Map<String, Long> freq = new HashMap<>();
try (Stream<String> words = new Scanner(System.in).tokens())
{
words.forEach(
word ->
{//错误更新外部局部变量
freq.merge(word.toLowerCase(), 1L, Long::sum);
}
);
}
/**
* 正确使用流来初始化频率表
*
* 下面代码正确使用了流API,更短更清晰
*
*/
try (Stream<String> words = new Scanner(System.in).tokens())
{
freq = words.collect(groupingBy(String::toLowerCase, counting()));
}②收集器
Collectors API(39个方法):收集器生成的对象通常是一个集合。用于将流元素收集到一个真正的集合的收集器有3个:toList()、toSet()、toCollection(collectionFactory),其分别返回一个List、一个Set和一个由程序员指定的Collection类型。
Collectors其他36个方法,其中大部分都是间流收集到Map中的,每个流元素都和一个键和一个值关联,并且多个流元素可以与同一个键相关联。
最简单的的映射收集器是toMap(KeyMapper, valueMapper),它接受两个函数,一个将流元素映射到键,一个将流元素映射到值。
若流中的每个元素都映射到唯一的键,toMap这种简单形式很好,但若有多个流元素映射到相同的键,管道将抛出IllegalStateException并终止。
toMap的更复杂的形式以及groupingBy方法以不同方式提供了处理这种冲突的策略。一种方式是,除了键和值的映射函数外,再提供一个归并函数,归并函数的类型是BinaryOperator<V>, V是映射值的类型。归并函数会将与一个键关联的任何其他值与现有值合并到一起,例如:若归并函数是乘法,最终会得到一个值,它是与同一个键关联的所有值的乘积。
三参数的toMap可以解决冲突,存在冲突时这个收集器会采用最后写入者获胜策略。
toMap的最后一个版本需要第四个参数,该参数是一个映射工厂,用于指定一个特定的映射实现,比如EnumMap或TreeMap。
toMap的前3个版本还有其他变体形式,名为toConcurrentMap,可以高效的并行运行并生成ConcurrentHashMap实例。
Collectors API还提供了groupingBy方法,它返回的收集器会生成这样的映射:根据分类函数将元素分到几个类别中。分类函数接受一个元素并返回其所属的类别,这个类别就用作该元素的映射键。groupingBy最简单版本就是只接受一个分类器,并返回一个映射,映射值是每个类别中所有元素的列表。
若想让groupingBy返回一个这样的收集器,它生成的Map中包含的是值而不是列表。那么除了分类器外,还可以指定一个下游收集器。下游收集器会从包含一个类别中的所有元素的流中生成一个值。这个参数最简单就是将toSet()传给他,这样得到的Map,它的值就是由元素组成的Set,而不是List。
另外,也可以传递toCollection(collectionFactory),这样可以创建放置每个类别的元素的集合,是的可以选择自己想要的集合类型。双参数的groupingBy另一个简单用法是将counting()作为下游收集器传递,这样得到的Map会将每个类别和这个类别中元素的数量关联起来,而不再是包含元素的集合。
groupingBy的第三个版本,除了下游收集器,还允许指定一个Map工厂。该方法违反了标准的伸缩参数列表形式:mapFactory参数在downStream参数之前,而不是之后。这个版本的groupingBy不仅可以控制所生成的映射,还可以控制用来包含元素的集合。例如:可以指定一个返回TreeMap且其值为TreeSet的收集器。
groupingByConcurrent方法提供了groupingBy的3个重载版本的变体。这些变体可以高效的并行运行,并生成ConcurrentHashMap实例。还有一个与groupingBy相关的叫做partitionBy方法,它接受的不是分类函数,而是一个谓词,并返回一个其键为Boolean的映射。这个方法有两个重载版本,其中之一除了谓词外还接受一个下游收集器。
counting方法返回的下游收集器仅用作下游收集器。若需要在Stream上使用相同的功能,可以通过count方法,因此没有理由使用collect(counting())。还有15个Collectors方法也是这样的,包括其名称以summing、averaging和summarizing开头的9个(相应的基本类型流也提供了这些功能),还包括各种重载版本的reducing方法以及filtering、mapping、flatMapping和collectingAndThen方法,大多数程序员可以忽略这些方法。
还有3个方法,虽然在Collectors类中,但他们与集合无关。前两个是minBy和maxBy,他们接受一个比较器,并返回根据这个比较器确定的流中的最小或最大的元素。他们是Stream接口中min和max的简单实现。
最后一个Collectors方法是joining, 他仅用于处理由CharSequence实例(如字符串)组成的流。在其无参版本中,他会返回一个只是将流元素连接起来的收集器。其单参数版本,会接受一个名为delimiter(分隔符)的CharSequence参数,并返回一个收集器,该收集器会将流元素连接起来,在相邻元素之间插入这个分隔符。若传入逗号作为分隔符,该收集器将返回一个以逗号分隔元素值的字符串(若流中任何元素本身就包含逗号,则生成的字符串会存在歧义)。其三采纳数版本,除了分隔符之外,还有前缀和后缀。这样的到的收集器,其生成的字符串和在打印集合时看到的类似,[came, saw]。
总而言之,编程实现流管道的精髓在于无副作用的函数对象。者适用于所有传递给流和相关对象的诸多函数对象。终结操作forEach应该只用来报告流执行的结果,而不是用来执行计算。
6. 作为返回类型时,首选Collection而不是Stream
①常见返回类型
许多方法会返回元素序列,Java8前常见的返回类型有Collection、Set和List等集合接口,还有Iterable接口以及数组类型;java8中流被添加到平台中。集合接口通常是常规选择。若方法只是为了支持for-each循环,或所返回的序列无法实现某个Collection方法(通常是contains(Object)),则使用Iterable接口。若返回的元素是基本类型值,或存在严格的性能要求,则使用数组。
②从Stream<E>到Iterable<E>的适配器
数组:对于数组,
for-each循环是通过普通的for循环来实现的。编译器会将for-each循环转换为普通的for循环,使用数组的索引来访问元素。集合:对于实现了
java.lang.Iterable接口的集合类,for-each循环是通过迭代器(Iterator)来实现的。编译器会将for-each循环转换为使用迭代器的代码。
Stream接口中包含了Iterable接口中唯一的抽象方法,两个方法的声明是兼容的,但Stream没有扩展Iterable, 使得无法使用for-each对流进行迭代。似乎将指向Stream的iterator方法的方法引用传递给for-each循环就行了,但由此产生的代码晦涩难懂不适合在实践中使用。
public class Main
{
public static void main(String[] args)
{
//因为Java类型推导的限制,无法通过编译
for (ProcessHandle ph : ProcessHandle.allProcesses()::iterator)
{
//对进程进行处理
}
//为了使其通过编译,必须将这个方法引用强制转换为一个适当参数化的Iterable
//比较丑陋的方案,实现在流上的迭代
for (ProcessHandle ph : (Iterable<ProcessHandle>) ProcessHandle.allProcesses())
{
}
//有了下面的适配器,就可以使用for-each对任何流进行迭代了
for (ProcessHandle ph : iterableOf(ProcessHandle.allProcesses()))
{
}
}
//从Stream<E>到Itreable<E>的适配器
public static <E> Iterable<E> iterableOf(Stream<E> stream)
{
/**
* stream::iterator 是一个方法引用,它实际上是创建了一个实现了 Iterable 接口的匿名对象。
* 当你调用这个匿名对象的 iterator() 方法时,会调用 Stream 对象的 iterator() 方法并返回相应的 Iterator。
*
* Iterator<T> iterator();是函数式接口Iterable的唯一方法
* 这里类似lambda那里。
*/
return stream::iterator;
}
/**
* 反过来若想使用流管道来处理序列,而API只提供了Iterable
* 也可以提供一个适配器
* <p>
* 从Iterable<E>到Stream<E>的适配器
*/
public static <E> Stream<E> streamOf(Iterable<E> iterable)
{
return StreamSupport.stream(iterable.spliterator(), false);
}
}③选择Collection的原因
返回一个对象序列的方法,并且直到它会被用于流管道,就可以返回Stream。若返回对象序列只会用于迭代,则应该返回Iterable。
Collection接口是Iterable的子类型,并且有一个Stream方法,所以其既支持迭代访问又支持流访问。对于公有的返回对象序列的方法,Collection或其适当的子类型通常是最佳的返回类型选择。有时候也会根据实现的难易程度来选择返回类型。
利用Arrays.asList和Stream.of方法,数组也很容易支持迭代访问和流访问。
若返回的序列足够小,可以轻松放入内存,最好返回某个标准的集合实现。但不要只是为了以Collection形式返回而将一个大型序列存储在内存中。
若这些元素已经在一个集合,或序列中元素的数量小到有理由创建一个新集合,就返回一个标准的集合,否则可以考虑去自定义一个集合。若返回的序列很大,但可以简洁的表示出来,可以考虑实现一个特殊用途的集合。
例如:假设相返回一个给定集合的幂集,它包括该集合的所有子集。集合{a, b}的幂集是{{},{a},{b}, {a, b}}。若一个集合有n个元素,其幂集就有2^n个元素。因此不应该考虑将幂集存储在某个标准的集合中。但借助AbstractList,很容易为这个需求实现一个自定义的集合。
技巧在于,将每个元素在幂集中的索引用作位向量,用索引中的第n位表示原集合中第n个元素是否存在。实质上,从0到2^n - 1的二进制数与包含n个元素的集合的幂集之间存在一个自然映射。
//通过自定义的集合返回输入集合的幂集
class PowerSet
{
public static final <E> Collection<Set<E>> of(Set<E> s)
{
List<E> src = new ArrayList<>(s);
//size方法返回类型为int, 限制集合大小为2^31 - 1
if (src.size() > 30) throw new IllegalArgumentException("Set too big" + s);
return new ArrayList<Set<E>>()
{
@Override
public int size()
{
return 1 << src.size();//从2到src.size()的幂
}
@Override
public boolean contains(Object o)
{
return o instanceof Set && src.containsAll((Set) o);
}
@Override
public Set<E> get(int index)//求哪个集合,实际就是选对应元素,时间换空间,不用存储
{
Set<E> result = new HashSet<>();
for (int i = 0; index != 0; ++i, index >>= 1)
if ((index & 1) == 1)
result.add(src.get(i));
return result;
}
};
}
}7. 将流并行化时要谨慎
①注意:Stream.iterate和limit
若源流来自Stream.iterate或使用了中间操作limit,将这样的流管道并行化不太可能提高:
Stream.iterate是一个用于生成无限流的方法,它接受一个初始元素和一个UnaryOperator函数,通过不断应用该函数来生成后续元素。顺序依赖性:
Stream.iterate生成的元素具有很强的顺序依赖性,每个元素的生成都依赖于前一个元素。例如,要生成n + 1这个元素,必须先得到n元素。而并行流的核心是将任务拆分成多个子任务并行执行,对于有顺序依赖的流,很难将其有效地拆分成多个独立的子任务并行处理,因为一个子任务的执行可能依赖于另一个子任务的结果。线程同步开销:并行流在执行过程中需要进行线程同步和协调,以确保元素的生成顺序和最终结果的正确性。由于
Stream.iterate的顺序依赖性,线程同步的开销会非常大,甚至可能超过并行执行带来的性能提升。-
提前终止困难:在并行流中,各个线程会独立地处理流中的元素。当使用
limit时,为了确定是否已经达到了指定的元素数量,需要对各个线程的处理结果进行汇总和协调。由于并行执行的不确定性,很难提前终止其他线程的执行,可能会导致不必要的计算开销。数据合并开销:并行流处理后需要将各个线程的结果合并成一个最终结果。对于使用
limit的流,在合并过程中需要进行额外的处理,以确保最终结果只包含前n个元素,这也会增加性能开销。
②适合并行的情况
对ArrayList、HashMap、HashSet、ConcurrentHashMap实例,数组,int区间,long区间上的流进行并行化,想你提升效果最佳:
这些数据结构共同点在于他们都可以被精确、低成本的分割成任意大小的子区间,这使得并行线程之间进行分工变得很容易。流库用于执行此任务的抽象是分割迭代器,他由Stream和Iterable上的spliterator方法返回。
这些数据结果公有的另一个重要特性是,他们在连续处理时提供了非常好的引用局部性:连续的元素引用在内存中被存储在一起。这些引用所指向的对象在内存中未必挨着,这降低了引用局部性。事实证明,引用局部性对于大批量操作的并行化至关重要:如果没有引用局部性,线程会出现闲置,等待数据从内存传输到处理器的高速缓存中。引用局部性最好的数据结构时基本类型的数组,因为数据本身在内存中是连续存储的。
③终结操作的影响
管道的终结操作的性质也会影响并行执行的有效性。如果与流管道的整体工作相比,终结操作中完成的工作量比重很大,并且该操作本质上是顺序的,则对该管道进行并行化的效果将很有限。
最适合并行化的终结操作是归约,就是使用Stream的某个reduce方法或类库提供的归约方法(min、max、count、sum),将从管道中出现的所有元素合并到一起。
短路操作anyMatch、allMatch、noneMatch也适合并行化。
由Stream的collect方法执行的操作称为可变归约,不适合并行化,因为对集合合并的开销很大。
④使用问题
若要编写自己的Stream、Iterable、Collection实现,且希望提供不错的并行性能,则必须重写spliterator方法,并对所生成的流的并行性能进行充分测试。
对流进行并行化处理不仅有可能导致性能变差(包括活性失败),还有可能导致错误的结果和不可预测行为(安全性失败)。安全性失败可能是因为并行化的管道使用了映射函数、过滤函数和其他由程序员提供的函数对象,而他们并未遵守相关的实现要求。Stream对这些函数对象有严格要求。例如,传递给Stream的reduce操作的累加函数和组合函数必须是可结合的、无干扰的和无状态的。若违反了这些要求,若以非并行化可能会得到正确结果,但若将其并行化,可能会失败。
即使正在使用的流管道,其源流可以高效分割,其终结操作可以并行化或计算开销很低,而且用到的函数对象都是无干扰的,除非这个流管道做的实际工作多道足以抵消与并行化相关的成本,否则也无法得到理想的并行加速。对于这里实际的工作量,粗略估计就是流中元素数乘以每个元素所执行的代码行数,应该至少是十万。
将流并行化是一种性能优化,应2该进行测试。
如果要并行化一个随机数流,应该从SplittableRandom实例开始,而不是ThreadLocalRandom(或Random)。SplittableRandom就是专门为此设计的,具有线性加速潜力。ThreadLocalRandom是为单线程设计的,虽然也可以并行化,但不快。Random会在每个操作上同步,导致大量竞争,难以并行。
除非有充分理由相信对流管道进行并行化可以保持正确性并提供速度,否则不要尝试。
七. 方法
1. 检查参数的有效性
大多数方法对弈可以传递给其参数的值都有限制,例如,索引值必须为非负数,对象引用不能为null。应该将这些限制都清楚地写在文档中,并在方法体的开头进行检查,以强制实施这些限制。
未能验证参数的有效性,可能导致违背故障的原子性:若无效的参数值被传递给方法,而这个方法在执行前对参数进行了检查,它就会很快失败,并抛出一个恰当的异常。若没有对其参数进行检查,可能会出现以下情况:方法在处理过程中失败,并抛出一个令人困惑的异常;方法正常返回,却计算出了错误的结果;方法正常返回,但让某个对象处于损坏状态,导致未来某个不确定的时间点、在某处不相关的代码上出现错误。
