
参考书籍:
《Effective Java》第三版 Joshua Bloch 著
一. 创建和销毁对象
1. 用静态工厂方法代替构造器
①介绍
设计类时,传统的方法是为其提供公有构造器,从而让客户端通过构造器来得到其实例。
此外,可以让类提供一个公有的静态工厂方法(一个用来返回这个类的实例的静态方法)(静态工厂方法并不是设计模式中的任何一个工厂模式)。作为公有构造器的替代和补充。
//boolean包装类的一个示例
public static Boolean valueOf(boolean b)
{
return b ? Boolean.TRUE : Boolean.FALSE;
}②优点
与构造器不同,他们有名称:
若构造器参数本身不能清晰描述所返回对象的信息时,若使用合适的静态工厂方法名称能够清晰描述。
例如:
BigInteger(int,int,Random)返回一个可能素数,但用BigInteger.probablePrime静态工厂方法会更好。此外,有的程序员会通过改变参数列表中参数类型的顺序来提供两个不同的构造器(绕过一个类只能有一个带有特定签名的构造器这一限制)。但是,这样行为不可取,用户容易调用错误的构造器。但是静态工厂方法有名称,若类需要多个带有相同签名的构造器,可用不同名称的多个静态工厂方法来替代。
与构造器不同,不用在每次调用时都创建一个新对象:
对于重复多次调用,静态工厂方法可以返回同一个对象。
若经常创建相同对象,且开销非常大时,利用重复对象可以提高性能。
返回同一个对象,使得类能够严格控制存在哪些实例。
与构造器不同,它们可以返回所声明的返回类型的任何子类型对象:
这样选择返回对象的类时,有很大灵活性。一种应用是,不用将类设计为公有的,就可以让API返回这个类的对象,从而将类隐藏起来,API会非常简洁。
在Java8前,接口中不能包含静态方法,按照惯例,接口Type的静态工厂方法会被放到一个名为Types的、不可实例化的伴生类。
例如,Java集合框架为其中的接口(Map、List等)提供了45个工具类实现,分别提供了不可修改集合、同步集合等等。几乎所有实现都是通过一个不可实例化类(Collections)中的静态工厂方法导出的,所有返回对象都是非公有的。
若45个工具类设计为公有的,与当前相比,API体积会更大(更多的暴露接口、增加维护成本、依赖性与扩展性、不必要的功能暴露)。设计为私有的会降低理解难度,用户知道所返回的对象完全遵循接口指定的API,不需要额外阅读实现类的文档。
使用静态工厂方法,客户端必须通过接口而不是实现类引用返回的对象,是一种好习惯。
从Java8开始,接口中可以包含静态方法,因此通常不需要为接口提供一个不可实例化的伴生类。但仍有必要将这些静态方法的实现代码放到一个单独的、包私有的类中。因为Java8仍要求接口中的所有静态成员是公有的。Java9支持私有的静态方法,但是静态字段和静态成员类仍然必须是公有的。
public class Collections
{
// Suppresses default constructor, ensuring non-instantiability.
private Collections()
{
}
public static <T> Collection<T> unmodifiableCollection(Collection<? extends T> c)
{
if (c.getClass() == java.util.Collections.UnmodifiableCollection.class)
{
return (Collection<T>) c;
}
return new java.util.Collections.UnmodifiableCollection<>(c);
}
static class UnmodifiableCollection<E> implements Collection<E>, Serializable
{
}
}在方法每次被调用时,所返回对象的类可以随输入参数的不同而改变:
EnumSet类没有公有构造器,只有静态工厂方法。根据底层枚举类型的元素数量,返回两个子类(对客户端不可见)之一的实例。
在编写包含该方法的类时,所返回对象(接口、抽象类)的类并不一定要存在:
这构成了服务提供者框架的基础。例如JDBC API,服务提供者框架是一个系统,在此系统中,多个提供者都可以实现某项服务,而系统将这些实现都提供给客户端,将客户端与实现解耦合。API 是供外部调用的接口,而 SPI 是供外部实现的接口。
服务提供者框架有三个基本组件:服务接口(代表一个实现);提供者注册API(提供者用它将实现注册到框架中);服务访问API(客户端用它获取这个服务的实例)。
若无指定,API返回一个默认实现的实例。服务访问API就是静态工厂。
例如:JDBC中,Connection是服务接口,DriverManager.registerDriver是提供者注册API,DriverManager.getConnection是服务访问API,而Driver是服务提供者接口。
依赖注入框架,可被看做服务提供者。
④java.util.ServiceLoader
Java6开始,引入一个通用的服务提供者框架(java.util.ServiceLoader):
java.util.ServiceLoader是 Java 1.6 引入的一个工具类,用于实现基于服务提供者接口(SPI,Service Provider Interface)的服务加载机制。它允许 Java 应用程序或框架在运行时动态加载和使用不同的服务实现,而无需在编译时指定具体的实现类。服务提供者接口(SPI):服务提供者实现了某个接口并通过配置文件进行注册,框架可以通过
ServiceLoader加载这些实现。配置文件:服务提供者的实现类通常会在
META-INF/services/目录下的配置文件中列出,配置文件的名称是接口的全名,内容是实现类的全名。当调用
ServiceLoader.load(GreetingService.class)时,ServiceLoader会查找META-INF/services/GreetingService文件,并加载文件中列出的所有服务实现(即EnglishGreetingService和SpanishGreetingService)。
1定义服务接口
// 定义一个接口作为 SPI
public interface GreetingService {
void greet(String name);
}2服务提供者实现接口
// 实现 SPI 接口的服务提供者
public class EnglishGreetingService implements GreetingService {
@Override
public void greet(String name) {
System.out.println("Hello, " + name);
}
}
public class SpanishGreetingService implements GreetingService {
@Override
public void greet(String name) {
System.out.println("Hola, " + name);
}
}3创建配置文件
在 META-INF/services/ 目录下,创建一个名为 GreetingService 的文件,该文件内容为服务实现类的完全限定名(FQN)。
META-INF/services/GreetingService
文件内容:
com.example.EnglishGreetingService
com.example.SpanishGreetingService4使用 ServiceLoader 加载服务
import java.util.ServiceLoader;
public class ServiceLoaderExample {
public static void main(String[] args) {
// 加载服务提供者
ServiceLoader<GreetingService> loader = ServiceLoader.load(GreetingService.class);
// 遍历所有实现
for (GreetingService service : loader) {
service.greet("John");
}
}
}⑤缺点
只提供静态工厂方法的缺点是,若没有公有构造器或受保护的构造器,就无法为这样的类创建子类:
例如:对于集合框架中任意一个工具实现类,都无法创建其子类。
程序员很难找到他们:
它们在API文档不像构造器那么明显。
在类或接口注释中引起人们对静态工厂的注释,并遵循通用的命名惯例,可以减少这个问题。
静态工厂方法通用惯例:
from:一个类型转换方法,它接受一个参数并返回该类型的一个对应实例。Date d=Date.from(instant)of:一个聚合方法,它接受多个参数并返回该类型的一个包含这些参数的实例。Set<Rank> faceCards=EnumSet.of(JACK, QUEE, KING)valueOf:比from和of更繁琐的替代方法。BigInteger prime=BigInteger .valueOf(Integer.MAX_VALUE)instance或getInstance:根据参数的描述返回一个实例,每次返回的实例未必有相同值。StackWalker luke=StackWalker.getInstance(options)create或newInstance:与instance或getInstance类型,但该方法会确保每次调用都返回一个新的实例。Object newArray=Array.newInstance(classObject, arrayLen)getType:与getInstance类似,但是在该工厂方法处于不同的类中时使用。Type是该工厂方法所返回对象的类型。FileStore fs=Files.getFileStore(path)newType:与newInstance类似,但是在该工厂方法处于不同的类中时使用。Type是该工厂方法所返回对象的类型。BufferedReadder br=Files.newBufferedReader(path)type:getType和newType的一个简洁的替代版本。List<Complaint> litany=Collections.list(legacyLitany)
2. 当构造器参数较多时考虑使用生成器
静态工厂和构造器都有一个共同缺点:当可选参数非常多时,不能很好扩展。例如这样一个类,有很多必须字段,也有很多可选字段。
①重叠构造器模式
第一个构造器只有必须参数,第二个构造器有一个可选参数,第三个构造器有两个可选参数,以此类推。
但是有这样一种情况,你只需要后面某个可选参数,但是前面的可选参数的值你也必须不得不提供。当参数非常多时,客户端代码写起来和读起来非常困难,阅读代码必须理解这些值是什么意思,并且实参顺序不能有误。
//不能很好扩展
class NutritionFacts
{
private final int servingSize;//每份的含量,必须的
private final int servings;//每包装所含分数,必须的
private final int calories;//每份卡路里,可选的
private final int fat;//每份所含脂肪,可选的
public NutritionFacts(int servingSize, int servings)
{
this(servingSize, servings, 0);
}
public NutritionFacts(int servingSize, int servings,
int calories)
{
this(servingSize, servings, calories, 0);
}
public NutritionFacts(int servingSize, int servings,
int calories, int fat)
{
this.servingSize = servingSize;
this.servings = servings;
this.calories = calories;
this.fat = fat;
}
}②JavaBeans模式
先调用一个无参构造器来创建对象,后面再调用set方法设置必要的参数,以及需要的可选参数。
这种模式没有重叠构造器的那些缺点,创建实例容易,但冗长。
缺点:
由于构造被分割成多个调用,一个JavaBean对象在构造过程中可能会处于不一致的状态(不一致的状态:是指在对象的构造过程中,部分属性可能已经被赋值,但其他属性仍然没有初始化或设置,因为用不到这些可选字段。这种中间状态可能导致对象处于一个不符合预期的状态,可能影响对象的行为或导致错误。例如,某个字段可能在setter方法被调用前没有得到适当的赋值,导致该字段的默认值与业务逻辑不匹配。业务逻辑错误:如果在对象构造完成之前就尝试使用这些未初始化的属性,可能会导致逻辑错误。不符合预期的行为:部分属性未初始化的对象可能不符合应用程序的预期行为或规则。例如,要求
age必须大于0,但构造过程中age尚未被设置。)。其次,选择JavaBeans模式,这个类就不可能再成为不可变类了,需要额外方式确保线程安全。
class NutritionFacts
{
private int servingSize=-1;//每份的含量,必须的
private int servings=-1;//每包装所含分数,必须的
private int calories=0;//每份卡路里,可选的
private int fat=0;//每份所含脂肪,可选的
public NutritionFacts() {}
//setter
public void setServingSize(int servingSize)
{
this.servingSize = servingSize;
}
public void setServings(int servings)
{
this.servings = servings;
}
public void setCalories(int calories)
{
this.calories = calories;
}
public void setFat(int fat)
{
this.fat = fat;
}
}③单层次生成器模式
该模式结合了重叠构造器模式的安全性和JavaBeans模式的可读性。
步骤:客户端不直接生成想要的对象,而是调用一个带有所有必须的参数的构造器(或静态工厂),得到一个生成器对象。然后客户端在这个生成器对象上调用类似setter的方法来设置每个需要的可选参数。最后,客户端调用一个无参的build方法来生成这个对象,该对象通常是不可变的。一般会将生成器设置为它所负责构建的类中的静态成员类。
NutritionFacts是不可变的,所有参数的默认值都放在一起。
为了简洁,示例省略了有效性检查,可在生成器的构造器和方法中检查参数有效性。在由build方法调用的构造器中,要检查涉及多个参数的不变式(不变式是在程序执行过程中始终保持成立的条件)(不变式通常涉及到类的状态或属性,必须始终保持为有效状态。举个例子,如果一个
Person类有age和name字段,并且要求age必须大于0,name不能为空,那么在构造过程中就需要检查这些条件。)。为了防止不变式受到攻击(攻击指的是在构造过程中恶意传入不符合不变式的参数,或者在构造器中没有进行适当的验证,导致对象处于非法状态),在复制了来自生成器的参数后,要在对象字段上执行检查。若检查失败,要抛出IllegalArgumentException,并利用详细消息说明哪些参数无效。
public class Test
{
public static void main(String[] args)
{
NutritionFacts nf=new NutritionFacts.Builder(240, 8)
.calories(100).fat(35).build();
}
}
//NutritionFacts是不可变的
class NutritionFacts
{
private final int servingSize;//每份的含量,必须的
private final int servings;//每包装所含分数,必须的
private final int calories;//每份卡路里,可选的
private final int fat;//每份所含脂肪,可选的
//私有构造器
private NutritionFacts(Builder builder)
{
this.servingSize=builder.servingSize;
this.servings=builder.servings;
this.calories=builder.calories;
this.fat=builder.fat;
}
public static class Builder
{
//必须的参数
private final int servingSize;
private final int servings;
//可选的参数,初始化为默认值
private int calories=0;
private int fat=0;
public Builder(int servingSize, int servings)
{
this.servingSize=servingSize;
this.servings=servings;
}
public Builder calories(int calories)
{
this.calories=calories;
return this;
}
public Builder fat(int fat)
{
this.fat=fat;
return this;
}
public NutritionFacts build()
{
return new NutritionFacts(this);
}
}
}④用于类层次结构的生成器模式
生成器模式模式非常适合类层次结构。可以使用一组平行层次结构的生成器,将每个生成器都嵌套在相应的类中。抽象的类有抽象生成器;具体的类有具体的生成器。
优点:
与构造器相比,生成器因为每个参数都是在自己对应的方法中指定的,所以可以有多个可变参数。生成器也可以将多次调用某个方法时分别传入的采纳数聚合到一个字段中,如addTopping方法。
生成器可创建多个对象,每次调用build时,调整生成器参数,以改变所创建的对象。
生成器可以在创建对象时自动填充一些字段,例如每次创建对象时都会自动增加一个序列号。
-
缺点:
要创建一个对象,必须创建生成器,在对性能非常敏感场景下,可能成为问题。
生成器比重叠构造器模式更为繁琐。只有在多参数时才值得这么做(>=4)。
public class Test
{
public static void main(String[] args)
{
NyPizza pizza=new NyPizza
.Builder(NyPizza.Size.SMALL)
.addTopping(Pizza.Topping.SAUSACE)
.addTopping(Pizza.Topping.ONION)
.build();
Calzone calzone=new Calzone
.Builder()
.addTopping(Pizza.Topping.HAM)
.sauceInside().build();
}
}
//根抽象类
abstract class Pizza
{
public enum Topping
{HAM, MUSHROOM, ONION, PEPPER, SAUSACE}
final Set<Topping> toppings;
Pizza(Builder<?> builder)
{
this.toppings = builder.toppings.clone();
}
/**
* 左边的 T(类声明中的泛型类型参数)
* 这是一个 泛型类型参数,表示类 Builder 的 类型占位符,
* 用于在类定义中处理不同类型的实例。在此声明中,T 是一个类型参数,
* 用来表示具体的类类型,可以是任何类型,如 String、Integer、
* 或其他自定义类型(例如 MyBuilder)。
* 具体地,这个 T 用来让 Builder 类成为一个通用的类,可以在不同情况下应用于不同的具体类型。
* 在实例化 Builder 时,T 会被替换成实际的类型。
* <p>
* 右边的 T(类型限制)
* T extends Builder<T> 是一种 类型限制(或类型约束),
* 意味着 T 必须是 Builder<T> 类本身或其子类的类型。
* 这个限制确保了 T 是 与 Builder<T> 相关联的类型,
* 即 T 必须是某种形式的 Builder 类型,并且该类型 递归地 指定了自己的类型。
* 这就是一个 自引用类型,意思是 T 不仅是一个泛型类型参数,而且还必须是 Builder 类的子类或本身。
* 这种做法可以让子类 返回自己类型的实例,从而支持方法链(Fluent Interface)和递归构建。
* <p>
* 递归类型参数+抽象的self方法,使得链式调用在子类中也可以正常工作,无需转换。
* 这就是模拟自身类型习惯用法。
*/
abstract static class Builder<T extends Builder<T>>
{
EnumSet<Topping> toppings = EnumSet.noneOf(Topping.class);
public T addTopping(Topping topping)
{
toppings.add(Objects.requireNonNull(topping));
return self();
}
abstract Pizza build();
//子类必须重写该方法来返回this
protected abstract T self();
}
}
//子类1
class NyPizza extends Pizza
{
public enum Size
{SMALL, MEDIUM, LARGE}
private final Size size;
private NyPizza(Builder builder)
{
super(builder);
this.size = builder.size;
}
public static class Builder extends Pizza.Builder<Builder>
{
private final Size size;
public Builder(Size size)
{
this.size = Objects.requireNonNull(size);
}
@Override
public NyPizza build()
{
return new NyPizza(this);
}
@Override
protected Builder self()
{
return this;
}
}
}
//子类2
class Calzone extends Pizza
{
private final boolean sauceInside;
private Calzone(Builder builder)
{
super(builder);
this.sauceInside = builder.sauceInside;
}
public static class Builder extends Pizza.Builder<Builder>
{
private boolean sauceInside = false;//默认
public Builder sauceInside()
{
this.sauceInside = true;
return this;
}
@Override
public Calzone build()
{
return new Calzone(this);
}
@Override
protected Builder self()
{
return this;
}
}
}3. 利用私有构造器或枚举类型强化Singleton属性
Singleton指只能被实例化一次的类。Singleton通常用于表示无状态对象(如函数),或本质上唯一的系统组件。
①final字段作为公有静态成员
私有构造器只在初始化常量Elvis时调用了一次。
没有公有或受保护构造器,保证其全局唯一。
但,越权的客户端可以借助AccessibleObject.setAccessible方法,通过反射机制调用私有构造器。可以修改构造器,在其被要求创建第二个实例时抛出异常,以防御这类攻击。
-
优点:
API可以清楚表明该类是个单例
公有静态字段是final,它将永远包含同一个对象的引用
class Elvis
{
public static final Elvis INSTANCE=new Elvis();
private Elvis() {}
}②静态工厂方法作为公有的成员
getInstance方法每次都会返回同一个对象,但同样要注意反射问题。
-
优点:
灵活性很高,即使以后不想将这个类设计为单例,也不需要修改其API。工厂方法现在返回的是唯一实例,但很容易修改,比如为每个调用它的线程返回唯一一个实例。
可以编写一个泛型单例工厂。
可以用作方法引用,作为Supplier。
-
在具体使用时,除非优点中某个有意义,否则优先考虑第一种方式。
-
无论上述两种方式哪一组实现单例,若想其支持序列化,仅实现Serializable不够。为保证其满足单例性质,还需用transient来声明其所有实例字段,并提供一个
readResolve方(反序列化时提供自己想要提供的对象)。否则,反序列化时,会有一个新的实例被创建出来。
class Elvis
{
private static final Elvis INSTANCE=new Elvis();
private Elvis() {}
public static Elvis getInstance()
{
return Elvis.INSTANCE;
}
private Object readResolve()
{
return INSTANCE;//新实例因为没有引用,会被垃圾处理器收集
}③用枚举实现单例--首选方法
优点:
线程安全:枚举类型在 Java 中是 自动线程安全 的。
防止反序列化:自带序列化机制,还未防止多次实例化问题提供了坚实保证,再复杂的序列化或反射攻击不用担心。枚举类型在反序列化时不会创建新的实例。
简单易用:不需要显式地写出同步代码或处理实例化逻辑,Java 保证了枚举实例的唯一性和初始化时机。
字段和方法:你可以在枚举类中添加任何字段和方法,就像普通的类一样。它们会作用于单例实例。
枚举的构造器总是(默认)私有的。可以省略private修饰符。如果声明一个enum构造器为public或protected, 则会出现语法错误。不可能构造新的对象。
缺点:
若要设计的单例必须扩展Enum外的超类,无法使用这种方式(尽管可以声明实现多个接口的枚举, 枚举类 是 隐式继承自
java.lang.Enum的,而 Java 不允许多重继承,即一个类不能同时继承多个类)。
public enum Singleton
{
INSTANCE;
// 你可以在这里添加字段和方法
private String value;
// 获取实例的方法
public String getValue()
{
return value;
}
public void setValue(String value)
{
this.value = value;
}
// 其他方法
public void doSomething()
{
System.out.println("Doing something...");
}
}4. 利用私有构造器防止类被实例化
工具类:仅包含静态方法和静态字段(java.util.Arrays、java.util.Collections)。或者将某个final类上的方法组织到一起,因为其不可继承,所以不会被子类包含。这些类是无序实例化。
若无显式构造器,编译器会生成公有无参默认构造器。
将类设计为抽象类来防止其被实例化行不通,因为可创建其子类,子类可被实例化。
class UtilityClass
{
//阻止编译器创建默认构造器
