
九. 流
1. 介绍
Java 8 引入了新的Stream API,它允许你以声明性的方式处理集合,并进行函数式编程。
流并不存储其元素:这些元素可能存储在底层的集合中,或者是按需生成的。
流式操作:可以通过管道方式组合多个操作,如
map()、filter()、reduce()等。流的操作不会修改其数据源:例如,filter方法不会从流中移除元素,而是会生成一 个新的流,其中不包含被过滤掉的元素。
惰性计算:只有在终止操作(如
collect()、forEach())调用时,流才会被触发。过程:创建流->中间操作->终结操作(这个操作会强制执行之前的惰性操作, 从此之后,这个流就再也不能用了)。
2. 创建流
①从集合创建流
List<String> list = Arrays.asList("a", "b", "c", "d");
Stream<String> stream = list.stream();②从数组创建流
String[] array = {"a", "b", "c"};
Stream<String> stream = Arrays.stream(array);③使用静态方法创建流
Stream<String> stream = Stream.of("a", "b", "c");
Stream<String> echos=Stream.empty();//创建空流④创建无限流
无限流是一种特殊的流。流是 Java 8 引入的一个重要概念,用于对集合等数据源进行操作。无限流是一种没有固定大小,理论上可以产生无限个元素的流。它可以持续地生成元素,直到外部终止条件被满足。
Random random = new Random();
// 生成一个无限流,元素是随机的整数
Stream<Integer> randomNumbers=Stream.generate(() -> random.nextInt(100));
// 获取前 5 个随机数
randomNumbers.limit(5).forEach(System.out::println);
//Stream.iterate() 生成的是基于某个初始元素的有界流。
//它接受两个参数:一个初始元素和一个 UnaryOperator,该操作符用于生成后续的元素。
// 生成一个从 0 开始递增的整数流
Stream<Integer> numbers = Stream.iterate(0, n -> n + 1);
// 获取前 10 个数字
numbers.limit(10).forEach(System.out::println);⑤其他API




3. 中间操作(流的转换)
流的转换会产生一个新的流,它的元素派生自另一个流中的元素。
①filter():过滤元素
//filter接受一个Predicate函数接口,流中所有满足此断言的元素都会成为新流的一部分
List<String> list = Arrays.asList("apple", "banana", "cherry");
List<String> filtered = list.stream()
.filter(s -> s.startsWith("a"))
.collect(Collectors.toList());
System.out.println(filtered); // [apple]②map():转换元素
//map接受一个Function函数接口,接受一个元素,返回一个元素,把原始流的元素映射为新元素
List<String> list = Arrays.asList("apple", "banana", "cherry");
List<String> upperCase = list.stream()
.map(String::toUpperCase)
.collect(Collectors.toList());
System.out.println(upperCase); // [APPLE, BANANA, CHERRY]③flatMap()
Stream<T> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);
mapper:接受流中的每个元素,并返回一个 Stream。这个 Stream 的元素会被合并到最终的流中。
flatMap() 将流中的每个元素转换成一个流,并将这些流合并成一个单一的流。
List<List<String>> listOfLists = Arrays.asList(
Arrays.asList("apple", "banana"),
Arrays.asList("cherry", "date"),
Arrays.asList("elderberry", "fig")
);
// 使用 flatMap 将嵌套的 List 扁平化为一个流
List<String> flattenedList = listOfLists.stream()
.flatMap(List::stream) // 扁平化
.collect(Collectors.toList());
System.out.println(flattenedList);//[apple, banana, cherry, date, elderberry, fig]④mapMulti()
mapMulti() 是 Java 16 中引入的一个新方法,它是 Stream 接口的一个中间操作。与 flatMap() 类似,mapMulti() 允许我们将每个元素映射到多个结果,并且比 flatMap() 更加灵活,因为它允许在映射过程中动态产生多个元素,并且避免了生成额外的流对象。
Stream<T> mapMulti(BiConsumer<? super T, ? super Consumer<? super R>> mapper);mapper:接受流中每个元素的BiConsumer函数,BiConsumer的第一个参数是流中的元素,第二个参数是一个Consumer,可以将结果添加到目标流中。
//将整数列表映射为多个倍数
List<Integer> numbers = Arrays.asList(1, 2, 3);
numbers.stream()
.mapMulti((num, consumer) ->
{
for (int i = 1; i <= 3; i++)
{
consumer.accept(num * i); // 添加 num 的倍数
}
})
.forEach(System.out::println);
1
2
3
2
4
6
3
6
9⑤limit()
它接收一个整数参数
n,返回一个新的流,包含流中前n个元素。如果流的元素个数小于n,则返回所有元素;如果流的元素个数大于n,则仅返回前n个元素。Stream<T> limit(long maxSize);
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9);
stream.limit(3).forEach(System.out::println);//1 2 3⑥skip()
丢弃流中前n个元素
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
stream.skip(3).limit(3).forEach(System.out::println); // 输出 4, 5, 6⑦takeWhile
takeWhile是 Java 9 引入的一个新方法,用于对流中的元素进行前置过滤。它返回流中从开始位置起,直到遇到第一个不满足给定条件的元素时为止的所有元素。换句话说,takeWhile会按顺序从流的开头取元素,直到某个元素不再符合给定的条件,之后的元素都被丢弃。Stream<T> takeWhile(Predicate<? super T> predicate);
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6, 7, 8);
stream.takeWhile(n -> n < 5).forEach(System.out::println);//1 2 3 4⑧dropWhile
dropWhile是 Java 9 引入的一个新方法,用于从流中丢弃(跳过)前置不符合条件的元素,直到遇到第一个符合条件的元素为止。它返回一个新的流,其中包含从第一个符合条件的元素开始之后的所有元素。Stream<T> dropWhile(Predicate<? super T> predicate);
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6, 7, 8);
stream.dropWhile(n -> n < 5).forEach(System.out::println);//5 6 7 8⑨concat
concat()是Stream接口中的一个静态方法,用于将两个流连接成一个流。它返回一个新的流,该流包含两个输入流的所有元素。这个方法非常有用,尤其是在你需要将多个流合并在一起时。concat()不会改变原始流,返回的是一个新的流。concat()本身是一个惰性操作,元素的计算在终止操作(如forEach)时才会执行。
Stream<Integer> stream1 = Stream.of(1, 2, 3);
Stream<Integer> stream2 = Stream.of(4, 5, 6);
Stream<Integer> concatenatedStream = Stream.concat(stream1, stream2);
concatenatedStream.forEach(System.out::println);//1 2 3 4 5 6⑩distinct
distinct()是Stream接口中的一个中间操作,用于从流中去除重复元素。它会返回一个新的流,其中不包含重复的元素。该操作基于元素的equals()方法来判断是否相等,因此它会保留每个元素的唯一性。
Stream<Integer> stream = Stream.of(1, 2, 3, 2, 4, 1, 5, 6, 4);
stream.distinct().forEach(System.out::println);//1 2 3 4 5 6①①sorted
sorted()是Stream接口中的一个中间操作,用于对流中的元素进行排序。它可以按自然顺序排序(对于实现了Comparable接口的元素),也可以按自定义的比较器进行排序。sorted()返回一个新的流,其中包含按排序规则排序后的元素。Stream<T> sorted();//自然序Stream<T> sorted(Comparator<? super T> comparator);//比较器序
//自然序
Stream<Integer> stream = Stream.of(5, 3, 8, 1, 4, 7, 2, 6);
stream.sorted().forEach(System.out::println);//1 2 3 4 5 6 7 8
//比较器序
Stream<Person> stream = Stream.of(
new Person("Alice", 30),
new Person("Bob", 25),
new Person("Charlie", 35)
);
stream.sorted(Comparator.comparingInt(Person::getAge).reversed()) // 按年龄降序排序
.forEach(System.out::println);①②peek
peek()是Stream接口中的一个中间操作,用于查看流中的元素。它允许在流的操作链中插入调试或其他操作。peek()本身不会改变流中的元素,而是返回一个新的流,其中包含与原始流相同的元素。常用于调试目的,以查看流中的元素在经过某些操作时的中间状态。Stream<T> peek(Consumer<? super T> action);action:一个接受流中元素并执行某些操作的Consumer,通常是一个输出或日志操作。
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5);
stream.filter(n -> n % 2 == 0) // 过滤偶数
.peek(n -> System.out.println("Filtered value: " + n)) // 调试:打印被过滤的元素
.map(n -> n * 2) // 将元素乘以2
.peek(n -> System.out.println("Mapped value: " + n)) // 调试:打印被映射的元素
.forEach(System.out::println); // 输出最终结果
Filtered value: 2
Filtered value: 4
Mapped value: 4
Mapped value: 8
4
8①③API



4. Optional类型
Optional是 Java 8 引入的一个容器类,用来表示可能为null的值,旨在帮助开发者避免NullPointerException(空指针异常)。通过Optional,你可以明确地处理可能不存在的值,而不需要直接操作null,从而提高代码的可读性和健壮性。流式操作的终结操作通常返回一个类型为Optional<T>的值。
①创建Optional实例
Optional.empty():返回一个空的Optional对象,表示没有值。Optional.of(T value):返回一个包含给定非null值的Optional对象。如果值为null,则抛出NullPointerException。Optional.ofNullable(T value):返回一个包含给定值的Optional对象,如果值为null,则返回一个空的Optional。
import java.util.Optional;
public class Main
{
public static void main(String[] args)
{
// 创建一个非空的 Optional
Optional<String> optional1 = Optional.of("Hello, Optional!");
// 创建一个空的 Optional
Optional<String> optional2 = Optional.empty();
// 创建一个可能为空的 Optional
Optional<String> optional3 = Optional.ofNullable("Hello, World!");
// 打印
System.out.println(optional1); // Optional[Hello, Optional!]
System.out.println(optional2); // Optional.empty
System.out.println(optional3); // Optional[Hello, World!]
}
}②获取Optional值
get():如果Optional中有值,返回该值。如果没有值,抛出NoSuchElementException。orElse(T other):如果Optional中有值,返回该值;否则返回other。orElseGet(Supplier<? extends T> other):如果Optional中有值,返回该值;否则调用other提供的Supplier来获取值。orElseThrow(Supplier<? extends X> exceptionSupplier):如果Optional中有值,返回该值;否则抛出由exceptionSupplier创建的异常。
public class Main
{
public static void main(String[] args)
{
Optional<String> optional1 = Optional.of("Hello");
Optional<String> optional2 = Optional.empty();
// 获取值,如果为空则抛出异常
System.out.println(optional1.get()); // Hello
// 如果为空返回默认值
System.out.println(optional2.orElse("Default Value")); // Default Value
// 如果为空调用 Supplier 提供的值
System.out.println(optional2.orElseGet(() -> "Generated Value")); // Generated Value
// 如果为空抛出自定义异常
// optional2.orElseThrow(() -> new IllegalArgumentException("Value is missing"));
}
} ③消费Optional值
isPresent():如果Optional中有值,返回true,否则返回false。ifPresent(Consumer<? super T> action):如果Optional中有值,就执行Consumer提供的操作。void ifPresentOrElse(Consumer<? super T> action, Runnable emptyAction)如果该Optional不为空,就将它的值传递给action, 否则调用emptyAction。
public class Main
{
public static void main(String[] args)
{
Optional<String> optional = Optional.of("Hello");
// 判断是否有值
if (optional.isPresent())
{
System.out.println("Value: " + optional.get());
}
// 使用 ifPresent() 来执行操作
optional.ifPresent(value -> System.out.println("Value from ifPresent: " + value));
}
}④管道化Optional值
这里的管道化操作是Optional中的,与Stream中的有些类似。
一般调用的是T即原来包裹的值,返回的是U新产生的值。