对于公有的和受保护的方法,应该使用Javadoc的@throws标签将违反参数限制时会抛出的异常写在文档中。
Java7新增的Objects.requireNonNull方法既灵活又方便,所以没必要再手动执行null检查了。
在Java9中,java.util.Objects中新增加了一个区间检查工具。该工具由三个方法组成:checkFromIndexSize()、checkFromToIndex()、checkIndex()。该工具不像null检查方法那样灵活,它不允许指定自己的异常详细信息,而且仅设计用于列表和数组索引。它不处理闭区间(包含区间两侧的两个端点)。
未导出的方法,作为包的创建者,我们控制方法的调用情况,所以我们能够确保,也应该确保只有有效的参数值会被传递进来。因此,非公有的方法可以使用断言来检查其参数。
应该检查那些将被存储下来供后面使用的参数的有效性,这个原则同样适用于构造器。
在执行方法的计算前,应该显式的检查其参数:但有一个例外情况,有效性检查的成本很高或难以操作,而且会在执行计算的过程中隐含进行。比如sort函数会隐式检查元素是否可比较,不可比较会抛出异常。
2. 必要时进行保护性复制
①两类攻击
Java是一门安全语言,意味着在不使用本地方法的情况下,困扰着C、CPP等不安全语言的缓冲区溢出、数组越界、野指针和其他内存损坏错误,Java都是免疫的。
即使在安全语言中,应该假设客户端会尽其所能的破坏类的不变式,所以必须进行防御性编程。
要修改对象的内部状态,若没有这个对象的协助,另一个类不可能做到这一点,但有时我们会轻而易举的提供了这样的协助,如下:
public class Main
{
public static void main(String[] args)
{
/**
* 第一类攻击
乍一看下面的类是不可变的,而且强制实施了这个不变式:时间段开始
* 不能位于结束之后。
* 然而Date是可变的,利用这一点很容易破坏掉这个不变式
*/
//攻击Period实例的内部
Date start = new Date();
Date end = new Date();
Period p = new Period(start, end);
end.setYear(78);//修改了p内部
/**
对Period内部的第二类攻击
**/
Date start = new Date();
Date end = new Date();
Period p = new Period(start, end);
p.end().setYear(78);//修改了p的内部
}
}
//有问题的不可变时间段
final class Period
{
private final Date start;
private final Date end;
public Period(Date start, Date end)
{
if (start.compareTo(end) > 0)
throw new IllegalArgumentException("Start date cannot be greater than end date");
this.start = start;
this.end = end;
}
public Date start()
{
return start;
}
public Date end()
{
return end;
}
}②实现保护性复制
从Java8开始,要解决这个问题,可以使用Instant(或LocalDateTime或ZoneDateTime)来代替Date,因为Instant(和java.time中的其他类)是不可变的。Date已经过时,不应该在新代码中使用。但有时我们不得不在API和内部表示中使用可变值类型。
为了保护Period视力内部受到此类攻击,有必要为其构造器的每个可变参数进行保护性复制,并使用这些副本作为Period实例的组成部分,而不是使用参数的原始值:
保护性复制是在检查参数的有效性之前进行了,而且检查会在副本而不是在参数的原始值上进行的:因为在检查参数的有效性和复制参数这两个时间点之间,存在一个漏洞窗口,可能会有另一个线程修改了参数,所以这里的做法可以避免此类问题。
如果参数的类型可以被不受信任方子类化,不要使用clone方法对这类参数进行保护性复制:没有使用Date的clone方法进行保护性复制,因为Date类不是final的,这意味着其他类可以继承自
Date类并覆盖clone方法,所以不能保证clone方法返回的一定是java.util.Date的对象:有可能存在一个专门为恶意攻击而设计的不受信任的子类,返回的就是这样的子类的实例。例如,这样的子类可以在创建实例时将指向每个实例的引用记录在一个私有的静态列表中,并允许攻击者访问此列表,这样攻击者能够自由控制所有实例。为了防御第二类攻击,只需修改访问器的方法,使其返回可变内部字段的保护性副本:与构造器不同的是,在访问器中的方法可以使用clone方法进行保护性复制,因为我们知道Period内部的Date对象的类就是java.util.Date,而不是一些不受信任的子类。但根据(二4), 通常最好使用构造器或静态工厂来复制实例。
final class Period
{
private final Date start;
private final Date end;
//修复的构造器,对参数进行了保护性复制
public Period(Date start, Date end)
{
this.start = new Date(start.getTime());
this.end = new Date(end.getTime());
if (start.compareTo(end) > 0)
throw new IllegalArgumentException("Start date cannot be greater than end date");
}
public Date start()
{
return start;
}
//修复访问器方法--返回内部字段的保护性副本
public Date end()
{
return new Date(end.getTime());
}
}③总结
参数的保护性复制不仅适用于不可变类。每当编写的方法或构造器会将客户端提供的对象存储在内部的数据结构时,都应该考虑这个对象是否是可变的,若不能容忍其可变,就应该进行保护性复制,并用副本代替原始对象,放到内部的数据结构中。例如,若考虑使用客户端提供的对象引用作为内部Set实例中的元素,或内部Map的键,若在这个对象放在实例后,它又被修改,Set或Map的不变式将被破坏。
将内部组件返回给客户端之前对其进行保护性复制,逻辑是一样的。
应该尽可能的使用不可变对象作为对象的组件,这样无需操心保护性复制的问题。
3. 仔细设计方法签名
仔细选择方法的名称:方法的名称应始终遵循标准的命名约定。首要的目标是选择可以理解的名称,并且与同一包中的其他名称保持一致。次要目标是,若存在更广泛的共识,所选择的名称也应该与该共识保持一致。避免使用过长的方法名称。
不要以方便用户使用的名义提供过多方法:过多的方法会使类难以学习、使用、文档化、测试和维护。对于接口更是如此。只有在使用频率非常高的情况下,才考虑提供一个便捷方法。
避免过长的参数列表:参数最好不超过4个,不方便使用。类型相同的一长串参数尤其有害,用户不仅无法记住参数的顺序,而且不小心弄反顺序,程序仍可以不希望的方式编译和运行。
有3种技巧可以缩短过长参数。第一是将方法分解成多个方法,每个方法仅需要原来方法参数列表的一个子集,若处理不当,可能又会导致方法太多,可以通过增加正交性来减少方法数量。
第二个技巧是,创建辅助类来保存参数组。这些辅助类通常会被设计为静态成员类。若一个参数序列看上去表示的是某个独立实体,而且这个序列会频繁出现,则建议使用这种技巧。
第三种技巧将前两种结合起来,将生成器模式(一2)从对象构建应用于方法调用中。若有个方法存在许多参数,其中有一些是可选的,那么定义一个表示所有参数的对象,并允许客户端在此对象上多次调用setter方法,每个setter方法负责设置一个参数或是存在关联的一小组参数。一旦设置了所需参数,客户端可以调用这个对象的execute方法,他会对参数进行最终的有效性检查,并执行实际计算。
对于参数类型,应该优先使用接口而不是类:因为接口,可以接受所有实现了这个接口的子类型。使用类而不是接口,就限制了客户端只能使用某个特定实现。
除非从方法名称中能够明确看出要表达布尔值的含义,否则对于存在两个选项的参数,应该首选包含两个元素的枚举类型,而不是boolean类型:枚举使得代码更容易阅读和编写,而且扩展更容易。
4. 谨慎使用重载
①重载特性
你可能认为下面程序会依次打印Set、List和Unknown Collection,但其实际打印了3次Unknown Collection。原因在于classify方法被重载了,而调用哪个重载版本的选择是在编译时做出的。在循环的3次迭代中,参数的编译时类型都是Collection<?>,虽然参数的运行时类型并不相同。
对重载方法的选择是静态进行的,而对重写方法的选择是动态进行的:重写方法的正确版本会在运行时做出选择,这会根据被调用方法所在对象的运行时类型来进行。
class CollectionClassifier
{
public static String classify(Set<?> s)
{
return "Set";
}
public static String classify(List<?> lst)
{
return "List";
}
public static String classify(Collection<?> c)
{
return "Unknown Collection";
}
public static void main(String[] args)
{
Collection<?>[] collections =
{
new HashSet<String>(),
new ArrayList<BigInteger>(),
new HashMap<String, String>().values()
};
for (Collection<?> c : collections)
System.out.println(classify(c));
}
}②建议
应该避免令人费解的重载使用情况。
一个安全、保守的策略是永远不要导出参数数量相同的两个重载版本:如果方法使用方法使用了可变参数,保守策略就是不要重载它,除了(七5)描述的情况。若遵循这些限制,程序员就不用怀疑使用哪个重载版本了。总是可以给方法起不同的名称,而不是重载他们。比如readInt、readLong...
对于构造器而言,无法选择使用不同的名字:一个类的多个构造器总是重载的。但可以选择导出静态工厂而不是构造器。对于构造器,不必担心重载和重写的相互影响,因为构造器不能被重写。
存在多个参数数量相同的方法:若对于给定的一组实参,调用哪个重载版本总是显而易见的,那么导出多个这样的参数数量相同的重载版本,不会困惑。即:在每对重载方法中,至少有一个相应的形参具有完全不同的类型。完全不同就是没有任何一个非null的表达式可以被强制转换成这两个类型。此时,哪个重载版本适用于一组给定的实参,完全由参数的运行时类型决定,并且不会受到其编译时类型影响,所以造成混淆的一个主要源头就没了。例如,ArrayList有一个构造器接收int类型的参数,另一个构造器接受Collection类型的参数,很容易区分。
③自动装箱和泛型对重载的影响
在Java5前,所有基本类型和所有引用类型都是完全不同的,但是随着自动装箱的引入,情况发生了变化,已经造成麻烦。
下面产生的问题是因为List<E>接口中有两个重载的remove方法:remove(Object)和remove(int)。在java5之前,List接口还没有被泛型化,两个参数类型Object和int是完全不同的。但是随着泛型和自动装箱的引入,这两种参数不再是完全不同的了。
class SetList
{
/**
* 该程序将-3到2添加到有序的Set和List实例中。然后
* 进行了三次相同的remove调用。你可能会认为程序从
* Set和List实例中删除非负值(0、1、2),并打印
* [-3, -2, -1] [-3, -2, -1]。
*
* 实际上删除了Set实例中的非负值,但删除了List实例中的奇数值,
* 并打印出[-3, -2, -1] [-2, 0, 2]。这样的行为,称为混淆都
* 保守了。
*
* 原因在于:set.remove(i)调用选择的是remove(E)这个重载版本,
* 其中E就是这个Set的元素类型(Integer),它将i从int自动装箱
* 为Integer,这也是我们期望的行为,删除了所有正值。
*
* 另一方面,list.remove(i)调用选择的是remove(int i)这个重载
* 版本,它会从这个List实例中删除指定位置的元素。要解决这个问题
* 可以将list.remove的参数强制转换为Integer,从而选择正确的重载版本。
* 也可以对i调用Integer.valueOf方法,这样才会得到预期输入
*/
public static void main(String[] args)
{
Set<Integer> set = new TreeSet<>();
List<Integer> list = new ArrayList<>();
for (int i = -3; i < 3; ++i)
{
set.add(i);
list.add(i);
}
for (int i = 0; i < 3; ++i)
{
set.remove(i);
//list.remove((Integer)i);list.remove(Integer.valueOf(i));
list.remove(i);
}
System.out.println(set + " " + list);
}
}④Lambda和方法引用对重载的影响
java8中加入的Lambda表达式和方法引用进一步增加了重载混淆的可能。
不要让多个重载方法在同一参数位置接收不同的函数式接口。按照本条目的说法,不同的函数式接口并不是完全不同的。








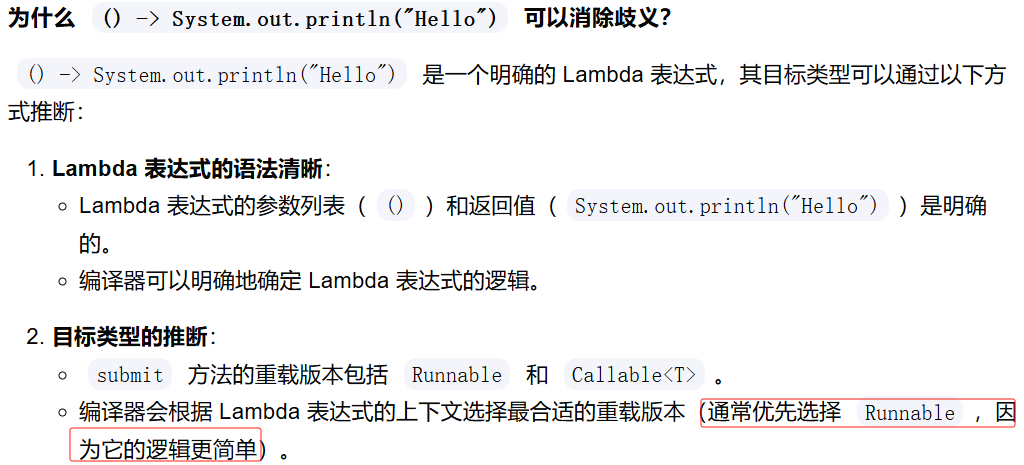

/**
* 虽然调用Thread的构造器和调用submit方法看起来很像
* 但前者可以通过编译,而后者不能。它们的参数是相同的
* (System.out::println),并且这个构造器和这个方法
* 都有一个接收Runnable类型的重载版本。
*
* 原因在于submit方法有一个接受Callable<T>类型的重载版本
* 而Thread的构造器没有。你可能会认为这不应该有任何区别,
* 因为println的所有重载版本都返回void,所以这个方法引用
* 不可能是Callable(返回的是T)。但重载解析算法不是这样工作的。
* 或许同样令人惊讶的是,若println方法也没有被重载,那么submit
* 方法调用将是合法的。问题在于被引用方法(println)和被调用方法(submit)
* 的重载结合在一起,阻止了重载解析算法按照我们期望的方式工作。
*
* 从技术上讲,问题在于System.out::println是一个不精确的方法引用
* 而“某些包含隐式类型的Lambda表达式或不精确的方法引用的参数表达式,
* 在适用性测试中会被忽略,因为他们的含义要到了选定某个目标类型时才能确定”。
* 关键的一点在于,对于重载的方法或构造器而言,如果在同一个参数位置使用了不同的
* 函数式接口,这回造成混淆。因此,不要让多个重载方法在同一参数位置接收不同的函数式
* 接口。按照本条目的说法,不同的函数式接口并不是完全不同的。
*/
new Thread(System.out::println).start();
ExecutorService exec = Executors.newCachedThreadPool();
exec.submit(System.out::println);//无法通过编译⑤其他准则
数组类型和除Object以外的类是完全不同的。此外,数组类型和除Serializable和Cloneable之外的接口也是完全不同的。若两个不同的类都不是彼此的后代,我们称这两个类是不相关的。任何对象都不可能是两个不相关的类的实例,所以不相关的类也是完全不同的。
通过转发,重载可以违反本条目的准则,因为其做的事情是完全相同的:
public boolean contentEquals(StringBuffer sb) { return contentEquals((CharSequence) sb); }
5. 谨慎使用可变参数
可变参数方法的工作原理:根据在调用位置传入的参数的数量,先创建一个数组,然后将参数值放入这个数组中,最后将数组传递给该方法。
在对性能要求很高的情况下,使用可变参数要非常小心:每次调用可变参数方法都会导致一次数组的分配和初始化。若根据经验确定无法承受这种开销,但又需要可变参数的灵活性,那么有一种方式可以二者兼得。假设已经确定,对一个方法95%的调用,参数都不超过3个。那么我们可以声明该方法的5个重载版本,,前4个分别包含0到3个普通参数,第五个除了3个普通参数,还包括一个可变参数,用于处理参数超过3个的情况。现在,只有参数超过3个的情况下才需要付出创建数组的开销,而这只占所有调用的5%。EnumSet的静态工厂使用了这种技术,将创建枚举集合的开销降到最低。
下面是使用可变参数的经典示例:
/**
* 有时编写这样的方法更合理--它需要一个或多个某种类型的参数,而不是零个
* 或多个。例如,要编写一个计算其参数最小值的函数。若客户端未传递任何参数
* 则该函数的行为时未定义的,我们可以在运行时检查这个数组的长度.
