
一. 变量和简单数据类型
1. 变量命名
定义:变量是可以被赋值的标签。
只能包含字母丶数字和下划线,只能以字母丶下划线开头。
不能使用关键字。
2. 字符串
定义:字符串是一系列字符,用引号引起的都是字符串,可以是双引号,单引号。
可以用'+'号连接两个字符串
字符串下标和切片(同列表)
>>> spam = 'Hello world!'
>>> spam[0]
'H'
>>> spam[4]
'o'
>>> spam[-1]
'!'
>>> spam[0:5]
'Hello'
>>> spam[:5]
'Hello'
>>> spam[6:]
'world!'
字符串的 in 和 not in 操作符
>>> 'Hello' in 'Hello World'
True
>>> 'cats' not in 'cats and dogs'
False### 在字符串中使用变量
# 在字符串中使用变量的值,在左引号前加上字母f, 再将要插入的变量放到花括号内
# 这种字符串称为f字符串, f是format(设置格式)的简写
# 这样不用用'+'号链接字符串
# eg:1
first_name='ada'
last_name='bob'
full_name=f"{first_name} {last_name}"
print(full_name)# ada bob
print('\n')
# eg:2
print(f"{first_name} {last_name}")# ada bob
print("\n")
# eg:3
print(f"Hello {full_name.title()}")#Hello Ada Bob“转义字符” 让你输入一些字符,它们用其他方式是不可能放在字符串里的。转义
字符包含一个倒斜杠(\),紧跟着是想要添加到字符串中的字符。(尽管它包含两个字符,
但大家公认它是一个转义字符。)
\' 单引号
\" 双引号
\t 制表符
\n 换行符
\\ 倒斜杠
### 换行\n和空白制表符
print("12\t-\n34")
# 12 -
# 34
# 检查A是否在不在B串中
if A in B:
if A not in B:
原始字符
可以在字符串开始的引号之前加上 r,使它成为原始字符串。“原始字符串”完
全忽略所有的转义字符,打印出字符串中所有的倒斜杠。
>>> print(r'That is Carol\'s cat.')
That is Carol\'s cat.
三重引号
虽然可以用\n转义字符将换行放入一个字符串,但使用多行字符串通常更容易。
在 Python 中,多行字符串的起止是 3 个单引号或 3 个双引号。“三重引号”之间的
所有引号、制表符或换行,都被认为是字符串的一部分。Python 的代码块缩进规则
不适用于多行字符串。
print('''Dear Alice,
Eve's cat has been arrested for catnapping, cat burglary, and extortion.
Sincerely,
Bob''')
Dear Alice,
Eve's cat has been arrested for catnapping, cat burglary, and extortion.
Sincerely,
Bob
多行注释
虽然井号字符(#)表示这一行是注释,但多行字符串常常用作多行注释。下
面是完全有效的 Python 代码:
"""This is a test Python program.
Written by Al Sweigart al@inventwithpython.com
This program was designed for Python 3, not Python 2.
"""
def spam():
"""This is a multiline comment to help
explain what the spam() function does."""
print('Hello!')
### 删除空白
str=" python "
print("="+str.lstrip()+"=\n")
# 删除左空白 =python =
print("="+str.rstrip()+"=\n")
# 删除右空白 = python=
print("="+str.strip()+"=\n")
# 删除两端空白 =python=### 移除前后缀, 没有则返回原串
str="https:www.wc.com"
print(str.removeprefix("https:"))# 移除前缀 www.wc.com
print(str.removesuffix(".com")+'\n')# 移除后缀 https:www.wc### 使用方法修改字符串大小写
name='ailic bob'
# title()是方法,以首字母大写方式输出字符串
print(name.title()) #Ailic Bob
print(name.upper())# 大写方式输出 AILIC BOB
print(name.lower())# 小写方式输出 ailic bob
isupper()和 islower()
如果字符串至少有一个字母,并且所有字母都是大写或小写,isupper()和
islower()方法就会相应地返回布尔值 True。否则,该方法返回 False。
>>> spam = 'Hello world!'
