
参考书籍:
《ApacheRocketMQ进阶之路》第1版 林俊杰 著
一. ApacheRocketMQ综述
1. 为什么高并发系统都绕不开消息中间件?
①互联网架构
一家西式快餐厅最初销售麦辣鸡腿堡,业务简单时收银员直接叫汉堡小哥同步制作,但顾客增多后排长队导致流失。老板引入纸条系统:收银员写下订单放指定点,汉堡小哥异步取单制作,大大减少了排队时间。生意扩大后,新增薯条、披萨等业务,需多厨师协作,收银员写多张纸条负担加重最终离职。老板自建订单系统,厨房屏幕显示订单实现解耦,但系统高并发时易宕机且数据丢失,引发投诉。最终,他采购专业云存储系统解决了问题。
这个故事类比互联网产品发展:初始系统点对点同步调用(如收银员叫单);业务增长超并发极限需异步化提高吞吐(如纸条解峰);业务复杂化(如多食品线)导致维护成本高、程序员离职;自建系统(如订单屏幕)虽实现解耦但可靠性不足(宕机、数据丢失);而专业消息中间件提供高可靠、高性能,解决峰值负载、系统解耦和最终一致性。
因此,大型互联网系统离不开消息中间件,它通过削峰填谷(平滑流量波动)、解耦(分离系统组件)和最终一致性(可靠数据存储)支撑高并发和复杂业务,避免自研系统的局限性。
② 大型互联网遇到的共性挑战
核心概念与能力要求: 消息中间件通过三个关键特性支撑互联网系统:削峰填谷(异步化处理高峰流量,避免系统崩溃,如餐厅老板引入纸条系统缓解排队);解耦(将A系统与B、C、D等多系统的直接交互转为通过消息系统中转,支持异构技术栈,减少接口变更风险);最终一致性(通过消息投递实现分布式事务的一致性,而非强一致性,类似餐厅先收钱再异步供餐)。这些特性要求消息系统具备高可靠性:消息存储高可靠(系统重启或磁盘损坏不丢消息)、消息投递可靠(消费者未确认消费完成,消息不被删除或标记已投递)。
消息中间件的必要性与实践: 在大型互联网业务中,削峰填谷、解耦或最终一致性至少其一常出现,消息中间件成为解决这些问题的通用方案。虽然理论上可自研消息系统(如餐厅老板的自建订单系统),但处理高并发、可靠性和异构环境等挑战复杂;消息中间件作为最佳实践产物,不同产品在原理和特性上各有亮点,能高效满足需求。架构师通常优先选择合适的产品,或在必要时基于开源定制或自研。
③为什么选择Apache RocketMQ
性能与解耦表现: RocketMQ 在支撑大型互联网系统核心需求上表现优异。应对削峰填谷,它具备卓越性能(公开压测显示发送性能媲美Kafka,大量分区时更具优势)和强大消息堆积能力(堆积上限取决于磁盘容量,且在大量堆积时仍能维持良好性能)。在系统解耦方面,其 Topic + 订阅模型 让生产者无需关注消费者数量或状态,专注于消息生产,解耦过程由 RocketMQ 自动完成;同时支持广播模式,满足消息需投递至所有实例的场景。
最终一致性支持与整体价值: 对于实现最终一致性,RocketMQ 提供了关键特性保障,包括消息高可靠存储、可靠投递机制及事务性消息支持,使其成为处理分布式一致性的强有力工具。综合来看,RocketMQ 在应对高并发互联网场景的三大核心挑战(削峰填谷、解耦、最终一致性)上完成度很高,是实用且高效的解决方案。
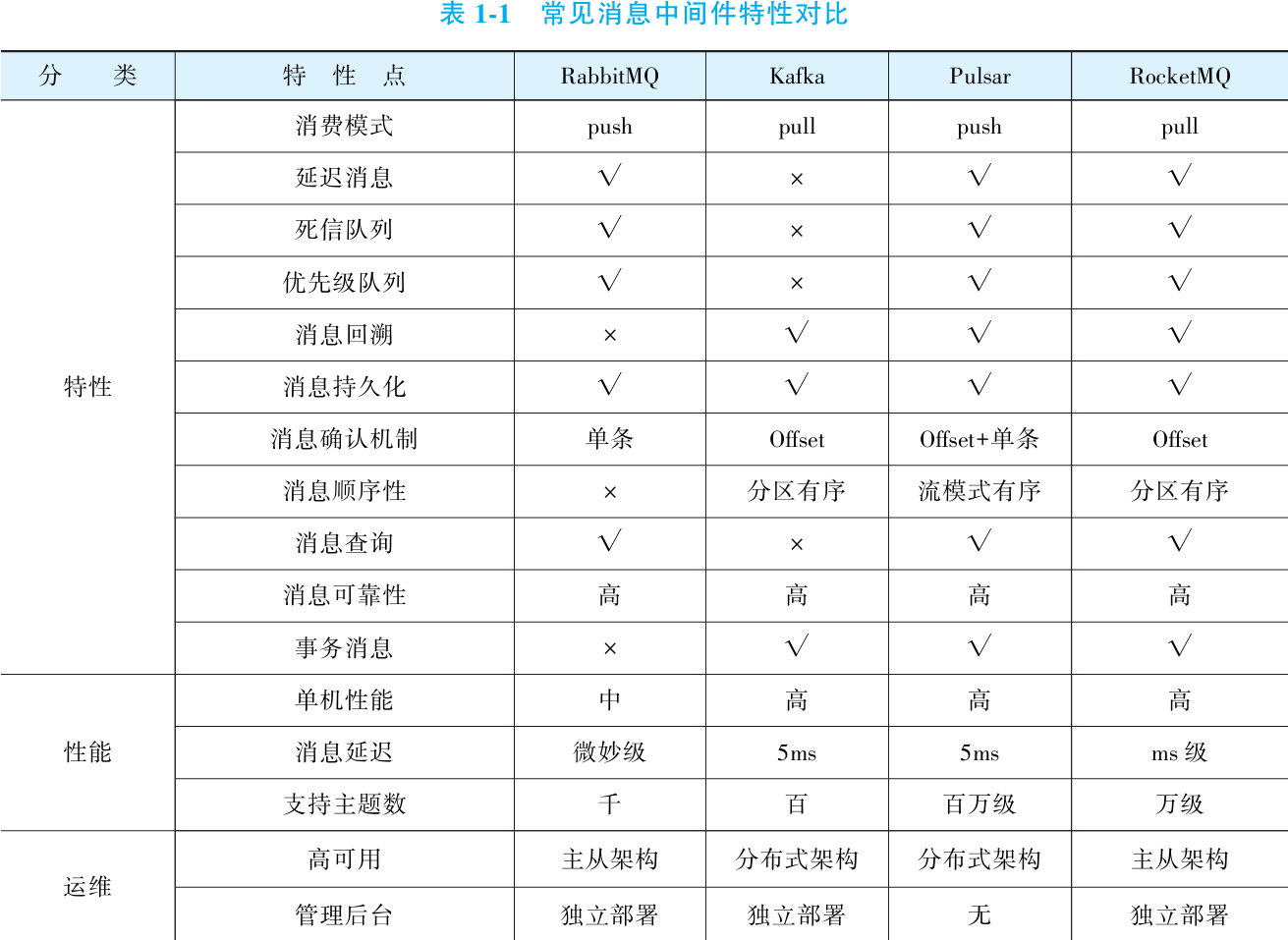
2. RocketMQ 简介
Apache RocketMQ 是一款开源的分布式高性能消息中间件与流数据处理平台,前身为阿里巴巴内部消息中间件 MetaQ。历经“双十一”海量高并发场景考验及3个版本迭代后,MetaQ 升级为通用型 RocketMQ,并于2017年贡献至 Apache 基金会,成为顶级开源项目。凭借强大的性能与可靠性,RocketMQ 已被国内众多互联网企业采用,成功支撑千万级日活应用及复杂金融业务,是国内领先的消息中间件解决方案。
RocketMQ 社区活跃度高,GitHub 获星超19万、分叉超10万。当前最新版本 5.1 面向云原生架构设计,但业界最广泛使用的稳定版本仍为 4.x 系列(如 4.9),其特性与原理也是技术实践的主要参考依据。
3. RocketMQ 核心概念与特性
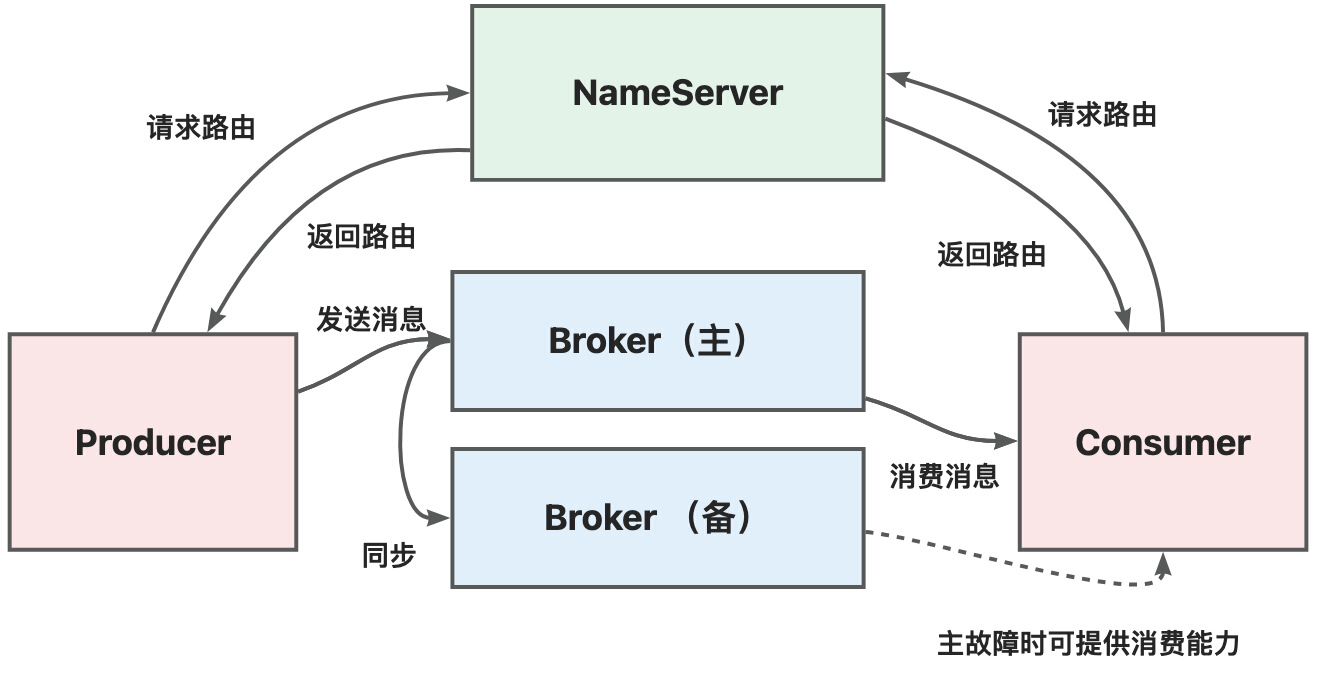
①RocketMQ 组件
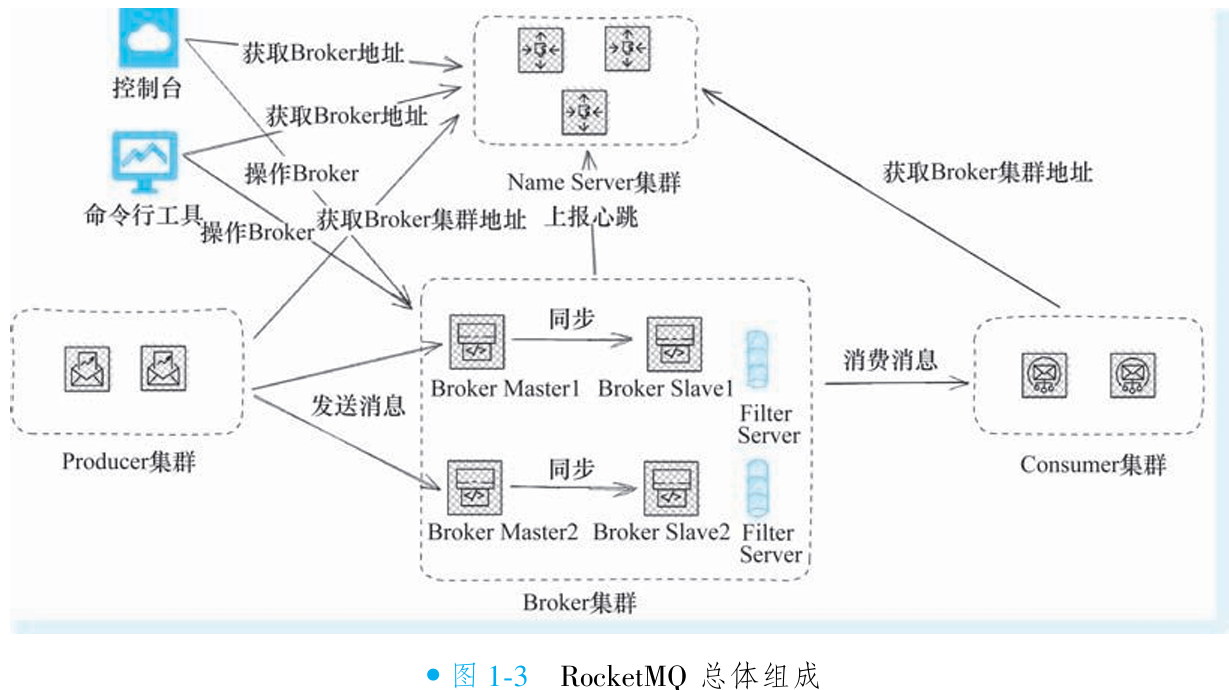
Broker 集群:负责消息存储、转发,每个 Broker 独立存储消息及索引文件。以
group为逻辑单元部署,每组仅含 1 个 master 和多个 slave。写入仅限 master;读取默认由 master 处理,故障时自动切换至 slave 保障可用性。slave 通过同步双写或异步复制从 master 同步数据。NameServer 集群:提供路由寻址服务,聚合所有 Broker 的主题路由信息。采用 无状态设计,节点间无通信(share-nothing),数据全内存存储。客户端随机连接单一节点获取路由,分散压力;若集群全挂,仍可基于缓存与已知 Broker 通信。
生产者集群:集成于应用,随应用集群化形成集群。通过 NameServer 获取主题路由,定位目标 Broker 投递消息。
消费者集群:集成于应用,形成集群后通过 Rebalance 机制分配消息队列,实现负载均衡。支持两种模式:集群模式:消息均匀分发至不同实例(负载均衡控制)。广播模式:所有实例接收全量相同消息。
控制台(Dashboard):运维管理界面,通过 NameServer 获取 Broker 信息,支持主题创建等操作。
命令行工具:临时客户端,执行运维命令后自动销毁连接。
历史组件(已弃用):Filter Server:旧版部署于 Broker 同机,通过自定义 Java Class 过滤消息(如复杂条件超越 Tag 能力)。设计初衷:利用空闲 CPU 资源减少无效消息的网卡占用。弃用原因:RocketMQ 已支持类 SQL92 表达式过滤,无需依赖此组件,且存在安全风险。
②术语
Producer Group:标识发送同类消息的生产者集群,普通消息中仅作逻辑标识。事务消息场景关键作用:标识事务者身份。若某生产者宕机导致事务消息卡在
PREPARED状态,Broker 会向同 Group 其他实例发起回查,决定提交(commit)或回滚(rollback)。Consumer Group:标识消费同类消息的消费者集群,集群内实例 负载均衡消费同一 Topic 消息。消费进度以 Group 为粒度管理,不同 Group 消费进度互不影响(消息可跨 Group 重复消费)。同 Group 内所有消费者必须订阅 相同 Topic 及 Tag。
Topic:消息的 逻辑管理单元,标识一类消息的主题名称。生产与消费均需指定 Topic。
Tag:消息标签,用于 过滤投递。同一 Topic 下,消费者仅接收所订阅 Tag 的消息(如订阅 TagA 则屏蔽 TagB)。
Message Queue:消息的 物理管理单元,一个 Topic 包含多个 Queue(简称 Q)。消息物理分散存储在不同 Broker 节点,支持水平扩展。生产/消费均基于 Queue 操作(如生产者轮询发至特定 Q,消费者拉取分配的 Q)。每个 Q 对应一个
consumequeue索引文件,即使删除也可通过commitlog消息文件恢复。逻辑 Offset:Min Offset:当前可消费的最小偏移量(早于该值的消息已被物理删除)。Max Offset:标识最新消息位置 + 1,随新消息写入递增。
Consumer Offset:标记 Consumer Group 在 Queue 上的 消费进度,语义为 下一次应消费消息的起始位置(即最新消费消息 Offset + 1)。持久化机制:集群模式:进度持久化到 Broker。广播模式:进度持久化到本地文件。消费者重启/扩缩容时,先读取持久化 Offset 再发起消费请求。





③RocketMQ 重要特性
集群消费(Cluster):
机制:一个 Consumer Group 内的多个实例分摊消费消息,每条消息仅投递至 Group 中的一个实例。
负载均衡:Group 内实例通过 Rebalance 机制均分 Message Queue(如 Topic 含 3 条队列,3 个实例各消费 1 条)。
效果:因 Producer 轮询发送使消息均匀分布队列,消费者实例可近似实现消息平均消费。
进度存储:消费 Offset 持久化至 Broker。
广播消费(Broadcast):
机制:消息对 Consumer Group 内所有实例各投递一次,不同 Group 亦可同时消费同一 Topic。
实现原理:通过修改负载均衡策略,使 Group 内每个实例拉取全量 Queue 消息。RocketMQ 并没有广播消息这样的概念, 而是通过修改负载均衡策略的方式实现 广播———一个消费组下的每个消费者实例会共享某 Topic 下的 Message Queue 去拉取消费, 所 以消息会投递到每个消费者实例上。
进度存储:消费 Offset 持久化至消费者实例本地。
事务消息:
目标:保证本地事务执行与消息投递的最终一致性。
流程:
① 发送半消息(Half Message)至 Broker →
② 执行本地事务 →
③ 依据事务结果提交/回滚半消息(提交后消息才被投递)。
定时消息(Delayed):
机制:消息发送后延迟投递(如预设 1s/5min/2h 等 18 级延迟)。
实现:Broker 将消息暂存内部主题,由定时任务检测到期后投递至目标 Topic。
限制:4.x 版本仅支持延迟投递(非精确定时)。
顺序消息:
在RocketMQ中并不存在顺序消息这一概念, 但 RocketMQ 通过约束生产者和消费 者的某些行为来达到类似顺序消息的能力。
首先, RocketMQ 要求消费消息的顺序要同发送消息的顺序一致, 且这些消息需要投递到相同的队列。
由于Consumer 消费消息的时候是针对 Message Queue 顺序拉取并开始消费的, 且一条Message Queue 只会给一个消费者 (集群模式下), 所以只要消息生产和消费顺序一致, 那么 就有能力保证同一个消费者实例对于队列上消息的消费是有序的。
达到顺序生产这个要求之后, 还要求消费者消费有序。 RocketMQ提供了顺序消费的模式, 可以保证同一个队列上的消息是串行消费的。 在RocketMQ 中, 顺序消费主要指的是队列级别的局部顺序。
综上两点, 对于生产者而言就要求 Producer 应该以单线程顺序发送该批次要求顺序的消息, 且发送到同一个队列; 而Consumer 端, 则要求启用顺序消费的模式 (使用 MessageListenerOrderly 的回调)。
-
普通顺序消息:
前提:生产者单线程顺序发送至同一队列;消费者启用
MessageListenerOrderly 模式串行消费。效果:正常情况保证队列级顺序;Broker 异常时(如Broker 宕机或重启, 由于队列总数发生发化, 消费者会触发负载均衡。 默认的负载均衡算法采取哈希取模平均, 这样负载均衡分配到定位的队列会发生变化, 使得队列可能分配到别的实例上, 则会短暂地出现消息顺序不一致。)可能短暂乱序。
-
严格顺序消息:
条件:全局仅限 1 条队列(所有消息完全串行)。
代价:牺牲高可用:任一 Broker 不可用则整个集群不可用;同步双写部署下 Slave 切换仍导致分钟级服务中断。


4. RocketMQ 初体验
①安装
下载二进制包:
wget https://archive.apache.org/dist/rocketmq/4.9.5/rocketmq-all-4.9.5-bin-release.zip解压缩:
unzip rocketmq-all-4.9.5-bin-release.zip进入目录即可得到所有二进制包内容:
cd rocketmq-all-4.9.5-bin-release注意:安装依赖的Java8环境,并
Please set the JAVA_HOME variable in your environment
②启动NameServer(启动Broker 之前, 必须要有Name Server)
脚本启动namesrv:
nohup sh bin/mqnamesrv &验证namesrv是否启动成功:
tail -f ~/logs/rocketmqlogs/namesrv.log显示The Name Server boot success...。或者应用根下的nohup.out修改启动参数(内存不足):
bin/runserver.sh的JAVA_OPT="${JAVA_OPT} -server -Xms512m -Xmx512m -Xmn256m"启动成功之后, Name Server进程会在端口9876上进行监听。
③启动Broker
由于前面已经启动了一个NameServer的进程, 端口是9876。 而启动Broker的时候, 需要 指定一个Name Server 地址用于心跳上报, 所以读者可以用以下的命名轻松启动一个Broker实例。
启动:
nohup sh bin/mqbroker -n localhost:9876 &验证:
tail -f ~/logs/rocketmqlogs/Broker.log出现The broker[broker-a,192.169.1.2(本机IP):10911] boot success...。或者应用根下的nohup.out修改启动参数(内存不足):
bin/runbroker.sh的JAVA_OPT="${JAVA_OPT} -server -Xms512m -Xmx512m -Xmn256m"
④消息收发
至此,一个单Master的RocketMQ集群已经部署起来了,我们可以利用脚本进行简单的消息收发。
需要在系统变量中告诉收发消息的例子进程需要连接的NameServer地址在本 机的9876 端口。 当然如果是通过一些公有云做测试, 这里就需要改成公有云的公网域名。
export NAMESRV_ADDR=localhost:9876
然后就可以执行预设好的一些demo命令:
sh bin/tools.sh org.apache.rocketmq.example.quickstart.Producer这时应该会看到类似以下的输出, 即证明发送成功了:
SendResult [sendStatus=SEND_OK, msgId= ...这里实际上是执行了二进制包中的一个org.apache.rocketmq.example.quickstart.Producer 的 示例代码。 这里面的逻辑很简单, 就是立刻创建一个生产者, 然后发送消息, 最后关闭生产 者。
有了消息后, 读者可以启动一个消费者demo进程去消费这条消息。 这样的demo进程同 样已经预先准备好了, 执行以下命令即可:
sh bin/tools.sh org.apache.rocketmq.example.quickstart.Consumer应该会看到类似下面这样的日志输出:
ConsumeMessageThread_1 Receive New Messages: [MessageExt...这个demo进程实际上是启动了一个消费者, 监听了前面生产者demo发送的消息主题, 所以这里就能消费到前面发送的demo消息了。
⑤关闭服务器
完成实验后,我们可以通过以下方式关闭服务(脚本)。
$ sh bin/mqshutdown broker
The mqbroker(36695) is running...
Send shutdown request to mqbroker(36695) OK
$ sh bin/mqshutdown namesrv
The mqnamesrv(36664) is running...
Send shutdown request to mqnamesrv(36664) OK二. RocketMQ 消息生产
1. 生产者概述
在消息中间件体系中,生产者(Producer) 指主动向消息系统投递消息的组件。以 RocketMQ 为例,生产者通常并非独立部署的服务,而是嵌入业务逻辑的集成模块。例如订单创建流程中,消息发送往往只是整体操作的最后环节(前序含数据库存储、缓存更新、外部接口调用等),因此只需通过 RocketMQ 客户端 SDK 接入现有服务,即可实现轻量级消息投递能力。
这种设计遵循 “业务逻辑优先” 原则:生产者作为业务服务的附属组件,避免独立部署带来的运维复杂度,同时通过 SDK 的低侵入性保障开发效率。其核心价值在于解耦消息投递与业务主流程,而非构建独立消息生产系统。
①生产者实例
在消息发送流程中,需创建 生产者实例 用于统一管理与 Broker 及 Name Server 的连接,开发者通过调用该实例的接口即可完成消息投递。出于资源优化考虑,单个应用进程仅需维护唯一生产者实例,此举可显著降低连接数、减少资源管理开销,同时保障高效的消息发送能力。
②生产者组
生产者组是逻辑概念,用于标记一批行为逻辑一致的生产者实例(如订单服务集群中的生产者)。
新建生产者实例时必须指定所属组名,以建立逻辑关联。
同一生产者组可发送多个不同主题的消息(如组
Order_Group同时发送Topic_Payment和Topic_Inventory),无主题绑定限制。当事务消息卡在
PREPARED状态时,Broker 会向该生产者组下的任意存活实例发起事务状态回查(而非必须原发送实例),确保事务状态最终确认。
2. 认识RocketMQ 消息
①消息结构
Topic(主题):消息发送的目标目的地,发送时必须指定。通过 RocketMQ 控制台(Console)或命令行(CLI)手动创建;若 Broker 启用自动创建功能,会在消息发送时自动生成。
Body(消息体):消息的必需内容主体,以消息数组形式存储。产和消费时需确保一致的编码格式(如 JSON),避免解析错误。
Properties(扩展属性):非必需的元信息,用于传递额外数据(如 Key、延迟级别)。支持消息过滤(如基于订单支付时间筛选数据),同时为 Tag 等特殊功能提供存储载体。
Tag(标签):一种特殊属性,本质存储在 Properties 中,用于消息分类(如订单的 create/pay 状态)。发送时仅能附加 一个标签(如
create)。订阅时可指定多个标签(如create和pay),实现细粒度投递控制。
②消息类型
普通消息:最常用的基础消息类型,无投递限制。消息可并发写入主题的不同队列(负载均衡);消费者实例并行消费,支持十万级TPS,轻松打满千兆网卡。
批量消息:本质为发送优化:通过单次API调用发送消息集合(非独立类型)。减少网络IO次数,显著提升吞吐量(尤其适用于日志等高频场景)。
分区顺序消息:将需顺序消费的消息按规则(如订单ID)路由至同一队列。该队列所在Broker成为瓶颈(生产/消费TPS受单机性能限制)。
全局顺序消息:主题全局仅设1个队列(分区顺序消息的特例)。生产与消费均受限于单Broker性能;消费者集群中仅1个实例可消费(违背负载均衡初衷)。
延迟消息:发送时预设延迟级别(如1s/30min/2h共18级),到期后投递。省去自研定时任务系统,适用于订单超时、计划提醒等场景。
事务消息:分布式事务利器:通过特殊事务生产者API发送,确保业务操作与消息投递最终一致。流程保障:半消息暂存 → 执行本地事务 → 提交/回滚 → 消费者可见。场景:解决跨系统数据一致性(如支付+库存扣减)。
3. 消息发送实战
①发送普通消息
步骤:
创建一个生产者的实例。
为实例设置对应的NameServer地址。如果NameServer是集群的话,这里可以填写所 有NameServer实例的地址。
启动生产者实例。
注:以上三个步骤通常是服务启动的时候在初始化动作里完成的。
创建一个消息。
调用接口发送消息。
public class SimpleProducer
{
public static void main(String[] args) throws Exception
{
// 1. 初始化一个生产者实例,初始化时需要指定生产者组名
DefaultMQProducer producer = new DefaultMQProducer("MyProducerGroup");
// 2. 设置 Name Server 的地址
producer.setNamesrvAddr(Constant.IP + ":" + Constant.PORT);
// 3. 启动生产者实例
producer.start();
// 4. 创建一个消息,参数依次为:主题、标签、消息 Body
// 注:原代码中的变量 `i` 未定义,此处修正为固定内容
Message msg = new Message(
Constant.TEST_TOPIC, /* Topic */
Constant.TEST_TAG, /* Tag */
"Hello RocketMQ".getBytes() /* Message body */
);
// 5. 调用 Send 接口发送这条消息,发送结果会同步返回
SendResult sendResult = producer.send(msg);
System.out.printf("发送结果:%s%n", sendResult);
// 6. 当不再使用这个生产者时关闭。实践场景通常是服务关闭的时候才需要关闭生产者
producer.shutdown();
}
}②发送批量消息
发送批量消息和发送普通消息几乎一样,只是发送的时候入参可以传入一个消息列表, 以下是一个Demo。
步骤:
创建一个生产者的实例。
为实例设置对应的Name Server 地址。 如果 Name Server 是集群的话, 这里可以填写所 有Name Server 实例的地址。
启动生产者实例。
注: 以上三个步骤通常是服务启动的时候在初始化动作里完成的。
创建一批需要批量发送的消息实例。 发送的时候要求这一批消息必须要一样的主题, 且waitStoreMsgOK 属性一致, 不支持延迟特性。 还有一个需要注意的点是, 这一批消息加起来 不能大于1MB, 如果大于, 需要做分批。
调用接口发送消息。
public class SimpleBatchProducer
{
public static void main(String[] args) throws Exception
{
// 初始化一个生产者实例,初始化时需要指定生产者组名
DefaultMQProducer producer = new DefaultMQProducer("MyProducerGroup"); // 1)
// 设置Name Server 的地址
producer.setNamesrvAddr("localhost:9876"); // 2)
// 启动生产者实例
producer.start(); // 3)
// 发送批量消息,要求这一批的所有消息都属于一个主题才行,消息的 waitStoreMsgOK 状态要一致,并且不能使用延迟特性
String topic = "BatchTest";
List<Message> messages = new ArrayList<>();
messages.add(new Message(topic, "Tag", "OrderID001", "Hello world 0".getBytes()));
messages.add(new Message(topic, "Tag", "OrderID002", "Hello world 1".getBytes()));
messages.add(new Message(topic, "Tag", "OrderID003", "Hello world 2".getBytes())); // 4)
// 调用批量 send 接口发送
producer.send(messages); // 5)
// 当不再使用这个生产者时关闭
producer.shutdown();
}
}③发送顺序消息
顺序消息的核心价值与实现原理:
顺序消息确保消息按其发布的严格顺序被消费,解决业务逻辑错乱问题。例如,订单场景中:
风险场景:普通消息可能导致消费者先处理“支付订单”,再处理“创建订单”,违反业务逻辑。
RocketMQ 实现方式:
无专门的顺序消息类型标识,而是通过队列级 FIFO 保证顺序(同一队列消息先进先出)。
开发者需使用 shard 规则(如订单号散列)将相同逻辑单元的消息路由至同一队列(例如,同一订单号的消息通过取余运算分配到固定队列)。
借助
send接口重载的MessageQueueSelector参数,可自定义队列选择逻辑。
顺序消息的发送步骤:
发送顺序消息需 5 个步骤(前 3 步通常在服务启动时完成初始化):
创建生产者实例:
DefaultMQProducer producer = new DefaultMQProducer("ProducerGroup");设置 Name Server 地址:支持集群多地址(如
producer.setNamesrvAddr("ns1:9876;ns2:9876");)。启动生产者:
producer.start();。构建消息:与普通消息无异(如
Message msg = new Message("OrderTopic", "TagA", orderData.getBytes());)。调用顺序发送接口:
需传入
MessageQueueSelector对象实现队列选择逻辑。
注意事项与局限性:
顺序保证范围:消息仅保证在队列内顺序存储与投递,无法自动控制消费者并发消费行为。
消费者调整需求:需额外对消费者逻辑优化(如单线程消费或队列绑定),确保完整顺序性(具体方案在后续章节详解)。
适用性:适用于强顺序依赖的业务(如订单流水),但需主动设计队列分配规则。
public class OrderProducer
{
public static void main(String[] args) throws UnsupportedEncodingException
{
try
{
// 1. 初始化生产者实例,指定生产者组名
DefaultMQProducer producer = new DefaultMQProducer("OrderProducer");
// 2. 设置 Name Server 的地址
producer.setNamesrvAddr("localhost:9876");
// 3. 启动生产者实例
producer.start();
for (int i = 0; i < 100; i++)
{
int orderId = i % 10; // 生成订单ID (0-9)
// 4. 创建消息(主题/标签/键/消息体)
Message msg = new Message(
"OrderTopic",
"TagA",
"KEY" + i,
("Order Message " + i).getBytes(RemotingHelper.DEFAULT_CHARSET)
);
// 5. 发送顺序消息(自定义队列选择器)
SendResult sendResult = producer.send(msg, new MessageQueueSelector()
{
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg)
{
Integer id = (Integer) arg;
// 按订单ID对队列数量取余进行散列
int index = id % mqs.size();
return mqs.get(index);
}
}, orderId);
System.out.printf("%s%n", sendResult);
}
// 6. 关闭生产者实例
producer.shutdown();
} catch (MQClientException | RemotingException |
MQBrokerException | InterruptedException e)
{
e.printStackTrace();
}
}
}④发送延时消息
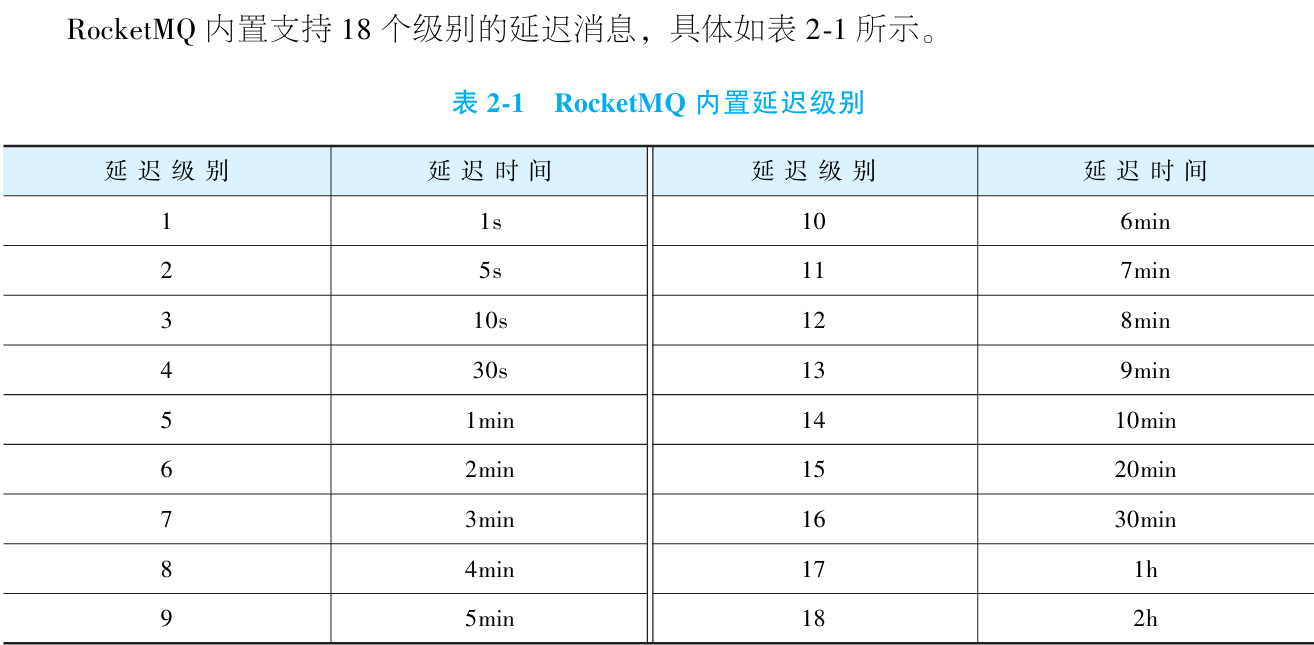
延迟消息是 RocketMQ 的关键特性,用于解决 定时触发类业务需求。典型场景如:
系统在凌晨识别一批目标用户,但需在早上 9 点推送消息(而非立即消费);
此时通过发送延迟消息,RocketMQ 将消息暂存并在预设时间点自动投递,实现精准定时触达。
本质:将 “业务事件生成” 与 “执行时机” 解耦,避免业务层自研定时任务系统。
发送延迟消息的流程与普通消息完全一致,仅需增加一步操作:设置延迟级别。
public class DelayProducer
{
public static void main(String[] args) throws Exception
{
// 1. 初始化一个生产者实例,初始化时需要指定生产者组名
DefaultMQProducer producer = new DefaultMQProducer("MyProducerGroup");
// 2. 设置 Name Server 的地址
producer.setNamesrvAddr("localhost:9876");
// 3. 启动生产者实例
producer.start();
// 4. 创建一个消息,参数依次为:主题、标签、消息 Body
Message msg = new Message("TopicTest" /* Topic */,
"TagA" /* Tag */,
"Hello RocketMQ".getBytes() /* Message body */);
// 5. 设置消息在 10s 后投递消费(延时级别 3 对应 10 秒)
msg.setDelayTimeLevel(3);
// 6. 调用 Send 接口发送这条消息,发送结果会同步返回
SendResult sendResult = producer.send(msg);
System.out.printf("发送结果:%s%n", sendResult);
// 7. 当不再使用这个生产者时关闭
producer.shutdown();
}
}⑤发送事务消息
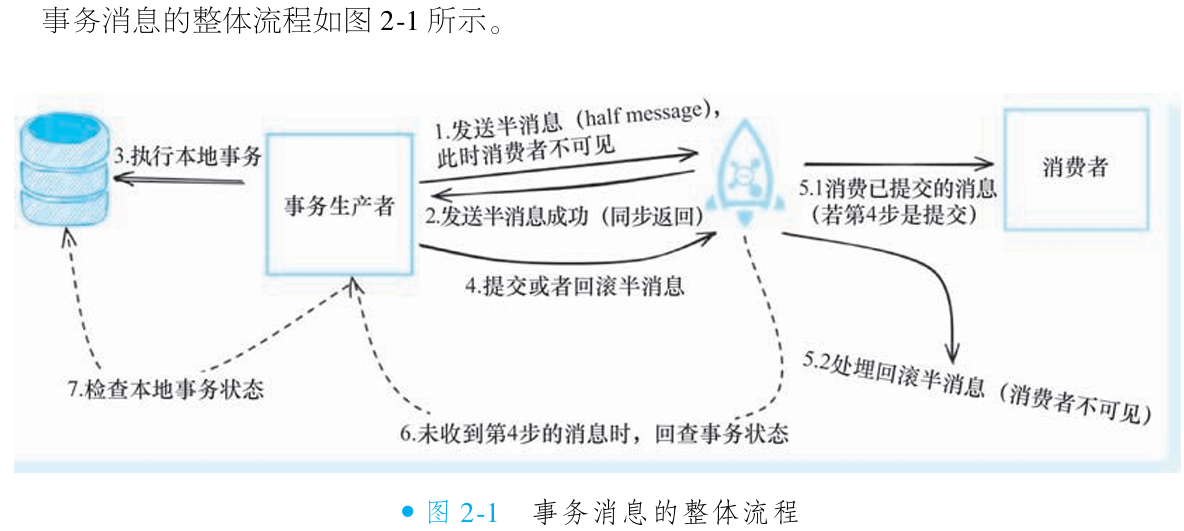
事务消息的本质与核心设计:
事务消息解决 本地业务操作 与 消息投递 的原子性一致问题,规避业务事务成功但消息未发送(或反之)的分布式状态冲突。其独特实现依赖三个关键机制:
半消息(Half Message):消息先发送至 消费者不可见的临时主题,此时消息对消费者屏蔽。
本地事务挂钩:半消息发送后,立即执行关联本地事务(如更新数据库)。
两阶段确认:本地事务成功 → 提交半消息(转为普通消息可消费);本地事务失败 → 回滚半消息(消息永久删除)。
事务状态回查:若生产者宕机未提交/回滚,Broker 定期发起 回查请求,根据业务侧返回的状态决策半消息终态。
开发实现框架(核心接口与逻辑):
开发者需实现
TransactionListener接口定义 事务行为,内含两个方法:executeLocalTransaction:半消息发送后同步触发,执行业务事务并返回状态。checkLocalTransaction:Broker 异步回查时触发,查询持久化事务状态决策消息终态。
事务消息发送流程:
创建一个事务生产者的实例。
为实例设置对应的NameServer地址。如果NameServer是集群的话,这里可以填写所 有NameServer实例的地址。
创建并设置一个线程池,用以执行事务回查。这一步不是必需的,如果没有设置,会 共享一个全局的线程池。
设置好事务回调器实例,用以执行本地事务和回查本地事务状态。
启动生产者实例。
创建消息。注意:这里事务消息和普通消息没有创建上的差异。
调用sendMessageInTransaction接口来发送事务消息。
/**
* 事务监听器实现类
* 随机把三分之一的消息设置为提交状态、三分之一设置为回滚状态,另外三分之一设置为未确认状态
*/
class TransactionListenerImpl implements TransactionListener
{
// 创建一个自增计数器,后面按照自增计数器的值来模拟事务状态
private AtomicInteger transactionIndex = new AtomicInteger(0);
// 创建一个 ConcurrentHashMap 来模拟存储本地事务的状态
private ConcurrentHashMap<String, Integer> localTrans = new ConcurrentHashMap<>();
@Override
public LocalTransactionState executeLocalTransaction(Message msg, Object arg)
{
int value = transactionIndex.getAndIncrement();
// 简单模拟本地事务的动作,按照自增数对3取模
// 余数=0,状态是未知;余数=1,状态是提交;余数=2,状态是回滚
int status = value % 3;
localTrans.put(msg.getTransactionId(), status);
return LocalTransactionState.UNKNOW;
}
@Override
public LocalTransactionState checkLocalTransaction(MessageExt msg)
{
// 这里模拟回查的过程,因为本地事务的状态用本地的 Map 去模拟了,所以这里直接查询 Map 状态即可
Integer status = localTrans.get(msg.getTransactionId());
if (null != status)
{
switch (status)
{
case 0:
return LocalTransactionState.UNKNOW;
case 1:
return LocalTransactionState.COMMIT_MESSAGE;
case 2:
return LocalTransactionState.ROLLBACK_MESSAGE;
default:
return LocalTransactionState.UNKNOW;
}
}
return LocalTransactionState.UNKNOW;
}
}
/**
* 事务消息生产者示例
*/
public class TransactionProducer
{
public static void main(String[] args) throws MQClientException, InterruptedException
{
// 创建事务生产者
TransactionMQProducer producer = new TransactionMQProducer("MyTransactionProducer"); // 1)
// 设置Name Server 的地址
producer.setNamesrvAddr("localhost:9876"); // 2)
// 回查事务执行的线程池,如果没有设置,会使用默认公共线程池,真实场景下建议设置
ExecutorService executorService = new ThreadPoolExecutor(
2,
5,
100,
TimeUnit.SECONDS,
new ArrayBlockingQueue<Runnable>(2000),
new ThreadFactory()
{
@Override
public Thread newThread(Runnable r)
{
Thread thread = new Thread(r);
thread.setName("transaction_thread_");
return thread;
}
}
);
producer.setExecutorService(executorService); // 3)
// 需要准备一个事务回调器,即上面实现好的TransactionListener实例
TransactionListener transactionListener = new TransactionListenerImpl();
producer.setTransactionListener(transactionListener); // 4)
producer.start(); // 5)
// 下面的示意代码尝试发送10条事务消息
String[] tags = new String[]{"TagA", "TagB", "TagC", "TagD", "TagE"};
for (int i = 0; i < 10; i++)
{
try
{
Message msg = new Message(
"TopicTest1234",
tags[i % tags.length],
"KEY" + i,
("Hello RocketMQ" + i).getBytes(RemotingHelper.DEFAULT_CHARSET));
SendResult sendResult = producer.sendMessageInTransaction(msg, null);
System.out.printf("%s%n", sendResult);
Thread.sleep(10);
} catch (MQClientException | UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
// 这里睡眠一段时间,用以观察Broker的事务回查逻辑
Thread.sleep(60000);
// 当确认事务消息不需要发送的时候,关闭生产者实例
producer.shutdown();
}
}4. 消息的三种发送模型
RocketMQ 提供三种核心消息发送模式,其本质差异在于 Broker 响应处理机制:
同步发送:生产者发出消息后阻塞线程,等待 Broker 返回响应(成功/失败状态);可靠性:最高(明确获知投递结果);性能影响:吞吐量受限于网络往返耗时。
异步发送:生产者发出消息后立即返回,通过回调函数异步处理 Broker 响应。可靠性:与同步模式一致(最终获取投递状态);性能优势:线程资源高效复用,吞吐量显著高于同步模式。
单向发送(Oneway):生产者发出消息后无任何等待与响应处理;可靠性:最低(无法确认消息是否到达 Broker);极致发送速度(无等待、无回调)。
①发送同步消息
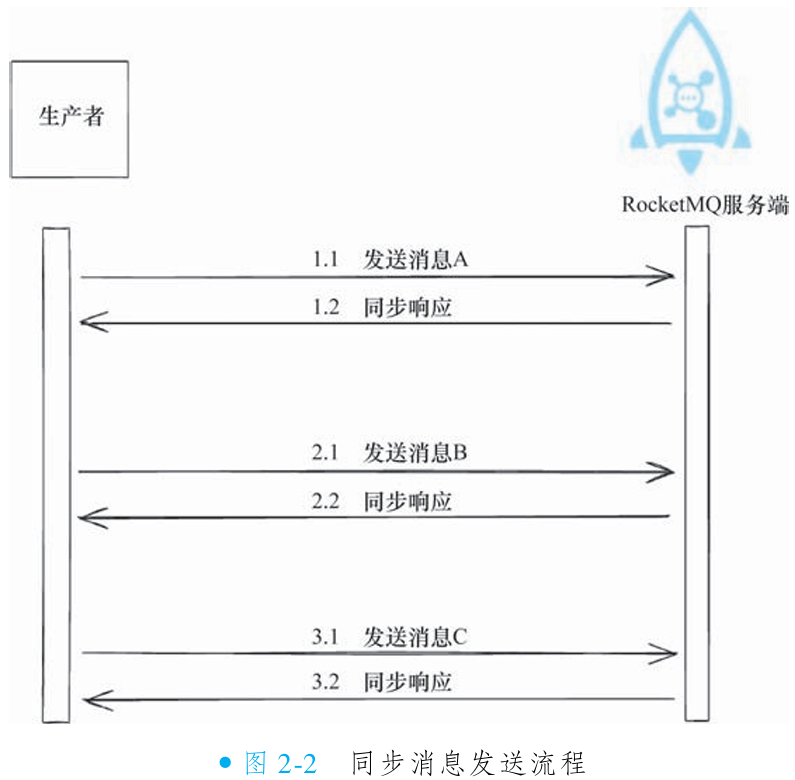
阻塞式交互模型:生产者发送消息后,当前线程立即阻塞,直到收到 Broker 响应或超时;消息按序发送:前一条消息收到响应后,才会发送下一条(如 A→B→C)。
同步消息的发送示意代码其实就是前面提到的发送普通消息的示意代码。