* <p>
* 使用可变参数来传递一个或多个参数的错误方式
*/
static int min(int... args)
{
if (args.length == 0)
throw new IllegalArgumentException();
int min = args[0];
for (int i = 1; i < args.length; ++i)
if (args[i] < min)
min = args[i];
return min;
}
/**
* 上面的方案有几个问题,最严重的是若客户端在没有参数的情况下调用了此方法,
* 他将在运行时而不是编译时失败。
* 另一个问题是,代码不美观,必须在args上包含一个显式检查,并且除非把min
* 初始化为Integer.MAX_VALUE,否则无法使用for-each循环,这也不够美观
* <p>
* 下面有一个更好的方式实现预期效果。可以声明该方法接受两个参数,一个是指定类型的
* 正常参数,一个是该类型的可变参数,解决了上一个所有不足
*/
static int min(int firstArg, int... remainArgs)
{
int min = firstArg;
for (int arg : remainArgs)
if (arg < min)
min = arg;
return min;
}6. 返回空的集合或数组,而不是null
①集合
有时候,人们认为返回null比返回空的集合或数组更好,因为可以避免分配空的容器所需要的开销。但有两个问题。首先,在这个层次上考虑性能问题不可取,除非有测量结果表明分配的开销确实是造成性能问题的真正的原因。其次确实有方法在不分配空间的情况下返回空的集合和数组,如下。
若确实有证据表明,分配空集合影响性能,可以通过重复返回一个不可变的空集合来避免分配,因为不可变对象可以自由共享。下面代码实现了这一点,他使用了Collectons.emptyList方法,若要返回Set, 使用Collections.emptySet,若要返回Map,使用Collections.emptyMap。这个优化措施很少使用,若确实使用,请在使用前后测试性能。
private static final List<Integer> integers = new ArrayList<>();
public static List<Integer> getIntegers()
{
return integers.isEmpty() ? null : new ArrayList<>(integers);
//return new ArrayList<>(integers);返回一个空集合或数组,但不分配空间
//return integers.isEmpty()?Collections.emptyList():new ArrayList<>(integers);优化,分配同一个空集合
}
public static void main(String[] args)
{
/**
* 若方法返回null而不是空的集合或数组,那么每次使用这个方法,都得额外判断
* 是否为null。这样很容易出错,因为编写客户端代码的程序员可能会忘记编写对
* null进行特殊处理的代码。
*
* 另外返回null而不是空的集合或数组,也会使返回该容器的实现变得复杂。
*/
List<Integer> integers = getIntegers();
if (integers != null)
{
}
}②数组
数组情况与集合相同,不要返回Null,而要返回长度为0的数组。
若你认为分配长度为0 的数组会影响性能,则可重复返回同一个长度为0的数族组,因为所有长度为0的数组都是不可变的。
//优化避免分配空数组
private static final Integer[] EMPTY_INTEGER_ARRAY = new Integer[0];
/**
* 不要为了改进性能而预先分配传递给toArray的数组,研究表明会适得其反
* private static final Integer[] EMPTY_INTEGER_ARRAY = new Integer[integers.size()];
*/
public static Integer[] getIntegers()
{
return integers.toArray(new Integer[0]);//返回可能为空的集合的正确方式
//return integers.toArray(EMPTY_INTEGER_ARRAY);优化
}7. 谨慎返回Optional
①介绍
java8前,当编写某些情况下无法返回一个值的方法时,可以返回异常或返回null(假设返回类型是对象引用类型)。但都存在问题,异常应该留作例外情况,而且抛出异常的开销很大,因为在创建异常时需要获得整个栈轨迹信息。返回null,则客户端需要包含处理这种特殊情况的代码。
Java8中有了第三种方式。Optional<T>sca类表示一个不可变容器,可以保存单个非null的T类型引用,也可以什么都不保存。不包含任何值的Optional称为空。若Optional不为空,则称其中存在一个值。Optional本质上是一个不可变的集合,最多可容纳一个元素。Optional<T>没有实现Collection<T>, 但原则上是可以的。
理论上会返回T类型的值,但在某些情况下却无法做到的方法,可以声明为返回Optional<T>。这允许该方法返回一个空结果来表示它无法返回有效结果。返回Optional的方法比抛出异常更灵活,更易用,且比有可能返回null的方法更不容易出错。
//返回集合最大值,集合为空则抛出异常
public static <E extends Comparable<E>> E max1(Collection<E> c)
{
if (c.isEmpty())
throw new IllegalArgumentException("Empty collection");
E result = null;
for (E e : c)
if (result == null || e.compareTo(result) > 0)
result = Objects.requireNonNull(e);
return result;
}
//以Optional<E>形式返回集合最大值
public static <E extends Comparable<E>>
Optional<E> max2(Collection<E> c)
{
if (c.isEmpty())
return Optional.empty();//返回一个空的Optional
E result = null;
for (E e : c)
if (result == null || e.compareTo(result) > 0)
result = Objects.requireNonNull(e);
return Optional.of(result);//返回一个包含给定非空值的Optional
/**
* 将null传给Optional.of是编程错误,会抛出空指针异常
* Optional.ofNullable(v)可以接受可能为null的值
*/
}
/**
* 以Optional<E>形式返回集合最大值--使用流
* <p>
* 流上的很多终结操作都会返回Optional
*/
public static <E extends Comparable<E>>
Optional<E> max3(Collection<E> c)
{
return c.stream().max(Comparator.naturalOrder());
}②建议
不要从返回Optional的方法中返回null,这回破坏这种机制的整个目的。
容器类型(集合、映射、流、数组和Optional等),不应该包装在Optional中:应该返回一个空的List<T>,而不是返回一个空的Optional<List<T>>。如果返回的是空的容器,客户端不用专门处理Optional。
如果方法可能无法返回一个结果,而且客户端不得不执行一些特殊处理,那就应该声明该方法返回Optional<T>:即使如此,返回Optional也是存在代价的。Optional实例是一个必须分配和初始化的对象,从这样的实例中读取值也需要一次额外的简介操作,这使得Optional在某些性能关键的情况下并不适用。
除了“较小的基本类型”的封装类(Boolean、Byte、Character、Short、Float)外,不要返回基本类型的封装类的Optional:与返回的基本类型相比,返回包含基本类型的封装类的Optional,开销很大,因为Optional多了两层封装。类的设计者认为有必要提供用于int、long、double的Optional类型,他们是OptionalInt、OptionalLong、OptionalDouble。
Optional几乎永远都不适合用作集合、数组、映射中的键、值或元素:例如若将Optional实例用作Map的值,则要表达某个键逻辑上不存在于这个Map中,就有了两者方式:要么就是这个键不存在,要么就是键存在,但是映射到了一个空的Optional,这会增加复杂性,极有可能导致混淆和出错。
将Optional实例存储在实例字段中是否合适?通常这是不好的,或许应该有一个包含该可选字段的子类。但有时包含Optional类型的字段可能是合理的。考虑(一2)中的NutritionFacts类,该类实例中包含很多非必须的字段,我们无法为每种可能的字段组合创建一个子类。此外这些字段是基本类型的,使得直接表示不存在的概念变得很麻烦。该类最适合的API是从每个可选字段的getter方法返回一个Optional实例,因此将Optional实例直接存储为对象中的字段是很有意义的。
除了作为返回值外,几乎不应该在其他情况下使用Optional。
③常用方法示例
public static <E extends Comparable<E>>
Optional<E> max(Collection<E> c)
{
return c.stream().max(Comparator.naturalOrder());
}
public static void main(String[] args)
{
//使用Optional来提供一个选定的默认值
String s1 = max(new ArrayList<String>()).orElse("No words...");
/**
* 使用Optional来抛出一个选定的异常
* 注意传入的是一个异常工厂,而不是实际异常。这样可以避免在实际需要抛出异常之前就
* 创建异常实例所带来的开销。
*/
String s2 = max(new LinkedList<String>()).orElseThrow(TemperTantrumException::new);
//当我们知道肯定存在返回值时
String s3 = max(new ArrayList<String>()).get();
/**
* 有时会遇到这种情况,获取默认值的开销很大,除非必要,否则我们想避免这种开销
* 对于这种情况,Optional提供了一个方法。它接受一个Supplier<T>,并且只在必要时
* 才调用它,这个方法是orElseGet。
*
* 还有一些方法用于处理更特殊的场景:filter、map、flatMap、ifPresent、or、
* ifPresentOrElse
*
* 还有一个isPresent方法,若Optional确实包含实例,则返回true,否则返回false。
* 但可以使用该方法的地方,上面可能有更好的替代,这样的代码会更短、更清晰、更符合习惯。
*/
Optional<ProcessHandle> parentProcess = ph.parent();
System.out.println(parentProcess.isPresent() ? String.valueOf(parentProcess.get().pid()) : "N/A");
//使用map替代
System.out.println(ph.parent().map(h -> String.valueOf(h.pid())).orElse("N/A"));
/**
* 在使用流编程时,会遇到这种情况,我们得到的是一个Stream<Optional<T>>,但需要处理
* 的是一个Stream<T>, 其中包含非空的Optional中的所有元素,若使用的是Java8,可以弥补差距
*/
streamOfOptionals//一个Optional流
.filter(Optional::isPresent)
.map(Optional::get);
/**
* 在java9中,Optional又加入了一个stream方法。这个方法是一个适配器,它将Optional转换为一个
* Stream;若Optional中存在一个元素,流就会包含该元素;若Optional为空,则流也为空。结合Stream
* 的flatMap方法,可以更简洁替换上面代码
*/
streamOfOptionals
.flatMap(Optional::stream);
}8. 为所有导出的API元素编写文档注释
要使一个API真正可用,必须为其编写文档,传统上,API文档是手动生成的,与代码保持同步是问题。Java编程环境通过Javadoc工具解决了这个问题,Javadoc利用特殊格式的文档注释,可以自动从源代码生成文档。
要正确的编写API文档,必须在每个导出的类、接口、构造器、方法和字段声明之前加上文档注释:若类是可序列化的,必须将其序列化形式也写在文档中。公有的类不应该使用默认构造器,因为无法为其提供文档注释。为了编写可维护的代码,还应该为大多数未导出的类、接口、构造器、方法和字段编写文档注释,但不需要像导出的API元素那样详细。
方法的文档注释应该简明扼要的描述该方法与其客户端之间的约定:除了为继承而设计的类中的方法外,约定应该说的是该方法会做什么,而不是怎么做。文档注释应该列出该方法的所有前置条件,即客户端为了调用该方法,所有必须满足的条件;还应该列出所有的后置条件,即在方法调用完成后,哪些条件肯定会成立。通常,前置条件是通过说明会抛出非检查型异常的@throws标签隐含描述出来的;每个非检查型异常对应一种违反前置条件的清晰。另外,前置条件可以在受影响的参数的@param标签中指定。
除了前置条件和后置条件,方法还应该将任何副作用都写在文档中:副作用指的是可以观察到的系统状态的变化,并且该变化不是实现后置条件所明显需要的。例如,若方法会启动一个后台线程,文档就应该说明这一点。
为了完整的描述方法的约定,文档注释应该为每个参数都添加一个@param标签,为返回值添加一个@return标签(除非返回值为void),并为方法抛出的每个异常添加一个@throws标签,无论是检查型异常还是非检查型异常。
按照惯例,跟在@param标签或@return标签之后的文本应该是一个名词性短语,用于描述参数或返回值所表示的值。少数情况下也可以用算术表达式代替名词性短语,例如:BigInteger。跟在@throws标签之后的文本应该包含由单词“if”引导的一个从句,描述在什么样的条件下会抛出该异常。
应该尽量让文档注释在源代码和生成的文档中都有不错的可读性:若二者不可兼得,应该优先保证生成的文档的可读性。
每个文档注释的第一句话成为该注释所涉及的元素的概述,概述必须能够独立的描述所涉及元素的功能。为避免混淆,一个类或接口中的两个成员或构造器不应该有相同的概述。特别注意方法重载。
在为泛型类或泛型方法编写文档时,一定要将所有的类型参数都写在文档中。
在为枚举类型编写文档时,除了类型本身和任何公有的方法之外,一定要将所有的常量都写在文档中。
在为注解类型编写文档时,除了类型本身,一定要将它的任何成员都写在文档中:对于成员,要使用名词性短语,就像他们是字段一样。对于该类型的概述,要使用动词性短语,说明当一个程序元素具有这种类型的注解时,它意味着什么。
包级文档注释应该放在一个命名为
package-info.java的文件中。API有两个方面在文档中经常被忽视:线程安全和可序列化能力:无论类或静态方法是否是线程安全的,都应该将其线程安全级别写在文档中。若类是可序列化的,应该将其序列化形式写在文档中。
虽然为所有导出的API元素提供文档注释是必要的,但有时还不够:对于由多个相互关联的类组成的复杂API,通常还需要提供一个描述该API的整体架构的外部文档,作为文档注释的补充。如果存在这样的文档,相关的类或包的文档注释应该包含一个指向它的连接。
八. 通用编程
1. 最小化局部变量的作用域
要最小化局部变量的作用域,最好的办法是在第一次使用它的地方进行声明:若一个变量在使用前声明了,只会造成混乱。局部变量的作用域从它被声明点到所封闭块的末尾,过早声明,会导致作用域过大。
几乎每个局部变量声明都应该包含一个初始化器:若还没有足够的信息来合理初始化这个变量,则应该推迟声明,直到具备了相关信息。该规则有个例外:与try-catch有关,如果变量是被一个有可能抛出检查型异常的表达式初始化的,那么该变量必须在try块内被初始化(除非这个块所在的方法可以将该异常传播出去)。如果该值必须在try块外使用,那么它必须在try块前被声明,此时它尚未被“合理的初始化”。
如果循环变量的内容在循环终止后不再需要,应该优先选择for循环而不是while循环:循环为将变量的作用域最小化提供了一个机会,无论是传统的for循环还是for-each形式的for循环,都支持声明循环变量,而且其作用域被限制在循环体以及for关键字和循环体之间的括号中的代码。且for循环更简短,可以重复使用变量名。
2. 与传统的for循环相比,首选for-each循环
①for-each优点
问题:传统for循环会通过迭代器或索引变量遍历,但有些多余,我们需要的只是元素,它们的出现增加了用错变量的机会。
for-each循环解决了上述问题:它通过将迭代器或索引变量隐藏起来,去掉了多余信息,避免了出错的可能性。使用for-each循环没有性能上损失,即使对于数组也是如此。
for-each循环不仅可以遍历集合和数组,还可以遍历实现了Iterable接口的任何对象。
当涉及嵌套的迭代时,for-each比传统的for循环优势甚至更大:
enum Suit {CLUB};
enum Rank {ACE};
static Collection<Suit> suits = Arrays.asList(Suit.values());
static Collection<Rank> ranks = Arrays.asList(Rank.values());
List<Card> deck = new ArrayList<Card>();
public static void main(String[] args)
{
//问题在于外循环的i在内循环被调用了
for (Iterator<Suit> i = suits.iterator(); i.hasNext(); )
for (Iterator<Rank> j = ranks.iterator(); j.hasNext(); )
deck.add(new Card(i.next(), j.next()));
//修复,但不美观
for (Iterator<Suit> i = suits.iterator(); i.hasNext(); )
{
Suit suit = i.next();
for (Iterator<Rank> j = ranks.iterator(); j.hasNext(); )
deck.add(new Card(suit, j.next()));
}
//对集合和数组嵌套迭代首选用法
for (Suit suit : suits)
for (Rank rank : ranks)
deck.add(new Card(suit, rank));
}②无法使用for-each的情况
破坏性过滤:若需要遍历集合并删除选定的元素,则需要一个显式的迭代器,以便调用remove方法。通常可以使用Collection的removeIf方法(java8加入)来避免显式的遍历。
转换:若需要遍历列表或数组并替换其部分或全部元素的值,则需要列表迭代器或数组索引,以便替换某个元素的值。
并行迭代:若需要并行遍历多个集合,则需要显式的控制迭代器或索引变量,以便所有的迭代器或索引可以同步推进。
3. 了解并使用类库
从Java7开始,不应该再使用Random(缺点很多,虽然Random.nextInt(int)没错),对于大多数场景而言,现在首选的随机数生成器是ThreadLocalRandom,他可以生成质量更高的随机数,而且速度很快。对于fork-join池和并行流,应该使用SplittableRandom。
使用标准类库优点1:可以利用这些编写标准类库的专家的知识,还有之前的使用者的经验。
使用标准类库优点2:若要解决的问题与我们的工作只有一点关系,没有必要浪费时间为其编写临时的解决方案。
使用标准类库优点3:他们的性能往往随着时间的推移而不断提高,而我们不必为此付出任何努力。
使用标准类库优点4:他们往往随着时间推移而增加功能。
使用标准类库优点5:会将我们的代码置于主流之中,代码更容易被阅读、维护和复用。
Java的每个重要版本都会向类库中添加许多特性,了解这些新特性是值得的。
每个程序员都应该熟悉java.lang、java.util、java.io以及他们的子包的基本内容。
集合类框架和流库,以及java.util.concurrent的部分并发机制,也是每个程序员都应该掌握的。
尽可能使用标准类库,若在Java平台类库中国找不到所需要的内容,下一个选择应该是寻找高质量的第三方类库,如谷歌的Guava类库。
4. 如果需要精确的答案,避免使用float和double
float和double类型主要是为科学和工程计算而设计的,它们会执行二进制浮点运算,而这种运算又是为了快速的在一个非常大的数量级范围内提供准确的近似值而精心设计的。然而它们并不提供精确的结果,因此不应该用在需要精确结果的地方。
float和double特别不适合货币计算:因为无法精确的用一个float和double值来表示0.1(或10的任何其他负整数次幂)。
BigDecimal:若不介意使用该类的不便和开销,可以使用该类。使用该类可以完全控制舍入模式,每当执行需要舍入的操作时,可以从8个舍入模式中做出选择。
int或long:若性能至关重要,且不介意自己记录小数点的位置,且所涉及数值不是很大,可以使用。若数值范围不超过9位十进制数字,可以使用int;若数值范围不超过18位十进制数组,可以使用long;若超过18位十进制数字,应该使用BigDecimal。
5. 首选基本类型,而不是其封装类
①封装类的问题
基本类型和封装类的主要区别:基本类型仅有值,而其封装类还有不同于值的身份信息,即:两个封装类实例可以有相同的值,但有不同的身份信息;其次,基本类型只有全功能值,而其封装类除了与基本类型值对应的所有全功能的值之外,还有一个非功能性质,即null;最后,基本类型与其封装类相比,在时间和空间方面的效率更高。若不小心,这三个差异有可能带来真正的麻烦。
几乎在所有混合使用基本类型和其封装类型的操作中,封装类都会被自动拆箱:若一个null的对象被自动拆箱,则会抛出空指针异常。
//问题1:相等问题
public static void main(String[] args)
{
/**
* 存在问题的比较器
*
* 对表达式i<j进行求值计算,会导致i、j引用的Integer实例
* 被自动拆箱,然后检查这样得到的第一个int值是否小于第二个。
*
* 但是对i==j表达式进行的比较是同一性比较,比较的是封装类的
* 引用地址而不是实际的int值,这就导致了错误。
*
* 在实践中,若需要一个比较器来描述某个类型的自然排序,只需要
* 调用Comparator.naturalOrder(),如果自己编写,则应该使用
* 比较器构造方法或基本类型的静态比较方法Integer.compare()。
*
* 即便如此,我们也可以添加两个局部变量来存储封装类参数对应的
* 基本类型值int值,然后使用这两个变量比较
*/
Comparator<Integer> naturalOrder =
(i, j) -> (i < j) ? -1 : (i == j ? 0 : 1);
naturalOrder = (iBoxed, jBoxed) ->
{
int i = iBoxed, j = jBoxed;//自动拆箱
return i < j ? -1 : (i == j ? 0 : 1);
};
}//问题2:初值问题
class Unbelievable
{
static Integer i=42;
public static void main(String[] args)
{
/**
* 没有打印Unbelievable,当对i==42求值时,抛出空指针异常
* 问题在于i是封装类,而不是int,它初始值为null.