private UtilityClass()
{
throw new AssertionError();//防止在类内部不小心调用这个构造器
}
}5. 优先考虑通过依赖注入来连接资源
很多类会依赖一个或多个底层资源。
可以将这样的类实现为静态工具类、单例模式、依赖注入模式、资源工厂等模式。例如拼写检查工具需要依赖字典。
①静态工具类或单例模式
下面两种方式都假定只有一本字典值得使用,但实际中每种语言都有自己的字典,不可能仅靠一本字典满足所有。
可以将dictionary修改为非final,并加入一个修改字典方法。但是这种方式容易出错在并发送下甚至无法正常工作。
对于行为会被底层资源以参数化方式影响的类而言,这两种模式都不合适。
在测试时,可能需要手动设置依赖,或者通过某些 DI 容器来进行依赖注入。在测试过程中,可能会遇到未初始化依赖的问题,或者需要对测试框架进行额外配置。
//静态工具类---不够灵活且难以测试
class SpellChecker
{
private static final Lexicon dictionary;
private SpellChecker() {}//不可实例化
}//单例模式---不够灵活且难以测试
class SpellChecker
{
private static final Lexicon dictionary;
public static SpellChecker INSTANCE = new SpellChecker();
private SpellChecker() {}//不可实例化
}②依赖注入
依赖注入:在创建实例的时候,将资源传入构造器。字典是拼写检查工具的一个依赖项,在创建该工具时将字典注入。
容易测试:由于所有依赖都必须在构造时传入,因此在单元测试时很容易通过构造函数传递模拟对象(Mock)。这使得测试更加简洁且易于控制。
确保不可变性:构造器注入要求所有依赖必须在对象创建时传入,因此实例化后无法更改这些依赖。这样可以确保类的依赖关系是不可变的,保证对象在生命周期中的一致性。
依赖注入同样适用于构造器、静态工厂(条目1)及生成器(条目2)。
该模式一个变体:将资源工厂传递给构造器。资源工厂(工厂方法模式)是一个对象,可被重复调用,来创建某个类型的实例。
Java8引入的Supplier<T>接口非常适合表示工厂,通常使用有限制通配符类型来约束工厂类型的参数,使得这样的工厂能够创建指定类型的任何子类型的对象。
Mosaic create(Supplier<? extends Tile> tileFactory) {}过多依赖项会导致复杂,可使用依赖注入框架来避免。
依赖注入将提升类的灵活性、可复用性和可测试性。
class SpellChecker
{
private static final Lexicon dictionary;
public SpellChecker(Lexicon dictionary)
{
this.dictionary = Objects.requireNonNull(dictionary);
}
}6. 避免创建不必要的对象
①不可变对象的复用
复用对象,而不是每次需要时都创建一个新的功能相同的对象。
不可变对象总是可以复用。
String s=new String("abc");//✖,每次都会创建一个新实例,参数本身就是一个实例,与调用构造器创建的对象功能相同
s="abc";//✔,每次都是用的同一个实例②静态工厂方法和构造器选择
对于既提供了静态工厂方法(条目1),又提供了构造器的不可变类,通常选择前者,以避免创建不必要对象
构造器每次调用都必须创建一个新对象,而工厂方法没有这样的要求。
public static final Boolean TRUE = new Boolean(true);
public static final Boolean FALSE = new Boolean(false);
public static Boolean valueOf(boolean b) {
return (b ? TRUE : FALSE);
}@Deprecated(since="9", forRemoval = true)//在java9 已经被废弃
public Boolean(String s) {
this(parseBoolean(s));
}③可变对象复用
对于可变对象,若知道其不会被修改,也可以复用。
有些对象创建开销很大,可以将其缓存下来以供复用。
//无缓存
class RomanNumerals
{
/**
*判断s是否为有效罗马数字,用正则表达式实现
*
* 问题:依赖String.matches方法。该方法内部会为这个正则表达式
* 创建一个Pattern实例,并且只使用一次,之后称为垃圾被回收。
* 创建Pattern实例的开销很大,因为需要将这个正则表达式编译为一个
* 有限状态机
*
* 有限状态机(Finite State Machine, FSM) 是一种数学模型,
* 用来描述系统在一组有限的状态之间的转换。FSM 常用于表示程序、
* 协议、控制逻辑以及解析器(如正则表达式引擎)的行为。
*/
static boolean isRomanNumeral(String s)
{
return s.matches("^(?=)");
}
}//缓存
class RomanNumerals
{
/**
* 为提升性能,可在类初始化时显式的将这个正则表达式
* 编译成一个Pattern实例(该实例不可变)缓存下来,
* 下面方法每次都复用同一个实例
*
* 且有名字,更容易理解
*
* 若该鳄梨被初始化,但下面方法从没被用过,则ROMAN字段会
* 无必要的初始化。可通过延迟初始化解决,即:只有第一次调用该
* 方法时才初始化ROMAN字段,但不建议这么做。大多数情况会使实现
* 变得更加复杂,且不会带来明显性能改进
*/
private static final Pattern ROMAN=Pattern.compile("^(?=)");
static boolean isRomanNumeral(String s)
{
return ROMAN.matcher(s).matches();
}
}④可变对象的适配器(视图)复用
对象不可变,可以安全复用;但在其他情况下不是显而易见,考虑适配器。
适配器:适配器对象将功能委托给一个后备对象,为其提供一种替代接口。适配器除了后备对象外不会保存其他状态信息,所以对于某个给定对象的给定适配器,不需要为其创建多个实例。
例如:Map接口的keySet方法会返回包含该Map对象中所有key的一个Set视图。在一个给定Map对象上每次调用keySet可能返回的是同一个Set实例。尽管被返回的Set实例通常是不可变的,但是所有返回对象在功能上是相同的:一个对象改变了,其他对象也会改变,因为他们的后备对象都是同一个Map实例。
⑤自动装箱问题
自动装箱会创建不必要的对象。
应该优先使用基本类型而不是其封装类,并提防无意中的自动装箱。
/**
* 计算所有int类型正整数值的总和
* 非常慢
*
* 变量sum被声明为了Long类型,而不是long,
* 这意味着,程序构造了大约2^31个不必要的Long实例
* (每次将long类型的i加到Long类型的sum上就会构造一个)
*
* 将sum声明从Long改为long,运行时间:6.3s -> 0.59s
*/
private static long sum()
{
Long sum = 0L;
for(int i=0;i<=Integer.MAX_VALUE;++i)
sum += i;
return sum;
}⑥对象池
除非创建对象的开销极为高昂,否则通过维护自己的对象池来避免创建对象并不好。
例如:数据库连接池。建立数据库连接的开销高到值得复用这些对象。
一般来说,维护自己的对象池会使得代码混乱、增加内存占用,影响性能。
现代JVM对构造器几乎没做什么明确工作的小对象,其创建和回收开销非常小,其性能很容易胜过这样的对象池。
(当应该复用现有对象时,不要创建新对象)与条目50对比相反(当应该创建新对象时,不要复用现有对象)。与不必要的创建对象相比,如果在需要使用保护性复制的时候复用了对象,危害非常严重。在必要时没有保护性复制,会导致安全问题;而不必要的创建对象,只会影响程序的风格和性能。
7. 清除过期的对象引用
①过期引用和内存泄露
过期引用:再也不会被解引用的引用。
内存泄露:随垃圾收集器活动增加或内存占用增加而导致的性能下降。
下面实现中,若一个该类型的栈先增长再收缩,那么从栈顶弹出的对象将不会被当作垃圾回收(因为只是逻辑弹出),即使这个程序不再使用这些对象。因为栈中仍维护着这些对象的过期引用在这个实例中,元素数组的活跃部分(下标<size的部分)之外的任何引用都是过期引用。
class Stack
{
private Object[] elements;
private int size = 0;
private static final int DEFAULT_INIT_CAPACITY = 16;
public Stack()
{
elements = new Object[DEFAULT_INIT_CAPACITY];
}
public void push(Object e)
{
ensureCapacity();
elements[size++] = e;
}
public Object pop()
{
if (this.size == 0)
throw new EmptyStackException();
return elements[--size];
}
//确保再来一个元素也有空间保存
private void ensureCapacity()
{
if (this.elements.length == this.size)
elements = Arrays.copyOf(this.elements, this.size * 2 + 1);
}
}解决方式:清除过期引用:一旦引用过期,就将其设置为null。
清除过期引用另一个优点:若随后又错误对其解引用,程序将抛出空指针异常,而不是错误运行。
清除引用最好方式是让包含该引用的变量随其作用域结束,不要矫枉过正。尽可能窄的作用域内定义每个变量,清除操作很容易完成。
②内存泄露原因
类自己管理自己内存时:每当释放一个元素时,其包含的任何对象引用都应该清除。
缓存:一旦将对象引用放入缓存,容易忘记其存在,不用后长时间让其留在缓存。
解决方法1:对于一条缓存项(包括键和值),只有在缓存外有对其键的引用时,他才有存在的意义,则可以用weakHashMap实现。缓存项在过期后会被自动删除。(只有当缓存项预期的生命周期由指向其键的外部引用而不是由值决定时,weakHashMap才有用)。
解决方法2:一般来说,一个缓存项什么时候用得到并不确定,所以其声明周期也是不确定的。此时,应该不定期的清理缓存中不再使用的项。可以通过后台线程(如ScheduledThreadPoolExecutor)来完成,或者在向缓存中加入新项时顺便处理。对于更复杂的缓存考虑使用java.lang.ref。
监听器和其他回调:若实现了一个API,客户端注册了回调,但是没有显式注销(在不需要时),这些对象会不断累积。确保回调及时被垃圾处理器收集和处理的一个方法是只存储他们的弱引用,例如:将其仅作为WeakHashMap中的键来存储。
8. 避免使用终结方法和清理方法
终结方法(finalizer)(java9废弃)是不可预测的,往往存在危险且一般不必要。
清理方法(cleaner)(java9引入)危险性比终结方法小,但仍不可预测,且运行很慢,一般来说不必要。
不要将终结方法和清理方法看做java版的析构函数。在cpp中析构函数是回收与对象相关资源的常规方式,是构造器的必不可少的对应物。而在java中,当一个对象不可达时,垃圾收集器会回收与之相关的存储空间,不需要程序员专门处理。cpp析构函数也被用来回收其他非内存资源。在java中一般使用try-with-resources和try-finally来完成这个工作。
①终结方法和清理方法的缺点
无法及时执行:终结和清理方法无法保证会及时执行,从一个对象变得不可达到这俩方法运行,中间花费多少时间都有可能。所以不该在终结方法和清理方法中做对任何对时间有严格要求的事情。
finalize()方法和清理方法的调用时机由垃圾回收器控制(垃圾收集算法),无法预测。在不同JVM上可能有不同表现。可能不会执行,导致内存泄露:java语言规范不报账他们会运行。所以,永远不要依赖终结方法或清理方法来更新持久化状态。例如:释放某个共享资源上的锁,容易让分布式系统陷入停顿。
System.gc和System.runFinalization可能会增加终结和清理方法执行的概率,但不保证一定会执行。
抛出的未捕获异常会被忽略:终结方法另一个问题是,在终结过程中被抛出的未捕获的异常会被忽略,并继续执行终结过程(如果有其他终结工作)。
而且对象终结过程会就此结束。未被捕获的异常会使其他对象处于损坏状态。若另一个线程使用这样一个被损坏的对象,不知道会发生什么。
未捕获的异常不会终止
finalize()方法的执行,也不会传播到调用finalize()的线程中。这可能会导致一些关键的清理工作无法完成。通常,未捕获的线程会终止当前线程,并打印栈轨迹信息,但如果其发生在终结方法中,就不会这样,甚至连警告都不会打印。
清理方法没有这个问题因为,使用清理方法的类库可以控制其线程。
严重的性能缺失:
finalize()方法的执行会影响垃圾回收的效率,因为垃圾回收器必须检查每个对象是否需要调用finalize()方法。这会导致性能问题,特别是在大量对象需要回收的情况下。使类易受到终结方法攻击:终结方法使类易受到终结方法攻击。原因:依赖
finalize()释放资源:如果一个类依赖finalize()来释放资源(例如文件句柄、数据库连接等),攻击者可能通过控制对象生命周期,延迟垃圾回收的发生,导致资源没有及时释放,甚至出现资源泄漏。通过继承或修改finalize()来干扰程序:攻击者可以通过子类继承或反射修改finalize()方法的行为,从而干扰正常的资源清理工作。引发异常导致无法清理资源:如果finalize()中出现异常,由于异常不会被报告,程序会继续执行,这可能导致一些关键资源无法正常清理。控制垃圾回收时机:攻击者可能通过某些手段,促使垃圾回收器过度或不必要地调用finalize(),从而引发资源泄漏、性能问题或潜在的攻击面。final类不会受到此类攻击,因为攻击者无法为其编写一个恶意子类,为了保护非final类免受此类攻击,可以在其中编写一个空的final的finalize方法。
②AutoCloseable接口(Closeable子接口)
在
try-with-resources语句中,所有在try语句中声明的资源都必须实现AutoCloseable接口,或者是其子接口。这是因为try-with-resources语句会在try语句块结束时自动调用每个资源的close()方法,因此需要确保该资源具有适当的close()方法。try-with-resources确保即使存在异常也能正常终止。实例必须记录它是否已经被关闭;close方法必须把对象不再有效这个信息记录在一个字段,其他方法必须检查这个字段,这些方法若在对象被关闭后调用,则抛出IllegalStateException。
public class MyResource implements AutoCloseable
{
public MyResource()
{
System.out.println("MyResource opened.");
}
public void doSomething()
{
System.out.println("MyResource is doing something.");
}
@Override
public void close()
{
System.out.println("MyResource closed.");
}
public static void main(String[] args)
{
try (MyResource resource = new MyResource())
{
resource.doSomething();
} catch (Exception e)
{
e.printStackTrace();
}
// MyResource 会在 try 块结束时自动关闭
}
}③终结和清理方法用途
在 Java 安全网(Safety Net)这一上下文中,通常指的是一系列的安全机制、策略和技术,用于保护 Java 应用程序免受潜在的安全威胁,确保系统的可靠性和数据的安全性。Java 安全网的核心目的是确保即使在出现异常、攻击或错误时,系统仍能保持一定的安全性和稳定性。
两个方法用作安全网:以防资源所有者忘记调用其close方法。虽然不能保证这两个方法及时运行或者运行,但客户端忘记释放资源,晚释放强于不释放。
本地对等体对象:本地对等体是一个(非Java)本地对象,普通对象通过本地方法将功能委托给他。因为本地对等体不是普通对象,所以垃圾回收器并不知道其存在,也不能在Java对等体被回收时回收它。若性能可以接受且本地对等体没有持有关键资源,终结或清理方法适合这样的任务,否则用AutoCloseable接口的close方法。
9. 与try-finally相比,首选try-with-resources
①try-finally
try块和finally块中的代码都可能抛出异常,在这种情况下第二个异常会完全掩盖第一个异常,第一个异常不会被记录在异常栈轨迹信息中。
在 Java 中,当一个异常发生时,Java 会创建一个异常对象,并将其信息存储在堆栈中。当一个异常被抛出时,异常堆栈(stack trace)会保存当前线程的堆栈信息。如果
finally块中的代码抛出了一个异常,那么这个异常将会被 Java 捕捉并传递到外部,但此时,try块中的异常被 抑制
//过去是关闭资源最佳方式
如果 br.readLine() 抛出了异常,finally 块中的 br.close() 也可能抛出异常,
导致原本在 try 块中的 IOException 被 br.close() 的异常所掩盖。
static String firstLineOfFile(String path) throws IOException
{
BufferedReader br = new BufferedReader(new FileReader(path));
try
{
return br.readLine();
} finally
{
br.close();
}
}
//当要处理资源不止一个时,很难看
如果 InputStream 或 OutputStream 在 try 块内抛出异常,finally 块的
in.close() 或 out.close() 也可能抛出异常。这样,try 块中的 IOException
可能会被 finally 块中的 close() 抛出的异常所掩盖。
static void copy(String src, String dst) throws IOException
{
InputStream in = new FileInputStream(src);
try
{
OutputStream out = new FileOutputStream(dst);
try
{
byte[] buf = new byte[1024];
int n;
while ((n = in.read(buf)) >= 0)
out.write(buf, 0, n);
} finally
{
out.close();
}
} finally
{
in.close();
}
}②try-with-resources
在
try-with-resources语句中,所有在try语句中声明的资源都必须实现AutoCloseable接口,或者是其子接口。这是因为try-with-resources语句会在try语句块结束时自动调用每个资源的close()方法,因此需要确保该资源具有适当的close()方法。如果try块抛出一个异常,而且close()方法也抛出一个异常,这就会带来一个难题。try-with-resource可以处理这种情况, 原来异常会重新抛出(无捕获下),close方法抛出的异常会被抑制。这些异常将被自动捕获,并由addSuppressed方法添加到原来的异常当中。若想获得这些异常,可用getSuppressed方法,会生成一个数组,其中包含从close方法抛出的被抑制的异常。否则也可以用原来的手动处理这些问题。
//处理单个资源
static String firstLineOfFile(String path) throws IOException
{
try (BufferedReader br = new BufferedReader(new FileReader(path)))
{
return br.readLine();
}
}
//处理多个资源
static void copy(String src, String dst) throws IOException
{
try (InputStream in = new FileInputStream(src);
OutputStream out = new FileOutputStream(dst))
{
byte[] buf = new byte[1024];
int n;
while ((n = in.read(buf)) >= 0)
out.write(buf, 0, n);
}
}
//带catch子句
static String firstLineOfFile2(String path, String defaultValue)
{
try (BufferedReader br = new BufferedReader(new FileReader(path)))
{
return br.readLine();
} catch (IOException e)
{
return defaultValue;
}
}二. 对所有对象都通用的方法
Object是为了扩展而设计的,其所有非final方法都有明确“通用约定”,从设计上讲,这些方法都是希望被重写的。任何重写这些方法的类都有责任遵守其通用约定;若没有遵守,那些依赖这些约定的类(HashMap和HashSet)在使用他们时就无法正常运行。
本章主要讲解何时以及如何重写Object类的非final方法。
1. 在重写equals方法时要遵循通用约定
①不重写equals方法合理情况(满足以下任何一个即可)
该类的每个实例在本质上都是唯一的。例如:对于诸如Thread这样代表活动实体而不是值的类。
该类没有必要提供一个“逻辑相等”的测试。
超类已经重写equals方法,而且其行为适合这个类。
类是私有的或包私有的,可以确信其equals方法绝对不会被调用。
单例类。
-
适合重写equals方法:当一个类在对象相同之外还存在逻辑相等的概念,而且其上层超类都没有重写equals方法时。
②重写equals方法的通用约定
自反性:对于任何非null引用值x, x.equals(x)必须返回true。
对称性:对于任何非null引用值x和y, 当且仅当y.equals(x)返回true时,x.equals(y)必须返回true。
传递性:对于任何非null引用值x和y和z, 若x.equals(y)返回true,且y.equals(z)返回true,那么x.equals(z)必须返回true。
一致性:对于任何非null的引用值x和y, 只要equals比较中用到的信息没有修改,多次调用x.equals(y)必须一致地返回true或一致地返回false。
非空性:对于任何非null的引用值x,x.equals(null)必须返回false。传入null, instanceof检查是false, 不需要显示检查o==null。
③违反实例
没有办法在扩展可实例化的类的同时,既增加值组件,同时又维持equals约定。
使用getClass测试代替instanceof会导致:两个对象只有其实现类相同时才可能相等。破坏里氏代换原则。
里氏代换原则:一个类型的任何重要属性都应该适应于其所有子类型,以便为该类型编写的任何方法在其子类上同样有效。
可以向抽象类的子类中添加值组件而不违反equals约定:只要无法创建超类的实例,就不会出现违反equals问题。
//违反对称性
final class CaseInsensitiveString
{
private String s;
public CaseInsensitiveString(String s)
{
this.s = s;
}
/**
* 违反对称性
* CaseInsensitiveString cis=new CaseInsensitiveString("test");
* String s="test";
* cis.equals(s);//true
* s.equals(cis);//false;
* 虽然CaseInsensitiveString的equals方法知道普通字符串, 但String类的equals
* 方法并不知道这个不区分大小写的字符串
*/
@Override
public boolean equals(Object o)
{
if (o instanceof CaseInsensitiveString)
return s.equalsIgnoreCase(((CaseInsensitiveString) o).s);
if (o instanceof String)
return s.equalsIgnoreCase((String) o);
return false;
}
//改进:将与String相互比较的代码去除
public boolean equals2(Object o)
{
return o instanceof CaseInsensitiveString &&
((CaseInsensitiveString) o).s.equalsIgnoreCase(s);
}
}/**
* 违反传递性
* 子类在超类基础上添加了一个值组件,即:
* 子类添加了会影响equals比较的信息
*/
class Point
{
private final int x;
private final int y;
public Point(int x, int y)
{
this.x = x;
this.y = y;
}
@Override
public boolean equals(Object o)
{
if (!(o instanceof Point))
return false;
Point p = (Point) o;
return p.x == x && p.y == y;
}
//getClass代替instanceof
//违反里氏代换原则
//这回导致只有两个类实现类相等时才可能相等
//Point的某个子类的实例仍为一个Point,而且
//需要表现得和Point一样,若用这个方法无法做到
//因为子类getClass和父类getClass一定不同,无法
//达到逻辑需要上的相同
//Set<Point> s={new Point(1, 0)}
//Point c=new ColorPoint(1, 0)
//我们认为s是包含c的,但是使用这个equals返回false
//若用instanceof就是true了
public boolean equals3(Object o)
{
if (o == null || o.getClass() != getClass())
return false;
Point p = (Point) o;
return p.x == x && p.y == y;
}
}
class ColorPoint extends Point
{
private final Color color;
public ColorPoint(int x, int y, Color color)
{
super(x, y);
this.color = color;
}
//比较一个普通的点和带颜色的点,与反过来结果不同
//前者忽略颜色信息(返回true),后者总是返回false
@Override
public boolean equals(Object o)
{
if (!(o instanceof ColorPoint))
return false;