②发送异步消息
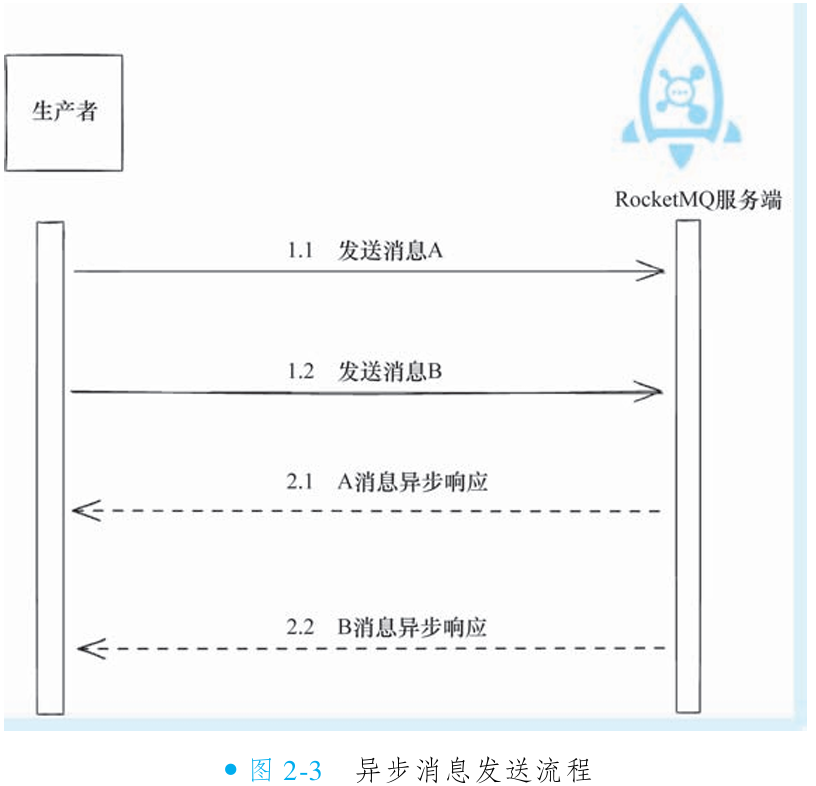
异步消息发送通过 非阻塞式设计 实现高性能与低延迟:生产者调用
send后立即释放线程(不阻塞);线程可继续执行后续操作(如发送下条消息/数据库查询);Broker 返回响应后,RocketMQ 异步触发回调通知结果;开发者通过实现SendCallback接口处理成功/失败逻辑。
public class AsyncProducer
{
public static void main(String[] args) throws Exception
{
// 1. 初始化一个 producer,并设置 Producer group name(生产组名)
DefaultMQProducer producer = new DefaultMQProducer("MyProducer");
// 2. 设置 Name Server 地址
producer.setNamesrvAddr("localhost:9876");
// 3. 启动 producer
producer.start();
int messageCount = 100;
for (int i = 0; i < messageCount; i++)
{
try
{
final int index = i; // 保存当前循环索引(需final)
// 4. 创建一条消息,并指定 topic、tag、body 等信息
Message msg = new Message(
"TopicTest",
"TagA",
"Hello world".getBytes(RemotingHelper.DEFAULT_CHARSET)
);
// 5. 异步发送消息,发送后会立刻返回,发送结果通过 callback 返回
producer.send(msg, new SendCallback()
{
@Override
public void onSuccess(SendResult sendResult)
{
// 发送成功回调
System.out.printf("%d OK %s %n", index, sendResult.getMsgId());
}
@Override
public void onException(Throwable e)
{
// 发送异常回调
System.out.printf("%d Exception %s %n", index, e);
e.printStackTrace();
}
});
} catch (Exception e)
{
e.printStackTrace();
}
}
// 6. 睡眠5秒等待Broker响应(方便观察回调日志)
Thread.sleep(5000);
// 7. 关闭producer释放资源
producer.shutdown();
}
}③发送单向消息
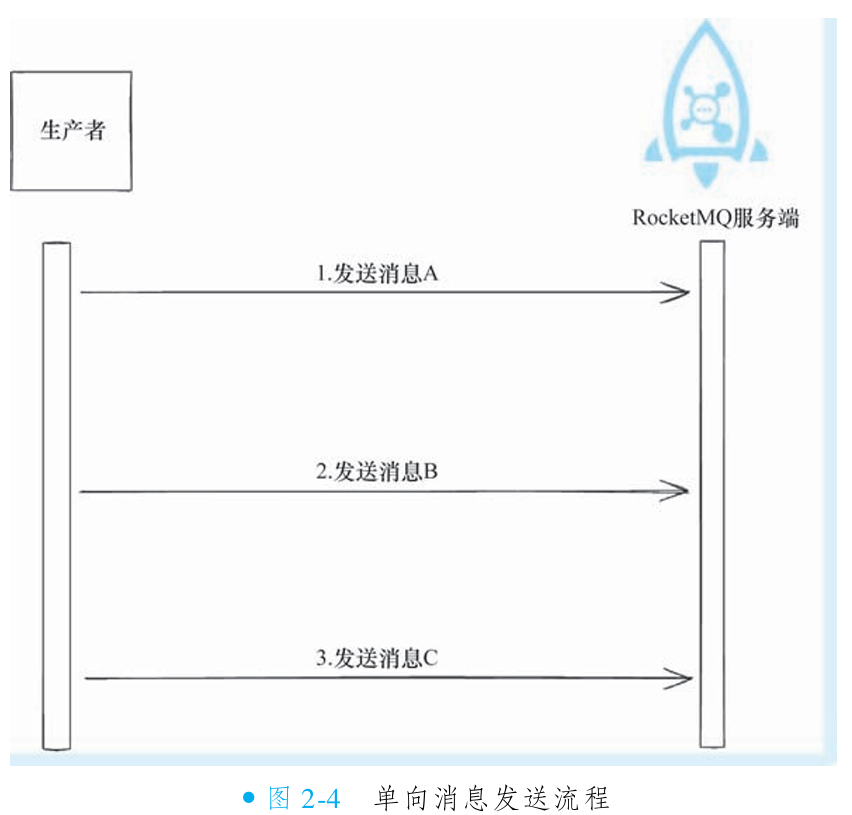
单向消息(Oneway)是RocketMQ的特殊发送模型:
非阻塞设计:生产者调用
sendOneway后接口立即返回(毫秒级耗时),不等待Broker响应,完全忽略结果状态。零感知风险:生产者无法通过返回值或回调获知消息是否成功写入Broker(包括网络中断、队列满等失败场景)。
优势:极致性能(微秒级响应),吞吐量远高于同步/异步模式。
代价:消息可能丢失且无重试机制(Broker异常或网络故障时数据不可恢复)。
适用边界:仅适用于可靠性要求低、可容忍数据丢失的场景(如日志采集、监控心跳)。
发送单向消息和发送普通消息几乎没有区别,唯一的区别就是换成sendOneway接口即可。
public class OnewayProducer
{
public static void main(String[] args) throws Exception
{
// 1) 初始化一个 producer,并设置 Producer group name
DefaultMQProducer producer = new DefaultMQProducer("MyProducer");
// 2) 设置 Name Server 地址
producer.setNamesrvAddr("localhost:9876");
// 3) 启动 producer
producer.start();
try
{
// 4) 创建一条消息:指定 Topic、Tag、消息体
Message msg = new Message(
"TopicTest" /* Topic */,
"TagA" /* Tag */,
"Hello RocketMQ ".getBytes(RemotingHelper.DEFAULT_CHARSET) /* Message body */
);
// 5) 调用 sendOneway 方法发送:通过 oneway 方式发送消息时获取不到发送响应
producer.sendOneway(msg); // ⚠️ 无返回状态
} catch (MQClientException | RemotingException | InterruptedException e)
{
e.printStackTrace();
}
// 6) 一旦 producer 不再使用,关闭 producer
producer.shutdown();
}
}5. 生产者最佳实践
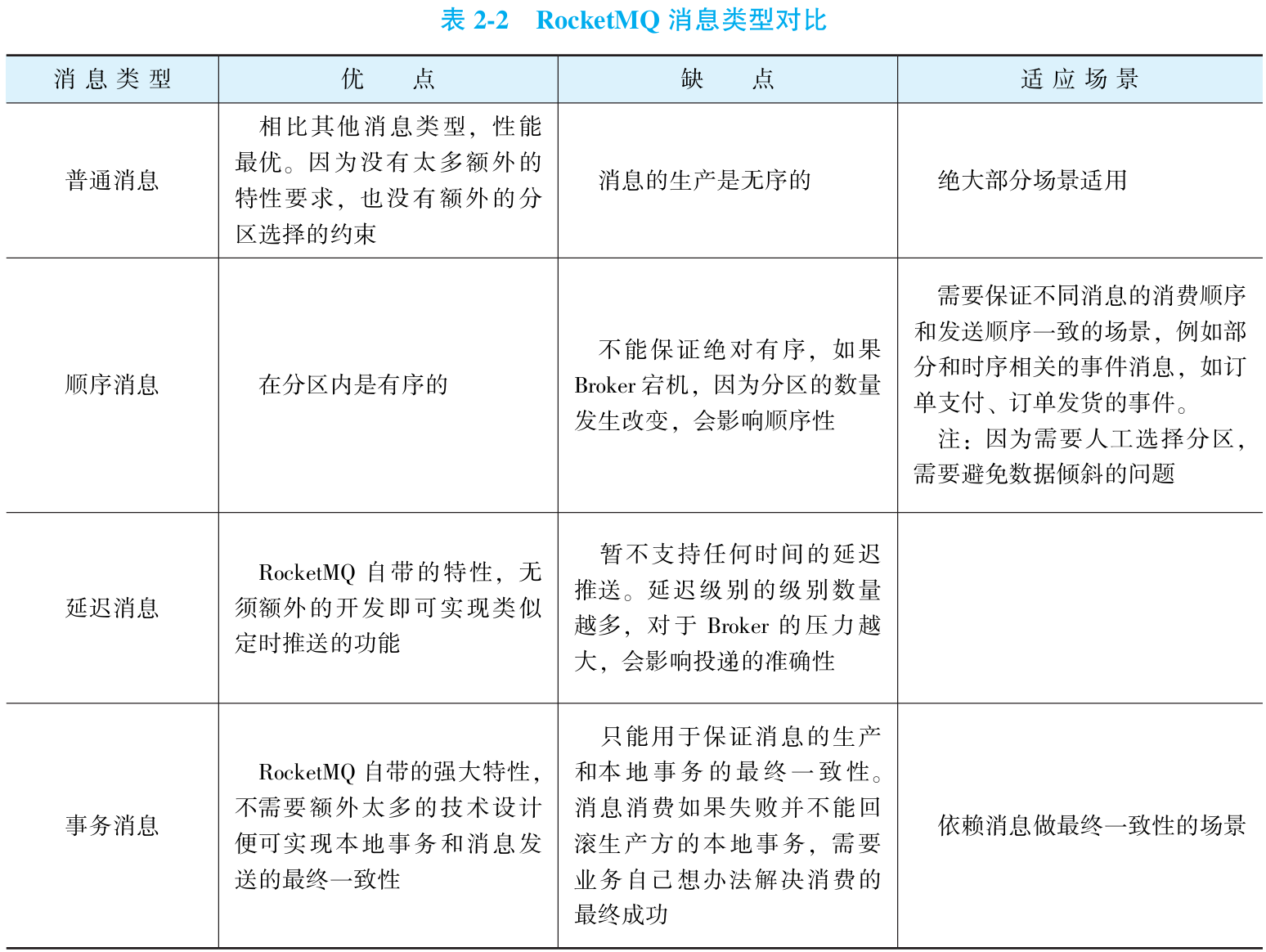
①不同消息类型的选择
②不同消息发送模型的选择
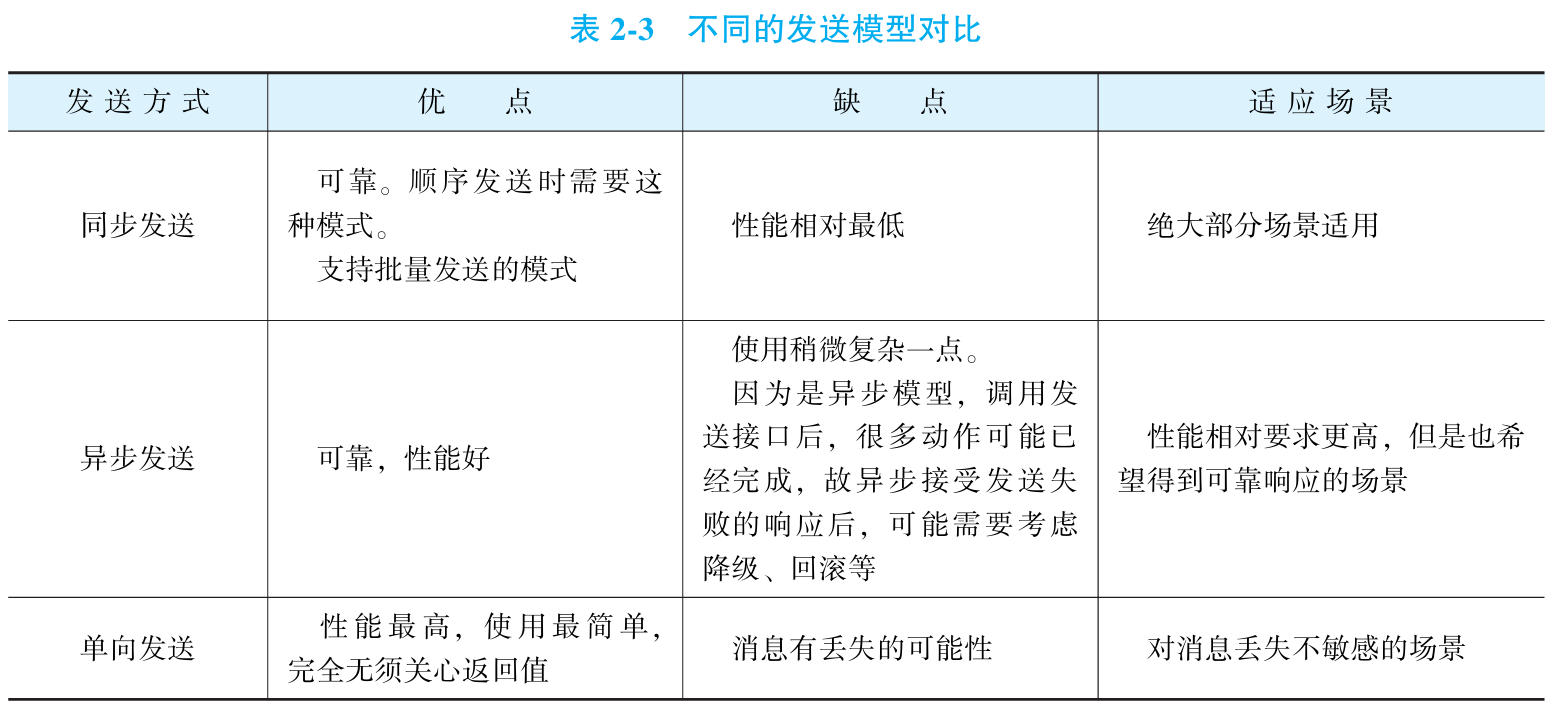
③发送消息的实战建议
Keys 的使用:
较为关键的消息, 尽量在业务层面定义唯一的标识, 用以设置keys字段, 以便定位消息丢 失、 消费轨迹等问题。 RocketMQ支持根据topic、 keys来快速检索一条消息。 但是keys尽可能全 局唯一, 大量的keys重复会严重影响检索的性能。
例如一个订单类的消息, 建议把订单号设置为其keys。
message.setKeys(orderId);
发送日志打印:
每次发送消息之后, 是否成功都会有具体的返回结果。 而且返回结果中除了发送的状态外, 还会返回其msgId、 发送成功的队列、 对应的offset等。 这对于判断消息是否有重复、 消息最终是 否丢失等极为有用, 建议重要的消息发送一定要打印其结果。
发送失败处理:
生产者的发送方法通常都自带内部重试, 重试逻辑如下。
1) 至多重试2次 (同步发送为2次, 异步发送为0次)。
2) 如果发送失败, 则轮转到下一个Broker。
3) 向Broker 发送消息产生超时异常, 就不会再重试。
以上策略一定程度上保证了消息发送的高可靠性。 但是如果业务本身对于消息的可靠性要 求较高, 那么在发送失败的时候, 建议业务在应用层面增加重试的逻辑。 例如把发送失败的消息 持久化到数据库中, 然后使用后台线程重试发送, 以确保消息最后是成功发送的。
Broker 角色:
与Kafka 不同, RocketMQ 消息持久化的可靠性策略并不是在客户端调用发送时决定的, 而 是由Broker 本身的角色决定的。 Broker角色分为ASYNC_MASTER (异步主机)、 SYNC_MASTER (同步主机) 以及SLAVE (从机)。 如果对消息可靠性要求比较严格, 建议采取SYNC_MASTER+ SLAVE 的方式部署。 如果对可靠性要求不高, 对性能要求更高, 可以采取ASYNC_MASTER+ SLAVE 的方式部署。
刷盘策略:
RocketMQ 的刷盘策略分为SYNC_FLUSH (同步刷新) 和ASYNC_FLUSH (异步刷新)。 前者 会损失很多性能, 但会更加可靠。 通常情况下, 如果是带着备机的部署方式, 研发人员可以调整 Broker 的角色以调整可靠性策略, 而不建议改为SYNC_FLUSH的刷盘策略。
三. RocketMQ 消息消费
1. 消费者概述
在消息中间件体系中,消费者(RocketMQ 中称为 Consumer)是消费消息的核心角色。其部署形态取决于业务逻辑的复杂度:
轻量级消费逻辑(如缓存刷新):通常嵌入主业务服务,作为功能模块直接复用服务资源,避免独立部署开销。
重量级消费逻辑(如订单发货、通知处理):需独立部署为专属服务,通过物理隔离保障系统稳定性,同时解耦核心业务链路。
①消费者实例
在 RocketMQ 中,创建消费者实例后,它会管理 Broker 和 NameServer 的底层连接。开发者仅需实现消费消息的核心逻辑,RocketMQ 客户端会自动处理网络连接维护、消息拉取和消费进度提交等细节工作。
②消费者组
消费者组是 RocketMQ 管理消费逻辑的基础单元,用于聚合相同消费逻辑(如订单处理)且订阅关系一致(如相同 Topic 和 Tag)的服务实例。组内多实例自动实现消息队列负载均衡(Rebalance 机制)。消费进度(Offset)以组为粒度管理,组间互不影响
同一消费者组可同时订阅多个不同主题(如同时消费
OrderTopic和PaymentTopic),实现跨业务流统一处理。组内所有实例必须保持完全相同的订阅关系(Topic/Tag 组合一致),否则触发订阅冲突。
2. 消费流程
①消息存储与消息队列的关系
主题与队列的存储关系:在消息生产流程中,虽然发送操作需指定主题(Topic),但实际存储时消息会被分发到该主题下的具体队列(Queue)。Broker 并非将消息直接存储在主题层级,而是通过队列实现物理存储的负载均衡。
队列分配逻辑与优化表述:以含 4 个队列的主题为例,消息发送时需通过策略(如默认轮询算法)确定所属队列。这种设计下,每条消息在逻辑层面必然归属于某个确定的队列,既保证主题的抽象管理能力,又实现存储资源的水平扩展。
②消息消费与消息队列的关系
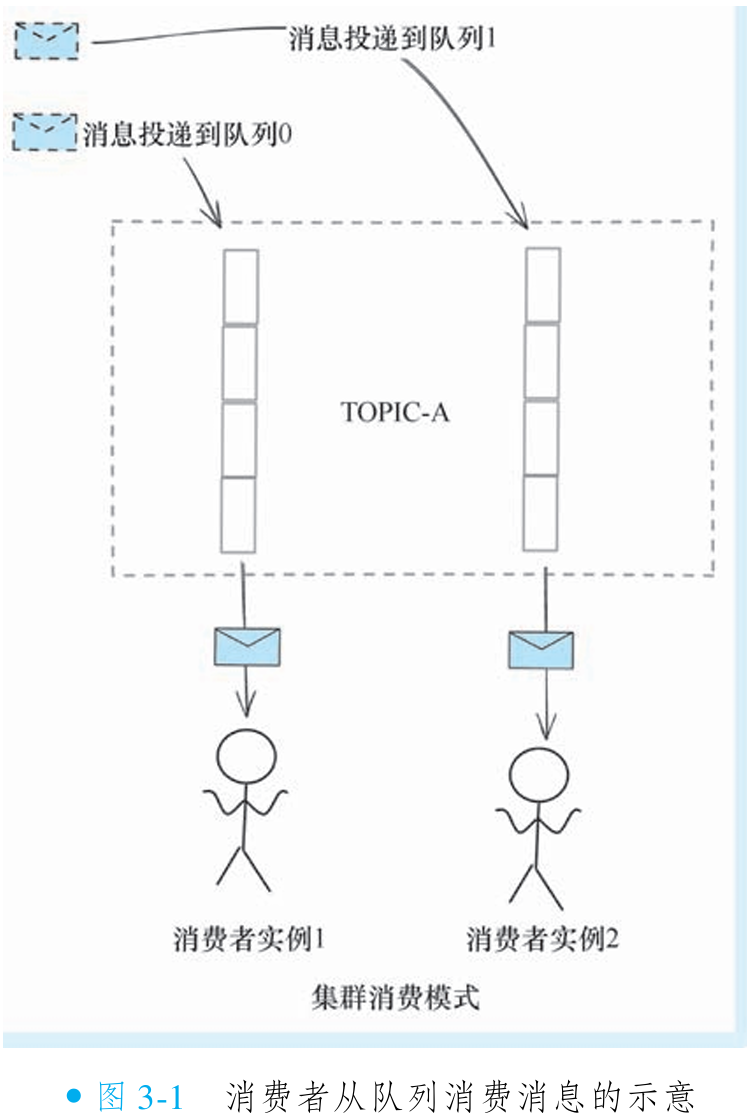
在消息队列系统中,消息的实际存储发生在具体的队列中。如果消费者在主题下的其他队列尝试查找消息,则无法成功获取,因为消费者必须明确知晓目标消息所在的队列位置才能完成查找。
RocketMQ 消费者采用拉取模式,需依赖队列分配机制来执行消费操作。系统会先将队列分配给消费者实例,每个实例仅消费其被分配的队列。这呈现出两个核心规律:同一主题内,队列被消费者实例独占且分配完整,确保无重叠;每条消息被唯一投递到特定队列,仅拥有该队列的消费者实例可消费其中消息。
队列的动态分配过程称为重平衡,它保障了消息路由的精确性和消费的独占性。
3. 消费实战
RocketMQ 提供两种消费者模式:
Push 消费者:封装底层轮询逻辑,消息自动推送至业务代码,开发更简单高效;
Pull 消费者:需主动拉取消息并管理位点,灵活性更高,适合定制化场景。
①Push 并发消费
Push 消费模式本质:
Push 消费通过设置回调方法实现:RocketMQ 自动拉取消息并持续投递至回调逻辑,形成消息被主动推送的交互体验。这种模式包含两种类型:并发消费、顺序消费。
PushConsumer 开发五步法:
创建实例:初始化
DefaultMQPushConsumer,指定唯一消费者组名(组内实例命名需一致)配置路由:设置 NameServer 地址(如
localhost:9876)订阅关系:声明监听的主题与 Tag(同组实例订阅关系必须完全相同,如统一订阅
TopicTest)注册回调:绑定并发消费逻辑(实现
MessageListenerConcurrently接口)启动消费:调用
start()激活消息接收,后续投递至回调方法自动处理
public class PushConsumer
{
public static void main(String[] args) throws InterruptedException, MQClientException
{
// 1) 初始化consumer,并设置consumer group name
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("MyConsumer");
// 2) 设置Name Server地址
consumer.setNamesrvAddr("localhost:9876");
// 3) 每个消费者组可以订阅一个或多个topic,并支持指定tag作为过滤条件,这里指定*表示接收所有tag的消息
consumer.subscribe("TopicTest", "*");
// 4) 注册回调接口来处理从Broker中收到的消息
consumer.registerMessageListener(new MessageListenerConcurrently()
{
@Override
public ConsumeConcurrentlyStatus consumeMessage(
List<MessageExt> msgs,
ConsumeConcurrentlyContext context
)
{
// 打印当前线程名称和接收到的消息
System.out.printf("%s Receive New Messages: %s %n",
Thread.currentThread().getName(),
msgs);
// 返回消息消费状态,CONSUME_SUCCESS表示消费成功
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
// 5) 启动Consumer
consumer.start();
System.out.printf("Consumer Started.%n");
}
}②Push 顺序消费
顺序消息的核心机制:RocketMQ 的顺序消息特性通过将同一批逻辑关联的消息路由到主题的同一队列,实现严格的先进先出(FIFO)投递。该机制要求生产端确保顺序投递,消费端启用队列级串行消费能力。
顺序消费的实现与并发差异:顺序消费需使用
MessageListenerOrderly回调器替换并发消费器,其关键返回状态:SUCCESS:消费成功,继续下条;SUSPEND_CURRENT_QUEUE_A_MOMENT:消费失败,触发阻塞重试
顺序模式下队列严格串行处理:前条未完成,后条不进入回调。
阻塞风险与开发警示:若单条消息持续返回 SUSPEND 状态,将导致整条队列阻塞(消息原地重试直至超限放弃)。开发者需特别注意消费逻辑的健壮性,避免单点故障影响全局吞吐。
public class PushOrderConsumer
{
public static void main(String[] args) throws MQClientException
{
// 1) 初始化consumer,并设置consumer group name(消费者组名)
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("MyOrderConsumer");
// 2) 设置Name Server地址
consumer.setNamesrvAddr("localhost:9876");
// 3) 订阅TopicTest主题(* 表示接收所有tag消息)
consumer.subscribe("TopicTest", "*");
// 4) 注册顺序消息监听器
consumer.registerMessageListener(new MessageListenerOrderly()
{
@Override
public ConsumeOrderlyStatus consumeMessage(
List<MessageExt> msgs,
ConsumeOrderlyContext context
)
{
// 打印接收到的消息
System.out.printf("%s 接收到新消息: %s %n",
Thread.currentThread().getName(),
msgs);
return ConsumeOrderlyStatus.SUCCESS;
}
});
// 5) 启动消费者
consumer.start();
System.out.printf("Consumer Started.%n");
}
}③Pull Subscribe 消费
Pull 模式核心价值与演进:RocketMQ 的 Pull 模式赋予开发者对消费时机和提交行为的精细控制权,尤其适用于限流、限速等特殊场景。4.6 版本前由
DefaultPullConsumer实现,但设计缺陷导致易用性差;4.6 后推出简化的DefaultLitePullConsumer替代旧方案,同时弃用前者。DefaultLitePullConsumer提供 Subscribe 和 Assign 两种消费模式,实现更灵活的拉取控制。Subscribe 模式五步实践法:
初始化:创建
DefaultLitePullConsumer实例,指定唯一消费者组名(组内需统一)路由配置:设置 Name Server 地址(如
localhost:9876)订阅关系:声明监听主题与 Tag(同组实例订阅需完全一致)
启动消费:调用
start()激活消息拉取链路主动轮询:在循环中调用
poll()接口:有消息:返回消息列表供业务处理;无消息:返回null;开发者可结合限速逻辑控制轮询频率。此模式自动处理负载均衡(内置策略),无需额外干预。
public class LitePullConsumerSubscribe
{
// Pull 模式通常需要一个标识位去控制是否需要进行拉取
public static volatile boolean running = true;
public static void main(String[] args) throws Exception
{
// 1) 创建 DefaultLitePullConsumer 实例
DefaultLitePullConsumer litePullConsumer = new DefaultLitePullConsumer("My-LitePullConsumer");
// 2) 设置 Name Server 地址
litePullConsumer.setNamesrvAddr("localhost:9876");
// 3) 订阅主题(支持通配符*)
litePullConsumer.subscribe("TopicTest", "*");
// 4) 启动消费者
litePullConsumer.start();
try
{
while (running)
{
// 5) 主动拉取消息
List<MessageExt> messageExts = litePullConsumer.poll();
if (messageExts != null && !messageExts.isEmpty())
{
// 处理接收到的消息
System.out.printf("接收到 %d 条新消息%n", messageExts.size());
for (MessageExt msg : messageExts)
{
System.out.println("消息内容: " + new String(msg.getBody()));
}
} else
{
// 无消息时短暂等待
Thread.sleep(100);
}
}
} finally
{
// 确保资源释放
litePullConsumer.shutdown();
System.out.println("消费者已关闭");
}
}
}④Pull Assign 消费
Assign 模式的核心特征:Pull 的 Assign 模式需手动管理消息队列与消费位点,不依赖自动负载均衡机制。开发者必须显式指定拉取队列(Queue),相比 Subscribe 模式复杂度更高,但灵活性极强(如定制化队列分配策略)。该模式通常配合手动提交位点(offset)使用。
操作流程关键步骤:
队列分配:通过
fetchMessageQueues获取主题队列列表,主动选择目标队列(如取队列前50%)位点控制:使用
seek接口精准设置消费起始位置(可差异化设置不同队列位点)消息拉取:
poll接口行为与 Subscribe 模式一致,返回消息列表进度提交:手动提交是核心操作,必须通过
commitSync确保位点持久化生产级实践警示:
队列分配策略:需实现消息负载均衡(避免实例间队列重叠)
位点安全设计:极端场景需记录位点快照,防止故障后消费混乱
性能瓶颈:高频手动提交影响吞吐量,需权衡可靠性与性能
public class LitePullConsumerAssign
{
// Pull 模式通常需要一个标识位去控制是否需要进行拉取
public static volatile boolean running = true;
public static void main(String[] args) throws Exception
{
// 1) 创建 DefaultLitePullConsumer 实例
DefaultLitePullConsumer litePullConsumer = new DefaultLitePullConsumer("My-LitePullConsumer");
// 2) 设置 Name Server 地址
litePullConsumer.setNamesrvAddr("localhost:9876");
// 设置自动提交位点关闭,后续需要调用 commitSync() 方法来手动提交位点
litePullConsumer.setAutoCommit(false);
// 3) 启动消费者
litePullConsumer.start();
// 4) 分配拉取队列
// 获取主题 "Topic-Test" 的所有消息队列
Collection<MessageQueue> mqSet = litePullConsumer.fetchMessageQueues("Topic-Test");
List<MessageQueue> list = new ArrayList<>(mqSet);
// 仅取队列的前一半进行消费
List<MessageQueue> assignList = new ArrayList<>();
for (int i = 0; i < list.size() / 2; i++)
{
assignList.add(list.get(i));
}
litePullConsumer.assign(assignList);
// 5) 手动设置位点:将第一个队列的消费起始位置设为 10
litePullConsumer.seek(assignList.get(0), 10);
try
{
while (running)
{
// 6) 主动拉取消息
List<MessageExt> messageExts = litePullConsumer.poll();
// 处理接收到的消息(修复格式错误)
if (messageExts != null && !messageExts.isEmpty())
{
System.out.printf("接收到 %d 条消息%n", messageExts.size());
}
// 7) 手动提交位点
litePullConsumer.commitSync();
}
} finally
{
// 关闭消费者(释放资源)
litePullConsumer.shutdown();
System.out.println("消费者已关闭");
}
}
}⑤集群模式与广播模式
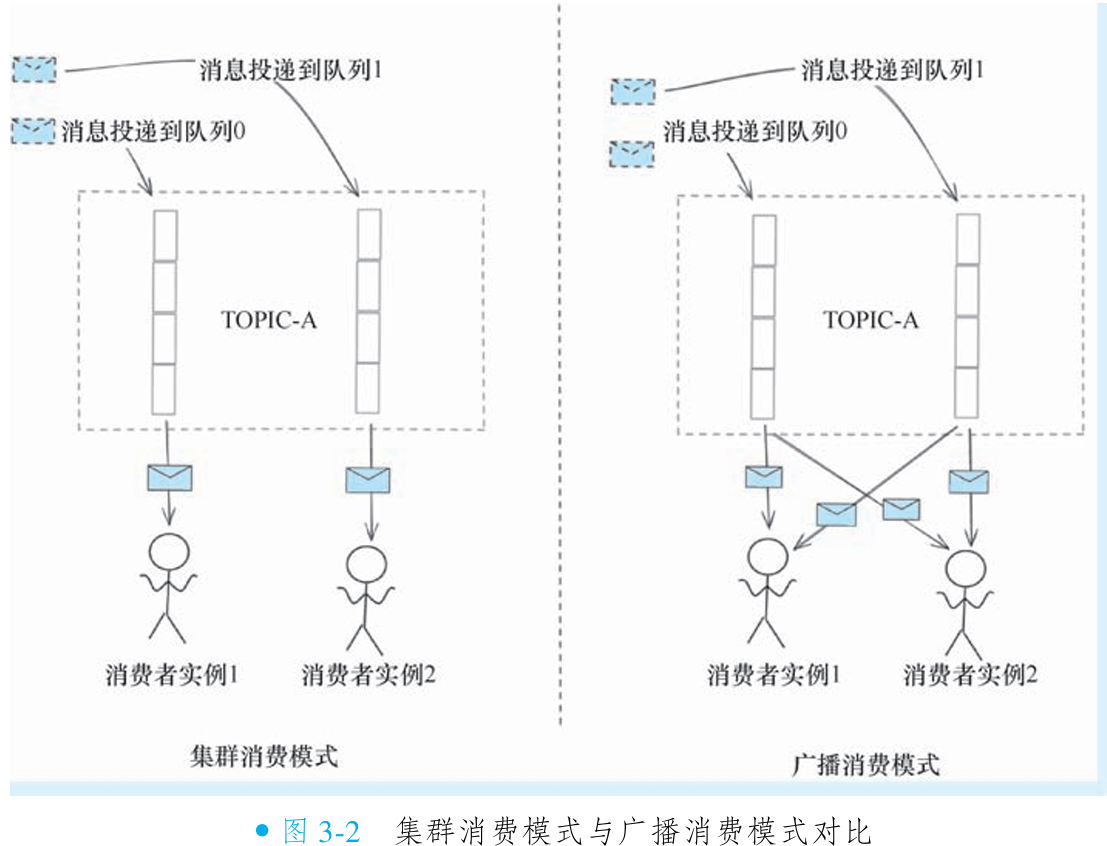
RocketMQ 默认启用集群模式(适用于绝大多数场景),两种模式核心差异在于:
集群模式(CLUSTERING):同一消费者组的所有实例分担消费订阅主题的消息(每条消息仅被一个实例消费),实现负载均衡
广播模式(BROADCASTING):消费者组内每个实例独立消费全量消息(所有实例接收相同消息)
需要在消费者启动之前, 通过一行代码动态指定消费模式(仅 PushConsumer/LitePullConsumer-Subscribe 模式支持):
// 集群模式(默认可省略,但显式声明更规范)
consumer.setMessageModel(MessageModel.CLUSTERING);
// 广播模式
consumer.setMessageModel(MessageModel.BROADCASTING);⑥标签过滤
标签过滤机制的本质与价值:标签是消息系统中用于分类的关键标识,允许开发者在订阅主题时指定过滤条件。该机制让消息消费具备精准定向能力,避免无关消息干扰业务逻辑处理流程。
典型场景实现逻辑:
以订单系统为例:
消息分类设计:创建订单消息 →
create标签;支付通知消息 →pay标签;物流更新消息 →delivery标签。系统级精准订阅:支付系统订阅
pay(仅接收支付消息);物流系统订阅delivery(仅接收物流消息);实时计算订阅*(通配符接收全量消息)。技术本质:通过标签将物理主题拆分为逻辑子通道,实现异构系统间的消息路由解耦与处理效率优化。
// 标签过滤实现说明:
// 1. 订阅所有标签方法
consumer.subscribe("order", "*"); // 使用星号(*)通配符订阅order主题的所有标签消息
// 2. 订阅单个标签方法
consumer.subscribe("order", "pay"); // 仅订阅order主题中的pay标签消息
// 3. 订阅多个标签方法
consumer.subscribe("order", "create||pay"); // 订阅order主题的create和pay标签消息
// 注意:多个标签必须使用双竖线(||)分隔且一次性完成订阅
// 4. 错误示范(必须避免)
consumer.subscribe("TagFilterTest", "TagA"); // 此订阅将被覆盖
consumer.subscribe("TagFilterTest", "TagB"); // 最终生效的是该订阅
// 警告:多次调用subscribe会导致前面的订阅被覆盖!
// 此时Consumer只能收到TagFilterTest主题下TagB的消息
// TagA的消息不会被接收⑦SQL92 过滤
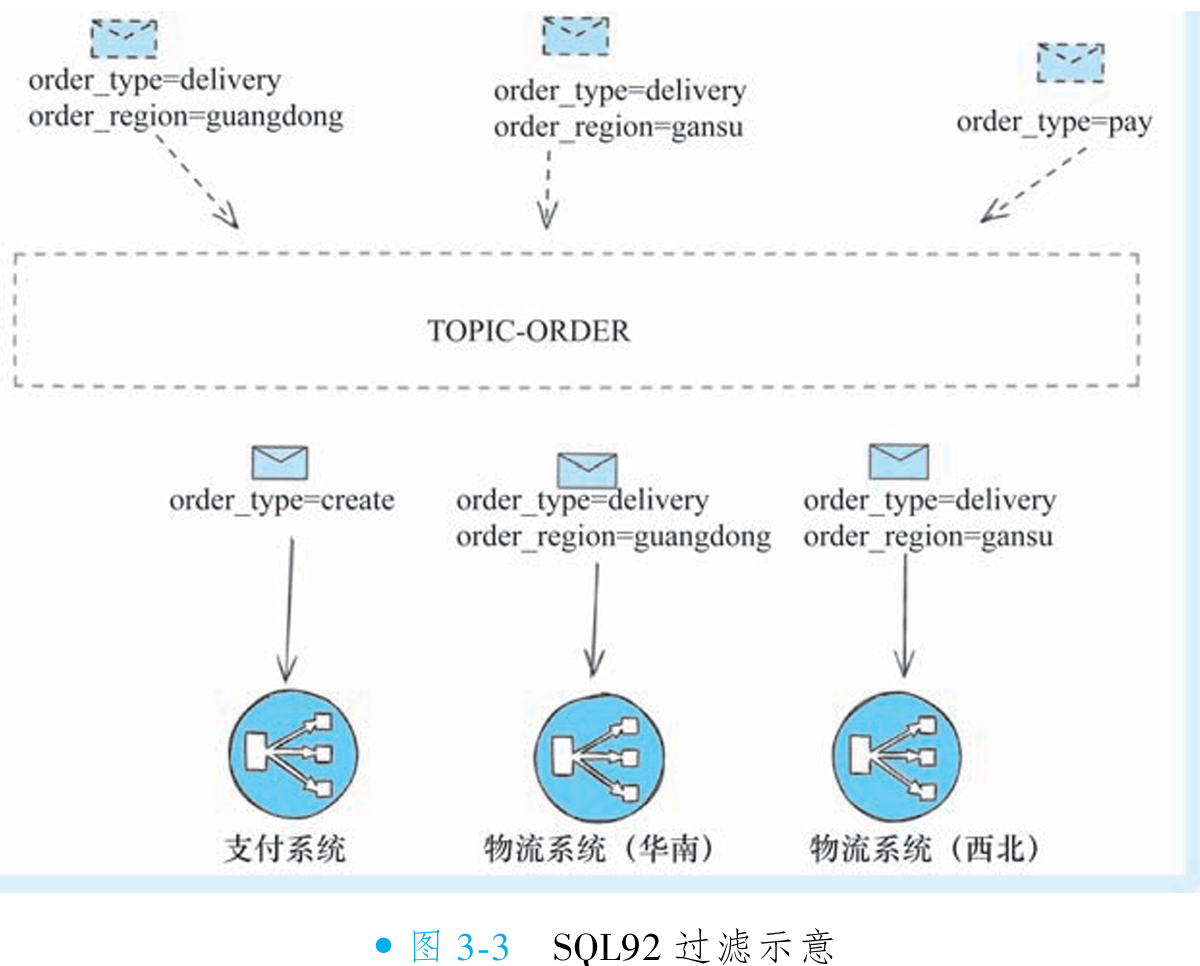
SQL92 提供基于消息属性的高级过滤能力,解决多维度精准订阅问题。典型场景如物流公司需差异化处理华南(广东订单)与西北(甘肃订单)物流中心消息:
标签系统缺陷:消息仅支持单标签(生产者),(消费者)多标签订阅为“或”逻辑(无法实现
delivery AND guangdong精准过滤)属性机制优势:每条消息可定义无限扩展属性(支持AND OR NOT)(如
order_type=delivery, order_region=guangdong),不同业务系统订阅特定属性组合(华南中心:order_type='delivery' AND order_region='guangdong')SQL92 订阅实现五步法:
创建消费者实例:
DefaultMQPushConsumer("GroupName")(组名需唯一)配置路由地址:
setNamesrvAddr("localhost:9876")定义订阅关系:
consumer.subscribe("Topic", MessageSelector.bySql("order_type='delivery' AND order_region='guangdong'"))注册消费回调:绑定
MessageListenerConcurrently处理消息启动消费者:
consumer.start()SQL92 表达式能力边界:
逻辑计算支持:
数值比较(>、≥、BETWEEN、=)
字符精确匹配(=、<>、IN)
NULL检测(IS NULL / NOT NULL)
布尔逻辑(AND、OR、NOT)
数据类型兼容:
数值(123)
字符('abc',单引号必填)
布尔(TRUE/FALSE)
NULL(特殊常量)
/**
* 要实现SQL92属性过滤功能,需在Broker端开启相关支持(默认关闭)。
* 需在Broker配置文件中设置以下四个参数:
* <p>
* 1. enablePropertyFilter = true
* - 启用基于属性的消息过滤功能
* <p>
* 2. filterSupportRetry = true
* - 支持过滤失败时的重试机制
* <p>
* 3. enableConsumeQueueExt = true
* - 启用扩展的消费队列存储(支持复杂过滤)
* <p>
* 4. enbaleCalFilterBitMap = true (注:原图拼写为'enbale')
* - 启用过滤位图计算优化(提升性能)
*/
public class BrokerConfig
{
// 实际配置示例(需要写入broker.conf配置文件)
boolean enablePropertyFilter = true;
boolean filterSupportRetry = true;
boolean enableConsumeQueueExt = true;
boolean enbaleCalFilterBitMap = true; // 注意原图拼写
}public class PropertyMessageExample
{
public static void main(String[] args)
{
// 创建支付订单消息
Message paymsg = new Message("topic_order", "Hello MQ".getBytes());
// 设置自定义属性:order_type="pay"(支付订单)
paymsg.putUserProperty("order_type", "pay");
// 创建广东地区物流订单消息
Message delivermsg1 = new Message("topic_order", "Hello MQ".getBytes());
// 设置自定义属性:order_type="delivery"(物流订单)
delivermsg1.putUserProperty("order_type", "delivery");
// 设置地区属性:order_region="guangdong"(广东地区)
delivermsg1.putUserProperty("order_region", "guangdong");
// 创建甘肃地区物流订单消息
Message delivermsg2 = new Message("topic_order", "Hello MQ".getBytes());
// 设置自定义属性:order_type="delivery"(物流订单)
delivermsg2.putUserProperty("order_type", "delivery");
// 设置地区属性:order_region="gansu"(甘肃地区)
delivermsg2.putUserProperty("order_region", "gansu");
/*
* 消息属性说明:
* 1. 支付订单:仅标记业务类型(order_type="pay")
* 2. 物流订单:除业务类型外,还包含地区属性(order_region)
* - 示例1:广东物流 (guangdong)
* - 示例2:甘肃物流 (gansu)
*/
}
}/**
* SQL92 过滤消费者实现类
* 华南地区物流系统订阅示例:仅消费 order_type='delivery' 且 order_region='guangdong' 的消息
*/
public class SqlFilterConsumer
{
public static void main(String[] args) throws MQClientException
{
// 1) 初始化 consumer,并设置 consumer group name(消费者组名)
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("SouthChinaDeliveryConsumer");
// 2) 设置 Name Server 地址
consumer.setNamesrvAddr("localhost:9876");
// 3) 使用 SQL92 选择器订阅:
// 仅订阅 order_type=delivery 且 order_region=guangdong 的消息
// 注意SQL表达式:保证非空 + 精确匹配
consumer.subscribe("topic_order",
MessageSelector.bySql("order_type is not null and order_type='delivery' and order_region='guangdong'"));
// 4) 注册并发消息监听器
consumer.registerMessageListener(new MessageListenerConcurrently()
{
@Override
public ConsumeConcurrentlyStatus consumeMessage(
List<MessageExt> msgs,
ConsumeConcurrentlyContext context
)
{
// 打印接收到的消息(修正输出格式错误)
System.out.printf("%s 接收到新消息: %s %n",
Thread.currentThread().getName(),
msgs);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
// 5) 启动消费者
consumer.start();
System.out.printf("消费者已启动%n");
}
}⑧消息重试和死信队列
核心设计目标:AT-LEAST-ONCE语义:RocketMQ通过重试机制确保消息至少被成功消费一次。当消费失败时,系统会固定间隔重复投递该消息,直至达到最大重试次数(并发消费默认16次,顺序消费默认无限次)。
并发消费失败标志:业务逻辑抛出异常或返回
ConsumeConcurrentlyStatus.RECONSUME_LATER状态顺序消费失败标志:返回
ConsumeOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT状态可通过
consumer.setMaxReconsumeTimes(10)动态调整最大重试次数死信队列(DLQ)处理流程:当消息重试达上限仍失败时:转入专属死信主题
%DLQ%ConsumerGroupName(如%DLQ%OrderConsumer);死信消息不再被自动消费,仅支持通过控制台或Admin工具人工处理。重试队列特性:失败消息实际投递至重试主题
%RETRY%ConsumerGroupName(非原Topic),该主题会自动创建并被消费者组订阅。顺序消费重试特殊性:采用本地原地重试(非跨主题重投)以避免破坏消息顺序性;关键风险:若单条消息持续重试失败,会导致整条队列消费阻塞。
4. 消息消费最佳实践
①消费日志
消息消费代码首行必须打印日志(含消息主题、ID、标签、队列、Offset),便于快速追踪链路和定位丢失问题。分布式系统中,此举是消息轨迹的关键锚点,提升系统可观测性。
日志内容需包含以下核心元数据:业务标记:消息标签(Tag);物理路由:队列编号(Queue ID);消费进度:消息偏移量(Offset)
PushConsumer 消费线程池状态需通过日志动态监控:线程名显式打印:日志中强制包含线程名(如
ConsumeMessageThread_OrderGroup_3);性能瓶颈检测:若连续出现同名线程(如..._OrderGroup_1),表明线程池配置异常,需立即扩容线程数。
②消费幂等
由于 RocketMQ 采用 AT-LEAST-ONCE 投递语义,消息重复投递无法避免。对重复敏感的金融交易、订单系统等场景,必须在业务层自主实现去重机制。
③提高消费并行度
消息消费(如数据库操作)大多属于IO密集型任务,消费速度直接受制于下游系统或数据库的吞吐能力限制。
可通过两种方式提高并行度实现:
增加消费者实例数量(同一消费组内),是最常用方法,但实例数不可超过队列总数;
上调消费线程数量,通过调整参数
consumeThreadMin和consumeThreadMax实现,无需额外部署实例。
④批量消费方式
对支持批量处理的业务流程(如订单扣款),开启批量消费可大幅提升吞吐效率。典型场景下:
单条处理:1 个订单耗时 1 秒
批量处理:10 个订单仅需约 2 秒
结合并行消费机制,批量处理相较单条处理可实现 5 倍吞吐量跃升(节省 80% 处理时间)。
通过消费者参数
consumeMessageBatchMaxSize 控制批量消费能力:默认值 1(单条消费模式)
优化设置:调整为 10 即可单次批量消费最多 10 条消息,显著减少循环调用开销。
本质是通过聚合消息处理逻辑,将固定成本(如网络/事务开销)分摊到批量操作中,实现规模效应。金融扣款、库存批量更新等场景优先推荐启用。
⑤大量堆积时跳过历史消息
当消息严重堆积导致消费延迟时,RocketMQ 的 FIFO 特性会阻塞后续消息处理。对于时效性敏感的业务(如会议提醒),过时消息已失去价值(如延迟一小时的会议提醒失效),此时需实施优先级策略:
主动丢弃过期消息:牺牲非核心堆积消息(如过期提醒),释放队列空间
保障新消息时效:确保新消息快速进入消费状态,维持系统实时性
此策略本质是 局部牺牲以保全整体:
通过识别业务价值衰减特征(如消息时效阈值)
动态跳过无效消息(而非机械遵循 FIFO)
建立系统自愈机制(避免积压蔓延引发雪崩)
/**
* 消息堆积处理策略示例
* <p>
* 策略1:当队列中堆积消息超过10万条时,直接丢弃当前消息批次
*/
class MessageOverflowHandler
{
public ConsumeConcurrentlyStatus consumeMessage(
List<MessageExt> msgs,
ConsumeConcurrentlyContext context)
{
// 获取当前消息的队列偏移量
long offset = msgs.get(0).getQueueOffset();
// 获取消息队列最大偏移量
String maxOffset = msgs.get(0).getProperty(Message.PROPERTY_MAX_OFFSET);
// 计算未处理消息数量
long diff = Long.parseLong(maxOffset) - offset;
// 策略1:当堆积消息超过10万条时的处理
if (diff > 100000)
{
// 消息堆积超过阈值,直接丢弃当前消息
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; // 第2张图内容
}
// 正常情况应在此处添加业务消费逻辑
// ...
// 消费成功
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
}
/**
* 消息过期处理策略示例
* <p>
* 策略2:丢弃超过1分钟未处理的过期消息
*/
class MessageExpirationHandler
{
public ConsumeConcurrentlyStatus consumeMessage(
List<MessageExt> msgs,
ConsumeConcurrentlyContext context)
{
// 遍历当前消息批次
for (MessageExt msg : msgs)
{
// 策略2:检查消息是否超过1分钟未处理
if (System.currentTimeMillis() - msg.getBornTimestamp() > 60 * 1000)
{
// 超过1分钟的消息视为过期,跳过处理
continue;
}
// 正常情况应在此处添加业务消费逻辑
// ...
}
// 消费成功
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS; // 第2张图内容
}
}⑥规范消费者组名
核心原则:微服务与消费者组一对一映射:每个微服务默认对应唯一专属的消费者组名,确保消息消费的隔离性。特殊场景下允许单个微服务使用多个消费者组,但需严格审批。
命名冲突的灾难性影响:不同微服务若组名重复,将共同消费同一批消息,导致业务逻辑错乱;共享消息集群时,团队间需建立组名注册机制,避免跨服务污染
命名规范强制要求:三段式命名:
业务域_服务名_功能(如payment_core_notify);全局唯一性:通过命名中心预注册保留组名;禁止任意字符串:杜绝test/group1等非规范命名。
⑦订阅关系保持一致
同一消费者组内的所有实例必须保持完全一致的订阅关系:包括订阅的主题、标签(Tag)及 SQL92 过滤表达式。
若组内实例订阅关系不一致(如实例A订阅主题T1的TagA,实例B订阅T1的TagB),会导致消息路由混乱、消费结果不可预测等异常现象。
⑧并发消费和顺序消费的选择
顺序消费依赖队列加锁机制,要求对目标队列串行处理。任一消息未完成处理时,后续消息均强制阻塞等待,牺牲了系统并发性能,显著降低吞吐效率。
除非业务逻辑强依赖严格消息顺序(如订单状态机流转),否则应默认采用并发消费模式。此举可释放队列并行处理能力,避免阻塞导致的吞吐量折损。
⑨起始消费位点的设置
RocketMQ 为新消费者组提供三种历史消息处理策略:
末尾位点模式(
CONSUME_FROM_LAST_OFFSET):忽略所有历史消息,仅消费启动后新消息(新服务上线首选)。首位点模式(
CONSUME_FROM_FIRST_OFFSET):全量消费 Broker 中所有现存历史消息。时间戳模式(
CONSUME_FROM_TIMESTAMP):指定时间点(如20230821000000),消费该时刻后产生的消息(历史回溯场景)。
新系统推荐策略:优先选择末尾位点模式,聚焦上线后实时流程
历史回溯须知:
时间戳模式需警惕海量历史消息压垮系统
仅对全新消费者组生效(老组严格遵循上次消费位点)
更换组名即被视为新组(触发历史消息策略)
⑩关于异步消费
PushConsumer 在设计上已默认采用线程池并发处理消息,开发者不应在消费回调方法中额外创建新线程执行消费逻辑。
当消费回调方法执行结束时,PushConsumer 会立即触发消费位点提交(即标记消息已成功处理)。若此时消费逻辑仍在额外线程中运行:位点提交与实际业务处理脱离原子性;额外线程崩溃将导致消息永久丢失;违反 "至少消费一次" 的核心语义保障。
正确并发实践方案:通过
consumeThreadMin/consumeThreadMax控制内置并发度;消费回调保持同步处理逻辑,确保位点提交与业务执行严格一致。
①①消费状态处理
相比 Kafka,RocketMQ 通过消费状态自动处理失败消息:消费成功:自动提交位点,消息标记完成;消费失败:触发延迟重试机制(优于 Kafka 的手动处理)。
关键开发规范:
禁止用
try-catch包裹整个消费逻辑,否则会吞没异常导致重试机制失效。典型场景如反序列化失败(代码 BUG 或消息错位):此类错误无限重试必然失败;正确方案:记录告警日志 + 返回消费成功状态;错误方案:持续抛异常浪费系统资源。
四. RocketMQ运维与管理
1. RocketMQ Admin Tool
①认识RocketMQ 管理工具
RocketMQ 二进制包通常安装在指定路径下(如
/Users/jaskey/rocketmq-all-4.9.5-bin-release)。进入其中的bin目录,可看到大量预置脚本文件,例如mqbroker用于启动 Broker 服务,而mqadmin则是核心命令行工具,提供主题、消费者组和集群管理等丰富功能。
②使用RocketMQ 管理工具
要使用 RocketMQ 的管理工具,需进入安装目录的
bin文件夹,统一通过./mqadmin <command> <args>语法执行操作。其中command代表命令类型,args为对应参数。直接执行./mqadmin(不带参数)可查看所有支持的命令类型及其功能简述。若需获取具体命令的详细帮助文档,可使用mqadmin help <command>查看说明。所有命令的实现逻辑均可在
rocketmq-tools模块的org.apache.rocketmq.tools.command包下找到(如UpdateTopicSubCommand类对应updateTopic命令)。通常无需阅读源码,但在以下场景中参考源码可事半功倍:开发定制化管理平台(需接入公司OA、审计系统时),可借鉴RocketMQ Dashboard的实现逻辑;
编写高级运维脚本(如批量主题迁移),需灵活扩展命令行工具功能。
2. RocketMQ Dashboard
RocketMQ Dashboard 本质上是一个特殊的 RocketMQ 客户端。它与生产者、消费者等普通客户端在核心机制上并无不同:均需从 NameServer 获取 Broker 地址、与 Broker 建立网络连接,并使用同一套通信协议进行交互。其特殊性仅在于交互过程中所使用的具体命令不同。
①Docker 方式安装 RocketMQ Dashboard
拉取镜像:执行
docker pull apacherocketmq/rocketmq-dashboard:latest运行容器:使用命令
docker run -d --name rocketmq-dashboard -e "JAVA_OPTS=-Drocketmq.namesrv.addr=你的NameServer地址:9876" -p 8080:8080 -t apacherocketmq/rocketmq-dashboard:latest,注意替换rocketmq.namesrv.addr为实际 Name Server 地址。安装后可通过
http://localhost:8080访问 Dashboard。若服务器启用防火墙,需开放相关端口。RocketMQ Dashboard:8080
Name Server:9876
Broker:10909、10911
②源码方式安装 RocketMQ Dashboard
要通过源码安装 RocketMQ Dashboard,首先从 GitHub 下载源码(https://github.com/apache/rocketmq-dashboard)并解压。使用 Maven 编译命令
mvn clean package -Dmaven.test.skip=true生成 jar 包,然后通过java -jar target/rocketmq-dashboard-1.0.1-SNAPSHOT.jar运行。启动后默认访问地址为 http://localhost:8080。源码安装后,需在
src/main/resources/application.yml文件中修改配置:端口设置:调整
server.port参数(如 8080)Name Server 地址:在
rocketmq.config.namesrvAddrs下列出地址,支持多集群(例如127.0.0.1:9876和127.0.0.2:9876)。
③使用RocketMQDashboard