*/
if (i == 42)
System.out.println("Unbelievable");
}
}//问题3:性能问题
/**
* 出奇的慢,能注意到对象创建吗?
*
* sum声明为了Long,导致在循环中sum
* 反复的被拆箱和装箱
*/
Long sum = 0L;
for (long i = 0; i < Integer.MAX_VALUE; i++)
sum += i;
System.out.println(sum);②适合使用封装类的场景
在参数化的类型和方法中:作为集合中的元素、键和值:无法将基本类型放入集合中,必须使用基本类型的封装类作为类型参数。
在以反射进行方法调用时:反射方法调用需要所有的参数以
Object类型传递。然而,基本类型(如int、float等)不是Object类型的,因此不能直接作为参数传递给反射方法。需要将其包装为对应的封装类对象,以便符合invoke()方法的要求。
6. 如果其他类型更合适,就不要使用字符串
字符串不适合用于替代其他值类型:当数据从文件、网络或键盘输入进入程序中时,通常会表现为字符串形式,人们自然倾向于让他保持这种形式,但只有数据本质上确实是文本内容时,这种倾向才是合理的。若它是数字,就应该转换为相应的数值类型,如int、double、BigInteger。若它是一个‘是或不是’类型问题的答案,应该转为相应的枚举类型或boolean。即:若存在一个适合的值类型,无论是基本类型还是对象引用,就应该使用它;若没有,则应该编写一个。
字符串不适合替代枚举类型:(五1)所讨论的,作为可枚举类型的常量,枚举类型比字符串好的多。
字符串不适合替代聚合类型:若一个实体有多个组件,通常不适合用单个字符串来表示。
字符串不适合代替能力表示:偶尔人们会用字符串来授予对某些功能的使用权限。例如,考虑设计一个线程局部变量机制。这样的机制提供了一些变量,每个线程都可以有自己的值。在官方没有提供前,有人提出以客户端提供的字符串作为键,来识别每个线程局部变量。
//存在问题--不恰当的使用字符串表示能力表
/**
* 这种实现方式的问题在于,字符串代表的是用于线程局部
* 变量的一个共享的全局命名空间。为使其发挥作用,客户端
* 提供的字符串必须是唯一的:若两个客户各自选择的线程
* 局部变量的名字恰好相同,他们就在无意中共享了同一个变量。
* 此外,安全性很差,恶意的客户端可以故意使用与另一个客户端相同
* 的字符串键,从而以非法方式访问另一个客户端的数据。
*/
class ThreadLocal
{
private ThreadLocal() {}//不可实例化
//设定当前线程中具名变量的关联值
public static void set(String key, Object value);
//返回当前线程中的具名变量关联的值
public static Object get(String key);
}//使用不可伪造的键(有时被称为capability)来代替字符串
/**
* 可以解决使用字符串作为键的问题,但还可以更好,
* 实际上不再需要这些静态方法。它们可以称为键的实例方法,
* 而此时这个键已经不是用于线程局部变量的键:它本身就是
* 一个线程局部变量。此时,顶层类没有任何实际性工作了
* 可以删除,并将嵌套类重命名为ThreadLocal
*/
class ThreadLocal
{
private ThreadLocal() {}//不可实例化
public static class Key
{
Key() {}
}
//生成一个唯一的、不可伪造的键
public static Key getKey()
{
return new Key();
}
//设定当前线程中具名变量的关联值
public static void set(Key key, Object value);
//返回当前线程中的具名变量关联的值
public static Object get(Key key);
}/**
* 这个API不是类型安全的,因为当我们从一个线程局部变量中检索值
* 时,必须将得到的Object类型强制转换为其实际类型。
* 要使原来基于字符串和Key的API做到类型安全很难。
* 但是对于下面的类只需将其参数化即可
*/
public final class ThreadLocal
{
private ThreadLocal() {}//不可实例化
public void set(Object value);
public Object get();
}
//类型安全的局部变量
//官方提供的API大致也是这样
public final class ThreadLocal<T>
{
private ThreadLocal() {}//不可实例化
public void set(T value);
public T get();
}7. 注意字符串拼接操作的性能
对于单行输出,或者构建一个小型的、大小固定的对象的字符串表示,字符串拼接都非常合适,但对于规模更大的场景,其就不合适了。
重复使用字符串拼接运算符来拼接n个字符串,需要的时间是n的平方级的:这是由‘字符串是不可变'的这一事实所导致的后果, 当两个字符串被拼接在一起时,它们的内容都会被复制。
为了达到字符串拼接可以接受的性能,应该使用StringBuilder(线性时间)代替String进行拼接。
除非性能不重要,否则不要使用字符串拼接运算符来组合多个字符串,应该使用StringBuilder的append方法来代替,或者使用字符数组,或者逐个处理每个字符串,而不是将其组合在一起。
8. 通过接口来引用对象
如果存在适合的接口类型,那么参数、返回值、变量和字段都应该使用接口类型来声明:唯一真正需要对象的类的时候,是使用构造器创建这个对象时。
使用接口作为类型,程序将变得更为灵活:如果决定更换实现,所要做的就是改变构造器中的类名(或者使用不同的静态工厂)。要注意,如果原来的实现提供了接口的通用的约定之外的某个特殊功能,并且代码依赖于这一功能,那么新实现也要提供同样的功能。更改实现类型,可能是第二个类更优秀,在性能和功能上。
使用其实现类型声明变量,可以同时改变声明类型和实现类型,但可能会导致程序无法编译:因为客户端代码可能使用了原来的实现上有,但新实现上没有的方法,或者客户端将该实例传给了一个要求原来的实现类型的方法。
若没有适合的接口类型,使用类而不是接口来引用对象也是可以的,就用类层次结构中最不具体的类来提供所需的功能:
第一种情况:值类,如String何BigInteger,值类很少会提供多个实现,他们通常是final的,并且大部分情况下没有相应的接口,使用这样的值类作为参数、变量、字段或返回类型是完全合适的。
第二种情况:对象属于其基本类型是类而不是接口这样的基于类的框架,那么最好使用相关的基类(通常是抽象类)来引用它,而不是使用其实现类。
第三种情况:类实现了一个接口,但还提供了接口中没有的方法。
9. 与反射相比,首选接口
Java的核心反射机制(java.lang.reflect包)提供了以可编程方式使用任意类的能力, 可以在运行时动态地操作类:给定一个Class 对象,可以获得构造器、方法和属性实例。
反射所操作的类必须是已经存在且具有定义的类:反射机制依赖于类的字节码文件和类加载器加载类到JVM中。因此,在使用反射时,需要确保目标类在运行时是可访问的。
反射允许一个类使用另一个类,即使在编译前一个类时后一个类尚不存在,但是这种能力需要付出以下代价:将失去编译时类型检查的所有好处;执行反射所需要的代码既笨拙又繁琐;影响性能。
可以仅以非常有限的形式使用反射,既获得反射的好处,又限制其开销:有很多程序,它们必须使用某个类,但这个类在编译时无法获得,不过在编译时存在适合的接口或超类来引用这个类的实例,若是这种情况,可以通过反射方式创建实例,并通过其接口或超类正常使用它们。
反射还可以管理一个类对在运行时可能不存在的其他类、方法或字段的依赖。
/**
* 下面程序要创建一个Set<String>实例,
* 但它的类是由第一个命令行参数所决定的
* <p>
* 创建完实例后,程序会将剩余的命令行参数插入到这个实例中,并打印它。
* 无论第一个参数是什么,程序都会在消除重复项后打印剩余的参数。
* <p>
* 但这些参数的打印顺序,取决于第一个参数中指定的类,若指定的是HashSet
* 他们将以看上去随机的顺序打印,若指定的是TreeSet,他们将按字母表顺序打印。
*/
public class Main
{
//以反射方式实例化,通过接口使用
public static void main(String[] args) throws Exception
{/**
若直接使用类构造器,但是就不知道使用哪个类(new 哪个类,哪怕知道其是一个Set)
因为其由运行时传递的参数确定的
**/
//将类名转换为Class对象
Class<? extends Set<String>> cl = (Class<? extends Set<String>>) Class.forName(args[0]);
//获得构造器
Constructor<? extends Set<String>> cons = cl.getConstructor();
//实例化这个Set
Set<String> s = cons.newInstance();
//使用这个Set
s.addAll(Arrays.asList(args).subList(1, args.length));
System.out.println(s);
}
}10. 谨慎使用本地方法
Java本地接口(JNI)允许java程序调用本地方法,也就是使用C或C++等本地编程语言编写的方法:本地方法主要有3个用途:它们提供了对平台特定功能的访问,如Windows注册表;还提供了对现有的本地代码库的访问,包括用于访问遗留数据的遗留库;还可以用于以本地语言编写应用程序性能关键部分,以提高性能。
使用本地方法访问平台特定功能是合理的,但很多时候不必要:随着java平台的成熟,很多以前在宿主平台上才有的特性,java可以直接使用了。
通常不建议使用本地方法来提高性能:对于大多数任务,现在用Java已经有可能获得与之相当的性能。
使用本地方法有严重弊端:因为本地语言不是安全的,使用本地方法的程序可能受内存损坏错误的影响。且与java相比,本地语言更依赖平台,所以使用本地方法的程序可移植性会查,调试也更困难。本地方法可能会降低性能,因为垃圾收集器无法自动化甚至跟踪本地内存的使用,且进入和退出本地代码也有开销。最后本地方法需要一些胶水代码,而且这些代码很难阅读,编写也很繁琐。
11. 谨慎进行优化
优化很容易得不偿失,特别是当过早的进行优化时,在此过程,可能会开发出既不快速也不正确的软件,还不容易修复。
不要为了性能而牺牲合理的架构原则,努力编写好的程序,而不是快的程序:如果好的程序不够快,它的架构会支持优化。实现上的问题可以后续解决,但是架构问题影响性能无法解决。
要努力避免会限制性能的设计决策:系统完成后,设计中最难改变的组件是那些用来指定组件和外部世界的交互关系的。
要考虑API设计决策的的性能后果:设计一个可变的公有类,可能需要大量不必要的保护性复制;若在适合使用组合的公有类中使用了继承,这个类就永远和其超类绑定,有可能人为的限制子类性能;在API中使用实现类而不是接口,会将我们与某个特定时限绑定在一起,即使将来出现更好的实现,我们也无法改变。
不要为了实现良好的性能而改变API:导致改变API的那些性能问题,可能在将来版本不存在了,但是修改后的API和随之而来的问题一直存在。
在每次尝试优化之前和之后,都要对性能进行测量。
12. 遵循普遍接受的命名惯例
①排版命名惯例
包和模块的名称应该是层次式的:各组件之间用句点分隔。组件应该由小写字母组成,极少数情况下可以使用数字。对于任何会在其开发者所在的组织外部使用的包,其名称应该以该组织的互联网域名开头,而且域名中各个部分的顺序要反过来。例如com.google。标准类库和可选包除外,他们的名字以java和javax开头。用户不得创建名字以java和javax开头的包或模块。
包名的其余部分应该由一个或多个描述该包的组件组成:组件应该比较简单,通常不超过8个字符。鼓励使用有意义的缩写,例如,使用util而不是utilities。也可以接受首字母缩写,如awt。组件通常应该由一个单词或缩写组成。
类和接口的名称,包括枚举和注解:应该由一个或多个单词组成,每个单词的首字母大写。
方法和字段:遵守和类和接口相同的惯例,不过首字母要小写。例外是常量字段,其名称应该由一个或多个大写的单词组成,单词之间以下划线分割。常量字段是值不可变的静态final字段。若一个静态final字段的类型是基本类型或不可变的引用类型,那么它就是常量字段。例如:枚举常量是常量字段。如果一个静态final字段的类型是可变的引用类型,如果所引用的对象是不可变的,它仍然可以是常量字段。
局部变量:与成员名称类似,只是允许使用缩写。
类型参数:其名称通常使用单个字母。T表示任意类型,E表示集合的元素类型,K和V表示Map的键和值的类型,X表示异常。函数的返回类型通常用R表示。要同时表示一些列的某个类型,可以使用T、U、V或T1、T2、T3。
②语法命名惯例
包:无语法命名惯例。
可实例化的类(包括枚举):通常用单数名称或名词性短语命名,如Thread。
不可实例化的工具类:用复数名词命名,例如:Collections。
接口:与类相似,如Collection。或使用以able或ible结尾的形容词,例如:Runnable、Accessible。
注解类型:使用场景多,无哪种词性占据主导。名词、动词、介词、形容词等都可以。
方法:
执行某个动作的方法通常用动词或动词性短语(包括动作所作用的对象)来命名,例如:append、drawImage。
返回boolean的方法名字通常以is开头,或不太常用的has开头,后跟名词、名词性短语或任何用作形容词的单词或短语,例如isDigit、isEnabled、hasSiblings。
返回被调用对象的非boolean类型的函数或属性的方法,通常用名称、名词性短语或以动词get开头的动词性短语命名,例如:size、getTime。
当类中包含用于同一属性的setter和getter方法上时,通常以getAttribute、setAttribute。
用于转换对象的类型并返回一个不同类型的独立对象的实例方法,通常命名为toType。例如:toString。
用于返回其类型与被调用对象不同的视图的方法,通常被命名为asType。例如,asList。
用于返回与被调用对象的值相同的基本类型值的方法,通常以typeValue命名。例如:intValue。
静态工厂方法的场景名称:from、of、valueOf、instance、getInstance、newInstance、getType、newType.