>>> spam.islower()
False
>>> spam.isupper()
False
>>> 'HELLO'.isupper()
True
>>> 'abc12345'.islower()
True
>>> '12345'.islower()
False
isalpha()返回 True,如果字符串只包含字母,并且非空;
isalnum()返回 True,如果字符串只包含字母和数字,并且非空;
isdecimal()返回 True,如果字符串只包含数字字符,并且非空;
isspace()返回 True,如果字符串只包含空格、制表符和换行,并且非空;
istitle()返回 True,如果字符串仅包含以大写字母开头、后面都是小写字母的单词。
>>> 'hello'.isalpha()
True字符串方法 startswith()和 endswith()
startswith()和 endswith()方法返回 True,如果它们所调用的字符串以该方法传入
的字符串开始或结束。否则,方法返回 False。
>>> 'Hello world!'.startswith('Hello')
True
>>> 'Hello world!'.endswith('world!')
True
字符串方法 join()和 split()
如果有一个字符串列表,需要将它们连接起来,成为一个单独的字符串,join()
方法就很有用。join()方法在一个字符串上调用,参数是一个字符串列表,返回一个
字符串。返回的字符串由传入的列表中每个字符串连接而成。
调用 join()方法的字符串,被插入到列表参数中每个字符串的中间
>>> ', '.join(['cats', 'rats', 'bats'])
'cats, rats, bats'
split()方法做的事情正好相反:它针对一个字符串调
用,返回一个字符串列表。
>>> 'My name is Simon'.split()
['My', 'name', 'is', 'Simon']
默认情况下,字符串'My name is Simon'按照各种空白字符分割,诸如空格、制表
符或换行符。这些空白字符不包含在返回列表的字符串中。也可以向 split()方法传入一
个分割字符串,指定它按照不同的字符串分割。
>>> 'MyABCnameABCisABCSimon'.split('ABC')
['My', 'name', 'is', 'Simon']
用 rjust()、ljust()和 center()方法对齐文本
rjust()和 ljust()字符串方法返回调用它们的字符串的填充版本,通过插入空格来
对齐文本。这两个方法的第一个参数是一个整数长度,用于对齐字符串。
>>> 'Hello'.rjust(10)
' Hello '
'Hello'.rjust(10)是说我们希望右对齐,将'Hello'放在一个长度为 10 的字符串中。
'Hello'有 5 个字符,所以左边会加上 5 个空格,得到一个 10 个字符的字符串,实现
'Hello'右对齐。
rjust()和 ljust()方法的第二个可选参数将指定一个填充字符,取代空格字符。
>>> 'Hello'.ljust(20, '-')
'Hello---------------'
center()字符串方法与 ljust()与 rjust()类似,但它让文本居中,而不是左对齐或
右对齐。
>>> 'Hello'.center(20, '=')
'=======Hello========'
用 pyperclip 模块拷贝粘贴字符串
pyperclip 模块有 copy()和 paste()函数,可以向计算机的剪贴板发送文本,或从
它接收文本。将程序的输出发送到剪贴板,使它很容易粘贴到邮件、文字处理程序
或其他软件中。pyperclip 模块不是 Python 自带的。要安装它
>>> import pyperclip
>>> pyperclip.copy('Hello world!')
>>> pyperclip.paste()
'Hello world!'