3. 主题管理实践
①主题分类
在 RocketMQ 中,Topic 是消息的一级分类,Tag 是二级分类。官方推荐一个应用尽量使用一个 Topic,并通过 Tag 标识子类型,但需谨慎复用,避免不加区分地混合消息。判断是否需独立管理 Topic 时,应基于以下四个维度:
消息类型一致性:不同类型消息(如普通、事务、定时、顺序、广播)应使用独立 Topic,即使功能相似(如订单处理需区分消费模式)。
业务关联性:完全不同业务(如交易与物流)的消息需分 Topic;同类业务(如不同商品订单)可共享 Topic,用 Tag 细分。
消息重要性:重要与不重要消息混用 Topic 时,不重要消息堆积可能阻塞重要消息处理。
消费优先级:不同优先级消息(如物流中时效要求差异)应分 Topic,以确保高优先级消息及时消费。
②主题命名
主题命名虽不影响系统功能,但良好规范能显著降低管理成本并避免潜在问题。建议从三个维度规划命名:
系统标识维度:多系统复用集群时,需以系统名作为前缀(如
trade_order),防止不同系统误用同名主题导致消息格式冲突与消费异常。环境隔离维度:测试/灰度/生产环境共享集群时,应以环境后缀区分主题(如
order_pre/order_formal)。一套业务系统的多套环境需对应独立主题集,避免交叉污染。消息特性维度:按消息类型添加特征前缀:延迟消息 →
delay_前缀(如delay_notify);事务消息 →trans_前缀(如trans_payment)。
③队列数管理
RocketMQ 的队列数量直接影响消费并行能力。建议队列数≥消费者实例数(避免实例空载),且消费者实例数宜为队列数的整数倍(如1:1、1:2或1:3),以实现负载均衡。若比例非整数倍(如8队列对3实例),会导致实例间负载不均。
队列增多会提升管理成本并降低写入性能。
消费速度受限于线程池能力,与队列数无关扩容时建议分两步操作:先扩容读队列,等待消费者获取新队列;再调整写队列数量,避免瞬间消息延迟。
绝大多数情况下, 读队列和写队列都应该是相等的。 但是有些特殊的 情况, 可以临时配置成不一样的数量。 例如当前的队列数是4, 不够用, 需要扩容更多的队列到 8。 这时候如果一下子把读队列数量和写队列数量都调到8, 可能会出现这样一个情况: 在扩容 队列的瞬间, 某些消息的消费延迟变长了。 原因是, 当写队列的数量扩容到8个的时候, 消息就 能马上写入了, 但是队列的分配是需要一些时间的, 并没有那么快, 那么短时间内就可能出现一 些消息进入了新扩容的队列中, 但是还没有把这个新扩容的队列分配出去给消费者的情况。 在 这段时间内, 这些消息就无法及时消费了。 所以在扩容队列的时候可以分成两步执行, 第一步先 扩容读队列数量, 第二步观察消费者实例已经获取到了这些新的队列之后, 再调整读队列的数 量。 用这个方法即可避免扩容队列的过程中部分消息消费延迟变长的问题。
4. 测试环境实践
测试环境的有效管理对研发团队至关重要,主要原因有三:
自主维护需求:研发测试人员接触测试环境远多于生产环境,且需独立完成其管理与维护,有序的维护机制是基础保障。
多环境隔离要求:互联网业务迭代快,需多套独立测试环境支持并行开发,必须通过可靠方法避免消息窜扰,提升协作效率。
多环境隔离要求:互联网业务迭代快,需多套独立测试环境支持并行开发,必须通过可靠方法避免消息窜扰,提升协作效率。
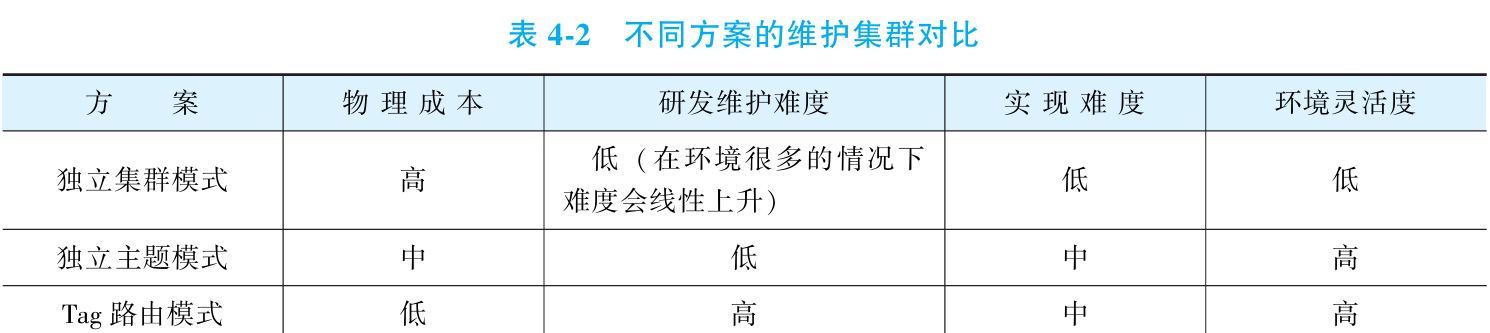
①独立集群模式
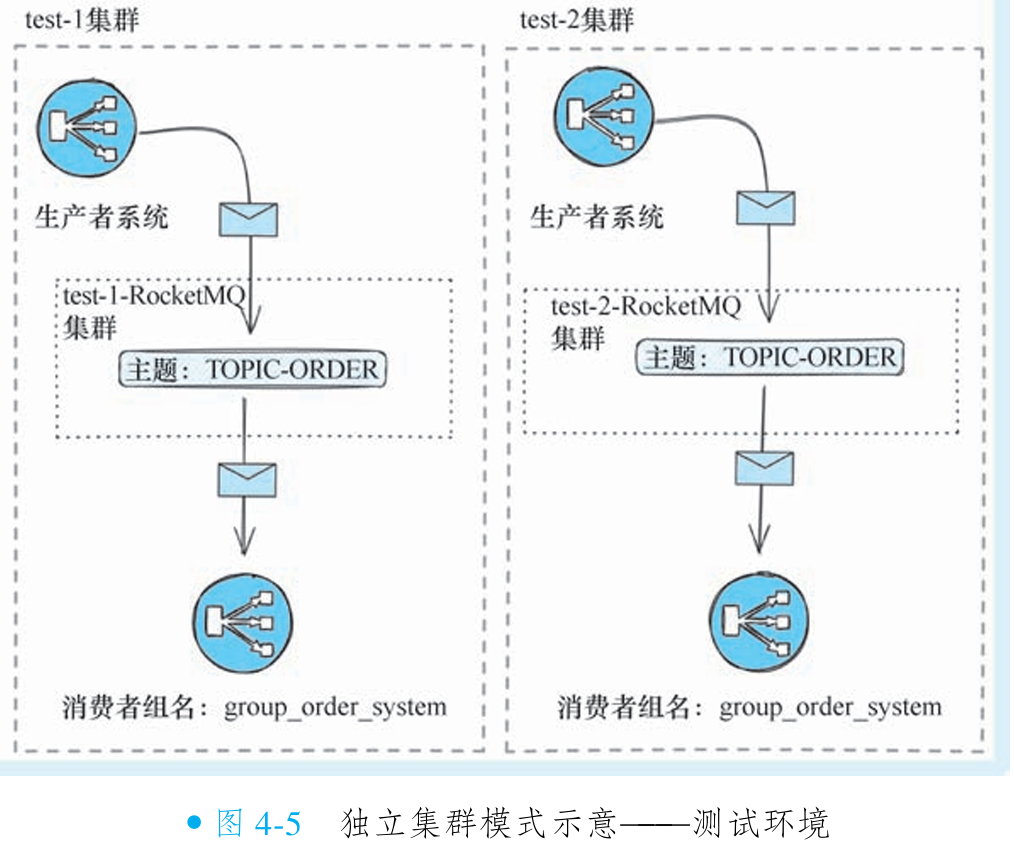
该方案为每套测试环境(如 test-1、test-2)部署独立的 RocketMQ 物理集群,实现环境间消息生产与消费的完全隔离。各环境可使用相同的主题名称和消费者组配置,仅需调整集群连接地址即可切换环境,大幅降低配置维护复杂度。对应生产环境可采用相同架构。
优势:隔离性高、理解简单、维护便捷。
局限:物理集群成本高;环境数量增多时运维复杂度显著上升(需在各集群重复创建主题和消费者组);无法支持动态创建测试环境的需求,缺乏灵活性。
②独立主题模式