字段:没有那么多惯例,因为涉及良好的API极少架构字段暴露出去。
九. 异常
1. 异常机制应该仅用于异常的情况
异常应该仅用于异常的情况,不应该用于普通的控制流。
一个设计良好的API决对不应该迫使其客户端将异常用于普通的控制流。
基于异常的控制流的缺点:因为异常机制是为异常的情况设计的,所以JVM实现者没什么动力将其优化得像显式的条件测试一样快;将代码放在try-catch内,会抑制JVM实现某些可能的优化;遍历数组的标准习惯用法未必会导致多余检查,许多JVM会将其优化掉;可能会掩盖系统中不相关部分存在的故障。
/**
* 滥用异常的情况
*
* 很难读懂他是干什么的
* 性能问题
* 真实故障掩盖
*/
try
{
int i = 0;
while (true)//仅仅是遍历数组,越界则抛出异常
range[i++].climb();
} catch (ArrayIndexOutOfBoundsException e)
{
}2. 对于可恢复条件,使用检查型异常;对于编程错误,使用运行时异常
Java提供了3种可抛出实体:检查型异常、运行时异常和错误。
如果调用者有望从异常的情况中恢复过来,就使用检查型异常:相当于下达了任务,从该条件中恢复过来。
应该使用运行时异常指示编程错误:绝大多数运行时异常表明违反了前置条件,一般指API的使用者没有遵循该API所说明的约定。运行时异常和错误不需要捕获,而且通常也不应该捕获,表明继续执行会弊大于利,若没有捕获会导致当前线程显示适当的错误消息并终止。
错误是被保留给JVM使用的,用以表示资源不足、不变式被破坏或其他导致执行无法继续的异常条件:最好不要实现任何新的Error子类。除了AssertionError外,也不应该抛出他们。
实现的所有非检查型异常都应该是RuntimeException的子类(直接或间接的)。
异常类应该提供帮助恢复的方法:比如余额不足,抛出一个检查型异常,这个异常应该提供一个访问器方法,以便用户查询所缺的数额,这样调用者可以把数额信息传给用户。
3. 避免不必要地使用检查型异常
检查型异常的问题:强制程序员去处理问题,提高可靠性;若方法抛出检查型异常,调用该方法必须多一个try catch块,或将其抛出去,这会给API的用户带来负担。在java8中,负担加重,因为抛出检查型异常的方法不能直接在流中使用。
适合检查型异常的场景:异常条件不能通过正确使用API来防止;一旦出现异常,使用这个API的程序员可以采取有用的动作。除非两个条件都满足,否则适合使用非检查型异常。
去掉检查型异常:可以返回所需结果类型的一个Optional实例,让方法不再抛出检查型异常,而是直接返回一个空的Optional。缺点在于关于因何不能执行所需的计算,该方式无法返回任何其他细节信息。
也可以将抛出异常的方法拆分为两个方法,从而将检查型异常变为非检查型异常,其中第一个方法返回一个boolean值,指示是否会抛出异常。
//存在检查型异常时的调用方式
try
{
obj.action(args);
} catch (TheCheckedException e)
{
//处理异常条件
}
//重构
//存在状态测试方法和非检查型异常时的调用方式
if(obj.actionPermitted(args))
obj.action(args);
else 处理异常条件4. 优先使用标准异常
使用标准异常的优点:使我们的API更容易学习和使用,因为其符合程序员已经熟悉的既定惯例;使用我们API的程序更容易阅读,因为没有混杂不常见的异常;异常类越少,则内存占用越少,加载类所需要的时间越少。
不要直接复用Exception、RuntimeException、Throwable或Error:将其当成抽象类即可,无法可靠的检测这些异常类型,因为它们是方法可能抛出的其他异常的超类。
如果任何参数值都不可以,则抛出IllegalStateException,否则抛出IllegalArgumentException:选择复用哪个异常,可能很难,因为‘场合’看上去并不是互斥的。比如考虑一副扑克牌对象,假设其有个负责发牌的方法,该方法接受一个参数handSize,表示要发几张牌。若调用者传入的值大于牌堆中剩余的张数,可以被解释为非法参数异常(handSize值过大),也可以被解释为非法状态异常(牌堆中牌数过少)。
按理说每个错误的方法调用都可归结为非法的参数或状态,但是还有适用于特定场景的异常(空指针等)。
5. 抛出适合于当前抽象的异常
异常转译:上层应该捕获底层的异常,并在捕获的位置上抛出可以用上层抽象来解释的异常(解决方案):如果方法抛出的异常和它所执行的任务没有明显的联系,就会让人感到困惑。当方法将底层抽象抛出的异常传播出来时,往往会出现这个情况。不仅让人感到困惑,而且使上层的API被实现细节污染了。如果上层实现在后续版本发生了变化,它所抛出的异常也可能变化,也就有可能破坏现有的客户端程序。
异常链:特殊形式的异常转译。用于这样的情况:底层的异常对于调试导致上层异常的问题有所帮助。这时候底层异常(即cause)被传递给上层异常,而上层异常会提供一个获取这个底层异常的访问器方法(Throwable的getCause方法)。
尽管与盲目的将异常传播到上层相比,异常转译方式更好,但也不能过度使用:在可能情况下,处理来自底层的异常的最佳方式是,确保底层方法成功,避免异常,有时可以在将上层方法的参数传递给底层方法之前,先检查其有效性。如果无法阻止来自底层的异常,次优选择就是让上层默默处理这些异常,将上层方法的调用者与底层问题隔离。在此,可以使用适当的日志工具将异常记录下来,这样可以帮助程序员调查问题,同时将客户端代码和其用户隔离。
如果无法防止或处理来此底层的异常,除非底层方法所抛出的异常恰好适合于上层抽象,否则应该使用异常转译。异常链提供了两全其美的方法:它允许抛出一个适合于上层的异常,同时又能获得底层的cause进行失败的原因。
//异常转译
public static void main(String[] args)
{
//异常转译
try
{
//使用底层抽象来完成工作
} catch (LowerLevelException e)
{
throw new HigherLevelException(...)
}
}
//示例
public E get(int index)
{
ListIterator<E> i = listIterator(index);
try
{
return i.next();
} catch (NoSuchElementException e)
{
throw new IndexOutOfBoundsException(index);
}
}异常链
//带有支持异常链的构造器的异常
/**
* 大多数标准异常都有支持异常链的构造器
* 对于没有这种构造器的异常,可以使用Throwable的
* initCause方法来设置cause。异常链不仅支持通过
* getCause方法在程序中访问cause,还将cause的
* 栈轨迹信息整合到了上层异常的栈轨迹信息中
*/
class HigherLevelException extends Exception
{
HigherLevelException(Throwable cause)
{
super(cause);
}
}
public class Main
{
public static void main(String[] args)
{
//异常链
try
{
//使用底层抽象完成工作
} catch (LowerLevelException cause)
{
throw new HigherLevelException(cause);
}
}
}6. 将每个方法抛出的所有异常都写在文档中
应该总是单独声明检查型异常,并使用@throws标签将每个异常抛出的条件准确的写在文档中:若一个方法可能抛出多个异常,不要用这些异常的超类来声明。
尽管Java并不要求程序员声明可能抛出的非检查型异常,但将他们像检查异常详细的写在文档中是明智的:非检查型异常是编程错误,将其写在文档,有助于使用方法。这些异常实际上是方法执行成功的前置条件。
使用Javadoc的@throws标签将方法可能抛出的每个异常记录在文档中,但不要将throws关键字用于非检查型异常:重要的是让使用API的程序员知道哪些是检查型异常,哪些是非检查型异常,因为两种情况下程序员的职责不同。
如果类中的多个方法会因为同样的原因抛出某个异常,可以将这个异常写在累计文档注释中,而不是每个方法单独写一次。
7. 将故障记录信息包含在详细信息中
当程序由于未被捕获的异常而失败时,系统会自动打印该异常的栈轨迹信息。栈轨迹信息包含该异常的字符串表示,即调用toString方法的结果,通常他由异常的类名后跟其详细消息组成。异常的详细信息应该记录故障信息,以供后续分析。
为了记录故障信息,异常的详细信息应该包含导致该异常的所有参数和字段的值:例如,越界异常的详细信息应该包含下界、上界以及未能落在二者之间的索引值。但是没必要再其中包含大量的描述信息。
不要将密码、密钥以及类似的信息包含在详细信息中。
不要将异常的详细消息与用户级的错误消息弄混,后者必须能够被最终用户理解,前者主要给工程师在分析故障时使用。
确保异常的详细信息包含足够的故障记录信息的一种方式:在构造器中要求提供这些具体消息,而不是要求提供字符串形式的消息,然后可以自动生成包含这些信息的详细消息。
class IndexOutOfBoundsException extends Exception
{
private final int lowerBound;
private final int upperBound;
private final int index;
public IndexOutOfBoundsException(int lowerBound, int upperBound, int index)
{
//生成了记录了故障的详细信息
super(String.format("Lower bound: %d, Upper bound: %d, Index: %d", lowerBound, upperBound, index));
//以可编程方式保存
this.lowerBound = lowerBound;
this.upperBound = upperBound;
this.index = index;
}
}8. 努力保持故障的原子性
故障原子性:失败的方法调用应该让对象保持调用前的状态,我们称有这种属性的方法是具备故障原子性的。
实现故障原子性的方式:
第一种:设计不可变对象:若对象时不可变的,自然就具备了。
第二种:对于可变对象,在执行操作前检查参数的有效性:这样大多数异常会在开始修改对象之前被抛出。有一种类似的实现故障原子性的方式,就是对计算进行排序,使得任何可能会失败的部分都在任何会修改对象的部分之前发生。这是上面的方式在不执行部分计算就无法对参数进行检查的情况下的一种自然延伸。例如,考虑TreeMap的情况,其元素会按某种顺序排序。为了向TreeMap添加一个元,该元素必须是可以使用TreepMap的排序进行比较的类型。尝试添加错误类型的元素将在查找树中的元素时自然失败,并抛出异常,这时树还没以任何方式进行修改。
第三种方式:在对象的临时副本上执行操作,并在操作完成后用临时副本替换该对象的内容:当数据一旦存储在某个临时数据结构中,计算可以更快的执行时,使用这种方式是自然而然的。例如,某些排序函数在排序前会将输入列表复制到一个数组中,以减少在排序内部循环中访问元素的开销。这么做不仅提高性能,且排序失败了,输入的列表不变。
第四种方式:编写恢复代码:拦截在操作过程中发生的故障,并让对象回滚到操作开始之前的状态。这种方法主要用于持久性的(基于磁盘的)数据结构。
故障原子性是理想目标,但有时难以实现:例如,两个线程在没有适当同步的情况下尝试并发修改同一个对象,该对象可能处于不一致的状态。
即使可以做到故障原子性,但未必总可取:对于某些操作,要保持故障原子性,会显著增加开销和复杂性。即使如此,一旦意识到这个问题,通常可以非常容易且没什么成本的实现故障原子性。
9. 不要忽略异常(检查和非检查型)
忽略异常:用try将方法调用包起来,catch语句留空。
异常是强制处理异常条件的,空的catch块违背了异常的本意。
有些情况可以忽略异常:当关闭FileInputStream时,我们没有改变文件的状态,所以没有必要执行任何恢复动作,而且我们已经从文件读取了所需的信息,也没有理由中止正在执行的操作。明智的选择是将该异常记录在日志中,这样如果这些异常经常发生,可以调查此事。
如果选择忽略一个异常,catch块应该包含一条注释,解释为什么这样做是合适的,而且异常变量应该被命名为ignored。
Future<Integer> f=exec.submit(planarMap::chromaticNumber);
int numColors=4;//默认值,确保任何地图都有足够颜色
try
{
numColors=f.get(1L, TimeUnit.SECONDS);
} catch (TimeoutException | ExecutionException ignored)
{
//使用默认值:最少的颜色数量是可以接受的,但不强制要求
}十. 并发
1. 同步对共享可变数据的访问
①对读取都是原子的变量不同步的问题
同步不仅可以防止线程观察到对象处于不一致的状态,还可以确保每个进入同步方法或代码块的每个线程,都能看到由同一个锁保护前面所有修改的效果。
除非读写操作都被同步,否则无法保证同步的有效性:有时仅对写(或读)进行同步的程序可能在某些机器上看起来可以工作,不要被表象所蒙蔽。
除非变量是long或double类型的,否则Java语言规范保证对变量的读取和写入都是原子的:即读取除long或double类型之外的变量,可以保证返回由某个线程存储到该变量中的值,即使有多个线程在没有同步的情况下并发的修改该变量,也是如此。a=10, return a是原子的。a=compute()、a=b不是原子的。
可靠的线程间通信和互斥都需要同步:虽然语言规范保证线程在读取字段时不会看到一个随机值,但它并不保证一个线程可以看到另一个线程写入的值。如果没有同步对共享可变数据的访问,即使这个数据的读写操作都是原子的,也可能产生可怕的后果。
//存在问题--你认为这个程序能运行多久?
public class Main
{
private static boolean stopRequested;//对其读写都是原子的
public static void main(String[] args) throws Exception
{
/**
* 你可能会认为这个程序会运行大约1s,之后主线程将stopRequested设置为true,
* 导致后台线程循环终止。但是程序不会终止:后台线程会一直运行下去。
*/
Thread backgroundThread = new Thread(
() ->
{
int i = 0;
while (!stopRequested) i++;
}
);
backgroundThread.start();
Thread.sleep(1000);//睡眠1s
stopRequested = true;
/**
* 问题在于,在没有同步的情况下,后台线程能不能看到主线程对stopRequested值
* 的修改,如果能看到,那在什么时候可以看到,都是无法保证的。在没有同步的情况
* 下,虚拟机完全可以将下面的代码
*
* while(!stopRequested) i++;
* //转换为:
* if(!stopRequested)
* while(true)
* i++;
*
* 这种叫做优化提升,结果是活性失败。
* 解决这个问题的一种方式是同步对stopRequested字段的访问
*/
}
}②同步对stopRequested字段的访问
这里对读写都进行了同步,否则无法保证同步的有效性。
就StopThread中的两个被同步的方法而言,即使没有同步,它们执行的动作也是原子的。即,这些方法上的同步仅起到通信的作用,而不是互斥。
//通过同步让合作线程正确终止
public class Main
{
private static boolean stopRequested;//对其读写都是原子的
private static synchronized void requestStop()
{
stopRequested = true;
}
private static synchronized boolean stopRequested()
{
return stopRequested;
}
public static void main(String[] args) throws Exception
{
Thread backgroundThread = new Thread(
() ->
{
int i = 0;
while (!stopRequested()) i++;
}
);
backgroundThread.start();
Thread.sleep(1000);//睡眠1s
requestStop();
}
}③使用volatile
虽然上述同步开销并不大,但还有一种性能更好更简洁的方式,使用volatile声明stopRequested,尽管volatile修饰符不执行互斥,但他保证任何读取该字段的线程都将看到最近写入的值。
public class Main
{
private static volatile boolean stopRequested;//对其读写都是原子的
public static void main(String[] args) throws Exception
{
Thread backgroundThread = new Thread(
() ->
{
int i = 0;
while (!stopRequested) i++;
}
);
backgroundThread.start();
Thread.sleep(1000);//睡眠1s
stopRequested = true;
}
/**
* 使用volatile时,多加小心
* 存在问题--需要同步
*
* 这个方法的目的确保每次调用都返回一个唯一的值。
* 这个方法的状态由一个可原子性访问的字段nextSerialNumber
* 组成,该字段所有可能值都是合法的,因此不需要同步保护其不变式
* 然后,没有同步,这个方法就无法工作。
*
* 问题在于,自增运算符++不是原子的,他会在nextSerialNumber字段上执行
* 两个操作:首先读取该字段的值,然后将旧值加1作为新值写回该字段。如果
* 在一个线程读取旧值和写回新值的过程中间,第二个线程读取了这个字段,那么它看到
* 的就是和第一个线程相同的值,于是就返回了同样的序列号。
*
* 修复的一种方式是在其声明中加上synchronized修饰符,然后可以去掉volatile
* 为了是方法更为健壮,可以使用long代替int,或在其即将溢出时抛出异常。
*
* 更好的方式是使用AtomicLong类
*/
private static volatile int nextSerialNumber = 0;
public static int generateSerialNumber()
{
return nextSerialNumber++;
}
}④使用AtomicLong类
java.util.concurrent.atomic包提供了用于在单个变量上进行无锁、线程安全编程的原语。volatile仅提供同步的通信效果,与之对比,该包还提供了原子性,且其比使用synchronized的版本性能更好。
private static final AtomicLong nextSerialNumber = new AtomicLong();
public static long generateSerialNumber()
{
return nextSerialNumber.getAndIncrement();