如果你的程序之外的某个程序改变了剪贴板的内容,paste()函数就会返
回它。例如,如果我将这句话复制到剪贴板,然后调用 paste()
>>> pyperclip.paste()
'For example, if I copied this sentence to the clipboard and then called
paste(), it would look like this:'3. 数
整数:+,-,*, /,**(乘方),(), %
print(2+3)
print(2-3)
print(2*3)
print(2/3)
print(2**3)
print(2+3-2)
# 5
# -1
# 6
# 0.6666666666666666
# 8
# 3
# 数很大时可以用下划线分组
bigNumber=14_000_000
print(bigNumber) # 14000000
# 同时给多个变量赋值
x, y, z=0, 0.1, -1
print(x)
print(y)
print(z)
# 0
# 0.1
# -1
str(xxx)、int(xxx)和 float(xxx)函将xxx转化为对应类型浮点数:带小数点
print(0.2+0.3) # 0.500003, python会找到一种最精确的方式,无需关高精度项(多余项)
# 任意两个数相除,结果总是浮点数
print(4/2) #2.0
# 只要有一个操作数是浮点数,结果总是浮点数
print(1+2.0) # 3.0常量:在程序整个生命周期都保持不变的数,Python无内置常量类,需将某个变量全部大写则为常量
MAX_NUMBER=1000
print(MAX_NUMBER) #1000注释:“#” 号
import this(python编写指导原则)
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!二. 列表
1. 是什么
列表由一系列按特定顺序排列的元素组成。用"[]"表示列表, 用","分割其中元素
list=[1, 'wxz', 2.0]
print(list) # [1, 'wxz', 2.0]
#访问列表元素, 指明索引即可,索引从0开始
print(list[0]) #1
print(list[1].title()) # Wxz
# -1表示返回最后一个元素, -2表示倒数第二个
print(list[-1]) # 2.0
print(list[-2]) # wxz
# 可以像其他变量一样使用列表中各个值
message=f"My Name is {list[1].title()}"
print(message) # My Name is Wxz2. 修改,添加和删除元素
list=['honda', 'yamaha', 'suzuki']
# 修改元素
print(list) # ['honda', 'yamaha', 'suzuki']
list[0]="ducati" # 指定索引去修改
print(list) # ['ducati', 'yamaha', 'suzuki']
# 添加元素
## 在列表末尾添加元素:append
list.append("wcf")
print(list) # ['ducati', 'yamaha', 'suzuki', 'wcf']
## 在列表中插入元素,需要指定索引和值:insert, 插入位置后的元素会向后移动
list.insert(1, "zxc")
print(list) # ['ducati', 'zxc', 'yamaha', 'suzuki', 'wcf']
# 删除元素
## 使用 del语句 删除元素, 需要指明索引,删除位置后的元素会前移
del list[2]
print(list) # ['ducati', 'zxc', 'suzuki', 'wcf']
## 使用 pop() 方法删除元素, 删除末尾元素并弹出
name=list.pop()
print(name) # wcf
print(list) # ['ducati', 'zxc', 'suzuki']
## 使用 pop() 删除任意位置元素,只需加索引即可
name=list.pop(1)
print(name) # zxc
print(list) # ['ducati', 'suzuki']
## 使用 remove(), 删除指定值
list.remove('suzuki')
print(list) # ['ducati']3. 管理列表
list=['honda', 'yamaha', 'suzuki']
# 使用 sort()方法 对列表永久排序
print(list) # ['honda', 'yamaha', 'suzuki']
list.sort()
print(list) # ['honda', 'suzuki', 'yamaha']
list.sort(reverse=True) # 传入参数,则按照字母顺序相反顺序排序
print(list) # ['yamaha', 'suzuki', 'honda']
# 使用 sorted()函数 临时排序,返回临时排好序的列表
print(sorted(list)) # ['honda', 'suzuki', 'yamaha']
print(list) # ['yamaha', 'suzuki', 'honda']
list.sort() #复原
print(list) # ['honda', 'suzuki', 'yamaha']
print(sorted(list, reverse=True)) # 反顺序:['yamaha', 'suzuki', 'honda']