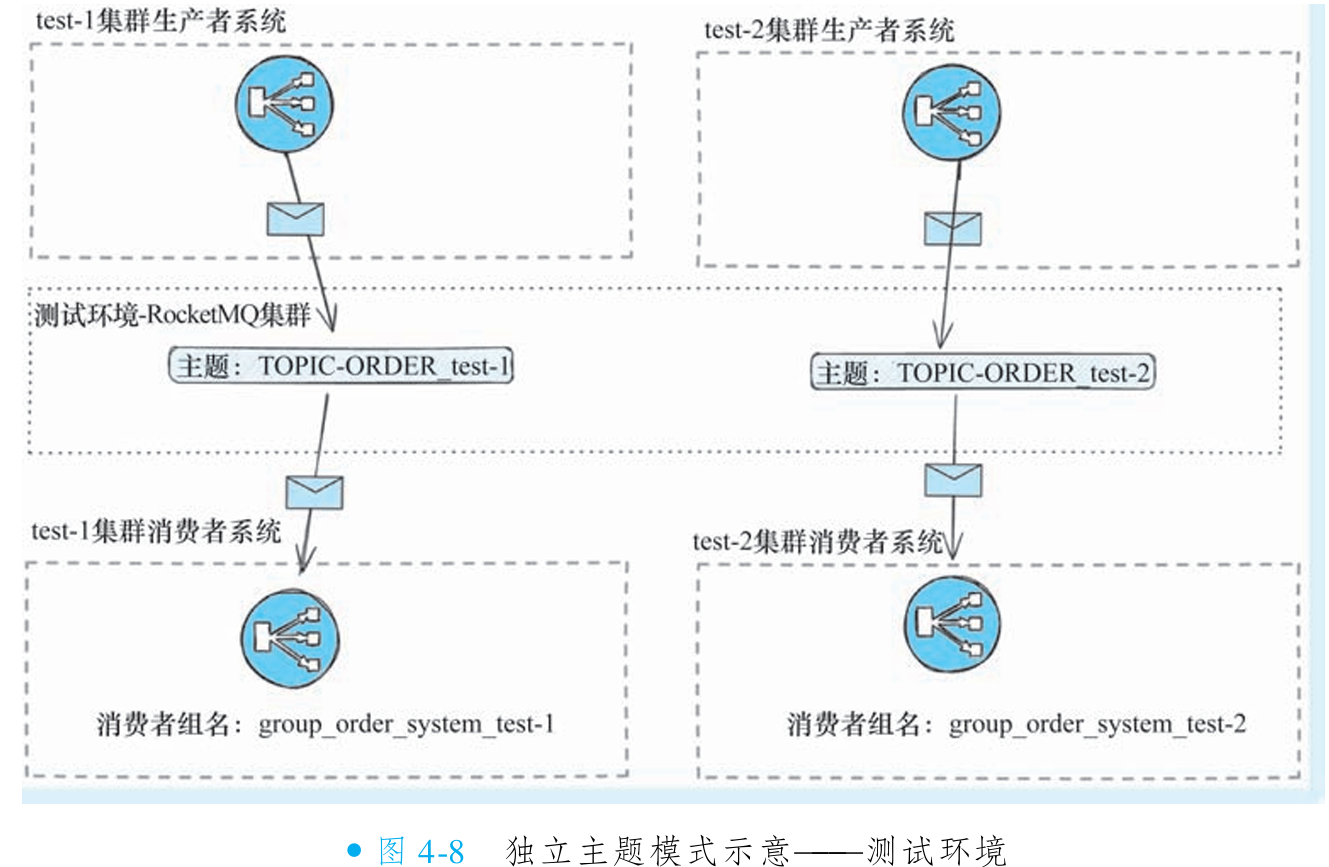

独立主题模式通过单集群多主题实现环境隔离。仅需部署一套 RocketMQ 集群,为每套测试环境(如 test-1、test-2)配置独立主题,采用"业务主题名_环境后缀"的命名规则(如 TOPIC-ORDER_test-1、TOPIC-ORDER_test-2)。
必须为不同环境配置差异化的消费者组名(如 group_order_system_test-1),避免同一消费者组出现订阅关系冲突。若组名相同但订阅主题不同,将导致消息路由异常。
优势:部署成本低,支持动态环境扩展(通过 Admin Tool 可快速创建环境专属主题和消费者组)
劣势:主题数量庞大增加管理复杂度,需在业务代码中集成环境标识(通常依赖配置中心实现动态切换)
③Tag 路由模式
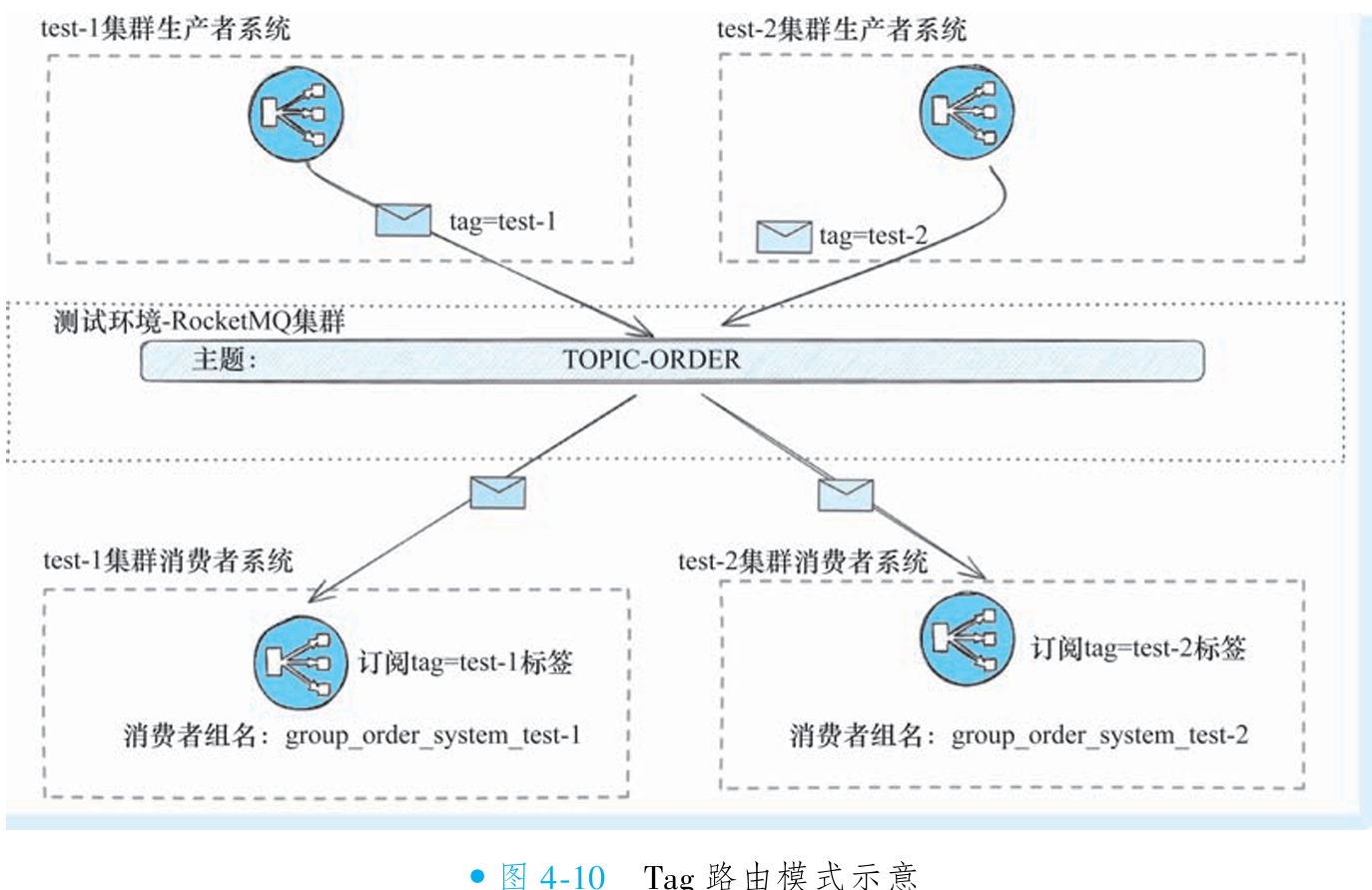
Tag 路由模式通过消息过滤特性实现多环境隔离:所有测试环境共享同一物理集群和主题,但为不同环境的消息打上独立标签(如 test1、test2)。消费者实例通过订阅特定标签(如 test1 环境仅消费 test1 标签消息),实现成本极低的逻辑隔离。该方案大幅减少主题数量和集群部署开销,尤其适合动态环境扩展。
必须确保不同环境的消费者组名唯一(如 group_order_test1、group_order_test2)。若组名重复,即使标签不同,也会导致订阅关系冲突和消息路由混乱,破坏隔离性。
优势:物理维护成本极低(单集群+单主题),支持快速动态扩展环境。
局限:原生标签机制仅支持单标签,需改用 Property 过滤(支持多属性)以避免业务标签冲突;所有环境消息混入同一队列,增加 offset 混乱和问题排查难度。
适用场景:仅推荐测试环境使用,生产环境应切换至独立集群或独立主题模式保障可靠性。
④三种模式对比
5. 生产环境运维实践
①集群缩/扩容

提升消费能力最直接的方式是增加消费者实例,但这要求主题下的队列数充足。若队列不足,需同步扩容队列数量。注意队列分为读队列和写队列,两者的扩容生效机制不同:写队列扩容后立即生效(新消息可即刻写入),而读队列扩容后需要经过客户端重排过程才能分配给消费者,可能存在延迟。
为避免消息消费延迟,建议采用三步扩容法:先扩容读队列数量;观察所有新队列是否均已分配给消费者实例;确认分配完成后再扩容写队列数量。
②集群迁移
当生产集群需迁移(如机房搬迁或配置升级)时,必须满足两大核心要求:
对研发透明:业务系统无感知,无需修改代码或配置
消息零丢失:保障数据完整性,迁移过程不影响业务连续性
迁移三阶段操作指南
新集群部署与校验:
完整复制原集群配置(主题/消费者组/队列数/性能参数)至新集群
将新集群挂载至原Name Server集群(关键透明化措施)
全面验证新集群功能与配置一致性
灰度流量切换与应急方案:
生产者通过Name Server自动发现新集群,逐步写入新消息
消费者自动订阅新集群队列,实现平滑分流
应急禁用方案:关闭新集群或伪造其上报地址(使业务系统不可见);直接禁用新集群读写权限(快速熔断)。
老集群优雅下线:先回收老集群写权限(阻断新消息流入)
监控残留消息是否全部消费完成(读写流量归零)
最终物理下线老集群机器
Name Server地址变更注意:如果Name Server 需要修改, 可以把新的 Name Server 地址新增到 Broker 的配置中 (注意不要直接替换, 否则业务系统会找不到Broker集群)。 最后待合适的时机让业务系统切 换Name Server 集群的地址。
6. RocketMQ 常见部署架构
①单主模式
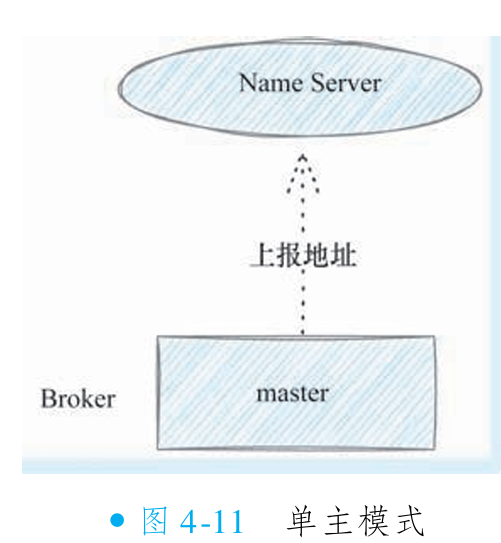
RocketMQ 单主模式是最简部署架构,仅需一个 Broker 节点(作为消息存储核心)和一个 Name Server 节点(负责路由发现)。Broker 与 Name Server 甚至可部署于同一台机器,以极致简化配置。此模式完整支持 RocketMQ 所有功能,但无任何容灾能力,可用性差。
适用环境:仅推荐用于开发或测试环境,满足基本功能验证。
优点:维护极简、物理成本极低。
缺点:无高可用保障,生产环境严禁使用。
②主备模式的架构
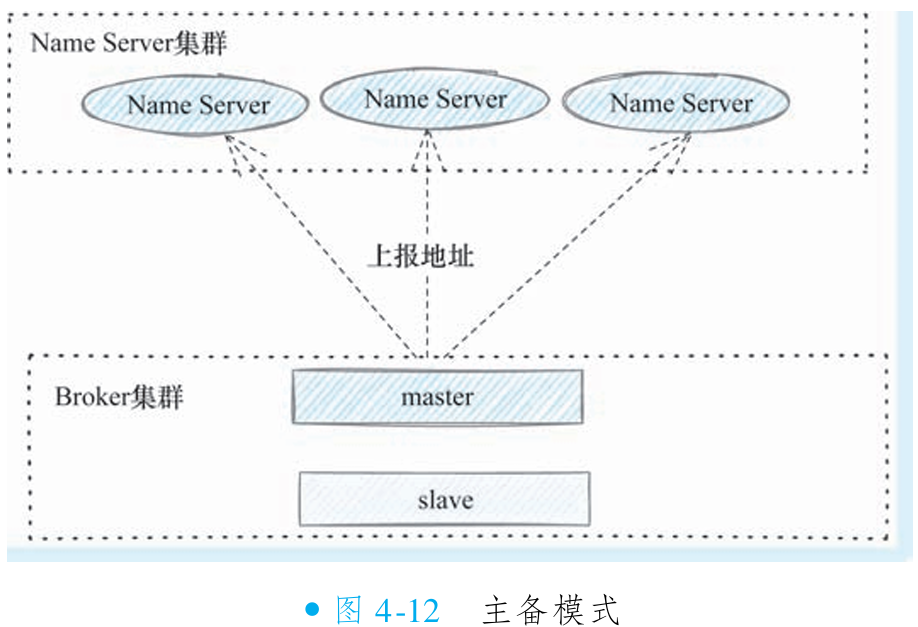
主备模式是 RocketMQ 最常见的生产环境部署方案,通过为 Broker 配置备用节点实现数据多副本存储,显著提升系统容灾能力。当主节点宕机时,备节点可立即接管所有读请求(消费不受影响),但默认不支持自动主备切换(写请求会失败)。从 4.5 版本开始提供 Dledger 集群模式支持主备切换,但因实际生产应用较少,通常不优先推荐。
为实现整体高可用,除 Broker 主备部署外,Name Server 也需采用集群模式(至少 2 节点)。此架构具备维护简单、读写分离、数据容灾等优点,适用于绝大多数互联网生产场景,但仍存在写可靠性不足的缺陷。
为解决主备模式写可靠性问题,可采用多主模式部署(同一集群部署多个主节点),通过写入节点冗余保障写服务高可用。多主模式需配合 Name Server 集群使用,形成完整的高可用生产架构。
③多主模式的架构
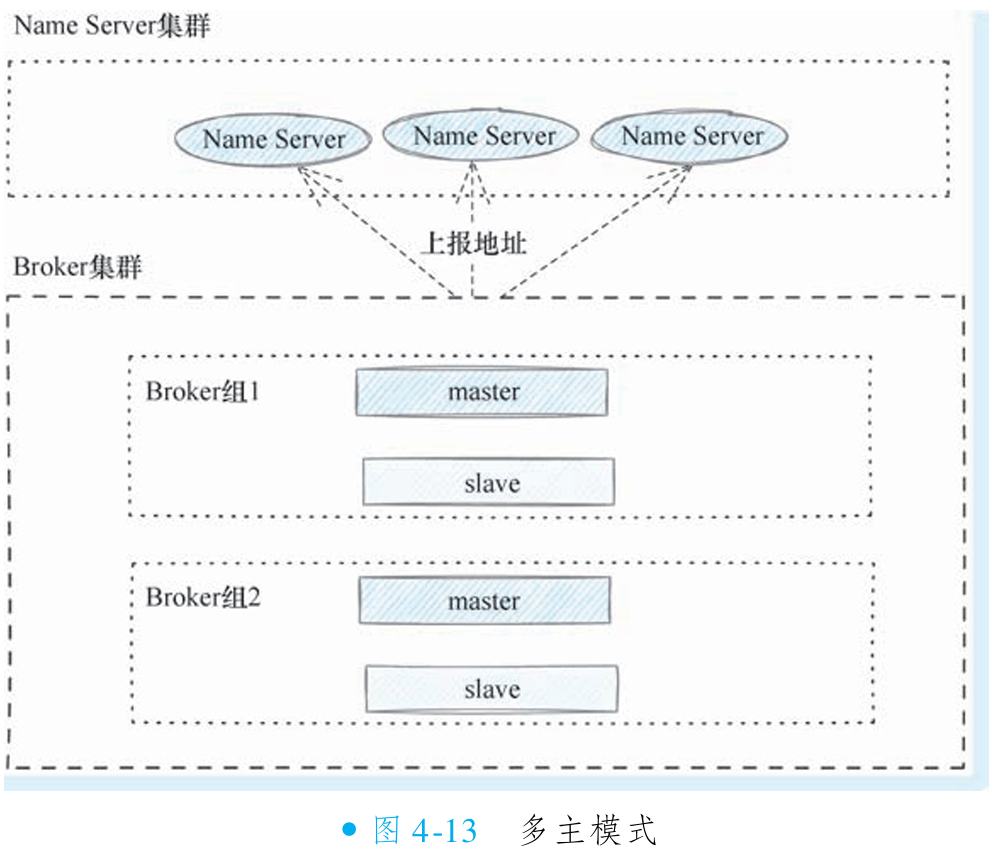
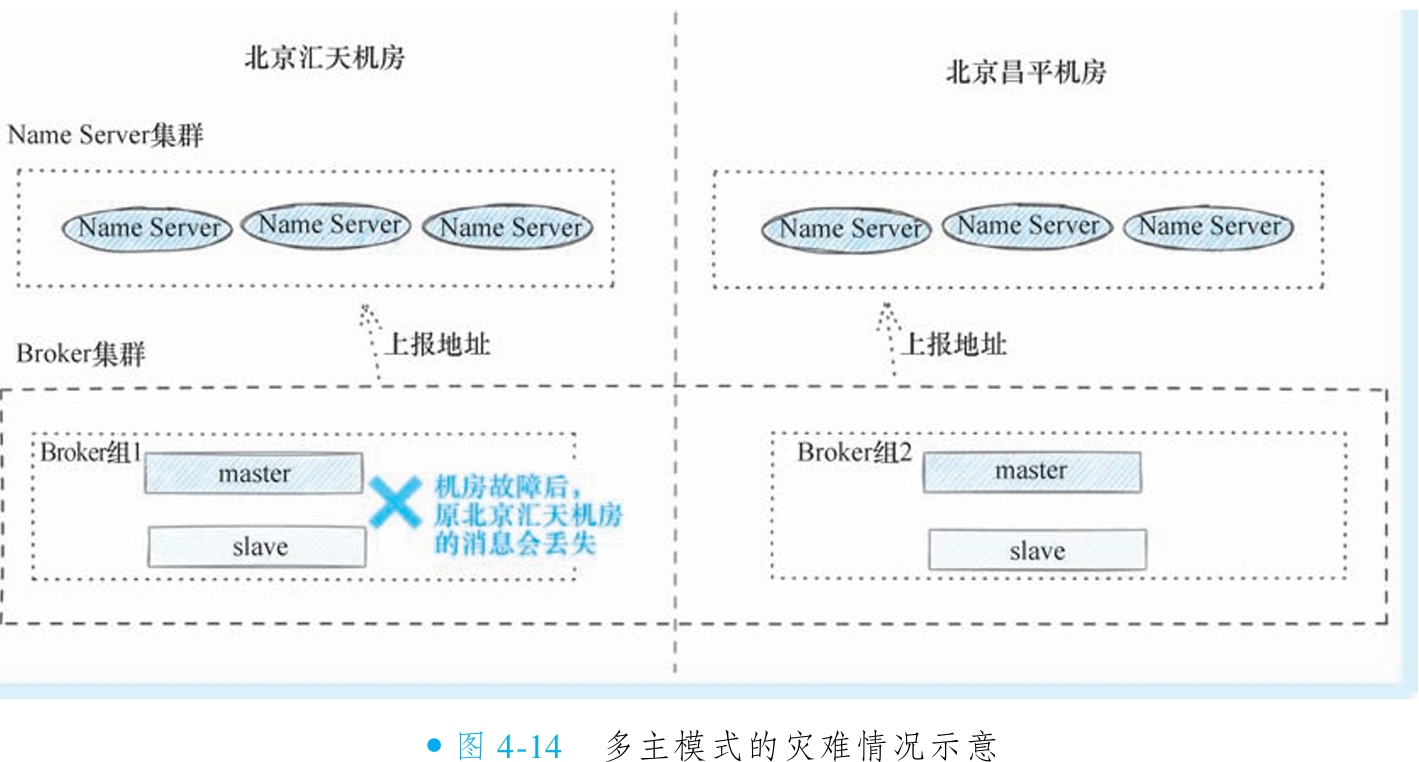
多主模式本质是主备模式的扩展,通过在同一集群部署多组 Broker(每组包含主备节点,共享相同 Broker Name),使客户端感知为单一集群。写操作在多组间负载均衡,一组主节点故障时其他组仍可服务,显著提升写可用性和横向扩展能力,缓解单机性能瓶颈。
尽管多主模式优化了读写性能,但存储层面仍存在单机房风险:同一组消息(包括主从副本)均存储于同一机房。若机房级故障(如整体断电或磁盘损坏),消息将无法恢复,缺乏跨机房容灾能力。
为解决单机房风险,可将多主模式升级为同城灾备模式,实现跨机房消息冗余,保障更高可用性。
④同城灾备模式
什么是同城灾备模式
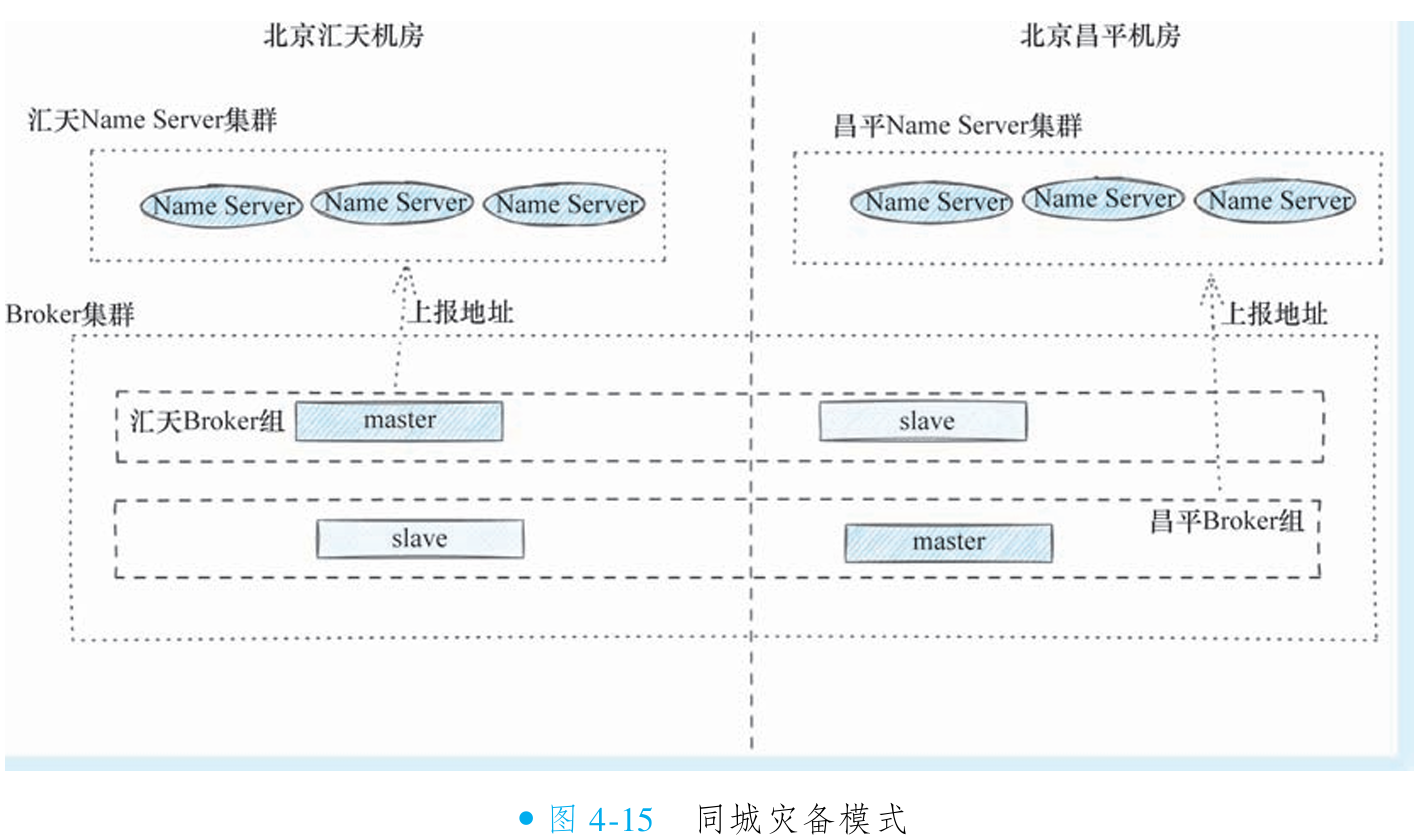
该模式旨在实现两大目标:
跨机房消息可靠性:确保单一机房灾难不会导致消息丢失
跨机房高可用性:单一机房故障时,集群读写服务不中断
关键部署方案:通过主备节点跨机房部署实现冗余容灾(如主节点在汇天机房,备节点在昌平机房)。生产者通过本地Name Server集群将消息发送至主机房,消费者也从本地消费。备节点实时同步数据,形成跨机房备份。
故障恢复机制:当主机房发生重大故障时,运维人员可手动将异地备节点修改为主节点并重启,从而快速恢复服务,保障业务连续性。
同城灾备模式解决消息跨机房高可用问题
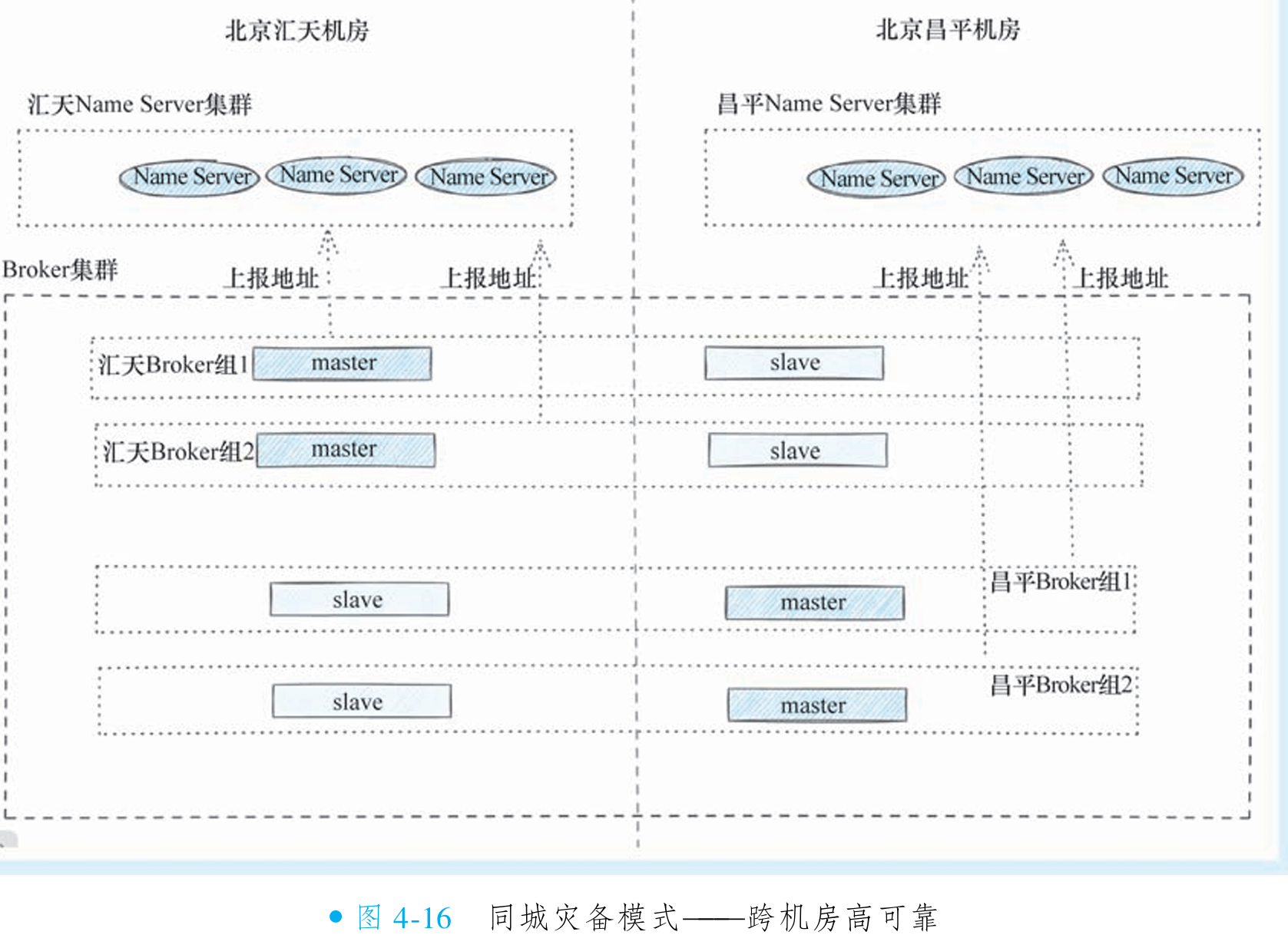

(图4-15)该部署架构旨在实现跨机房高可用性:当汇天机房 Master 宕机时,昌平机房 Slave 可自动接管读服务,保障业务连续性。但基础模式存在致命缺陷——若汇天机房 Master 故障,该机房将完全丧失写能力。
更完善的方案采用多主模式(图4-16):在每个机房部署独立 Broker 组(含 Master),实现写服务冗余。任一机房 Master 故障时,其他机房 Master 仍可提供写服务,真正实现读写双高可用。
同步写入策略下,消息需跨机房写入昌平 Slave 节点才能返回,受网络延迟影响严重。终极优化方案(图4-17)是在 Master 同机房额外部署 Slave 节点,使同步写入优先在机房内部完成,彻底规避跨机房延迟,大幅提升写入性能。
同城灾备模式解决Name Server 跨机房高可用问题

图4-17架构虽已高度完善,但仍存在Name Server未跨机房部署的缺陷:若汇天机房完全崩溃,新服务将无法通过其Name Server寻址,难以实现真正容灾。终极解决方案是将两机房Name Server混合为跨机房集群(图4-18),形成四重保障机制:
寻址高可用:昌平机房Name Server持续服务,避免寻址中断
写入无缝切换:故障时新数据自动写入昌平可用Broker组
消费连续性:原汇天Broker组的队列仍可从其(汇天)Slave节点持续消费
数据恢复保障:即使汇天磁盘全损,仍可通过昌平副本恢复数据
五. RocketMQ 消费原理
1. 理解RocketMQ的推模式
在消息中间件领域消息投递分为两种模式: Push模式和Pull模式。
①Push模式
客户端与消息中间件建立长连接后,当服务端出现消费者订阅的新消息时,会主动将消息推送至客户端,从而实现高效、实时的消息传递。
②Pull模式
在拉取模式(Pull Mode)下,消费者客户端需主动向服务端发送请求以获取消息。由于客户端无法预知消息到达时间,必须通过轮询机制持续查询服务端。典型实现采用无限循环结构:先调用
pullMsg()拉取消息,再通过休眠(如100毫秒)减少无效请求,平衡资源消耗与消息延迟。实际应用中,休眠时间可调整为固定长间隔或动态策略(如阶梯延迟),以优化性能。轮询逻辑不仅适用于消息中间件,亦是消息推送系统、聊天室、配置中心等业务的共性需求——解决数据实时传输问题。核心矛盾在于:休眠时间短则资源消耗大,休眠时间长则消息延迟高,需根据场景权衡策略。
③Push模式与Pull模式的优劣对比
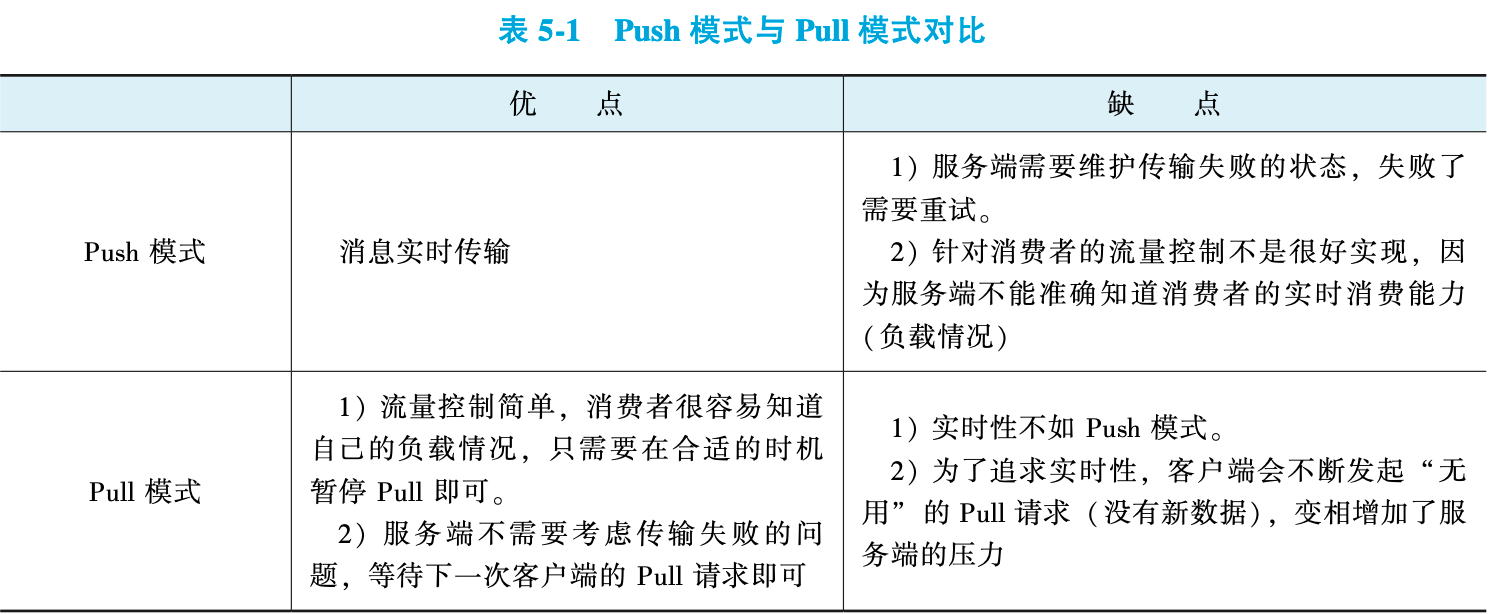
尽管Push模式在消息实时性和性能上更具优势,但RocketMQ及其底层实现均采用Pull模式,包括API中的Push-Consumer(回调编程)和PullConsumer(主动拉取)本质都是基于Pull的变体。
Pull模式通过“长轮询”技术平衡性能与实时性——该机制并非简单轮询,而是服务端持有请求直至消息到达或超时,既减少空轮询开销,又保障了消息投递的实时性。这一设计也被主流推送系统、配置中心等广泛采用。
2. 了解长轮询
①短轮询
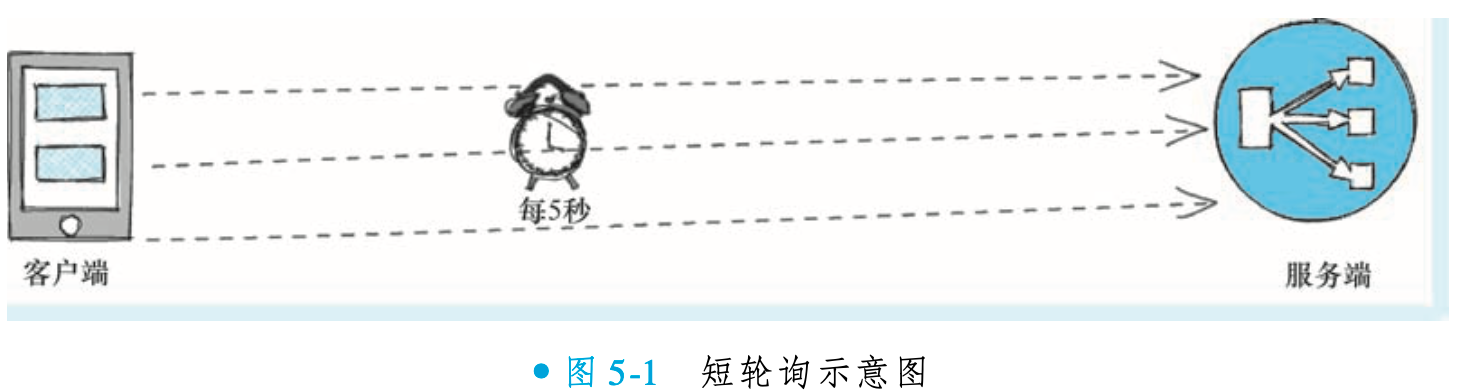
短轮询是Pull模式的一种具体实现方式,其核心机制是客户端周期性地向服务端发起请求以获取最新数据。该方式实现简单,但存在明显缺点:若请求间隔设置过长,数据更新的延迟会相应增加;若间隔过短,则会产生大量无效请求,显著增加服务端压力。因此,在实际应用中,开发者需根据业务对数据实时性的要求,审慎权衡和设置轮询频率。
②长轮询