}⑤总结
将可变数据限制再单个线程内:要避免本条目所讨论的问题,最好的方式是不共享可变数据,要么共享不可变数据。如果此案有这种方式,一定要将其写在文档,以便该策略不会随着程序的演进而变化。还要了解正在使用的框架和类库,因为他们可能会引入我们不知道的线程。
当多个线程共享可变数据时,每个读取或写入这些数据的线程都必须执行同步。
2. 避免过度同步
根据情况的不同,过度的同步可能导致性能下降、死锁甚至不确定行为。
①同步区域调用外来方法的问题
为了避免活性失败和安全性失败,在同步的方法或代码块内,绝对不要将控制权交给客户端:即,在同步区域内,不要调用可以被重写的方法,也不要调用客户端以函数对象形式(匿名类、Lmabda等)提供的方法。从包含这个同步区域的类的角度看,这样的方法是外来的,这个类不知道这样的方法会做什么,也无法控制他。根据外来方法的具体操作,从同步区域调用它可能会引发异常、死锁或数据损坏。
通常,在同步区域做的工作应该尽可能少:获取锁,检查共享数据,必要时对其进行转换,然后释放该锁。如果必须执行某个非常耗时的活动,在不违反上节的准则的情况下,应该想办法将其移出同步区域。






②性能问题
到现在为止,同步的开销已经大幅降低,但仍不要过度同步。在多核时代,过度同步的真正开销不是获取锁所消耗的CPU时间,而是争用:失去并行的集合,以及为了确保每个核心对内存具有一致的视图而引入的延迟。另一个潜在开销是,它可能会限制虚拟机优化代码执行的能力。
编写一个可变类,同步的两种选择:第一是省略所有的同步操作,如果需要并发使用,客户端可以在外部进行同步;或者在内部进行同步,使这个类称为线程安全的。若与让客户端在外部同步相比,通过内部同步可以获得高得多的性能,这样才选择内部同步。如果拿不定注意,就不要对自己的类进行同步,但要在线程中写清楚他不是线程安全的。
如果方法修改了一个静态字段,并且这个方法有可能被多个线程调用,那么必须在内部同步对这个字段的访问:对于这样的方法,客户端无法对其进行外部同步,因为其他无关的客户端仍然可以在没有同步的情况下调用该方法。
3. 与线程相比,首选执行器、任务和流
可以利用执行器(ExecutorService)做很多事情:可以等待某个特定任务完成(如上节代码中的get方法);可以等待任务集合中的任何一个或所有任务完成(invokeAny或invokeAll方法);可以等待执行器服务终止(awaitTermination);可以在任务完成后逐一检索其结果(使用ExecutorCompletionService);还可以调度任务,使其在特定时间运行或定期运行(使用SheduledThreadPoolExectur)等等。
若想让多个线程处理队列中的请求,只需调用不同的静态工厂,创建一个叫做线程池的执行器服务:java.util.concurrent.Executors类中包含的静态工厂,可以提供我们所需要的大多数执行器。若需要一些特殊的功能,那么可以直接使用ThreadPoolExecutor类,利用这个类,可以配置线程池操作的几乎每个方面。
选择合适的执行器服务:对于小型程序或负载较轻的服务器,Executors.newCachedThreadPool(缓存线程池)是不错的选择,因为其不需要配置,而且一般会做正确的事情;对于负载较重的生产服务器来说缓存线程池不好,在缓存线程池中,被提交的任务不会排队,而是立即交给一个线程执行,若没有线程可调用,就会创建新的线程。若服务器的负载较重,所有CPU会处于忙碌,但随着更多任务到达,缓存线程池会创建更多线程,只会使情况更糟。因此在负载较重的服务器上,最好使用Executors.newFixedThreadPool, 它会返回一个线程数固定的线程池,或直接使用ThreadPoolExecutor类,以获得最大程度的控制权。
不仅应该避免编写自己的工作队列,而且通常应该避免直接使用线程:在直接使用线程时,Thread既是工作单元,又是执行机制。而在执行器框架中,工作单元和执行机制是分开的。关键抽象是工作单元,即任务。任务有两种类型:Runnable和其近亲Callable。执行任务的一般机制是执行器服务。如果以任务的方式思考,并让执行器服务来执行这些任务,就可以灵活的选择自己需求的执行策略,并在需求改变时更改策略。
在Java7中,执行器框架的到了扩展,以支持fork-join任务,这些任务由一个叫做ForkJoinPool的特殊执行器服务来运行:fork-join任务由ForkJoinTask实例表示可以被分解为更小的子任务,而组成ForkJoinPool的线程不仅会处理这些任务,还会互相窃取任务,以保证所有线程保持忙碌,从而提高CPU利用率、吞吐量并降低延迟。编写和调优fork-join任务非常棘手。并行流是在ForkJoinPool之上构建的,并且允许我们轻松利用其性能优势,前提是它适合我们手头的任务。
4. 与wait和notify相比,首选高级并发工具
鉴于正确使用wait和notify的困难,我们应该使用更高级的并发工具。
java.util.concurrent中的高级工具可以分为3类:执行器框架、并发集合以及同步器。本节主要介绍后两者。
①并发集合
不可能将并发活动排除在并发集合之外;对这样的集合进行锁定只会降低程序的运行速度:因为并发集合是标准集合(List、Queue、Map)的高性能并发实现,为了提供高并发性,这些实现会在内部管理自己的同步。又因为无法将并发活动排除在并发集合之外,所以也无法对他们之上的方法调用进行原子化的组合。因此,并发集合接口配备了状态依赖的修改操作,可以将几个原语组合成一个原子操作。事实证明,这些操作非常有用,以至于他们在java8中作为默认方法被添加到了相应的集合接口中。
并发集合使得同步集合几乎被淘汰:例如,应该优先使用ConcurrentHashMap而不是Collections.synchronizedMap。仅仅将同步映射替换为并发映射,就可以极大提高并发应用程序的性能。
有些集合接口还进行了扩展,以支持阻塞操作,这样的操作会一直等待(或阻塞),直到操作执行成功:例如,BlockingQueue扩展了Queue接口,并添加了几个方法,包括take方法,他会从队列中删除并返回头元素,如果队列为空则等待。这使得阻塞队列可以用作工作队列(生产者-消费者队列),其中一个或多个生产者线程可以将工作项放入队列中,一个或多个消费者线程可以从队列中获取并处理可用的项。大多数ExecutorService实现,包括ThreadPoolExecutor,都使用了一个BlockingQueue。
②同步器
同步器:是使线程能够等待另一个线程的对象,从而使他们能够协调彼此的活动。最常用的同步器是CountDownLatch和Semaphore,不常用的有CyclicBarrier和Exchanger。最强大的同步器是Phaser。CountDownLatch是一次性的屏障,允许一个或多个线程等待另外的一个或多个线程来完成某个操作。CountDownLatch的唯一构造器接收一个int参数,表示在允许所有等待的线程继续执行之前,必须调用countDown方法的次数。
对于需要计算时间间隔的场合,应该总是使用System.nanoTime,而不是System.currentTimeMills:System.nanoTime更准确、更精确,而且不受系统实时时钟调整的影响。此外,除非action执行了相当多的工作(>=1s),否则下面的计时代码不会太准确。
下面的代码中的3个CountDownLatch, 可以用一个CyclicBarrier或Phaser实例来替代,这样代码可能更简洁。
/**
* 用于对并发执行进行计时的简单框架
*
* ready.countDown()用于让工作线程告诉计时器,它们已经准备就绪。
* 然后工作线程会在start.await()这里等待。当最后一个工作线程调用
* 了ready.countDown(),计时器开始记录时间并调用start.countDown()
* 允许所有工作线程继续执行。然后计时器线程在done.await();这里等待
* 直到所有工作线程都调用了done.countDown()。
*
* 传递给time方法的执行器必须允许创建至少与给定的并发级别一样多个线程,
* 否则测试永远无法完成,这叫线程饥饿死锁。
*
* 如果工作线程捕获到InterruptedException,它会使用Thread.currentThread().interrupt()
* 这个习惯用法来重置中断状态,从而使其从run()方法返回
*/
public static long time(Executor executor, int concurrency, Runnable action)
throws InterruptedException
{
CountDownLatch ready = new CountDownLatch(concurrency);
CountDownLatch start = new CountDownLatch(1);
CountDownLatch done = new CountDownLatch(concurrency);
for (int i = 0; i < concurrency; i++)
{
executor.execute(() ->
{
ready.countDown();//告诉计时器,准备就绪
try
{
start.await();//等待其他选手准备就绪
action.run();//具体工作
} catch (InterruptedException e)
{
Thread.currentThread().interrupt();
} finally
{
done.countDown();//告诉计时器执行完毕
}
});
}
ready.await();//等待所有工作线程准备就绪
long startNanos = System.nanoTime();
start.countDown();//开始计时
done.await();//等待所有工作线程执行结束
return System.nanoTime() - startNanos;
}③维护历史遗留代码
在新代码中很少或根本没有理由使用wait或notify,若使用了,请使用wait方法的标准习惯用法:尽管与wait和notify相比,应该总是优先使用高级并发工具,但我们不得不维护使用了wait和notify的遗留代码。wait方法用于让线程等待某个条件。它必须在锁住了该方法所在对象的同步区域内调用。
应该总是使用wait循环习惯用法来调用wait方法;永远不要在循环外部调用它:这个循环用来测试等待前后的条件。
在等待之前对条件进行测试,并且如果条件成立的话就跳过等待,这对于确保活性是必要的。如果在线程开始等待前,条件已经成立,而且notify(或notifyAll)方法也被调用了,这是不能保证线程会从等待中醒来的(这是因为在并发环境中,线程的调度和执行顺序是不确定的,而
wait和notify/notifyAll的配合使用必须遵循严格的顺序。如果线程在调用wait之前,条件已经成立,且notify/notifyAll已经调用,那么线程可能会错过通知)。在等待之后对条件进行测试,并且如果条件不成立的话就继续等待,这对于确保安全性是必要的。如果线程在条件不成立时继续执行相关动作,可能会破坏由这个锁保护的不变式。
线程可能会在条件不成立时被唤醒的原因有以下几个:
在一个线程调用notify和等待的线程被唤醒之间,另一个线程可能获得了这个锁并改变了被保护的状态。
另一个线程可能在条件不成立时意外或恶意调用了notify。如果是在可以公开访问的对象上等待,类有可能将自己暴露给这种恶意行为。在这样的对象的同步方法中的任何wait调用,都容易受到这个问题的影响。
通知线程在唤醒等待的线程时,可能过于‘慷慨’了。例如,通知线程可能会调用notifyAll,即使只有部分等待的线程的条件得到了满足。
等待的线程可能会在没有收到通知的情况下被唤醒,不过这样的情况非常少见。这被称为虚假唤醒。
使用notify还是notifyAll来唤醒线程:
notify会唤醒一个等待的线程,假设这样的线程存在,而notifyAll会唤醒所有等待的线程。有时候人们说应该总是用notifyAll,这是合理且保守的建议。它总能产生正确的结果,因为它保证会唤醒需要被唤醒的线程。当然也会唤醒其他一些线程,但不会影响程序正确性,这些线程会检查他们等待的条件,如果发现条件不成立,会继续等待。
作为一种优化,如果处于等待集合中的所有线程都在等待同一个条件,并且如果条件成立,每次都只有一个线程可以被唤醒,这时可以选择调用notify,而不是notifyAll。
即使这些前提条件都满足,也可能有理由使用notifyAll。就像将wait调用放在循环中来防止可以公开访问的对象上的意外或恶意的通知一样,使用notifyAll而不是notify,可以防止无关线程上的意外或恶意的等待。这样的等待可能会吃掉某个关键通知,使目标接收对象处于无期限的等待之中。
5. 将线程安全性写在文档中
方法声明中的synchronized修饰符属于实现细节,而不是其API的一部分,利用有没有synchronized修饰符来判断方法是否是线程安全的并不可靠。
①线程安全级别
为了实现安全的并发使用,一个类必须在文档中清除的说明它支持哪个级别的线程安全性(线程安全不是要么有,要么就没有,下面总结了常见的线程安全级别):
下面分类无条件的线程安全和有条件的线程安全都涵盖在ThreadSafe中。
不可变的(immutable):该类的实例表现为不可变的,不需要在外部使用同步操作。比如String、Long和BigInteger。
无条件的线程安全(unconditionally thread-safe):该类的实例是可变的,但是类提供了足够的内部同步,使得其实例可以在不需要任何外部同步的情况下并发使用。例如AtomicLong和ConcurrentHashMap。
有条件的线程安全(conditionally thread-safe):与无条件的线程安全类似,但是有些方法需要外部同步才能安全的并发使用。例如Collections.synchronized返回的集合,其迭代器需要外部同步。
非线程安全(not thread-safe):该类的实例是可变的。要并发使用,客户端必须使用自己选择的外部同步来包围每个方法调用(或调用序列)。例如通用集合实现ArrayList和HashMap等。
线程不利的(thread-hostile):即使每个方法调用都被外部同步所包围,该类也不能安全的并发使用。这种情况通常是在没有同步的情况下修改静态数据导致的。没有人会有意的编写线程不利的类;通常是因为没有考虑到并发性。如果发现一个类或方法是线程不利的,最好修复或废弃它。例如(十1中的generateSerialNumber为例,如果没有内部同步,这个方法就是线程不利的)。






②注意事项
对于有条件的线程安全类,编写文档时必须指明哪些调用序列需要外部同步,以及必须获取哪个锁(或在极少数情况下是哪些锁)来执行这些序列。通常会使用实例本身的锁,但也有例外。
对于类的线程安全性描述,通常应该放在该类的文档注释中,但具有特殊线程安全属性的方法应该在自己的文档注释中描述这些属性。没有必要在文档中描述枚举类型的不可变性。除非从返回类型中就能明显看出,否则静态工厂必须将所返回对象的线程安全性写在文档中。
当类承诺使用一个公开可访问的锁时,它使得客户端能够以原子方式执行一个方法调用序列(一直持有锁,在去调用方法),但这种灵活性是有代价的。它与高性能的内部并发控制并不兼容,比如ConcurrentHashMap等并发集合所使用的控制方式。此外,通过长期持有这个公开可访问的锁,客户端可以发起拒绝服务攻击。为了防止这种拒绝服务供给,可以使用私有锁对象来代替同步方法。因为私有锁对象在类外是不可访问的,所以客户端就不能干扰这个对象的同步。
锁字段应该始终被声明为final的:lock字段被声明为final的,这样可以防止因为不小心修改了其中的内容而造成的非同步访问。
私有锁对象习惯用法只能用在无条件的线程安全的类上:有条件的线程安全的类不能使用这种习惯用法,因为它们必须在文档中写清楚,客户端程序正在执行特定的方法调用序列时需要获取哪个锁。
私有锁对象习惯用法适合设计用于继承的类:如果这样的类使用自己的实例来加锁,子类很容易在无意中干扰了基类的操作,反之亦然。将同一个锁用于不同的目的,子类和基类可能会相互掣肘。
//私有锁对象习惯用法--防止拒绝服务攻击
private final Object lock = new Object();
public void foo()
{
synchronized (lock)
{
}
}6. 谨慎使用延迟初始化
本条目讨论的所有初始化技术,既适用于基本类型字段,又适用于对象引用字段。基本类型与0比较,引用类型与null比较。
①介绍
延迟初始化:是指将字段的初始化推迟到需要它的值时进行。如果永远不需要这个值,这个字段就永远不会被初始化。这种技术对于静态和实例字段都适合。虽然延迟初始化主要是一种优化手段,但它也可以用来打破类和实例初始化中的不良循环。
除非需要,否则不要使用延迟初始化:它降低了初始化类或创建实例的开销,但增加了访问这样的字段的开销。根据这些字段中最终需要进行初始化的比例、初始化他们的开销以及初始化后每个字段被访问的频率,延迟初始化甚至有可能(像很多优化一样)损害性能。
适用场景:对于类中的一个字段,如果只会在这个类的一部分实例上被访问,而且初始化的开销很大,那么延迟初始化可能是值得的。决定使用与否的唯一方式,是测量这个类在使用延迟初始化前后的性能。
在多线程情况下:如果有两个或多个线程共享一个延迟初始化字段,必须使用某种形式的同步,否则可能会导致严重的错误。本条目讨论的所有初始化技术都是线程安全的。
在大多数情况下,应该首选正常的初始化,而不是延迟初始化。
如果使用延迟初始化来打破初始化循环依赖,应该使用同步访问器方法:这是最简单、清晰的选择。
将这两种习惯用法(正常初始化和使用了同步访问器方法的延迟初始化)应用于静态字段时,只需在字段和访问器方法的声明上加上static修饰符,无需别的修改。
//正常初始化了一个实例字段
private final FieldType field = computeFieldValue();
//实例字段的延迟初始化--使用了同步访问器方法
private FiedlType field;
private synchronized FieldType getField()
{
if (field == null)
field = computeFieldValue();
return field;
}②延迟初始化Holder类
如果出于性能原因需要在静态字段上使用延迟初始化,应该使用延迟初始化Holder类习惯用法:这个习惯用法利用了类在用到的时候才会被初始化这一保证。
当getField第一次被调用时,它第一次读取FieldHolder.field,使得FieldHolder类被初始化。这个习惯用法的好处是getField方法没有被同步,而且只执行了一个字段访问操作,所以延迟初始化实际上没有增加任何访问开销。为了初始化这个类,典型的虚拟机会同步这个仅有的字段访问(原子)操作。一旦类被初始化,虚拟机就会对代码进行修补,这样后续对该字段的访问就不会涉及任何测试或同步了。

public class Main
{
//用于静态字段的延迟初始化Holder类习惯用法
private static class FieldHolder
{
static final FieldType field = computeFieldValue();
}
private static FieldType getField()
{
return FieldHolder.field;
}
}③双重检查
如果出于性能原因需要在实例字段上使用延迟初始化,应该使用双重检查习惯用法:如果在初始化后访问字段,这个习惯用法可以避免锁定的开销。其思路是,对字段值进行两次检查:第一次检查不锁定,如果字段看起来还没有被初始化,第二次检查会锁定。只有在第二次检查表明字段还没有被初始化时,这个调用才会初始化该字段。因为字段一旦被初始化了就不会再锁定,所以字段必须用volatile来声明。