Optional<String> optional = Optional.of("Hello");
// 使用 map 转换值
Optional<String> uppercased = optional.map(String::toUpperCase);
System.out.println(uppercased.orElse("No value"));//HELLO
// 使用 flatMap 处理返回的 Optional
Optional<String> flatMapped = optional.flatMap(s -> Optional.of(s.toUpperCase()));
System.out.println(flatMapped.orElse("No value"));//HELLO
/////////////////////////////
Optional<String> optional = Optional.of("Hello");
// 使用 filter 过滤值
Optional<String> filtered = optional.filter(value -> value.length() > 3);
System.out.println(filtered.orElse("No value"));//Hello
Optional<String> filtered2 = optional.filter(value -> value.length() < 3);
System.out.println(filtered2.orElse("No value"));//No value⑤使用Optional值的注意
Optional类型的变量永远都不应该为null。
不要使用Optional类型的域(一个类或对象的属性)。因为其代价是额外多出来一个对象。在类的内部,应该 使用null表示缺失的域更易于操作。如果不希望使用Optional类型的域,那么就让类是不可序列化的。
Optional主要用于方法的返回类型,而不是类的字段。你不应该使用Optional来表示类中的字段,因为这会导致不必要的复杂性和性能开销。Optional更适合用于方法返回值,表示某些值可能不存在。不要将Optional作为方法参数。
不要在集合中放置Optional对象,并且不要将它们用作map的键。应该直接收集其中的值。
使用Optional的get或isPresent方法并没有比值的
⑥将Optional转换为流
Optional.stream()
5. 终结操作(约简)
①count
count()用于返回流中元素的数量。count()操作会遍历整个流,并统计流中元素的个数,最终返回一个long类型的结果。long count();
List<String> list = Arrays.asList("apple", "banana", "cherry", "date");
long count = list.stream().count(); // 计算流中元素的数量
System.out.println("Number of elements: " + count); // 输出:4②max、min
max()和min()是 Java Stream API 中的终结操作,它们用于从流中找出最大值和最小值。Optional<T> max(Comparator<? super T> comparator);Optional<T> min(Comparator<? super T> comparator);
List<Integer> numbers = Arrays.asList(5, 12, 3, 8, 20);
// 使用 max 找到最大值
Optional<Integer> max = numbers.stream()
.max(Comparator.naturalOrder()); // 使用自然顺序(升序比较)
max.ifPresent(System.out::println); // 输出:20③findFirst、findAny
findFirst()和findAny()用于从流中查找一个元素。它们的主要区别在于元素的选择和并行流的行为。findFirst()会返回流中第一个遇到的元素,它始终按照流的顺序返回第一个元素。Optional<T> findFirst();findAny()会返回流中任意一个元素。在顺序流中,它返回的元素和findFirst()相同,但是在并行流中,findAny()可以返回任何符合条件的元素,不一定是第一个遇到的元素。Optional<T> findAny();
List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "Dave");
// 查找第一个名字
Optional<String> firstName = names.stream().findFirst();
firstName.ifPresent(System.out::println); // 输出:Alice
/////////////////////////
List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "Dave");
// 查找任意一个名字
Optional<String> anyName = names.stream().findAny();
anyName.ifPresent(System.out::println); // 输出:任意一个名字,例如 "Alice"④anyMatch、allMatch、noneMatch
anyMatch()用于检查流中是否有至少一个元素满足指定的条件。如果流中至少有一个元素符合条件,它会返回true,否则返回false。boolean anyMatch(Predicate<? super T> predicate);allMatch()用于检查流中是否所有元素都满足指定的条件。如果所有元素都符合条件,则返回true,否则返回false。boolean allMatch(Predicate<? super T> predicate);noneMatch()用于检查流中是否没有任何元素满足指定的条件。如果流中没有任何元素符合条件,则返回true,否则返回false。boolean noneMatch(Predicate<? super T> predicate);
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
// 判断流中是否有任何一个数字大于 4
boolean hasLargeNumber = numbers.stream()
.anyMatch(n -> n > 4);
System.out.println(hasLargeNumber); // 输出:true
//////////////////////////////////////////////////
List<Integer> numbers = Arrays.asList(2, 4, 6, 8, 10);
// 判断流中的所有数字是否都是偶数
boolean allEven = numbers.stream()
.allMatch(n -> n % 2 == 0);
System.out.println(allEven); // 输出:true
///////////////////////////////////////////////////////////////
List<Integer> numbers = Arrays.asList(1, 3, 5, 7, 9);
// 判断流中是否没有任何数字是偶数
boolean noEven = numbers.stream()
.noneMatch(n -> n % 2 == 0);
System.out.println(noEven); // 输出:true⑤收集结果

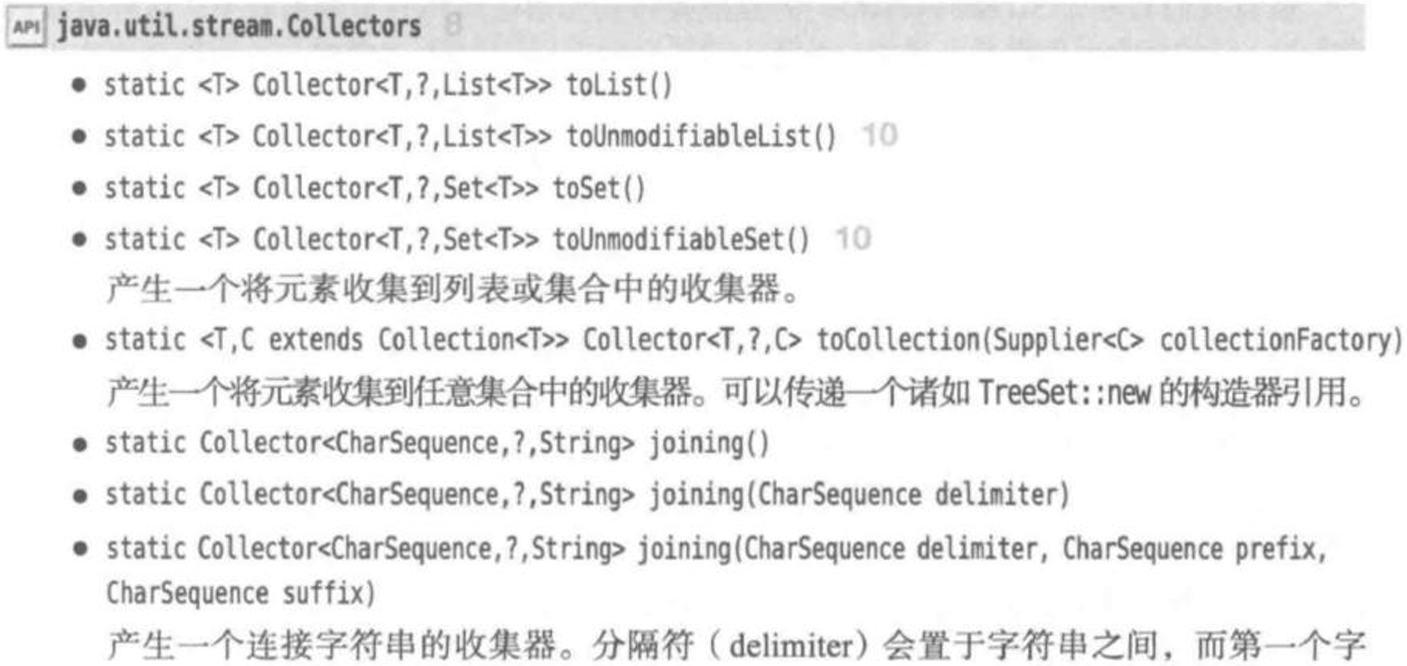


⑥收集到映射表


⑦群组收集器
Collectors.groupingBy是一个非常常用的收集器(Collector),用于将流中的元素按照指定的规则分组。分组的结果是一个Map,键是分组的依据,值是分组后的元素集合。
下面的下游收集器是处理每个键对应的列表的。