长轮询是一种结合了推送(Push)和轮询(Pull)优势的通信机制。其核心流程是:当客户端发起请求时,若服务端暂无新数据,会暂时“Hold”住该请求而非立即返回空结果;在此期间,一旦有新数据到达或等待超时,服务端便会立即返回响应。随后客户端迅速发起下一轮请求,循环往复。
该机制的关键优势在于:既避免了短轮询中大量无效请求对服务端的压力,又保证了消息投递的实时性,其效果可媲美推送模式。RocketMQ 正是基于此机制,以 Pull 模式实现了低延迟的消息投递。
3. RocketMQ长轮询实现
①客户端增大超时时间
public class PollingExample
{
// 普通短轮询可能是这样处理的:
public void shortPolling()
{
while (true) {
pullMsg(1000); // 超时时间 1s
// 请求数据的间隔,这会影响数据的延迟性以及服务端的压力
try {
Thread.sleep(5000); // 睡眠5秒,减少请求频率
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
// 长轮询处理:
public void longPolling() {
while (true) {
// 对比原来的普通轮询,所需的修改是设置一个合适的超时时间(足够长的超时时间),RocketMQ 默认是 30s
pullMsg(30 * 1000); // 超时时间 30s
// 注:长轮询的服务端处理空请求实际上会Hold住,所以客户端自身的睡眠就可以不需要了
}
}
// 就这么简单,客户端就完成了长轮询的所有修改了。剩下的工作都需要服务端去支持。
// 假设的 pullMsg 方法,用于模拟消息拉取
private void pullMsg(int timeout) {
// 实际实现中,这里会调用消息中间件的拉取接口
System.out.println("Pulling message with timeout: " + timeout + "ms");
}
}②服务端Hold住无数据的请求
/**
* MQ 服务端处理 Pull 请求的示例代码
* 包含正常情况和长轮询机制的实现
*/
public class MQServer {
/**
* 正常情况下,MQ 服务端处理 Pull 请求逻辑伪代码如下。
*/
public void processReq(/* 这里省略一系列的 pull 入参 */) {
// 针对这次 pull 请求的参数,查找对应的消息,有可能查不到
Object msgs = findMsg(/* ... */);
// 构建网络响应体
Object res = buildResponse(msgs);
// 写响应包
out.writeAndFlush(res);
}
/**
* 长轮询的实现则有那么一点点的区别,如果 findMsg()查不到消息时,需要 Hold 住请求。
* 具体 Hold 住请求的方法:在处理这个 Pull 请求的线程时,如果找不到消息直接空处理。
*/
public void processReqLongPolling(/* 这里省略一系列的 pull 入参 */) {
// 针对这次 pull 请求的参数,查找对应的消息,有可能查不到
Object msgs = findMsg(/* ... */);
if (msgs == null) {
// 查不到数据,不写响应包,直接结束
// 把这个请求“记住”,等消息真的到了,能找到这个请求对应的网络连接
addHoldRequest(/* ... */);
// 请求空处理,对于客户端来说,就好像还没响应一样
return;
}
// 找到消息,回写响应包
Object res = buildResponse(msgs);
out.writeAndFlush(res);
}
/**
* 从上面的伪代码可以看到,如果消息在这次请求没有查到,那么MQ服务端并不会立刻做出网络响应。
* 而由于消费者客户端的超时时间设置了一个长时间(RocketMQ默认有30s之长),所以它会一直处于等待服务端处理状态。
* 在客户端看来,它以为服务端一直在处理它的查询请求,实际上并没有。
*
* 服务端还需要再做一件事:后面新消息到达的时候需要重新写响应回客户端。
*/
/**
* 在消息到达的时候, 除了做存储操作外, 最后还需要增加一个类似下面这样的操作:
* 新消息到来时的一些处理
*/
public void msgArrive(/* 这里省略一系列的入参 */) {
// 针对这次消息对应的 topic、queueId 等参数查找看有没有在 Hold 住的请求
// 这些请求对应上面伪代码里 addHoldRequest 的数据
Object holdRequests = findHoldRequest(topic, queueId);
// 如果查不到 Hold 请求数据(证明没有请求在等待这个主题的消息),不写响应包,直接结束
// 如果查到数据,证明有请求在等待,那么需要处理这些 Hold 请求的响应
if (holdRequests != null) {
for (Object holdReq : holdRequests) {
// 重新再执行查找消息的请求,由于这次肯定有消息了,所以会查到消息
// 查到消息后,立刻就写响应包给客户端,这时候客户端就会得到有新数据的响应
redoPullRequest(holdReq);
}
}
}
/**
* 从上面的伪代码可以看到,如果有新的消息到达,会去检查是不是有在 Hold 的请求,
* 有的话会立刻找出这些请求,把数据传输给客户端,以解决消息的实时性问题。
*/
// 假设的辅助方法
private Object findMsg(/* ... */) { return null; }
private Object buildResponse(Object msgs) { return null; }
private void addHoldRequest(/* ... */) {}
private Object findHoldRequest(String topic, int queueId) { return null; }
private void redoPullRequest(Object holdReq) {}
}③RocketMQ长轮询小结
长轮询通过客户端与服务端的协同优化实现消息高效实时传递:客户端发起请求后,若服务端无新数据,会暂存请求而非立即返回;待新数据到达时,服务端立即响应并推送数据。客户端感知上如同“服务端处理良久但返回实时消息”,实则通过暂存请求机制避免了频繁轮询的资源消耗。
技术实现三要素:
较长超时时间:客户端设置足够长的请求超时(如 RocketMQ 默认 30s)
服务端请求保持:无数据时服务端暂存连接(Hold),非立即返回空响应
实时触发机制:新数据到达时主动检索暂存请求并立即响应
该机制兼顾消息实时性与服务端资源效率,被 RocketMQ 等主流消息中间件默认采用,成为高并发场景下平衡实时性与性能的核心方案。
4. RocketMQ的消息拉取优化细节
直接阅读 RocketMQ 消息拉取源码时会发现其实现远比伪代码复杂,但这并非长轮询核心逻辑本身复杂,而是源于 RocketMQ 为精细化处理多场景所做的工程扩展。若遵循长轮询伪代码的主线理解(请求保持、延迟响应、实时触发),会发现核心流程与理论完全一致。
源码的额外复杂性旨在覆盖边缘场景、优化性能瓶颈、增强系统健壮性(如网络异常、并发竞争、资源回收等),而非改变长轮询的本质。这种设计确保了 RocketMQ 在高并发生产环境中的可靠性,但其核心仍是对简单长轮询模型的扩展与加固。
①客户端请求异步化
消费者需为每个订阅的 queue 发起 Pull 请求,但同步请求在服务端无消息时会被 Hold 住,导致多 queue 场景下请求阻塞与延迟加剧。RocketMQ PushConsumer 采用异步 Pull 机制破解此难题:单线程发起异步请求后立即返回,通过回调处理响应,既避免阻塞又保障实时性,无需多线程负担。
PullConsumer 虽提供异步接口(如
DefaultMQPullConsumerImpl.pull(MessageQueue mq, String subExpression, long offset, int maxNums, PullCallback pullCallback)),但该组件将被废弃;替代者DefaultLitePullConsumer改用多线程同步拉取方案,不再依赖单线程异步化。
/**
* RocketMQ 消费者拉取消息机制示例
* 展示同步 Pull 的问题和异步 Pull 的解决方案
*/
public class AsyncPullConsumerExample {
// 模拟消费者订阅的多个队列
private List<MessageQueue> messageQueues;
/**
* 同步 Pull 方式的问题示例:
* 消费者需要为每个 queue 发起 Pull 请求,但如果某个 queue 无数据,服务端会 Hold 住请求。
* 如果 pullMsg 是同步实现,请求会卡住,导致后续 queue 的 Pull 请求被阻塞,造成数据延迟。
若使用多线程拉取,上下文切换成本过高
*/
public void syncPullProblem() {
while (true) {
for (MessageQueue queue : messageQueues) {
// 同步拉取消息,超时时间 30 秒
// 如果服务端无消息,会 Hold 请求,导致此处阻塞
PullResult result = pullMsgSync(queue, 30 * 1000);
processResult(result);
}
}
}
/**
* RocketMQ PushConsumer 的解决方案:异步 Pull
* 单线程发起异步请求,立即返回,不阻塞其他队列的拉取请求。
* 消息拉取响应回来后,通过回调处理。
*/
public void asyncPullSolution() {
while (true) {
for (MessageQueue queue : messageQueues) {
// 异步发起拉数据请求,超时时间 30 秒
pullMsgAsync(queue, 30 * 1000, new PullCallback() {
@Override
public void onSuccess(PullResult pullResult) {
// 响应回来后调用回调处理
processResult(pullResult);
}
@Override
public void onException(Throwable e) {
// 处理异常
e.printStackTrace();
}
});
}
}
}
/**
* DefaultMQPullConsumer 提供的异步 Pull 接口示例
* 注意:DefaultMQPullConsumer 将在将来被废弃,不推荐在新项目中使用。
*/
public void useDeprecatedAsyncPull() {
DefaultMQPullConsumer consumer = new DefaultMQPullConsumer("consumerGroup");
try {
consumer.start();
for (MessageQueue queue : messageQueues) {
// 异步 Pull 接口:pull(MessageQueue mq, String subExpression, long offset, int maxNums, PullCallback pullCallback)
consumer.pull(queue, "*", 0, 32, new PullCallback() {
@Override
public void onSuccess(PullResult pullResult) {
processResult(pullResult);
}
@Override
public void onException(Throwable e) {
e.printStackTrace();
}
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
consumer.shutdown();
}
}
/**
* 替代方案:DefaultLitePullConsumer
* 采用多线程同步方式进行拉取,而不是单线程异步化。
* 这是当前推荐的方式。
*/
public void useLitePullConsumer() {
// DefaultLitePullConsumer 实现多队列拉取时使用多线程+同步方式
// 具体用法请参考官方文档
}
// 辅助方法:同步拉取消息(模拟)
private PullResult pullMsgSync(MessageQueue queue, long timeout) {
// 实际实现会调用 RocketMQ 的同步 Pull API
return null;
}
// 辅助方法:异步拉取消息(模拟)
private void pullMsgAsync(MessageQueue queue, long timeout, PullCallback callback) {
// 实际实现会调用 RocketMQ 的异步 Pull API
}
// 处理拉取结果
private void processResult(PullResult result) {
// 处理消息
}
}②服务端超时处理细节
RocketMQ 通过服务端定时检查机制确保客户端不会因消息长时间未到达而超时。服务端默认每 5 秒触发一次定时任务,检测所有挂起的请求:若某请求挂起时间超过服务端最大允许值(默认 15 秒),则主动组装并返回
PULL_NOT_FOUND响应,明确告知消费者当前无数据。此设计避免了简单实现中客户端无限等待的问题,确保在网络正常的情况下,所有请求均能获得服务端的明确响应(要么返回消息,要么返回
PULL_NOT_FOUND),从根本上杜绝了因消息延迟导致的超时故障。
③服务端多线程交互
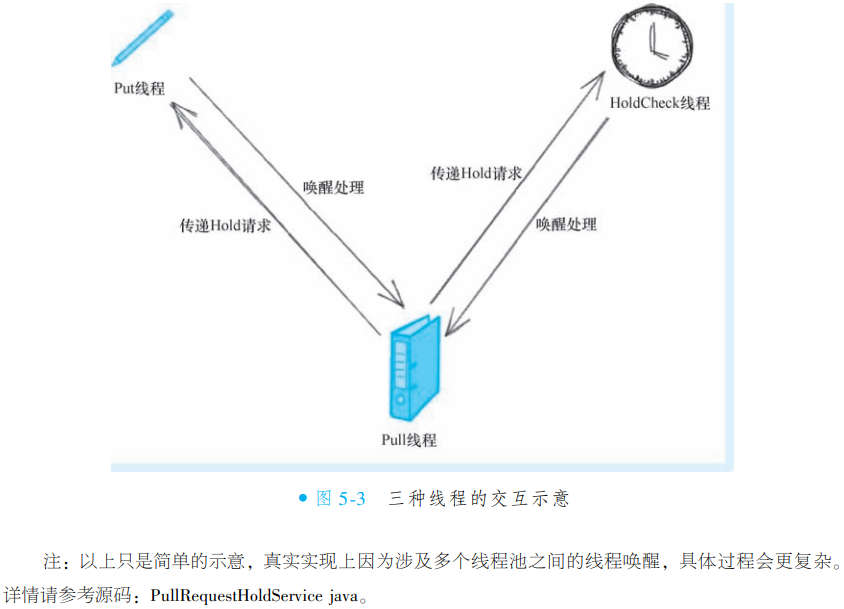
RocketMQ 服务端采用多线程分工架构实现高效消息处理:
Pull 线程:专责处理消费者拉取请求
Put 线程:专责处理生产者消息写入
HoldCheck 线程:独立定时检测请求超时
-
无数据时的请求传递:Pull 线程发现无数据时,将 Hold 请求同步至 Put 和 HoldCheck 线程,为未来唤醒建立链路
写入完成的通知:Put 线程在消息写入成功后,主动通知 Pull 线程处理积压请求
超时控制的兜底:HoldCheck 线程定期检查并唤醒可能僵死的 Pull 线程
-
设计价值:通过线程专责化与协同机制,在保障消息实时性的同时,避免单线程阻塞风险,实现高并发场景下的稳定服务。
④合并多个Pull请求
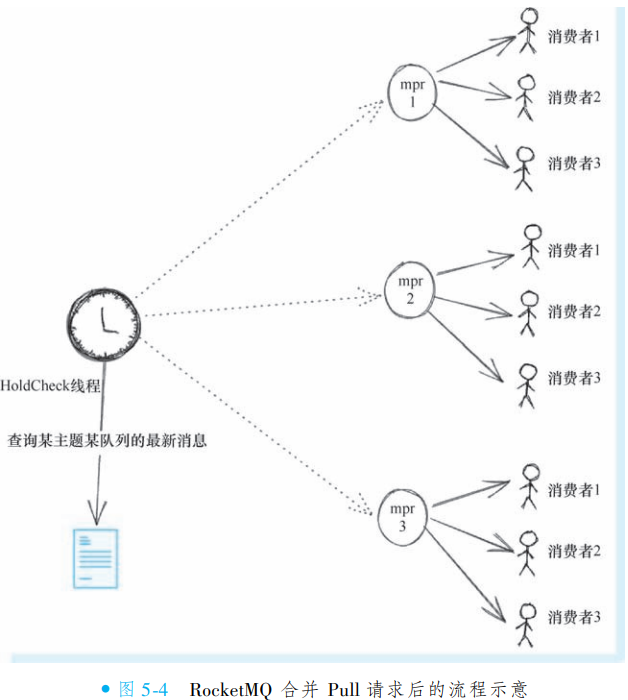
RocketMQ 服务端为提升高并发场景下的处理效率,采用 ManyPullRequest(mpr)机制对同一队列的多个 Pull 请求进行合并管理。当多个消费者组订阅同一 Topic 时,服务端会将针对同一队列的等待请求聚合为一个 mpr 单元(按 queue 维度管理,非 Topic 维度)。
响应效率优化:消息到达时可直接定位关联的所有网络连接并批量响应,避免逐个查找请求
检查成本降低:定时任务只需检测一次队列数据状态,无需为相同队列的多个请求重复检查(如原需3次检测现仅需1次)
5. 消费者线程模型
RocketMQ 将详细阐述消息消费进度在成功、失败乃至异常(如死循环)等场景下的管理机制,并解释其如何保证消息“至少成功消费一次”的核心语义。后续讲解将基于 PushConsumer(推模式)展开,因其代表最主流用法且涵盖 RocketMQ 对消费的完整设计。需注意,4.3 版本后引入的 LitePullConsumer 在底层管理上复用大部分逻辑,而 DefaultPullConsumer 因编程模型过于复杂已被标记为废弃。
①消费流程涉及的关键线程
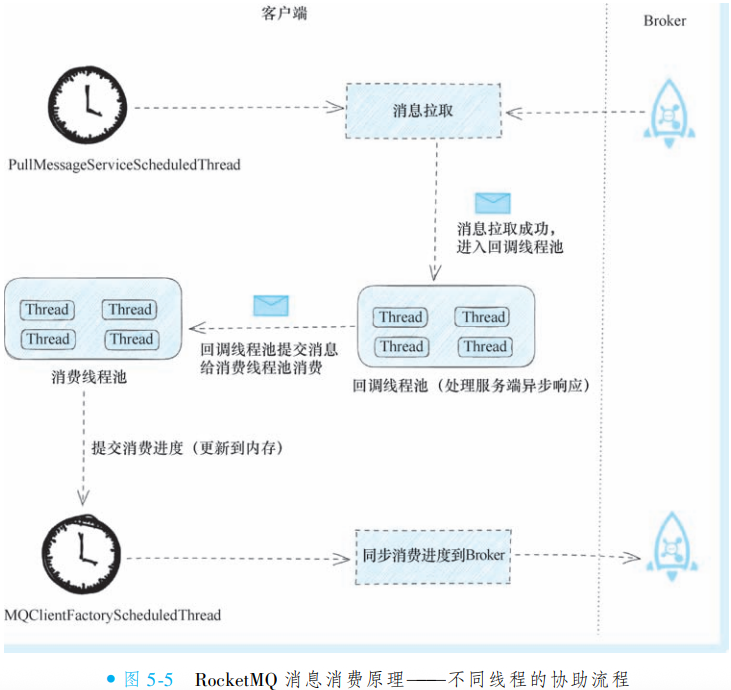
RocketMQ 的消息消费流程可归纳为三个核心步骤:
消息拉取:客户端从消息队列中获取待处理消息
消息消费:执行具体的业务逻辑处理
消费进度提交:记录消费位置,确保故障恢复后能继续消费
-
该流程依赖四个核心线程(池)协同工作:
PullMessageServiceScheduledThread:定时任务线程,持续发起消息拉取请求
回调线程池:处理异步拉取返回的消息并进行初步解析
消费线程池:执行业务逻辑代码,并在内存中更新消费进度
MQClientFactoryScheduledThread:定时任务线程,将内存中的消费进度同步至Broker
设计价值:通过异步拉取与多线程分工,在保障消息实时处理的同时,确保消费进度的持久化与系统可靠性。
②消费线程池
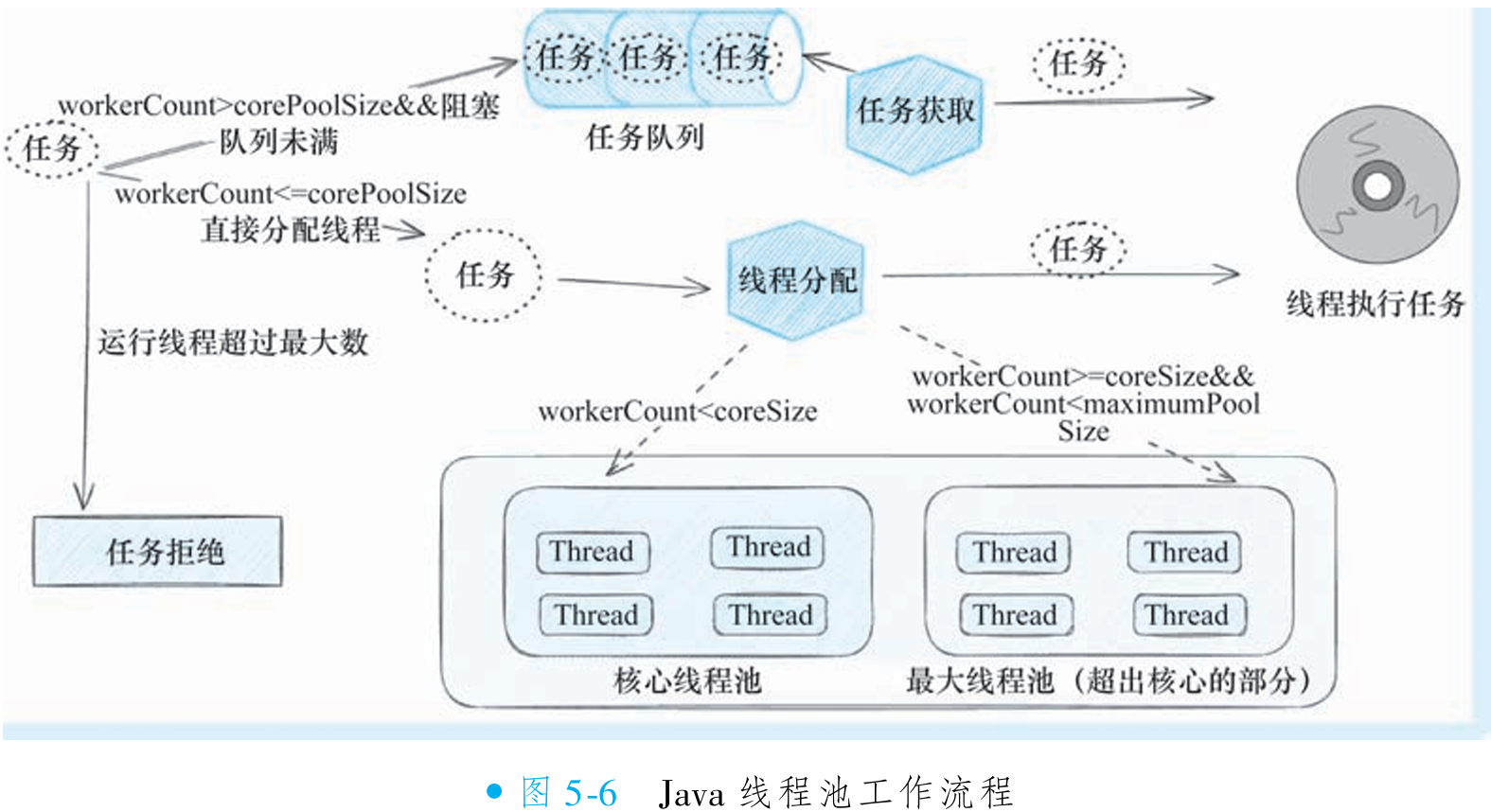
RocketMQ 的消息消费流程始于长轮询机制:拉取线程从 Broker 获取消息后,经线程间协调,最终交由消费线程池(consumeExecutor)处理。在该线程池中,开发者注册的回调逻辑(如
MessageListenerConcurrently)被执行,完成消息消费。线程池线程名以 "ConsumeMessageThread_" 开头,可通过业务日志观察线程名验证并发情况。consumeExecutor 是标准 Java 线程池,工作流程遵循核心线程池优先、任务队列次之、最大线程池兜底的原则。常见配置错误是将最小线程数(
consumeThreadMin)设为 1、最大线程数(consumeThreadMax)设为 32,但由于任务队列默认无限长(Integer.MAX_VALUE),最大线程池基本无法启用,导致消费者实际以单线程运行,严重限制吞吐量。开发者应检查业务日志:若线程名全为 "ConsumeMessageThread_1",表明存在单线程消费问题。需合理设置最小线程数(如 4 以上),确保任务队列不满时也能多线程并发处理。PushConsumer 通过 consumeExecutor 实现消息并发消费,但配置不当会抵消其优势。更多线程池细节参考 Java 官方文档,但核心是避免最小线程数过低和队列无限长的组合。
/**
* RocketMQ 消费者配置示例
* 展示消息监听器注册和线程池配置的最佳实践
*/
public class RocketMQConsumerExample
{
public static void main(String[] args) throws Exception
{
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("MyConsumerGroup");
consumer.setNamesrvAddr("localhost:9876");
/*
* 消息消费流程说明(来自第1张图):
* 消息经过长轮询之后,拉取线程将从Broker拉取到消息,
* 消息经过一系列线程间的协调工作后,最终会进到消费线程池。
* 在线程池中运行的就是代码里写的回调逻辑。
*/
consumer.registerMessageListener(new MessageListenerConcurrently()
{
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context)
{
// 打印当前线程名和接收到的消息
System.out.println(Thread.currentThread().getName() + " Receive New Messages: " + msgs);
// 执行真正消费(伪代码)
doMyJob();
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
/*
* 线程池配置说明(来自第2、3张图):
* 虽然Java线程池工作流程是基础,但还是有很多开发者对线程池工作流程有误解,
* 以至于在RocketMQ的配置代码中,经常会出现以下的情况:
* consumer.setConsumeThreadMin(1); //最小线程数1
* consumer.setConsumeThreadMax(32); //最大线程数32
*
* 按照Java的线程池工作流程,由于任务队列默认是无限长的(Integer的最大值),
* 所以最大线程池里面的线程基本用不上,也就是说最后实际上整个消费者其实是单线程在消费。
*
* 正确配置:设置合理的最小线程数,避免单线程消费瓶颈
*/
consumer.setConsumeThreadMin(4); // 推荐设置:最小线程数4
consumer.setConsumeThreadMax(32); // 最大线程数32
consumer.subscribe("TestTopic", "*");
consumer.start();
System.out.println("Consumer Started.");
}
// 模拟消息消费业务逻辑
private static void doMyJob()
{
// 这里实现实际的消息处理逻辑
}
}6. 消费进度管理
①消费进度存储
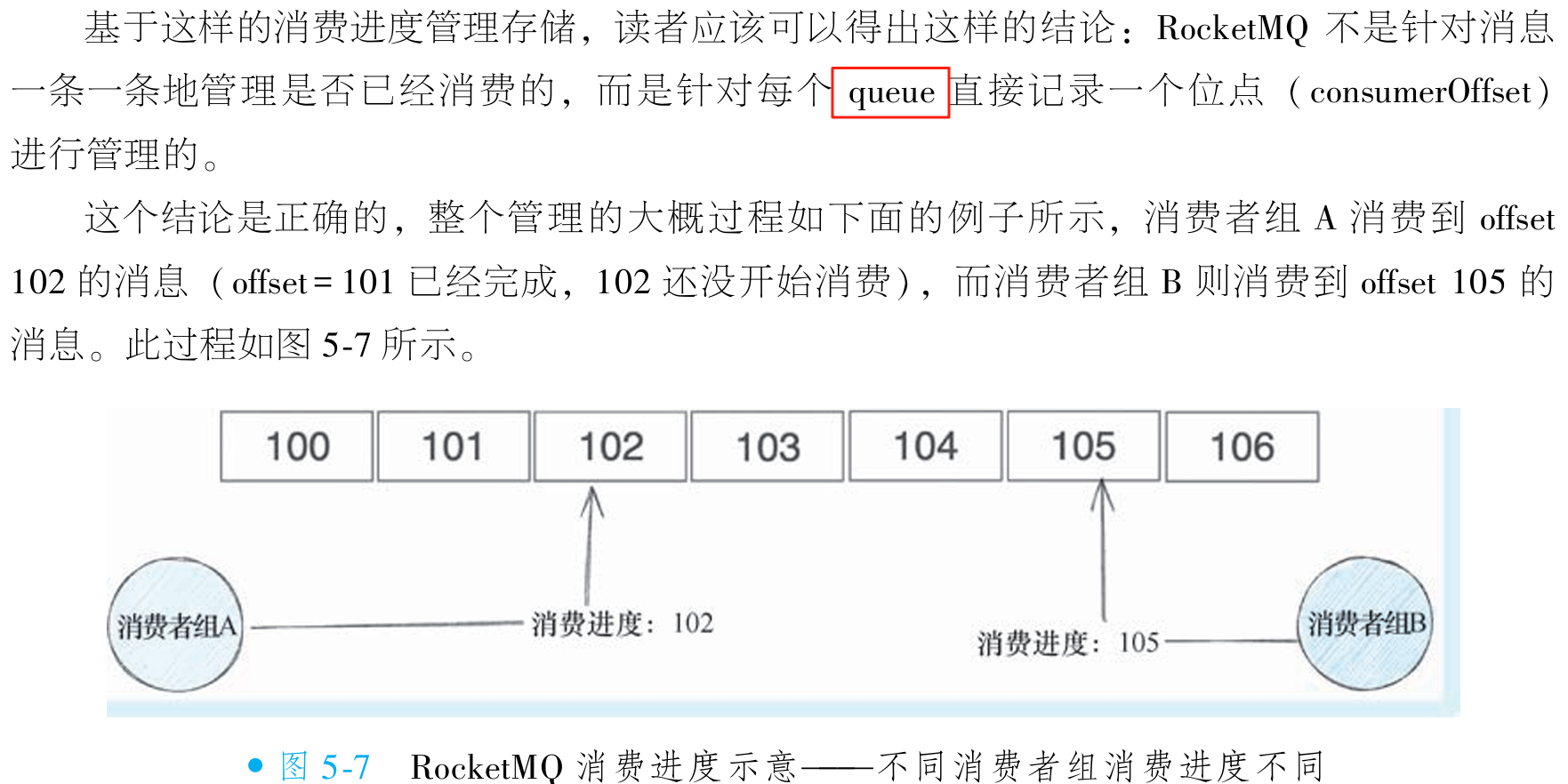
/**
* RocketMQ 消费进度管理机制说明:
* 前面提到,消息消费后会有独立的线程同步内存的消费进度到Broker。
* 但是这里的消费进度是存储在内存的,要存储好这个进度,就要管理哪些消息已经消费过了,
* 哪些还没有成功被消费。所以 RocketMQ 需要某种机制去记住这些信息,
* 这个机制就是消费进度管理。
*
* 读者可能已经知道了,RocketMQ 是针对某个 queue 维度去管理消费进度的,
* 例如某个消费者 CONSUMER-GROUP-A 消费到某个 queue offest 100 的位置,
* 另外一个消费者 CONSUMER-GROUP-B 同样的 queue 消费到 offest 101 的位置,
* 那么最终会有类似下面这样的 JSON 结构存储在 Broker 端。
*/
// Broker端存储的消费进度JSON结构示例:
// {
// "TOPIC-X@CONSUMER-GROUP-A": {
// "0": 100
// },
// "TOPIC-X@CONSUMER-GROUP-B": {
// "0": 101
// }
// }
// 注:实际上每个topic不止一个queue,那么整个JSON可能会出现下面的情况:
// {
// "TOPIC-X@CONSUMER-GROUP-A": {
// "0": 100,
// "1": 98
// },
// "TOPIC-X@CONSUMER-GROUP-B": {
// "0": 101,
// "1": 101
// }
// }②初次启动从哪里消费
消费者启动时的消费位点确定机制:当消费者实例启动时,PushConsumer 会首先向 Broker 查询本消费者组的消费进度(consumer offset)。若找到历史记录,则直接基于该进度发起首次拉取请求,确保从上次消费中断处继续消费,保障消息处理的连续性和准确性。
全新消费者组的位点初始化策略:
若 Broker 中无该消费者组的记录(即全新消费者组),客户端可从以下三种策略中选择初始消费位点:
CONSUME_FROM_LAST_OFFSET(默认):从队列尾部开始消费,跳过所有历史消息;
CONSUME_FROM_FIRST_OFFSET:从队列首部开始消费,处理全部历史消息;
CONSUME_FROM_TIMESTAMP:从指定时间点(默认半小时前)开始消费。
需注意:上述策略仅对全新消费者组生效。已存在消费进度的组重启时均按历史进度恢复,避免重复消费或消息遗漏。此设计确保了消费行为的可预测性与一致性。
7. 消息ACK机制
①ATLEASTONCE保证
RocketMQ 采用顺序提交策略保障消息至少被成功消费一次(AT-LEAST-ONCE)。当并发消费多条消息时(如位点1-10),即使高位消息(如位点10)率先完成消费,系统也不会立即更新消费位点至11。此举旨在避免消费者异常重启后,Broker因位点提前提交而跳过尚未消费的低位消息(如1-9),导致消息永久丢失。
该机制要求所有消息均消费成功后才推进位点,确保任意消息至少被成功处理一次。若高位消息完成后立即提交位点11,遇消费者重启等异常时,Broker将误判1-9已消费(实际未处理),彻底违背消息中间件的核心可靠性承诺。
②消息消费失败进度管理
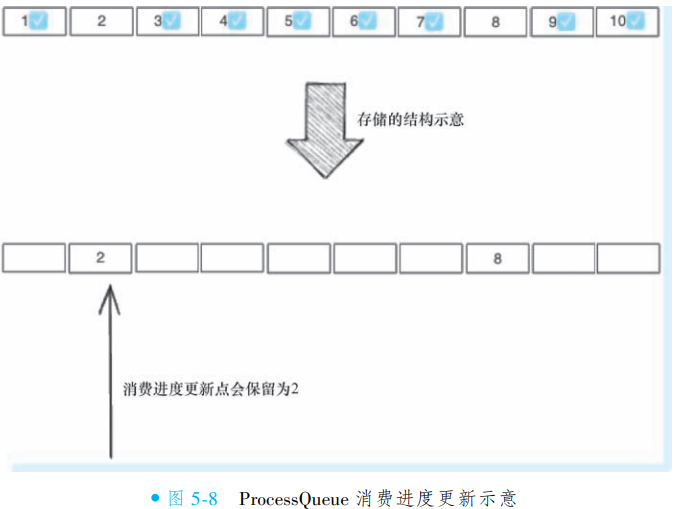
RocketMQ 采用部分区间提交策略管理消费进度,不要求所有消息消费完成才提交进度。例如当消息 1、[3,7]、[9,10] 已消费成功时,可安全提交消费进度为 2(即最大成功消费位点+1),避免因单条消息消费慢阻塞整体进度更新。
消息拉取后按顺序存储在本地 ProcessQueue 中(底层为 TreeMap 结构),消费成功的消息会从中删除。提交的消费进度值为 ProcessQueue 的队首位点,并通过定时任务异步同步至 Broker 持久化存储。这种设计使得消费进度落后并不一定代表消息大量堆积,可能是因部分消息处理耗时较长所致。
RocketMQ 不会因消费失败或长时间消费而永久卡住进度。当出现消息持续消费中(如线程池死锁等待外部资源)时,系统具备相应的容错机制处理消费超时和失败场景,确保进度不会无限期停滞,保障整体消费流程的可靠性。
8. 消息失败重试设计
在讨论消费失败处理前,请思考以下场景:若从消息队列拉取编号 [1, 10] 的消息进行处理,其中仅消息 5 消费失败,其余消息([1, 4] 和 [6, 10])均成功消费。此时应如何提交消费进度才算合理?
①重试主题
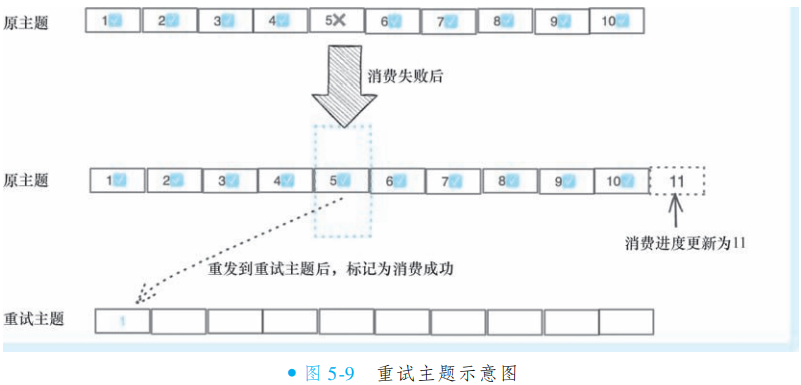
当消息消费失败时(如偏移量5的消息),RocketMQ 采用重试主题机制确保消息不丢失且不影响整体消费进度。具体流程如下:失败消息会被从本地 ProcessQueue 中移除,并发送到该消费者组专属的重试主题(命名规则为
%RETRY%消费者组名),同时将消费进度更新至最新成功消息的下一位(如偏移量11)。此举既避免了单条消息失败阻塞队列,又保障了失败消息有机会被重新消费。重试主题是 RocketMQ 的核心容错机制,每个消费者组自动创建并监听自己的重试主题。例如,消费者组
CONSUMER_GROUP_A会监听主题%RETRY%CONSUMER_GROUP_A。失败消息转入重试主题后,客户端会继续尝试消费,直至成功或达到重试上限。此设计实现了消费进度推进与消息重试的平衡,确保至少一次消费语义。
②延迟重试
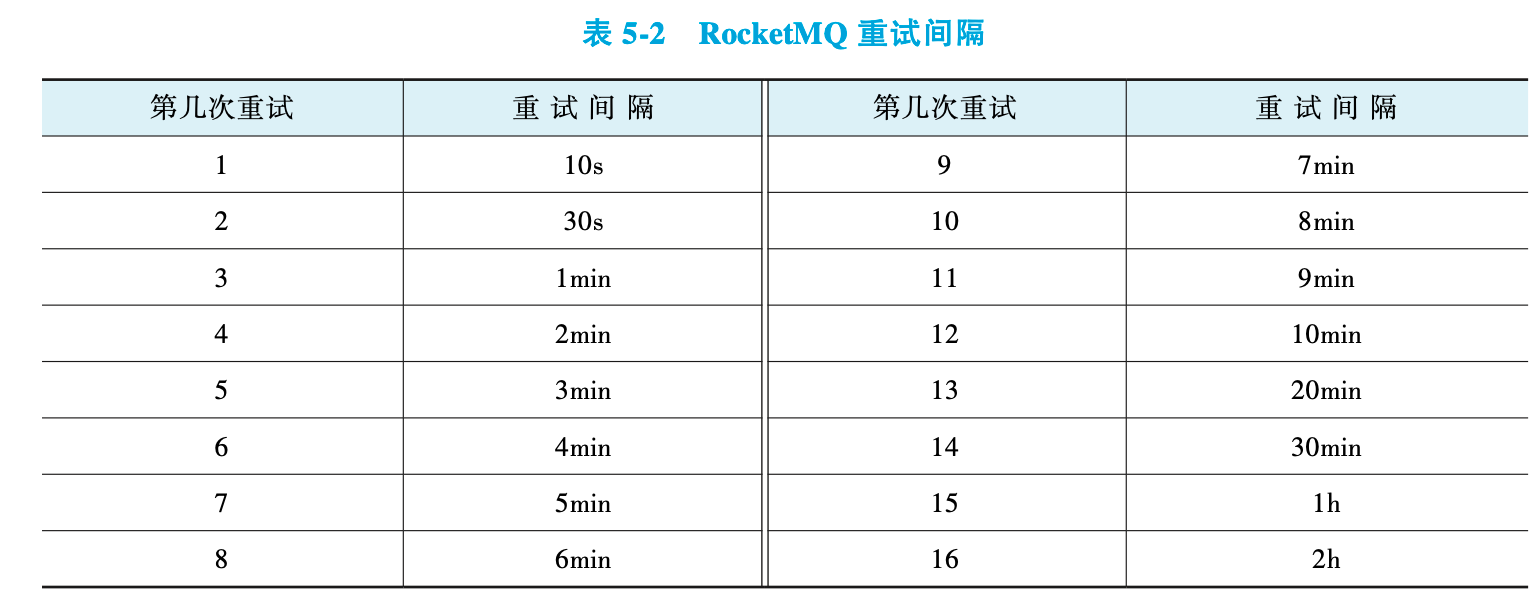
RocketMQ 通过延迟重试与死信主题机制处理消费失败的消息。当消费因外部资源故障(如数据库短暂异常)失败时,消息会被发送至重试主题并作为延迟消息投递,初始延迟较短,随后随重试次数增加而延长(参见延迟级别表),以为外部资源恢复预留时间。若消息重试达默认16次仍失败,则被转入死信主题(命名格式:
%DLQ%原消费者组名),不再自动投递,需人工干预处理。延迟重试功能直接基于 RocketMQ 的延迟消息特性实现。
9. 消息消费异常处理
除正常消费成功与失败外,生产环境常面临两类异常场景:
消费耗时过长:单条消息处理时间远超预期,阻塞队列进度;
消息持续失败:特定消息反复消费均无法成功,陷入死循环。
若这些异常未妥善处理,将严重破坏 RocketMQ 的健壮性。为此,RocketMQ 内置了针对性的异常处理机制(后续详述),确保系统在极端场景下仍保持稳定可靠。
①消费超时