return super.equals(o) && ((ColorPoint) o).color == color;
}
//混合比较时,让ColorPoint.equals忽略颜色信息
//确实保证了对称性,但是违反了传递性
//ColorPoint p1=new ColorPoint(1, 2, Color.RED)
//Point p2=new Point(1, 2)
//ColorPoint p3=new ColorPoint(1, 2, Color.BLUE)
//p1.equals(p2)和p2.equals(p3)都为true, 但p1.equals(p3)为false
//还可能导致无限递归:假设有两个Point子类,ColorPoint和SmellPoint
//每个类都有个这样的方法,则调用myColorPoint.equals(mySmellPoint)
//会栈溢出,if (!(o instanceof ColorPoint)) return o.equals(this);
//这行代码导致
public boolean equals2(Object o)
{
if (!(o instanceof Point))
return false;
//若o是一个普通Point对象,则比较时不考虑颜色信息
if (!(o instanceof ColorPoint))
return o.equals(this);
//若o是一个ColorPoint对象,则完整比较
return super.equals(o) && ((ColorPoint) o).color == color;
}
}④组合优于继承--在扩展可实例化类同时增加值组件
与其让ColorPoint扩展Point不如为ColorPoint定义一个私有的Point字段并提供一个公有的视图方法(底层数据一样),该方法返回与当前的带颜色的点位置相同的Point对象。
class Point
{
private final int x;
private final int y;
public Point(int x, int y)
{
this.x = x;
this.y = y;
}
@Override
public boolean equals(Object o)
{
if (!(o instanceof Point))
return false;
Point p = (Point) o;
return p.x == x && p.y == y;
}
}
//增加一个值组件,而不破坏equals约定
class ColorPoint
{
private final Point point;
private final Color color;
public ColorPoint(int x, int y, Color color)
{
point = new Point(x, y);
this.color = color;
}
//返回ColorPoint的Point视图
public Point asPoint()
{
return point;
}
@Override
public boolean equals(Object o)
{
if (!(o instanceof ColorPoint))
return false;
ColorPoint cp = (ColorPoint) o;
return cp.point.equals(point) && cp.color.equals(color);
}
}⑤编写equals准则
使用==运算符检查参数是否指向当前对象的引用:若是返回trrue,这为性能优化,若后续进行比较的开销非常大,性能会提示非常大。
使用instanceof检查参数是否具有正确的类型:若不是返回false,正确的类型指这个方法所在的类。偶尔指这个类所实现的某个接口。如果当前类实现的接口细化了equals约定,支持在实现了该接口的多个类之间进行比较,那么就使用接口(例如:Set、List、Map和Map.Entry等集合接口都有这个特性)。
将参数强制转换为正确的类型:因为执行过instanceof,一定会成功。
对于类中的每个重要字段,检查参数的这一字段和当前对象的相应字段是否匹配:
若所有测试都成功了返回true,否则返回false。
若在第2步中用来对采纳数进行检测的类型是一个接口,则必须通过这个接口的方法来访问参数的字段;
若该类型是一个类,可能可以直接访问参数的字段。
若字段类型是float和double之外的基本类型,使用==运算符来比较;
若字段是对象引用类型,递归调用其equals方法;若字段是float类型,使用静态的Float.compare(float, float)方法;
若字段类型是double类型,则使用Double.compare(ddouble, double)方法。
对于数组字段,可以用上面准则处理它每个元素(Array.equals方法来处理)。
一些包含null的对象引用字段可能是合法的,为避免空指针异常,可以使用静态方法Objects.equals(Object, Object)来检查这样的字段是否相等。
对于某些类,如前面的CaseInsensitiveString,字段的比较不是简单的相等性测试。此时,可以考虑存储器字段的一个标准形式,让equals方法在标准形式上进行开销低的精确比较,而不是开销更高的非精确比较。此技术最适合不可变类,若对象可以改变,必须及时更新标准形式。对于一些不可变类,字段的比较可能会有较大的开销,特别是当字段需要进行复杂的比较操作(比如忽略大小写、比较字符串时考虑字符编码等)。在这种情况下,通过将字段转换为一种标准形式,可以使得后续的比较操作变得更加高效。例如,如果类中有一个字段是字符串,并且需要做 不区分大小写 的比较,可以将其存储为 标准化的形式(如全部转为小写或大写),而不是每次比较时都进行转换。
字段比较的顺序也会影响equals方法的性能。为了更好的性能,应该首先比较那些更有可能不同的字段或者比较开销不高的字段。
不要比较不属于对象的逻辑状态的字段(例如用于对操作进行同步的锁字段)。
不需要比较可以从其他“重要字段”计算出来的衍生字段,不过这样做会提升equals方法性能。
若某个衍生字段相当于对整个对象的综合描述,在比较这个衍生字段就能判断不相等的情况下,可以省下对实际数据进行比较的开销。
重写equals方法时,必须重写hashCode方法。
不要自作聪明:不要过度考虑各种相等关系,通常不应该将任何别名考虑在内。例如:File类不应该将多个指向同一文件的符号链接视为相等。
不要将equals方法声明中的Object替换为其他类型:不符合符合 Java 标准;失去多态性和通用性;失去兼容性(Java 的核心类库和框架(如集合类、Java反射机制等)依赖于
equals()方法接受Object类型作为参数);违反最佳实践。考虑Lombok等框架自动生成。
//最佳实践
final class PhoneNumber
{
private final short areaCode, prefix, lineNum;
public PhoneNumber(int areaCode, int prefix, int lineNum)
{
this.areaCode = rangeCheck(areaCode, 999, "area code");
this.prefix = rangeCheck(prefix, 999, "prefix");
this.lineNum = rangeCheck(lineNum, 9999, "line num");
}
private static short rangeCheck(int val, int max, String arg)
{
if (val < 0 || val > max)
throw new IllegalArgumentException(arg + ": " + val);
return (short) val;
}
@Override
public boolean equals(Object o)
{
if (o == this) return true;
if (!(o instanceof PhoneNumber)) return false;
PhoneNumber pn = (PhoneNumber) o;
return pn.lineNum == lineNum &&
pn.prefix == prefix &&
pn.areaCode == areaCode;
}
}2. 重写equals方法时应该总是重写hashCode方法
重写equals方法时应该总是重写hashCode方法,否则违反hashCode通用约定,使得实例无法正常应用于HashMap和HashSet等集合中。
①hashCode通用约定
当在一个对象上重复调用hashCode方法时,只要在equals的比较中用到的信息没有修改,就必须返回同样的值。
若根据equals(Object)方法,两个对象时相等的,则在这两个对象上调用hashCode方法,必须产生同样的整数结果。
若根据equals(Object)方法,两个对象不相等,则在这两个对象上调用hashCode方法,并不要求产生不同的结果。
②实例
Map<PhoneNumber, String> m=new HashMap<PhoneNumber, String>();
m.put(new PhoneNumber("123"), "Samsung");
m.get(new PhoneNumber("123"));
//会返回null, 因为PhoneNumber没有重写hashCode方法,导致存入的桶和查找的桶不是一个 //导致相等的对象有相同的哈希码
//但是每个对象都有相同的哈希码
//每个对象都会存储到同一个桶,
//哈希表退化成了链表,线性时间->平方时间
@Override
public int hashCode()
{
return 42;
}③编写准则


在计算哈希码时可以将衍生字段排除在外,即:若一个字段的值可以通过其他任何字段计算出来,则在计算哈希码的时候可以不考虑它。
在equals比较中没有用到的任何字段,也必须排除在外。
步骤2.b中的乘法使得哈希值依赖于字段处理顺序,若类中有多个类似的字段,这样可以得到更好的哈希函数。例如:若将String的哈希函数中的乘法去掉,那么只是字母顺序不同的所有字符串都会有相同的哈希码。
选择31是因为其是奇素数。若选择了偶数,并且乘法溢出,就会丢失信息,因为乘2相当于移位。
若类不可变,且计算哈希的开销很大,可以将哈希码缓存在对象中。若认为这个类型的大多数对象都会被用作哈希键,应该在实例创建时将哈希码计算出来,否则选择将哈希码的初始化延迟到hashCode方法第一次被调用时。延迟初始化要注意线程安全。hashCode字段的初始值不应该为某个常见实例的哈希码。
不要为了提升性能而将重要字段排除在哈希码的计算之外。
不要为hashCode返回的值提供详细的说明,这样客户端就不能理所当然的依赖它了;我们也可以灵活的修改。
final class PhoneNumber
{
private final short areaCode, prefix, lineNum;
public PhoneNumber(int areaCode, int prefix, int lineNum)
{
this.areaCode = rangeCheck(areaCode, 999, "area code");
this.prefix = rangeCheck(prefix, 999, "prefix");
this.lineNum = rangeCheck(lineNum, 9999, "line num");
}
private static short rangeCheck(int val, int max, String arg)
{
if (val < 0 || val > max)
throw new IllegalArgumentException(arg + ": " + val);
return (short) val;
}
@Override
public boolean equals(Object o)
{
if (o == this) return true;
if (!(o instanceof PhoneNumber)) return false;
PhoneNumber pn = (PhoneNumber) o;
return pn.lineNum == lineNum &&
pn.prefix == prefix &&
pn.areaCode == areaCode;
}
//根据准则完美实现
@Override
public int hashCode()
{
int result = Short.hashCode(areaCode);
result = 31 * result + Integer.hashCode(prefix);
result = 31 * result + Integer.hashCode(lineNum);
return result;
}
/**
* 使用Objects静态方法计算哈希函数
* 性能一般因为会创建衣蛾传递数量的可变参数的数组
* 若有基本类型的参数,还会涉及自动装箱和自动拆箱
*/
public int hashCode2()
{
return Objects.hash(areaCode, prefix, lineNum);
}
/**
* 缓存哈希值,延迟初始化
*/
private int hashCode;//自动初始化为0
public int hashCode3()
{
int result = hashCode;
if (result == 0)
{
result = Short.hashCode(areaCode);
result = 31 * result + Integer.hashCode(prefix);
result = 31 * result + Integer.hashCode(lineNum);
hashCode = result;
}
return result;
}
}3. 总是重写toString方法
虽然Object类提供了toString方法的一个实现,但其返回的字符串通常不是类的用户所希望看到的。
提供一个好的toString实现可以让类使用更舒适,使用该类的系统也更容易调试。
若条件允许,toString方法应该返回当前对象中包含的所有有意义的信息。
是否在文档中指定返回值的格式,对于值类(如电话号码或矩阵类)建议这样做。其好处为,该格式可以作为一种标准的、明确的、适合人阅读的对象表示,这种表示可用于输入和输出,还可用于持久化、适合人阅读的数据对象中。若指定了格式,最好提供一个匹配的静态工厂或构造器,以便在对象和其字符串表示之间来回转换。缺点为:若该类被广泛使用,一旦指定了格式,就会受制于格式。
无论是否决定指示格式,应该在文档中清晰表明自己的意图。
无论是否指定格式,都应该为toString返回值中包含的信息提供编程访问方式(getter等方法)。若不提供,程序员不得不自己解析字符串。
在静态工具类中编写toString方法无意义。对于大多数枚举类型,也不应该为其编写toString方法,因为 Java 默认会为所有枚举类型提供一个
toString()方法。对于子类会共享同样的字符串表示形式的任何抽象类,都应该为其提供toString方法(例如:大部分集合实现中的toString方法都是从抽象的集合类继承而来的)。
4. 谨慎重写clone方法
①Cloneable接口
Mixin是一种编程概念,通常用于实现类的功能扩展。它允许你将某些功能或行为"混入"到现有的类中,从而避免了多重继承的复杂性。Cloneable接口本想成为类的一个mixin接口,表明这样的类支持克隆。但是由于该接口缺少一个clone方法,而Object类的clone方法是受保护的,其目的没有实现。若不借助反射,并不能因为一个对象实现了该接口就在其上调用clone方法。即使借助反射来调用,也有可能失败,因为无法保证这个对象存在可访问的clone方法。
Cloneable接口作用:虽然该接口中没有任何方法,但对于Object类中受保护的clone实现而言,这个接口决定了其行为:若类实现了Cloneable,Object的clone方法会返回当前对象的一个逐字段复制而来的副本;否则就会抛出CloneNotSupportedException。
实现Cloneable接口的类应该提供一个可以正常运作的、公有的clone方法。
②clone方法通约
创建并返回该对象的副本。副本的含义取决于该对象的类。一般含义是,对于任何对象x:
x.clone()!=x将为true。
x.clone().getClass()==x.getClass()将为true。(并非绝对要求)
x.clone().equals(x)为true(非绝对要求)
按照惯例。这个方法返回的对象应该通过调用super.clone()来获得。若类以及所有超类(Objecct除外)都遵循这个约定,上面第二个表达式为true。若类的clone方法返回的实例不是通过调用super.clone获得的,而是通过调用构造器,编译器不会报错,但会影响这个类的子类,当子类的clone方法调用super.clone时,生成对象的类型会是错误的,子类的clone方法不能正常工作。
按照惯例,返回的对象与被克隆的对象应该是相互独立的。
不可变类不应该提供clone方法,纯属浪费。
③克隆相关问题
浅拷贝:默认的
clone()是浅拷贝。对象内部的引用字段不会被递归克隆(可以手动递归调用clone实现深拷贝),原对象和克隆对象共享引用字段。深拷贝:深拷贝需要手动实现,将引用类型字段也克隆。
Java 中更推荐使用拷贝构造器或序列化方式来实现深拷贝。
同构造器,clone方法不能在仍处于构造过程中的克隆体上调用可重写的方法。因为克隆的对象在构造过程中,调用可重写的方法可能会导致不正确的行为。可重写的方法依赖于对象的实例状态,而此时实例状态尚未完全初始化。在对象的构造过程完成之前调用这些方法,可能会导致对未初始化字段的引用,或访问到不完整的对象状态,这可能会引发异常或错误的行为。
Object的clone方法会被声明为会抛出CloneNotSupportException,但重写方法无需这样。公有的clone方法应该去掉throws子句,不抛出检查型异常使其更易用。
在设计用于被继承的类,不应该实现Cloneable接口。当基类实现
Cloneable接口时,意味着所有继承该基类的子类都会继承这个行为。如果子类没有克隆的需求,但由于继承了基类,依然会被迫实现clone()方法或者继承Cloneable接口。这会导致不必要的耦合。可以选择实现一个功能正常的受保护的clone方法,并声明抛出CloneNotSupportedException,来模仿Object行为,这样子类可以自由选择实现或不实现Cloneable接口,就像直接扩展Object一样。或者,可以选择不实现功能正常的clone方法,而且也不让子类实现它,可以通过下面退化的clone实现来做到:用于不支持Cloneable的可扩展类中的clone方法@Override public final Object clone() throws CloneNotSupportedException { throw new CloneNotSupportedException(); }若要编写一个实现了Cloneable接口的线程安全的类,这个类的clone方法必须正确的进行同步处理。Object的clone方法不是同步的,所以即使其实现满足要求,也必须编写一个同步的clone方法,让其返回super.clone。
所有实现Cloneable的类都应该用一个返回类型为类本身的公有方法来重写clone。这个方法首先应该调用super.clone,然后修复任何需要修复的字段。
若类只包含基本类型字段或指向不可变对象的引用,可能无需修复任何字段。但一个代表序列号或其他唯一ID的字段,即使它是基本类型或不可变的,也需要修复。
实现对象复制的更好方式:复制构造器(拷贝构造器)和复制工厂和序列化。复制构造器是一个只接受一个参数,且该参数的类型就是该构造器所在的类的构造器或接口
public Yum(Yum yum){}。复制工厂是与复制构造器类似的静态工厂(一1)public static Yum newInstance(Yum yum)。与Cloneable/clone相比,复制构造器方式及其静态工厂有以下优点:他们不依赖于Java核心语言之外的、存在风险的对象创建机制;他们不需要遵守基本没有文档说明的约定,更何况这样的约定没法强制实施;他们与final字段的正常使用没有冲突;他们不会抛出不必要的检查型异常;他们不需要类型转换。
数组的clone是浅拷贝。
5. 考虑实现Comparable接口
①Comparable接口
本节讨论的方法与前面不同的是,compareTo方法不是在Object类中声明的,其是Comparable接口中唯一的方法。其与Object的equals方法有相似之处,只是除了简单的相等性比较外,还支持顺序比较,且为泛型方法。
类中实现了Comparable接口,就表示其实例具有自然排序。
②Comparable接口通约


equals方法是在所有对象上施加了一个全局相等的关系,与其不同的是,compareTo方法不必在不同类型的对象之间进行比较:当遇到不同类型的对象时,compareTo可以抛出ClassCastException。
违反compareTo约定,可能破坏其他依赖比较的类,如TreeSet、TreeMap,以及工具类Collections和Arrays,这些类包含查找和排序算法。
这几个通约造成的结果是,由compareTo方法所施加的相等性测试,必须遵守equals约定所施加的相同限制:自反性、对称性和传递性。因此:除非愿意放弃面向对象的抽象机制所带来的优势,否则没办法在扩展了可实例化的类并增加了新的值组件的同时又维持compareTo约定。同样的变通:若想向一个实现了Comparable的类中增加一个值组件,不要扩展它,而是要写一个不相关的类让他包含第一个类的一个实例。然后提供一个视图方法来返回所包含的实例。
最后一条,若一个类的compareTo方法所施加的排序与equals方法不一致,它仍可以工作,但是以这个类的对象为元素的有序集合未必能遵守相应集合接口(Collection、Set、Map)的通约了。因为这些接口的通约是通过equals定义的,但有序集合的相等性测是由compareTo得到的,而不是equals。
例如:以BigDecimal为例,其compareTo方法就与equals方法不一致。若创建一个空HashSet实例,然后将
new BigDecimal("1.0")和new BigDecimal("1.00")添加进去,这个集合将包含两个元素,因为添加到这个集合中的两个BigDecimal实例在使用equals方法比较时是不相等的。但是若使用TreeSet来进行相同操作,那么这个集合将只包含一个元素,因为用compareTo方法来比较这两个BigDecimal实例时,他们是相等的。在compareTo方法中,字段被比较的是顺序而不是是否相等,要比较对象引用字段,可递归调用他们的comapreTo方法。
在Java7中所有基本类型的封装类都添加了静态的compare方法。在compareTo中使用<和>非常繁琐,且容易出错,不再推荐,而是用compare。
若类有多个重要字段,可以从最重要的字段开始,然后继续进行。
③Comparator
在Java8中,Comparator接口配备了一组比较构造器方法,然后这些比较器可以用来实现Comparable接口所要求的compareTo方法(compareTo方法调用Comparator)。
Comparator提供了很多静态方法,返回比较器。
偶尔会看到,使用两个值的差来实现compareTo或compare方法:这种方式,存在整数溢出和IEEE754浮点运算问题的风险。
建议,要么使用静态的compare方法(封装类提供),要么使用比较器的构造方法(静态方法)。
compareTo方法调用Comparator
public class Test implements Comparable<PhoneNumber>
{
private static final Comparator<PhoneNumber> COMPARATOR =
Comparator.comparingInt(pn -> pn.areaCode)
.thenComparingInt(pn -> pn.prefix);
@Override
public int compareTo(PhoneNumber pn)
{
return COMPARATOR.compare(this, pn);
}
}//不建议的方式,会破坏传递性
static Comparator<Object> hashCodeOrder = new Comparator<Object>()
{
@Override
public int compare(Object o1, Object o2)
{
return o1.hashCode()-o2.hashCode();
}
};//使用静态的compare方法比较器
static Comparator<Object> hashCodeOrder = new Comparator<Object>()
{
@Override
public int compare(Object o1, Object o2)
{
return Integer.compare(o1.hashCode(), o2.hashCode());
}
};//基于比较器构造方法的比较器
static Comparator<Object> hashCodeOrder = Comparator.comparingInt(o -> o.hashCode());Comparator接口的一些常用静态方法:
comparing() 方法用于创建一个 Comparator,它根据指定的键比较器(即一个可以从对象中提取一个键的函数)来比较对象。
static <T, U extends Comparable<? super U>> Comparator<T> comparing(Function<? super T, ? extends U> keyExtractor)
class Person
{
String name;
int age;
Person(String name, int age)
{
this.name = name;
this.age = age;
}
@Override
public String toString()
{
return name + " (" + age + ")";
}
}
public class Main
{
public static void main(String[] args)
{
List<Person> people = Arrays.asList(
new Person("Alice", 30),
new Person("Bob", 25),
new Person("Charlie", 35)
);
// 按年龄升序排序
people.sort(Comparator.comparing(person -> person.age));
System.out.println(people);
}
}
[Bob (25), Alice (30), Charlie (35)]comparingInt(), comparingDouble(), comparingLong(), int可以用于short等更债的,double可以用于float
这些方法是 comparing() 方法的简化版本,用于针对 int、double 和 long 类型进行比较。
class Person
{
String name;
int age;
Person(String name, int age)
{
this.name = name;
this.age = age;
}
@Override
public String toString()
{
return name + " (" + age + ")";
}
}
public class Main
{
public static void main(String[] args)
{
List<Person> people = Arrays.asList(