List<String> words = Arrays.asList("apple", "banana", "cherry", "date", "elderberry");
// 使用 groupingBy 按照单词长度分组
Map<Integer, List<String>> groupedByLength = words.stream()
.collect(Collectors.groupingBy(String::length));
// 输出按长度分组的结果
System.out.println(groupedByLength);
{5=[apple], 6=[banana], 7=[cherry], 4=[date], 10=[elderberry]}
**************************
List<String> words = Arrays.asList("apple", "banana", "cherry", "date", "elderberry");
// 使用 groupingBy 和 counting 统计每个分组中的元素个数
Map<Integer, Long> wordCountByLength = words.stream()
.collect(Collectors.groupingBy(String::length, Collectors.counting()));
// 输出按长度分组并统计个数的结果
System.out.println(wordCountByLength);
{5=1, 6=1, 7=1, 4=1, 10=1}
**************
List<String> words = Arrays.asList("apple", "banana", "cherry", "date", "elderberry");
// 使用 groupingBy 和 joining 按长度分组并将每组中的单词连接成一个字符串
Map<Integer, String> wordsByLength = words.stream()
.collect(Collectors.groupingBy(String::length, Collectors.joining(", ")));
// 输出按长度分组并连接单词的结果
System.out.println(wordsByLength);
{5=apple, 6=banana, 7=cherry, 4=date, 10=elderberry}
**********
List<String> words = Arrays.asList("apple", "banana", "cherry", "date", "apple");
// 将流中的元素按长度分组,并且每个分组的元素收集到 Set
Map<Integer, Set<String>> groupedByLengthSet = words.stream()
.collect(Collectors.groupingBy(
String::length,
Collectors.toSet() // 使用 Set 作为收集器
));
// 输出分组结果
System.out.println(groupedByLengthSet);
{5=[apple], 6=[banana], 7=[cherry], 4=[date]}⑧reduce
reduce是一种用于集合操作的常见方法,它主要用于将集合中的元素通过某种方式进行累积或归约,最终得到一个结果。它通常在 Stream API 中使用,特别是在进行聚合计算(如求和、求最大值、连接字符串等)时。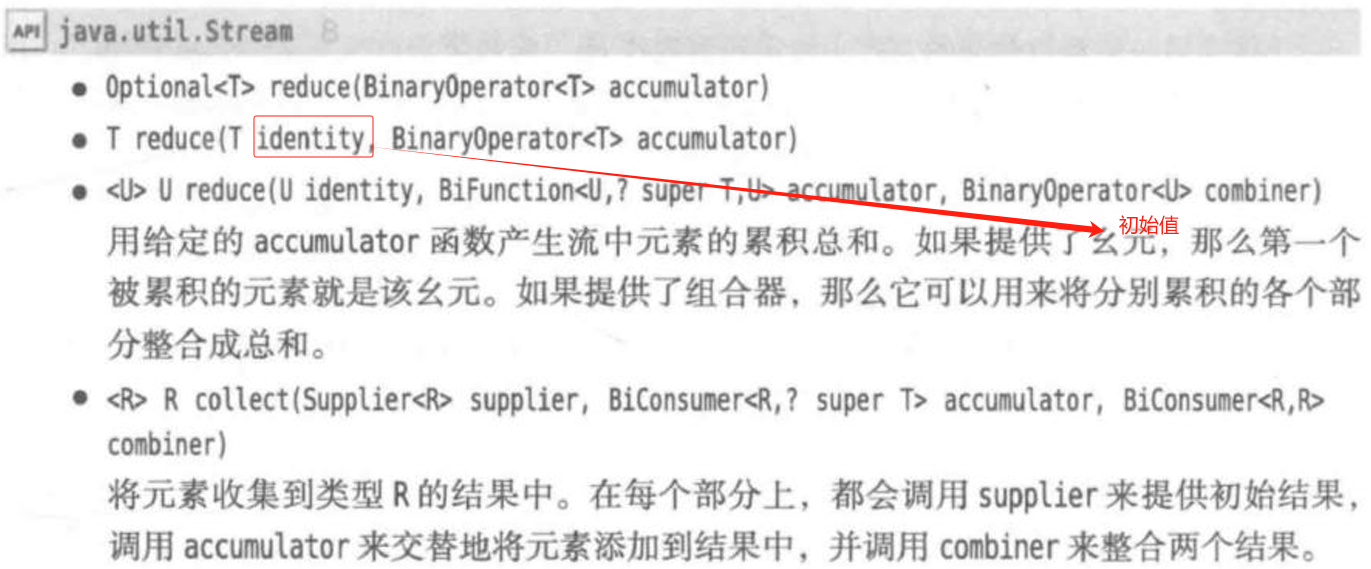
6. 基本类型流
①介绍
基本数据类型流是对
StreamAPI的一种优化,避免了对包装类型(如Integer,Double等)的装箱和拆箱操作。基本类型流有三个主要的子接口:IntStream:用于处理int(short、char、byte、boolean)类型的数据流。LongStream:用于处理long类型的数据流。DoubleStream:用于处理double(float)类型的数据流。-
包装类型流(
Stream<T>):流中的元素是对象,可能会涉及装箱(boxing)和拆箱(unboxing),即将基本类型转换为包装类(例如,将int转换为Integer)。基本类型流(
IntStream,LongStream,DoubleStream):专门用于处理基本数据类型,避免了装箱和拆箱,因此在处理大量数据时更高效。-
转换:基本类型流和包装类型流之间可以通过
mapToXxx和boxed()方法进行转换。
②API







7. 并行流
①介绍
并行流 (Parallel Streams) 是 Java 8 引入的一个重要特性,它允许开发者在处理集合数据时通过多个线程同时执行操作,从而提高程序的性能。Java Stream API 提供了
parallel()方法来将一个普通的流转换为并行流。并行流是基于 Java 7 引入的 Fork/Join Framework 来实现的,它可以在多核处理器上并行处理数据,提高处理速度。只要在终结方法执行时流处于并行模式,所有的中间流操作就都将被并行化。
②注意
并行化会导致大量的开销,只有面对非常大的数据集才划算。
只有在底层的数据源可以被有效地分割为多个部分时,将流并行化才有意义。
并行流使用的线程池可能会因诸如文件I/O或网络访问这样的操作被阻塞而饿死。
③API

十. 输入与输出
1. 介绍
①基本介绍
定义:I/O流就是指数据在内部存储器和外部存储器或其他周边设备之间输入和输出产生的数据流,包括了数据的流向。流向是以程序(CPU和主存)为参照物,数据从程序输出到其他节点称为输出流,数据从其他节点输入到程序称为输入流。

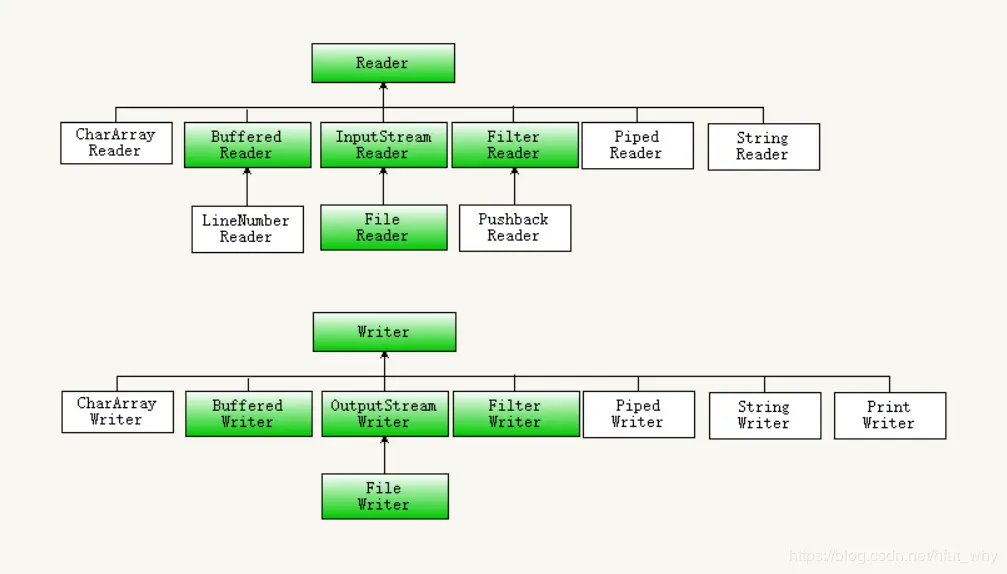
四大首领:其中InputStream、OutputStream、Reader、Writer是所有流的基类。
分类:这4个基类是输入流、输出流和字节流、字符流的两两组合,当这4个基类与不同节点的节点流,不同功能的处理流再进行组合时,就形成了java的IO流体系
按流向分类——输入流,输出流。
按操作数据单位分类——字节流(处理所有类型的原始二进制数据,包括图像、音频、视频以及任何其他文件格式。字节流直接处理字节(
byte)数据,不做编码转换),字符流(处理文本数据(即字符),并会根据字符编码(如UTF-8或UTF-16)自动进行字节到字符的转换。字符流适用于处理文本文件)。按角色分类——节点流,处理流。
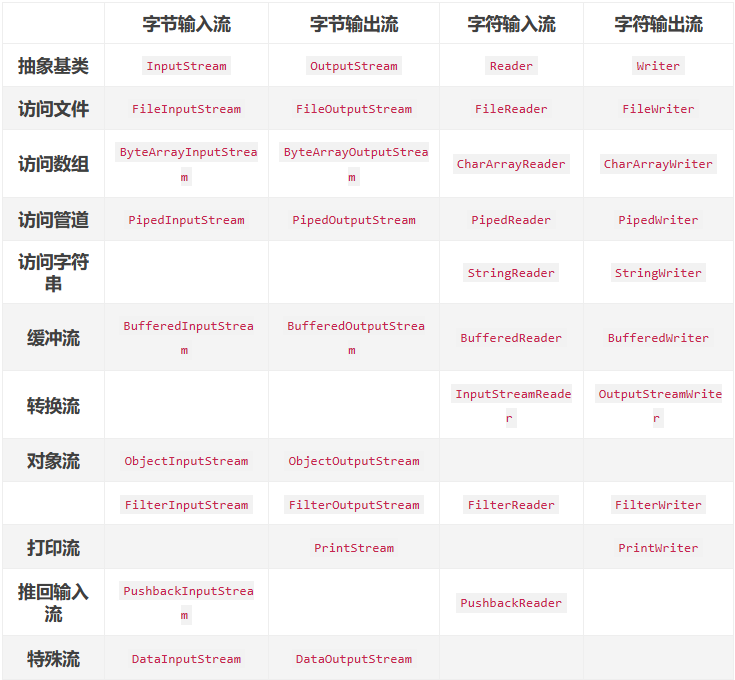
②四大组合