消费超时指因代码缺陷(如死循环、死锁)或无限期等待外部资源,导致单条消息处理无法完成,进而阻塞整个队列消费进度。例如:当第5条消息陷入死循环时,后续9994条消息(6-10000)将无法被消费。若此时消费者重启,这些消息会被重复投递,造成数据污染和系统异常。
PushConsumer 提供
ConsumeTimeout配置(默认15分钟),通过定时器扫描所有"消费中"的消息。当检测到某消息消费时长超过阈值时,系统会自动将其标记为需重试,转发至重试主题进行延迟处理,并从当前处理队列(ProcessQueue)中移除。该机制有效避免单条异常消息阻塞整体消费进度,保障系统可靠性。
②卡进度的保护处理
RocketMQ 通过
consumeConcurrentlyMaxSpan参数(默认值 2000)应对消费异常场景:当 ProcessQueue 中最大与最小消息位点差超过阈值时,客户端自动触发流控并暂停拉取新消息,同时输出预警日志 "the queue's messages, span too long, so do flow control"。此机制将异常重启后的消息重复量限制在阈值内(如 2000 条),显著降低数据污染风险。PushConsumer:通过
consumeConcurrentlyMaxSpan参数控制LitePullConsumer:提供功能一致的
consumeMaxSpan参数也就是说, 上面的例子如果消息5一直卡住, 而当发现最大的消息位点是2005的时候,
客户端就会暂停拉取, 以减少重复消息的影响。
③消息重发与顺序性的矛盾
RocketMQ 通过重试主题机制处理消费失败或超时的消息:当某条消息(如顺序中的消息5)处理异常时,系统会将其转发至专属重试主题,从而避免阻塞整体消费进度(后续消息6-10可继续处理)。然而,这一容错设计与消息顺序性要求存在本质冲突——重试后实际消费顺序变为1-4、6-10、5,破坏了原始严格顺序。
并行消费场景(绝大多数用例):系统默认启用重试机制,因顺序非关键需求,优先保障吞吐与进度;
顺序消费场景:RocketMQ 主动禁用重试与超时处理(避免顺序破坏),开发者需自行解决卡进度问题(如死循环或外部依赖超时)。
设计本质:通过区分场景下的策略选择(并行重试优先效率,顺序消费优先一致性),平衡可靠性约束与业务需求。实践中需明确业务是否真需强顺序,避免不必要的顺序约束牺牲系统容错能力。
六. RocketMQ负载均衡与消费模式
1. 负载均衡综述
RocketMQ 作为高性能分布式消息中间件,支持多节点部署以突破单机资源上限,实现系统容量与并发能力的横向扩展。其核心包含服务端组件(Name Server、Broker)与客户端组件(Producer、Consumer),共同构成消息生产与消费的完整链路。
负载均衡是发挥分布式扩展优势的关键:通过将消息生产与消费的压力均匀分摊至各节点,避免单点瓶颈,确保系统高效稳定运行。
2. 消息生产负载均衡
RocketMQ 具备极高的单机性能和出色的消息堆积能力,但受限于单机资源(如磁盘、CPU、内存等),无法将所有消息存储于单一节点。一个优秀的分布式系统应能持续扩展其系统能力和容量,以突破单点资源瓶颈。
①消息生产负载均衡概述
RocketMQ 采用消息级分布式存储设计:每条消息均以完整形式存储于特定 master 节点(非如 HDFS 的分块存储),slave 节点通过同步机制备份 master 数据。该特性决定了其生产者负载均衡的核心策略——将消息均匀分发至不同 master 节点,通过分散写入压力实现横向扩展与性能优化。
②消息生成负载均衡的原理
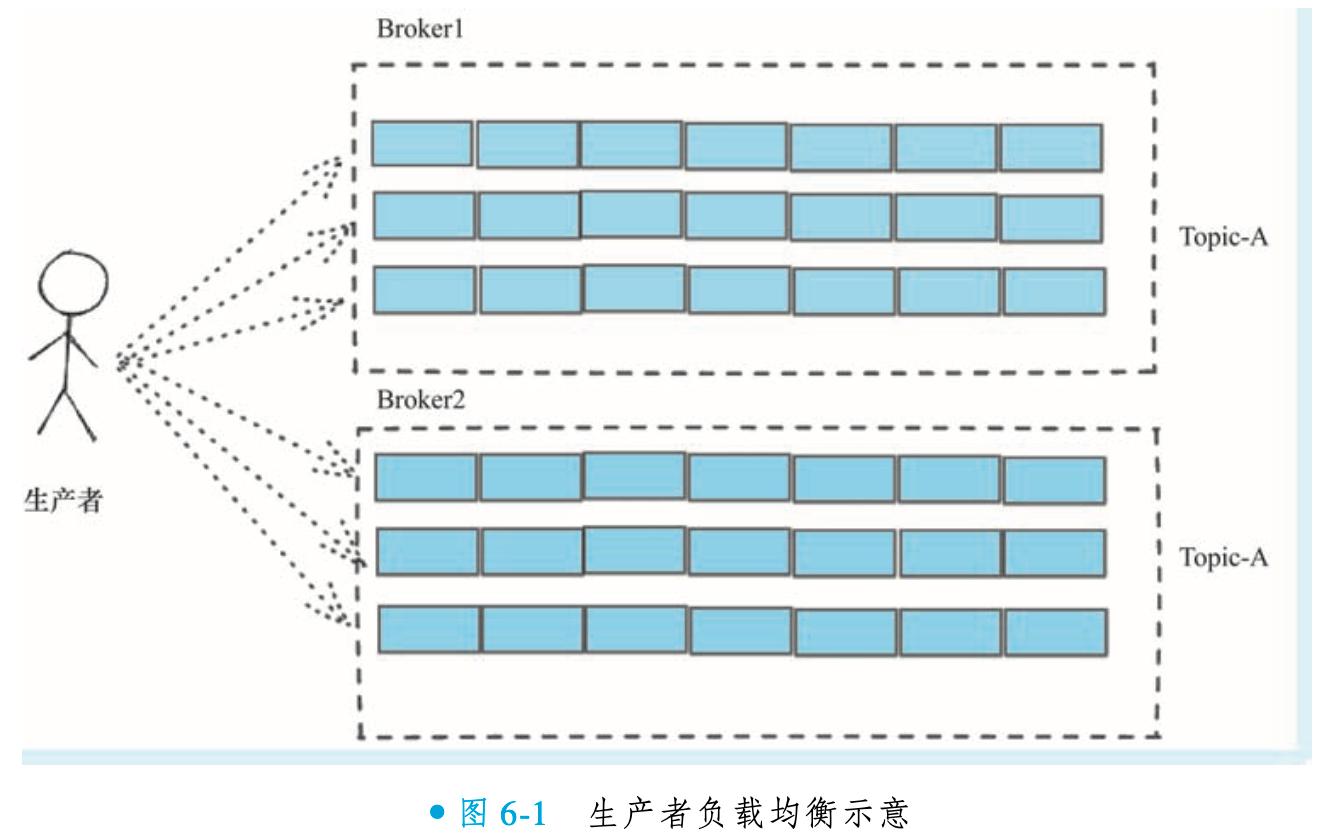
RocketMQ 通过主题跨节点冗余与队列级轮询投递实现消息的均匀存储与负载均衡。不同 Broker 节点可创建同名主题,使生产者将任一节点视为等效目标。其核心策略并非按节点分发,而是以消息队列(Message Queue)为粒度:生产者对所有节点上的主题队列(如 3 节点 × 3 队列 = 9 队列)进行轮询发送,使消息均匀分布至不同物理节点。
该机制确保消息存储自动均衡,且无需生产者感知物理拓扑。通过队列抽象,系统可通过增减节点或队列数灵活扩展吞吐能力,完美适配分布式架构的弹性需求。
3. 消息消费负载均衡
①无中心的队列负载均衡
RocketMQ 的负载均衡涵盖消息生产与消费两个维度。生产负载均衡通过将消息均匀存储在不同 Broker 节点实现;消费负载均衡则通过将主题下的队列分配给订阅该主题的消费者实例完成。在集群模式下,RocketMQ 采用队列级独占分配策略:每个队列仅由一个消费者实例处理,避免消息重复或遗漏。分配过程无中心协调者,由各消费者实例基于相同规则(如默认的平均分配)独立计算所需队列,最终形成均衡的负载关系。广播模式因消息需投递至所有实例,不涉及负载均衡。RocketMQ 支持通过
AllocateMessageQueueStrategy接口自定义分配规则,适应多样化场景需求。该机制通过队列抽象实现横向扩展,确保系统吞吐量随节点增加而提升。其无中心化设计降低了协调复杂度,同时保障了分布式环境下的可靠性与弹性。
②无中心负载均衡的核心源码
/**
* RocketMQ 默认的客户端负载均衡规则(平均获取策略)核心源码
* 该算法将消息队列平均分配给消费者组内的所有消费者实例
*
* @param consumerGroup 消费者组名称
* @param currentCID 当前消费者ID
* @param mqAll 所有消息队列列表
* @param cidAll 所有消费者ID列表
* @return 分配给当前消费者的消息队列列表
*/
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,
List<String> cidAll) {
List<MessageQueue> result = new ArrayList<MessageQueue>();
// 校验当前消费者ID是否在有效消费者列表中
if (!cidAll.contains(currentCID)) {
log.info("[BUG] ConsumerGroup: {} The consumerId: {} not in cidAll: {}",
consumerGroup, currentCID, cidAll);
return result; // 返回空列表
}
// 计算当前消费者在列表中的索引位置
int index = cidAll.indexOf(currentCID);
// 计算队列总数对消费者数量的余数
int mod = mqAll.size() % cidAll.size();
// 计算每个消费者平均应分配的队列数量,考虑余数的影响
int averageSize = mqAll.size() <= cidAll.size() ? 1 :
(mod > 0 && index < mod ? mqAll.size() / cidAll.size() + 1
: mqAll.size() / cidAll.size());
// 计算当前消费者分配的起始索引
int startIndex = (mod > 0 && index < mod) ? index * averageSize : index * averageSize + mod;
// 计算实际分配的范围,防止越界
int range = Math.min(averageSize, mqAll.size() - startIndex);
// 循环分配队列给当前消费者
for (int i = 0; i < range; i++) {
result.add(mqAll.get((startIndex + i) % mqAll.size()));
}
return result;
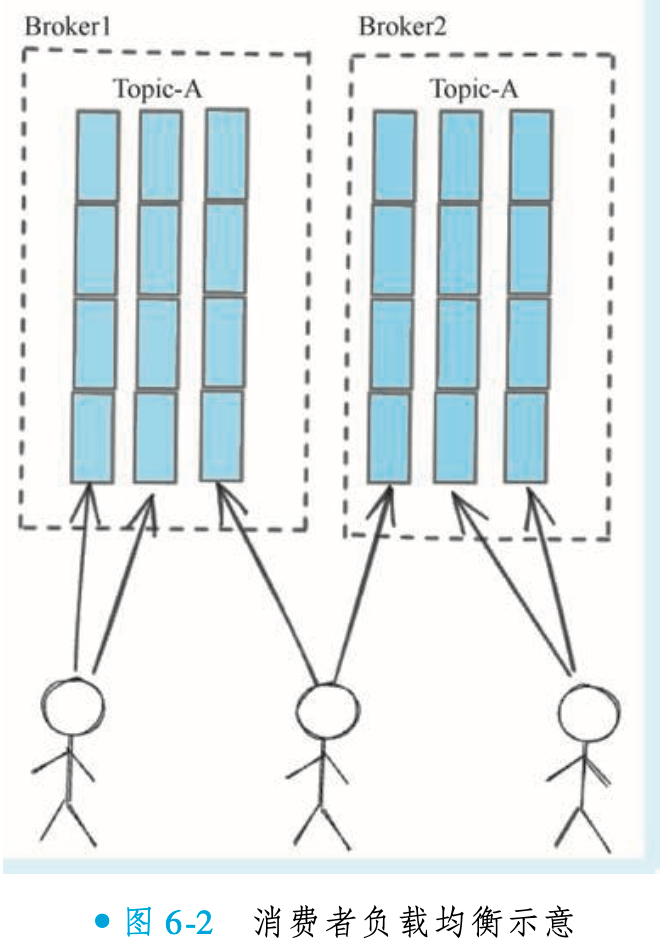
}③消费者负载均衡策略
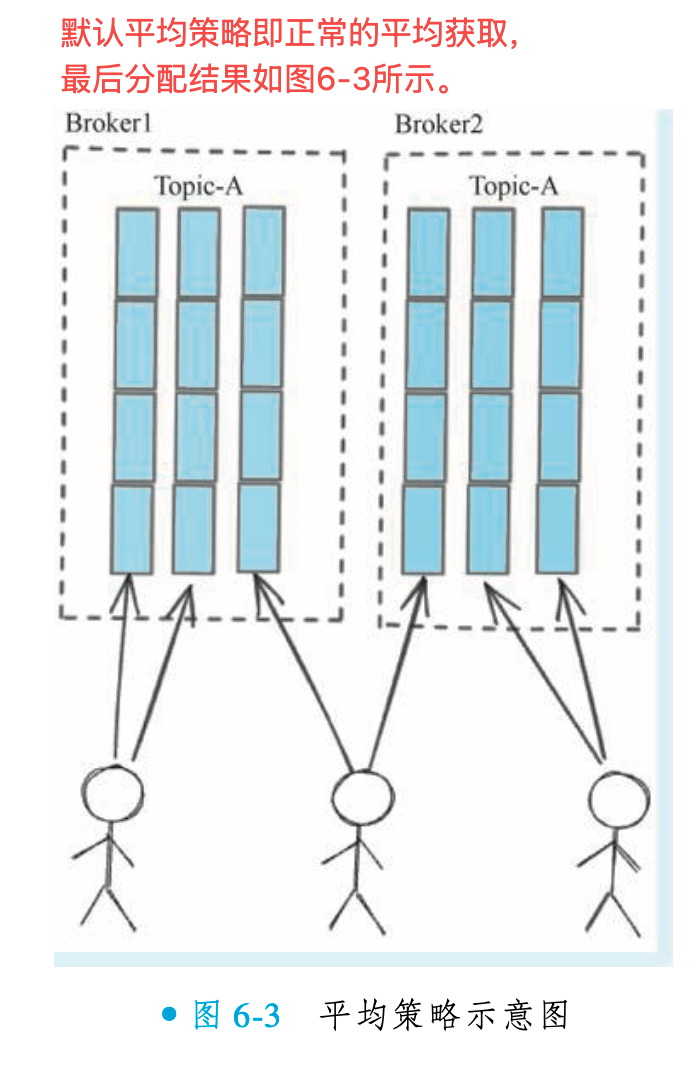
平均策略(AllocateMessageQueueAveragely)
环状平均策略(AllocateMessageQueueAveragelyByCircle)
AllocateMessageQueueAveragely 策略采用连续分配的方式,即一个消费者会一次性获得一段连续的消息队列。例如,若某消费者需获取3个队列,它会直接分配到3个连续的队列。
而 AllocateMessageQueueAveragelyByCircle 策略则采用轮流顺序分配的方式。该策略让各个消费者实例按顺序依次挑选队列(例如消费者A选队列1,消费者B选队列2,消费者C选队列3,然后消费者A再选队列4,依此类推),直到所有队列分配完毕。这种轮询机制能避免队列过于集中,有助于实现更均匀的负载分布。
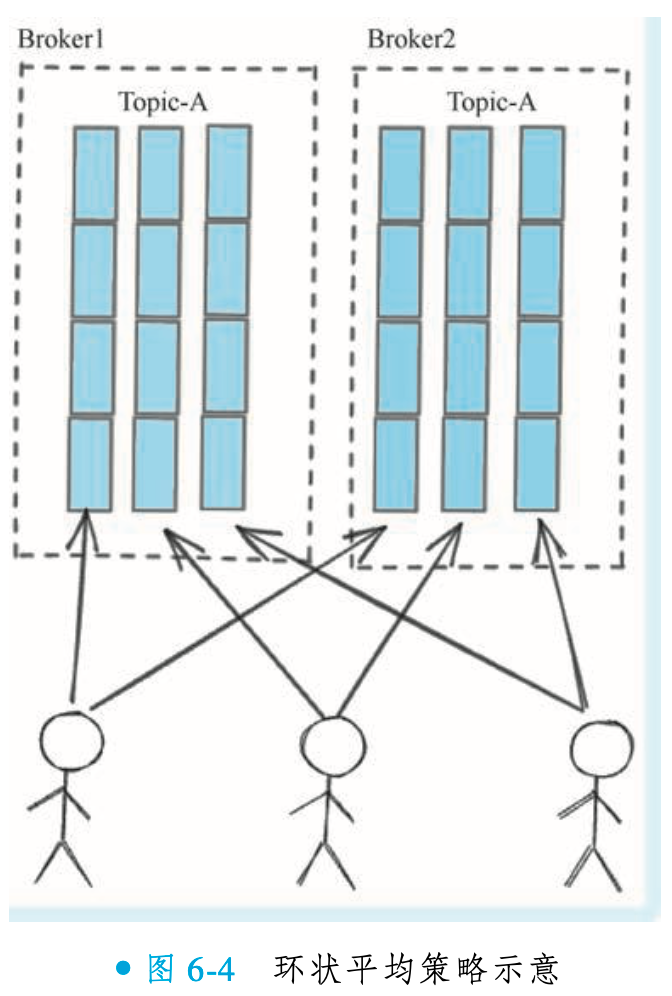
手动指定策略(AllocateMessageQueueByConfig)
AllocateMessageQueueByConfig是一种需开发者显式配置的队列分配策略。消费者启动时,需创建该策略对象并手动指定消费队列列表,完全跳过自动负载均衡逻辑。该策略无法自动感知Broker端队列扩容:若主题队列数量增加,必须人工修改配置并重启消费者才能识别新队列。因此仅适用于队列结构稳定的场景,动态扩容需求需结合配置中心实现热更新,以弥补其灵活性缺陷。
按机房配置策略(AllocateMessageQueueByMachineRoom)
当 RocketMQ Broker 集群跨同城机房混合部署时(如北京昌平 CP 和汇天 HT 机房共同提供 Topic-X 服务),可通过机房感知策略优化消费端路由,避免跨机房通信开销。具体配置要求:
Broker 命名规范:名称需以
[机房标识]@开头(如HT@Broker、CP@Broker);消费者机房绑定:调用策略实例的
setConsumeridcs接口,明确指定消费者实例需消费的机房消息。该策略生效后,相同机房标识的消费者与 Broker 自动匹配(如汇天消费者仅消费汇天队列),实现同机房优先消费,显著降低网络延迟与带宽成本。
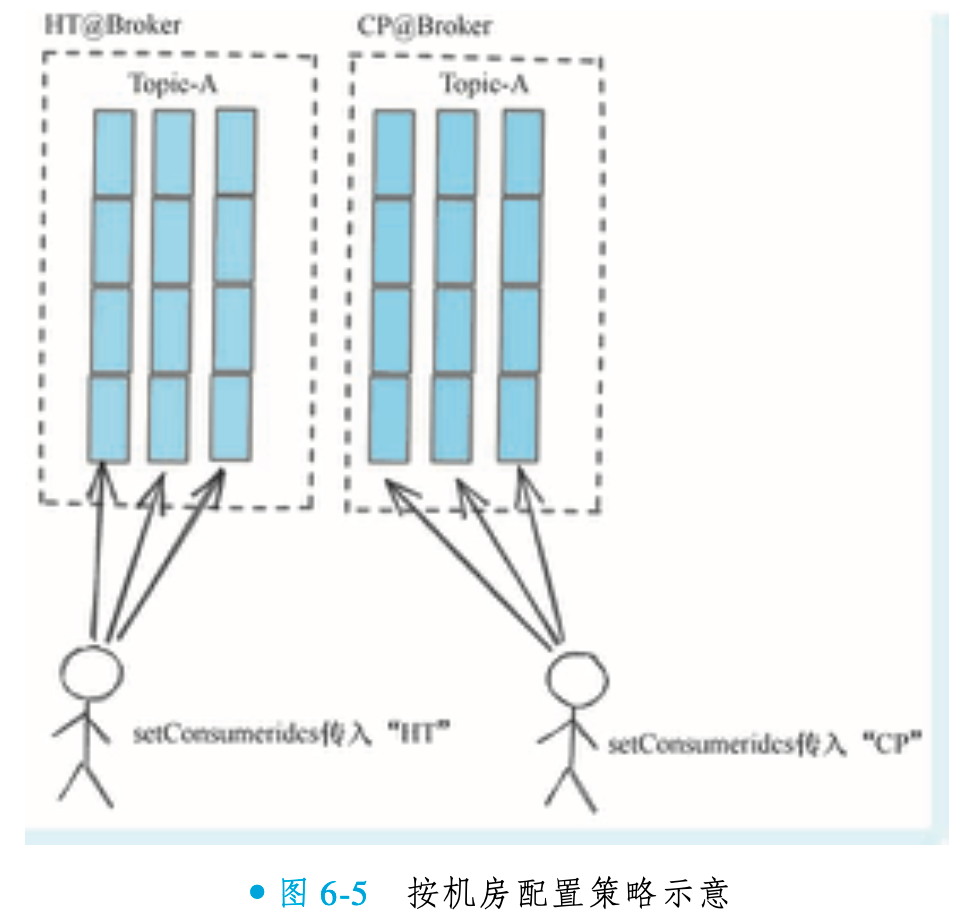
一致性哈希负载均衡策略(AllocateMessageQueueConsistentHash)