new Person("Alice", 30),
new Person("Bob", 25),
new Person("Charlie", 35)
);
// 使用 comparingInt 按年龄升序排序
people.sort(Comparator.comparingInt(person -> person.age));
System.out.println(people);
}
}
[Bob (25), Alice (30), Charlie (35)]thenComparing()
thenComparing() 方法用于在主要比较相等的情况下,进一步按次要标准进行比较。它可以与其他 Comparator 链接,以形成复合比较器。
default <U> Comparator<T> thenComparing(Comparator<? super T, ? super U> otherComparator)
class Person
{
String name;
int age;
Person(String name, int age)
{
this.name = name;
this.age = age;
}
@Override
public String toString()
{
return name + " (" + age + ")";
}
}
public class Main
{
public static void main(String[] args)
{
List<Person> people = Arrays.asList(
new Person("Alice", 30),
new Person("Bob", 30),
new Person("Charlie", 25)
);
// 先按年龄升序排序,如果年龄相同,则按名字升序排序
people.sort(Comparator.comparingInt(person -> person.age)
.thenComparing(person -> person.name));
System.out.println(people);
}
}
[Charlie (25), Alice (30), Bob (30)]reversed()
reversed() 方法用于返回当前 Comparator 的反转版本,即将升序变为降序,或者将降序变为升序。
class Person
{
String name;
int age;
Person(String name, int age)
{
this.name = name;
this.age = age;
}
@Override
public String toString()
{
return name + " (" + age + ")";
}
}
public class Main
{
public static void main(String[] args)
{
List<Person> people = Arrays.asList(
new Person("Alice", 30),
new Person("Bob", 25),
new Person("Charlie", 35)
);
// 按年龄降序排序
people.sort(Comparator.comparingInt(person -> person.age).reversed());
System.out.println(people);
}
}
[Charlie (35), Alice (30), Bob (25)]nullsFirst() 和 nullsLast()
这两个方法用于处理 null 值的比较。默认情况下,Comparator 会将 null 排在最后面。
使用 nullsFirst() 可以将 null 排在前面,nullsLast() 可以确保 null 排在最后。
class Person
{
String name;
Integer age;
Person(String name, Integer age)
{
this.name = name;
this.age = age;
}
@Override
public String toString()
{
return name + " (" + age + ")";
}
}
public class Main
{
public static void main(String[] args)
{
List<Person> people = Arrays.asList(
new Person("Alice", 30),
new Person("Bob", null),
new Person("Charlie", 25)
);
// 按年龄升序排序,null值排到前面
people.sort(Comparator.comparingInt((Person p) -> p.age != null ? p.age : Integer.MAX_VALUE).nullsFirst());
System.out.println(people);
}
}
[Bob (null), Charlie (25), Alice (30)]三. 类和接口
1. 最小化类和成员的可访问性
①访问控制机制
封装(信息隐藏):设计良好的组件会隐藏其所有实现细节,并将API与实现清晰的隔离,组之间仅通过他们的API进行通信,而对彼此的内部工作一无所知。
尽可能使每个类或成员不可访问:在能让我们所写的软件正常运行的前提下,尽可能降低访问级别。
对于顶层(非嵌套的)类和接口,只有两种可能访问级别:包私有的和公有的。对于顶层类和接口,
protected和private访问级别是不可用的。protected是用于限制成员的访问,使得成员在同一包或子类中可见,但顶层类的继承并不会受限于包,因此不能限制类本身。private类是完全封闭的,只能在当前类中访问。如果顶层类是private,那么它就无法被其他类访问,这会导致设计上的不合理,因为顶层类本来就应该能被其他类(至少同一包内的类)使用。对于一个包私有的顶层类或接口,若只有一个类用到了它,可以考虑将其设计为这个唯一使用了它的类的静态私有嵌套类。
公有类是包的api的一部分,而包私有的顶层类已经是实现的一部分:
当一个类被声明为
public时,它意味着该类是包的 公共接口(API)的一部分。这意味着:可被外部访问:该类可以被任何其他包中的代码使用,只要通过适当的
import语句导入。对外暴露功能:公有类的设计往往是为外部代码提供功能、服务或数据模型。因此,类的可见性需要放宽,以便在外部系统中进行访问和交互。
API 设计:当你设计一个包的公共接口时,公有类是整个包的外部接口的一部分。它提供了包的核心功能,外部代码能够访问这些类来实现其自己的需求。
当一个类是包私有的(即没有显式的访问修饰符,或者使用
package-private作为访问级别)时,它仅在同一包内可见。这种类通常是该包的 实现的一部分,而不是对外暴露的 API。仅供内部使用:包私有类用于包内部的逻辑实现,不应当被外部代码直接访问。它们的存在是为了支持包内的功能实现,但不应暴露给包外的其他代码。
实现细节:包私有类通常是实现细节的一部分,它们实现了公有类或接口所暴露的功能,但不应暴露给外部系统。这有助于封装内部实现,减少不必要的依赖。
四种访问级别,按照可访问性递增顺序如下:
private(私有):被声明为private的成员只能在同一类内部访问。它对于外部类、同包中的其他类、子类都不可见。default(包私有):如果没有显式指定访问修饰符,Java 会将成员的访问级别默认为 包私有(default),即该成员只能在同一包内的类中访问。protected(受保护):被声明为protected的成员可以在同一个包内的类中访问,并且在不同包的子类中也可以访问。public(公有):任何类、接口、方法、变量被声明为public,意味着它们可以在任何地方被访问。
若一个方法重写了超类方法,则这个方法在子类中的访问级别不能比在超类中的访问级别更严格:这是为了确保子类在任何使用超类实例的地方都能使用。
公有类的实例字段尽量不要设计为公有的:这样导致放弃对这个字段中可以保存什么值进行限制的能力。因此,带有公有可变字段的类通常不是线程安全的。即使一个字段是final的,并且引用了一个不可变对象,若将其设计为公有的,则当想去掉这个字段转而采用新的内部数据表示时,就没有这样的灵活性了。
静态字段尽量不要设计为公有的:但有一个例外,可以通过公有的静态final字段来暴露常量,前提是这些常量是这个类所提供的抽象的必要组成部分。这些字段的名称全为大写字母,单词之间用下划线分割。这些字段包含的要么是基本类型的值,要么时指向不可变对象的引用。若字段包含的是指向可变对象的引用,就会存在非final字段的缺点,虽然这个引用不能修改,但是被引用的对象能被修改。
一个长度不为0的数组总是可以修改的,所以若类有一个公有的静态final数组字段,或有一个返回者类字段的访问器方法,这样设计是错误的。IDE生成的访问器方法会返回对私有数组的引用,会导致这个问题。一种方式是把公有数组变成私有的,并添加一个公有的不可变列表,另一种方法是把数组变为私有的,并添加一个公有方法,让其返回该私有数组的一个副本。
//法一
返回的 List 不能进行结构修改(如添加或删除元素),
但是你可以修改列表中对象的内部状态(如果这些对象本身是可变的)。
private static final Thing[] PRIVATE_VALUES = {};
public static final List<Thing> VALUES =
Collections.unmodifiableList(Arrays.asList(PRIVATE_VALUES));
//法二
private static final Thing[] PRIVATE_VALUES = {};
public static final Thing[] values()
{
return PRIVATE_VALUES.clone();
}
数组本身:PRIVATE_VALUES.clone() 创建了一个新的数组对象,
所以 原数组和返回的副本指向不同的数组对象。修改返回的副本中的数组元素 不会影响原数组。
数组元素(对象引用):如果 Thing 是一个对象类型(而不是基本类型),
那么数组中的元素是 对象的引用,而不是对象本身。
因此,返回的数组中的元素仍然是指向原始 Thing 对象的引用。
如果你修改了返回副本数组中某个元素的内容(例如,修改 Thing 对象的字段),
这将会影响原数组中对应的元素,因为它们指向相同的对象。②模块系统(Java9)(除非迫切需要,否则最好不要使用)
Java 模块系统(Java Platform Module System,简称 JPMS)是在 Java 9 中引入的,它为 Java 平台提供了一个新的 模块化 机制。模块系统的目标是使 Java 应用程序能够更加可维护、可扩展,同时提供更强的封装性和模块间的依赖管理。
模块系统带来另外两个隐式访问级别。模块是一组包,就像包是一组类。一个模块可以通过其模块声明中的导出声明显式的导出其某些包。按惯例, 模块声明通常会包含在一个名为moudle-info.java的源文件中。模块中未导出的包中的公有成员和受保护成员,在模块外不可访问;在模块内,可访问性不受导出声明影响。
2. 在公有类中,使用访问器方法,而不使用公有的字段
若类在包外可以访问,就提供访问器方法:应该总是用私有的字段和公有的访问器方法,对于可变类,则提供修改器方法。
对于包私有的类或私有的嵌套类,暴露其数据字段本质上无问题:与使用访问器方法相比,这种方式写的代码更清晰。虽然客户端代码和这个类的实现被绑定到了一起,但是这些代码被限制在该类所在的包中,修改这个类的内部表示,不会触及包外任何代码。对于私有的嵌套类,修改的范围更是被进一步限制在它所在的包围类中。
公有类永远不该暴露可变字段,暴露不可变字段危害会小一些,但仍值得怀疑。
对于包私有的类或私有的嵌套类而言,无论字段是可变的还是不可变的,有时暴露它是可取的。
3. 使可变性最小化
①不可变类
定义:不可变类是指实例无法修改的类,每个实例包含的所有信息在这个对象的整个生命周期中都是固定的。
Java类库中的不可变类:String、基本类型的封装类、BigInteger和BigDecimal等。
优点:与可变类相比,不可变类更容易设计、实现和使用,且不容易出错,更加安全。
成为不可变类规则:
不要提供修改对象状态的方法。
确保这个类不能被扩展:这样可以防止粗心或恶意实现的子类的实例改变了状态,进而破坏依赖该类的不可变行为的代码。一般通过将类声明为final类型来防止子类化或将其所有的构造器设计为私有的或包私有的,并添加静态工厂(一1)代替公有的构造器。
将所有字段都声明为final类型:
将所有字段都声明为私有的:虽然不可变类从技术上讲可以有公有的final类型的字段,只要他们包含的是基本类型的值,或是指向不可变对象的引用,但这样做会阻止在后续版本修改该类的内部表示。
确保对任何可变组件的独占访问:若类中存在任何指向可变对象的字段,应该确保该类的用户无法获得指向这些对象的引用。不要将这样的字段初始化为用户提供的对象引用,也不要将其从访问器方法返回给用户。在构造器、访问器方法和readObject方法中进行保护性复制。
//不可变复数类
public final class Complex
{
private final double re;
private final double im;
public Complex(double re, double im)
{
this.re = re;
this.im = im;
}
public double realPart()
{
return re;
}
public double imaginaryPart()
{
return im;
}
/**
* 这里加减乘除创建并返回一个新的Complex实例,而不是修改当前实例
* 这种模式被称为函数式方式。
*
* 四则运算方法的名称使用的是介词plus而不是动词add
*/
public Complex plus(Complex c)
{
return new Complex(re + c.re, im + c.im);
}
public Complex minus(Complex c)
{
return new Complex(re - c.re, im - c.im);
}
public Complex times(Complex c)
{
return new Complex(re * c.re - im * c.im,
re * c.im + im * c.re);
}
public Complex divideBy(Complex c)
{
double tmp = c.re * c.re + c.im * c.im;
return new Complex((re * c.re + im * c.im) / tmp,
(im * c.re - re * c.im) / tmp);
}
}②不可变性优缺点
类的不变式(Class Invariant)是指在类的所有方法执行过程中,类的对象应该始终保持满足的一组条件或约束。换句话说,不变式是类在任何时刻都必须满足的条件,它保证了对象状态的一致性和有效性。
不变式可以看作是对类内部数据的约束条件,它描述了类的合法状态。类的不变式通常在以下几个方面体现:
对象状态一致性:类的属性必须在有效范围内,不允许出现非法或不一致的值。
数据结构的有效性:对于集合类或容器类,数据结构应该始终保持有效,比如链表中的每个节点应该始终指向下一个有效节点。
线程安全性:对于多线程环境下的类,不变式要求类的状态在并发访问时不受破坏。
优点:
不可变对象很简单:不可变对象只能处于一种它被创建时的状态。若能确保所有的构造器都建立了类的不变式,则可以保证这些不变式始终成立。
不可变对象本质上是线程安全的,不需要同步:因而不可变对象可以自由的共享。因此,不可变类鼓励客户端尽可能复用现有实例,一个简单做法是为常用值提供公有的静态常量,这种方法进一步扩展就是不可变类提供静态工厂,将经常被请求的实例缓存下来;所有的基本类型的封装类和BigInteger类都是这样做的。设计新类时,提供静态工厂而不是公有的构造器,可以以后再添加缓存,而无需修改客户端代码,非常灵活。
永远无需对其进行保护性复制:因为其可自由的共享。就算复制了,这些副本和原始对象也一定相等。 因此不应该在不可变类上提供clone方法或复制构造器。(Stringq确实有一个复制构造器,但应该尽量少用)
除了可以共享不可变对象,不可变对象之间还可以共享它们的内部数据:例如,BigInteger类内部使用符号数值表示法,符号由一个int表示,数值由一个int数组表示。negate方法会生成一个新的BigInteger,其和原来的对象数值相同,但符号相反。它无需复制数值数组,即使其是可变的;新创建的BigInteger对象和原始对象会指向同一个内部数组。
无论是可变对象还是不可变对象,都可以将不可变对象当作其构建块:若知道一个复杂对象的组件不会发生改变,则这个复杂对象的不变式维护起来很容易。比如:不可变对象非常适合做Map的键和Set的元素:若把可变对象放入Map或Set中,还要担心对象的值变了会破坏Map和Set不变式。因为
Map和Set都依赖于对象的 哈希码 和 相等性 来确保它们的操作(如查找、插入、删除)正确且高效。如果你将一个 可变对象 放入Map或Set中,并在之后修改这个对象的值,就可能会破坏这些数据结构的 不变式,导致潜在的错误和不一致的行为。不可变对象自然保证了故障原子性:因为其状态永远不会改变,因此不存在临时不一致的可能性。故障原子性是在系统发生故障时保证操作的原子性的一种扩展。在分布式系统或者多层次事务处理中,某些操作可能会失败或出现中断。在这种情况下,故障原子性确保了操作要么完全生效,要么完全回滚,即使在操作的某个中间步骤发生故障时,系统也不会进入不一致的状态。
缺点:
不可变类需要为每个不同的值创建一个单独的对象:创建这些对象的开销可能很大,特别是大型对象(BigInteger等)。
若执行的是一个多步操作,且每步操作都会生成一个新对象的话,除了最后的结果,所有对象最终都会抛弃,性能问题将会放大:
第一种解决方案:猜测客户端通常需要执行哪些多步操作,并将其作为原语提供,这样这个不可变类就不必在每步操作中创建单独的对象了。
第二种解决方案:提供一个公有的可变伴生类:String类和其可变伴生类StringBuilder(还有过时的前身StringBuffer)。
StringBuilder用于拼接字符串,然后通过toString()将结果转换为String,在后续处理中使用不可变的String对象。
③确保这个类不能被扩展
有效final:如果一个局部变量在声明后没有被修改过,那么它就是“有效 final”的,意味着它的值在方法执行期间不会改变。
不可变类是有效 final” 这个说法是指,不可变类的实例一旦被创建,其状态(即对象的属性值)就不能再被修改。这种特性使得不可变类的行为在某种程度上等同于
final类,即它们无法在实例化后发生变化。
一般通过将类声明为final类型来防止子类化或将其所有的构造器设计为私有的或包私有的,并添加静态工厂(一1)代替公有的构造器(最佳选择)。
第二种方式是最佳选择,因为其允许使用多个包私有的实现类(protcted私有构造器+静态工厂返回不同子类),最为灵活。对其所在的包之外的客户端,这个不可变类是有效final的,因为不可能扩展来自另一个包中的、没有提供公有的或受保护的构造器的类。除了支持存在多个实现类的灵活性外,这种方式还是得后续版本中通过改进静态工厂的对象缓存能力来进行优化的可能。
//用静态工厂代替构造器的不可变类
class Complex
{
private final double re;
private final double im;
private Complex(double re, double im)
{
this.re = re;
this.im = im;
}
public static Complex valueOf(double re, double im)
{
return new Complex(re, im);
}
}BigInteger和BigDecimal不是有效final,这些类的所有方法都是可重写的。若要写一个这样的类,其安全性依赖于BigInteger和BigDecimal参数的不可变性,并且参数来自于不可信的客户端,则必须检查该参数是否为真正的BigInteger或BigDecimal,而不是他们的某个不可信的子类的实例。若为后者,则必须基于“这个对象有可能改变”这样的假设,进行保护性复制。
public static BigInteger safeInstance(BigInteger val)
{
return val.getClass() == BigInteger.class ?
val : new BigInteger(val.toByteArray());
}④注意
序列化:若选择让自己的不可变类实现Serializable接口,而且类中包含一个或多个指向可变对象的字段,即使默认序列化形式可以接受,也必须提供一个显式的readObject或readResolve方法,或使用ObjectOutputStream.writeUnshared和ObjectInputStream.readUnshared方法。否则攻击者有可能创建这个不可变类的一个可变实例。
假设我们有一个不可变类
Person,它包含一个Date类型的字段(Date是可变的)。当Person对象被序列化后,如果我们没有正确处理Date字段的序列化过程,那么攻击者可能通过反序列化对象后修改Date对象的状态,从而破坏Person对象的不可变性。
public class ImmutablePerson implements Serializable
{
private final String name;
private final Date birthDate;
// 构造器初始化字段
public ImmutablePerson(String name, Date birthDate)
{
this.name = name;
// 重要:创建一个副本,而不是直接引用原始 Date 对象
this.birthDate = new Date(birthDate.getTime()); // 深拷贝
}
// getter 方法
public String getName()
{
return name;
}
public Date getBirthDate()
{
// 返回 birthDate 的副本,而不是直接返回原始对象
return new Date(birthDate.getTime());
}
// 提供显式的 readObject 方法,确保安全的反序列化
private void readObject(ObjectInputStream ois) throws IOException, ClassNotFoundException
{
ois.defaultReadObject(); // 进行默认的反序列化
// 确保 birthDate 始终是不可变的副本
birthDate = new Date(birthDate.getTime());
}
// 提供一个 readResolve 方法来确保反序列化后的对象始终返回一个相同的实例
private Object readResolve()
{
return new ImmutablePerson(name, birthDate);
}
public static void main(String[] args) throws Exception
{
// 创建不可变对象
ImmutablePerson person = new ImmutablePerson("Alice", new Date());
// 序列化到文件
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("person.ser")))
{
oos.writeObject(person);
}
// 从文件反序列化
ImmutablePerson deserializedPerson;
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("person.ser")))
{
deserializedPerson = (ImmutablePerson) ois.readObject();
}
// 输出序列化后的对象的状态
System.out.println("Name: " + deserializedPerson.getName());
System.out.println("Birth Date: " + deserializedPerson.getBirthDate());
}
}除非有充足理由,否则应该将类设计为不可变的:应该总是小型值对象设计为不可变的;对于大型对象应考虑设计为不可变的,仅当需要性能达标时,才为不可变类提供公有的可变伴生类。
若类无法被设计为不可变的,应该尽可能限制其可变性:除非有充足理由将字段设计为非final的,否则每个字段都应为final, 结合三1,应为private final。
构造器应该创建完全初始化的对象,并建立起所有的不变式:除非有充足理由,否则不要提供一个独立于构造器和静态工厂的公有初始化方法;也不要为了支持重复使用对象而提供一个“重新初始化”方法。
4. 组合优先于继承(仅限于类继承类,不含类实现接口,接口扩展接口)
在同一个包内使用继承是安全的,因为子类和父类的实现都在同一批程序员控制下。
对于专为扩展而设计并提供了文档说明的类,使用继承机制来扩展他是安全的。
继承别的包中的普通具体类存在危险。
①继承缺点
继承会破坏封装:
访问权限暴露:在子类中,你可以访问父类的
protected和public成员。这意味着父类的实现细节可能被暴露给子类,从而破坏了封装性。如果父类的某些成员变量或方法不应该被外部访问,却被子类访问或修改,就会违反封装的原则。内部实现暴露:子类继承父类时,如果父类暴露了实现细节,子类可能会依赖这些细节。这使得父类的实现修改时,可能会影响到子类,从而导致不易维护和扩展的情况,违背了封装的初衷。
父类修改影响子类:如果父类对某个字段或方法进行了修改或替换,而子类依赖于这些修改,可能会破坏子类的封装和稳定性,导致子类的行为不一致。
重写问题:子类重写父类的方法可能产生逻辑问题。
如何避免继承破坏封装:
尽量使用
private和protected字段:在父类中,使用private修饰字段和方法,只有通过public或protected的getter和setter方法来暴露必要的信息和操作。使用接口或抽象类:通过接口或抽象类来定义公共行为,而避免暴露不必要的实现细节。这有助于子类在继承时只关注接口或抽象方法,而不是具体实现。
避免滥用继承:继承是为了表达“是一个”的关系,如果类之间的关系不合适,考虑使用组合(
has-a关系)而非继承,减少直接继承带来的封装破坏。
假定创建了一个类,继承了HashSet,并且重写了add和addAll方法,使其能够记录自创建依赖添加了多少个元素:
另一个问题:超类有可能在后续版本加入新方法:假设有个程序,其安全性依赖于所有被插入集合中的元素都要满足某个谓词条件。可以这样保证:设计这个集合的一个子类,重写每个能添加元素的方法,在添加元素前确保其满足谓词条件。若超类后续版本加入一个能插入元素的新方法,此时若调用子类没有重写的新方法,就可能导致添加非法元素。
若子类只是添加新方法,而不重写现有方法,仍会存在问题。若后续,超类加入一个新方法,这个方法和我们实现继承时子类中加入的方法签名一样,但返回类型不同,那么子类就无法再通过编译了。若方法签名和返回类型都一样,就又需要重写了。
//存在问题,不恰当的使用了继承
//自身使用问题
class InstrumentedHashSet<E> extends HashSet<E>
{
//尝试插入元素的数量
private int addCount = 0;
@Override
public boolean add(E e)
{
++addCount;
return super.add(e);
}
/**
* 若使用该方法,添加3个元素。
* 本来期望getAddCount方法返回3,但是返回了6.