③节点流

④处理流

⑤I/O流体系的设计思想
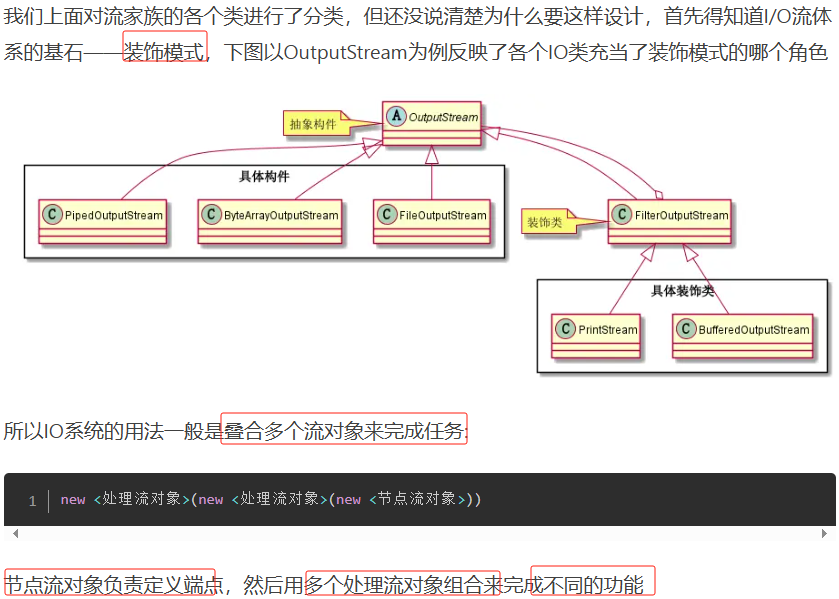
⑥附加接口


⑦流关闭
当完成对输人/输出流的读写时,应调用
close方法来关闭它,这个调用会释放掉有限的操作系统资源。如果一个应用程序打开了过多的输人/输出流而没有关闭, 那么系统资源将被耗尽。关闭一个输出流的同时还会冲刷用于该输出流的缓冲区:所有被临时置于缓冲区中,以便用更大的包的形式传递的字节在关闭输出流时都将被送出。如果不关闭文件,那么写出字节的最后一个包可能永远也得不到传递。当然,还可以用flush方法来人为地冲刷这些输出。
⑧组合输入/输出流过滤器
FileInputstream和FileOutputStream可以提供附着在一个磁盘文件上的输人流和输出流,只需向其构造器提供文件名或文件的完整路径名。如果我们只有DataInputStream,那么我们就只能读入数值类型。但是正如FileInputStream没有任何读入数值类型的方法一样,DataInputStream也没有任何从文件中获取数据的方法。Java采用这样的机制分离这两种职责,某些输入流(例如FileInputStream)可以从文件和其他更外部位置获取字节,而其他的输入流(例如DataInputStream)可以将字节组装到更有用的数据类型。Java中的组合输入/输出流(
composite I/O streams)是指通过多个流的组合来处理数据的输入输出。在Java I/O中,流的组合通常是通过将一个流包装在另一个流中来实现的。这样可以在不改变原始流的基础上,增加更多的功能。例如:为了冲文件读入数字,要首先创建一个
FileInputstream,然后将其传递给DataInputStream的构造器。var fin=new FileInputStream("wcc.dat"); var din=new DataInputStream(fin); var x=din.readDouble();