# 反向打印列表, reverse()
print(list) # ['honda', 'suzuki', 'yamaha']
list.reverse()
print(list) # ['yamaha', 'suzuki', 'honda']
# 确定列表长度, len()函数, 返回当前长度
print(len(list)) # 34. 操作列表
list=['honda', 'yamaha', 'suzuki']
# 循环打印列表
## for循环后,没有缩进的代码都只会执行一次,每行缩进的代码都是循环内的
## :后是循环体
for name in list:
print(name)
print("---")
print("结束")
# honda
# ---
# yamaha
# ---
# suzuki
# ---
# 结束
# print("1")
# IndentationError: unexpected indent, 上述代码不需要缩进,会语法报错
用index()方法在列表中查找值
列表值有一个 index()方法,可以传入一个值,如果该值存在于列表中,就返回它
的下标。如果该值不在列表中,Python 就报 ValueError
spam = ['hello', 'hi', 'howdy', 'heyas']
spam.index('hello') # 0
用 list()和 tuple()函数来转换类型
函数 list()和 tuple()将返
回传递给它们的值的列表和元组版本
tuple(['cat', 'dog', 5])
('cat', 'dog', 5)
list(('cat', 'dog', 5))
['cat', 'dog', 5]
list('hello')
['h', 'e', 'l', 'l', 'o']
copy 模块的 copy()和 deepcopy()函数
在处理列表和字典时,尽管传递引用常常是最方便的方法,但如果函数修改了
传入的列表或字典,你可能不希望这些变动影响原来的列表或字典。要做到这一点,
Python 提供了名为 copy 的模块,其中包含 copy()和 deepcopy()函数。第一个函数
copy.copy(),可以用来复制列表或字典这样的可变值,而不只是复制引用。
>>> import copy
>>> spam = ['A', 'B', 'C', 'D']
>>> cheese = copy.copy(spam)
>>> cheese[1] = 42
>>> spam
['A', 'B', 'C', 'D']
>>> cheese
['A', 42, 'C', 'D']
如果要复制的列表中包含了列表,那就使用 copy.deepcopy()函数来代替。列表推导式
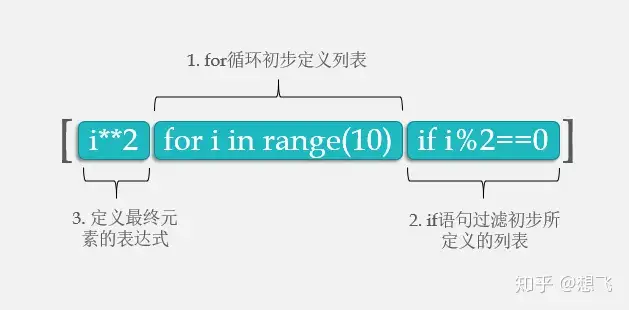
创建列表
# 使用 range()函数 生成数列, range()返回生成的数列
## range(开始,结束)
## range(6), 一个参数,则会生成0~5
for v in range(1, 5):
print(v)
# 1
# 2
# 3
# 4
# 并不会生成5,生成从1开始到5结束,所以没有5, 若想有5则range(1, 6)
# 使用range()创建数值列表, 用list()将range()的结果转化为列表
# range(2, 11, 2), 第三个参数为步长, 输出1~10内的偶数
list=list(range(2, 11, 2))
print(list) # [2, 4, 6, 8, 10]
# 生成1~10的平方的数列
squares=[]
for v in range(1, 11):
# square=v**2
# squares.append(square)
squares.append(v**2)
print(squares) # [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
# 列表推导式,如下:
squares=[v**2 for v in range(1, 11)]
print(squares) # [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
# 对数值列表统计计算
v=[1, 2, 3]
print(min(v))
print(max(v))
print(sum(v))
# 1
# 3
# 65. 使用列表的一部分(切片)
创建切片则要指定切片的第一个元素和最后一个元素索引(不含最后一个), 若没有指定第一个索引,则从头开始;若没有指定第二个索引则,直到末尾;负数索引同样生效;也可以指定步长
players=["a", "b", "c", "d"]
print(players[0:3]) # ['a', 'b', 'c']
print(players[:2]) # ['a', 'b']
print(players[2:]) # ['c', 'd']
print(players[-2:]) # ['c', 'd']
print(players[0::2]) # ['a', 'c'], 步长为2
# 遍历切片,结合for
for name in players[-2:]:
print(name.title())
# C
# D
# 复制列表:创建一个包含整个列表的切片
p2=players[:]
print(p2) # ['a', 'b', 'c', 'd']
p3=players #这种方式p3和players指向同一列表,并不是复制了一个新的6. 元组
列表适合存储程序运行期间可能变化的数据集,列表是可以修改的。Python将不能修改值称为不可变的,将不可变的列表称为元组。
元组用圆括号而不是方括号来标识。