* 因为HashSet的addAll方法是基于add方法实现的。
*
* 在InstrumentedHashSet中,addAll方法将3加到addCount
* 上,然后使用super.addAll调用HashSet的addAll实现。
* 而HashSet的addAll实现在每次添加元素时会反过来调用InstrumentedHashSet
* 的add方法,每次调用又向addCount加1,
*/
@Override
public boolean addAll(Collection<? extends E> c)
{
addCount+=c.size();
return super.addAll(c);
}
public int getAddCount()
{
return addCount;
}
}②使用组合代替继承
组合:不扩展现有类,而是在类中提供一个私有字段,让他引用现有类的实例。这样创建的类非常牢靠,不会依赖现有类(父类)的实现细节。新类中的实例方法都会调用所包含的现有类的实例上的相应方法,并返回结果,这被称为转发,新类中的方法被称为转发方法。
InstrumentedHashSet类被称为包装器类,因为其包装了Set类。这样被称为装饰模式。包装器类不适合用于回调框架,在这种框架中,对象需要将自身引用传递给其他对象,以供后续回调。因为被包装的对象不知道包装器对象的存在,它会将自身的引用传递进去,回调就绕过了包装器对象了。
//可复用转发类
//转发类只是包含所有的转发方法
class ForwardingSet<E> implements Set<E>
{
private final Set<E> s;
public ForwardingSet(Set<E> s)
{
this.s = s;
}
@Override
public int size()
{
return s.size();
}
@Override
public boolean isEmpty()
{
return s.isEmpty();
}
@Override
public boolean contains(Object o)
{
return s.contains(o);
}
//....
}
//包装器类--使用组合来代替继承
class InstrumentedHashSet<E> extends ForwardingSet<E>
{
//尝试插入元素的数量
private int addCount = 0;
public InstrumentedHashSet(Set<E> s)
{
super(s);
}
@Override
public boolean add(E e)
{
++addCount;
return super.add(e);
}
@Override
public boolean addAll(Collection<? extends E> c)
{
addCount+=c.size();
return super.addAll(c);
}
public int getAddCount()
{
return addCount;
}
//...
}③何时使用继承
只有子类确实是超类的子类型,继承才是合适的:对于A和B两个类,只有当两者之间存在
"is-a"关系(子类是父类的一种类型,因此可以说子类是父类的一种)时,类B才应该扩展类A。若不能保证上述关系,B应该包含一个私有的A实例,并提供一个不同的API:A不是B的构成要素,而只是其实现的一个细节。
在决定继承代替组合前,应该考虑父类API是否有弊端,若有,是否愿意让这些缺陷传播到子类的API。继承会向下传播超类API的任何缺陷,而组合可以让你设计一个新的API来隐藏这些缺陷。
5. 要么为继承而设计提供文档说明,要么就禁止继承
类必须将存在自身使用可重写方法的情况写在说明文档中:对于每个公有的或受保护的方法,文档必须说明这个方法会调用哪些可重写(非final的公有或受保护的方法)方法,会议什么样的顺序调用,以及每次调用的结果对后续处理有何影响(用Implementation Requirements来标记)。Implementation Requirements违反了好的API文档应该描述的是给定方法会做什么,而不是怎么做。这是继承破坏封装带来的负面影响。为了使类可以被安全的子类化,必须在文档中描述根本不需要指明的细节。
类可能必须以谨慎选择的受保护的方法(极少数情况下甚至是受保护的字段)的形式提供进入其内部的钩子:例如,java.util.AbstractList的removeRange方法。这个方法对某个List实现的最终用户而言没有什么意义,之所以提供这个方法,只是为了方便子类在子列表上提供一个快速的clear方法。如何决定对外暴露哪些受保护的成员呢?认真思考、尽力猜测、然后编写子类来测试。
要测试一个为继承而设计的类,唯一的方式就是编写子类:三个子类足以测试一个可扩展的类。
构造器不得直接或间接调用可重写的方法:超类的构造器会在子类的构造器之前运行,所以子类重写的方法会在子类构造器运行之前被调用。若重写的方法依赖于子类构造器执行的任何初始化操作,则该方法的行为将于预期不符。
从构造器中调用私有的方法、final方法和静态方法是安全的,因为这些方法都不可重写。
在设计用于继承的类时,Cloneable和Serializable接口会带来特殊困难,通常不建议设计用于继承的类实现这两个接口,因为其会为扩展该类的程序员带来很大困难。但是,可以采取一些特殊措施来允许子类实现这些接口,而不是强制其实现。这些措施在二4和十一2有描述。
若决定让设计用于继承的类实现Cloneable和Serializable,应注意,clone和readObject方法行为很像构造器,所以clone和readObject不得直接或间接调用可重写的方法。在readObject方法的情况下,重写方法将在子类的状态被反序列化完毕前运行(父类的
readObject方法会先于子类的readObject方法执行)。在clone方法下,重写的方法将在子类的cone方法有机会修复克隆体的状态之前运行(clone方法的调用顺序是父类的clone方法先于子类的clone方法执行)。若决定让设计用于继承的类实现Serializable,并且这个类中存在readResolve或writeReplace,则必须将这些方法设置为受保护的,而不是私有的。若这些方法是私有的,他们将被子类忽略。设置为受保护的,子类可以调用或重写这两个方法,这样可以确保序列化和反序列化的行为在继承体系中正常工作。
对于并非为可以安全的子类化而设计并提供文档说明的类,禁止对其子类化:一般通过将类声明为final类型来防止子类化或将其所有的构造器设计为私有的或包私有的,并添加静态工厂(一1)代替公有的构造器(最佳选择)。
很多程序员习惯了对于普通的具体类进行子类化,以增加功能或限制功能。若一个类实现了某个能体现其核心功能的接口,如Set、List、Map,则应该禁止子类化。若需要增加功能三4中的包装器模式更好。
若一个具体类没有实现某个标准接口,禁止继承可能会带来不便。若必须允许继承这样的类,合理的方式是确保该类永远不会调用它的任何可重写方法(也是上面实现核心接口不能继承的原因,因为核心接口的方法调用了可重写方法),并将其写入文档。完全避免自身使用可重写方法的情况,则重写一个方法永远不会影响其他任何方法的行为。
一种机械的方式去掉其中自身使用可重写方法的情况:将每个可重写方法的方法体移到一个私有的辅助方法,并让每个可重写方法调用其私有的辅助方法。然后对于存在自身使用可重写方法的情况,都直接调用对应的私有辅助方法来替代。
6. 与抽象类相比优先选择接口
①接口优点
很容易改造现有的类使其实现一个新接口:添加必需的方法(若不存在)并在类声明中添加一个implements子句。
接口是定义mixin(混合类型)的理想选择:类只有单继承,而接口可以多实现。mixin是一个类型,类在实现其主要类型外,还可实现一个这样的类型,以表明他能提供某个可选行为。
接口允许构建非层次结构的类型框架:不是所有事物都适合用类型层次结构来组织。例如:有一个代表歌手的接口Singer, 还有一个代表词曲创作人的接口Songwriter。在现实中,有些歌手也是创做人,由于是接口而不是抽象类,所以可以让一个类同时实现这两个接口。
通过包装器类(三4)习惯用法,接口可以实安全且强大的功能增强:使用接口和包装器类的组合来增强功能是一种常见的设计模式,通常被称为装饰者模式(Decorator Pattern)。包装器类通过组合原始对象的方式,提供增强的功能而不直接修改原始对象的代码。这种方式的关键是通过接口来定义行为,并通过包装器类来增强或修改这些行为。若使用抽象类来定义类型,只能使用继承,与包装器类相比,这样的类更为脆弱(继承的缺点)。
②默认方法
若一个接口方法很明显可以基于其他接口方法实现,应该考虑以默认方法的形式实现(程序员不用再去从头构思和编写那些可以通过已有接口方法组合或者推导得出的功能代码)。
对于来自Object类的方法,尽管很多接口都明确包含了这样的方法并具体指定了其行为,但我们不能为其提供默认方法。
不能为一个不归我们控制的接口添加默认方法。
③模板方法模式
模板方法模式:通过提供一个与接口配合的抽象的‘骨架实现’类,可以将接口和抽象类的优点结合在一起。接口用来定义类型,可能会提供一些默认方法,骨架类负责在基本接口方法之上实现其余的非基本接口方法。扩展骨架可以省去实现接口的大部分工作。
按照惯例,骨架会命名为AbstractInterface,Interface是它所实现的接口的名字。例如,Java集合框架为每个主要集合接口提供了一个骨架实现:AbstractCollection、AbstrractSet等。骨架实现(无论是单独的抽象类还是仅由接口中的默认方法组成)可以使程序员轻松提供自己的接口实现。
骨架实现类提供了抽象类的所有实现帮助,但又不存在将抽象类用于类型定义时的严格限制。对于配备了骨架实现类的接口来说,通常实现者扩展这个骨架实现类;若一个类不能扩展骨架实现类,也可以直接实现接口,接口本身的默认方法还是能简化实现的。
模拟多重继承:实现该接口的类可以引入一个私有的、扩展了骨架实现类的内部类,并包含一个这个内部类的实例,然后将对接口的方法的调用转发给这个实例。与包装器类模式密切相关,其提供了多重继承的许多好处,同时避免了其缺点。
//下面静态工厂方法中包含了一个基于
//AbstractList构建的,完整的,全功能的List实现
//构建于骨架实现之上的具体实现
static List<Integer> intArrayAsList(int[] a)
{
return new AbstractList<Integer>()//大部分List的方法骨架都实现了
{
@Override
public Integer get(int i)
{
return a[i];
}
@Override
public int size()
{
return a.length;
}
};
}骨架实现视为继承设计的,应遵守三5。
骨架实现变体:简单实现:AbstractMap.SimpeEntry:与骨架实现类似,也实现了接口。而且是为继承设计的,不同之处在于其不是抽象的。
要支持多种实现类型,接口通常是最佳选择,若接口很复杂,考虑提供一个骨架实现。在可能情况下,应该通过接口上的默认方法来提供骨架实现,以便该接口的所有实现者都可以使用。即使如此,接口上的限制通常会使得抽象类形式成为骨架实现的最佳选择。
编写骨架实现:
决定接口中哪些方法是基本方法,其他方法可以基于这些基本方法来实现,这些基本方法将成为骨架实现中的抽象方法。
在接口中为所有可以直接基于基本方法实现的方法提供默认方法,但不要为Object类的方法提供默认方法。(基本方法不提供默认实现:接口的主要目的是为不同的实现提供统一的抽象,不同的类可以根据自己的需求实现接口的具体行为。如果所有的方法都提供默认实现,接口就变成了类似抽象类的角色,可能会导致设计上的混乱,使得接口和抽象类的职责模糊不清。)
若基本方法和默认方法涵盖了接口的所有方法,则无需骨架实现类。
否则,编写一个类,让其实现这个接口,然后实现剩下的所有接口方法(通用方法,不会影响子类扩展灵活性,例如记录日志等操作,不会影响核心业务逻辑,这也是为啥不实现基本方法的原因,可能会影响子类灵活性),这个类可以包含实现该任务所需的任何非公有的字段和方法。
//骨架实现类
//考虑Map.Entry<K, V>接口,显然,基本方法是getKey、getValue、(可选的)setValue
//该接口明确指定了equals和hashCode的行为,并且有一个明显的基于基本方法的toString实现
//由于不能为Object方法提供默认实现,所以所有的实现都放在骨架实现类中了
//这个骨架实现不能在Map.Entry接口中实现,也不能实现为子接口,因为默认方法不能重写Object类方法。
abstract class AbstractMapEntry<K, V> implements Map.Entry<K, V>
{
//可修改的Map中Entry必须重写该方法
@Override
public V setValue(V value)
{
throw new UnsupportedOperationException();
}
//实现Map.Entry,equals的通用约定
@Override
public boolean equals(Object o)
{
if (o == this) return true;
if (!(o instanceof Map.Entry)) return false;
Map.Entry<?, ?> e = (Map.Entry<?, ?>) o;
return Objects.equals(getKey(), e.getKey()) && Objects.equals(getValue(), e.getValue());
}
//实现Map.Entry.hashCode的通约
@Override
public int hashCode()
{
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
@Override
public String toString()
{
return getKey() + "=" + getValue();
}
}7. 为传诸后世而设计接口
Java8前不可能在不破坏现有实现的情况下向接口中添加新方法,若向接口中添加了新方法,现有实现通常会缺少这个方法,导致编译错误。
Java8引入默认方法,目的就是允许像现有的接口添加方法,但这是非常危险的。默认方法包含一个默认实现,所有实现了这个接口但没有实现该默认方法的类都会使用它。默认方法是在实现者并不知情也无许可下被注入到现有实现的,无法保证这些方法在所有预先存在的实现中都能工作。
在存在默认方法情况下,一个接口现有实现可能在编译时没有错误或警告,但在运行时却失败了:除非必须,否则应该避免使用默认方法向现有接口中添加新方法。
默认方法不支持从接口中删除方法或改变现有方法签名。
编写一个默认方法,使其能够保证每个可以想到的实现的所有不变式,未必总能做到。例如:org.apache.commons.collections4.collection.SynchronizedCollection, 它是一个包装器类,其所有的方法在委托给被包装的集合之前都会在某个锁定的对象上同步。但其并没有重写removeIf方法,若这个类与Java 8一起使用,它将继承removeIf默认实现,但默认实现不能维护这个类的基本承诺:自动对每个方法调用同步。
为了防止上述情况在类似的Java平台类库发生,例如由Collections.synchronizedCollection返回的包私有类,JDK维护者不得不重写默认的removeIf及其其他类似方法,以便在调用默认实现之前执行必要的同步,不属于Java平台的集合就没有这样的机会了。
8. 接口仅用于定义类型
当一个类实现了一个接口时,该接口可以充当引用这个类的实例的类型。类实现了某个接口,表明客户端可以使用这个类的实例实施某些动作,为其他任何目的定义接口都是不合适的。
①常量接口反模式-不要使用
常量接口:这种接口不含任何方法,只由静态的final字段组成,每个字段都导出一个常量。需要使用这些常量的类会实现该接口,这样就不用通过类名来线段常量名了。
常量接口模式是对接口的不恰当使用:类在内部使用常量属于实现细节。实现常量接口会导致实现细节泄露到该类的导出API中。类实现了常量接口,对这个类的用户来说是没有什么价值的。更坏的是,它代表了一种承诺:若在未来版本中,类被修改,不再需要使用这些常量,但是为了确保二进制兼容(二进制兼容性是指已经编译的类文件(字节码)与新版本的库能够正常运行,而无需重新编译。为了确保兼容性,即使在未来版本中某些类或接口的设计发生了变化,Java 的规范建议保留旧的接口或类,以避免对现有代码造成破坏。),它仍然必须实现这个接口。若一个非final类实现了一个常量接口,那么其所有子类的命名空间都会被接口中的常量污染。
//常量接口-不要使用
interface Constants
{
static final double AVOGADROS_NUMBER = 6.022_140_857e23;
}导出常量合理的选择:
若这些常量与现有的类或接口密切相关,则应该将其添加到类或接口中。例如:所有的数值基本类型的封装类,如Integer导出了MIN_VALUE和MAX_VALUE.