//常见的组合输入/输出流:
BufferedInputStream/BufferedOutputStream
用于缓冲输入输出,减少读取或写入操作的次数,提高性能。
例如:将一个FileInputStream包装成一个BufferedInputStream来提高读取性能。
InputStream fileInputStream = new FileInputStream("input.txt");
BufferedInputStream bufferedInputStream = new BufferedInputStream(fileInputStream);
************
DataInputStream/DataOutputStream
用于从输入流中读取原始数据类型(如int, float等)并写入输出流。
它是通过组合原始字节流(如FileInputStream和FileOutputStream)来处理更高层次的数据类型。
DataInputStream dataInputStream = new DataInputStream(new FileInputStream("input.dat"));
DataOutputStream dataOutputStream = new DataOutputStream(new FileOutputStream("output.dat"));
***********
ObjectInputStream/ObjectOutputStream
用于对象的序列化和反序列化,将对象转换为字节流或将字节流恢复为对象。
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("object.dat"));
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("object.dat"));
************
FilterInputStream/FilterOutputStream
这是一个抽象类,所有装饰性输入输出流的基类。它可以包装任何输入或输出流,为其添加额外的功能。
例如:BufferedInputStream继承自FilterInputStream,提供缓冲功能。
FilterInputStream filterInputStream = new BufferedInputStream(new FileInputStream("input.txt"));
************
PrintStream
用于格式化输出,可以结合FileOutputStream或ByteArrayOutputStream等流来输出格式化的数据。
PrintStream printStream = new PrintStream(new FileOutputStream("output.txt"));
printStream.println("Hello, World!");
**********
Chained Streams
可以通过链式组合多个流。例如,首先将文件输入流包装为BufferedInputStream,再包装为DataInputStream来读取数据。
DataInputStream dataInputStream = new DataInputStream(new BufferedInputStream(new FileInputStream("input.dat")));2. 文件流
读取写入文件。
①FileInputStream(文件字节输入流)/FileOutputStream(文件字节输出流)
public class FileInputStreamExample
{
public static void main(String[] args)
{
FileInputStream fis = null;
try
{
// 创建 FileInputStream 对象,指向要读取的文件
fis = new FileInputStream("input.dat");
int data;
// 逐字节读取文件数据
while ((data = fis.read()) != -1)
{
System.out.print((char) data); // 打印文件中的字节(字符)
}
} catch (IOException e)
{
e.printStackTrace();
} finally
{
try
{
if (fis != null)
{
fis.close(); // 关闭流
}
} catch (IOException e)
{
e.printStackTrace();
}
}
}
}public class FileOutputStreamExample
{
public static void main(String[] args)
{
FileOutputStream fos = null;
try
{
// 创建 FileOutputStream 对象,指向要写入的文件
fos = new FileOutputStream("output.dat");
String content = "Hello, this is an example of FileOutputStream!";
byte[] contentBytes = content.getBytes(); // 将字符串转换为字节数组
fos.write(contentBytes); // 写入字节数据到文件
System.out.println("Data has been written to output.dat");
} catch (IOException e)
{
e.printStackTrace();
} finally
{
try
{
if (fos != null)
{
fos.close(); // 关闭流
}
} catch (IOException e)
{
e.printStackTrace();
}
}
}
}②FileReader(文件字符输入流)/FileWriter(文件字符输出流)
public class FileReaderExample
{
public static void main(String[] args)
{
FileReader fr = null;
try
{
// 创建 FileReader 对象,指向要读取的文件
fr = new FileReader("input.txt");
int data;
// 逐字符读取文件数据
while ((data = fr.read()) != -1)
{
System.out.print((char) data); // 打印文件中的字符
}
} catch (IOException e)
{
e.printStackTrace();
} finally
{
try
{
if (fr != null)
{
fr.close(); // 关闭流
}
} catch (IOException e)
{
e.printStackTrace();
}
}
}
}public class FileWriterExample
{
public static void main(String[] args)
{
FileWriter fw = null;
try
{
// 创建 FileWriter 对象,指向要写入的文件
fw = new FileWriter("output.txt");
String content = "Hello, this is an example of FileWriter!";
fw.write(content); // 将字符数据写入文件
System.out.println("Data has been written to output.txt");
} catch (IOException e)
{
e.printStackTrace();
} finally
{
try
{
if (fw != null)
{
fw.close(); // 关闭流
}
} catch (IOException e)
{
e.printStackTrace();
}
}
}
}3. 转换流
InputStreamReader和OutputStreamWriter是桥接类(adapter),将字节流转换为字符流,或者将字符流转换为字节流。这两者的主要作用是为字节流和字符流之间提供编码和解码支持。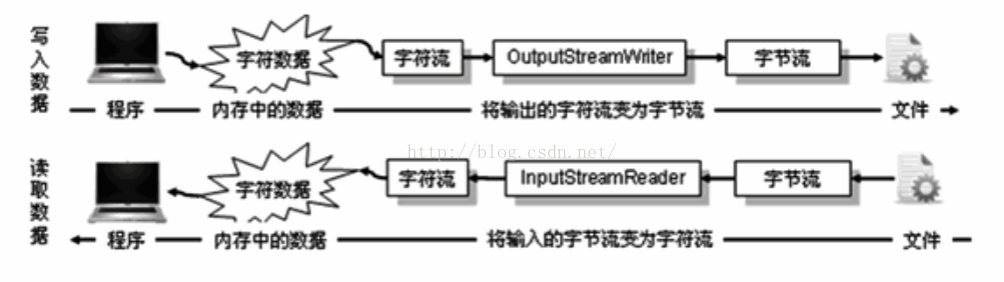
①InputStreamReader
InputStreamReader是一个将字节流转换为字符流的桥接类,它通过指定字符编码来将字节数据解码为字符。默认情况下,InputStreamReader使用平台的默认字符编码,但你可以通过构造函数显式指定编码。
public class InputStreamReaderExample
{
public static void main(String[] args)
{
InputStreamReader isr = null;
try
{
// 创建一个 FileInputStream,读取文件的字节数据
FileInputStream fis = new FileInputStream("input.txt");
// 使用 InputStreamReader 将字节流转换为字符流,默认使用 UTF-8 编码
isr = new InputStreamReader(fis, "UTF-8");
int data;
// 逐字符读取文件数据
while ((data = isr.read()) != -1)
{
System.out.print((char) data); // 打印文件中的字符
}
} catch (IOException e)
{
e.printStackTrace();
} finally
{
try
{
if (isr != null)
{
isr.close(); // 关闭流
}
} catch (IOException e)
{
e.printStackTrace();
}
}
}
}②OutputStreamWriter
OutputStreamWriter是一个将字符流转换为字节流的桥接类,它使用指定的字符编码将字符数据编码为字节。你可以显式指定编码类型,或者使用平台默认编码。
public class OutputStreamWriterExample
{
public static void main(String[] args)
{
OutputStreamWriter osw = null;
try
{
// 创建一个 FileOutputStream,准备写入字节数据
FileOutputStream fos = new FileOutputStream("output.txt");
// 使用 OutputStreamWriter 将字符流转换为字节流,指定编码为 UTF-8
osw = new OutputStreamWriter(fos, "UTF-8");
String content = "Hello, this is an example of OutputStreamWriter!";
osw.write(content); // 将字符数据写入字节流
System.out.println("Data has been written to output.txt");
} catch (IOException e)
{
e.printStackTrace();
} finally
{
try
{
if (osw != null)
{
osw.close(); // 关闭流
}
} catch (IOException e)
{
e.printStackTrace();
}
}
}
}4. 缓冲流
①BufferedInputStream/BufferedOutputStream
BufferedInputStream 和 BufferedOutputStream 是基于字节流的缓冲流,它们用于提高输入和输出操作的效率。缓冲流会将数据缓存到内存中,减少频繁的磁盘操作,从而提升性能。
public class BufferedInputStreamExample
{
public static void main(String[] args)
{
BufferedInputStream bis = null;
try
{
// 创建 FileInputStream 用于读取文件
FileInputStream fis = new FileInputStream("input.txt");
// 使用 BufferedInputStream 缓冲读取,提高性能
bis = new BufferedInputStream(fis);
int data;
// 逐字节读取文件
while ((data = bis.read()) != -1)
{
System.out.print((char) data); // 打印文件中的字符
}
} catch (IOException e)
{
e.printStackTrace();
} finally
{
try
{
if (bis != null)
{
bis.close(); // 关闭流
}
} catch (IOException e)
{
e.printStackTrace();
}
}
}
}public class BufferedOutputStreamExample
{
public static void main(String[] args)
{
BufferedOutputStream bos = null;
try
{
// 创建 FileOutputStream 用于写入文件
FileOutputStream fos = new FileOutputStream("output.txt");
// 使用 BufferedOutputStream 缓冲写入,提高性能
bos = new BufferedOutputStream(fos);
String content = "Hello, this is an example of BufferedOutputStream!";
byte[] contentBytes = content.getBytes(); // 将字符串转换为字节数组
bos.write(contentBytes); // 写入数据
System.out.println("Data has been written to output.txt");
} catch (IOException e)
{
e.printStackTrace();
} finally
{
try
{
if (bos != null)
{
bos.close(); // 关闭流
}
} catch (IOException e)
{
e.printStackTrace();
}
}
}
}②BufferedReader/BufferedWriter
BufferedReader 和 BufferedWriter 是基于字符流的缓冲流,用于提高字符输入输出的性能。它们通过内存缓冲区来减少对磁盘的频繁读取和写入操作,从而提高了效率。
public class BufferedReaderExample
{
public static void main(String[] args)
{
BufferedReader br = null;
try
{
// 创建 FileReader 用于读取字符文件
FileReader fr = new FileReader("input.txt");
// 使用 BufferedReader 缓冲读取
br = new BufferedReader(fr);
String line;
// 按行读取文件数据
while ((line = br.readLine()) != null)
{
System.out.println(line); // 打印每行内容
}
} catch (IOException e)
{
e.printStackTrace();
} finally
{
try
{
if (br != null)
{
br.close(); // 关闭流
}
} catch (IOException e)
{
e.printStackTrace();
}
}
}
}public class BufferedWriterExample
{
public static void main(String[] args)
{
BufferedWriter bw = null;
try
{
// 创建 FileWriter 用于写入文件
FileWriter fw = new FileWriter("output.txt");
// 使用 BufferedWriter 缓冲写入
bw = new BufferedWriter(fw);
String content = "Hello, this is an example of BufferedWriter!";
bw.write(content); // 写入字符数据
bw.newLine(); // 插入换行符
bw.write("This is the second line.");
System.out.println("Data has been written to output.txt");
} catch (IOException e)
{
e.printStackTrace();
} finally
{
try
{
if (bw != null)
{
bw.close(); // 关闭流
}
} catch (IOException e)
{
e.printStackTrace();
}
}
}
}5. 数据流
DataInputStream和DataOutputStream用于处理基本数据类型的输入输出,如int、float、double、boolean等,它们提供了以平台无关的方式读写数据的能力。
①DataInputStream
DataInputStream用于从输入流中读取原始数据类型。它提供了多种方法来读取各种基本数据类型(如int、double、char等)。
public class DataInputStreamExample
{
public static void main(String[] args)
{
DataInputStream dis = null;
try
{
// 创建 FileInputStream 用于读取文件字节流
FileInputStream fis = new FileInputStream("data.dat");
// 使用 DataInputStream 读取原始数据类型
dis = new DataInputStream(fis);
// 读取并打印各种数据类型
int intValue = dis.readInt();
double doubleValue = dis.readDouble();
boolean booleanValue = dis.readBoolean();
char charValue = dis.readChar();
System.out.println("Read int: " + intValue);
System.out.println("Read double: " + doubleValue);
System.out.println("Read boolean: " + booleanValue);
System.out.println("Read char: " + charValue);
} catch (IOException e)
{
e.printStackTrace();
} finally
{
try
{
if (dis != null)
{
dis.close(); // 关闭流
}
} catch (IOException e)
{
e.printStackTrace();
}
}
}
}②DataOutputStream
DataOutputStream用于将原始数据类型写入输出流。它提供了多种方法来写入各种基本数据类型(如int、double、char等)。
public class DataOutputStreamExample
{
public static void main(String[] args)
{
DataOutputStream dos = null;
try
{
// 创建 FileOutputStream 用于写入文件字节流
FileOutputStream fos = new FileOutputStream("data.dat");
// 使用 DataOutputStream 写入原始数据类型
dos = new DataOutputStream(fos);
// 写入不同类型的数据
dos.writeInt(42);
dos.writeDouble(3.14159);
dos.writeBoolean(true);
dos.writeChar('A');
System.out.println("Data has been written to data.dat");
} catch (IOException e)
{
e.printStackTrace();
} finally
{
try
{
if (dos != null)
{
dos.close(); // 关闭流
}
} catch (IOException e)
{
e.printStackTrace();
}
}
}
}6. 标准输出流
PrintStream和PrintWriter是 Java 中的输出流类,它们为输出提供了便捷的方法,尤其适合打印格式化的数据,能够直接输出文本和各种数据类型,并且自动进行字符编码。
①PrintStream
PrintStream是一个字节输出流,能够自动将字符数据转换为字节数据,适用于打印各种类型的数据,如int、float、String等。PrintStream还可以自动刷新输出,并且能够将内容输出到控制台或文件。
public class PrintStreamExample {
public static void main(String[] args) {
try {
// 创建 PrintStream,输出到控制台
PrintStream ps = new PrintStream(System.out);
// 打印不同类型的数据
ps.println("This is a PrintStream example!");
ps.print("Integer: ");
ps.println(42);
ps.printf("Formatted double: %.2f%n", 3.14159);
// 将输出重定向到文件
PrintStream fileStream = new PrintStream("output.txt");
fileStream.println("This text is written to a file!");
// 关闭文件流
fileStream.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}②PrintWriter
PrintWriter是一个字符输出流,类似于PrintStream,但它专门用于处理字符数据,支持自动换行,适合文本输出。PrintWriter也支持输出到文件,并且可以指定字符编码。
public class PrintWriterExample
{
public static void main(String[] args)
{
PrintWriter writer = null;
try
{
// 创建 PrintWriter,用于将数据写入到文件
writer = new PrintWriter("output.txt");
// 输出不同类型的数据
writer.println("This is a PrintWriter example!");
writer.printf("Formatted integer: %d%n", 123);
writer.printf("Formatted float: %.2f%n", 3.14);
writer.println("This is another line of text.");
// 自动换行
writer.println("This line ends with a newline.");
System.out.println("Data has been written to output.txt");
} catch (IOException e)
{
e.printStackTrace();
} finally
{
if (writer != null)
{
writer.close(); // 关闭 PrintWriter
}
}
}
}7. 对象专属流
①序列化和反序列化
序列化:将对象转换为字节流的过程,以便将对象保存到文件、数据库、网络传输或其他媒介中。Java 通过
Serializable接口来实现对象的序列化。对象需要实现Serializable接口。反序列化:将字节流转换回对象的过程。通过反序列化,恢复对象的状态,以便在程序中重新使用。使用
ObjectInputStream来读取序列化数据并恢复为对象。序列化的对象要求:序列化的对象及其引用的对象也必须实现
Serializable接口,否则会抛出java.io.NotSerializableException异常。
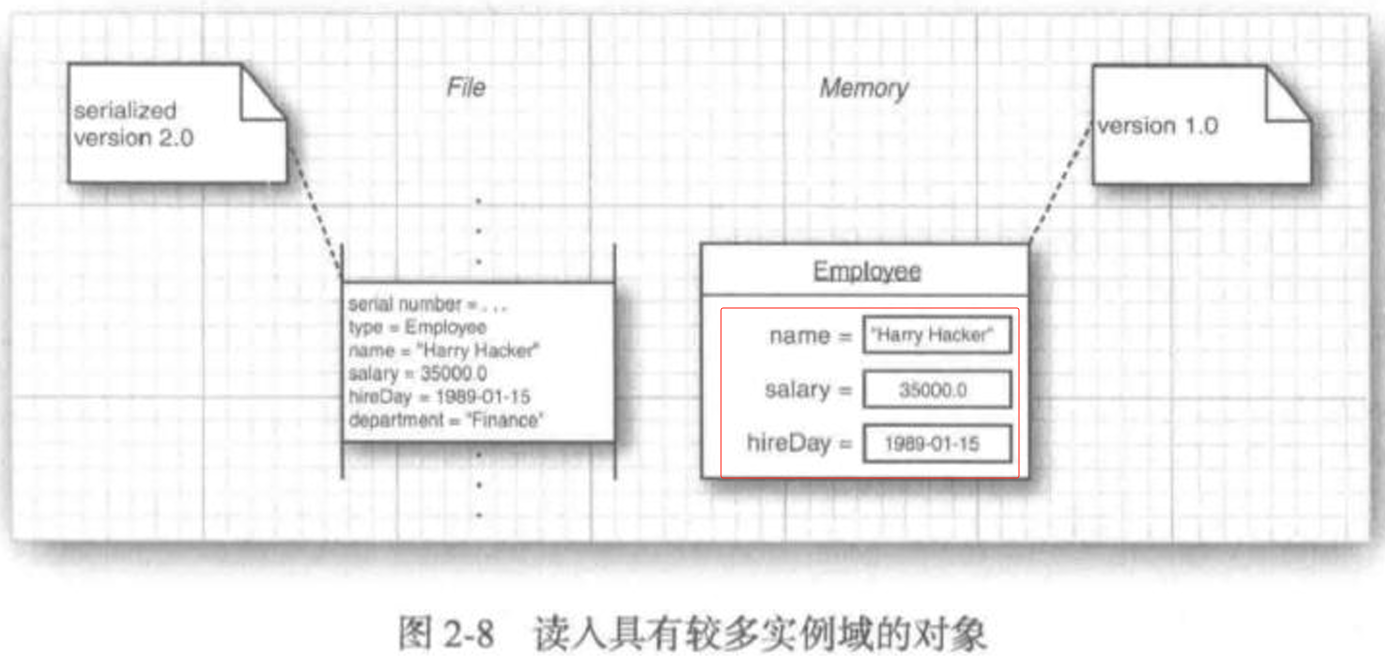
②序列化版本号 serialVersionUID
serialVersionUID是用于版本控制的一个唯一标识符。在反序列化时,Java 会检查序列化版本号是否一致。如果版本号不一致(例如类发生了变化),则会抛出InvalidClassException异常。因此,定义serialVersionUID是一种良好的实践,确保序列化与反序列化过程的一致性。确保不同版本的类可以正确反序列化。即使类发生变化,只要serialVersionUID保持一致,Java 就可以成功反序列化。
③非序列化字段
非序列化字段:如果某个字段不需要被序列化,可以使用
transient关键字标记该字段。例如,private transient String password;。
④Serializable 接口
Serializable接口是一个标记接口,用于指示一个类的对象可以被序列化或反序列化。
⑤@Serial
@Serial注解的引入是为了增强 Java 序列化机制的类型安全性,并在编译时对序列化相关的字段和方法提供更多的语义信息。该注解可以应用于以下场景:
serialVersionUID字段:Java 中的序列化版本控制字段,确保类的版本兼容性。@Serial注解可以标记该字段,以增强类型安全。writeObject方法:当类需要自定义序列化过程时,开发者可以实现writeObject方法,该方法负责将对象的状态写入到输出流中。使用@Serial注解可以明确标记该方法与序列化相关。readObject方法:当类需要自定义反序列化过程时,开发者可以实现readObject方法,该方法负责从输入流中读取对象的状态。@Serial注解标记该方法可以明确其序列化相关性。readObjectNoData方法:该方法用于反序列化时,当对象没有数据时需要做一些特定的处理。@Serial注解可以标记该方法。序列化机制为单个的类提供了一种定制化默认读写行为的方式。若自定义了
writeObject和readObject并@Serial标识,实例域就再也不会被自动序列化,取而代之的是调用这些方法。优势:
增强类型安全性:通过使用
@Serial注解,编译器能够识别出与序列化相关的方法,提供更好的错误检测和提示,避免潜在的错误。代码规范化:标明方法和字段的目的,提升代码的可读性和维护性。
编译时检查:使用
@Serial注解后,编译器会检查writeObject、readObject等方法是否正确实现,并确保这些方法的正确性。注意:
@Serial注解仅适用于序列化和反序列化的相关方法,比如readObject和writeObject,而不适用于其他类型的类方法。@Serial注解不会影响类的序列化行为,它仅仅用于编译时的静态分析,帮助开发者理解和规范序列化相关的代码。