digits=(200, 50)
print(digits)
print(digits[0])
# (200, 50)
# 200
# 遍历元组所有元素
for v in digits:
print(v)
# 200
# 50
# 修改元组变量
## 虽然不能修改元组的元素,但是可以给表示元组的变量赋值
digits=(100, 200)
print(digits) # (100, 200)三. if语句
if语句
if 条件测试 :
同样以缩进判断是否在同一代码块
list=["cat", "tiger"]
# ==, !=, >, <, >=, <=
for name in list:
if name=="cat":
print("1") # 1
# not运算符,作用于布尔值或者表达式
# 检查多个条件:and, or
age=10
if age>=10 and age<=11:
print("yes") # yes
if age>10 or age <20:
print("yes") # yes
# 检查特定值在不在列表中:关键字 in, not in
foods=["jiaoZi", "xiGua"]
if "xiGua" in foods:
print("true") # true
if "xiangJiao" not in foods:
print("不在") # 不在if-else语句:
if-elif-else语句:
list=["cat", "tiger"]
for name in list:
if name!="cat":
print("yes")
else:
print("no")
# no
# yes
age=1
if age>1:
print(">1")
elif age>2:
print(">2")
elif age==1:
print("==1") # ==1
else:
print("no")使用if语句处理列表
list=["cat", "tiger"]
# 确定列表非空, 将列表名用作条件表达式时,若列表不空
# 返回True, 否则返回False
if list:
print("full") # full
else:
print("kong")四. 字典
字典:键值对(kay:value),每个键都和一个值关联,值可以是python中的任意对象。在python, 用 {} 表示字典。
集合:s={'a', 'b', 'c'}
curd
# 创建:alien={}, 空字典
alien={'color':'green', 'points':5}
print(alien) # {'color': 'green', 'points': 5}
# 访问
print(alien['color']) # green, 键不存在会报错
#使用get()方法访问, 第一个参数指定键,第二个参数指定键不存在时返回的值(可选),
# 第二个不指定将返回None
print(alien.get('w', 'no')) # no
# 添加
alien['px']=0
alien['py']=0
print(alien) # {'color': 'green', 'points': 5, 'px': 0, 'py': 0}
# 修改
alien['color']='red'
print(alien) # {'color': 'red', 'points': 5, 'px': 0, 'py': 0}
# 删除:del语句,指定字典名和删除的键
del alien['px']
del alien['py']
print(alien) # {'color': 'red', 'points': 5}遍历字典
alien={'color':'green', 'points':5}
# 遍历所有的键值对
for key, value in alien.items(): # item()返回一个键值对列表
print(f"Key:{key} Value:{value}")
# Key:color Value:green
# Key:points Value:5
# 遍历字典中所有键
for k in alien.keys(): # keys()会返回一个列表或 for k in alien: 变量字典名时默认遍历所有键
print(f"Key:{k}")
# Key:color
# Key:points
if 'color' in alien.keys(): # in, not in
print("yes") # yes
# 变量字典中所有值: values()方法, 返回一个值列表
for v in alien.values():
print(f"Value:{v}")
# Value:green
# Value:5
# 可以使用集合剔除值中重复元素, set()函数创建一个集合
for v in set(alien.values()):
print(f"Value:{v}")
# Value:green
# Value:5
## 集合:一对{}来创建集合
s={'a', 'b', 'c'}
# 按特定顺序遍历字典中所有键
## 默认按插入顺序遍历, 但可以使用sorted()函数对键进行排序
for k in sorted(alien.keys()):
print(f"Key:{k}")
# Key:color
# Key:points
setdefault()方法
setdefault()方法提供了一种方式,在一行中完成这件事。传递给该方法的第一
个参数,是要检查的键。第二个参数,是如果该键不存在时要设置的值。如果该键
确实存在,方法就会返回键的值。
>>> spam = {'name': 'Pooka', 'age': 5}
>>> spam.setdefault('color', 'black')