若这些常量最好被视为某个枚举类型的成员,应该用enum导出。
否则应该用一个不可实例化的工具类来导出常量(一4)。
②常量工具类
数字字面常量中使用的下划线,其为Java7开始支持的语法,对值无影响,可以提高可读性。
若数字字面常量的位数不低于5,无论是定点数还是浮点数都可以加。
对于十进制数字字面常量,无论是整数还是浮点数,都应该用下划线将其按三维一组来分割。
class Constants
{
private Constants()
{
//阻止实例化
}
public static final double AVOGADROS_NUMBER = 6.022_140_857e23;
}③使用静态导入避免完全限定名
class Constants
{
private Constants()
{
//阻止实例化
}
public static final double AVOGADROS_NUMBER = 6.022_140_857e23;
}
import static Constants.*;
public class Test
{
public static void main(String[] args)
{
System.out.println(AVOGADROS_NUMBER);//不用类名限定了
}
}9. 优先使用类层次结构而不是标记类
①标记类
存在这样的类,它的实例有两种或更多的种类,类中会包含一个标记字段来指示这个实例的具体种类。
缺点:冗长、容易出错、效率低下。
充斥样板代码,包括枚举声明、标记字段和条件语句。
多个实现混杂在一个类中,影响可读性。
实例要担属其他种类不相关字段,内存占用增加。
由于构造器不能初始化不相关字段,所以字段不能设置为final的,会带来更多样板代码。
构造器必须设置标记字段,并且要初始化正确的字段,但这无法利用编译器来提供帮助。
若添加新种类,必须在每个switch语句中添加一个case。
但从实例的数据类型看不出具体种类。
//标记类
class Figure
{
enum Shape
{RECTANCLE, CIRCLE}
;
//标记字段--该图的形状
final Shape shape;
//仅当shape为RECTANCLE时,才使用这些字段
double length;
double width;
//当shape为CIRCLE时,使用该字段
double radius;
//圆形的构造器
Figure(double radius)
{
shape = Shape.CIRCLE;
this.radius = radius;
}
//矩形的构造器
Figure(double length, double width)
{
shape = Shape.RECTANCLE;
this.length = length;
this.width = width;
}
double area()
{
switch (shape)
{
case RECTANCLE:
return length * width;
case CIRCLE:
return Math.PI * radius * radius;
default:
throw new AssertionError(shape);
}
}
}②类层次结构
当遇到一个标记类时,考虑将其重构成一个层次结构。
优点:
修正了标记类的缺点。
可以反映类型之间的自然层次关系,有助于增加灵活性,并有助于更好的编译时类型检查。
abstract class Figure
{
abstract double area();
}
class Circle extends Figure
{
final double radius;
Circle(double radius)
{
this.radius = radius;
}
@Override
double area()
{
return Math.PI * radius * radius;
}
}
class Rectangle extends Figure
{
final double width;
final double height;
Rectangle(double width, double height)
{
this.width = width;
this.height = height;
}
@Override
double area()
{
return width * height;
}
}10. 与非静态成员类相比,优先选择静态成员类
一个嵌套类应该只是服务于它的包围类,若一个嵌套类在其他上下文也有应用,其应该设计为顶层类。
①静态成员类
最好将其视为一个普通类,只是声明在另一个类中,可以访问包围类的所有成员,即使是声明为私有成员。
静态成员类是其包围类的静态成员,并遵守与其他静态成员相同的可访问性规则。
若静态成员类被声明为私有的,则只能在包围类内部访问,以此类推。
常见用途:作为一个公有辅助类,仅配合其包围类一起使用。例如,考虑一个描述计算器所支持的操作的枚举,Operation枚举应该是Calculator类的一个公有的静态成员。然后可以使用Calculatro.Operation.PLUS这些的名字来引用这些操作。
若成员类不需要访问包围实例,应总是将static修饰符放在他的声明中,使其成为静态成员类,而不是非静态成员类。若为非静态成员类,不仅每个实例包含额外引用,需要额外空间和时间。此外,当包围实例符合垃圾收集的条件时,可能因为这个引用保留下来,会造成内存泄露。
②非静态成员类
对于非静态成员类,其每个实例都会隐含的关联一个其包围类的实例。可以使用限定性this语法来调用其包围类实例的方法,或获得指向其包围类的实例的引用。
若嵌套类的实例可以独立于其包围类实例存在,则必须将其设计为静态成员类:没有包围类的实例是不可能创建出非静态成员类的实例的。
非静态成员类的实例与其包围类的实例之间的关联是在成员类实例创建时建立的,此后无法修改。通常,在包围类的实例方法内调用了非静态成员类的构造器时,其值关联会自动建立起来。也可使用表达式enclosingInstance.newMemberClass(args)手动建立,但很少使用。这种关联会占用非静态成员类实例的空间,还会增加其构建时间。
常见用途1:非静态成员类:定义适配器:它允许将包围类的实例视为某个不相关的类的实例。例如,Map接口的实现通常使用非静态成员类来实现其集合视图,这些视图由Map的KeySet、entrySet和Values方法返回。
常见用途2:私有静态成员类:表示其包围类所表示对象的组件。
若内部类是导出类的公有的或受保护的成员,选择静态成员类和非静态成员类就更重要。此时,成员类是导出的API元素,并且不能在后续版本中将其从非静态成员类改成静态成员类,否则破坏向后兼容性。
③匿名内部类
匿名类没有名字,不是包围类的成员,它不是和其他成员一起声明的,而是在使用的地方同时进行了声明和实例化。
代码中可以使用表达式的地方就可以使用匿名类。
当且仅当出现在非静态的上下文中时,匿名类才有包围实例。
即使出现在静态的上下文中,除了常量(即用常量表达式初始化的final的基本类型或字符串类型的字段)之外,匿名类中不能存在任何静态成员。
常见用途:
在Lambda表达式加入Java前,匿名类是临时创建小型函数对象和过程对象的首选,现在Lambda是首选。
另一个用途是实现静态工厂方法(三6③的initArrayAsList)。
使用限制:
除了在匿名类声明的地方,无法实例化它。
无法执行instanceof测试,也不能做任何需要用类名来引用它的事情。
不能声明一个匿名类来实现多个接口,也不能同时扩展一个类并实现一个接口。
除了从超类型继承而来的成员,客户端不能调用匿名类的任何成员。
由于匿名类出现在表达式中,所以其必须简短,否则会影响可读性。
④局部类
在任何可以声明局部变量的地方,几乎都可以声明局部类,其遵守同样的作用域规则。
局部类和其他嵌套类有一些共同属性:像成员类一样,局部类有名字,可以重复使用;像匿名类一样,局部类只有在非静态上下文中定义时才有包围实例,并且不能含静态成员,且应该尽量简短,以免影响可读性。
11. 将源文件限制为单个顶层类
永远不要将多个顶层类或接口放在一个源文件中,遵循这个规则可以确保在编译时不会出现单个类重复定义问题,这反过来又保证了编译生成的类文件和所得到的程序的行为都不会受到源文件传递给编译器时的顺序的影响。
①问题
尽管Java编译器允许单个源文件定义多个顶层类,但这样做存在重大风险。因为在一个源文件定义多个顶层类,可能会导致为一个类提供了多个定义,哪一个定义被使用,取决于传递给编译器的源文件的顺序。
例如:存在这样一个源文件,其只包含一个Main类,而Main类又引用了另外两个顶层类(Utensil和Dessert)的成员。假设在一个名为Utensil.java的源文件中定义了Utensil和Dessery这两个类;又在一个名为Dessert.java的源文件,定义了同样的两个类。
若使用了javac Main.java Dessert.java这个命令编译程序,会编译失败,编译器提醒重复定义了Utensil和Dessert这两个类。这是因为编译器会先编译Main.java,在看到对Utensil的引用时(位于Dessert的引用之前), 他会去Utensil.java中查找这个类,并找到了Uttensil和Dessert。当编译器在命令行中遇到Dessert.java时,他也会拉入该文件,导致它遇到了Utensil和Dessert的定义。
若使用命令javac Main.java或javac Main.java Utensil.java编译程序,和编写Dessert.java文件之前一样,仍会输出pancake。但是如果使用命令javac Dessert.java Main.java编译程序,则会输出potpie。因此,程序的行为受到了传递给编译器的源文件的顺序的影响,显然不可接受。
public class Main
{
public static void main(String[] args)
{
System.out.println(Utensil.NAME+Dessert.NAME);
}
}//Utensil.java
class Utensil
{
static final String NAME = "pan";
}
class Dessert
{
static final String NAME = "cake";
}//Dessert.java
class Utensil
{
static final String NAME = "pot";
}
class Dessert
{
static final String NAME = "pie";
}②解决方案
将顶层类(在例子中是Utensil和Dessrt)分别放到单独的源文件中。
若很想把多个顶层类放在一个源文件中,可以考虑使用静态成员类。同时可以将其声明为私有的来降低这些类的可访问性。
public class Main
{
public static void main(String[] args)
{
System.out.println(Utensil.NAME + Dessert.NAME);
}
private static class Utensil
{
static final String NAME = "pan";
}
private static class Dessert
{
static final String NAME = "cake";
}
}四. 泛型
1. 不要使用原始类型
泛型类和接口统称为泛型类型。
泛型类或接口就是声明中存在一个或多个类型参数的类或接口。例如,List接口有单个类型参数E,表示其元素类型。接口全名是List<E>。
参数化类型:先是类或接口的名字,后面是尖括号,尖括号中是由于泛型类型的形式类型参数对应的实际类型参数组成的列表。例如,List<String>
原始类型:不带任何实际类型参数,而是直接使用泛型类型的名称。例如,List<String>对应的原始类型是List,这是类型擦除机制实现的。原始类型之所以存在,主要是为了兼容引入泛型前的代码。
如果使用原始类型,就会失去泛型在安全性和表现力等方面的所有优势:List中实际插入Integer,但是需要的是String,编译时检查不出来,直到运行时把实际Integer当成String调用方法才会异常。
若想使用一个泛型类型,但不知道或不关心实际类型参数是什么,可以使用一个问号代替。List<?>:任何类型放入一个原始类型的集合中,容易破坏集合的类型不变式;但是不能把任何元素(除了null)放入一个Collection<?>中。
Set<Object>表示可以包含任何类型对象的集合(可添加);Set<?>是通配符类型,表示只能包含某些位置类型对象的集合(不可添加,元素在创建时得到);而Set是原始类型,脱离了泛型类型系统。前两者安全,后者不安全。
例外:在class字面量中必须使用原始类型,Java语言规范不允许在这里使用参数化类型(尽管允许使用数组类型和基本类型)。即:List.class,String[].class,int.class都是合法的,但List<String>.class和List<?>.class不合法。
第二个例外与instanceof有关,因为类型擦除,所以除了无限制的通配符类型,在参数化类型上使用instanceof运算符是不合法的。使用无限制的通配符类型代替原始类型不会对instanceof运算符的行为产生任何影响,在此情况,尖括号和问号显得多余。下面是使用instanceof运算符处理泛型类型的首选方式:
//一旦确定o是一个Set,必须将其强制转换为通配符类型Set<?>,
//而不是原始类型,因为是一个检查型转换,所以不会导致编译器警告
if (o instanceof Set)//原始类型
{
Set<?> s = (Set<?>) o;//通配符类型
}


2. 消除unchecked类型的警告
①unchecked类型的编译器警告
当使用泛型编程时,会有许多unchecked类型的编译器警告:未经检查的转换警告、方法调用未经检查警告、未经检查的转换警告、未经检查的参数化可变参数类型警告。
尽其所能消除unchecked警告:若消除了所有警告,可以确信代码是类型安全的,在运行时不会遇到ClassCastException。
Set<Lark> s=new HashSet<>(), 编译器会自动推断出后面尖括号的类型。
②抑制警告:@SuppressWarings
若无法消除某个警告,但可以证明引发该警告的代码是类型安全的,那么(只有在这种情况下)可以使用@SuppressWarings("unchecked")注解来抑制此警告:若在未证明代码安全就抑制了警告,运行时还是会有问题。若证明了代码安全但没抑制,则新警告出现时可能注意不到。
SuppressWarings注解可以用在任何声明上,从单个局部变量到整个类,应该总是在尽可能小的范围内使用SuppressWarings注解:适合的情况通常就是一个变量声明,或者一个非常短的方法或构造器。不要在整个类上使用,可能会掩盖重要警告。
每次使用@SuppressWarnings("unchecked")注解时,应该添加注释,说明为什么这样做是安全的。
若发现在超过一行的方法或构造器上使用了SuppressWarings注解,可以将其移到一个局部变量声明上,即使不得不声明一个新的局部变量:
//ArrayList的方法
public <T> T[] toArray(T[] a)
{
if (a.length < size)
// Make a new array of a's runtime type, but my contents:
//下面返回语句会产生警告: [unchecked] unchecked cast
//在返回语句上使用SuppressWarings注解是不合法的,
//你可能想把这个注解放在整个方法上,但不要这么做
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}
*****
//ArrayList的方法
public <T> T[] toArray(T[] a)
{
if (a.length < size)
{
//这个转换是正确的,因为正在创建的数组和传入的
//数组类型相同,可以抑制
//这样的方法可以编译,且被抑制的[unchecked]警告的作用范围最小化了
@SuppressWarnings("unchecked")
T[] result = (T[]) Arrays.copyOf(elementData, size, a.getClass());
return result;
}
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}3. 列表优先于数组
①协变、逆变、不变
协变:复杂类型保留了简单类型之间的子类型关系。例如:数组是协变的,若Sub是Super的子类型,那么数组Sub[]就是数组类型Super[]的子类型。
逆变:逆转了子类型关系。
不变:不是以上两者。例如:泛型是不变的:对于任何两个不同类型Type1和Type2,List<Type1>既不是List<Type2>的子类型,也不是他的超类型。
②区别1:数组是协变的,泛型类型是逆变的
下面无论哪种方式都无法将String放到容器中,但数组要到运行时才能发现错误,而列表在编译时就能发现错误。
//代码合法,但运行时会失败
Object[] objectArray = new Long[1];
objectArray[0] = "I don't fit in";//ArrayStoreException
//无法编译
List<Object> ol = new ArrayList<Long>();//不兼容的类型
ol.add("I don't fit in");②区别2:数组是具体化的,泛型是擦除实现的
数组在运行时知道其元素类型而且会执行类型约束。
而泛型是通过擦除实现的,他们只在编译时执行其类型约束,而在运行时会丢弃其元素类型信息。擦除使得泛型类型与不使用泛型的遗留代码自由的进行互操作,确保遗留代码可以过度到Java5中的泛型。
③禁止创建泛型数组
由于以上差异,数组和泛型不能混用在一起。例如,创建泛型类型、参数化类型或类型参数的数组都是不合法的:new List<E>[ ]、new List<String>[ ]和new E[ ]这些数组创建表达式都是不合法的,会在编译时导致泛型数组错误。
若其是合法的,可能会导致在运行时出现ClassCastExcption。
E、List<E>、List<String>这些类型技术上称为不可具体化类型,即:运行时表示所包含的信息比其编译时表示要少的类型。
唯一可具体化的参数化类型是无限制的通配符类型,如List<?>和Map<?,?>, 因为其表示任何类型。
禁止创建泛型数组导致泛型集合通常不可能返回其元素类型的数组(参考四8解决方案);且当可变参数方法与泛型类型结合时会警告,因为调用可变参数方法时,编译器会创建一个数组来保存可变参数,若这个数组的元素类型是不可具体化的,会产生一个警告,可以使用SafeVargs注解来解决这个问题。
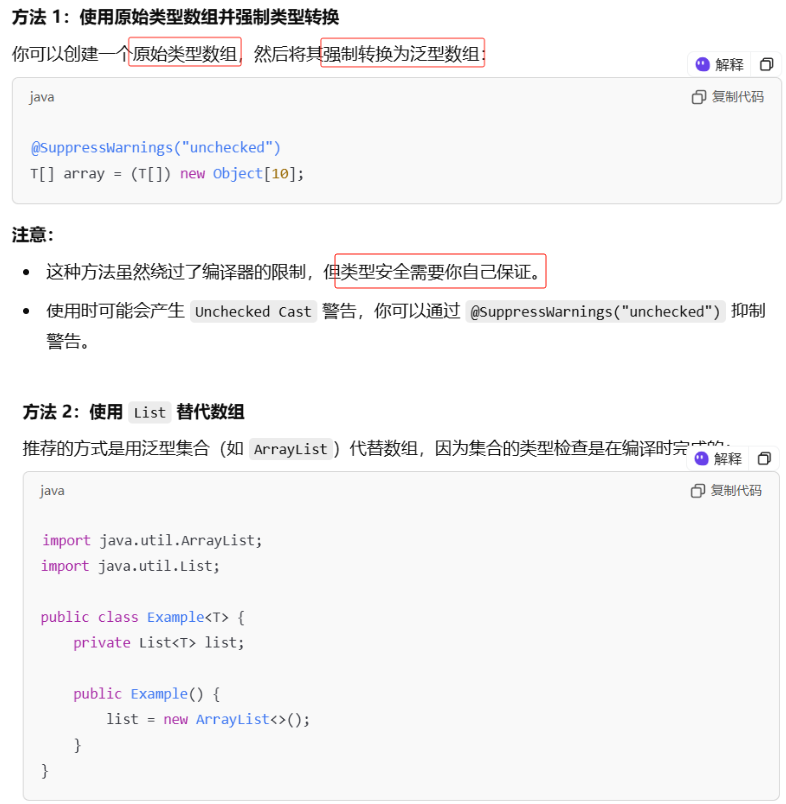
在强制转换数组类型时,若遇到泛型数组创建错误或未经检查的转换警告,最好解决方案是用集合类型List<E>, 而不是数组类型E[ ], 另一种是(T[ ])new Object[ ], 或将其数组元素类型从E[ ]改为Object[ ]。
/**
* 假设第1行创建的泛型数组是合法的
* 2合法,3因为数组协变也合法
* 4合法,因为泛型是类型擦除实现,List<Integer>运行时是List, List<String>[]运行时是List[]
* 5错误,ClassCastException
* 为了防止5发生,编译器不允许1出现,编译错误
*/
List<String>[] stringLists=new List<String>[1];//1
List<Integer> intList=List.of(42);//2
Object[] objects=stringLists; //3
objects[0]=intList;//4
String s=stringLists[0].get(0);//54. 首选泛型类型
与需要在客户端代码中进行强制类型转换的类型相比,泛型类型更安全且更容易使用。
在设计新类时,通常将其设计为泛型类型;若有任何一个现有的类型本应该是泛型类型,但实际不是,就将其泛型化,这将使这些类型的新用户使用更容易,且不会破坏已有客户端。
5. 首选泛型方法
泛型方法与泛型类型一样,与需要客户端对输出参数和返回值进行显示的强制类型转换相比,他们更安全易用。就像类型一样,应该确保自己的方法不需要强制类型转换就能使用,通常意味着使其成为泛型方法。而且像类型一样,应该将需要强制类型转换才能使用的现有方法泛型化,使得新用户使用更方便,同时不会破坏现有的客户端。
①简单示例
用于声明类型参数的类型参数列表应该放在方法的修饰符和返回类型之间。
//不要使用原始类型,不能保证类型转换安全
public static Set union(Set s1, Set s2)
{
Set result = new HashSet(s1);
result.addAll(s2);
return result;
}
//安全的
//不足:3个Set的类型必须完全相同,可以使用有限制的通配符类型,让其更为灵活
public static <E> Set<E> union2(Set<E> s1, Set<E> s2)
{
Set<E> result = new HashSet<>(s1);
result.addAll(s2);
return result;
}②泛型单例工厂
泛型单例工厂:有时需要创建一个不可变但又可用于许多不同类型的对象。由于泛型是通过擦除实现的,因此可以用一个对象来满足所有必要的类型参数化场景,但需要一个静态工厂方法,以便为每个请求的类型参数化场景重复分配该对象。这种主要用于函数对象,如Collections.reverseOrder或集合Collections.emptySet。
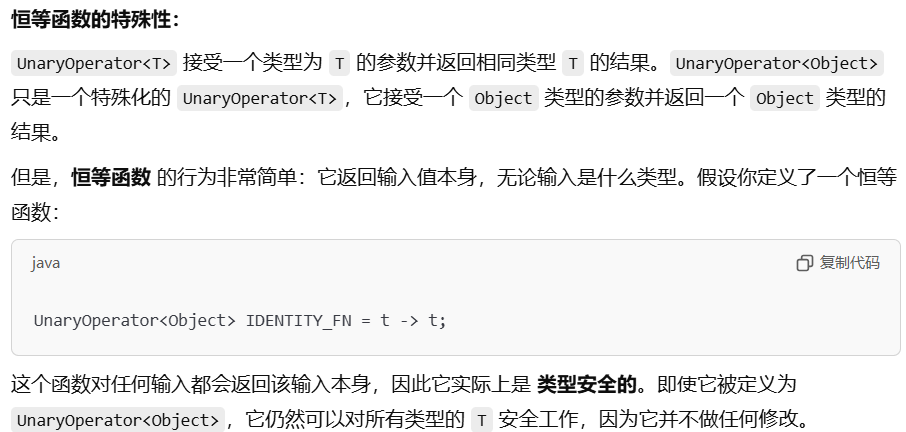
假设要编写一个恒等函数分发器,Java类库中提供了Function.identity, 因此无需自己编写,但可以从其实现方式得到启发。若每次请求时都创建一个新的函数,由于其是无状态的,非常浪费。若Java泛型可以被具体化,那么每个类型都需要一个恒等函数,但因为泛型信息会被擦除,所以一个泛型单例足够了。


public class Test
{
public static void main(String[] args)
{
//练习泛型单例的示例程序
String[] strings = {"jute", "hemp", "nylon"};
UnaryOperator<String> sameString = identityFunction();
for (String s : strings)
System.out.println(sameString.apply(s));
Number[] numbers = {1, 2.0, 3L};
UnaryOperator<Number> sameNumber = identityFunction();
for (Number n : numbers)
sameNumber.apply(n);
}
/**
* UnaryOperator<T> 是一个泛型接口,它接收并返回同一个类型 T。
* 而 IDENTITY_FN 是一个接受任意类型的 Object 类型并返回该类型本身的恒等函数,
* 尽管我们在定义时声明了它为 UnaryOperator<Object>,但它实际上的行为就是返回输入的值,
* 因此它对于所有类型都安全。不会引入类型不匹配,因为它总是返回输入的类型。
* <p>
* 因此,你可以安全地将 UnaryOperator<Object> 转换为 UnaryOperator<T>,并且这样做不会破坏类型安全。
*/
//泛型单例工厂模式,它是一个返回输入值本身的操作符
private static UnaryOperator<Object> IDENTITY_FN = t -> t;
/**
* 将IDENTITY_FN强制转换为UnaryOperator<T>会产生未经检查的警告,
* 因为不是对于所有的T而言,UnaryOperator<Object>都是UnaryOperator<T>。
* 但是恒等函数很特殊,他会直接返回未加修改的参数(t->t,它总是返回输入值本身,
* 因此无论输入类型 T 是什么,它都能正确地工作,且不会改变输入类型的安全性。),
* 因此无论T是什么值,将其作用UnaryOperator<T>都是类型安全的,所以可以抑制警告。
*/
@SuppressWarnings("unchecked")
public static <T> UnaryOperator<T> identityFunction()
{
return (UnaryOperator<T>) IDENTITY_FN;
}
}③递归类型限定
递归类型限定:类型参数使用包含该类型参数本身的表达式限定。
常见用途:与Compapable接口一起使用。类型参数T定义了实现Comparable<T>接口的类型可以与哪种类型的元素进行比较,实际上几乎所有类型都只能与自身类型的元素进行比较。例如,String实现了Comparable<String>、Integer实现了Comparable<Integer>等。
很多方法都可以接受一个这样的集合:其中的元素都实现了Comparable接口,然后对其进行排序、查找、计算最大值或最小值。要完成这些操作,需要确保集合中的每个元素都可以与其他所有元素比较。
递归类型限定还有更复杂用法,但只需理解模拟自身类型(一2)、本节、下节的通配符变体即可。
//E extends Comparable<E>:任何可以与自身进行比较的类型E
public static <E extends Comparable<E>> E Max(Collection<E> c)
{
if (c.isEmpty())
throw new IllegalArgumentException();//更好的做法:返回一个Optional<E>
E result = null;
for (E e : c)
if (result == null || e.compareTo(result) > 0)
result = Objects.requireNonNull(e);
return result;
}6. 使用有限制的通配符增加API的灵活性
参数化类型是不变的,对于任意两个不同的类型Type1和Type2,即使Type1和Type2有父子关系,但List<Type1>既不是List<Type2>的子类型,也不是他的超类型。
泛型是非协变的,因为类型擦除 后,泛型的类型信息消失,
List<Object>和List<String>都是原始类型List,而原始类型并不具有任何类型参数信息,不能保证转换安全。如果允许List<Object>转换为List<String>,那么在执行时,你可能会遇到ClassCastException,因为List<Object>中可能包含不是String的对象。不要将有限制的通配符类型用作返回类型:这样不仅不会提供灵活性,还会迫使客户端代码中使用通配符类型。
①有限制的通配符类型
为了获得最大灵活性,应该在代表生产者或消费者的输入参数上使用通配符类型,若一个输入参数既是生产者又是消费者,此时需要精确类型匹配。
PECS:
producer-extends, consumer-super。若一个参数化类型代表的是T类型的生产者,应该使用<? extends T>, 若它代表的是T类型的消费者,则应该使用<? super T>.
//未使用通配符类型的pushAll方法--存在缺陷
/**
* 若src的元素类型与栈的元素类型完全匹配,则能正常工作
* 假设:有一个Stack<Number>,并且调用了push(intVal)
* 其中intVal的类型为Integer,这个方法应该也能工作
* 因为Integer是Number的子类型。下面代码应该能运行:
* Stack<Number> numStack=new Stack<>()
* Iterable<Integer> ints=...