public class Person implements Serializable
{
private static final long serialVersionUID = 1L; // 版本号
private String name;
private transient int age; // 使用 transient,不希望自动序列化这个字段
// 自定义序列化方法
@Serial
private void writeObject(ObjectOutputStream out) throws IOException
{
// 先调用默认的序列化行为
out.defaultWriteObject();
// 然后自己序列化 age 字段
out.writeInt(age); // 将 age 字段显式地序列化
}
// 自定义反序列化方法
@Serial
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException
{
// 先调用默认的反序列化行为
in.defaultReadObject();
// 然后反序列化 age 字段
age = in.readInt(); // 反序列化 age 字段
}
public Person(String name, int age)
{
this.name = name;
this.age = age;
}
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
@Override
public String toString()
{
return "Person{name='" + name + "', age=" + age + "}";
}
public static void main(String[] args)
{
Person person = new Person("Alice", 30);
// 序列化对象
try (ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("person.ser")))
{
out.writeObject(person);
System.out.println("Person object has been serialized.");
} catch (IOException e)
{
e.printStackTrace();
}
// 反序列化对象
try (ObjectInputStream in = new ObjectInputStream(new FileInputStream("person.ser")))
{
Person deserializedPerson = (Person) in.readObject();
System.out.println("Deserialized Person object: " + deserializedPerson);
} catch (IOException | ClassNotFoundException e)
{
e.printStackTrace();
}
}
}
writeObject 方法:在自定义的 writeObject 方法中,我们首先调用了
defaultWriteObject() 来执行默认的序列化行为(即序列化所有非 transient 字段)。
然后我们额外处理了 age 字段(它是 transient 的,因此默认不会被序列化),手动将它写入输出流中。
readObject 方法:在自定义的 readObject 方法中,我们首先调用了
defaultReadObject() 来执行默认的反序列化行为(即恢复所有非 transient 字段)。
然后,我们手动读取 age 字段并恢复它的值。⑥Externalizable接口
Externalizable接口继承自Serializable接口,因此实现了Externalizable的类也能进行序列化和反序列化。与
Serializable的默认序列化机制不同,Externalizable需要开发者自己显式地定义序列化和反序列化的逻辑。通过实现
writeExternal()和readExternal()方法,开发者可以自由选择哪些数据需要被序列化,如何进行序列化,并在反序列化时恢复对象的状态。Serializable:默认情况下,所有类的实例变量会被自动序列化。如果需要自定义序列化行为,开发者只能使用writeObject()和readObject()方法。Externalizable:要求开发者显式实现writeExternal()和readExternal()方法,完全控制序列化和反序列化的过程。
public class Person implements Externalizable
{
private String name;
private int age;
// 必须定义无参数构造函数
public Person()
{
// 无参数构造函数是 Externalizable 接口的要求
//因为反序列化时,JVM 需要通过无参数构造函数创建对象实例,
// 然后再调用 readExternal() 来恢复对象状态。
}
public Person(String name, int age)
{
this.name = name;
this.age = age;
}
// 必须实现 writeExternal 方法
// 序列化:通过 ObjectOutputStream 的
//writeObject() 方法,Person 对象被序列化到文件 person.dat 中。
// 在 writeExternal() 中,我们选择了如何序列化对象的字段。
@Override
public void writeExternal(ObjectOutput out) throws IOException
{
out.writeObject(name); // 显式序列化 name 字段
out.writeInt(age); // 显式序列化 age 字段
}
// 必须实现 readExternal 方法
// 反序列化:通过 ObjectInputStream 的 readObject() 方法,
// Person 对象被从文件 person.dat 中反序列化。在 readExternal() 中,
// 我们从流中恢复对象的字段。
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException
{
name = (String) in.readObject(); // 显式反序列化 name 字段
age = in.readInt(); // 显式反序列化 age 字段
}
@Override
public String toString()
{
return "Person{name='" + name + "', age=" + age + "}";
}
public static void main(String[] args)
{
Person person = new Person("Alice", 30);
// 序列化对象
try (ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("person.dat")))
{
out.writeObject(person);
System.out.println("Person object has been serialized.");
} catch (IOException e)
{
e.printStackTrace();
}
// 反序列化对象
try (ObjectInputStream in = new ObjectInputStream(new FileInputStream("person.dat")))
{
Person deserializedPerson = (Person) in.readObject();
System.out.println("Deserialized Person object: " + deserializedPerson);
} catch (IOException | ClassNotFoundException e)
{
e.printStackTrace();
}
}
}⑦readResolve和writeReplace方法
writeReplace方法:作用:
writeReplace方法在对象序列化时被调用,它允许你在对象写入流之前将其替换为另一个对象。该方法通常用于对象在序列化时的替换或转化。工作原理:当对象调用
ObjectOutputStream.writeObject()进行序列化时,JVM 会先检查对象是否实现了writeReplace()方法。如果实现了该方法,则会调用该方法,返回一个替代对象(通常是一个不同的对象)。然后,替代对象会被序列化,而不是原始对象。使用场景:
writeReplace用于在对象序列化时进行替换,常见的用途包括对象的代理模式、序列化时替换复杂对象等。
readResolve方法:作用:
readResolve方法在对象反序列化时被调用,它允许你在对象反序列化之后对对象进行替换。具体来说,它会返回一个新的对象,替代反序列化得到的对象。工作原理:当对象通过
ObjectInputStream.readObject()被反序列化时,JVM 会检查对象是否实现了readResolve()方法。如果实现了该方法,readResolve()将会被调用,并且返回一个新的对象替代原来的反序列化对象。使用场景:
readResolve常用于单例模式的实现中,可以确保在反序列化时只返回一个单一的实例。此外,readResolve还可以用于在反序列化后修复对象的状态,或者将反序列化的对象转换为其他类型。
class PersonProxy implements Serializable
{
private static final long serialVersionUID = 1L;
private String name;
public PersonProxy(String name)
{
this.name = name;
}
@Override
public String toString()
{
return "PersonProxy{name='" + name + "'}";
}
}
class Person implements Serializable
{
private static final long serialVersionUID = 1L;
private String name;
public Person(String name)
{
this.name = name;
}
public String getName()
{
return name;
}
// 在序列化时替换为另一个对象
private Object writeReplace() throws ObjectStreamException
{
// 替换成另一个对象,例如可以替换为一个更简化的对象
return new PersonProxy(this.name);
}
// 反序列化时,替换为原始对象
private Object readResolve() throws ObjectStreamException
{
return new Person(this.name); // 在反序列化后返回原始对象
}
@Override
public String toString()
{
return "Person{name='" + name + "'}";
}
public static void main(String[] args)
{
Person person = new Person("Alice");
// 序列化
try (ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("person.dat")))
{
out.writeObject(person);
System.out.println("Person object serialized.");
} catch (IOException e)
{
e.printStackTrace();
}
// 反序列化
try (ObjectInputStream in = new ObjectInputStream(new FileInputStream("person.dat")))
{
Person deserializedPerson = (Person) in.readObject();
System.out.println("Deserialized person: " + deserializedPerson);
} catch (IOException | ClassNotFoundException e)
{
e.printStackTrace();
}
}
}⑧为克隆使用序列化
序列化机制有一种很有趣的用法:即提供了一种克隆对象的简便途径,只要对应的类是 可序列化的即可。其做法很简单:直接将对象序列化到输出流中,然后将其读回。这样产生的新对象是对现有对象的一个深拷贝。在此过程中,我们不必将对象写出到文 件中,因为可以用ByteArrayOutputStream将数据保存到字节数组(内存)中。
class Person implements Cloneable, Serializable
{
private String name;
private int age;
private Address address;
// 构造函数
public Person(String name, int age, Address address)
{
this.name = name;
this.age = age;
this.address = address;
}
// Getter 和 Setter 方法
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
public Address getAddress()
{
return address;
}
// 使用序列化方式进行深拷贝
@Override
public Object clone() throws CloneNotSupportedException
{
try
{
// 使用序列化和反序列化实现深拷贝
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
try (ObjectOutputStream out = new ObjectOutputStream(byteArrayOutputStream))
{
// 将当前对象写入字节流
out.writeObject(this);
}
// 通过字节流读取对象,完成深拷贝
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(byteArrayOutputStream.toByteArray());
try (ObjectInputStream in = new ObjectInputStream(byteArrayInputStream))
{
// 从字节流反序列化出一个新的对象
return in.readObject();
}
} catch (IOException | ClassNotFoundException e)
{
throw new CloneNotSupportedException("深拷贝失败:" + e.getMessage());
}
}
@Override
public String toString()
{
return "Person{name='" + name + "', age=" + age + ", address=" + address + "}";
}
}
class Address implements Serializable
{
private String street;
private String city;
// 构造函数
public Address(String street, String city)
{
this.street = street;
this.city = city;
}
// Getter 和 Setter 方法
public String getStreet()
{
return street;
}
public String getCity()
{
return city;
}
@Override
public String toString()
{
return "Address{street='" + street + "', city='" + city + "'}";
}
}
public class DeepCopyUsingSerialization
{
public static void main(String[] args)
{
try
{
// 创建原始对象
Address address = new Address("123 Main St", "Springfield");
Person person1 = new Person("Alice", 30, address);
// 使用 clone() 方法进行深拷贝
Person person2 = (Person) person1.clone();
// 修改克隆对象中的地址字段
person2.getAddress().setCity("New York");
// 打印原始对象和克隆对象,验证它们是独立的
System.out.println("Original Person: " + person1);
System.out.println("Cloned Person: " + person2);
//Original Person: Person{name='Alice', age=30, address=Address{street='123 Main St', city='Springfield'}}
//Cloned Person: Person{name='Alice', age=30, address=Address{street='123 Main St', city='New York'}}
} catch (CloneNotSupportedException e)
{
e.printStackTrace();
}
}
}⑨ObjectInputValidation接口
ObjectInputValidation是 Java 中的一个接口,用于在对象反序列化时执行额外的验证或校验操作。这个接口与 Java 序列化机制结合使用,允许在反序列化过程中调用对象自身的方法进行验证。这对于确保反序列化后的对象符合某些条件或限制是很有用的。该接口的
validateObject()方法会在反序列化过程中被调用,用于对反序列化后的对象进行验证。如果验证失败,validateObject()方法可以抛出InvalidObjectException,该异常表示反序列化的对象无效。
class Person implements Serializable, ObjectInputValidation
{
private static final long serialVersionUID = 1L;
private String name;
private int age;
// 构造函数
public Person(String name, int age)
{
this.name = name;
this.age = age;
}
// Getter 和 Setter 方法
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
// 实现 ObjectInputValidation 接口的 validateObject 方法
@Override
public void validateObject() throws InvalidObjectException
{
// 在反序列化后,进行一些自定义验证
if (name == null || name.isEmpty())
{
throw new InvalidObjectException("Name cannot be null or empty");
}
if (age < 0 || age > 150)
{
throw new InvalidObjectException("Age must be between 0 and 150");
}
}
@Override
public String toString()
{
return "Person{name='" + name + "', age=" + age + "}";
}
}
public class ObjectInputValidationExample
{
public static void main(String[] args)
{
try
{
// 创建一个 Person 对象并进行序列化
Person person = new Person("Alice", 30);
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
ObjectOutputStream objectOutputStream = new ObjectOutputStream(byteArrayOutputStream);
objectOutputStream.writeObject(person);
objectOutputStream.flush();
byte[] personData = byteArrayOutputStream.toByteArray();
// 从字节流中反序列化对象,并注册验证
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(personData);
ObjectInputStream objectInputStream = new ObjectInputStream(byteArrayInputStream)
{
@Override
protected Object resolveClass(ObjectStreamClass desc) throws IOException, ClassNotFoundException
{
Object obj = super.resolveClass(desc);
// 注册验证, 这个方法不会被自动调用必须显式注册到readObject或者在重写的readObject调用
//第二个参数是优先级,具有高优先级的验证求情会先被执行
if (obj instanceof Person)
{
registerValidation((ObjectInputValidation) obj, 0);
}
return obj;
}
};
// 读取并验证对象
Person deserializedPerson = (Person) objectInputStream.readObject();
System.out.println("Deserialized Person: " + deserializedPerson);
} catch (IOException | ClassNotFoundException | InvalidObjectException e)
{
e.printStackTrace();
}
}
}⑩ObjectInputStream和ObjectOutputStream
ObjectOutputStream用于将对象序列化为字节流。它将对象的状态(字段)转换为字节流,并将这些字节写入到输出流中,以便可以在网络上传输或写入磁盘存储。writeObject(Object obj):将指定的对象写入到输出流中,序列化该对象。flush():强制刷新输出流,将数据写入目标流。close():关闭流,释放资源。
ObjectInputStream用于将字节流转换回对象,即反序列化。它从输入流中读取字节流并恢复原始对象。这意味着它通过字节流重新构建对象的状态。readObject():从输入流中读取下一个对象并进行反序列化。close():关闭流,释放资源。
class Person implements Serializable
{
private String name;
private int age;
public Person(String name, int age)
{
this.name = name;
this.age = age;
}
@Override
public String toString()
{
return "Person{name='" + name + "', age=" + age + "}";
}
}
public class ObjectOutputStreamExample
{
public static void main(String[] args)
{
Person person = new Person("Alice", 30);
try (ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("person.ser")))
{
// 将 person 对象写入到文件
out.writeObject(person);
System.out.println("Object has been serialized.");
} catch (IOException e)
{
e.printStackTrace();
}
}
}class Person implements Serializable
{
private String name;
private int age;
public Person(String name, int age)
{
this.name = name;
this.age = age;
}
@Override
public String toString()
{
return "Person{name='" + name + "', age=" + age + "}";
}
}
public class ObjectInputStreamExample
{
public static void main(String[] args)
{
try (ObjectInputStream in = new ObjectInputStream(new FileInputStream("person.ser")))
{
// 从文件中读取 person 对象
Person person = (Person) in.readObject();
System.out.println("Deserialized Person: " + person);
} catch (IOException | ClassNotFoundException e)
{
e.printStackTrace();
}
}
}8. 操作文件
文件管理的内涵远远比读写要广,Path接口和Files类封装了在用户机器上处理文件系统所需的所有功能。输入/输出流类关心的是文件的内容,而我们在此处要讨论的类关心的是文件在磁盘上的存储。
①Path接口
绝对路径:指从文件系统的根目录开始,精确地指定文件或目录的位置。无论当前工作目录在哪里,绝对路径始终指向相同的文件或目录。
相对路径:是相对于当前工作目录(即当前所在目录)来描述文件或目录的位置。它不从根目录开始,而是依赖于当前所在的路径。
Path是 Java NIO(New I/O)中的一个接口,属于java.nio.file包,用于表示文件和目录的路径。它是 Java 7 引入的,目的是为了提供比传统的File类更加强大的文件操作功能。Path对象与文件系统上的文件或目录位置相关联,可以用来执行路径相关的操作,如查找、创建、删除、修改文件、读取文件等。Paths是 Java NIO 中的一个工具类,位于java.nio.file包。它提供了静态方法来创建Path对象,Path用于表示文件或目录的路径,并与其他 NIO 文件操作类(如Files)协同工作。Paths类本身不用于操作文件,它主要用于路径的创建和转换。