这是笔者为 RocketMQ 贡献的一个特性,在负载均衡时采用一致性哈希方式分配队列。一致性哈希是一种特殊哈希方式,能解决节点数量变化时哈希值剧烈变动的问题。在队列负载均衡领域,采用一致性哈希可带来稳定性提升,该策略通常应用于缓存负载均衡场景以满足相应需求。
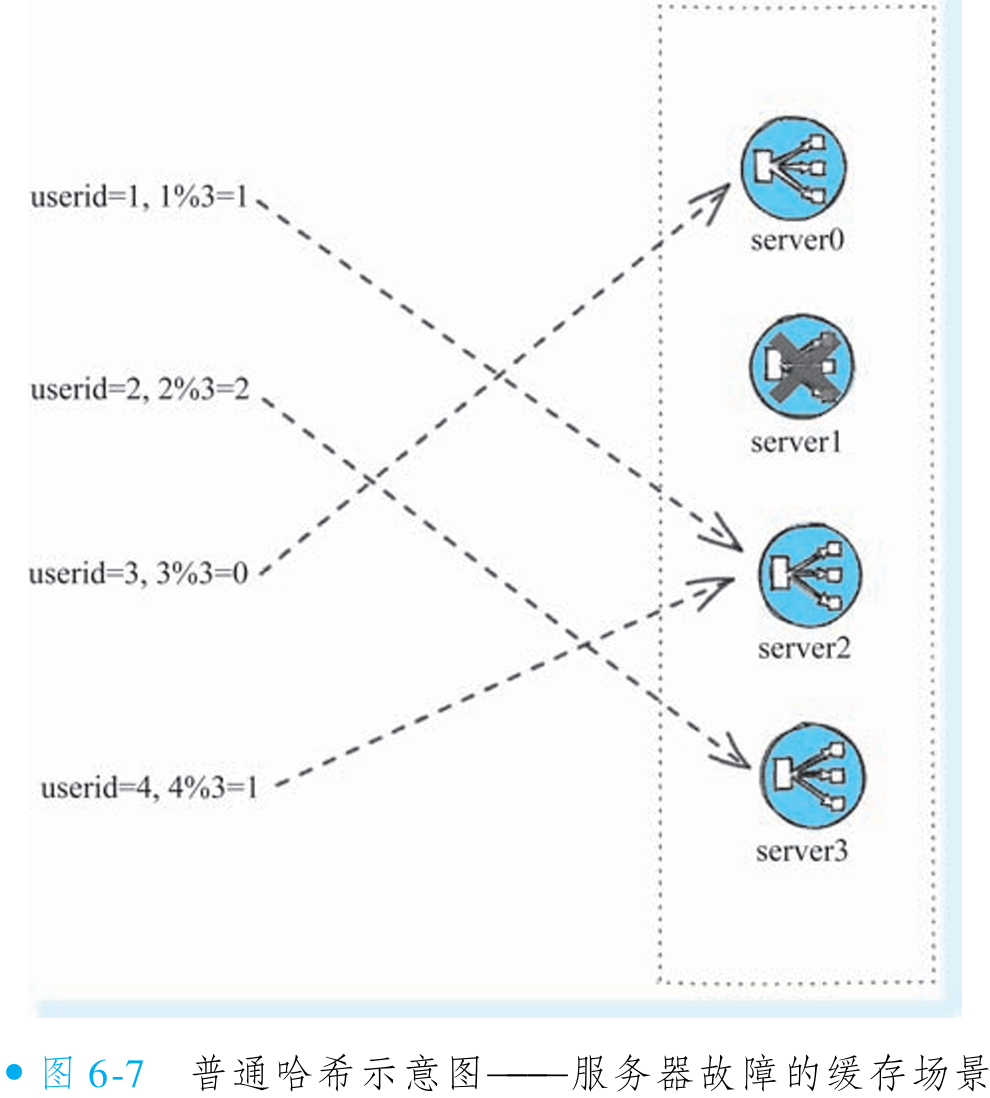
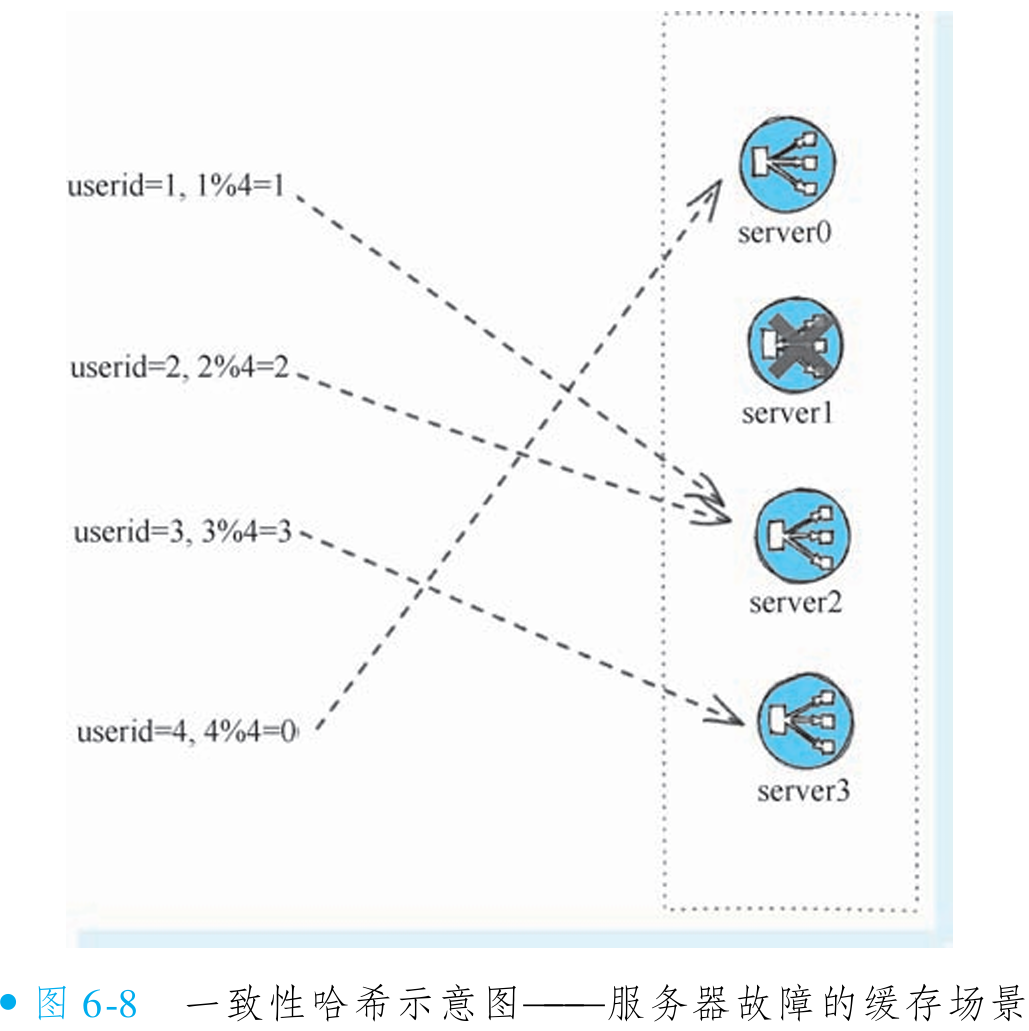
普通哈希算法(如取模)在集群节点变化时会导致缓存大量不命中。以 4 个节点为例,按 userid 取模分配缓存(userid=1、2、3、4 对应节点 1、2、3、0),过程如图 6-6 所示。若节点 1 故障,节点数变为 3,取模结果变为 userid=1、2、3、4 对应节点 1、2、0、1(如图 6-7 所示)。
如果采取一致性哈希的策略, 这时候4个用户的分配将只有 userid=1的分配受到转移, 而其他的三个用户分配都不会受到影响。 这个结果如图6-8所示。
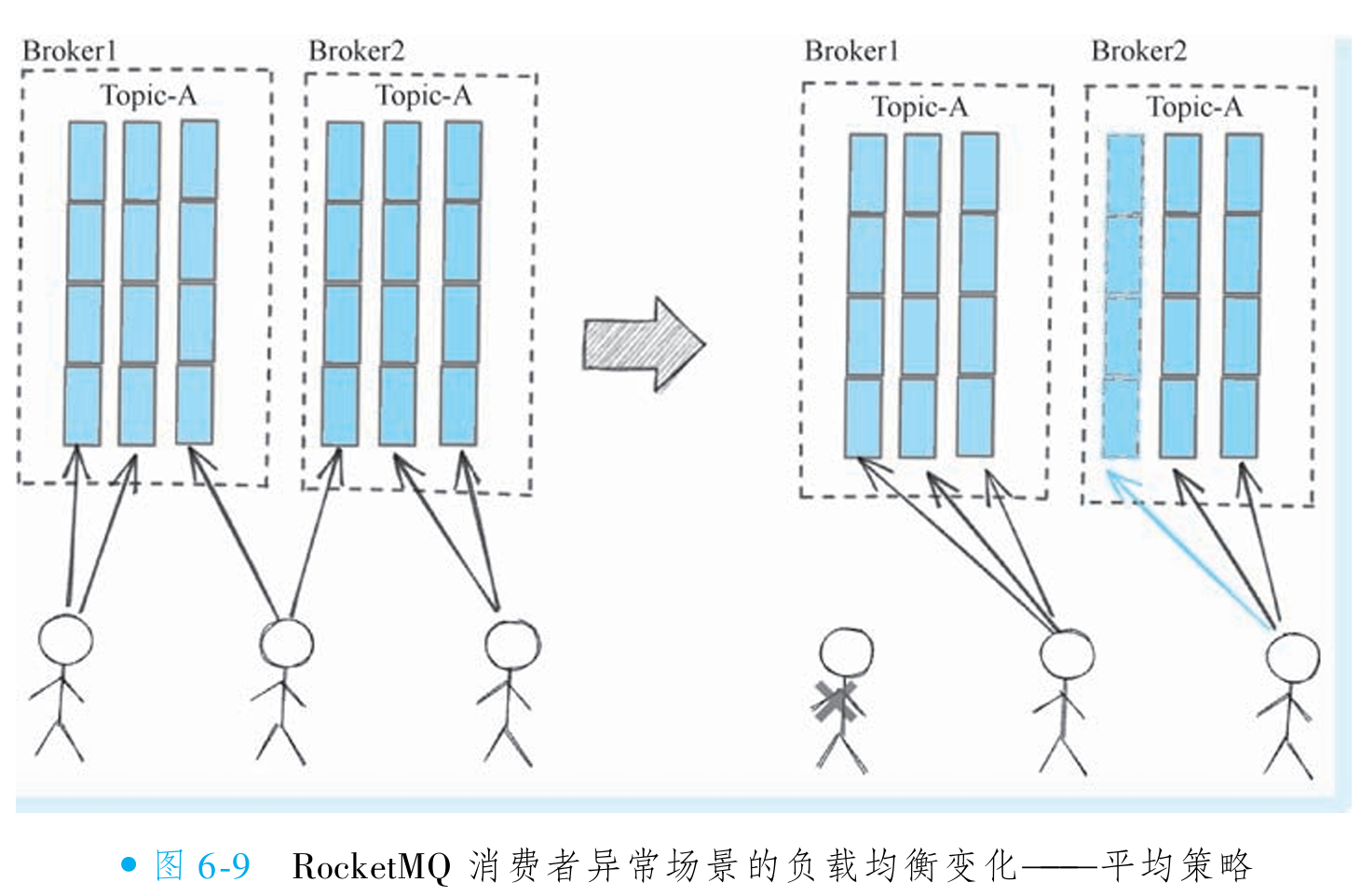
而对应到RocketMQ 的分配策略上, 需要分配的对象是 queue, 接收负载的则是消费者实 例。 一致性哈希负载均衡策略能解决的问题就是在消费者实例发生变化的时候, 队列的重新 分配降到最低 (把刚刚的例子userid对应成 queue, 节点对应为消费者实例去理解一下)。 因 为如果采取默认的平均策略, 实际上就是简单取余的策略, 就会出现大量的队列重新分配, 导致短时间的 “惊群效应”。 可以看到, 对于Broker2的第0条队列而言, 因为一个完全没有。关系的消费者实例下线了, 导致其分配给了另外一个消费者实例。 这个结果如图6-9所示。
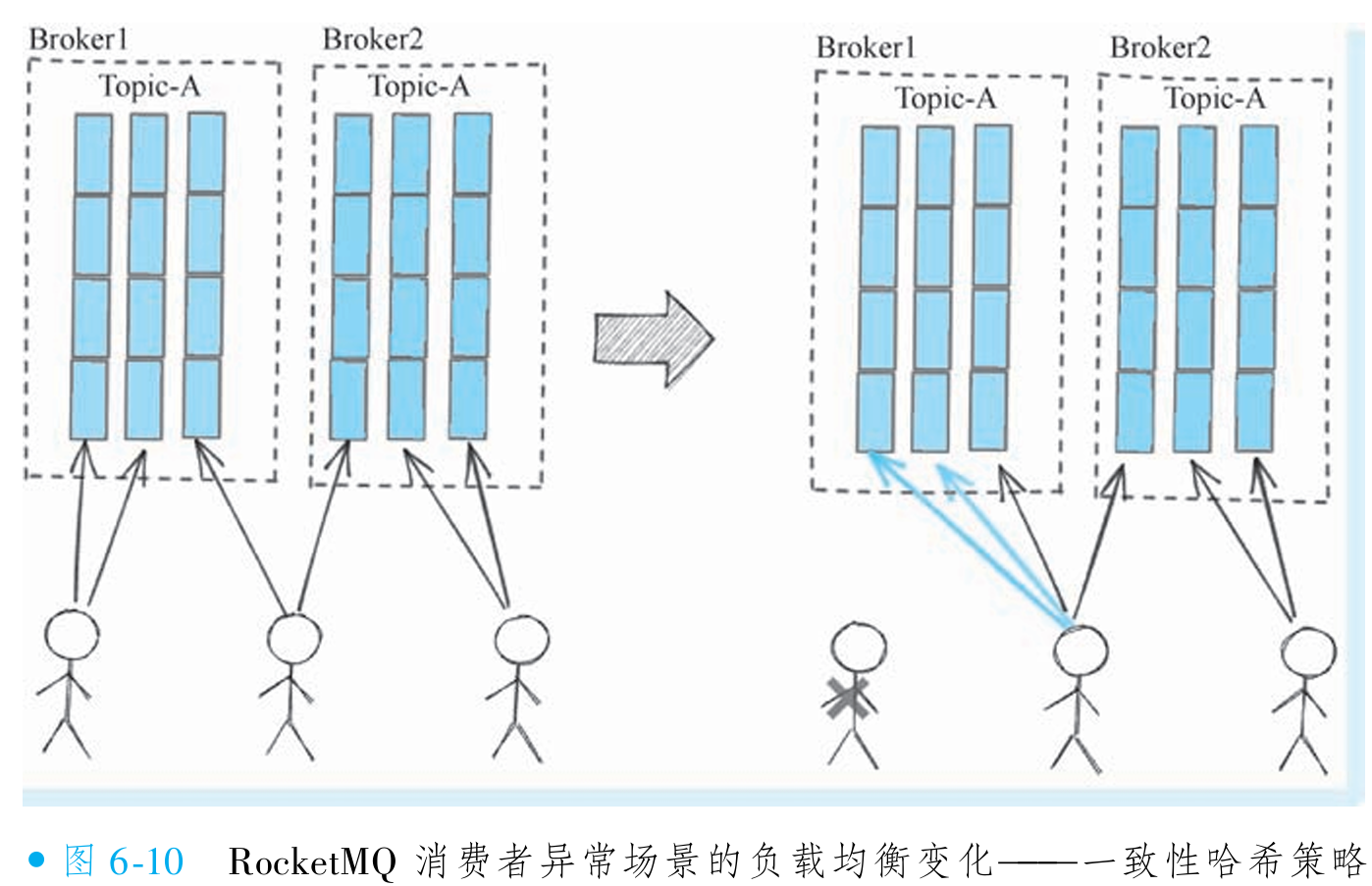
而如果采取一致性哈希的策略, 最后效果如图6-10所示, 大部分队列在消费者实例不可 用的前提下得到稳定的分配结果。
机房就近接入策略(AllocateMachineRoomNearby)
该策略(由笔者提交的PR实现)通过构造函数传入
MachineRoomResolver实例指定机房,其行为分为两层逻辑:同机房优先分配:若队列所在机房存在活跃消费者实例,则队列仅分配给同机房实例(与
AllocateMessageQueueByMachineRoom逻辑一致);跨机房容灾分配:若同机房无可用消费者,队列会自动分配给其他机房实例,避免因单机房消费者全不可用导致消息消费中断。
该策略本质是装饰器:核心(装饰器)功能为“就近分组”(按机房分组),分组后的具体分配方式(如平均分配、轮询、一致性哈希)可由开发者自定义(通过组合
AllocateMessageQueueAveragely等策略实现)。此设计分离了分组逻辑与分配逻辑,兼顾机房亲和性与策略灵活性。
4. 无中心负载均衡带来的弊端
RocketMQ的负载均衡均由客户端执行,无中心节点参与。生产者策略在单个实例内作用,全局趋向平均;消费者采用无中心协调,平均分配时全局公平,但队列数不整除消费者数时可能出现负载不均。
核心问题在于消费者或队列数量变化触发重排,引发“惊群效应”,且策略更换时(如从Averagely改为AveragelyByCircle)会导致升级期间策略不一致,造成消息重复消费或队列无人消费。假设遇到某个情况需要仅发布一个实例以便灰 度验证一个小时, 那么在这一个小时的时间里, 这个实例和其他实例就会处于策略不一致的 情况。 这一个小时必然会出现: 消息重复消费+某些队列无消费者实例消费的情况。 这时候就 需要开发者想办法解决这个平滑升级的过程。 消息重复消费还能用消息幂等方案解决, 队列无人分配就比较麻烦, 因为这就意味着有些消息无法被拉取。 其中一个可能的解决方案是升级的时候更换consumer group(升级的那台) 的名字, 然后灰度消费者在这一小时内就会被全部队列分配, 然 后再辅以消息幂等把重复分配的队列里的消息给幂等处理掉。
RocketMQ 5.0将引入POP消费模式,由Broker控制负载均衡,但短期内传统一队列一消费者模式仍为主流。
5. RocketMQ 广播消息原理
RocketMQ 支持广播消费特性(消息可被消费者组内所有实例接收),但需从默认集群模式显式切换至广播模式。该模式下系统将启用特殊的负载均衡实现机制,确保消息广播至所有实例。广播消息的概念源于 JMS 规范,其实现原理与集群模式有本质差异。
①JMS 的消息类型
JMS 简介
JMS(Java Message Service)是 Java 平台消息中间件的技术规范,定义了消息操作的接口标准(如连接工厂、会话、目的地、生产者、消费者等编程模型),但未提供具体实现(类似 JDBC 规范)。尽管现代开发中已较少直接使用 JMS,其核心概念(如消息类型、优先级)仍被广泛沿用。RocketMQ 虽不严格遵循 JMS 规范,但在设计上主动借鉴其特性(如广播消息场景),以兼容标准生态并适应更多应用场景。
JMS 通过消息类型(如点对点、发布订阅)引出广播消息场景,这一概念被 RocketMQ 吸收并实现为广播消费模式,允许消息被消费者组内所有实例接收。其规范价值在于提供统一接口模型,而具体实现由各中间件厂商(如 RocketMQ)自主完成。
JMS 消息类型
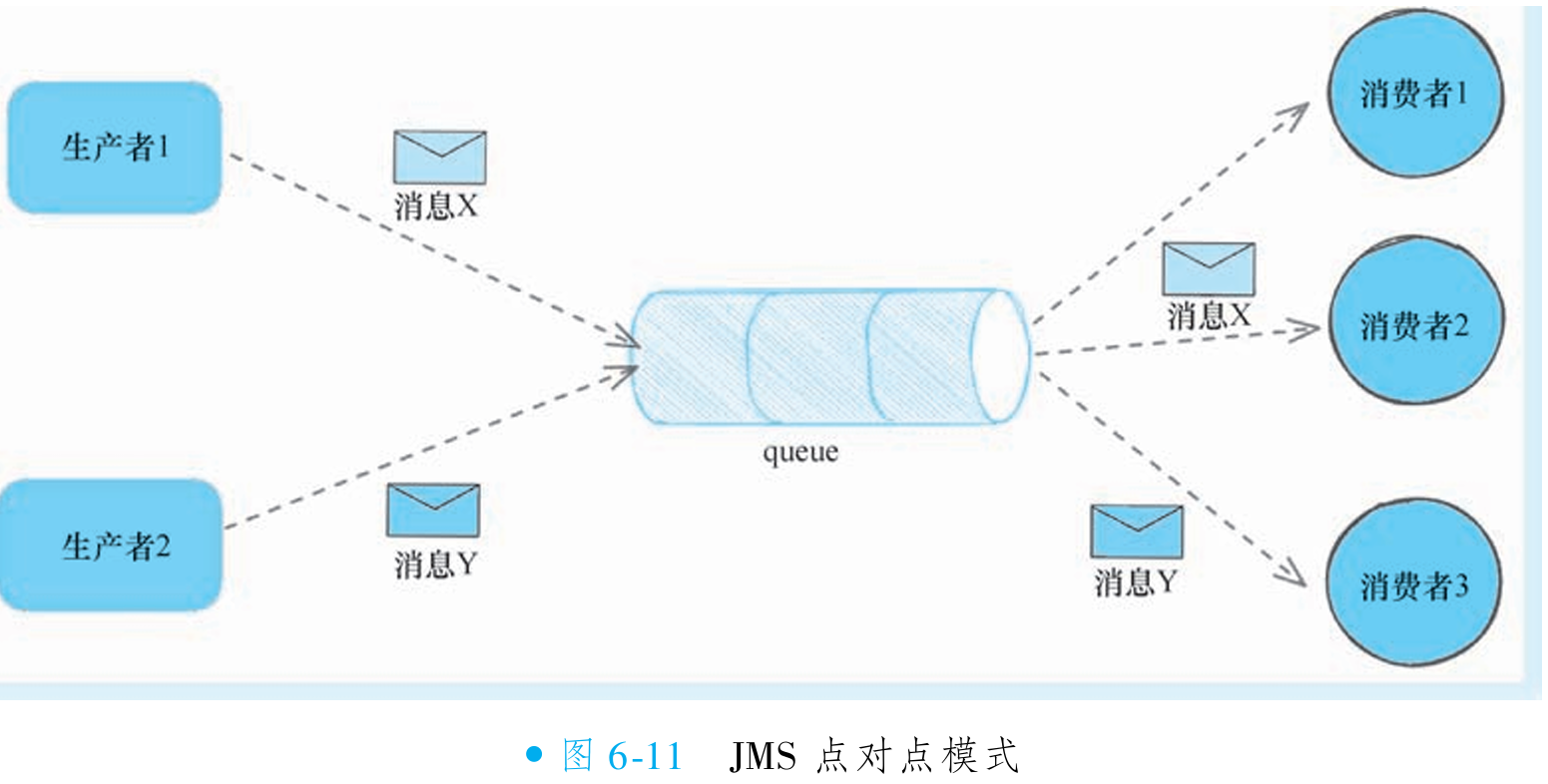
JMS 规范定义了点对点(Point to Point)和发布/订阅(Publish/Subscribe)两种消息模式。点对点模式下,消息发送至队列(JMS 概念,与 RocketMQ 队列不同),仅由一个消费者消费,消费后消息立即删除,且消费者与生产者无时间依赖(可以先发送消息, 再启动消费者, 也可以反过来)(如图 6-11 所示)。此模式与 RocketMQ 集群消费模式相似,均采用负载均衡机制。
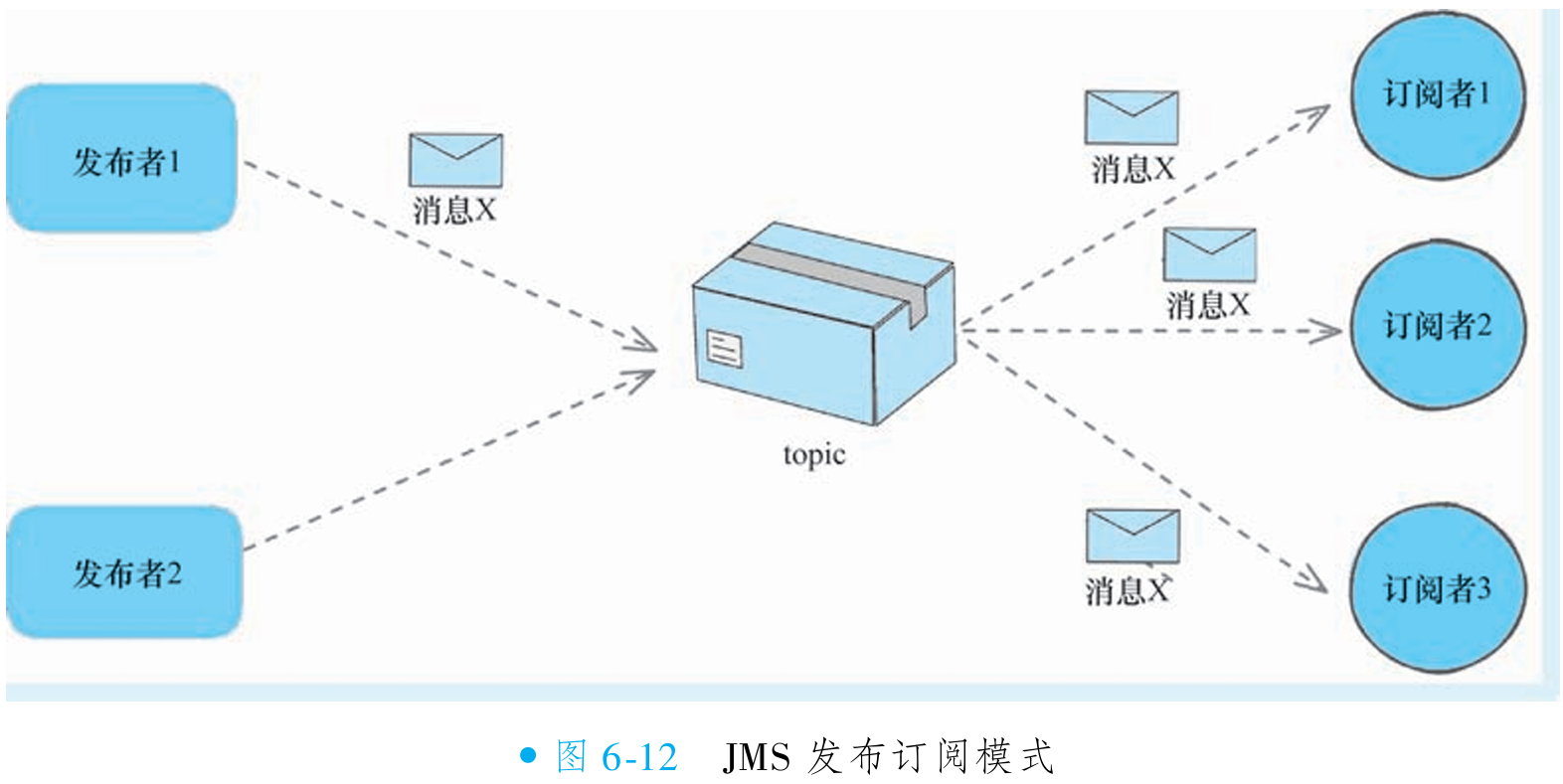
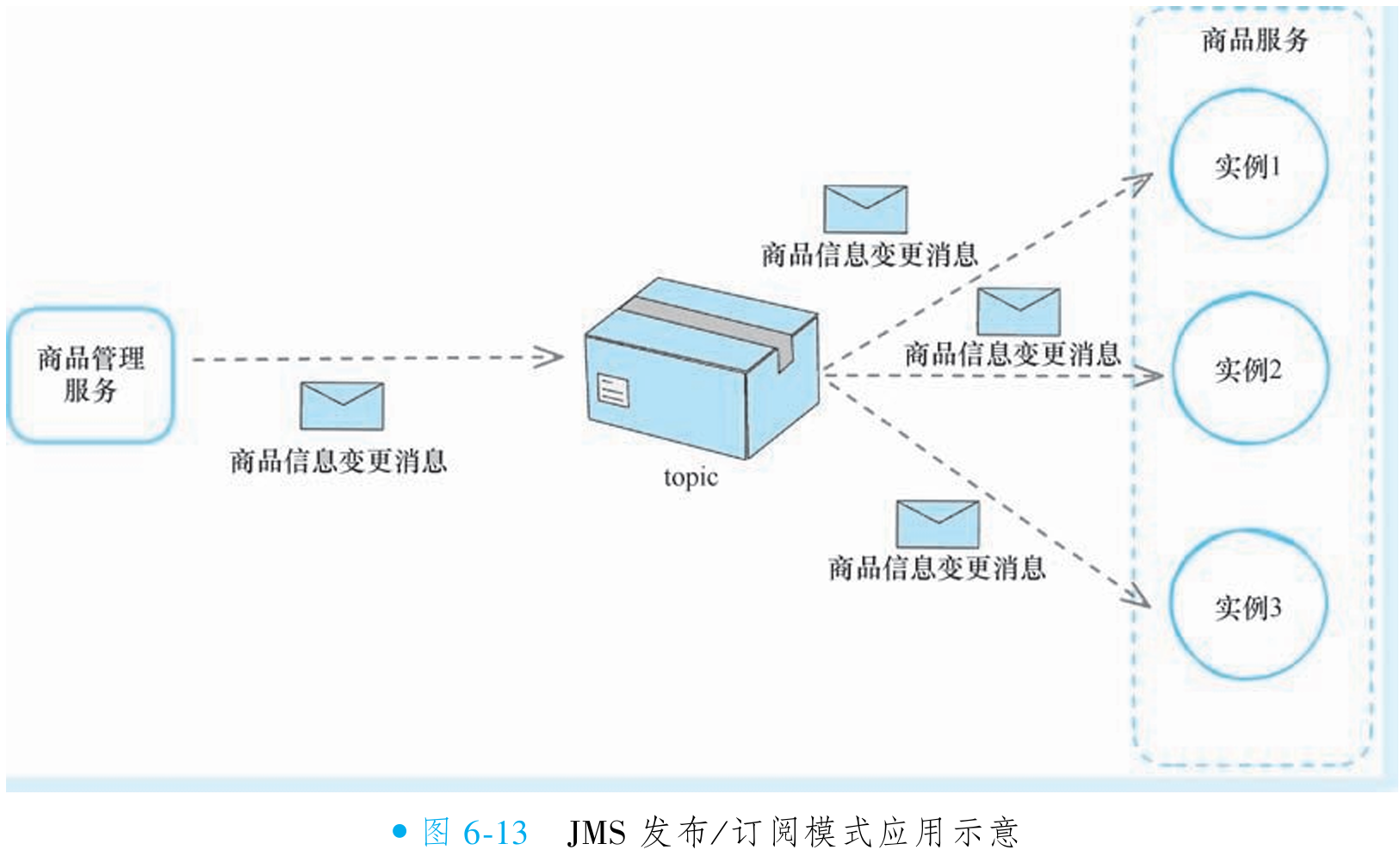
发布/订阅模式下,消息发布者将消息发送至主题(JMS 概念, 与 RocketMQ 主题不同),所有订阅者均能接收消息,消息需所有订阅者消费后才删除,因此一条消息可能被多次消费。生产者和消费者有时间依赖(如果先发送消息, 后订阅主题, 那么订阅之前的消息将不能被这个订阅者 消费),只有订阅后才能消费消息(如图 6-12 所示)。此模式适用于本地缓存更新等场景,如商品服务实例订阅商品变更消息,各实例接收相同消息刷新缓存(如图 6-13 所示)。在 RocketMQ 中,此模式称为广播模式。
②主流消息中间件对发布/订阅模式的支持
RabbitMQ 对发布/订阅模式的支持
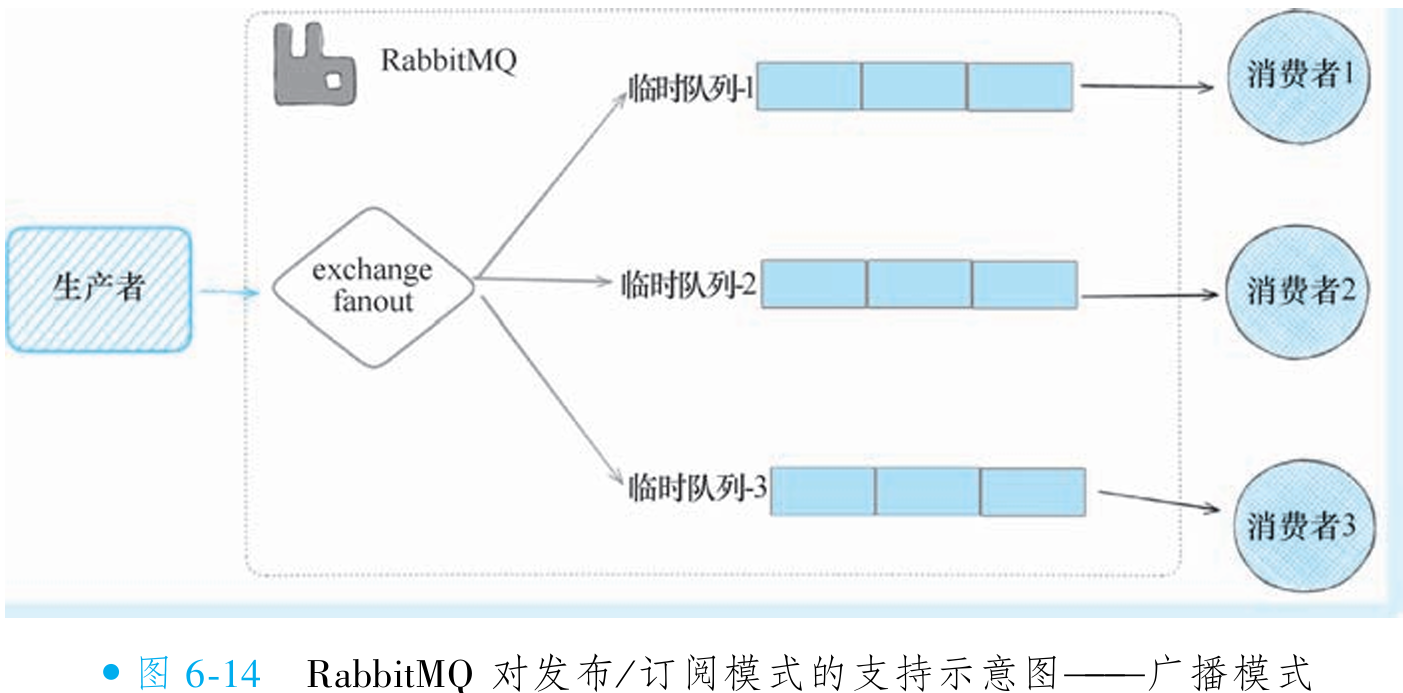
RabbitMQ 的发布/订阅模式基于广播机制实现,核心概念为 exchange(交换器):消息发送至 exchange 后,由其按广播类型分发至对应队列。广播模式支持三种策略:
fanout(扇出):所有绑定到该 exchange 的队列均接收消息,用于广播场景(如图 6-14 所示),也是对 JMS 发布/订阅模式的支持;
direct:通过 routingKey 和 exchange 确定唯一接收队列,实现 JMS 点对点模式;
topic:符合 routingKey(支持表达式)的队列接收消息。
RabbitMQ 天然支持该模式:消费者启动时创建临时队列(离线时自动销毁),并将其绑定至 fanout 类型 exchange。消息到达 exchange 后,自动投递至所有绑定队列,确保每个消费者接收副本。此设计无需持久化队列,依赖临时队列实现动态订阅与消息广播。
Kafka 对发布/订阅模式的支持
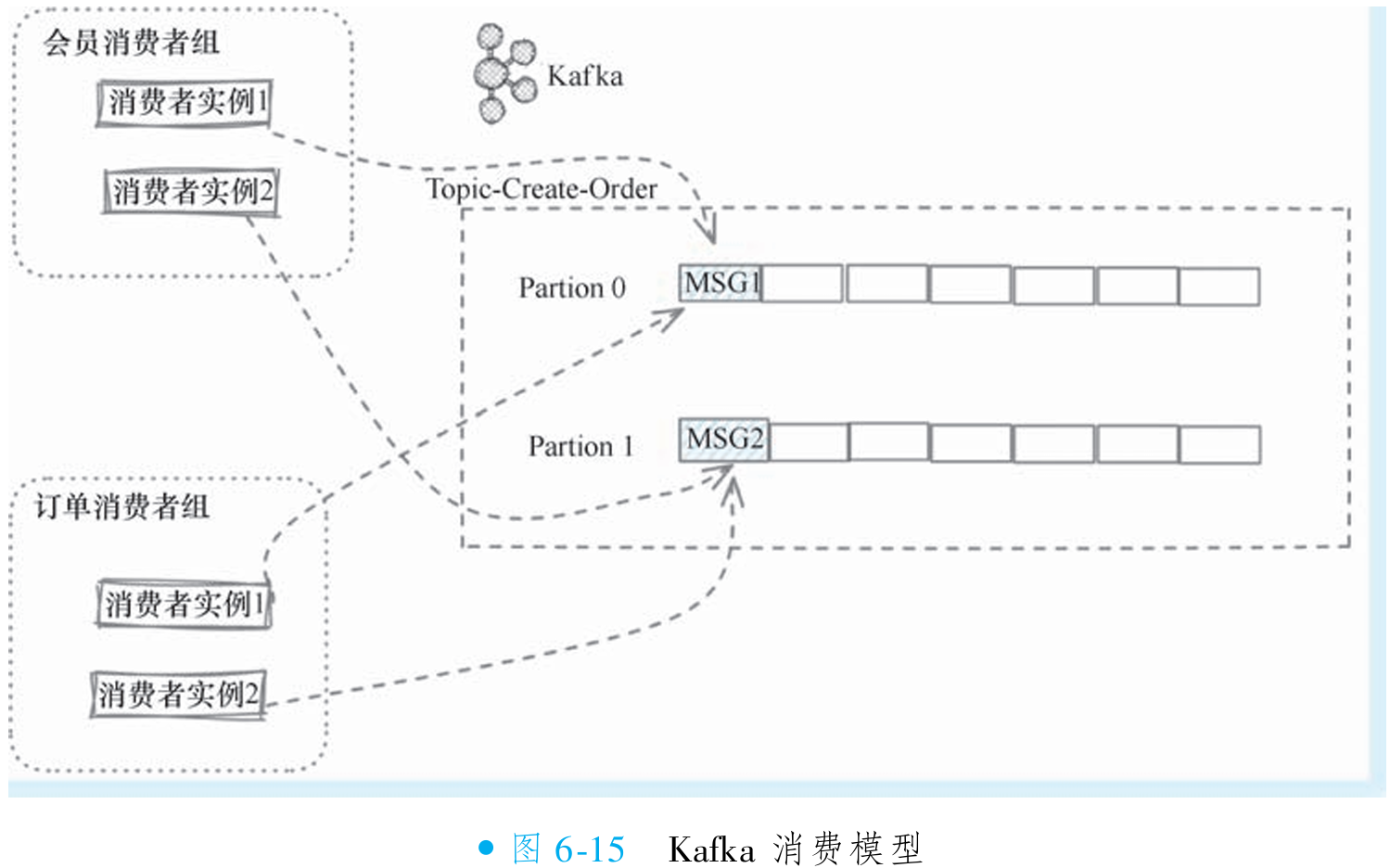

Kafka 与 RocketMQ 均采用消费者组管理消费者,但消费模式存在核心差异。Kafka 的消费者组内遵循严格点对点模式:一个分区仅由一个消费者实例消费(如图 6-15 所示),天然支持负载均衡与有序处理,但无法直接实现发布/订阅模式。
Kafka 未原生支持发布/订阅,需通过单实例消费者组模拟:若需两个实例同时接收全量消息,须将其分属不同消费者组(如图 6-16 所示)。此设计下,每个实例独立消费所有分区,实现消息广播,但需维护大量消费者组(实例数=组数),增加运维复杂度。
Kafka 以分区粒度保障顺序性与均衡性,牺牲了广播便利性;RocketMQ 则原生支持集群与广播双模式。Kafka 的变通方案虽可实现广播,但违背其消费者组设计初衷,需权衡架构简洁性与功能需求。
③RocketMQ 对发布/订阅模式的支持
RocketMQ 广播模式的使用
RocketMQ 的整体模型与 Kafka 极为相似,但无需通过拆分消费者组的方式实现发布/订阅模式支持。RocketMQ 在特性上天然支持该模式,无需额外操作。
在 RocketMQ 中,此模式称为广播模式,相关消息亦称为广播消息。与 Kafka 需破坏消费者组统一性不同,RocketMQ 允许不同实例在保持同一消费者组名称的前提下,直接完成消息向所有实例的广播,简化了架构设计与运维。
那么RocketMQ是怎样实现只需要改一行代码,就把整个消费模式修改的呢?其解决的思路 其实也很简单———改变广播模式下的重平衡(Rebalancing)。
/**
* RocketMQ 广播消费模式示例
* 使用起来非常简单,和普通的集群模式只有一行代码的区别:设置广播消费模式。
*/
public class BroadcastConsumerExample
{
public static void main(String[] args) throws Exception
{
// 新建一个消费者组,用以处理商品的缓存刷新
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("GOODS_CACHE_CONSUMER");
// 设置消费的初始位点,因为缓存刷新只关心最新的消息,所以设置从尾部开始消费
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_LAST_OFFSET);
// 设置消费模式为广播消费模式
// 那么 RocketMQ 是怎样实现只需要改一行代码,就把整个消费模式修改的呢?
// 其解决的思路其实也很简单——改变广播模式下的重平衡(Rebalancing)
consumer.setMessageModel(MessageModel.BROADCASTING);
// 订阅关心的主题
consumer.subscribe("TOPIC_GOODS_INFO_UPDATE", "*");
// 注册消息监听器
consumer.registerMessageListener(new MessageListenerConcurrently()
{
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context)
{
// 打印接收到的消息
System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);
// 伪代码。这里是消费逻辑,暂且假设这个方法可以实现本地缓存的刷新动作
updateCache(msgs);
// 返回消费成功
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
// 启动消费者
consumer.start();
System.out.printf("Broadcast Consumer Started.%n");
}
// 伪代码方法:更新本地缓存
private static void updateCache(List<MessageExt> msgs)
{
// 实现本地缓存刷新逻辑
// 例如:解析消息内容并更新缓存
}
}广播模式下的队列重平衡
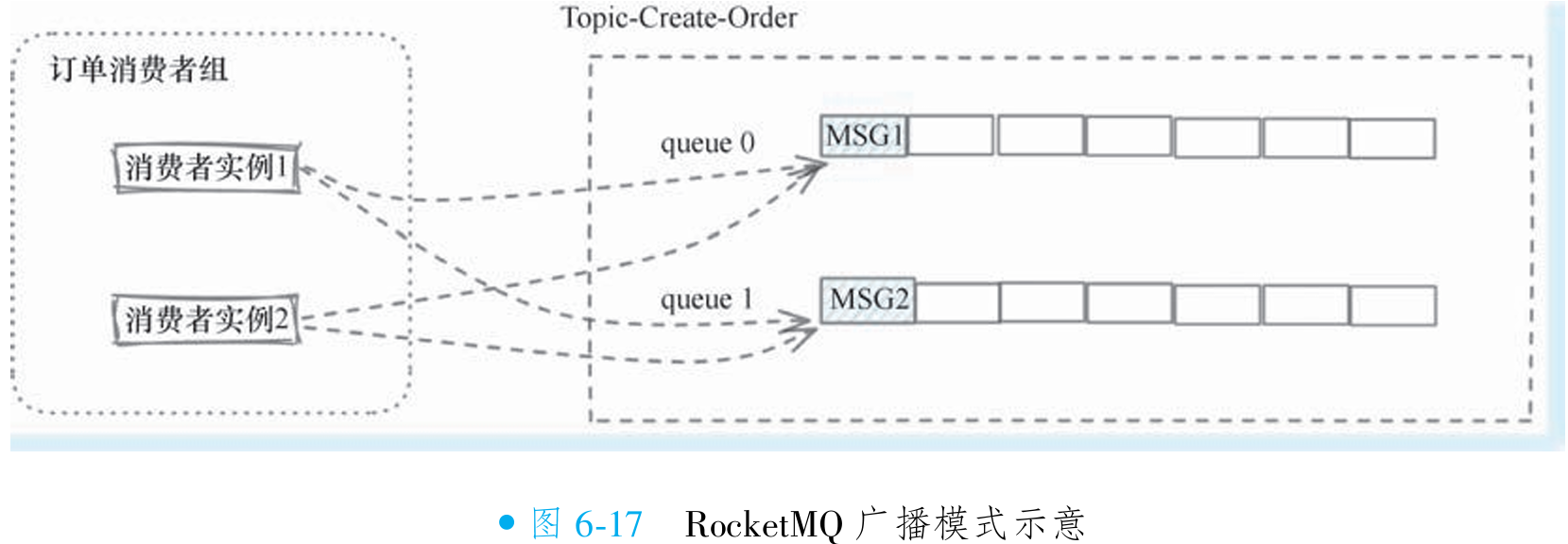
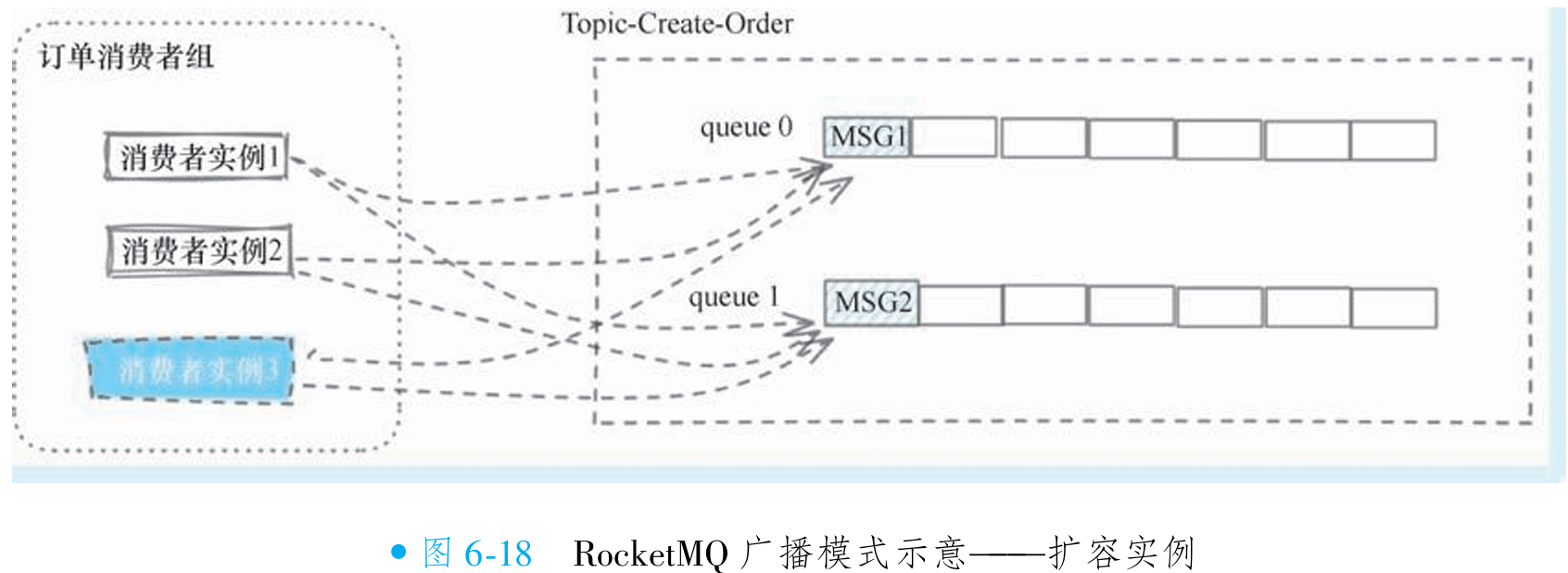
之前的章节介绍过 RocketMQ 的队列分配策略,在集群模式下遵循两个原则:所有队列都会被分配到,且一个队列在一瞬间只会被分配给一个消费者实例(策略差异主要体现在分配算法上)。为实现消息的全实例广播,RocketMQ 定义了广播模式(MessageModel.BROADCASTING),在该模式下不再遵循常规负载均衡策略,而是无条件将所有队列分配给所有消费者实例(如图 6-17 所示)。
以订单服务消费者组为例:若有两个实例,每个实例都会分配全部队列(如两个队列),消息进入任意队列时,所有实例均能接收,实现广播效果(如图 6-18 所示)。即使消费者组扩容(如新增实例),新实例也会自动分配全部队列,确保消息持续广播。
利用队列的重平衡算法的修改, RocketMQ很巧妙地实现了对广播消息的支持, 同时所有的 消息持久化等相关的工作都无须重新设计, 因为消息本身不会因为消费模式的不同而有所影响, 仅仅只是消费者获取消息的方式上会有所不同而已。 而且这样设计还有一个好处, 即便 RocketMQ 有 100 个消费者实例需要广播消费, 消息存储方面实际上不需要做100份存储, 只需 要不同的实例拉取同一份消息即可完美地支持。
RocketMQ 通过修改重平衡算法实现广播模式,无需改变消息持久化机制——消息仅存储一份,所有实例拉取同一份数据即可支持广播,极大节省存储成本。相较于 RabbitMQ(广播需消息多份存储),RocketMQ 性能更优;对比 Kafka(需拆分消费者组模拟广播),RocketMQ 的统一消费者组设计在管理和使用层面更加优雅。
广播模式下的队列消费进度管理