'black'
>>> spam
{'color': 'black', 'age': 5, 'name': 'Pooka'}
>>> spam.setdefault('color', 'white')
'black'
>>> spam
{'color': 'black', 'age': 5, 'name': 'Pooka'}字典嵌套
# 字典列表
alien1={'id':1, 'name':'a'}
alien2={'id':2, 'name':'b'}
aliens=[alien1, alien2]
for alien in aliens:
print(alien)
# {'id': 1, 'name': 'a'}
# {'id': 2, 'name': 'b'}
# 在字典中存储列表
pizza={
'crust':'thick',
'toppings':['mushrooms', 'banana'],
}
print(pizza) # {'crust': 'thick', 'toppings': ['mushrooms', 'banana']}
print(f'大小:{pizza["crust"]}')
for zucheng in pizza['toppings']:
print(f"zucheng:{zucheng}")
# 大小:thick
# zucheng:mushrooms
# zucheng:banana
# 字典存储字典
users={
'Bob':{
'first':'a',
'last':'b'
},
'Alice':{
'f':'c',
'l':'d'
}
}
print(users) # {'Bob': {'first': 'a', 'last': 'b'}, 'Alice': {'f': 'c', 'l': 'd'}}五. 集合
集合(set)是一个无序的不重复元素序列。
集合中的元素不会重复,并且可以进行交集、并集、差集等常见的集合操作。
可以使用大括号 { } 创建集合,元素之间用逗号 , 分隔, 或者也可以使用 set() 函数创建集合。
set1 = {1, 2, 3, 4} # 直接使用大括号创建集合
set2 = set([4, 5, 6, 7]) # 使用 set() 函数从列表创建集合
添加
s.add(x)
s.update(x) # 参数可以是列表,元组,字典等,语法格式如下
移除
s.remove(x) # 将元素 x 从集合 s 中移除,如果元素不存在,则会发生错误
s.discard(x) # 如果元素不存在,不会发生错误
len(s) #计算集合 s 元素个数。
s.clear() # 清空集合 s。
x in s # 判断元素是否在集合中存在六. 用户输入和while循环
1. input()函数
# input()第一个参数,可以编写提示
name=input('please enter youer name:')
print(name) # 上面键入的
# input()自动将输入解读为字符串,可用int()函数将其化为数值
age=input('please enter youer age: ')
age=int(age)
if age>=18:
print('true')2. while循环
whie 条件:
缩进循环体
whie, break, continue
## 当num==5时结束
num=0
flag=True
while flag:
num+=1
if num==5:
print(num) # 5
break
## 输出flag为偶数时,当num>7,flag=false结束
num=0
while flag:
num+=1
if num%2==0:
print(num) # 2 4 6 8
if num>7:
flag=False七. 函数
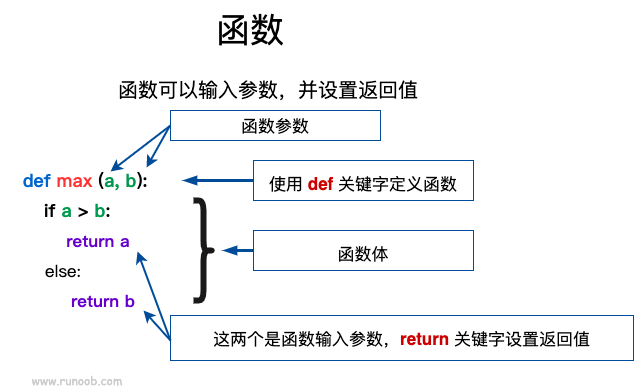
# 实参:调用时的传入,形参:函数定义时参数位置的参数
## 位置实参:基于顺序传入
def draw(animal_type, pet_name):
print(f"类型:{animal_type}")
print(f"名字:{pet_name}")
draw('dog', 'cc')
# 类型:dog
# 名字:cc
## 关键字实参:无需考虑实参顺序
draw(pet_name='ww', animal_type='cat')
# 类型:cat
# 名字:ww
# 默认值:优先列出没有默认值的形参,再列出有默认值的形参
## 编写函数时,可以给形参指定默认值,若函数调用时传递了实参则使用实参
## 否则使用默认值
def write(animal_type, pet_name='asa'):
print(f"类型:{animal_type}")
print(f"名字:{pet_name}")
write('dog')
# 类型:dog
# 名字:asa
# 等效的函数调用
## 鉴于可以混合使用位置实参,关键字实参,和默认值,通常有多种等效函数调用方式
# 返回值
## 可以返回简单值字典,列表...# 传递列表
def test(list):
list[0]='c'
for l in list:
print(l)
list=['a', 'b']
test(list)
print(list)
# c
# b
# ['c', 'b']
# 在函数中对列表做的修改是永久的
# 禁止函数修改列表:通过切片创造副本
list[0]='a'
print(list)
test(list[:])
print(list)
# ['a', 'b']
# c
# b
# ['a', 'b']
# 传递任意数量的实参:*参数名, 这样传递的是一个元组
def test1(*a):