②File(s)类
File类是 Java 中用于文件和目录路径操作的一个类,位于java.io包中。它提供了用于处理文件和目录的各种方法,比如创建、删除、重命名文件或目录,检查文件的存在性、权限等。File类并不直接用于读取文件的内容,而是用于对文件和目录进行基本的操作,通常与流类(如FileInputStream、FileOutputStream)配合使用来完成文件的读写任务。Files类是 Java NIO(New I/O)库中的一个工具类,位于java.nio.file包,提供了大量静态方法来操作文件和目录。Files类与Path类紧密结合,能够执行许多常见的文件操作,如创建、复制、移动、删除文件,读取和写入文件内容,检查文件属性等。与File类不同,Files类更为高效和灵活,尤其在大规模文件系统操作时,性能更佳。
③读写文件



④创建文件和目录

⑤复制、移动和删除文件


⑥获取文件信息

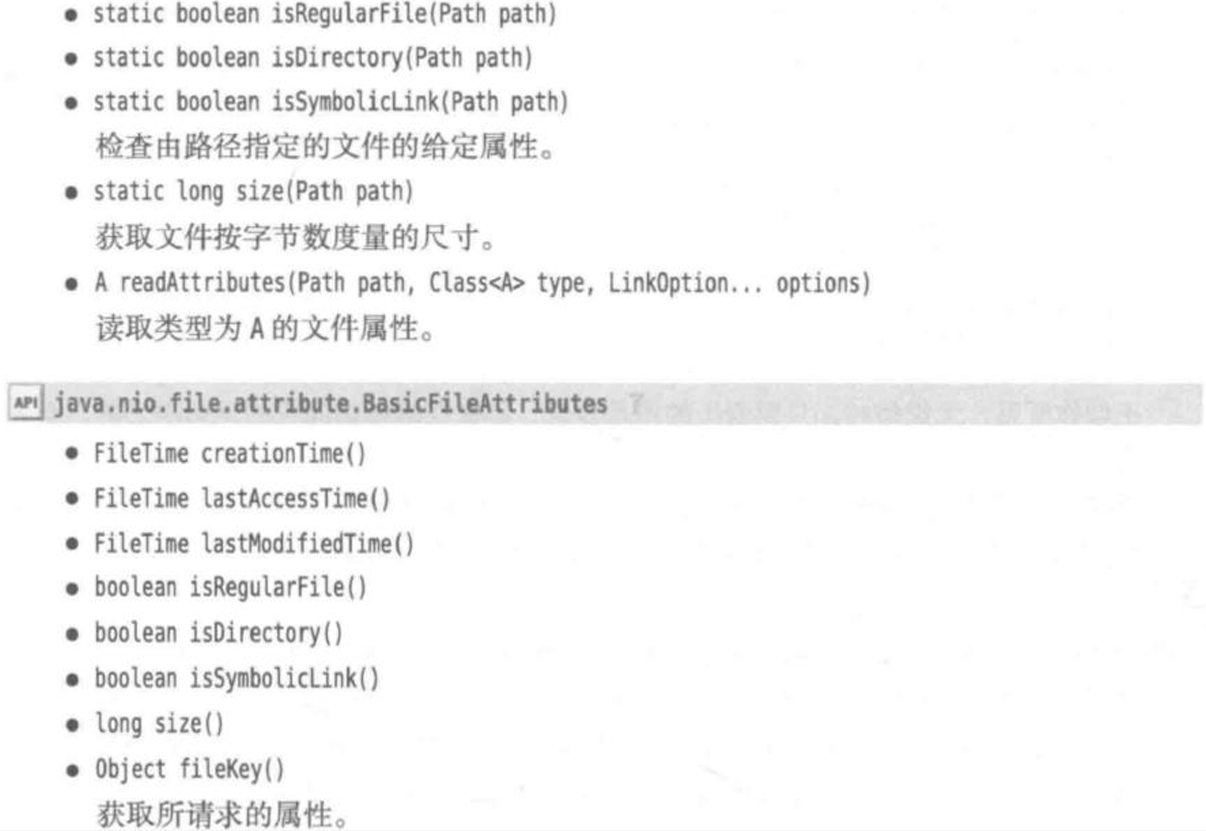
⑦访问目录中的项
访问目录中的项(如文件和子目录)可以通过
java.nio.file.Files和java.nio.file.Paths类实现。通常使用Files.list(),Files.walk(), 或Files.walkFileTree()来列出目录中的内容。Files.list()方法返回一个Stream<Path>,它可以用于遍历目录中的文件。这个方法适用于列出目录中的直接子项(即不会递归进入子目录)。
Files.walk()方法返回一个Stream<Path>,用于递归遍历目录及其子目录中的所有项。你可以通过指定最大深度来限制递归的层次。
Files.walkFileTree()方法提供了更细粒度的控制,可以通过实现FileVisitor接口来定义如何访问目录中的文件和子目录。这个方法适用于更复杂的文件遍历需求,例如在遍历过程中需要自定义操作。