在广播模式下,所有队列被重复分配给多个消费者实例,为避免消费进度混乱(如实例间进度差异导致消息遗漏),RocketMQ 将消费进度存储从 Broker 迁移至消费者本地磁盘。进度文件默认存储在用户目录下的
rocketmq_offsets文件夹中,路径格式为/用户目录/rocketmq_offsets/客户端唯一ID/消费者组名称/offsets.json,其中客户端唯一ID由实例IP和instanceName组合而成(如192.168.0.8@DEFAULT),确保各实例进度相互隔离。消费者启动时,首先从本地offsets.json文件读取消费进度以确定拉取位点;若文件不存在(如新实例),则依据
ConsumeFromWhere参数(建议设置为CONSUME_FROM_FIRST_OFFSET或CONSUME_FROM_TIMESTAMP)初始化位点。为避免进度丢失,务必固定instanceName(避免使用动态值如时间戳),推荐采用前缀+IP等稳定命名方式,保障重启后能恢复历史进度。
/**
* 广播模式下消费进度本地存储说明:
* 广播模式下,消费进度不再存储于Broker端,而是持久化到消费者本地磁盘文件中。
* 文件存储内容与Broker端存储的内容结构基本一致,但由于广播模式下单个文件仅对应一个消费者组的消费进度,
* 因此在结构上存在细微差异。
*
* 存储结构说明:
* - key: 队列信息(包含broker名称、主题名称、队列ID等元数据)
* - value: 对应的消费进度值(偏移量)
*
* 以下是一个存储示例(JSON格式):
* {
* "offsetTable": {
* {"brokerName":"broker-a", "queueId":2, "topic":"TopicTest"}: 1116,
* {"brokerName":"broker-a", "queueId":1, "topic":"TopicTest"}: 1141,
* {"brokerName":"broker-a", "queueId":0, "topic":"TopicTest"}: 1139
* }
* }
*/④广播模式下的可靠性及顺序性处理
广播模式下的ACK处理
在广播模式下,消息会被重复投递到所有消费者实例(N个实例),这与集群模式下仅由单一实例处理消息的逻辑形成鲜明对比。由于该特性,广播模式取消了集群模式中"单个实例消费失败触发全体实例重试"的机制。
若广播模式下某个实例消费失败,系统不会触发全局重发(否则100个实例中1个失败导致全体重试显然不合理),该实例将直接记录消费失败并提交位点。因此开发者必须自行实现异常处理与重试逻辑。值得注意的是,广播模式与集群模式同样遵循AT-LEAST-ONCE投递保证:RocketMQ确保在消费者未成功接收消息前,不会停止向任何实例投递该消息,这一保证通过消费位点机制实现。
广播模式下的顺序消费处理
广播模式下无法实现全局严格顺序,因其核心机制与集群模式存在本质差异:集群模式通过队列加锁实现消息独占和顺序保证,而广播模式下所有消费者实例共享同一队列,导致队列无法加锁,从而无法约束跨实例的消费顺序。
广播模式仅能保障单实例内部的消费顺序(如实例1按序处理MSG1、MSG2、MSG3),但不同实例间的消费进度完全独立。例如,实例1可能快速处理完MSG1和MSG2后,实例2才开始消费MSG1。这一行为符合设计预期——广播模式下各实例独立消费全量消息,互不干扰,其顺序性约束仅限于实例内部。
七. RocketMQ 存储设计
1. RocketMQ消息存储概览
①文件构成
RocketMQ 的消息存储管理依赖三个关键文件:
CommitLog:核心消息存储文件,负责持久化所有消息体内容,确保消息的可靠存储。
ConsumeQueue:基于队列和偏移量的索引文件,每个队列独立一组,用于加速消费时对 CommitLog 中消息的定位查询。
IndexFile:基于消息 Key(如订单号)的索引文件,支持通过业务关键词快速检索消息内容,满足按条件查询的需求。
CommitLog 集中存储消息实体,ConsumeQueue 和 IndexFile 分别提供队列维度和业务维度的索引能力,三者协同实现消息的高效存储、快速检索与可靠消费。此架构兼顾了顺序写入性能与多维查询灵活性。
②消息存储过程
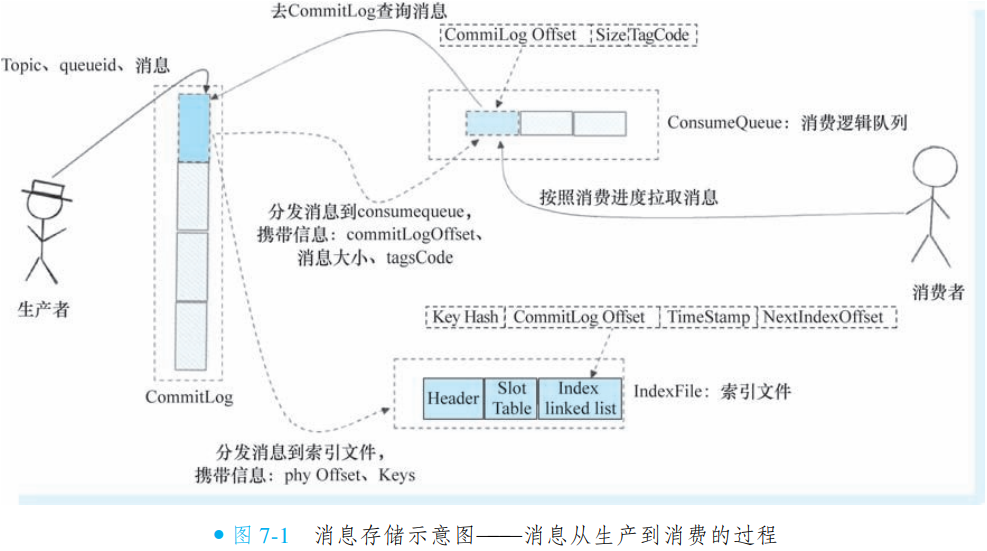
RocketMQ 通过三个核心文件协同完成消息的高效存储与检索:
CommitLog:作为主存储文件,生产者发送消息时,所有消息体及元数据均直接写入此文件,完成持久化;
ConsumeQueue:基于 CommitLog 异步构建的队列索引文件,按队列维度组织,记录消息在 CommitLog 中的物理位置;
IndexFile:同样基于 CommitLog 异步构建的哈希索引文件,支持通过消息 Key(如订单号)快速检索。
消费者拉取消息时,无需直接扫描 CommitLog:首先查询 ConsumeQueue 获取消息在 CommitLog 中的定位信息,再精准读取具体内容。此设计通过索引机制将随机读转换为顺序读,极大提升消费效率,同时保障 CommitLog 的顺序写入性能。
2. RocketMQ存储与检索
①RocketMQ存储对比Kafka存储
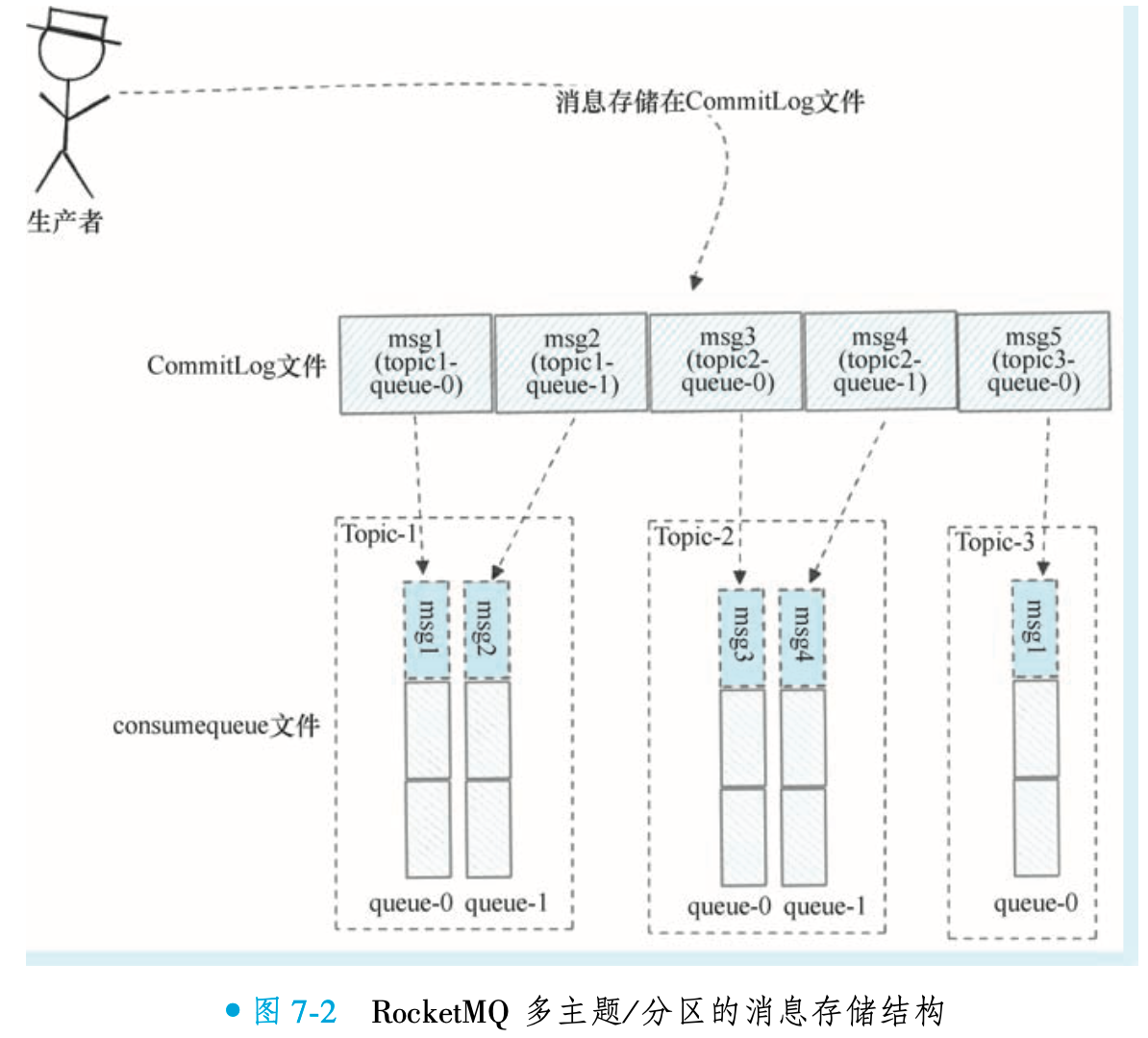
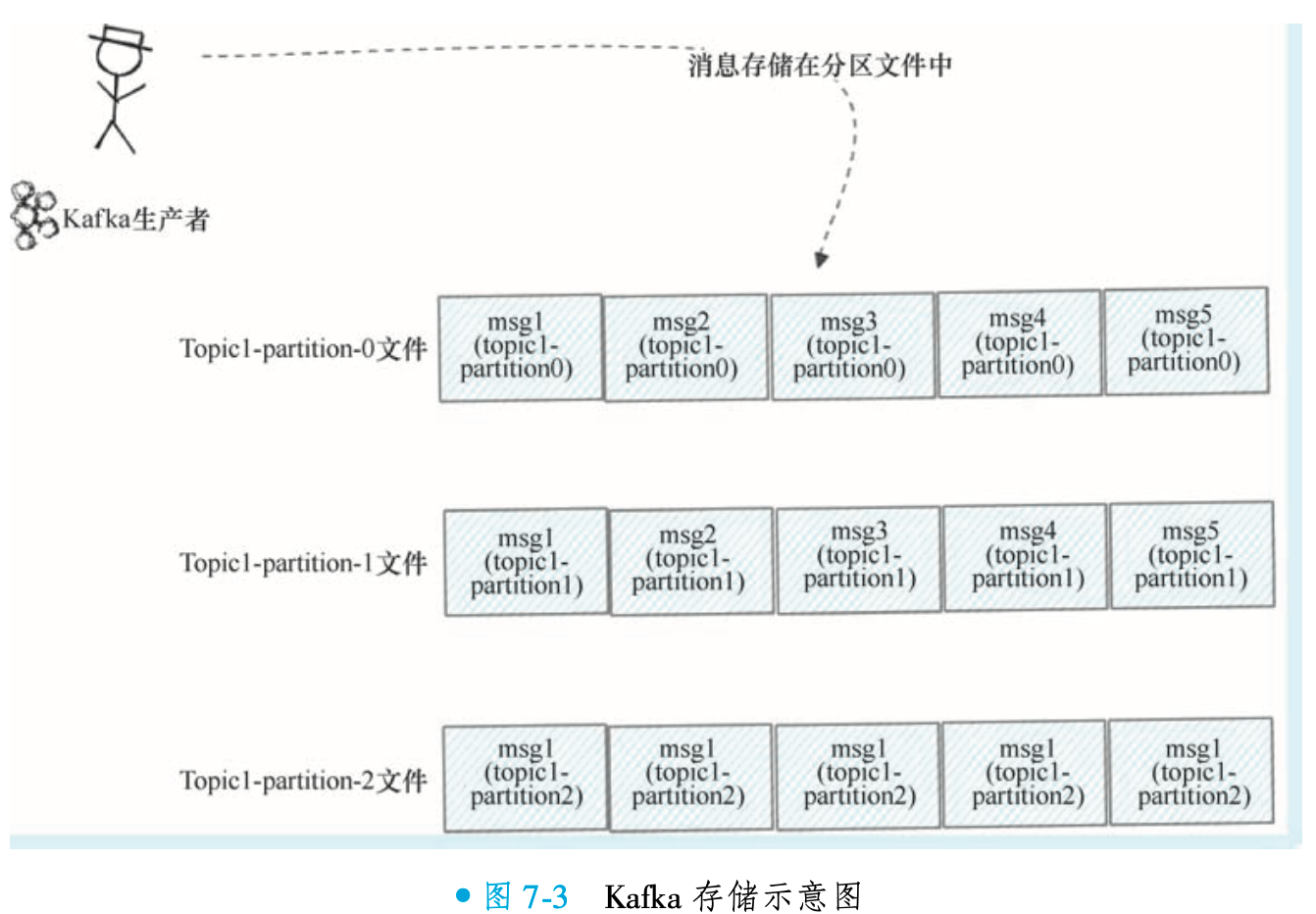
RocketMQ 在多主题消息存储场景下显著优于 Kafka,其核心优势源于独特的存储架构:所有 Topic 的消息统一写入 CommitLog 文件(默认单文件 1GB,写满后滚动新建),而非按主题或队列物理分离。这种设计将随机写转换为顺序写,极大提升磁盘 I/O 效率。
Kafka 采用分区独立存储:每个 Partition 单独存储消息实体(如图 7-3 所示),导致多主题/多分区时产生大量小文件,引发磁盘寻址瓶颈。而 RocketMQ 通过 CommitLog 统一存储 + 异步构建队列索引(ConsumeQueue)的方案,既保障写入性能,又支持高效检索,实现吞吐量与扩展性的平衡。
②RocketMQ存储设计对比Kafka的优势
RocketMQ 通过 CommitLog 统一存储设计实现性能优化:所有消息顺序写入单一文件,充分利用磁盘顺序 IO 接近内存的读写速度。相比之下,Kafka 采用分区独立存储(每个 Partition 单独文件),主题/分区数量增加时会产生大量随机 IO,导致性能显著下降。
即便 ConsumeQueue 索引文件采用随机 IO,其效率依然极高:文件体积小(单条记录约 20B),且通过 MappedFile 内存映射与操作系统 page cache 机制,使读写操作多在内存完成,有效规避磁盘随机 IO 瓶颈。这一设计保障了 RocketMQ 在多主题场景下的稳定高性能。
内存映射文件(Memory-Mapped File)是一种将文件或设备直接映射到进程虚拟地址空间的技术,允许程序像读写内存一样直接操作文件内容,而无需传统的
read或write等系统调用。这种机制由操作系统内核提供支持,广泛应用于高性能 I/O 处理、大文件操作和进程间通信(IPC)等场景。内存映射文件的核心依赖于操作系统的虚拟内存管理机制,其基本工作流程如下:
建立映射:进程通过系统调用(如 Linux 的
mmap)请求将特定文件的一部分或全部映射到其虚拟地址空间。操作系统会在虚拟地址空间中分配一段区域,并建立该区域与磁盘文件的关联。此时,文件内容并未立即全部加载到物理内存。按需加载:当进程首次访问(读或写)已映射的虚拟地址时,如果该地址对应的文件数据尚未加载到物理内存,硬件会触发一个缺页中断(Page Fault)。操作系统捕获此中断后,负责将相应的文件页从磁盘读取到物理内存页中,然后更新进程的页表,建立虚拟地址到物理地址的映射。此过程称为延迟加载(Lazy Loading)或按需分页,它避免了一次性加载整个文件,节省了内存资源。
访问与修改:此后,进程对该内存区域的读写操作(如通过指针操作)会直接作用于对应的物理内存页。这些修改首先体现在内存中。
同步与解除映射:修改过的页面会被标记为“脏页”,操作系统会择机(或根据进程的显式请求,如调用
msync)将脏页写回磁盘,确保数据持久化。当进程解除映射(如调用munmap)或终止时,所有脏页会被同步到文件,并释放相关的虚拟地址区域和内存资源(除共享情况外)。内存映射文件相比传统文件 I/O 具有显著优点:
减少数据拷贝:传统 I/O 通常需要数据在内核缓冲区和用户空间缓冲区之间拷贝。内存映射文件使得进程可以直接通过内存地址访问文件数据,避免了这至少一次的数据拷贝,实现了零拷贝(Zero-Copy),从而降低了 CPU 开销,提高了吞吐量。
高效随机访问:一旦文件被映射,访问文件中任意位置的数据都如同访问内存数组一般简单高效,无需复杂的
lseek操作,非常适合数据库、索引结构等场景。共享内存与 IPC:多个进程可以映射同一个文件。通过共享映射(如
MAP_SHARED),一个进程对映射内存的修改可以立即被其他映射该文件的进程看到,这为进程间通信提供了一种非常高效的方式。延迟加载与内存效率:大文件映射时,并不是所有内容都立即占用物理内存,而是根据访问情况按需加载,有效节省了物理内存的使用。
使用内存映射文件时也需注意以下几点:
映射大小限制:在 Java 中,
MappedByteBuffer单次映射的大小受Integer.MAX_VALUE限制(约 2GB)。处理更大文件需进行分段映射。文件空洞:如果映射区域超过文件实际大小,可能会在文件中创建“空洞”(用零填充),并占用相应的虚拟地址空间。
数据一致性:虽然操作系统会负责将修改写回磁盘,但应用程序应注意同步时机。及时调用
force()或msync()可确保关键数据持久化,防止系统崩溃导致数据丢失。资源管理:在某些语言/环境中(如 Java),映射的内存在垃圾回收时可能不会自动清理,可能导致文件锁等资源无法释放。需要显式管理(如调用
Cleaner)或使用try-with-resources确保资源释放。
3. CommitLog文件
CommitLog是真实存储消息内容的文件, 其实它是一组同类文件的统称。 实际上所谓的CommitLog文件并不是只有一个文件, 而是连续存储的多个文件。
①CommitLog文件结构
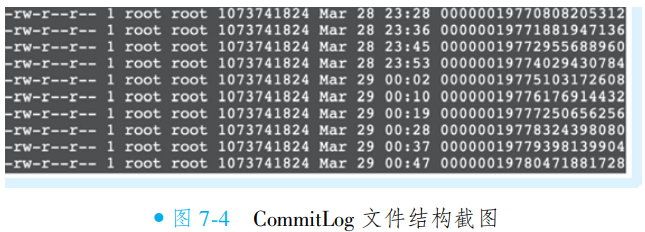
RocketMQ 将所有消息统一存储在独立的 CommitLog 目录中,路径为
$HOME/store/commitlog/{fileName}。每个 CommitLog 文件默认大小为 1GB,写满后自动滚动创建新文件。件名采用 20 位纯数字(不足位左补零),数字值代表文件中第一条消息的起始偏移量。例如:
00000000000000000000:起始偏移量为 0,对应第一个文件;00000000001073741824:起始偏移量为 1073741824(即 1GB),为第二个文件,依此类推。此设计通过偏移量直接定位消息物理位置,兼顾顺序写入性能与高效检索能力。
②CommitLog 抽象模型
RocketMQ 的 CommitLog 由多个等长文件(默认 1GB)逻辑首尾拼接而成,形成连续的抽象存储空间。消息严格按写入顺序追加至最新文件,且为保证绝对顺序性,同一时刻仅允许单线程执行写入操作。
CommitLog 内各消息长度可变(非定长数组结构),故其自身无法直接支持搜索功能。然而,凭借固定的消息头部结构(含消息长度等元数据),只需获知消息的起始偏移量,即可完整解析出该消息全部内容。这一偏移量定位与解析能力是 RocketMQ 存储设计的核心,贯穿整个消息检索流程。
③CommitLog 文件组成

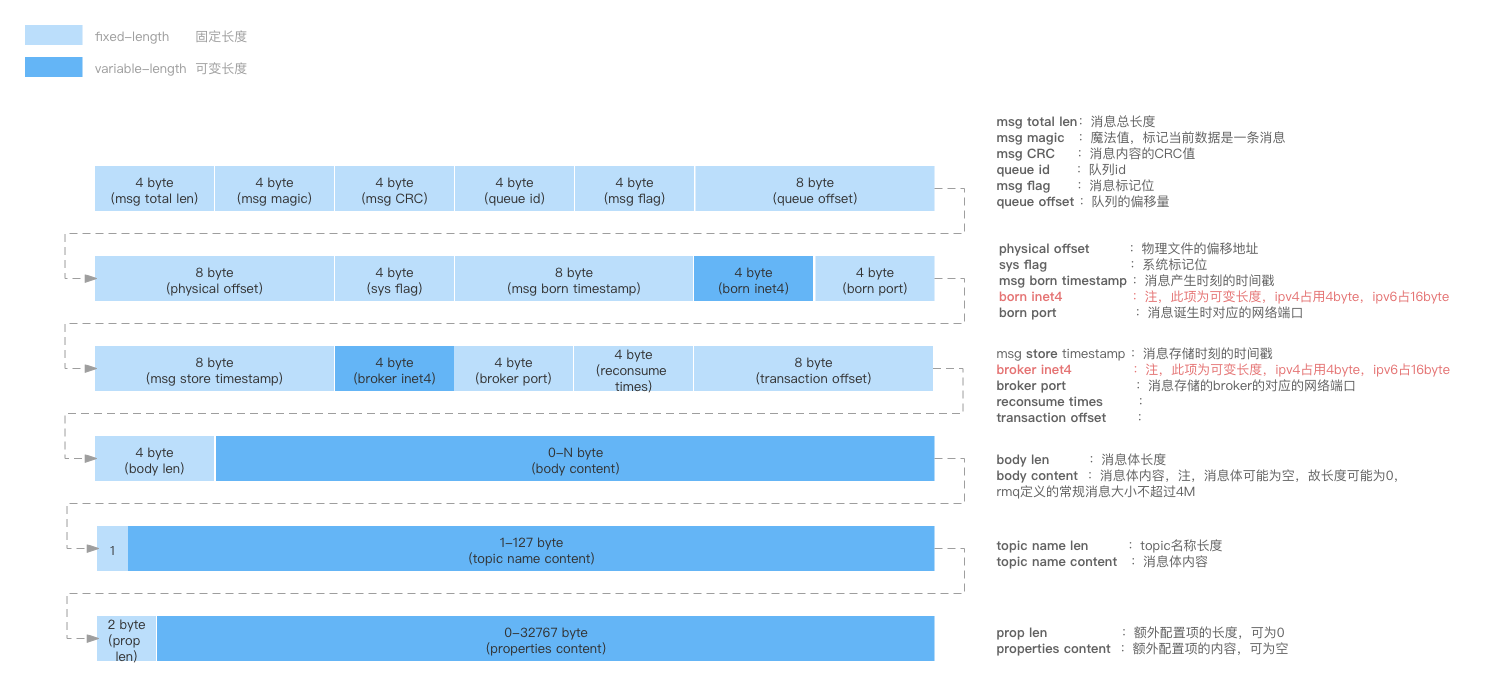
虽然每个消息的大小是不一样的, 但是每一个消息在 CommitLog 中会由相同的部分组成, 如图 7-6 所示。
图 7-6 中包含的多个部分实际上是按顺序存储在 CommitLog 一个消息的内部的, 以下按顺 序简单说明各个部分的含义。
RocketMQ 的 CommitLog 采用定长头部 + 变长内容的统一结构存储所有消息(结构见图 7-6)。
4B 的 msgLen: 消息的长度, 是整个消息体所占用的字节数的大小。
4B 的 mogicCode: 固定值, 有 MESSAGE_MAGIC_CODE 和 BLANK_MAGIC_CODE。
4B 的 bodyCRC: 消息体的校验码, 用于防止网络、 硬件等故障导致数据与发送时不一 样带来的问题。
4B 的 queueId: 表示消息存储的 MessageQueue 的 id, 用于后续查询消息的时候知道查 哪个 consumeQueue 文件。
4B 的 flag: 创建 Message 对象时由生产者通过构造器设定的 flag 值。
8B 的 queueOffset: 表示在 queue 中的偏移量。
8B 的 physicalPosition: 表示在存储文件中的物理偏移量。
4B 的 sysFlag: 是生产者相关的信息标识, 具体的生产逻辑可以看相关代码。
8B 的消息创建时间。
8B 的消息生产者的 host。
8B 的消息存储时间。
8B 的消息存储机器的 host。
4B 表示重复消费次数。
8B 的消息事务相关偏移量。
4B 表示消息体的长度。
动态消息体:依赖上一个字段
1B 表示 Topic 的长度: 因此 Topic 的长度最多不能超过 127B, 超过的话存储会出错 (有前置校验) 。
动态大小的 Topic 的内容: 存储 Topic 的具体值。 因为 Topic 不是固定长度, 所以这里 所占的字节是不固定的, 和前一个表示 Topic 长度的字节的值相等。
2B properties 的长度: properties 是创建消息时添加到消息中的。 此部分内容是动态的, 故需要一个表示 properties 长度的值。
动态大小的 properties 的内容: 和前面的 2B properties 长度的值相同, 存储具体消息里 的 properties。
4. ConsumeQueue 文件
①ConsumeQueue 文件结构

RocketMQ 采用 CommitLog + ConsumeQueue 的二级存储架构解决消息检索效率问题。所有消息原始数据统一写入全局唯一的 CommitLog 文件,但基于主题的订阅模式要求高效检索能力。为此,系统为每个主题的每个队列独立创建一组 ConsumeQueue 文件,专用于存储消息元数据。
ConsumeQueue 采用定长条目设计(每条 20B),包含 8B CommitLog 偏移量(定位消息物理位置)、4B 消息体大小、8B 标签哈希值(tagCode)。此类小文件专为辅助检索设计,不存储具体消息内容,通过偏移量直接映射至 CommitLog 实现高效查找。存储路径为
$HOME/store/consumequeue/{topic}/{queueId}/{fileName},实现主题与队列维度的精细化管理。
②ConsumeQueue 文件组成
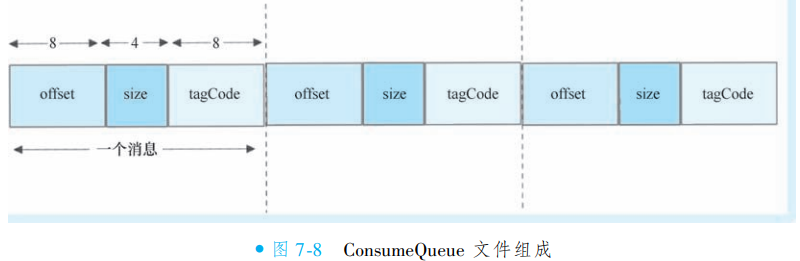
ConsumeQueue 采用固定大小条目设计,每条消息仅存储 20B 元数据:前 8B 记录消息在 CommitLog 中的物理偏移量(offset),中间 4B 存储消息体大小,后 8B 保存消息标签的哈希值(tagCode)。该结构如图 7-8 所示,极大压缩存储空间。
单个 ConsumeQueue 文件默认包含 30 万条消息(约 5.72MB),所有条目定长排列。此设计使 ConsumeQueue 可像数组一样实现随机访问,支持二分查找等算法快速定位指定 offset 的消息,显著提升消息检索效率。
5. IndexFile 文件
①IndexFile 概览
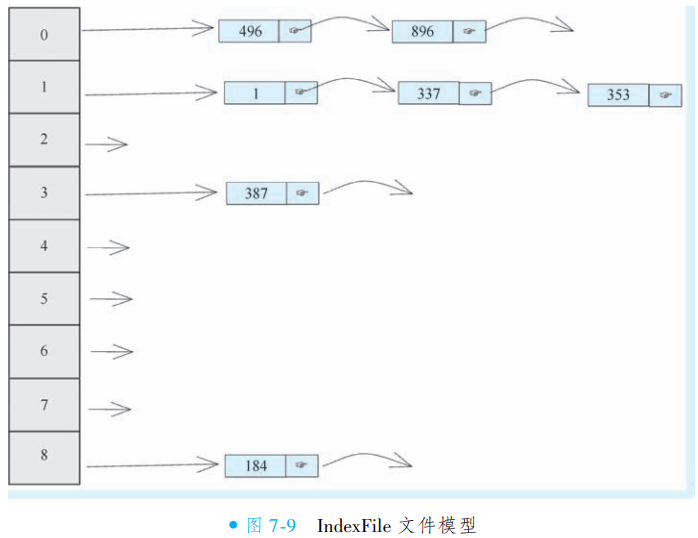
RocketMQ 提供两种消息搜索能力:
MessageID 搜索:服务端 MessageID 由 Broker 标识与 CommitLog 偏移量(offset)组合生成,可直接反解 offset 并定位至 CommitLog 文件快速检索消息内容。
Key 搜索:针对业务字段(如订单号)的搜索需求,RocketMQ 设计了 IndexFile 索引文件。其模型类似 Java HashMap,由固定数量 Slot 组成,采用拉链法解决哈希冲突(结构见图 7-9),通过哈希机制高效匹配业务关键词与消息物理位置。
②IndexFile 文件结构
IndexFile 文件统一存储于
$HOME/store/index/目录下,其文件名采用创建时的时间戳命名(如20211204094647480),随时间推移形成一组按时间排序的文件(例如20211204094647480、20211205094647480、20211206094647480等)。每个 IndexFile 为定长结构,容量上限为 500 万个 Hash 槽和 2000 万个索引项。当数据量超过单个文件承载能力时,系统自动创建新索引文件继续存储。此设计导致相同 Hash 值的消息可能分布在不同索引文件中,需跨文件检索以保障查询完整性。
③IndexFile 文件组成
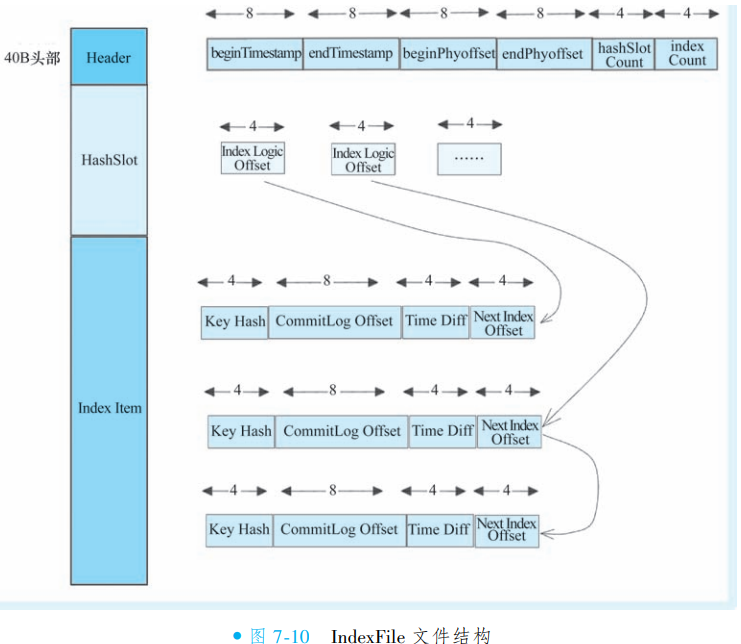
IndexFile 为定长结构文件(约 400MB),由三部分组成:
40B 文件头(Header):含 6 个关键字段——最早/最晚消息存储时间(begin/endTimestamp)、最小/最大物理偏移量(begin/endPhyoffset)、最大哈希槽数(hashSlotCount)和已使用索引数(indexCount);
500 万个哈希槽(HashSlot):每个槽占 4B,存储索引项的逻辑下标(数量可通过 Broker 配置 maxHashSlotNum 调整);
2000 万个索引项(Index Item):每项占 20B,包含消息 Key 的哈希值(Key Hash)、CommitLog 物理偏移量(用于定位消息)、时间差(Time Diff,秒级精度)及链表下一项的逻辑下标(Next Index Offset)。
哈希槽与索引项数量均可配置,整体通过逻辑下标计算绝对偏移量实现快速定位。索引项采用链表结构解决哈希冲突,支持基于 Key 哈希或时间范围的高效消息检索,其结构如图 7-10 所示。
八. RocketMQ消息高可靠的设计
1. 消息中间件如何做到消息高可靠
①消息中间件三个核心环节
实现消息高可靠性需涵盖三个核心环节:
发送高可靠:确保消息成功送达消息中间件,规避网络故障、Broker不可用等异常导致的发送失败;
存储高可靠:消息中间件需持久化存储消息,避免因宕机或磁盘损坏造成数据丢失;
消费高可靠:保障消息投递消费者后能被成功处理,防止Broker误删未实际消费的消息。
这些环节中的任一异常均可能破坏系统可靠性,需通过针对性设计全面防护。
②消息中间件的高可靠承诺
实现消息高可靠需满足三个核心设计原则:
生产者可靠确认:若消息中间件确认消息接收成功,则后续存储与消费流程均可靠,生产者无需再介入;
存储持久化保障:消息一旦成功存储,Broker 需保证其在被成功消费前不因任何异常(如宕机、磁盘故障)而丢失;
消费至少一次:若消费者因异常未能成功处理消息,Broker 需确保消息至少被投递并消费一次。
满足上述条件即可认定消息系统具备高可靠性,有效覆盖发送、存储、消费全链路风险。
2. 消息生产的高可靠
①消息生产过程可能遇到的异常
/**
* 支付消息处理流程说明:
* 假设现在在处理一个支付的消息,这个支付消息消费成功后,
* 需要发送一个支付成功的事件,以便积分系统增加用户的积分。
*
* 代码可能是以下这样(片段):
* String sql = "update t_pay_order set order_status='SUCCESS' where order_no='12345678'";
* stmt.executeUpdate(sql);
* sendMQMessage(myMsg);
*
* 这里可能遇到的异常如下:
* 1)如果数据库执行成功了,但这时候服务重启了
* 2)服务正常,但是发送消息到Broker的时候,那一台Broker挂了
* 3)服务正常,但是发送消息到Broker的时候消息超时,或者网络出现了异常无法发送
*/②应对消息生产的异常
关于第一个异常, 常见的解决思路是用消息表去存储待发送的消息, 直到消息发送成功 后才删除/更新消息表数据; RocketMQ还提供了很强大的事务消息功能去解决这个场景。
关于第2个和第3个异常, 实际上都是一类问题, 就是发送消息的指令已经发出去了, 但 是由于各种异常没有得到一个明确的成功响应。针对消息发送过程中的异常场景,核心处理原则是:未收到明确成功响应则必须重试。消息重复可通过去重手段处理,但消息丢失无法挽回。RocketMQ 生产者客户端提供
retryTimesWhenSendFailed参数支持内置重试机制,若仍失败(如超时或 Broker 不可用),则需应用层自行处理——常见方案包括将消息持久化至数据库后异步重试,或启用独立线程持续重试。
3. 消息消费的高可靠
消息消费的高可靠性,与 RocketMQ 的消费进度管理及 ACK(确认)机制密不可分。事实上,消费进度管理和 ACK 机制的设计初衷,正是为了解决消息消费过程中的高可靠性问题。
①消费高可靠的保证
RocketMQ 通过 ACK 确认机制保障消息消费的高可靠性:若未收到消费者对某条消息的成功确认(ACK),系统不会将其标记为已消费。只要消费者在线,该消息将持续被尝试投递,确保最终成功处理。
重新投递时,RocketMQ 会为消息附加延迟级别(非立即重试)。这是因为消费失败多由外部资源异常(如数据库访问失败、Redis 故障或下游系统报错)引起,此类问题通常需要一定时间恢复。延迟投递为外部资源提供了自动恢复的时间窗口,避免无效的即时重试,提升系统整体容错能力。
②消费高可靠的实践建议
/**
* RocketMQ 消息监听器实现示例
* <p>
* 虽然 RocketMQ 已经对消息消费的高可靠性做了很好的支持,但是笔者总还是能看到非常多
* 的人为原因导致"消息丢失"的问题。最常见的问题便是很多人采取以下的消费模板。
*/
public class ReliableMessageListener implements MessageListenerConcurrently
{
/**
* 消息消费处理方法
* 这类开发模板很可能是从类似 RabbitMQ 这类消息中间件迁移到 RocketMQ 时顺手带过来的。
* 在 RabbitMQ 的消费代码里,开发者是需要手动调用 ACK 方法的,否则消息会处于 UNACK 状态,
* 达到一定程度,这个消费者就无法再消费消息了,所以开发者可能会 catch 住异常,也把消息给 ACK 掉。
* <p>
* 实际上这种消费的方式在 RabbitMQ 也不是很好,因为这样的异常相当于消息消费失败了,
* 但是直接当作成功处理了。在 RabbitMQ 的场景下,要很好地处理这类错误,开发者的确需要 catch 异常,
* 但是针对异常的消息是需要做更多的错误处理的,例如把消息暂存到某个地方,后面再消费等。
* <p>
* RocketMQ 把错误处理内置到 API 级别中,也就是说 RocketMQ 在各种消费失败的场景
* 都能贴心地帮你做重新消费。但前提是能正确地告诉 RocketMQ,这条消息消费失败了。
*
* @param msgs 消息列表
* @param context 消费上下文
* @return 消费状态
*/
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context)
{
try
{
// 处理消息的业务逻辑
processMessages(msgs);
// 消息处理成功,返回成功状态
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
} catch (Exception ex)
{
/**
* 所以上面的 catch 代码后直接 return ConsumeConcurrentlyStatus.CONSUME_SUCCESS
* 的处理就画蛇添足了,实际上开发者只需要任由这个异常往外抛出即可。
* 当然了,如果觉得这个异常不加处理就抛出不是很好,也可以 catch 住这个异常
* 返回 ConsumeConcurrentlyStatus.RECONSUME_LATER,效果也是一样的。
*/
// 正确做法:返回重新消费状态,让 RocketMQ 自动重试
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
// 或者直接抛出异常,效果相同
// throw new RuntimeException("消息消费失败", ex);
}
}
/**
* 处理消息的核心业务逻辑
*
* @param msgs 消息列表
*/
private void processMessages(List<MessageExt> msgs)
{
// 在这里实现具体的消息处理逻辑
// 例如:数据库操作、业务计算、调用外部服务等
for (MessageExt msg : msgs)
{
System.out.println("处理消息: " + new String(msg.getBody()));
// 模拟业务逻辑处理
}
}
}4. 消息存储的高可靠
①消息刷盘策略
RocketMQ 通过 CommitLog 文件持久化存储消息。当 Broker 所在机器发生重启等故障时,因消息已完成持久化,通常不会丢失。
其持久化机制依赖操作系统的文件映射(Memory-Mapped Files)技术:消息成功写入仅保证进入操作系统的 page cache,未必立即落盘。为此 RocketMQ 提供两种刷盘策略:
同步刷盘(SYNC_FLUSH):消息写入 page cache 后立即调用 fsync 强制刷盘,生产者收到成功响应即确认消息已持久化,可靠性最高但性能较低;
异步刷盘(ASYNC_FLUSH):消息写入 page cache 即返回成功,依赖操作系统异步刷盘或 RocketMQ 定时强制刷盘。此策略下 Broker 异常重启可能丢失未刷盘消息,但性能更优。
实际应用中,异步刷盘因更好的吞吐表现更为常用,需根据业务对可靠性及性能的要求权衡选择。
②消息同步策略
RocketMQ 通过主从架构解决单点故障问题,确保即使 Broker 磁盘损坏仍能维持消息高可靠。一个 Master 节点可挂载多个 Slave 节点,数据完全一致但角色分工明确:Master 专责处理写入请求,Slave 负责数据同步与读请求处理。
RocketMQ 提供两种数据同步策略:
ASYNC_MASTER(异步复制):消息写入 Master 即返回成功,Slave 通过后台线程异步同步数据(按 CommitLog 文件顺序同步);
SYNC_MASTER(同步双写):写入线程需等待至少一个 Slave 同步完成(上报物理 offset 与 Master 一致)后才返回响应,确保消息至少存在于两个 Broker。
推荐采用 SYNC_MASTER + ASYNC_FLUSH 组合:同步双写保障跨节点冗余,异步刷盘平衡性能。此配置下,生产者收到成功响应即表示消息已写入两个 Broker 的 Page Cache,在可靠性与吞吐量间取得最优平衡。
③消息的读写高可用
RocketMQ 通过多副本机制实现读服务高可用:当 Master 节点发生故障时,Slave 节点可立即接管读请求,确保消息消费不中断。一旦消息成功发送至 Master,即使出现单点故障,Slave 仍能可靠投递消息至消费者,完整保障消息传递链路的可靠性。
④消息高可靠小结
RocketMQ 通过三重机制确保消息传递的高可靠性:
生产者重试机制:当出现 Broker 单点故障或网络异常时,生产者会自动重试发送,直到收到 Broker 的成功响应,确保消息投递成功。
主从同步与持久化策略:支持主从架构部署,Slave 节点实时同步数据避免单点故障;同时提供同步/异步刷盘策略,允许开发者在性能与可靠性之间灵活权衡。
消费端至少一次投递:采用 at least once 消费模式,除非消费者明确确认消费成功,否则消息会持续投递(死信主题除外),确保消息不被遗漏。
⑤多副本的DLedger
RocketMQ 通过多副本机制实现读服务高可用:当 Master 节点发生故障时,Slave 节点可立即接管读请求,确保消息消费不中断。然而在较长时间内,RocketMQ 的 Slave 节点不具备自动升级为 Master 的能力,这意味着写服务在 Master 故障时会中断。
为解决写服务高可用问题,RocketMQ 支持部署多个 Master 节点组(Broker Group),同一 Topic 可在不同 Broker 上同时提供读写服务。当某个 Master 故障时,生产者会自动切换到其他可用 Master,保障写服务连续性。
从 4.5.0 版本开始,RocketMQ 引入基于 Raft 协议的 Dledger 多副本架构,提供自动选主能力。使用 Dledger 模式后,CommitLog 具备选举复制功能,可实现主从自动切换。但需注意:生产环境中大型 Dledger 存储案例较少,且 5.x 版本对多副本架构有重大升级,采用此方案需关注升级兼容性。