为什么需要局部变量result:大部分情况下field是已经被初始化的,这个变量的作用就是确保该字段只被读取一次, 使用局部变量
result,可以减少对volatile字段的读取次数。因为volatile的读取操作相对昂贵。虽然并非严格需要,但这样可以提高性能,而且按照适用于底层并发编程的标准,这样更优雅。虽然也可以将双重检查用于静态字段,但是延迟初始化Holder类习惯用法是更好的选择。
public class Main
{
//用于延迟初始化实例字段的双重检查习惯用法
private volatile FieldType field;
private FieldType getField()
{
FieldType result = field;
if (result != null)//第一次检查,不锁定
return result;
synchronized (this)
{
if (field == null)//第二次检查,锁定
field = computeFieldValue();
return field;
}
}
}④单次检查
单次检查习惯用法:有时可能需要延迟初始化能容忍重复初始化的实例,可以省掉第二次检查。其仍是volatile来声明的。
在单次检查习惯用法中,如果不关心每个线程是否会重新计算字段的值,并且这个字段的类型是除了long或double以外的其他基本类型,则可以选择从字段声明中删除volatile修饰符。这一变体被称为激进的单次检查习惯用法。它在某些架构上可以加快字段访问速度,但增加了额外初始化(可能每个访问该字段的线程都会初始化一次,因为无volatile)。这是一种特殊技术,不适合日常使用。
public class Main
{
//用于延迟初始化实例字段的双重检查习惯用法
private volatile FieldType field;
private FieldType getField()
{
FieldType result = field;
if (result == null)//第一次检查,不锁定
field = result = computeFieldValue();
return result;
}
}7. 不要依赖线程调度器
任何依赖线程调度器来保证正确性或性能的程序都很可能是不可移植的:当有多个可运行线程时,由线程调度器决定哪些线程可以运行,以及运行多长时间。任何一个合理的OS都会尽量公平的做出决策,但是策略可能会有所不同,所以好的程序不应该依赖这种策略细节。
要编写出健壮、响应迅速、可移植的程序,最好的方法是确保可运行线程的平均数量不明显大于处理器数量:这样,线程调度器的选择余地很小:它只需运行这些可运行的线程,直到他们是不可运行的。即使在完全不同的线程调度策略下,程序的行为也不会有太大变化。
如果线程没有执行有用的工作,就不该运行:要将可运行线程的数量保持在较低水平,主要技术是让每个线程都执行一些有用的工作,然后等待更多工作。就执行器框架而言,这意味着适当设置线程池大小,并让任务短一些,但也不要太短,否则调度开销将影响性能。
线程不应该忙等:忙等就是反复检查一个共享对象(一般是循环检查条件,直到其成立),等其状态发生改变。除了使程序容易受到不可捉摸的线程调度器的影响之外,忙等还会大大增加处理器的负载,而这些处理器时间本可以供其他线程完成有用的工作。
有的多线程程序存在这样的问题:有些线程相对于其他线程无法获得足够的CPU时间,从而导致这个程序几乎无法正常工作。当面对这样的程序时,不要试图通过调用Thread.yield来‘修复’它。这样有可能勉强让程序正常工作,但这种方案是不可移植的,在一个JVM实现上可以提高性能的同样的yield调用,在第二个实现上可能会使性能变差,而在第三个实现上可能没有任何效果。Thread.yield没有可测试的语义。更好的做法是重新组织这个应用程序,减少可以并发运行的线程数量。
还有一个相关方法,就是调整线程优先级,类似的注意事项也适用。线程优先级是Java中可移植性最差的特性之一。通过调整一些线程优先级来优化应用程序的响应速度,也不是没有道理,但大部分情况下没有必要这么做,而且这么做也是不可移植的。通过调整线程的优先级来解决严重的活性问题,这是不合理的。在找到并修复根本原因前,这个问题可能会再次出现。
十一. 序列化
1. 优先选择其他序列化替代方案
序列化使得不需要付出多少努力,就可以实现分布式对象,尽管这种承诺很有吸引力,但代价是看不见的构造器以及API和实现之间的模糊界限,有可能导致正确性、性能、安全性和维护等方面的问题。
序列化的一个根本问题是:攻击面过于庞大而无法保护,而且攻击面还在不断增长:对象图是通过调用ObjectInputStream上的readObject方法进行反序列化的。这个方法本质上就是一个构造器,可以用来实例化类路径上的几乎任何类型的对象,只要这个类型实现了Serializable接口。在反序列化字节流的过程中,该方法可以执行来自这些类型的任何代码,因此所有这些类型的代码都属于攻击面。攻击面包括Java平台类库中的类、第三方类库中的类以及应用程序自己的类。即使遵循了所有相关的最佳实践,并成功编写出不易受到攻击的可序列化类,应用程序仍然可能存在漏洞。
gadget和gadget链:可序列化类中可能调用的、执行危险活动的方法就是gadget。gadget配合使用形成一个gadget链。在gadget链上,攻击者只要有机会提交精心设计的用于反序列化的字节流,就能在底层硬件上执行任意的本地代码。即使不使用任何gadget,只要反序列化一个需要很长的操作时间的短流,就可以发起一次拒绝服务攻击。
要避免利用序列化的漏洞进行的攻击,最好的办法就是永远不使用反序列化。
在编写的任何新系统中,都没有理由使用Java序列化:有其他机制可以实现对象和字节序列之间的转换,而且这些机制能够避免Java序列化的许多危险,同时提供了许多优势,诸如跨平台支持、高性能、庞大的工具生态系统和广大的专业技术社区。本书将这些机制称为跨平台结构化数据表示,虽然有人称之为序列化系统,但为了避免与java序列化混淆,本书不会采用这样的表达。这些表示有一个共同的特点,它们比Java序列化要简单的多,它们不支持任意对象图自动进行序列化和反序列化。相反,它们支持的是简单、结构化的数据对象,这些数据对象由一些‘属性-值’对组成。它们只支持一些基本类型和数据类型。事实证明,这种简单的抽象足以构建极其强大的分布式系统,并简单到足以避免Java序列化诞生以来一直困扰着它们的一些严重问题。
主要的跨平台结构数据表示包括JSON和Protocol Buffers(也叫protobuf):二者之间最明显的区别在于,JSON是基于文本的,人可以读懂,而protobuf是二进制的,效率更高;JSON仅仅是一种数据表示,而protobuf支持编写模式(类型),从而强制保证正确使用。尽管protobuf比JSON高效,但对于基于文本的表示而言,JSON是非常高效的。而且,虽然protobuf是一种二进制表示,但它还提供了一种备选的文本表示形式,用于需要人读懂的场景。
如果无法完全避免Java序列化,比如正面对一个用到了序列化机制的遗留系统,次佳的选择是永远不要反序列化不可信数据:特别是,永远不应该接受来源不可信的RMI通信。
如果无法避免序列化,并且对于所要反序化的数据的安全性,没有十足把握,那么可以使用在Java9中加入的对象反序列化过滤机制(java.io.ObjectInputFilter)(这个功能已经移植到更早的java版本中):该功能允许我们指定一个过滤器,在反序列化之前,在数据流上应用这个过滤器。它以类为粒度进行操作,允许我们接受或拒绝特定的类。如果列出的是存在风险的类,除此之外,其他类默认都可接受,这是黑名单;如果列出的是安全的类,除此之外,其他类默认都会拒绝,这叫白名单。应该优先选择白名单,而不是黑名单(因为黑名单只能预防已知的威胁)。序列化在Java生态系统中仍然广泛存在,若正在维护的是一个基于Java序列化的系统,应该认真考虑将其迁移到跨平台结构化数据表示,即使要付出大量的时间和精力。
2. 在实现Serializable接口时要特别谨慎
要支持一个类的实例可序列化,只需在其声明中加上implement Serializable,虽然让一个类可序列化的直接成本可以忽略不计,但为此付出的长期成本往往是巨大的。
实现Serializable接口所带来的一个主要成本是,它降低了在类发布之后修改其实现的灵活性:当一个类实现了Serializable接口时,它的字节流编码(或者说序列化形式)就成为其导出API的一部分。如果这个类被广泛应用的话,通常需要永远支持其序列化形式,就行需要支持其导出API的所有其他部分一样。如果不花费精力设计一个自定义的序列化形式,而只是接受默认的形式,那么这个序列化形式将永远与类的原始内部表示绑定在一起。即:如果介绍默认的序列化形式,这个类的私有的和包私有的实例字段都将称为其导出API的一部分,而最小化字段的可访问性做法,为信息隐藏所做的努力也就付诸东流了。
如果接受了默认的序列化形式,但后来又修改了类的内部表示,这会导致其序列化形式不再兼容:如果客户端程序在序列化时使用的是类的旧版本,但在反序列化时又使用了这个类的新版本,程序就会执行失败,反之亦然。使用ObjectOutputStream.putFields和ObjectInputStream.readFields,也可以做到在保持原始的序列化形式不变的同时修改类的内部表示,但实现起来可能会非常困难,而且会在源代码中留下明显的瑕疵。如果选择让类成为可序列化的,就应该仔细设计一个自己愿意长期面对的、高质量的序列化形式。这样会增加开发的初始成本,但这种付出是值得的。即使设计良好的序列化形式,也会限制类的演进,而设计不良的序列化形式,更是有可能造成严重后果。
序列化的演进:流唯一标识符(序列化版本号):每个可序列化类都有一个与之关联的唯一标识号。如果我们没有通过声明一个名为serialVersionUID的静态的、final的long类型字段来指定这个数字,系统会在运行时,自动通过对这个类的结构应用一个加密哈希函数来生成一个。类的名称、所实现的接口及其中的大部分成员(包括编译器生成的合成成员),都会影响这个值。如果没有声明序列化版本号,将导致兼容性问题,会在运行时出现InvalidClassException。
实现Serializable接口的第二个成本是,增加了出现故障和安全漏洞的可能性:正常情况下,对象是通过构造器创建的;序列化是Java核心语言之外的一种创建对象的机制。无论是接受默认行为,还是重写它,反序列化都是一个‘隐藏的构造器’,其他构造器有的问题它都有。由于没有与反序列化关联的显式构造器,所以很容易忘记必须确保它满足构造器建立的所有不变式,并且对于正在构建的对象,不允许攻击者获得对其内部的访问权。单纯依赖默认的反序列化机制,很容易导致对象的不变式被破坏以及不合法的访问。
实现Serializable接口的第三个成本是,增加了发布这个类的新版本时的测试负担:在对可序列化的类进行修订时,重要的是检查这样一点:在将新版本的类的实例序列化之后,能否用老版本的类进行反序列化;反之亦然。
实现Serializable接口不是一个可以轻易做出的决定:如果类要参与到一个依靠Java序列化来实现对象传输或持久化的框架中,实现Serializable就是必要的。此外,如果类要用作另一个必须实现Serializable接口的类的组件,实现Serializable接口也是有好处。然而实现Serializable接口有很高成本,每当设计一个类时,都要权衡收益和成本。例如BigInteger和Instant等值类实现了Serializable接口,集合类也是如此。表示活动实体的类,如线程池,则不应该实现Serializable接口。
设计用于继承的类基本不应该实现Serializable,接口也基本不应该扩展它:若违反,可能会给扩展该类或实现该接口的人带来巨大的负担。当然,若该类参与的框架要求实现,则可以实现。设计用于继承,但又实现Serializable的类,包括Throwable和Component。Throwable实现Serializable, 这样RMI就可以将异常从服务器发送到客户端。
如果我们实现了一个包含实例字段的类,它既可以序列化,又可以扩展,则有些风险需要注意:如果实例字段的值要满足任何不变式,一定要防止子类重写finalize方法,可以让这个类重写finalize方法,并将其声明为final的。否则,这个类很容易受到终结方法攻击。如果实例字段被初始化为其默认值,会违反这个类的某些不变式,则必须在类中加入readObjectNoData方法,这个方法用于处理向已有的可序列化类添加可序列化的超类这样的特殊情况。
当不实现Serializable:如果一个设计用于继承的类没有实现Serializable,当我们需要编写它的一个可序列化的子类时,可能需要更多努力。正常情况下,对这样的类进行反序列化,需要超类有一个可访问的无参构造器,若没有,子类将不得不使用序列化代理模式。
内部类不应该实现Serializable:它们使用编译器生成的合成字段来存储指向包围实例的引用,以及存储来自包围作用域的局部变量值。这些字段与这个类定义的对应关系并没有明确的规定,匿名类和局部类的命名也是如此。因此,内部类默认序列化形式是不明确的。然而,静态成员类可以实现Serializable。
3. 考虑使用自定义的序列化形式
①适用默认序列化的情况
在认真考虑了是否适合接受默认的序列化形式之前,不要盲目接受它:如果要接受,应该是从灵活性、性能和正确性的角度来看,这样编码是合理的,然后慎重做出的决策。一般来说,只有在默认序列化形式在很大程度上与自定义序列化形式相同,才接受它。
如果一个对象的物理表示与其逻辑内容完全相同,则可以考虑默认的序列化形式:例如,对于下面这个简单表示人名的类,采用默认的序列化形式是合理的。从逻辑上讲,一个名字由表示姓、名和中间名的3个字符串组成。Name类中的实例字段精确的反映了这个逻辑内容。
即使我们已经做出决定,默认的序列化形式是合适的,通常也必须提供一个readObject方法来确保其不变式和安全性:对于Name类来说,readObject方法必须确保lastName和firstName字段不为null。尽管lastName、firstName和middleName字段都是私有的,但它们有文档注释。因为这些私有的字段定义了一个公有的API,也就是这个类的序列化形式。这里使用了@serial标签,告诉javadoc将这些文档信息放在一个专门记录序列化形式的特殊页面中。
//适合使用默认的序列化形式
class Name implements Serializable
{
/**
* 必须不为空
* @serial
*/
private final String lastName;
/**
* 必须不为空
* @serial
*/
private final String firstName;
/**
* 不存在可为空
* @serial
*/
private final String middleName;
}②不适用默认序列化的情况
从逻辑上讲,下面的类表示一个字符串序列。而在物理上,它将序列表示为一个双向链表。如果接受默认序列化形式,该形式会费力的将链表中的每个项,以及项与项之间的双向链接关系都反映出来。
当一个对象的物理表示与其逻辑数据内容大不相同时,使用默认的序列化形式有以下4个缺点:
它将导出的API与当前的内部表示永远绑到了一起:在下面的示例中,私有的StringList.Entry类称为公有的API的一部分。如果这种表示在未来的版本中发生了改变,StringList类仍然需要接受这种链表形式的表示作为输入,并生成这种表示作为输出。即使这个类已经不再使用链表项,但它永远都无法摆脱处理链表项的所有代码。
它可能会消耗过多的空间:在下面示例中,序列化形式不必要的表示了链表中的每个项和所有的链接关系。这些项和链接只是实现细节,没有必要包含在序列化形式中。由于序列化形式过大,将其写入磁盘或通过网络发送会非常缓慢。
它可能会消耗过多的时间:序列化逻辑对对象图的拓扑结构一无所知,因此必须进行开销很高的图遍历操作。在下面的实例中,其实只要跟踪next引用就足够了。
它可能会引导致溢出:默认的序列化过程会对对象图进行递归遍历,即使对于中等规模的对象图,也可能导致溢出。
StringList的合理序列化形式,只需包含列表中的字符串数量,然后是字符串本身,这构成了StringList所表示的逻辑数据,剥离了其物理表示的细节。
writeObject和readObject做的第一件事都是调用默认的行为,尽管StringList所有字段都是transient的,因为序列化的规格说明要求,无论如何都要调用它们。这些调用的存在,使得在以后的版本中添加非瞬时的实例字段成为了可能,同时保留向后和向前兼容的能力。如果一个实例在较晚的版本中被序列化了,又在较早的版本中被反序列化,那么后续版本添加的字段将被忽略。如果较早版本的readObject方法没有调用默认形式反序列化会在抛出StreamCorruptedException后失败。
尽管writeObject方法是私有的,但也有一个文档注释。这和Name类中私有字段的文档注释类似。这个私有方法定义了一个公有的API,也就是其序列化形式。作为公有API就应该提供文档说明。@@serialData告诉javadoc工具,将这个文档注释放在序列化形式相关的页面中。
虽然默认序列化形式不适合StringList,但至少可用,对一些其他类会有问题。对于StringList来说,默认的序列化形式不够灵活,且性能较差,但在序列化和反序列化一个StringList实例时,会得到原始对象的一个副本,而且所有不变式都是完整的。但对于那些其不变式与实现细节绑定在一起的对象来说,就不是这样了。
例如,哈希表。其物理表示是包含一系列键值项的哈希桶。一个项会存在于哪个桶中,由它的键的哈希码的一个函数决定,但一般而言,不能保证哈希码在不同的实现之间是相同的。事实上,甚至不能保证每次运行都有相同的哈希码。因此,接受哈希表的默认的序列化形式,会造成故障。对哈希表进行序列化和反序列化,可能会得到一个其不变式被严重破坏的对象。
//不适合使用默认的序列化形式
final class StringList implements Serializable
{
private int size = 0;
private Entry head = null;
private static class Entry implements Serializable
{
String data;
Entry next;
Entry previous;
}
}//提供一个合理的自定义序列化形式的StringList
final class StringList implements Serializable
{
private transient int size = 0;//transient表示该字段不会出现在类的默认序列化形式中
private transient Entry head = null;
//不再实现Serializable
private static class Entry
{
String data;
Entry next;
Entry previous;
}
//将指定的字符串附加到列表中
public final void add(String s)
{
}
/**
* 序列化StringList这个实例
*
* @param s
* @throws IOException
* @serialData
*/
private void writeObject(ObjectOutputStream s)
throws IOException
{
s.defaultWriteObject();//先默认序列化
s.writeInt(size);//序列化大小
//按正确的顺序将所有元素写到流中