Files.newDirectoryStream()方法返回一个DirectoryStream<Path>,(目录流)可以用于遍历一个目录中的文件。与Files.list()方法不同,DirectoryStream提供了显式的关闭机制。可以用glob模式来过滤文件
public class ListDirectory
{
public static void main(String[] args)
{
Path dirPath = Paths.get("C:/Users/John/Documents"); // 指定目录路径
try (Stream<Path> paths = Files.list(dirPath))
{
paths.forEach(path -> System.out.println(path.getFileName()));
} catch (IOException e)
{
e.printStackTrace();
}
}
}public class WalkDirectory
{
public static void main(String[] args)
{
Path dirPath = Paths.get("C:/Users/John/Documents"); // 指定目录路径
try (Stream<Path> paths = Files.walk(dirPath, 2))
{ // 最大深度为2
paths.forEach(path -> System.out.println(path));
} catch (IOException e)
{
e.printStackTrace();
}
}
}/**
* SimpleFileVisitor 是 FileVisitor 接口的一个简易实现,
* 你可以重写 visitFile 和 visitDirectory 方法来处理访问到的文件和目录。
* FileVisitResult.CONTINUE 表示继续遍历,FileVisitResult.TERMINATE 表示终止遍历。
*/
public class WalkFileTree
{
public static void main(String[] args)
{
Path startPath = Paths.get("C:/Users/John/Documents"); // 指定目录路径
try
{
Files.walkFileTree(startPath, new SimpleFileVisitor<Path>()
{
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException
{
System.out.println("File: " + file);
return FileVisitResult.CONTINUE; // 继续遍历
}
@Override
public FileVisitResult visitDirectory(Path dir, BasicFileAttributes attrs) throws IOException
{
System.out.println("Directory: " + dir);
return FileVisitResult.CONTINUE; // 继续遍历
}
});
} catch (IOException e)
{
e.printStackTrace();
}
}
}public class DirectoryStreamExample
{
public static void main(String[] args)
{
Path dirPath = Paths.get("C:/Users/John/Documents"); // 指定目录路径
try (DirectoryStream<Path> stream = Files.newDirectoryStream(dirPath))
{
for (Path entry : stream)//DirectoryStream是Iterable的子接口可以用增强for
{
System.out.println(entry.getFileName()); // 打印目录项的文件名
}
} catch (IOException e)
{
e.printStackTrace();
}
}
}⑧ZIP文档




//创建zip文件
public class ZipExample
{
public static void createZip(String zipFileName, String[] filesToZip) throws IOException
{
try (ZipOutputStream zos = new ZipOutputStream(new FileOutputStream(zipFileName)))
{
for (String filePath : filesToZip)
{
File fileToZip = new File(filePath);
try (FileInputStream fis = new FileInputStream(fileToZip))
{
// 创建一个新的 ZipEntry,表示一个文件
ZipEntry zipEntry = new ZipEntry(fileToZip.getName());
zos.putNextEntry(zipEntry);
// 将文件内容写入到 ZipOutputStream 中
byte[] buffer = new byte[1024];
int length;
while ((length = fis.read(buffer)) >= 0)
{
zos.write(buffer, 0, length);
}
// 关闭当前的 entry
zos.closeEntry();
}
}
}
}
public static void main(String[] args)
{
try
{
// 要压缩的文件列表
String[] files = {"file1.txt", "file2.txt"};
createZip("output.zip", files);
System.out.println("ZIP file created successfully.");
} catch (IOException e)
{
e.printStackTrace();
}
}
}//读取zip文件
public class ZipExtractExample
{
public static void extractZip(String zipFileName, String destDir) throws IOException
{
File destDirFile = new File(destDir);
if (!destDirFile.exists())
{
destDirFile.mkdir();
}
try (ZipInputStream zis = new ZipInputStream(new FileInputStream(zipFileName)))
{
ZipEntry entry;
while ((entry = zis.getNextEntry()) != null)
{
File file = new File(destDir + File.separator + entry.getName());
if (entry.isDirectory())
{
file.mkdirs(); // 如果是目录,则创建目录
} else
{
// 如果是文件,则解压缩到文件
try (BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(file)))
{
byte[] buffer = new byte[1024];
int length;
while ((length = zis.read(buffer)) >= 0)
{
bos.write(buffer, 0, length);
}
}
}
zis.closeEntry();
}
}
}
public static void main(String[] args)
{
try
{
extractZip("output.zip", "extracted");
System.out.println("ZIP file extracted successfully.");
} catch (IOException e)
{
e.printStackTrace();
}
}
}⑨(ZIP)文件系统


9. 内存映射文件
①介绍
内存映射文件将文件内容映射到进程的虚拟地址空间。操作系统将文件的部分内容(或者整个文件)加载到内存中,程序可以直接访问这些内容,就像访问内存中的数组一样。操作系统会负责文件与内存之间的同步,确保文件内容的变化会反映到磁盘上。
②Java内存映射文件
Java 提供了
java.nio包中的MappedByteBuffer类来实现内存映射文件的功能。使用内存映射文件,你可以将整个文件或文件的一部分映射到内存中,允许程序像操作内存一样进行文件的访问,尤其适用于处理大型文件时。









③缓冲区数据结构
在使用内存映射时,创建了单一的缓冲区横跨整个文件或我们感兴趣的文件区域。 可以使用更多的缓冲区来读写大小适度的信息块。
缓冲区:是由具有相同类型的数值构成的数组,Buffer类是一个抽象类,它有众多的具体子类,包括ByteBuffer、CharBuffer、DoubleBuffer. IntBuffer、LongBuffer 和 ShortBuffer。(StringBuffer和上面没有关系)
缓冲区(Buffer) 是 Java NIO(New Input/Output)库中的一个核心概念,代表着一块用于存储数据的内存区域。缓冲区提供了操作数据的底层机制,能够在内存中有效地处理 I/O 操作,从而提高程序的性能。缓冲区广泛用于文件 I/O、网络 I/O 等场景。
缓冲区的属性:

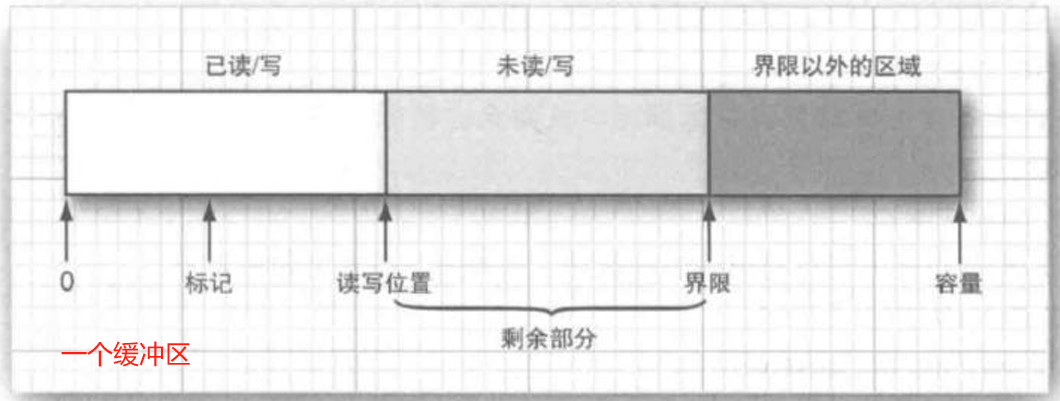



缓冲区工作流程:
写入模式:缓冲区刚创建时处于写入模式。在此模式下,你可以将数据写入缓冲区。
position从 0 开始,limit等于容量(capacity)。切换为读取模式:使用
flip()方法切换为读取模式。limit被设置为position,position被重置为 0。此时,缓冲区变为只读状态,准备从position读取数据。清空缓冲区:当你完成读取并希望重新使用缓冲区进行写入时,可以使用
clear()方法将缓冲区重置。position被设置为 0,limit设置为容量值,clear()方法通常用于重新开始写数据。回滚:
rewind()方法将position重置为 0,用于重复读取缓冲区的数据。
10. 文件加锁机制
①介绍
文件加锁通常是通过使用 文件锁(File Lock) 来控制对文件的并发访问。文件锁机制可以防止多个进程或线程同时访问文件,确保文件的安全性和一致性,特别是在并发环境下。Java 提供了
java.nio.channels包中的FileChannel类和java.nio.channels.FileLock类来实现文件锁。共享锁(Shared Lock):多个进程或线程可以同时获得共享锁,只要它们都只是读取文件而不修改文件。共享锁允许多个读取进程同时访问文件。
独占锁(Exclusive Lock):一个进程或线程获得独占锁后,其他进程或线程无法访问文件,直到释放锁。独占锁用于写操作或修改文件内容。
②文件锁的使用
获取文件锁:使用
FileChannel的lock()或tryLock()方法来获取锁。释放文件锁:调用
FileLock对象的release()方法来释放锁。通常在文件操作完成后释放锁。

③注意

④实例
/**
* 步骤:
* 打开文件:使用 RandomAccessFile 打开文件,并获取 FileChannel。
* 获取锁:调用 channel.lock() 获取文件的独占锁,确保没有其他进程或线程可以同时修改文件。
* 执行操作:在文件上执行相应的文件操作(可以是读或写),确保在锁定期间数据一致性。
* 释放锁:完成操作后,调用 lock.release() 释放锁。
* 关闭资源:最后,关闭 FileChannel 和 RandomAccessFile。
*/
public class FileLockExample
{
public static void main(String[] args)
{
try
{
// 打开文件并获得 FileChannel
RandomAccessFile file = new RandomAccessFile("example.txt", "rw");
FileChannel channel = file.getChannel();
// 获取文件的独占锁
FileLock lock = channel.lock();
System.out.println("文件已锁定...");
// 在文件上执行读写操作
// 可以在此处执行对文件的读写操作
// 释放锁
lock.release();
System.out.println("文件锁已释放...");
// 关闭通道和文件
channel.close();
file.close();
} catch (Exception e)
{
e.printStackTrace();
}
}
}