print(a)
test1('a', 'b') # ('a', 'b')
# 传递任意数量的键值对实参:**参数名, 传递的是字典user_info
def build(name, **user_info):
user_info['name']=name
return user_info
user=build('zxc', loc='xxx', num='123') # {'loc': 'xxx', 'num': '123', 'name': 'zxc'}
print(user)模块:视为扩展名为.py的文件
pizza.py模块
def make_pizza():
return '榴莲披萨'导入模块
# 导入:import 模块名
# 调用:模块名.函数名
import pizza
name=pizza.make_pizza()
print(name) # 榴莲披萨导入特定函数
# 导入:from 模块名 import 函数1,函数2
# 导入所有函数:from 模块名 import *
# 调用:函数名
from pizza import make_pizza
name=make_pizza()
print(name) # 榴莲披萨使用as给模块和函数指定别名
模块:import 模块名 as 模块别名
函数;from 模块名 import 函数名 as 函数别名八. 类
面向对象OOP, 定义类,可以根据类创建实例对象。
创建类
class ClassName:
<statement-1>
.
.
.
<statement-N>
class Dog:
def __init__(self, name, age):
self.name=name
self.age=age
self.time=0 # 设置默认值
def sit(self):
print(f"Name:{self.name} Age:{self.age}")
# 类中的函数称为方法,__init__()是一个特殊的方法,每次根据Dog类创建实例时都会调用它
# 类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。
# 从执行结果可以很明显的看出,self 代表的是类的实例,代表当前对象的地址,而 self.class 则指向类。
# self 不是 python 关键字,我们把他换成 runoob 也是可以正常执行的:
# 每个与实例关联的方法调用都会自动传递实参self
# self.xxx=xxx, 相当于定义了类属性
def update_time(self, time):
self.time=time
# 创建实例
my_dog=Dog("zxc", 18)
print(f"my dog name is {my_dog.name}") # my dog name is zxc
print(f"my dog age is {my_dog.age}") # my dog age is 18
my_dog.sit() # Name:zxc Age:18
# 修改属性的值
## 直接改
my_dog.time=1
print(my_dog.time) # 1
## 通过方法改
my_dog.update_time(2)
print(my_dog.time) # 2继承:子类(派生类 DerivedClassName)会继承父类(基类 BaseClassName)
的属性和方法。支持单继承与多继承。
class DerivedClassName(BaseClassName):
<statement-1>
.
.
.
<statement-N>
class DerivedClassName(Base1, Base2, Base3):
<statement-1>
.
.
.
<statement-N>
需要注意圆括号中父类的顺序,若是父类中有相同的方法名,而在子类使用时未指定,
python从左至右搜索 即方法在子类中未找到时,从左到右查找父类中是否包含方法。
class Animal:
def __init__(self, name, age):
self.name=name
self.age=age
def toString(self):
print(f"My name is {self.name}\nMy age is {self.age}")
class Dog(Animal):
def __init__(self, name, age):
super().__init__(name, age) # super()能够调用其父类的方法
self.type="Dog" # 子类定义的属性
def red(self): # 子类自己的方法
print("旺旺")
# 定义与父类中的方法同名,从而重写父类
# 调用时只会调用子类,而忽略父类
def toString(self):
super().toString()
print(f"I am a {self.type}")
an =Animal("w", 18)
an.toString()
# My name is w
# My age is 18
dog=Dog("wcf", 18)
dog.red() # 旺旺
dog.toString()
# My name is wcf
# My age is 18
# I am a Doglei.py
class Animal:
def __init__(self, name, age):
self.name=name
self.age=age
class Dog(Animal):
def __init__(self, name, age):
super().__init__(name, age) # super()能够调用其父类的方法