for (Entry e = head; e != null; e = e.next)
s.writeObject(e.data);
}
//反序列化
private void readObject(ObjectInputStream s)
throws ClassNotFoundException, IOException
{
s.defaultReadObject();
int numElements = s.readInt();
//读入所有的元素,并将其插入列表
for (int i = 0; i < numElements; i++)
add((String) s.readObject());
}
}③注意事项
无论是否接受默认序列化的形式,当defaultWriteObject方法被调用时,每个未被标记为transient的实例字段都将被序列化。因此,每个可以声明为transient的实例字段都应该这样做。这包括派生字段,其值可以从主要数据字段计算出来,比如缓存的哈希值。还包括其值与JVM的一次特定运行相关联的子弹,比如用于表示执行本地数据结构的指针的long类型字段。如果已经决定,不将一个字段设置为transient,在此之前请说服自己,它的值是对象的逻辑状态的一部分。如果要使用自定义的序列化形式,大部分或所有的实例字段都应该用transient标记。
如果正在使用默认的序列化形式,并且已经将一个或多个字段标记为transient,则当实例被反序列化时,这些字段将被初始化为它们的初始值。如果对于某个transient字段,这些值都是不可接受的,则必须提供一个readObject方法,这个方法会调用defaultReadObject方法,然后将transient字段恢复成可接受的值。也可以选择将这些字段的初始化延迟到其首次使用。
无论是否使用默认的序列化形式,如果用于读取对象整个状态的任何方法需要同步,那么也必须对对象的序列化操作施加同样的同步措施:因此,假设有一个线程安全的对象,他是通过对每个方法进行同步来实现线程安全的,若选择使用默认的序列化形式,则应该使用下面的writeObject方法:
private synchronized void writeObject(ObjectOutputStream s) throws IOException { s.defaultWriteObject();//先默认序列化 }如果将同步放在该方法中,必须确保它遵守与其他活动相同的锁排序约束,否则有可能出现资源排序死锁。
无论选择何种序列化形式,在编写的每个可序列化的类中,都要声明一个显式的序列化版本号:这样可以避免由于序列化版本号造成的不兼容,且没有自动生成的成本大。只需加:
private static final long serialVersionUID=randomLongValue;randomLongValue选择什么值并不重要,可以在这个类上运行serialver工具来生成,也可以随意选择一个数字。序列化版本号并不用保证唯一性。如果修改了一个没有序列化版本号的类,同时希望这个新版本能够接受已被序列化的老版本的实例,则必须使用老版本的那个自动生成的序列化版本号。可以在老版本类上运行serialver工具来获取这个数字。只要不想破坏类与所有现有的已被序列化的实例的兼容性,就不要修改其序列化版本号。
4. 保护性地编写readObject方法
①实例
七(2)提供了一个不可变日期范围类,其中包含的是可变的私有Date类型字段。这个类通过在其构造器和访问器方法中对Date字段进行保护性复制来维护其不变式和不可变性。
假如我们决定让这个类支持序列化。因为Period对象的物理表示完全反映了其逻辑数据内容,所以使用默认的序列化形式并非不合理。因此好像仅仅在声明中加上implements Serialzable即可,但是这样做并不能保证其关键的不变式。问题在于,readObject方法实际相当于另一个公有的构造器,需要和其他任何构造器一样对待,需要像构造器一样检查其参数的有效性,必要时对参数进行保护性复制。不严格的讲,readObject是一个以字节流作为其唯一参数的构造器,在正常情况下字节流是通过对一个正常构造的实例进行序列化产生的。但如果readObject面对的是一个人为构造的字节流,由此产生的对象会破坏类的不变式,这样的字节流可以用来创建一个无法通过正常的构造器创建出来的‘不可能的对象’。
要解决参数有效性问题,可以在Period中提供一个readObject方法,让它先调用defaultReadObject,然后再检查反序列化对象的有效性。如果有效性检查失败,就让readObject方法抛出InvalidObjectException,阻止反序列化完成。
虽然上面可以防止攻击者创建一个无效的Period实例,但攻击者可以构造这样的一个字节流,其开头是一个有效的Period实例,但后面附加了额外引用,使其指向Period实例内部私有的Date字段(字节流是没地址的,只有反序列化后才有地址),这样就可以创建出一个可变的Period实例。
问题自在于,Period的readObject方法还没有进行足够的保护性复制。在反序列化对象时,有些字段会包含客户端不得拥有的对象引用,对于任何这样的字段都要进行保护性复制。
注意,保护性复制是在有效性检查前进行的,并且没有使用Date的clone方法来执行保护性复制,为了保护Period免受攻击,这都是必要的(见七2)。final字段无法进行保护性复制,为了使用readObject方法,必须将start和end声明为非final的。
对于一个类而言,默认的readObject方法是否可以接受,有个简单的判断方式:你是否能够放心的加入这样一个公有构造器,它以参数形式接受对象中每个非transient字段的值,而且不经任何验证,就将这些值保存到相应字段中?如果不能,就必须提供一个readObject方法,并且它必须执行所有的有效性检查和保护性复制。另外,还可以使用序列化代理模式,使用该模式把安全反序列化的许多工作都做了。
对于非final的可序列化类而言,readObject方法和构造器还有一个相似之处。和构造器一样,readObject方法不能直接或间接的调用可重写方法。如果违反,并且所调用的方法被重写了,那么这个重写的方法会在子类的状态被反序列化完毕前执行,可能导致程序出错。
final class Period implements Serializable
{
private Date start;
private Date end;
//修复的构造器,对参数进行了保护性复制
public Period(Date start, Date end)
{
this.start = new Date(start.getTime());
this.end = new Date(end.getTime());
if (start.compareTo(end) > 0)
throw new IllegalArgumentException("Start date cannot be greater than end date");
}
public Date start()
{
return new Date(start.getTime());
}
//修复访问器方法--返回内部字段的保护性副本
public Date end()
{
return new Date(end.getTime());
}
//带有保护性复制和有效性检查的readObject方法
private void readObject(ObjectInputStream s)
throws IOException, ClassNotFoundException
{
s.defaultReadObject();
//对可变组件进行保护性复制
start = new Date(start.getTime());
end = new Date(end.getTime());
//检查不变式是否满足
if (start.compareTo(end) > 0)
throw new InvalidObjectException("Start date cannot be greater than end date");
}
}②编写readObject方法的准则
如果类中的对象引用字段必须保持私有,对这类字段中的每个对象执行保护性复制。不可变类的可变组件就属于这种。
检查任何不变式,如果检查失败,抛出InvalidObjectException。这些检查应该放在任何保护性复制后进行(防止检查完,客户端又修改字段了,在反序列化前)。
如果在反序列化后必须验证整个对象图,请使用ObjectInputValidation接口。
不要直接或间接的调用类中的任何可重写方法。
5. 对于实例受控的类,首选枚举类型而不是readResolve
①readResolve
(一3)描述了单例模式,并给出了下面的单例类的示例:
class Elvis { public static final Elvis INSTANCE=new Elvis(); private Elvis() {} }如果在其声明上加上
implements Serializable,那么这个类就不是单例类了。无论这个类使用默认序列化形式还是自定义序列化形式,也无论是否提供了显式的readObject方法。任何readObject方法都会返回一个新创建的实例,而这个实例不是在类初始化时创建的那个。若想其支持序列化,仅实现Serializable不够。为保证其满足单例性质,还需用transient来声明其所有实例字段,并提供一个
readResolve方法(反序列化时提供自己想要提供的对象)。如果类中定义了一个具有恰当声明的readResolve方法,那么在这个类的对象在被反序列时,新创建的对象会在反序列化之后调用这个方法。该方法返回的引用将代替新创建的对象最终返回,在这个特性大多数使用情况下,指向新创建对象的引用不会被保留,因此它会立即进入等待垃圾收集处理的状态。class Elvis { private static final Elvis INSTANCE = new Elvis(); private Elvis() { } public static Elvis getInstance() { return Elvis.INSTANCE; } private Object readResolve() { return INSTANCE;//新实例因为没有引用,会被垃圾处理器收集 } }如果依赖readResolve进行实例控制,那么所有具有对象引用类型的实例字段都必须用transient声明:因为Elvis实例的序列化形式并不需要包含任何实际的数据。此外,攻击者有可能在readResolve方法运行之前获取到指向反序列化对象的引用:如果单例中包含一个没有用transient来声明的对象引用字段,这个字段内容将在readResolve方法运行之前被反序列化。利用一个精心构造的流,在这个对象引用字段被反序列化时,可以获得指向最初通过反序列化得到的单例的引用,攻击者可以通过构造恶意的字节流,在反序列化过程中修改这些字段的值,从而破坏单例的完整性或执行恶意操作。
尽管枚举是最优选择,但若必须编写一个可序列化的实例受控的类,但它的实例在编译时还不知道,就无法将其表示为枚举类型,此时readResolve还是有用的。
readResolve的可访问性非常重要:如果readResolve位于一个final类中,它应该被声明为私有的。如果是非final的类,必须仔细考虑其可访问性。如果它是私有的,它将无法应用于任何子类。如果它是包私有的,它就只能应用于同一个包中的子类。如果它是受保护或公有的,他就可以应用于任何没有重写它的所有子类。如果一个readResolve是受保护的或公有的,并且子类没有重写它,那么在反序列化这个子类的实例时,将产生一个超类的实例,这可能导致ClassCastException。
②枚举
对于需要支持序列化的实例受控的类,如果将其实现为枚举类型,Java可以确保除了声明的常量之外不会有其他实例。
线程安全:枚举类型在 Java 中是 自动线程安全 的。
防止反序列化:自带序列化机制,还未防止多次实例化问题提供了坚实保证,再复杂的序列化或反射攻击不用担心。枚举类型在反序列化时不会创建新的实例。
简单易用:不需要显式地写出同步代码或处理实例化逻辑,Java 保证了枚举实例的唯一性和初始化时机。
字段和方法:你可以在枚举类中添加任何字段和方法,就像普通的类一样。它们会作用于单例实例。
枚举的构造器总是(默认)私有的。可以省略private修饰符。如果声明一个enum构造器为public或protected, 则会出现语法错误。不可能构造新的对象。
若要设计的单例必须扩展Enum外的超类,无法使用这种方式(尽管可以声明实现多个接口的枚举, 枚举类 是 隐式继承自
java.lang.Enum的,而 Java 不允许多重继承,即一个类不能同时继承多个类)。
//枚举类型的单例类--首选方式
enum Elvis
{
INSTANCE;
private String[] favoriteSongs = {"abc", "cdd"};
}6. 考虑使用序列化代理替代序列化实例
①序列化代理模式
使用序列化代理模式可以有效降低序列化出现故障和安全性问题的可能性。
序列化代理模式:首先设计一个私有的静态嵌套类,简明的表示其包围实例的逻辑状态。这个嵌套类被称为包围类的序列化代理。它应该只提供一个构造器,以包围类作为其参数的类型。这个构造器复制来自参数的数据:它不需要进行任何的一致性检查或保护性复制。按照设计,序列化代理的默认序列化形式,就是包围类的完美的序列化形式。包围类和他的序列化代理都必须声明Serializable接口。
final class Period implements Serializable
{
private final Date start;
private final Date end;
//修复的构造器,对参数进行了保护性复制
public Period(Date start, Date end)
{
this.start = new Date(start.getTime());
this.end = new Date(end.getTime());
if (start.compareTo(end) > 0)
throw new IllegalArgumentException("Start date cannot be greater than end date");
}
//Period类的序列化代理
private static class SerialzationProxy implements Serializable
{
private static final long serialVersionUID = 1L;
private final Date start;
private final Date end;
SerialzationProxy(Period p)
{
this.start = p.start;
this.end = p.end;
}
/**
* 负责返回一个逻辑上等价的包围类的实例。这个方法的
* 存在会使序列化系统在反序列化时时将序列化代理转回
* 其包围类的实例。
* <p>
* readResolve方法会使用其包围类的公有API来创建实例,
* 该模式魅力在于此。它在很大程度上消除了序列化这种Java核心
* 语言之外的机制的特征,因为反序列化实例是使用与其他任何
* 实例相同的构造器、静态工厂和方法来创建的。这样我们不用
* 单独确保反序列化的实例不会违反类的不变式了。如果这个类的
* 静态工厂或构造器建立了这些不变式,并且其实例方法会保持这些
* 不变式,我们就已经确保了序列化也会保持这些不变式.
*
* 和保护性复制一样,序列化代理可以中途拦截伪造字节流攻击
* 和内部字段窃取攻击。与前两种方式不同的是,这种方式
* 允许Period的字段设置为final的,而使Period真正成为
* 不可变类。这种方式使我们不必弄清楚哪些字段会受到不择手段
* 的序列化攻击,也不必在反序列化时执行有效性检查
*/
private Object readResolve()
{
return new Period(this.start, this.end);
}
}
/**
* 用于序列化代理模式的方法:这个方法可以原封不动复制到任何使用序列
* 化代理的类中。
* <p>
* 包围类上这个方法的存在,会使得序列化系统序列化时生成SerialzationProxy
* 实例,而不是包围类的实例。
*/
private Object writeReplace()
{
return new SerialzationProxy(this);
}
/**
* 有了writeReplace方法,序列化系统永远不会生成包围类的实例
* 但攻击者可能伪造一个,企图破坏这个类的不变式。
* 为了预防此类攻击,只需将下面方法加入包围类
*/
private void readObject(ObjectInputStream stream)
throws InvalidObjectException
{
throw new InvalidObjectException("Proxy required");
}
public Date start()
{
return new Date(start.getTime());
}
//修复访问器方法--返回内部字段的保护性副本
public Date end()
{
return new Date(end.getTime());
}
}②另一种使用方式
还有一种使用方式,使得序列化代理模式比在readObject方法中进行保护性复制更为强大。序列化代理模式允许反序列化出来的实例与最初被序列化的实例具有不同的类。
以EnumSet为例,这个类没有公有的构造器,只有静态工厂。从客户端的角度看,这些静态工厂返回的是EnumSet实例,但在当前的OpenJdk实现中,他们返回的是两个子类之一的实例,具体取决于底层枚举类型大小。如果底层枚举类型的元素数量不超过64,静态工厂会返回一个RegularEnumSet实例;否则会返回一个JumboEnumSet实例。
现在考虑这样的情况:我们序列化了一个枚举类型包含60个元素的EnumSet实例,然后想这个枚举类型添加了5个元素,之后再反序列化这个EnumSet实例,这样会发生什么?在被序列化时,它是RegularEnumSet实例,但一旦被反序列化,它最好是一个JumboEnumSet实例。而事实上,真实情况就是这样的,因为EnumSet使用了序列化代理模式。
//EnumSet的序列化代理, 一个内部类
private static class SerializationProxy<E extends Enum<E>>
implements Serializable
{
//这个EnumSet实例的元素类型
private final Class<E> elementType;
//包含在这个EnumSet实例中的元素
private final Enum<?>[] elements;
SerializationProxy(EnumSet<E> set)
{
elementType = set.elementType;
elements = set.toArray(new Enum<?>[0]);
}
private Object readResolve()
{
EnumSet<E> result = EnumSet.noneOf(elementType);
for (Enum<?> e : elements)
result.add((E) e);
return result;
}
private static final long serialVersionUID = 1L;
}③序列化代理的限制
首先,它不能用于可由用户扩展的类。
其次,对于对象图中包含循环的某些类,它也不能使用。
最后,序列化代理模式带来的安全性和功能是有代价的(性能)。