* numStack.pushAll(ints);
* 但由于参数化类型是不变的,所以编译会报错
*/
public void pushAll(Iterable<E> src)
{
for (E e : src)
push(e);
}
/**
* 为了处理上述情况,java提供了有限制的通配符类型
* pushAll的输入参数类型不应该是"E类型的Iterable"接口
* 而应该是"E的某个子类型的Iterable"接口
* Iterable<? extends E> 可以表达上述意思
*/
public void pushAll(Iterable<? extends E> src)
{
for (E e : src)
push(e);
}
/**
* popAll方法将每个元素从栈中弹出,并将这些元素添加到给定的集合
* 未使用通配符类型的popAll方法,存在缺陷
* <p>
* 若目标集合的元素类型与栈的元素类型完全匹配,则可以正常运行。
* Stack<Number> numStack=new Stack<Number>();
* Collection<Object> objects=...
* numStack.popAll(objects)
* 会报和之前类似的错误
* 通配符类型可以解决,popAll的输入参数不应该是"E的集合",
* 而应该是"E的某个超类型的集合"
* Collection<? super E>可以表达上述意思
*/
public void popAll(Collection<E> dst)
{
while (!isEmpty())
dst.add(pop());
}
//解决问题
public void popAll(Collection<? super E> dst)
{
while (!isEmpty())
dst.add(pop());
}②PECS实例
//上节递归,原来的声明
public static <T extends Comparable<T>> T max(List<T> list);
//使用通配符修改后
/**
* 第一次PECS在参数列表中:参数会产生T类型的实例,所以将List<T>改为List<? extends T>
* 第二次是在参数类型中:原版类型参数被指定为<T extends Comparable<T>>, 但是可比较的T
* 会消费T(并产生表示顺序关系的整数),因此将Comparable<T>替换为Comparable<? super T>
*
* 可比较对象总是消费者,所以通常应该优先使用Comparable<? super T>,比较器也是如此
* 优先使用Comparator<? super T>
*/
public static <T extends Comparable<? super T>> T max(List<? extends T> list);
//下面的示例无法应用于原来的版本,但是新版可以
List<ScheduledFuture<?>> scheduledFutures=....
之所以无法应用原来的版本,是因为ScheduledFuture没有实现Comparable<ScheduledFuture>。相反
他是Delayed的子接口,而Delayed扩展了Comparable<Delayed>,即:ScheduledFuture实例不仅可以与
其他ScheduledFuture实例比较,还可以与任何Delayed实例比较,原来接口接受不了。
更通俗的讲,通配符是为了支持这样的类型--没有直接实现Comparable,但扩展了实现了该接口的类型。③类型参数和通配符之间存在二元性
类型参数和通配符之间存在二元性,许多方法可以选择其中之一进行声明:例如:考虑一个静态方法,来交换列表中用索引指定的两个元素,其有两个可能的声明的方式。第一个使用了无限制的类型参数,第二个使用了无限制的通配符。
在公有的API中,第二个更好,因为其更简单。我们传入一个列表(可以是任何列表),这个方法就可以交换索引指定的两个元素,不需要关心类型参数。
一般,若一个类型参数在方法声明中只出现了一次,就将其替换为通配符:若它是无限制的类型参数,就替换为无限制的通配符;若它是有限制的类型参数,就替换为有限制的通配符。
//swap方法的两个可能的声明方式
public static <E> void swap(List<E> list, int i, int j);
public static void swap(List<?> list, int i, int j);swap的第二个声明有个问题,下面的实现无法通过编译,因为无法将非null之外的任何值放入List<?>中。
public static void swap(List<?> list, int i, int j)
{
list.set(i, list.set(j, list.get(i)));//无法将非null的任何值放入List<?>中
}
******
解决方法:
编写一个私有的方法来捕获通配符类型,为了捕获该类型,这个辅助方法必须是泛型方法。
public static void swap(List<?> list, int i, int j)
{
swap(list, i, j);
}
//swapHelper方法知道list是一个List<E>
private static <E> void swapHelper(List<E> list, int i, int j)
{
list.set(i, list.set(j, list.get(i)));
}7. 谨慎混用泛型和可变参数
①混用泛型和可变参数会破坏类型安全
可变参数本质是一个数组。
不可具体化类型:运行时表示所包含的信息比其编译时少,几乎所有的泛型和参数化类型都是不可具体化的。
在声明方法时若可变参数是一个不可具体化的类型,编译器会生成警告,在调用方法时,若编译器推断可变参数的类型是不可具体化的,也会生成警告。
当一个参数化类型的变量指向一个并非该类型的对象时,就会发生堆污染。它可能会导致编译器自动生成的强制类型转换失败,从而违反泛型类型系统的基本保证。
//混用泛型和可变参数会破坏类型安全
static void dangerous(List<String>... stringLists)
{
List<Integer> intList = List.of(42);
Object[] objects = stringLists;
objects[0] = intList;//堆污染, 类型擦除,缺乏信息,无法检测这一步错误
String s = stringLists[0].get(0);//ClassCastException,隐式强制转换
} //不安全--暴露了指向其泛型参数数组的引用
/**
* 这个数组的类型是由传入方法的参数的编译时类型决定的
* 而编译器可能没有足够的信息来做出准确的判断
* 因为这个方法返回了它的可变参数数组,所以堆污染会沿着调用栈
* 向上传播
* <p>
* 编译时T[]被类型擦除为Object[]类型的数组,实际返回的是Object类型的数组
*/
static <T> T[] toArray(T... args)
{
return args;
}
/**
* 这个方法本身不存在危险,但是调用了带有可变参数的toArray方法产生警告
*/
static <T> T[] pickTwo(T a, T b, T c)
{
switch (ThreadLocalRandom.current().nextInt(3))
{
case 0:
return toArray(a, b);
case 1:
return toArray(a, c);
case 2:
return toArray(b, c);
}
throw new AssertionError();//不会走到这里
}
public static void main(String[] args)
{
//这里隐含一个强制类型转换
//ClassCastException,Object[]数组不是String[]的子类型,且实际也为Object[],所以转换失败
String[] a = pickTwo("f", "s", "c");
//下面a2实际就是String[],所以能够向下转换为String[]
// String[] a1={"a", "b"};
// Object[] a2=a1;
// String[] a3=(String[]) a2;
}上面示例强调,让别的方法访问泛型可变参数数组是不安全的。
两个例外:
将这个数组传递给另一个正确使用了@SafeVarargs注解的可变参数方法是安全的。
将数组传递给一个仅使用数组的内容来计算某个函数的非可变参数方法也是安全的。
下面是安全使用泛型可变参数的示例:
@SafeVarargs
static <T> List<T> flatten(List<? extends T>... lists)
{
List<T> result = new ArrayList<>();
for (List<? extends T> list : lists)
result.addAll(list);
return result;
}②显式创建泛型数组非法,为什么允许声明带有泛型可变参数的方法?
因为对于可变参数方法,支持泛型或参数化类型,在实践中可能非常有用。例如:Arrays.asList(T... a)、Collections.addAll(Colloection<? super T> c, T... elements), 与前面的dangerous方法比,这些方法是安全的。
③消除警告
可变参数的泛型方法会产生警告。
java7前,可以在每个调用处使用@SuppressWarings("unchecked")注解来消除警告,不过繁琐可读性不好,会掩盖反映实际问题的警告。
java7, 可以使用SafeVarargs注解,自动抑制调用该方法时的警告。本质上:该注解承诺,方法的作者保证该方法是类型安全的。
如何确保方法是安全的:当这样的方法被调用时,编译器会创建一个泛型数组来保存可变参数,若方法内不会向这个数组中存储数据(以免参数被覆盖),而且不允许指向该数组的引用逃逸到方法之外(以免不受信任的代码访问该数组),那么它就是安全的。换句话说,若可变参数数组只是用来将数量可变的一组参数从调用者传递给方法(可变参数的目的),那么这个方法就是安全的。
④何时使用SafeVarargs注解
对于每个带有泛型或参数化类型的可变参数方法,都要使用@SafeVarargs注解。意味着用户不必为警告困扰,我们也不必编写不安全的方法。
只要满足以下条件,泛型可变参数方法就是安全的:
它不会将任何内容存储到可变参数数组中。
它不会使该数组(或克隆体)对不受信任的代码可见。
若违反上述任何一条就要修复它。
SafeVarargs注解只能用到无法被重写的方法上,因为无法保证每个可能的重写版本都是安全的。
在java8, 该注解只能用在静态方法和final的实例方法上;在Java9,该注解也可用在私有的实例方法上。
⑤使用List替换可变参数注解
List是泛型可变参数的类型安全的替代选择。
//前提是List.of使用了@SafeVarargs注解
public static void main(String[] args)
{
//与静态工厂方法List.of结合使用,以支持数量可变的参数
flatten(List.of(friends, romans, countrymen));
}
static <T> List<T> flatten(List<List<? extends T>> lists)
{
List<T> result = new ArrayList<>();
for (List<? extends T> list : lists)
result.addAll(list);
return result;
}
static <T> List<T> pickTwo(T a, T b, T c)
{
switch (ThreadLocalRandom.current().nextInt(3))
{
case 0://只使用了泛型,没有使用数组,是安全的
return List.of(a, b);//List.of保证安全性
case 1:
return List.of(a, c);
case 2:
return List.of(b, c);
}
throw new AssertionError();//不会走到这里
}8. 考虑类型安全的异构容器
①类型安全的异构容器
实现:对键而不是容器进行参数化,然后将参数化的键交给容器来插入或检索值,利用泛型系统来保证值的类型与它的键一致。
例如:设计一个Favorite类。支持用户存储和检索自己喜欢的任何类型的实例。可以使用这个类型的Class对象来充当被参数化的键,因为Class是泛型的(Class<T>)。例如,String.class的类型是Class<String>。当一个class字面量在方法之间传递,以传达编译时和运行时的类型信息时,它被称作类型令牌。
Favorite是类型安全的,当请求String时,它绝不会返回Integer。他也是异构的,与普通Map不同,它的所有键都是不同类型。因此,称其为类型安全的异构容器
//类型暗算的异构容器模式---API
class Favorites
{
//instance的类型是T, 和键的泛型T保持一致
public <T> void putFavorite(Class<T> type, T instance);
public <T> T getFavorite(Class<T> type);
}
//类型暗算的异构容器模式---实现
class Favorites
{
//这里的通配符是嵌套的,不是Map的参数是?,所以可以添加到Map
private Map<Class<?>, Object> favorites = new HashMap<>();
//instance的类型是T, 和键的泛型T保持一致
public <T> void putFavorite(Class<T> type, T instance)
{
//favorites.put(type, instance);
//让putF方法检查instance确实是type所代表的类型的实例
favorites.put(type, type.cast(instance));//利用动态转化实现运行时类型安全。
}
public <T> T getFavorite(Class<T> type)
{
//cast方法是强制转换运算符的动态对应,他会检查其参数是否是Class
//对象所表示的类型的实例
return type.cast(favorites.get(type));//cast方法动态转化为T
}
}
public class Test
{
public static void main(String[] args)
{
Favorites f = new Favorites();
f.putFavorite(String.class, "Java");
f.putFavorite(Integer.class, 1);
f.putFavorite(Class.class, Favorites.class);
String s = f.getFavorite(String.class);
Class<?> c = f.getFavorite(Class.class);
}
}②局限性
第一个局限:恶意客户端利用原始类型的Class对象破坏Favorite实例的类型安全。利用原始类型HashSet, 可以将String放入HashSet<Integer>。
Java.util.Collections类中有一些集合采用动态转换实现运行时类型安全,包括checkedSet等,除了接受一个集合或映射,这些静态工厂方法还接受一个或两个Class对象。这些方法是泛型方法,确保作为参数的Class对象和集合的编译时类型匹配。
public <T> void putFavorite(Class<T> type, T instance)
{
//favorites.put(type, instance);
//让putF方法检查instance确实是type所代表的类型的实例
favorites.put(type, type.cast(instance));//利用动态转化实现运行时类型安全。
}第二个局限:不能用于不可具体化的类型。即:可以存储String或String[ ],但不能存储List<String>。若试图存储List<String>, 将无法编译。因为无法获得List<String>类型的Class对象。List<String>.class将导致语法错误,这样的规定是有意义的。List<String>和List<Integer>共享同一个class对象,即List.class。若语法上支持List<String>.class和List<Integer>.class,他们会返回相同的引用,会严重破坏Favorite的内部实现。
③有限制的类型令牌或有限制的通配符
/**
* 注解API大量使用了有限制的类型令牌
* 例如:下面是一个在运行时读取注解的方法。这个方法
* 来自AnnotatedElement接口,该接口提供表示类、方法、
* 字段和其他程序元素的反射类型实现
* <p>
* 其参数annotationType是一个表示注解类型的有限制的类型令牌
* 若当前元素具有该类型的注解,则该方法将其返回;否则返回null
* <p>
* 本质上,带注解的元素就是一个类型安全的异构容器,它的键是注解类型
*/
public <T extends Annotation> T getAnnotation(Class<T> annotationType)
{
return annotationType.getAnnotation(annotationType);
}
/**
* 若有一个Class<?>类型的对象,要将其传递给一个使用了有限制的类型令牌的方法
* 比如上面的方法。我们可以把这个对象强制转换为class<? extends Annotation>
* ,但是这种转换是未经检查的,会产生编译时警告。
* <p>
* class类提供了一个实例方法,可以安全动态的执行这种转换,这就是asSubclass方法
* 它将会调用它的Class对象转换为其参数所代表的类的子类。
* 若转换成功,该方法将返回其参数,若失败,则抛出ClassCastException
* <p>
* 下面展示了如何使用asSubclass方法来读取一个其类型在编译时未知的注解
*/
//使用asSubclass安全的转换为有限制的类型令牌
static Annotation getAnnotation(AnnotatedElement element, String annotationTypeName)
{
Class<?> annotationType = null;//无限制的类型令牌
try
{
annotationType = Class.forName(annotationTypeName);
} catch (Exception e)
{
throw new IllegalArgumentException(e);
}
return element.getAnnotation(annotationType.asSubclass(Annotation.class));
}五. 枚举和注解
Java支持两种特殊的引用类型:一种是称为枚举类型的类,一种是称为注解类型的接口。
1. 使用enum代替int常量
①int(String)枚举模式的不足
类型安全方面没有提供任何保障(不同常量间可以运算),也几乎没有任何描述性可言。
因为int枚举是常量变量,他们的int值会被编译到使用他们的客户端中(编译器将
int常量直接替换为常量的值),若与某个int枚举关联的值发生了变化,其客户端必须重新编译。将int枚举常量转换成可打印的字符串也没有什么好的方法。
也没有很好的方法来遍历一个int枚举组中的所有枚举常量,甚至无法获得这个枚举组的大小。
下面无关系的常量,还能够运算。
String枚举模式则将字符串硬编码到客户端代码,字符串可能拼写错误,且编译无法检查,且会导致性能问题。
int枚举模式
//int枚举模式
public static final int APPLE_FUJI = 0;
public static final int APPLE_PIPPIN = 1;
public static final int ORANGE_NAVEL = 0;②枚举类型
public enum Apple
{FUJI, PIPPIN}
;
public enum Orange
{NAVEL}
;
//带有数据和行为的枚举类型
enum Planet
{
EARTH(1.0, 2.0);
private final double mass;
private final double radius;
Planet(double mass, double radius)
{
this.mass = mass;
this.radius = radius;
}
public double mass()
{
return mass;
}
public double radius()
{
return radius;
}
}类型安全:
enum类型确保了值的有效性和合法性,编译时会检查是否使用了有效的枚举常量,而不像int常量那样容易出现类型错误。枚举类与编译时常量的区别:虽然
enum常量的值可能在编译时嵌入到代码中,但它们仍然保持为类型安全的实例,不会像int常量一样直接嵌入数值。这保证了在编译时能够进行类型检查,从而避免了错误的传值。即使枚举的值发生变化,只要枚举类型的结构没有变化,编译器会帮助检查客户端代码中的所有引用是否与新的枚举值兼容。java的枚举类型是全功能的类:这样的类通过公有静态final字段为每个枚举常量导出了一个实例。由于没有可访问的构造器,枚举类型实际上相当于final类。因为客户端既不能创建枚举类型实例,也不能扩展它,所以除了已经声明的枚举常量之外,不可能有其他实例,即枚举类型是实例受控的。他们是单例的一种泛化,单例本质上就是只包含一个元素的枚举。
具有同名常量的枚举类型可以共处,因为每个类型都有自己的命名空间。
可以在一个枚举类型中添加常量或调整常量顺序,而无需重新编译其客户端代码,因为用来导出常量的字段在枚举类型和其客户端之间提供了一层隔离:常量值不会像在int枚举模式那样被编译到客户单。
可以通过调用toString方法将其转换为可打印的字符串。
枚举类型允许添加任意的方法和字段以及实现任意的接口,且提供了所有Object方法的高质量实现,还实现了Comparable和Serializable接口,并且针对序列化形式进行了设计,足以承受对枚举类型的大多数更改。
由于枚举类型本质上是可变的,因此所有字段都应是final的,这些字段可以是公有的,但最好设为私有的,并设置公有的访问器方法。
所有枚举类型都有一个静态的
values方法,该方法会返回一个数组,数组中是按照声明顺序保存的枚举值。枚举类型有一个自动生成的
valueOf(String)静态方法,可以将常量名字转换为常量本身。示例:若存在枚举Color { RED, GREEN },调用Color.valueOf("RED")返回Color.RED。字符串必须与枚举常量名称完全一致(包括大小写)。ordinal()方法返回枚举常量在声明时的位置序号(从0开始计数)。enum Color {RED,// ordinal() = 0 GREEN,// ordinal() = 1}每个枚举常量的ordinal()值由编译器根据声明顺序自动分配,无需手动设置。一旦枚举类被编译,ordinal()的值就固定不变(即使后续在源码中添加新常量,已编译的旧版本枚举类的ordinal()值也不会改变)。如果修改枚举常量的声明顺序或插入新常量,ordinal()的值会发生变化,可能导致依赖它的代码逻辑出错(如序列化、数据库存储、状态机等)。除非有充分理由将一个枚举方法暴露给用户,否则应将其声明为私有的,或如果需要,声明为包私有的。
若一个枚举较为通用,就应该将其设计为顶层类;若其使用仅限于一个特定的顶层类之内,就应该将其设计为这个顶层类的成员类。
每当需要一组常量,而且其成员在编译时都已知的时候,就应该使用枚举。
并不要求枚举类型中的常量集合已知保持不变,这是为了支持枚举类型在演变时能保持二进制兼容而设计的(指代码的修改(如添加枚举常量)不会导致依赖该代码的已编译类无法运行。例如,新增枚举常量不会引发链接错误或类加载失败。)。
③将不同行为与枚举常量关联
enum Operation
{
PLUS, MINUS, MULTIPLY, DIVIDE;
/**
* 若新加了枚举常量,有可能忘记在下面添加但仍能通过编译,
但是运行时尝试新运算会报错
*/
//执行该常量所代表的算术运算
public double apply(double x, double y)
{
switch (this)
{
case PLUS:
return x + y;
case MINUS:
return x - y;
case MULTIPLY:
return x * y;
case DIVIDE:
return x / y;
}
throw new AssertionError();
}
}enum Operation
{
/**
* 特定常量的方法实现的枚举类型
* 在枚举类型中声明一个抽象的apply方法
* 并在特定于常量的类主体中用一个具体的方法来重写该方法
*
* 在下面添加新常量后,若编译器会提醒你实现抽象方法
*/
PLUS
{
public double apply(double x, double y)
{
return x + y;
}
},
MINUS
{
public double apply(double x, double y)
{
return x - y;
}
},
MULTIPLY
{
public double apply(double x, double y)
{
return x * y;
}
},
DIVIDE
{
public double apply(double x, double y)
{
return x / y;
}
};
public abstract double apply(double x, double y);
}enum Operation
{
PLUS("+")
{
public double apply(double x, double y)
{
return x + y;
}
},
MINUS("-")
{
public double apply(double x, double y)
{
return x - y;
}
},
MULTIPLY("*")
{
public double apply(double x, double y)
{
return x * y;
}
},
DIVIDE("/")
{
public double apply(double x, double y)
{
return x / y;
}
};
//与特定常量的数据结合使用
private final String symbol;
Operation(String symbol)
{
this.symbol = symbol;
}
@Override
public String toString()
{
return symbol;
}
public abstract double apply(double x, double y);
}④初始化执行顺序
普通类:静态字段初始化、静态代码块执行、非静态字段初始化、构造器执行。
枚举类:
枚举常量实例化优先:在 Java 中,枚举类型实际上是一种特殊的类。当枚举类被加载时,首先会按照枚举常量在代码中出现的顺序进行实例化。在实例化每个枚举常量时,会调用枚举的构造器来创建该常量对应的实例。
静态字段初始化随后执行:在所有枚举常量都实例化完成后,才会进行静态字段的初始化。静态字段的初始化同样按照它们在类中出现的顺序进行。
⑤策略枚举模式
每当添加一个枚举常量时,就强制选择一种加班工资计算策略。将加班工资计算转移到一个私有的嵌套枚举中,并将这个策略枚举的一个实例传递给PayrollDay的构造器。然后PayrollDay枚举将加班工资计算委托给这个策略枚举,这样PayrollDay中就不需要switch语句或特定于常量的方法实现了。虽然不如switch语句简洁,但更安全、更灵活。
//策略枚举模式
enum PayrollDay
{
MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY(PayType.WEEKEND), SUNDAY(PayType.WEEKEND);
private final PayType payType;
PayrollDay(PayType payType)
{
this.payType = payType;
}
PayrollDay()
{
this(PayType.WEEKDAY);
}
int pay(int minutesWorked, int payRate)
{
return payType.pay(minutesWorked, payRate);
}
//策略枚举类型
private enum PayType
{
WEEKDAY
{