self.type="Dog" # 子类定义的属性test.py
# 导入单个类
## from 模块 import 类名
from lei import Animal
a=Animal("1", 1)
# 导入多个类
## from 模块 import 类1, 类2
from lei import Animal, Dog
d=Dog("2", 2)
# 导入整个模块
## import 模块
import lei
aa=lei.Animal("3", 3) #模块名.类名
# 导入模块所有类
## from 模块名 import *
from lei import *
a=Animal("4", 4)
# 给模块指定别名
## import 模块 as 新名
import lei as l
a=l.Animal('0', 0)python标准库和第三方库
Python 库可以分为两大类,一类是 标准库 ,一类是 三方库 。标准库大都是下载对应 Python 版本时文件内置的,在程序中可直接调用且不需要用 pip 包管理工具从互联网上下载。而三方库则是其他程序员为了更好的实现某种目标,在实际开发中逐渐衍生出来的函数库或副产品,然后将其放在互联网上我们共享。
九. 文件和异常
1. 文件
读取文件
from pathlib import Path
path=Path('t.txt') # t.txt:3.1435926
contents=path.read_text().rstrip()
print(contents)
# 3.1415926
## 从pathlin库中导入路径类Path
## 创建相对路径类Path('t.txt'), 会从当前程序找t.txt文件
## read_text()访问t.txt内容, 该方法会在末尾返回一个
## 空字符串,显示为一个空行
# 绝对文件路径
p2=Path('D:/AbzyA/Python/IDE/projects/test/t.txt')
print(p2.read_text().rstrip())
# splitlines(), 方法返回一个列表,包含文件中所有行
print(p2.read_text().splitlines()) # ['3.1415926535', ' 8973923944']相对文件路径:像上面简单文件名传递给Path时,会从当前执行的程序所在的目录查找文件
绝对文件路径:从根目录到当前文件的路径。
写入文件
from pathlib import Path
# 写入一行
## write_text(), 若文件不存在,则会先创建文件,若原文件有内容,则会覆盖
## 将字符串写入文本,若想将数据写入,则先用str()函数转化成字符串
path=Path('D:/AbzyA/Python/IDE/projects/test/t.txt')
path.write_text('new things !') # new things !
# 写入多行
# 先创建字符串,在累加,\n 换行
content='a\n'
content+='b'
path.write_text(content)
# a
# bpath.exists()来判断文件(夹)是否存在,存在返回True, 不存在返回False2. 异常
Python使用异常的特殊对象来管理程序执行期间发生的错误。每当发生让Python不知所措的错误时,它都会创建一个异常对象。若编写了处理该异常的代码,程序将继续运行。若未对异常处理,程序将停止,并显示一个traceback.其中包含了有关异常的报告。
try-except代码块
## 若try中代码运行无问题,则程序继续往下执行
## 若有问题,则找到与之匹配的except执行,并且程序会继续执行剩余部分
try:
print(1/0)
except ZeroDivisionError:
print('非法除0') # 非法除0
try-except-else
## try中成功执行后应执行的代码,都应放到else中
try:
print(1/2) # 0.5
except ZeroDivisionError:
print('非法除0')
else:
print('success') # success
pass静默失败
try:
print(1/0)
except ZeroDivisionError:
pass # 捕获异常后希望程序什么都不做存储数据:用户输入的信息存储在列表,字典等数据结构中,一般使用模块json存储。
模块json将Python数据结构转化为JSON格式的字符串,并在程序再次运行时从文件中加载数据。
# json.dumps()接受实参,将其转化为json格式字符串
# json.loads()将json格式的字符串作为参数,转化为python对象
from pathlib import Path
import json
numbers=[1, 2, 3]
path=Path('num.json')
contents=json.dumps(numbers) # [1, 2, 3]
path.write_text(contents)
con=path.read_text()
num=json.loads(con)
print(num) # [1, 2, 3]十. 其他
1. global 语句
如果需要在一个函数内修改全局变量,就使用 global 语句。如果在函数的顶部
有 global eggs 这样的代码,它就告诉 Python,“在这个函数中,eggs 指的是全局变
量,所以不要用这个名字创建一个局部变量。”
def spam():
global eggs
print(eggs)
eggs = 'global'
spam() # global