int overtimePay(int minsWorked, int payRate)
{
return 1;
}
},
WEEKEND
{
int overtimePay(int minsWorked, int payRate)
{
return 2;
}
};
abstract int overtimePay(int mins, int payRate);
int pay(int minsWorked, int payRate)
{
return overtimePay(minsWorked, payRate);
}
}
;
}⑥枚举中如何使用switch语句
若Operation枚举不受我们控制,但是希望它可以有一个返回每个运算逆运算的实例方法。
即使自己可以控制枚举类型,若某个方法不属于该枚举类型,也应该这样实现。这个方法可能在某些地方是必须的,但通常又不足以将其包含在这个枚举类型中。
enum Operation
{
PLUS, MINUS, MULTIPLY, DIVIDE;
//在枚举上使用switch来模拟缺少的方法
public static Operation inverse(Operation op)
{
switch (op)
{
case PLUS:
return MINUS;
case MINUS:
return PLUS;
case MULTIPLY:
return DIVIDE;
case DIVIDE:
return MULTIPLY;
default:
throw new AssertionError("Unknown operation: " + op);
}
}
}2. 使用实例字段代替序号
很多枚举自然与一个int值关联。所有的枚举类型都有一个ordinal方法,它返回每个枚举常量在这个类型中以数字表示的位置信息,即序号。使用这个值有很多问题,常量顺序改变,以及删除常量、插入新常量会导致值改变。
对于一个与枚举有关联的值,永远不要根据枚举的序号将其计算出来,而应该将其存储在一个实例字段中。
Enum文档中对ordinl方法的说明:大多数程序员用不到这个方法,他是设计用于基于枚举的通用数据结构的,例如EnumSet和EnumMap。除非正在编写这种数据结构,否则最好完全避免使用ordinal方法。
enum Ensemble
{
SOLO(1), DUET(2);
private final int number;
Ensemble(int size)
{
number = size;
}
//而不是
public int getNumber()
{
return ordinal() + 1;
}
}3. 使用EnumSet代替位域
①使用位域实现可枚举常量(过时)
若一个可枚举类型的元素主要以集合的形式使用,传统的做法是使用int枚举模式,将每个不同的常量赋值为2的不同次方。这种表示法允许我们使用按位或运算将多个常量组合到一个集合中,这个集合叫做位域。
位域表示法允许使用位运算来高效计算并集和交集等操作。但是位域具有int枚举常量所有的缺点,甚至更多。当以数字形式打印时,位域解释比int枚举常量更困难。没有简单的方式可以变量位域的所有元素。必须在编写API时预测可能需要的最大位数,并相应的选择这个位域的类型(通常为int或long), 一旦选定类型,就不能在不修改API的情况下扩充其宽度了。
class Text
{
public static final int STYLE_BOLD = 1 << 0;//1
public static final int STYLE_ITALIC = 1 << 1;//2
public static final int STYLE_UNDERLINE = 1 << 2;//4
//以0个或多个STYLE_常量按位或作为参数
//text.applyStyles(STYLE_BOLD|STYLE_ITALIC)
public void applyStyles(int styles)
{
}
}②EnumSet
有些程序员习惯使用枚举而不是int常量,但当需要以常量集合的形式来传递时,他们则坚持使用位域。
EnumSet可以高效的表示来自一个枚举类型的值的集合,这个类实现了Set接口,提供了任何其他Set实现同样丰富的功能,提供了类安全性和互操作性。但在内部,每个EnumSet都被表示为一个位向量。若底层的枚举类型的元素不超64,则整个EnumSet将被表示为一个单一的long,因此其性能与位域相当。批量操作(removeAll)也使用位运算实现。
不能仅仅因为一个可枚举类型要放到集合中,就使用位域来表示它:EnumSet有一个实际缺点,即无法创建不可变的EnumSet。在这个问题解决前,可以使用Collections.unmodifiableSet将EnumSet封装起来,但简洁性和性能会受到影响。
public class Test
{
public static void main(String[] args)
{
Text t = new Text();
t.applyStyles(EnumSet.of(Text.Style.BOLD, Text.Style.ITALIC));
}
}
class Text
{
public enum Style
{BOLD, ITALIC, UNDERLINE}
;
//可以传入任何Set, EnumSet最佳
//Set接口,因为可能有特殊Set传入
public void applyStyles(Set<Style> styles)
{
}
}4. 不要以序号作为索引,使用EnumMap代替
①序号作为索引的问题
将ordinal()序号作为索引会产生很多问题:因为数组与泛型不兼容(Set<Plant>[ ]),所以程序需要进行未经检查的转换,不简洁。数组不知道其索引代表什么,需要手动标记输出。无法确保枚举的序号是正确的值。
public class Test
{
public static void main(String[] args)
{
//想按照生长周期将植物放入不同的集合
//使用ordinal()索引数组,不要这么做
Set<Plant>[] plantsByLifeCycle = (Set<Plant>[])
new Set[Plant.LifeCycle.values().length];
for (int i = 0; i < plantsByLifeCycle.length; i++)
plantsByLifeCycle[i] = new HashSet<Plant>();
for (Plant p : garden)
plantsByLifeCycle[p.lifeCycle.ordinal()].add(p);
}
}
class Plant
{
enum LifeCycle
{ANNUAL, PERENNIAL, BIENNIAL}
final String name;
final LifeCycle lifeCycle;
Plant(String name, LifeCycle lifeCycle)
{
this.name = name;
this.lifeCycle = lifeCycle;
}
}②使用EnumMap将数据与枚举关联
EnumMap就是为了enum类型的键设计的。
下面代码更简洁,速度一致,无不安全的类型转换,不要手动标记输出。计算数组索引时也不会出错。
EnumMap性能可以与数组媲美,是因为其内部使用了这样的一个数组,但向上层隐藏了该实现细节。
public class Test
{
public static void main(String[] args)
{
Map<Plant.LifeCycle, Set<Plant>> plantByLifeCycle =
new EnumMap<>(Plant.LifeCycle.class);
for (Plant.LifeCycle lc : Plant.LifeCycle.values())
plantByLifeCycle.put(lc, new HashSet<>());
for (Plant p : garden)
plantByLifeCycle.get(p.lifeCycle).add(p);
/**
* 流版本
* EnumMap版本总是会创建键对应的集合,但流版本只有确实存在
* 才会创建。
* 比如缺少2年生植物,EnumMap版的大小为3,而流为2
*/
Arrays.stream(garden).collect(groupingBy(p -> p.lifeCycle,
() -> new EnumMap<>(Plant.LifeCycle.class)), toSet());
}
}
class Plant
{
enum LifeCycle
{ANNUAL, PERENNIAL, BIENNIAL}
final String name;
final LifeCycle lifeCycle;
Plant(String name, LifeCycle lifeCycle)
{
this.name = name;
this.lifeCycle = lifeCycle;
}
}③两次引用
//问题同一维,使用了ordinal()索引数组
//从液态到固态是凝固,从液态到气态是沸腾等等
enum Phase
{
SOLID, LIQUID, GAS;
public enum Transition
{
MELT, FREEZE, BOIL, CONDENSE, SUBLIME, DEPOSIT;
//行以from的序号为索引,列以to的序号为索引
private static final Transition[][] TRANSITIONS =
{
{null, MELT, SUBLIME},
{FREEZE, null, BOIL},
{DEPOSIT, CONDENSE, null}
};
//返回从一个相到另一个相的相变
public static Transition from(Phase from, Phase to)
{
return TRANSITIONS[from.ordinal()][to.ordinal()];
}
}
}//使用一个嵌套的EnumMap将数据和枚举对关联起来
enum Phase
{
SOLID, LIQUID, GAS;
public enum Transition
{
MELT(SOLID, LIQUID), FREEZE(LIQUID, SOLID),
BOIL(LIQUID, GAS), CONDENSE(GAS, LIQUID),
SUBLIME(SOLID, GAS), DEPOSIT(GAS, SOLID);
private final Phase from;
private final Phase to;
Transition(Phase from, Phase to)
{
this.from = from;
this.to = to;
}
//初始化相变映射
private static final Map<Phase, Map<Phase, Transition>>
m = Stream.of(values()).collect(groupingBy(t -> t.from, () -> new EnumMap<>(Phase.class),
toMap(t -> t.to, t -> t, (x, y) -> y, () -> new EnumMap<>(Phase.class))));
//返回从一个相到另一个相的相变
public static Transition from(Phase from, Phase to)
{
return m.get(from).get(to);
}
}
}5. 使用接口模拟可扩展的枚举
枚举的本质是final的不可扩展。
可扩展的枚举类型使用场景:运算码(opcode):运算码是一个可枚举类型,其元素表示某个机器支持的运算。让API的用户提供其自己的运算可以有效扩充API所提供的运算集。利用枚举类型可以实现任意接口这一事实,为opcode类型定义一个接口,并定义一个枚举,作为该接口的标准实现。下面为(五1)中的Operation枚举类型的一个可扩展版本。
虽然BasicOperation这个枚举类型是不可扩展的,但Operation这个接口类型是可扩展的,而且他是用来表示API中的运算的接口类型。可以顶一个另一个实现了该接口的枚举类型,并用这个新类型的实例代替基类型。
只要API被编写为接收接口类型,则任何可以使用基本运算的地方都可以使用我们的新运算了。
使用接口模拟可扩展枚举的缺点:实现代码不能从一个枚举类型继承搭配另一个中。若实现代码不依赖于任何状态,可以将其置于接口中,并使用默认实现。在下面示例中,用于存储和检索与运算关联的符号逻辑必须在Basic和Extended中各实现一次,由于代码量较少,问题不严重。若相同功能的代码量很大,可以将其封装在一个辅助类或一个静态辅助方法中。
//使用接口模拟可扩展的枚举
interface Operation
{
double apply(double x, double y);
}
enum BasicOperation implements Operation
{
PLUS("+")
{
@Override
public double apply(double x, double y)
{
return x + y;
}
},
MINUS("-")
{
@Override
public double apply(double x, double y)
{
return x - y;
}
},
TIMES("*")
{
@Override
public double apply(double x, double y)
{
return x * y;
}
},
DIVIDE("/")
{
@Override
public double apply(double x, double y)
{
return x / y;
}
};
private final String symbol;
BasicOperation(String symbol)
{
this.symbol = symbol;
}
@Override
public String toString()
{
return symbol;
}
}
//模拟扩展枚举
enum ExtendedOperation implements Operation
{
EXP("^")
{
@Override
public double apply(double x, double y)
{
return Math.pow(x, y);
}
},
REMAINDER("%")
{
@Override
public double apply(double x, double y)
{
return x % y;
}
};
private final String symbol;
ExtendedOperation(String symbol)
{
this.symbol = symbol;
}
@Override
public String toString()
{
return symbol;
}
}6. 与命名模式相比首选注解
①命名模式缺点
命名模式:历史上通常使用命名模式来指示某些程序元素需要由工具或框架进行特殊处理。例如在JUnit4前,这个测试框架要求用户以test为前缀来标识测试方法。
命名模式缺点:
首先,若存在拼写错误,框架不会有任何提示。
此外,无法确保它们只用于应该使用的程序元素。例如,假如将一个类命名为TestSafetyMechanisms, 希望JUnit 3会自动测试其所有方法,而不用管其方法名是什么。JUnit3不会报错,但也不会执行该测试。
最后,它们没有提供将参数值与程序元素关联起来的好方法。假设想支持一类测试,只有当方法抛出某个特点异常时才算测试成功。这个异常类本质上是该测试的一个参数。可以使用命名模式将异常类型的名称编码到测试方法的名称中,但难看且脆弱。编译器并不知道要去检查那个应该命名为异常的字符串是否真的是这么做的。若以这个字符串为名字的类并不存在,或不是异常,也要到运行测试时才会发现。
②简单示例
注解很好的解决了上述问题,JUnit 4开始采用了注解。
//标记注解类型声明
import java.lang.annotation.*;
//处理标记注解的程序,反射
import java.lang.reflect.*;
/**
* 标明被注解的方法是一个测试方法
* 仅用于无参数的静态方法(但将该注解放在实例方法上或带参数
* 的方法上,编译仍会通过,除非编写一个注解处理器,否则只能
* 留给测试工具运行时处理)
* <p>
* 下面注解运行时保留,若无这个,测试工具就看不到注解了
* 且是应用到方法上
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@interface Test
{
}
//包含标记注解的程序
class Sample
{
@Test
public static void m1() {}//测试应该通过
@Test
public static void m2()//测试应该失败
{
throw new RuntimeException("Boom");
}
@Test
public void m3() {}//无效使用非静态方法
}
/**
* Test注解对Sample类的语义没有直接影响
* 他们只用于为感兴趣的程序提供信息。
* 更一般的说,注解不会改变被注解的代码的语义
* ,而是使其能够被某些工具进行特殊处理,如下:
*
* 这个测试工具在命令行上接受一个完全限定的类名作为参数
* 并通过调用Method.invoke,以反射的方式运行了所有使用
* 了Test注解的方法
*/
class RunTests
{
public static void main(String[] args) throws Exception
{
int tests=0;
int passed=0;
Class<?> testClass=Class.forName(args[0]);
for(Method m:testClass.getDeclaredMethods())
{
if(m.isAnnotationPresent(Test.class))
{
++tests;
try
{
m.invoke(null);
++passed;
//封装目标方法或构造函数执行过程中抛出的原始异常, 其本身是一个包装器
} catch (InvocationTargetException e)
{
}catch (Exception exc)//非上面的异常,表名出现了无效使用:对实例方法注解,带有参数
{
}
}
}
}
}③检查异常
/**
* 对只在抛出特定异常时才会成功的测试添加支持
* 需要一个新的注解类型实现该功能
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@interface ExceptionTest
{
Class<? extends Throwable> value();//注解的参数类型
}
//包含了带参数的注解程序
class Sample2
{
@ExceptionTest(ArithmeticException.class)
public static void m1()//测试应该通过
{
int i=0;
i=i/i;
}
@ExceptionTest(ArithmeticException.class)
public static void m2()//应该失败,错误的异常
{
int a[]=new int[0];
int i=a[1];
}
@ExceptionTest(ArithmeticException.class)
public static void m3() {}//应该失败,未出现异常
}
//测试工具
class RunTests2
{
public static void main(String[] args) throws Exception
{
int tests=0;
int passed=0;
Class<?> testClass=Class.forName(args[0]);
for(Method m:testClass.getDeclaredMethods())
{
if(m.isAnnotationPresent(ExceptionTest.class))
{
++tests;
try
{
m.invoke(null);
//封装目标方法或构造函数执行过程中抛出的原始异常, 其本身是一个包装器
} catch (InvocationTargetException e)
{
Throwable exc=e.getCause();
Class<? extends Throwable> excType=
m.getAnnotation(ExceptionTest.class).value();
if(excType.isInstance(exc)) ++passed;//是要求的异常才增加
//若注解参数在编译时是有效的,但表示指定的异常类型的文件在运行时
//不存在了,测试工具将抛出TypeNotPresentException
}catch (Exception exc)//非上面的异常,表名出现了无效使用:对实例方法注解,带有参数
{
}
}
}
}
}④多值注解1
/**
* 若被测试的方法出现了几个指定异常中的任何一个
* 则测试通过。注解机制有一种方式,使得上面要求很容易实现
* <p>
* 使用了数组参数的注解类型
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@interface ExceptionTest2
{//只是返回了参数化数组,没有创建
Class<? extends Throwable>[] value();
}
//包含了带数组参数的注解代码
class Sample3
{
@ExceptionTest2({IndexOutOfBoundsException.class,
NullPointerException.class})
public static void doublyBad()
{
List<String> list=new ArrayList<>();
//前面的方法说明允许抛出IndexOutOfBoundsException\NullPointerException
list.addAll(5, null);
}
}
//测试工具
class RunTests3
{
public static void main(String[] args) throws Exception
{
int tests=0;
int passed=0;
Class<?> testClass=Class.forName(args[0]);
for(Method m:testClass.getDeclaredMethods())
{
if(m.isAnnotationPresent(ExceptionTest.class))
{
++tests;
try
{
m.invoke(null);
//封装目标方法或构造函数执行过程中抛出的原始异常, 其本身是一个包装器
} catch (InvocationTargetException e)
{
Throwable exc=e.getCause();
int oldPassed=passed;
Class<? extends Throwable>[] excTypes=
m.getAnnotation(ExceptionTest2.class).value();
for(Class<? extends Throwable> excType: excTypes)
{
if(excType.isInstance(exc))
{
++passed;//是要求的异常才增加
break;
}
}
}catch (Exception exc)
{
}
}
}
}
}⑤多值注解2
可重复注解会生成一个包含注解类型的合成注解。getAnnotationsByType方法掩盖了这一事实,它可以用来访问一个可重复注解类型的重复注解和非重复注解。
但isAnnotationPresent方法可以明确区分,重复注解的类型并不是这个可重复注解类型,而是这个包含注解类型。若一个元素具有某种类型的重复注解,当使用isAnnotationPresent方法来检查这个元素是否具有该类型的注解时,会发现没有。

/**
* java8开始,有另一种实现多值注解的方式:
* 在声明注解的时候,可以使用@Repeatable元注解代替使用数组
* 参数,来表名该注解可重复应用于单个元素。
*
* @Repeatable注解接受单个参数,该参数是一个包含注解类型的class对象,
* 而这个包含注解类型(ExceptionTestContainer)的唯一参数是一个注解类型的数组
*/
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@Repeatable(ExceptionTestContainer.class)
@interface ExceptionTest3
{
Class<? extends Throwable> value();
}
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@interface ExceptionTestContainer
{
ExceptionTest3[] value();
}
class Sample4
{
@ExceptionTest3(IndexOutOfBoundsException.class)
@ExceptionTest3(NullPointerException.class)
public static void doublyBad()
{
List<String> list=new ArrayList<>();
//前面的方法说明允许抛出IndexOutOfBoundsException\NullPointerException
list.addAll(5, null);
}
}
class RunTests4
{
public static void main(String[] args) throws Exception
{
int tests=0;
int passed=0;
Class<?> testClass=Class.forName(args[0]);
for(Method m:testClass.getDeclaredMethods())
{//处理可重复注解
if(m.isAnnotationPresent(ExceptionTest3.class)
|| m.isAnnotationPresent(ExceptionTestContainer.class))
{
++tests;
try
{
m.invoke(null);
//封装目标方法或构造函数执行过程中抛出的原始异常, 其本身是一个包装器
} catch (InvocationTargetException e)
{
Throwable exc=e.getCause();
int oldPassed=passed;
ExceptionTest3[] excTests=
m.getAnnotationsByType(ExceptionTest3.class);
for(ExceptionTest3 execTest:excTests)
{
if(execTest.value().isInstance(exc))
{
++passed;
break;
}
}
}catch (Exception exc)
{
}
}
}
}
}7. 始终使用Override注解
只要你认为一个方法声明是要重写超类的方法声明,就应该使用Override注解:但有个小例外:若正在编写一个类,而这个类没有被标记为抽象类,我们认为他会重写其超类中的一个抽象方法,这时我们无需在该方法上放置Override注解。在没有声明为抽象的类中,若它没有成功重写抽象超类方法,编译器会生成错误消息。
大多数IDE为使用该注解提供另外一个理由。若启用了相应的检查,当一个方法没有使用该注解,但重写了超类某个方法时,IDE会生成警告。
除了类中的方法,重写接口中的方法时也可以使用该注解。
8. 使用标记接口来定义类型
标记接口:是一个不包含方法声明的接口,它只是标记一个实现了该接口的类具有某种属性。例如,Serializable接口,标明该类可以被序列化。
与标记注解相比,标记接口有两大优势:
标记接口定义了一个由被标记类的实例实现的类型,而标记注解没有。若使用标记注解,有些错误可能到运行时才会被发现;而标记接口,可以在编译时捕获这些错误。
另一个优势是,标机接口可以被更精确的定位到:若一个注解类型是用目标类型ElementType.TYPE,它可以应用到任何类或接口。假设有一个只适用于特定接口实现的标记。若将其定义为标记接口,就可以让其扩展那个唯一适用的接口,从而确保所有标记类型也是它所适用的唯一接口的子类型。
与标记接口相比,标记注解的主要优势在于,他们是更大的注解机制的一部分,在基于注解的框架中,标记注解可以实现一致性。
适用场景:若想定义一个不带任何新方法的类型,应该选择标记接口。若想标记除了类和接口之外的程序元素,或者将这个标记与已经大量使用注解类型的框架配合使用,则应选择标记注解。如果不想定义类型就不要使用接口,反之则定义接口。